基于實時車流信息的電動汽車未來行駛工況預測
2023-12-12 04:25:44黃韜一劉寅童
重慶理工大學學報(自然科學) 2023年11期
關鍵詞:實驗
張 毅,黃韜一,劉寅童
(1.重慶理工大學 車輛工程學院, 重慶 400054; 2.重慶長安汽車股份有限公司, 重慶 400020)
0 引言
汽車是一種便利高效的交通工具,如今在人們的生活中已不可或缺。傳統燃油車對燃料的需求造成了棘手的能源危機,各種尾氣的排放也引出了環境污染等問題。而電動車等新能源汽車則是解決這些問題的主要手段[1]。但由于不能精確地預測車輛的未來能耗與剩余行駛里程,導致新能源車廠選擇保守的整車能量管理策略[2],同時也加劇用戶的里程焦慮。針對此問題,目前出現了許多針對電動車未來能耗的預估方法。林仕立等[3]進行基于SOE (state of energy)的純電動車剩余行駛里程預測,相較于傳統SOC (state of charge)的預測方法,預測精度可以提升4.09%。劉光明等[4]將電池容量估計和能耗預測結合,利用純電動汽車相關測試數據和基于最小二乘法的能耗估計公式,得到預測的剩余續航里程。Rodgers等[5]使用多元回歸方法分析出車輛行駛速度、環境溫度、交通狀況等因素與能耗變化之間的關系,然后根據車輛歷史能耗數據預測未來能耗值。Pan等[6]提出基于工況識別與預測相結合的電動車行駛里程估計模型。該模型基于核主成分特征參數和模糊算法對駕駛工況進行識別,以建立特征參數與能耗之間的模糊關系,進而利用馬爾可夫和神經網絡算法預測未來車輛的行駛工況。