基于CoSENT的航空裝備領(lǐng)域問句相似度匹配算法*
2023-12-11 12:10:56翟一琛顧佼佼姜文志
艦船電子工程 2023年9期
翟一琛 顧佼佼 劉 濤 姜文志
(海軍航空大學(xué) 煙臺 264001)
1 引言
隨著軍事裝備信息化的高速發(fā)展,裝備配套相關(guān)技術(shù)保障文檔大量增加,戰(zhàn)場形勢瞬息萬變,如何高效地利用這些非結(jié)構(gòu)化文本,快速檢索到需要的信息,對提升裝備使用和維護(hù)效率、掌握戰(zhàn)場主動權(quán)具有重要意義。傳統(tǒng)的信息檢索通常采取基于關(guān)鍵詞匹配的方式,這種方式?jīng)]有考慮到用戶語義表述的多樣性,常常無法準(zhǔn)確地理解用戶意圖[1]。近年來,基于深度學(xué)習(xí)的自然語言處理技術(shù)快速發(fā)展,通過使用深度學(xué)習(xí)模型考慮文字的上下文信息,產(chǎn)生向量化的語義表示,可以更加準(zhǔn)確地表示文本語義。
基于文本語義表示的文本匹配技術(shù)是實現(xiàn)智能問答的關(guān)鍵技術(shù)[2],這類方法通常使用文本對作為知識來源,通過文本相似度匹配將用戶輸入的檢索項與知識庫中存儲的文本進(jìn)行匹配,是目前工業(yè)界實現(xiàn)智能問答系統(tǒng)的主要方式之一[3~4]。隨著深度學(xué)習(xí)的發(fā)展,使用深度學(xué)習(xí)模型進(jìn)行文本相似度匹配是當(dāng)前的主流研究方向,主要分為特征式和交互式兩類方式[5~6]。特征式指輸入的兩個句子分別通過編碼器獲得句向量表示再進(jìn)行相似度匹配,文獻(xiàn)[7]提出的InferSent 模型是典型的特征式模型,文中驗證了將兩路句向量進(jìn)行拼接等操作后作為輸入分類器的特征可以有效提升文本匹配模型的性能。文獻(xiàn)[8]提出Sentence-BERT 模型,驗證了使用BERT(Bidirectional Encoder Representation from Transformers)[9]預(yù)訓(xùn)練模型作為特征抽取器可以有效提升模型性能。交互式指將兩個句子進(jìn)行拼接后再輸入模型,這種方式使得文本在模型內(nèi)可以進(jìn)行更多的交互,模型性能一般較特征式更好,缺點是無法提前存儲計算好的緩存向量,在檢索場景下的效率較差。