Yu等[7]使用基于聚類分析的車輛行駛狀態識別方法,確定車輛行駛能耗需求,在空間域內將行駛道路分割成若干小的行駛片段,并根據交通狀況、道路信息及駕駛行為特性等對各區段內的車輛行車狀態進行狀態識別,進而預測各段能耗需求。Lee等[8]基于大數據理論,利用聚類算法分析不同駕駛模式下的能量效率,再結合動力電池的老化模型,較高精度地估計純電動車的SOC與行駛里程。
現有研究仍有較大的改進空間。首先,現有研究并未充分考慮到實時車流狀況對能耗的影響。其次,現有實驗驗證大多基于理想情況下的假設條件,并沒有進行真實車輛道路實驗驗證。這導致其數據過于理想化,缺少實際可行性。基于以上不足,為精確且穩定地預測車輛的未來行駛工況,本文基于百度地圖API (application programming interface)接口的實時車流信息和實車OBD (on-board diagnostics)獲取的單車歷史行駛數據,建立了一個基于機器學習的車輛行駛工況預測模型,并使用實車在環平臺進行實車路試實驗。
本文提出的預測算法流程如圖1所示。其中,實車在環平臺中測試車輛所獲取的單車行駛數據(見1.4節)與百度地圖API所提供的車流數據(見1.5節)在被預處理和特征參數提取后,將在云端服務器中用以離線訓練機器學習預測算法。通過EM (expectation maximization)聚類分析,將歷史行車數據分成8種典型行駛工況(見2.1節),并用于訓練RBF (radial basis function)分類器(見2.2節)。