文獻(xiàn)[10]提出交互式文本匹配模型ESIM,表明了通過構(gòu)建匹配矩陣進(jìn)行句子間交互的有效性。文獻(xiàn)[11]借鑒卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNN)處理圖像的原理,提出MatchPyramid 模型,通過CNN 提取句子間的相似度矩陣特征,達(dá)到融合特征表示,提升模型性能的目的。
將知識庫問答技術(shù)應(yīng)用到垂直領(lǐng)域面臨諸多困難,在數(shù)據(jù)集構(gòu)建方面,現(xiàn)有研究大多基于社區(qū)問答數(shù)據(jù)自動構(gòu)建[12~14]。對于垂直領(lǐng)域下非結(jié)構(gòu)化文本內(nèi)容的問句對構(gòu)建,通常需要組織行業(yè)專家針對文檔內(nèi)容人工提出問題,在問答系統(tǒng)啟動初期,人工標(biāo)注工作量大。為此,本文提出一種面向航空裝備領(lǐng)域技術(shù)文檔的問句對構(gòu)建方法。首先,針對文檔行文特點,對文檔內(nèi)各級標(biāo)題采取規(guī)則模板和SimBERT[15]生成模型進(jìn)行問句生成,然后使用語義相似的關(guān)鍵詞替換方法擴(kuò)充數(shù)據(jù)集,調(diào)整數(shù)據(jù)集正負(fù)比例,減輕人工標(biāo)注工作量。
考慮特征式模型在檢索場景下的優(yōu)點和數(shù)據(jù)集規(guī)模小的問題,使用基于預(yù)訓(xùn)練BERT 的特征式文本相似度匹配模型CoSENT 作為基準(zhǔn)模型。通過關(guān)鍵詞注意力機(jī)制引入外部領(lǐng)域詞典知識指導(dǎo)模型訓(xùn)練;同時針對特征式模型缺乏句對間交互的問題,加入交互機(jī)制進(jìn)一步提升模型性能。
2 命名實體識別模型
2.1 CoSENT模型