最后,利用訓練好的RBF分類器根據百度地圖API提供的實時車流信息,以預測汽車的未來行駛工況類型及其平均能耗,從而得到未來SOC(即剩余續航里程)的變化趨勢。
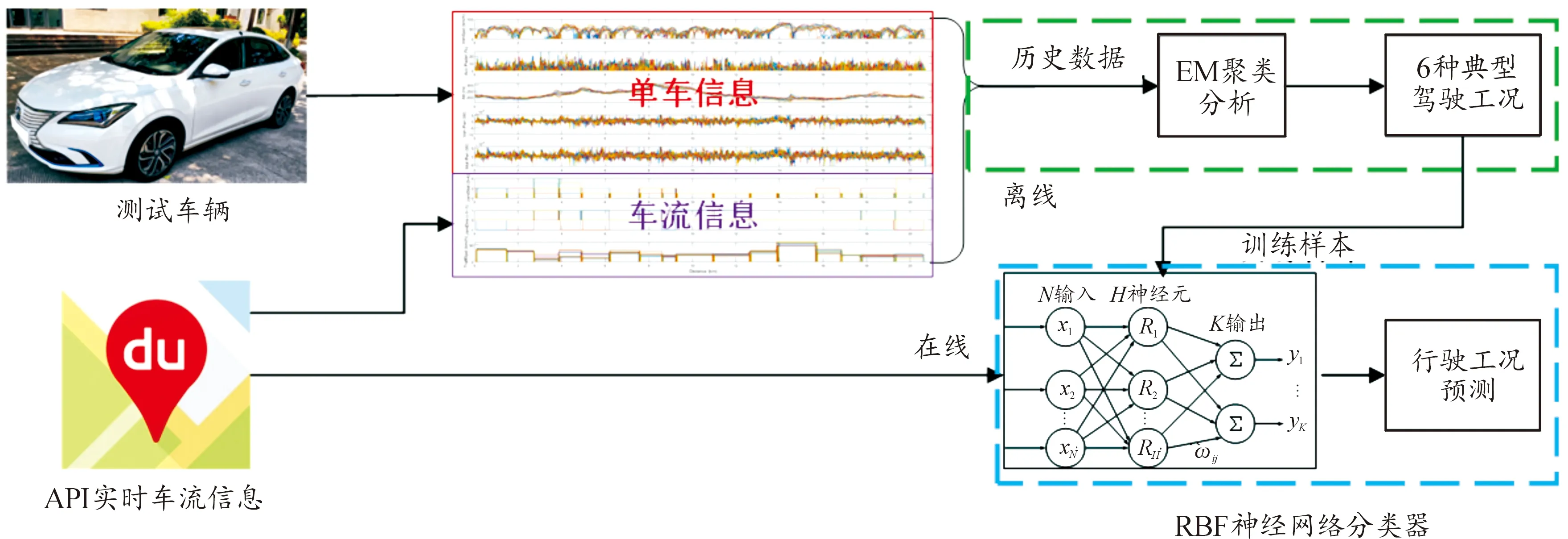
圖1 基于百度地圖API的車輛行駛工況預測算法流程
1 實車在環實驗平臺
1.1 車聯網與云計算
傳統車載控制器的計算能力與存儲空間無法滿足實時運行車輛未來工況預測算法的需求。本研究使用云端服務器作為計算與通信中樞,如圖2所示。云端服務器存儲著通過車載OBD獲取的單車數據,以及通過百度地圖API接口獲取的實時車流信息。這二者共同作為歷史數據,用于離線訓練基于機器學習的云端預測算法。在實車實驗中,云端服務器使用離線訓練完成的機器學習預測算法,并根據百度地圖API提供的實時車流信息,對未來行駛工況進行在線預測。
1.2 實車在環設備
本實驗使用長安逸動純電動汽車作為在環車輛。如圖3所示,實驗中涉及的車載硬件子系統包括:USB轉CAN接口卡,筆記本電腦,GPS模塊。實車在環相關實驗設備如圖4所示。測試車輛的具體參數見表1。
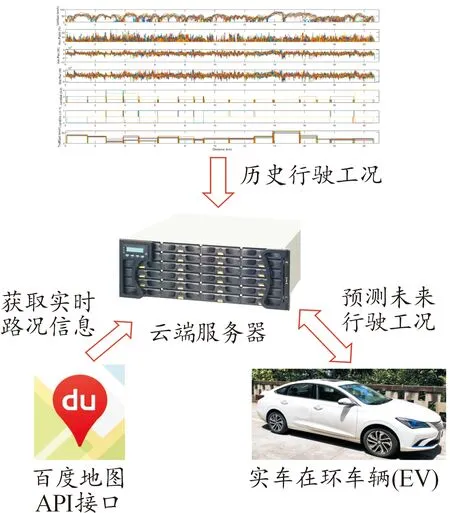
圖2 云數據處理示意圖

圖3 上路測試車輛
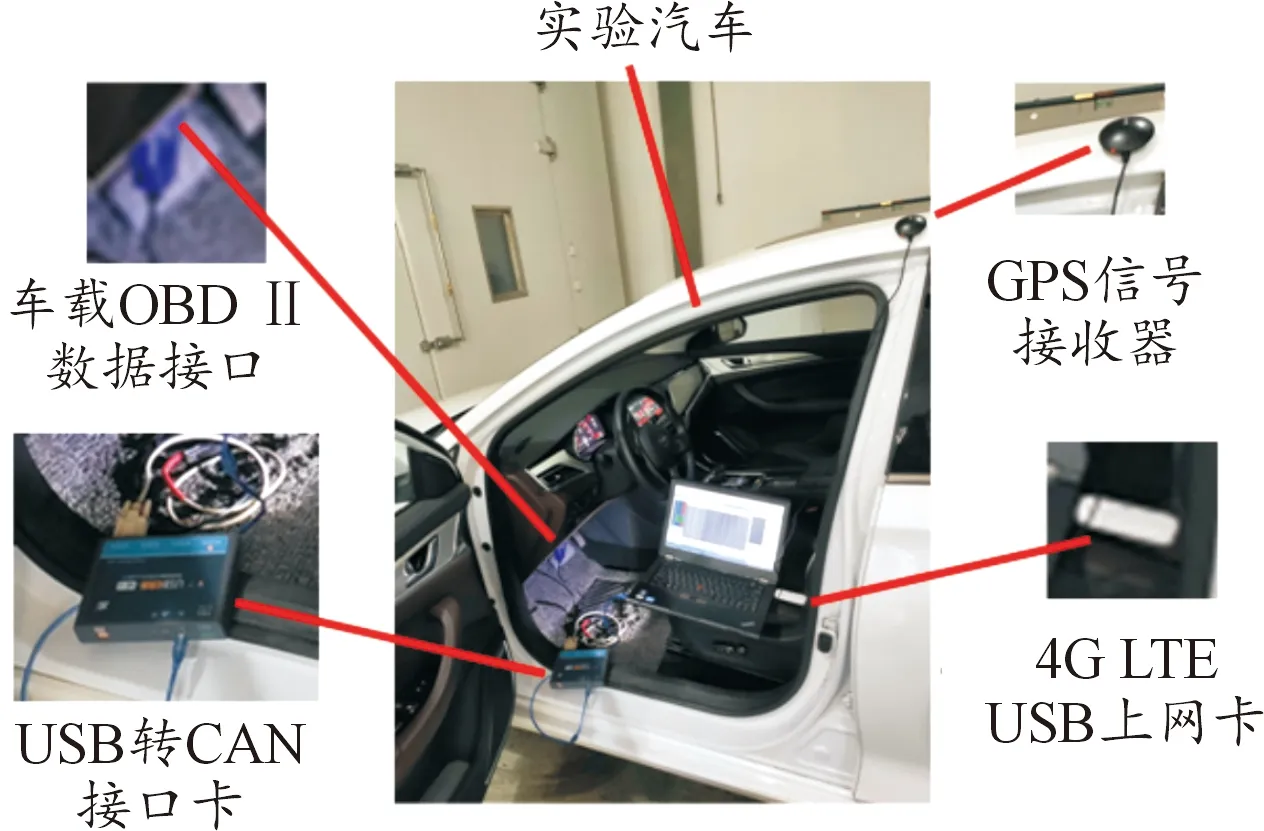
圖4 實車在環相關實驗設備