BERT 是一種基于多層雙向Transformer 編碼器的預(yù)訓(xùn)練語言模型,可以生成融合上下文信息的句子表征。通常采取預(yù)訓(xùn)練加微調(diào)的訓(xùn)練方式,首先在大量無監(jiān)督數(shù)據(jù)上進(jìn)行掩碼語言模型(Masked Language Model,MLM)和下一句預(yù)測(Next Sentence Prediction,NSP)訓(xùn)練,之后結(jié)合具體的任務(wù)在少量標(biāo)注數(shù)據(jù)上進(jìn)行微調(diào),這種訓(xùn)練方式使得BERT 具有較強(qiáng)的泛化能力,即使在小數(shù)據(jù)集上進(jìn)行訓(xùn)練也能取得良好的性能。
SBERT(Sentence-BERT)模型將BERT 引入到孿生網(wǎng)絡(luò)結(jié)構(gòu)中,利用BERT 生成更有效的句子嵌入用于文本相似性度量任務(wù),模型結(jié)構(gòu)如圖1所示。基于SBERT 模型改進(jìn)的CoSENT 模型[16]主要針對原模型訓(xùn)練與預(yù)測不一致的問題,對模型的損失優(yōu)化部分進(jìn)行了改進(jìn),由原來先特征拼接再連接Softmax 分類器輸出類別,優(yōu)化分類損失的方式,改為直接優(yōu)化句子對間的余弦距離,模型結(jié)構(gòu)如圖2所示,損失計算公式為

圖1 Sentence-BERT模型結(jié)構(gòu)圖
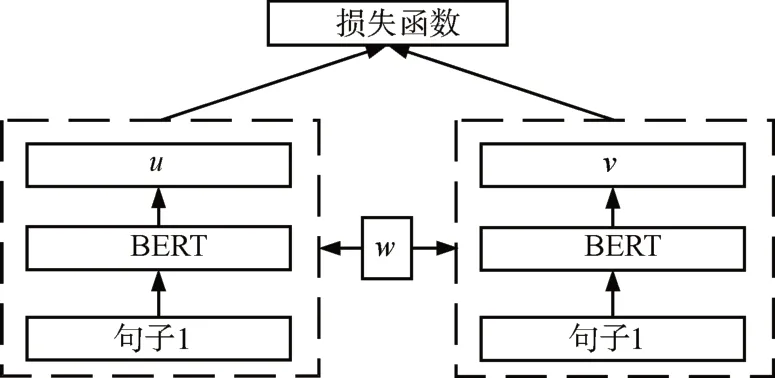
圖2 CoSENT模型結(jié)構(gòu)圖
其中(i'j)∈Ωpos,(k'l)∈Ωneg,Ωpos為正樣本集合,Ωneg為負(fù)樣本集合,uk、ul、ui、uj分別為正樣本對和負(fù)樣本對的句向量表示,λ為超參數(shù)。
2.2 SimBERT模型
Seq2Seq[17]指的是給模型輸入一段文本后,模型會輸出另一段文本,Seq2Seq 模型一般采用編碼器-解碼器結(jié)構(gòu),編碼器將輸入文本編碼為固定大小的向量,解碼器將這個向量以自回歸的方式進(jìn)行解碼,生成對應(yīng)的文本。BERT 模型在提出時用于進(jìn)行自然語言理解任務(wù),其核心Transformer[18]編碼器采用雙向自注意力機(jī)制,對于輸入的句子,句子中每個詞之間都是可見的,無法用于自然語言生成任務(wù)。微軟提出通過構(gòu)建如圖3所示的特殊的注意力掩碼矩陣,將BERT 模型改造為可以進(jìn)行自然語言生成任務(wù)的統(tǒng)一預(yù)訓(xùn)練語言模型(Unified Language Model,UniLM)[19]。

圖3 UniLM模型的注意力掩碼矩陣
SimBERT 是一種以BERT 模型為基礎(chǔ)的融合檢索與生成于一體的模型,與BERT 模型相比,其具有文本生成能力的核心就是使用了UniLM 中的Seq2Seq 訓(xùn)練方式。訓(xùn)練SimBERT 生成相似問句首先需要收集大量的相似問句對,同一相似問句對在輸入模型時通過[SEP]進(jìn)行分割,之后對輸入語句使用特殊的注意力掩碼矩陣,這種形式的注意力掩碼矩陣使得[SEP]之前的字符之間實現(xiàn)了雙向注意力,[SEP]之后的字符之間實現(xiàn)了單向注意力,從而使得模型具有遞歸的預(yù)測后半句的能力。
2.3 關(guān)鍵詞注意力機(jī)制
與交互式模型相比,特征式模型由于缺乏對句子間的特征融合,模型無法更加有效地關(guān)注文本中的關(guān)鍵信息,本文借鑒文獻(xiàn)[20]提出的關(guān)鍵詞自注意力機(jī)制,利用外部領(lǐng)域關(guān)鍵詞知識指導(dǎo)模型訓(xùn)練。自注意力機(jī)制可以計算句子內(nèi)部字符之間的相關(guān)性,本文首先通過對文本輸入X=[x1'...'xn]使用領(lǐng)域詞典W進(jìn)行關(guān)鍵詞識別,之后構(gòu)建關(guān)鍵詞掩碼矩陣作用在關(guān)鍵詞掩碼自注意力層上,強(qiáng)制模型關(guān)注句子中的關(guān)鍵詞。其表達(dá)形式如下:
改進(jìn)后的模型整體結(jié)構(gòu)如圖4所示,句子1、2通過的網(wǎng)絡(luò)均共享權(quán)重。首先,句子按字符粒度輸入到BERT 模型中,BERT 模型輸出包含上下文信息的語義表示,其中[CLS]向量作為句子原始的整體信息直接送入特征拼接層,其余每個字符的輸出向量送入關(guān)鍵詞掩碼自注意力層。在關(guān)鍵詞掩碼矩陣的作用下,句子內(nèi)的關(guān)鍵詞進(jìn)行注意力交互,之后輸出向量至池化層進(jìn)行特征的進(jìn)一步提取,兩路池化層的輸出向量之間進(jìn)行特征拼接與交互,與Sentence-BERT、InferSent等特征式模型不同,CoSENT模型直接對句子表示的余弦相似度進(jìn)行優(yōu)化,所以在進(jìn)行特征拼接和交互后,特征向量仍應(yīng)保持句子表示的相對獨立性,即拼接后的特征向量仍然可以表示該輸入語句的語義信息。