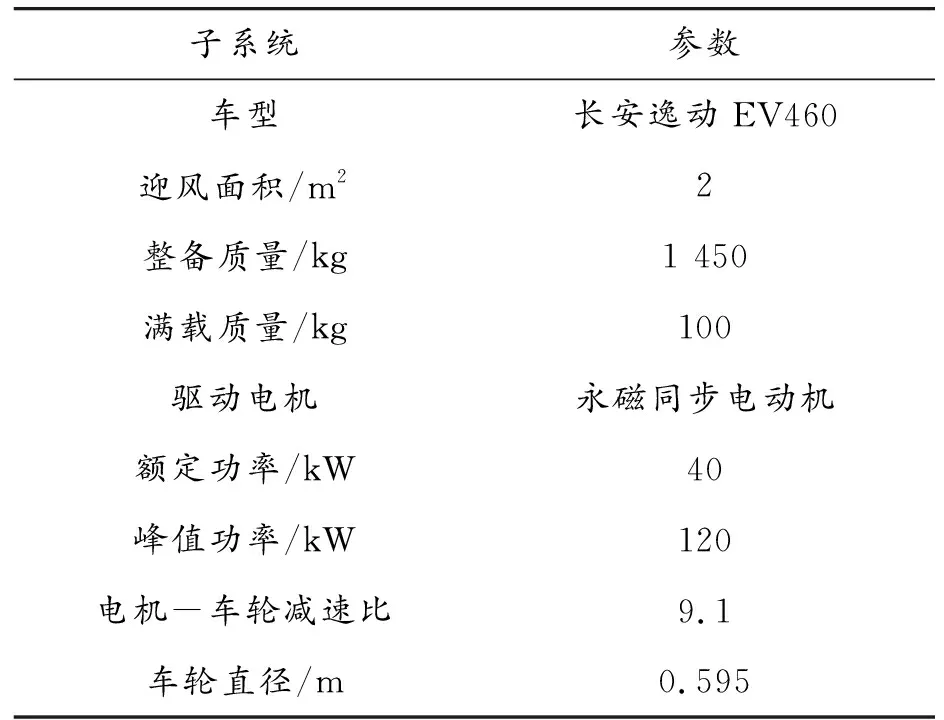
表1 測試車輛參數
此外,本文在汽車OBD通信協議的基礎上設計了一套能夠讀取車載OBDII接口數據的軟硬件系統[9]。通過USBCAN-4E-U接口卡與車載CAN總線進行數據交換,讀取車輛行駛狀態相關數據(即單車數據),并通過4G LTE (long term evolution)網絡實時上傳到云端服務器并作為歷史數據,建立一個未來行駛工況的預測模型。數據的具體情況在1.4節中介紹。
1.3 電池仿真模型
測試車輛(長安逸動)自帶的電池系統的SOC檢測僅精確到個位數,無法滿足本文的實時預測算法的精度需求,故在云端建立了一個電池軟件仿真模型,根據實車OBD的驅動功率,實時計算電池SOC的變化量。如圖5所示,電池等效電路模型為一個經典的內阻模型。圖中,電池開路電壓Voc(V)和等效電阻Rin(Ω)均為SOC的函數。
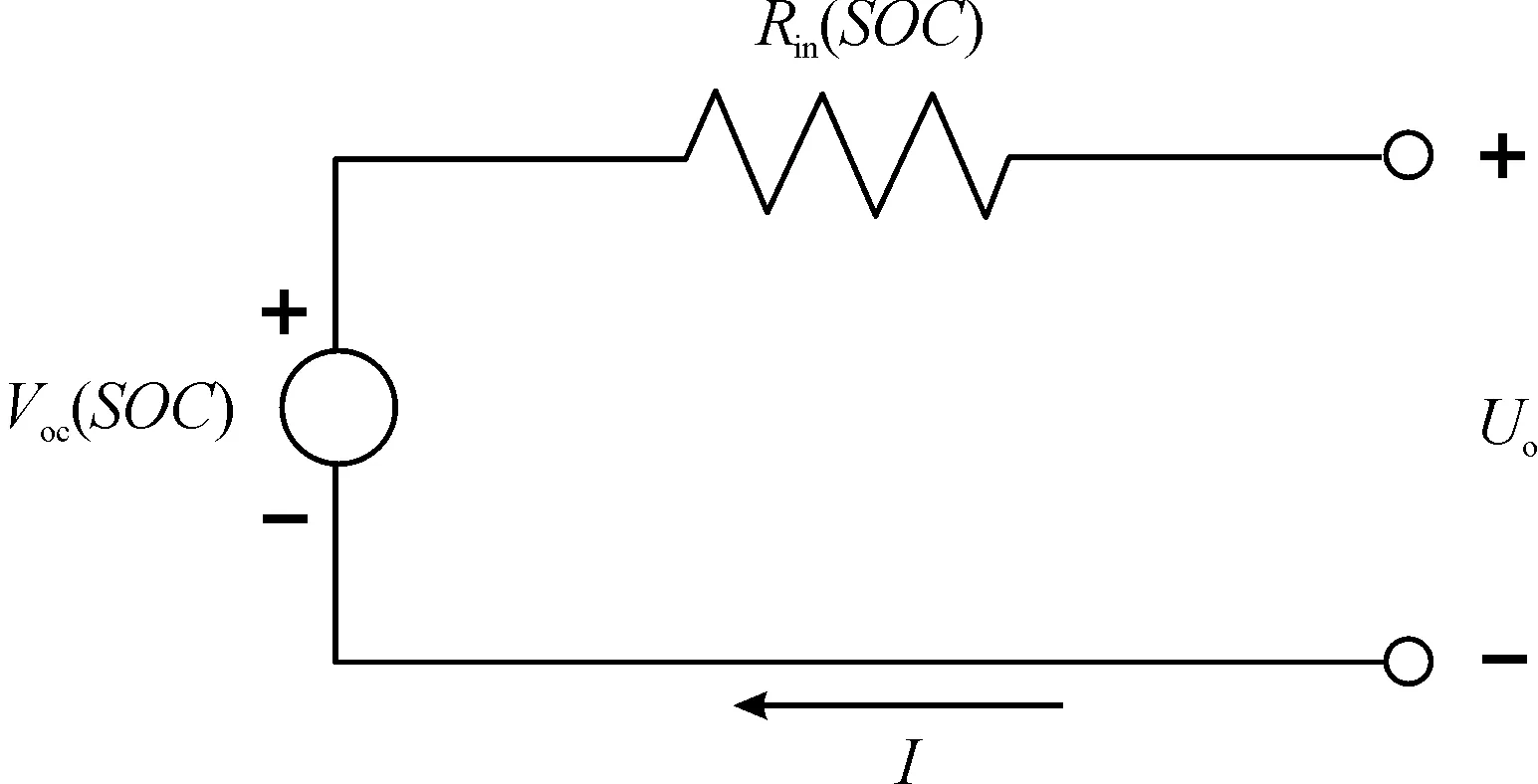
圖5 電池等效電路模型
Voc和Rin的具體參數使用的是某型號磷酸鐵鋰電池的實測參數[10],如圖6所示。
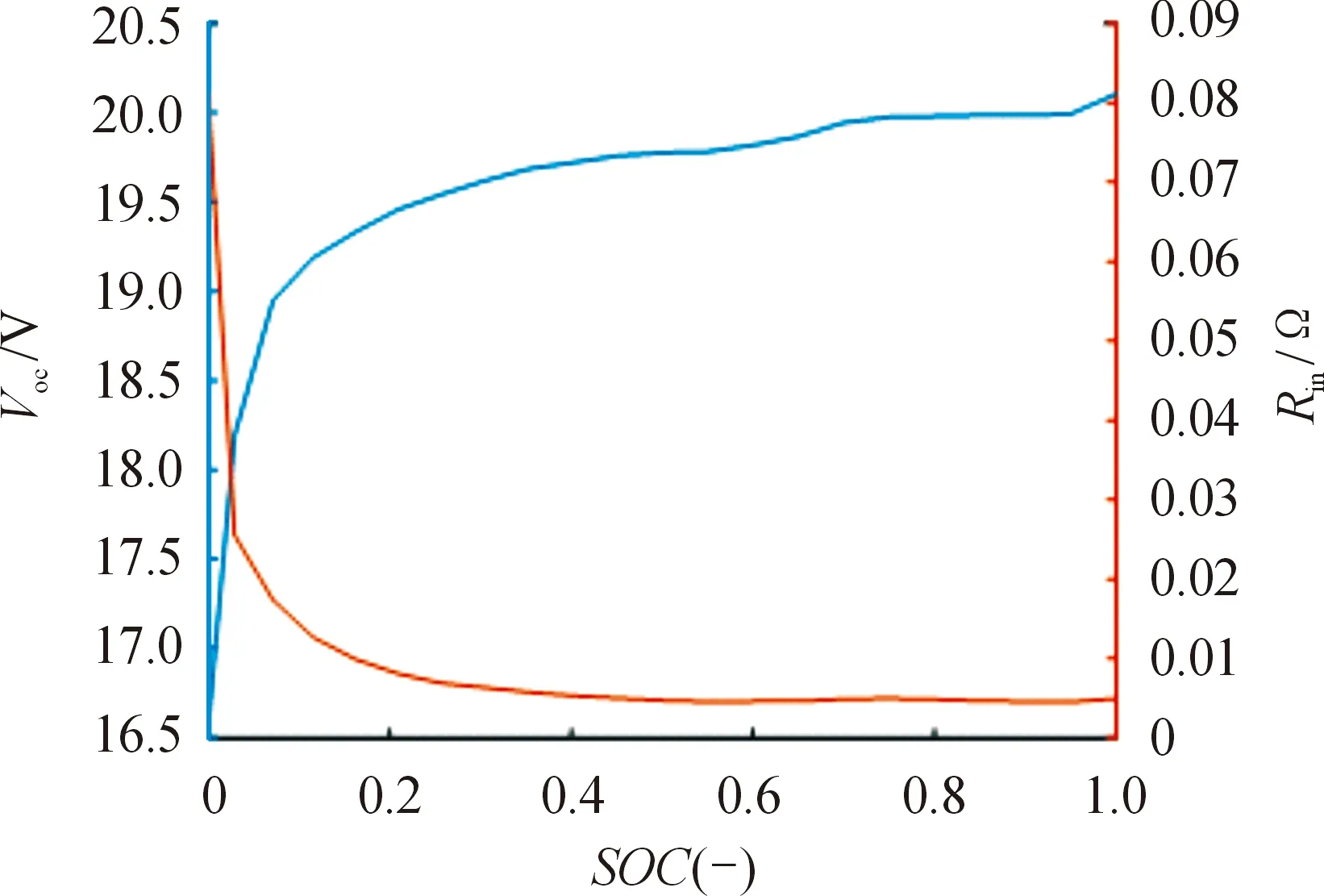
圖6 電池開路電壓與等效內阻
根據圖5中的模型和圖6中的Voc和Rin的數據,使用安時法即可求得ΔSOC[11]:
(1)
式中:Qbattery為電池電量,即電池額定容量,Ah;Pbattery為電池輸入的電功率,W,根據車輛驅動功率算得,計算過程的解釋參見文獻[11]。Pbattery正為放電,負為充電。