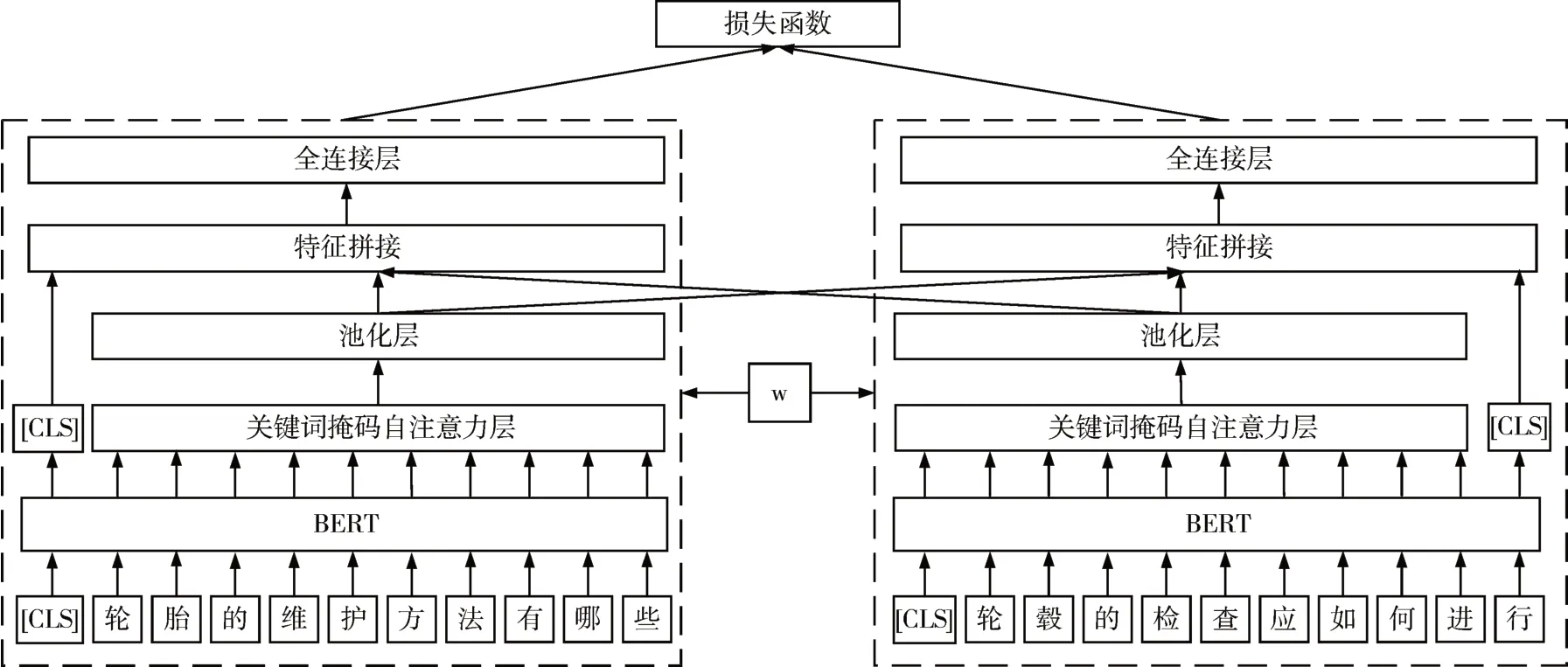
圖4 融合關(guān)鍵詞注意力機(jī)制的CoSENT模型
3 實驗驗證
3.1 數(shù)據(jù)集構(gòu)建
自建數(shù)據(jù)集來源于航空行業(yè)IETM相關(guān)技術(shù)手冊中的PDF 文檔,根據(jù)文檔文本的行文特點,首先使用PDF 文本抽取技術(shù)和正則表達(dá)式匹配的方法提取文檔內(nèi)所有的標(biāo)題,根據(jù)標(biāo)題的層級關(guān)系,建立常見問句模板將標(biāo)題關(guān)鍵詞擴(kuò)充成句,然后使用在2200萬個問句對數(shù)據(jù)集上預(yù)訓(xùn)練的SimBERT模型自動生成大量相似問句,生成示例如表1所示。人工挑選出表達(dá)通順的句子并判斷相似或不相似,根據(jù)此方法標(biāo)注數(shù)據(jù)集共2463條。

表1 文本生成示例
利用SimBERT 生成的相似問句多數(shù)與原句語義相似,數(shù)據(jù)集會出現(xiàn)正負(fù)比例不均衡的現(xiàn)象。通過隨機(jī)替換、隨機(jī)刪除等方法生成的負(fù)例與真實標(biāo)注相差較大,使得數(shù)據(jù)集噪聲過大,訓(xùn)練效果差。本文使用領(lǐng)域詞典對句子中的關(guān)鍵詞進(jìn)行識別,并在與關(guān)鍵詞同類型的詞語中選擇字面不同但語義相關(guān)的詞語進(jìn)行替換,通過此方法生成的負(fù)樣例更難區(qū)分,更接近真實負(fù)例,有助于模型訓(xùn)練。語義相似度使用在所有語料上訓(xùn)練的Word2Vec[21]模型進(jìn)行計算,本文選取相似度大于0.8但小于0.9的詞語進(jìn)行相似詞替換,生成負(fù)樣本示例如表1所示。
在非結(jié)構(gòu)化文本數(shù)據(jù)上,通過這種方式生成數(shù)據(jù)集不需要人工生成問句,只需要進(jìn)行選擇,減輕了人工標(biāo)注的工作量。最終得到4000 對相似問句對數(shù)據(jù)集,數(shù)據(jù)集平均文本長度為17,最大文本長度為42,問句對正負(fù)比例為1.25∶1,按6∶2∶2 劃分為訓(xùn)練集、驗證集和測試集。
訊飛文本相似度數(shù)據(jù)集來自訊飛中文問題相似度挑戰(zhàn)賽,為通用領(lǐng)域下的相似問句對數(shù)據(jù)集。本文使用可供下載的5000 對問句對進(jìn)行實驗,數(shù)據(jù)集平均文本長度為21,最大文本長度為83,問句對正負(fù)比例為1.37∶1,在數(shù)據(jù)集規(guī)模、文本長度和正負(fù)比例上與本文自建數(shù)據(jù)集相近,按6∶2∶2 劃分為訓(xùn)練集,驗證集和測試集。
3.2 實驗配置
1)實驗設(shè)置
實驗環(huán)境為處理器Inter(R)Xeon(R)Gold 5218R、操作系統(tǒng)Ubuntu 18.04.2LTS、顯卡RTX 3090,開發(fā)環(huán)境為Python3.7,使用Pytorch1.8.0 框架。
模型參數(shù)設(shè)置如下:BERT 輸入的最大序列長度為64,批處理大小為128,向量維度為768,使用AdamW優(yōu)化器,學(xué)習(xí)率設(shè)置為2e-5,超參數(shù)λ=5。
2)評價指標(biāo)
在檢索場景下,更關(guān)注預(yù)測分?jǐn)?shù)的順序,Spearman 相關(guān)系數(shù)定義為兩個變量的秩統(tǒng)計量間的Pearson 相關(guān)系數(shù),其值與兩組變量的具體值無關(guān),僅與值之間的大小關(guān)系有關(guān)。首先將模型輸出的相似度與真實標(biāo)簽值分別進(jìn)行排序(同時為升序或降序),得到集合x和y后其計算公式如下:
其中兩個集合的元素個數(shù)均為N,、分別表示兩集合平均位次的值。
3.3 實驗結(jié)果及分析
本文選取了ESIM,InferSent,Sentence-BERT,BERT,CoSENT共五種主流的文本匹配模型進(jìn)行對比實驗,其中InferSent 和ESIM 模型均采用CNN 進(jìn)行特征抽取,表2 展示了選取的幾種基準(zhǔn)模型在自建數(shù)據(jù)集和訊飛文本相似度數(shù)據(jù)集上的實驗結(jié)果。