1.4 行駛路徑與歷史數據采集
本文主要研究在預定路線上行駛的車輛,如通勤交通和公共交通,故需要先規劃好實驗路徑。為方便實驗,選取了學校附近的一段約20.6 km的閉環路段,包括紅光大道(1、2、16)、渝南大道(3、4、5、6)、學府大道(7、8)、南濱路(9、10、11)、巴濱路(12、13、14、15)。具體線路如圖7所示。此行駛路徑路況相對復雜,包含非常通暢到嚴重擁堵等各種路況,可確保本實驗結論對于不同行駛工況都具有普適性。
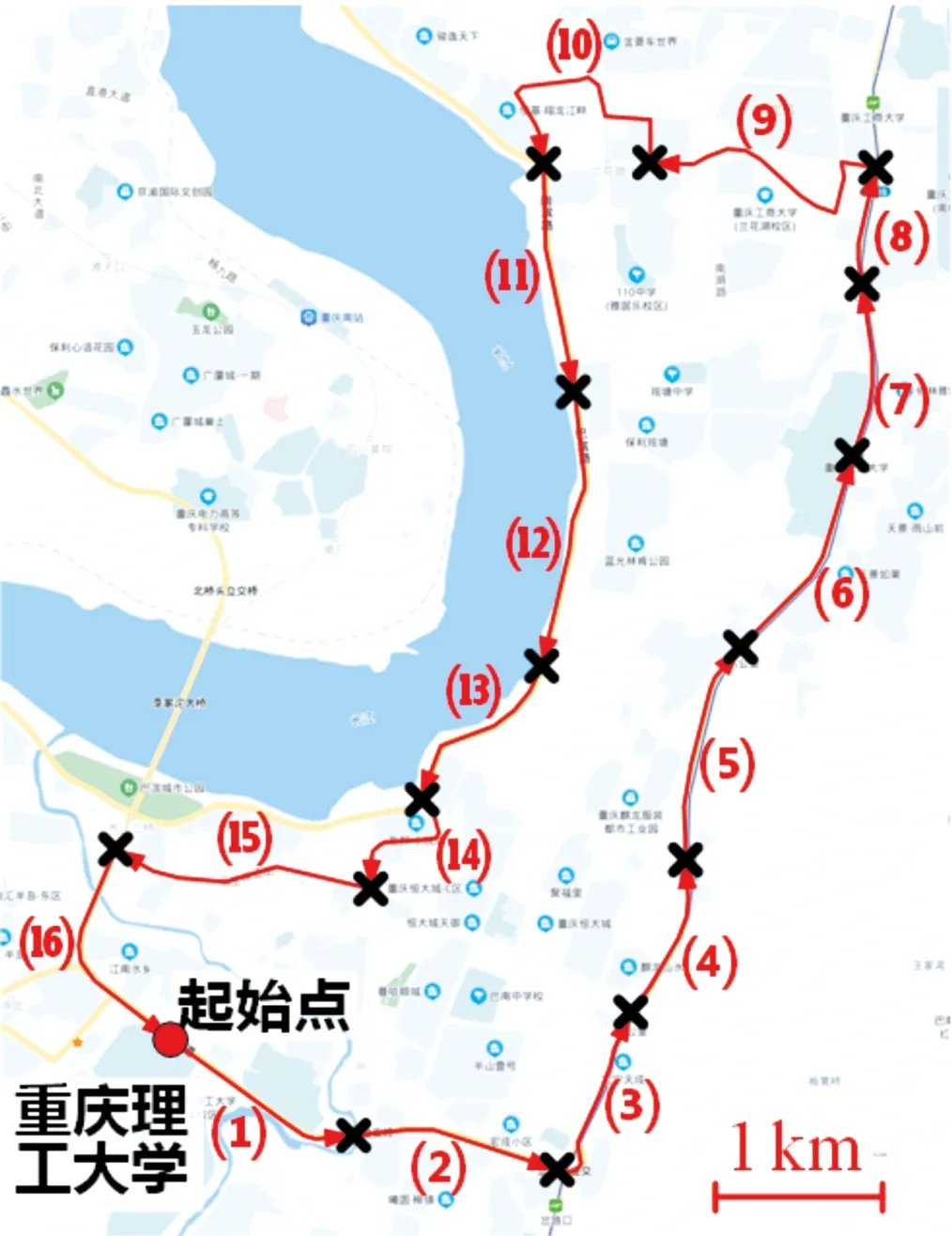
圖7 道路測試的行駛路線
通過實車行駛實驗,從行駛路線中收集若干歷史行駛數據。數據采集時間為下午17∶30左右的典型下班高峰時段。為了減少駕駛員的駕駛習慣對所記錄數據的影響,在保障安全和遵守規則的前提下,駕駛員被要求盡可能地跟隨車流行駛。為優化數據處理過程,增加數據的可靠性與穩定性,筆者根據路徑中的地理特征(如十字路口和紅綠燈),將行駛數據分割分為16個路段,即文獻[12]中的“微行程”。一組良好分割的“微行程”可以簡化數據處理,并增強其魯棒性。
實車采集的行駛數據包括車速、油門開度、整車功率和電機功率(見圖8)。為方便后續進行聚類分析,需要對歷史數據提取特征值和篩選數據。提取出的特征參數如表2所示,將作為后續聚類分析的樣本數據。
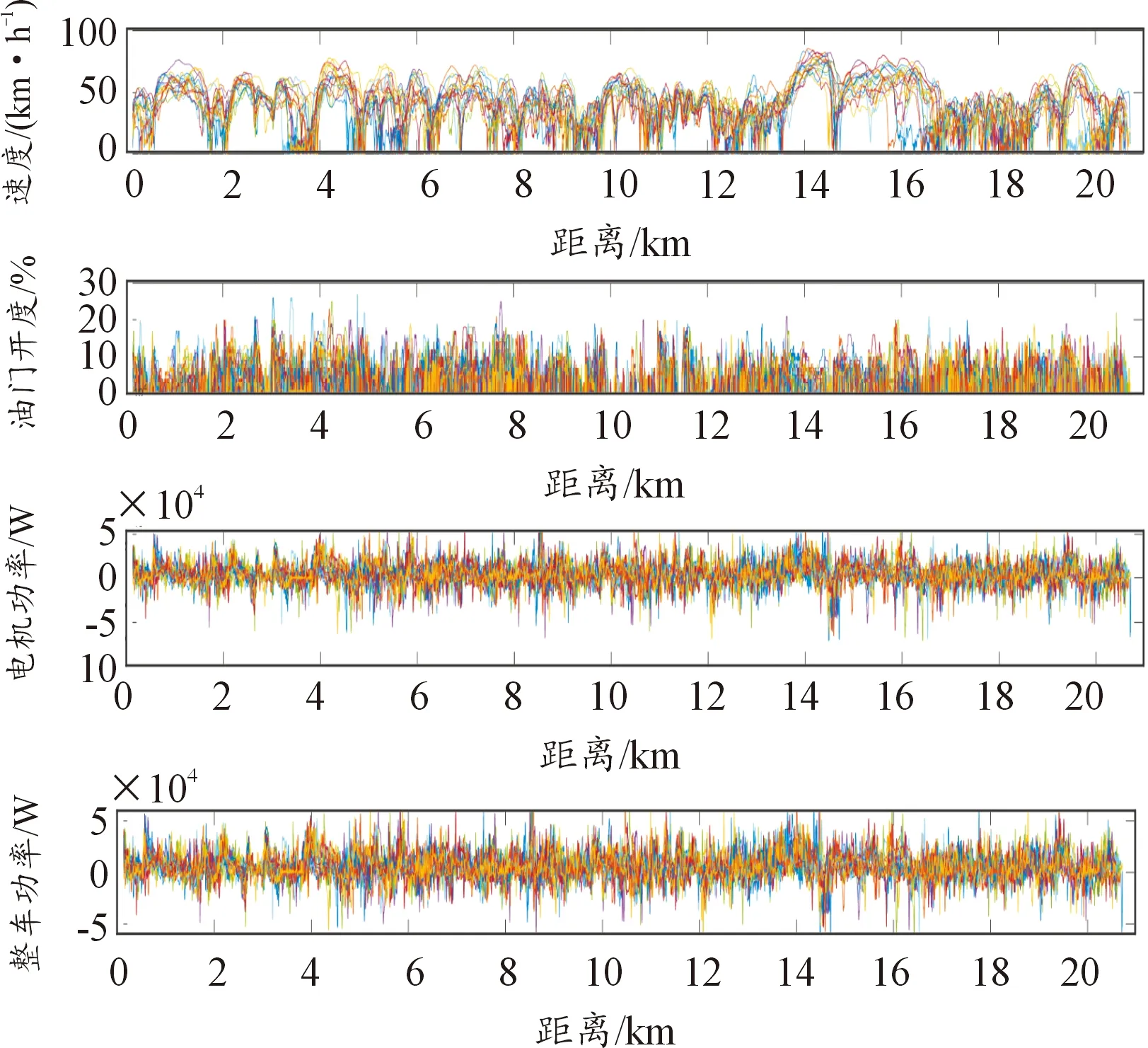
圖8 OBD單車行駛數據記錄
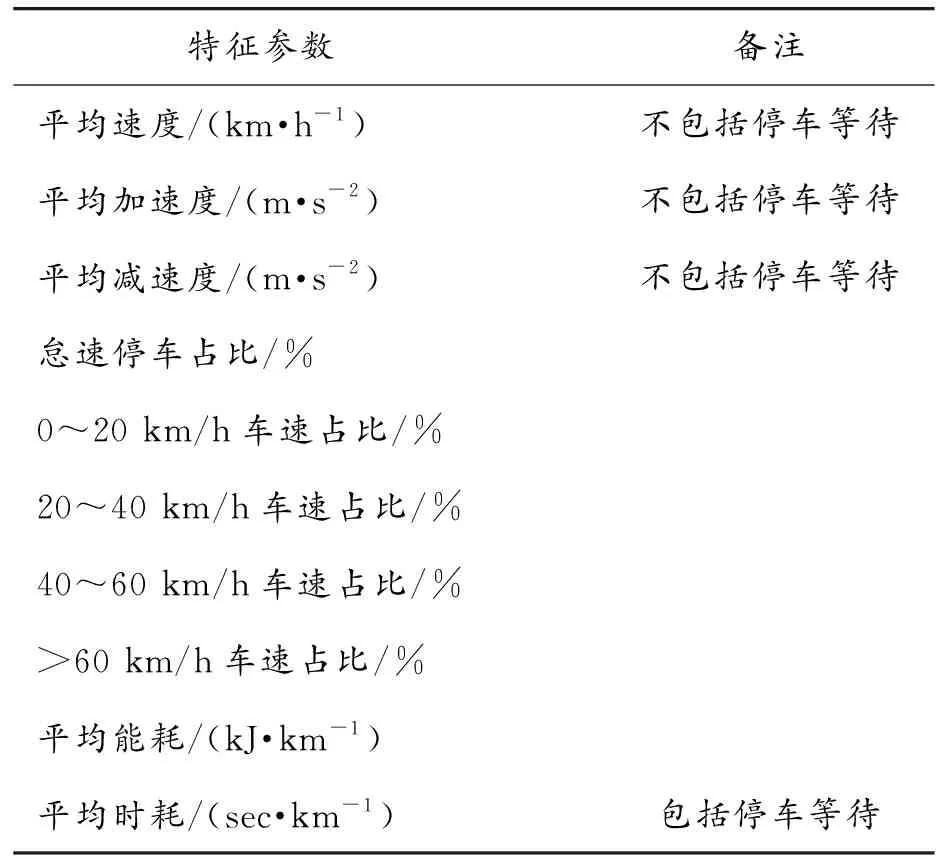
表2 來自車輛OBD接口的特征參數
1.5 百度地圖API
百度地圖Web服務API為開發者提供了http和https接口。開發者可以通過http/https形式發起檢索請求,用以獲取以json或xml格式的返回的包含相關車流信息的檢索數據。本文中車流信息數據的收集主要使用到了百度地圖API中的實時路況查詢服務(Traffic API)和批量算路服務(RouteMatrix API)。其中,前者提供了表3中的第1、2行數據,即擁堵狀況與擁堵方向;后者提供表3中第3行數據,即車流平均速度。

表3 來自百度地圖API的特征參數
實時路況查詢服務用于查詢指定道路或區域的實時擁堵情況和擁堵趨勢。擁堵狀況大致有未知、非常暢通、暢通、擁堵、嚴重擁堵等。若出現擁堵,則可用擁堵方向來判斷是否影響此次的采集數據(若同向,則影響;若反向,則無影響)。百度地圖API車流信息如圖9所示。
圖9 百度地圖API車流信息
批量算路服務可以根據起點和終點坐標計算路段行駛距離并預測行駛時間。表3中的車流平均速度由路段行駛距離除以批量算路服務提供的預測行駛時間得到。車流平均速度代表車流通過某路段的平均速度,并且包括了停車等待時間。而實車OBD的特征參數數據中的平均速度則不包括停車等待時間。因此車流速度會略慢于實車OBD中的平均速度。利用這些數據,可以獲取相關道路的車流信息,包括擁堵相關情況與車流平均速度情況。