實驗結(jié)果表明,不論是交互式模型還是特征式模型,在使用預(yù)訓(xùn)練BERT 模型后,模型性能均得到較大提升。選擇同樣的特征抽取模型時,交互式模型的表現(xiàn)明顯優(yōu)于特征式模型。由于交互式模型不能離線獲得文本的向量表示,檢索場景下效率較低,本文選取特征式模型中表現(xiàn)最優(yōu)的CoSENT作為基準(zhǔn)模型。
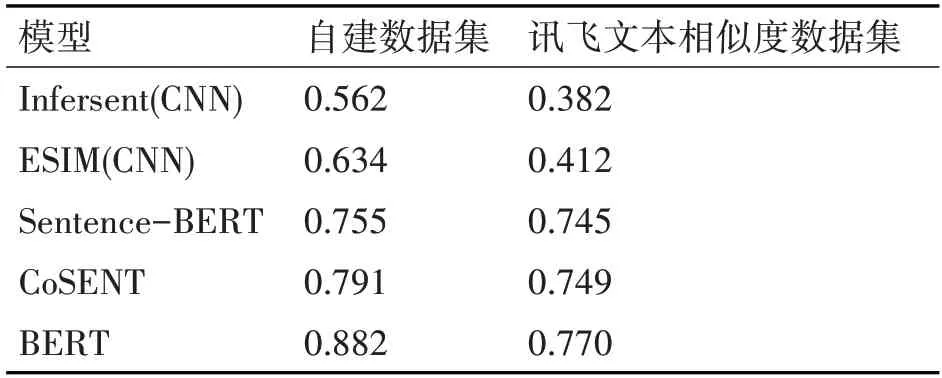
表2 模型對比實驗
為加強(qiáng)文本中關(guān)鍵信息在模型訓(xùn)練過程中的重要性,使用詞典識別輸入文本中的名詞、動詞和動名詞,構(gòu)建關(guān)鍵詞掩碼矩陣,并作用在CoSENT模型向量輸出部分的關(guān)鍵詞自注意力層上,對該層的輸出向量進(jìn)行三種池化策略的實驗,實驗結(jié)果如表3所示,在自建數(shù)據(jù)集上,直接取關(guān)鍵詞自注意力層的CLS向量與CoSENT模型的CLS輸出向量進(jìn)行拼接時,Spearman 相關(guān)系數(shù)由0.791 提升到了0.806;在訊飛文本相似度數(shù)據(jù)集上對關(guān)鍵詞自注意力層使用平均池化策略輸出的向量與CoSENT模型的CLS輸出向量進(jìn)行拼接時,Spearman相關(guān)系數(shù)由0.749 提升到了0.763。同時注意到,不論使用何種形式的關(guān)鍵詞注意力機(jī)制,模型性能都會穩(wěn)定提升,驗證了本文提出方法的有效性。
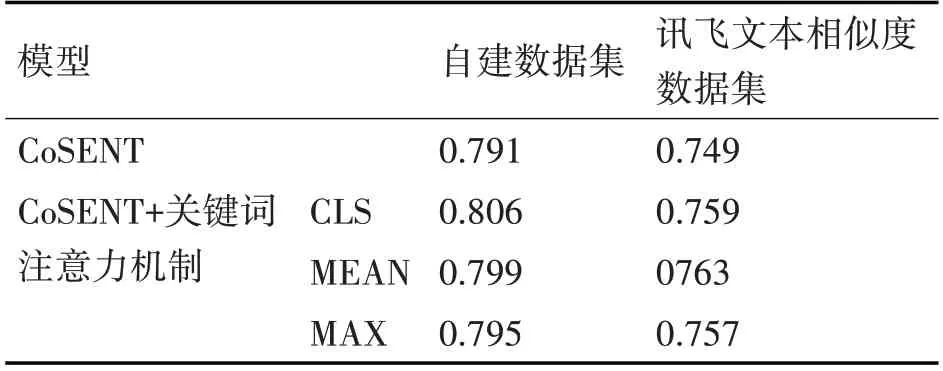
表3 關(guān)鍵詞注意力機(jī)制實驗
圖5 為CoSENT 模型加入關(guān)鍵詞自注意力層前后的損失函數(shù)曲線圖,從圖中可以看出加入關(guān)鍵詞注意力機(jī)制可以有效幫助模型收斂,使得模型性能更加穩(wěn)定。
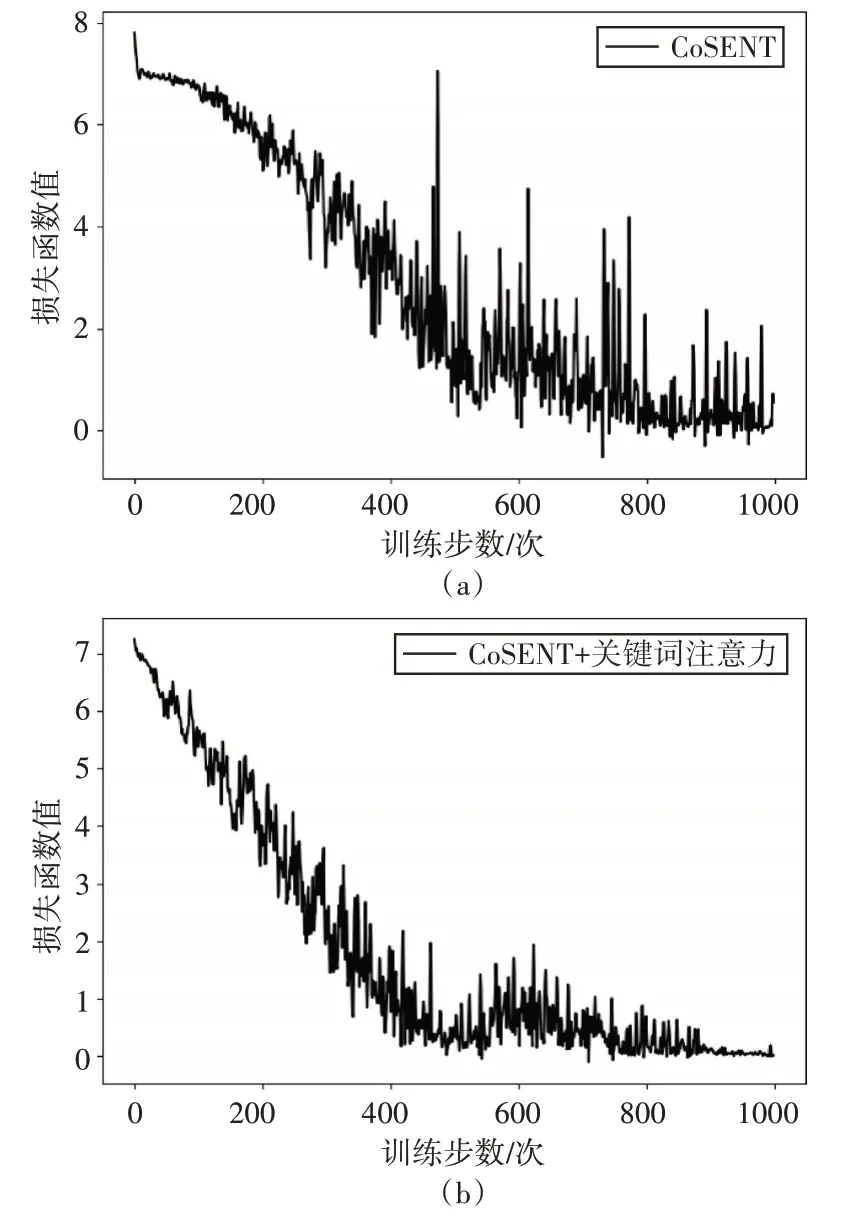
圖5 損失函數(shù)曲線圖