本章介紹了云端服務器與實車在環實驗平臺的搭建過程,以及從規劃的行駛路徑中采集的實車OBD單車數據和從百度地圖API中獲取的車流信息。這兩者一并作為歷史數據,經預處理后上傳至云端服務器。將用其訓練后續章節中介紹的機器學習預測算法,以此達到預測未來行駛工況的目的。
2 預測算法
2.1 EM聚類分析
本文基于百度地圖API車流數據與實車OBD行駛數據,應用EM算法[13]對其進行聚類分析。根據表2和表3數據中具有代表性的特征參數,EM算法將其微行程數據通過聚類分析分成8種行駛工況,以此來反映汽車的行駛周期行為。EM算法類似于K-means算法[14],都是通過對迭代過程的模型進行優化來尋找最優的聚類方式,但K-means使用歐幾里得距離來測量2個數據樣本之間的距離,而EM則采用統計方法。有2種方法可以從EM算法中得到K-means算法:其一是將聚類方差取極限值為零;其二是假設方差足夠小,相比簇與簇之間的距離可以忽略不計。而本研究使用的EM算法具體如下。
首先,在n維樣本空間χ里,假定x=(x1,x2,…,xn)為隨機向量,表示表2和表3中百度地圖API與車輛OBD數據的特征參數向量。若x服從高斯分布,則其概率密度函數為
(2)
式中:μ是n維均值向量;Σ是n×n協方差矩陣。
其次,如果EM將樣本數據通過聚類分析分成k組,即C={C1,C2,…,Ck},則可以定義一個高斯混合分布
(3)