在使用關(guān)鍵詞注意力機(jī)制的基礎(chǔ)上,對特征交互階段的向量拼接策略進(jìn)行實驗,表4 中列出了特征拼接時選擇三種池化策略時各自最好的實驗結(jié)果。對于本文使用的兩個數(shù)據(jù)集而言,選擇平均池化策略和最大池化策略的效果都要優(yōu)于直接使用CLS向量,兩個數(shù)據(jù)集的Spearman相關(guān)系數(shù)分別達(dá)到了0.814 和0.766。另外,在表4 中還分別展示了在自建數(shù)據(jù)集和訊飛文本相似度數(shù)據(jù)集下分別使用平均池化策略和最大池化策略進(jìn)行特征拼接的實驗結(jié)果,ucls'表示當(dāng)前輸入句子BERT 層的CLS輸出向量,u,v分別表示兩句子的輸出向量。實驗結(jié)果顯示,在自建數(shù)據(jù)集和訊飛文本相似度數(shù)據(jù)集上,特征交互階段分別使用(ucls''u'u-v) 和(ucls''u'|u-v|) 拼接策略時模型性能最好,代表在CoSENT 模型中,表示兩句子間差異信息的u-v和|u-v|向量可以為相似性度量提供更多的特征信息。同時,使用u*v向量作為交互特征均會降低模型性能。
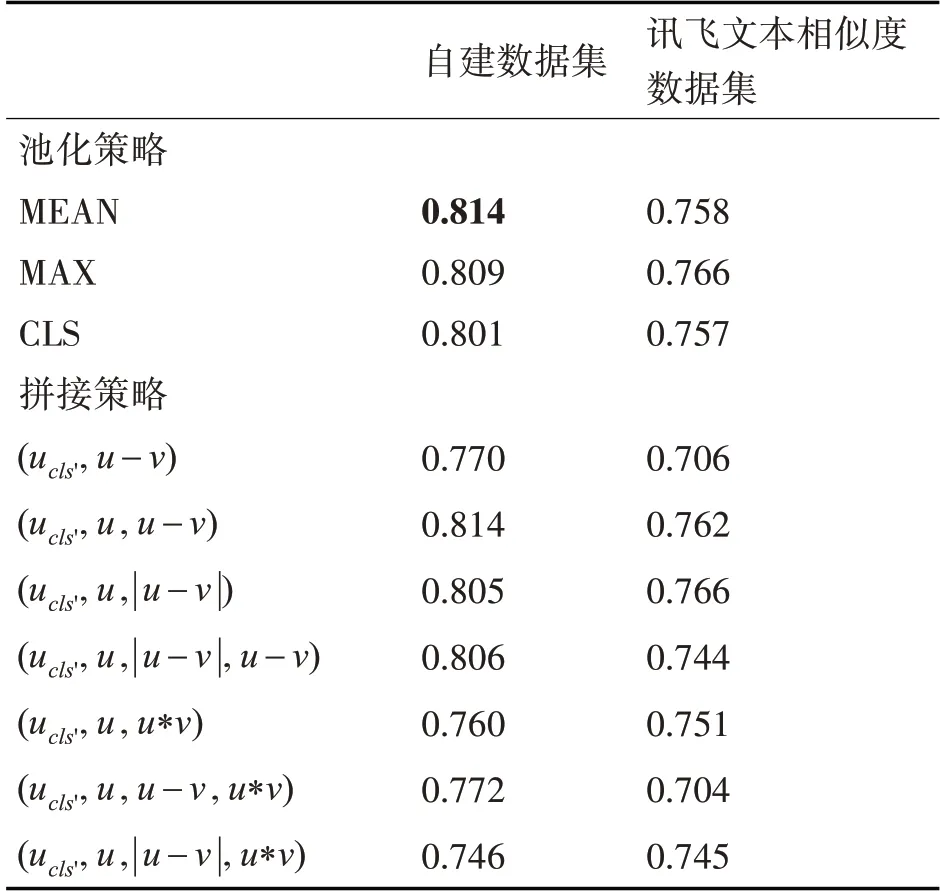
表4 特征向量拼接實驗
4 結(jié)語
首先針對航空維修領(lǐng)域技術(shù)手冊中非結(jié)構(gòu)化文本問句對數(shù)據(jù)集構(gòu)建困難的問題,提出一種面向該領(lǐng)域技術(shù)手冊的數(shù)據(jù)集構(gòu)建方法,結(jié)合文本行文特點,利用規(guī)則模板、Word2Vec 模型、深度學(xué)習(xí)生成模型等手段自動生成有實際意義的問句對,減輕人工標(biāo)注的工作量,構(gòu)建了一個數(shù)據(jù)量大小為4000對的航空維修領(lǐng)域問句相似對數(shù)據(jù)集。
對主流的文本相似度匹配模型進(jìn)行實驗,選取檢索場景下效率更高的特征式模型CoSENT 作為基準(zhǔn)模型,使用外部詞典知識通過關(guān)鍵詞注意力機(jī)制指導(dǎo)模型訓(xùn)練,同時針對特征式模型文本交互不夠充分的特點加入特征交互機(jī)制,并對關(guān)鍵詞注意力機(jī)制和特征融合方式在自建數(shù)據(jù)集和訊飛文本相似度數(shù)據(jù)集上進(jìn)行實驗,結(jié)果表明本文提出的方法可以有效提升CoSENT模型的文本匹配性能。