然后,如果樣本集合D={x1,x2,…,xm}表示圖8和圖9中的歷史樣本數據,那么后驗概率定義xj∈cj定義為
(4)
最后,本文采用的EM聚類分析算法具體描述如下。
1) 初始化:輸入混合高斯分布的模型參數{(αi,μi,Σi)|1≤i≤k}
2) E步,根據式(3)計算每個混合高斯分布的后驗概率,即
γji=pM(zj=i|xj)=1≤i≤k)
(5)
3) M步,計算混合高斯分布的新參數如下
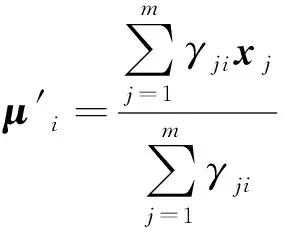
(6)
新協方差矩陣
(7)

(8)
4) 更新模型參數,重復2)3)直至聚類結果收斂。
5) 輸出:各樣本xj通過聚類分析歸入相應的簇
(9)
算法中選擇的聚類類型Cλj是按照最大后驗概率γji來選擇的。
基于以上特征參數,以路況的擁堵情況和能耗的高低為參照,將圖8和圖9中的歷史駕駛數據最后聚成8類,設定k=8時,代表性最為典型,其聚類分析結果如圖10所示。聚類完成后,從中選取2個最具有代表性的特征參數,平均能耗和平均時耗來描述聚類分析的結果,如圖11、圖12和表4所示。
聚類分析所得的結果,是具有子工況標簽的樣本的特征參數,將用來訓練后續的RBF神經網絡分類器。
圖10 子工況類型聚類分析結果
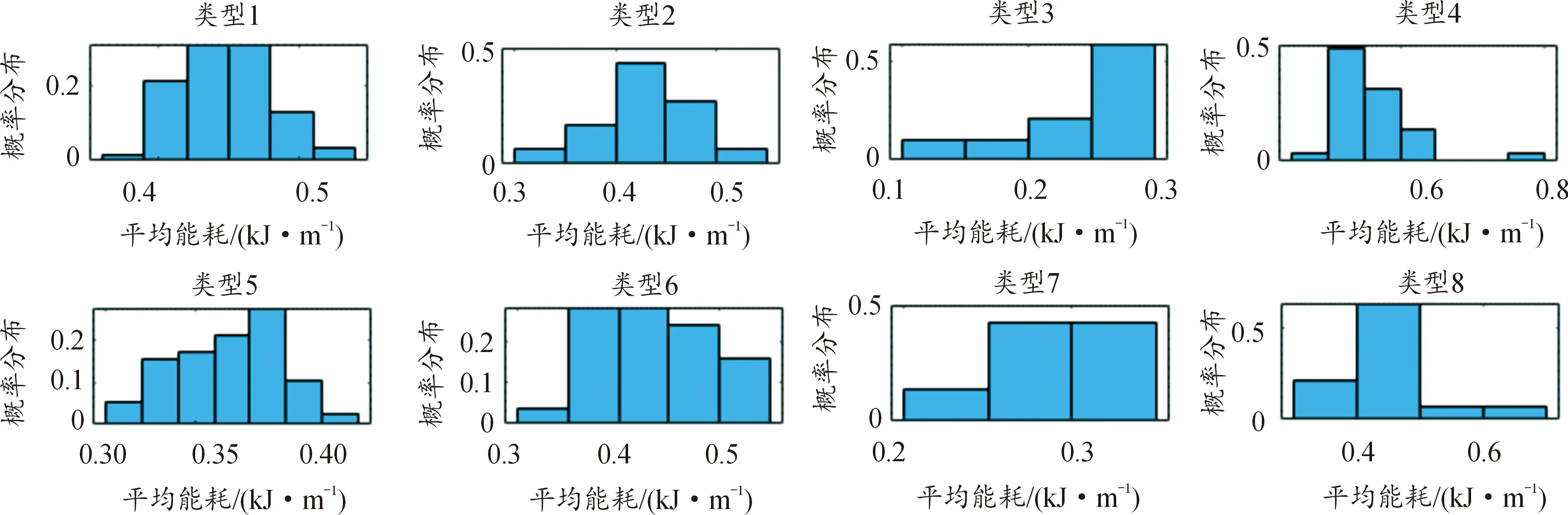
圖11 子工況能耗概率分布直方圖
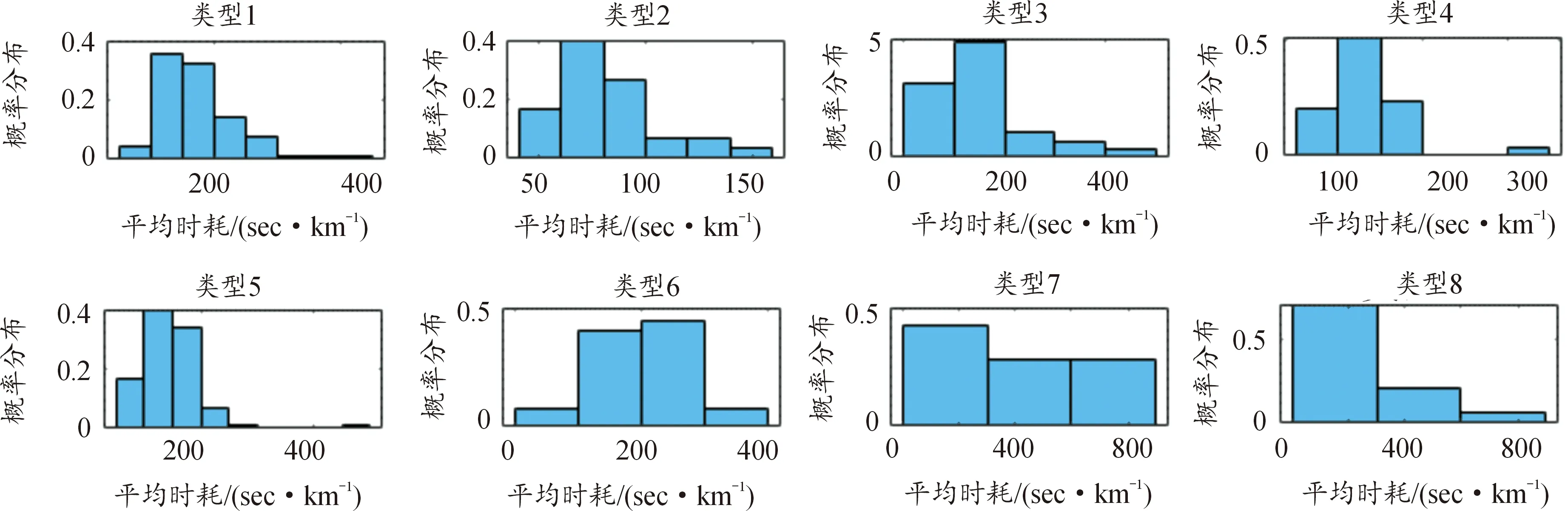
圖12 子工況時耗概率分布直方圖
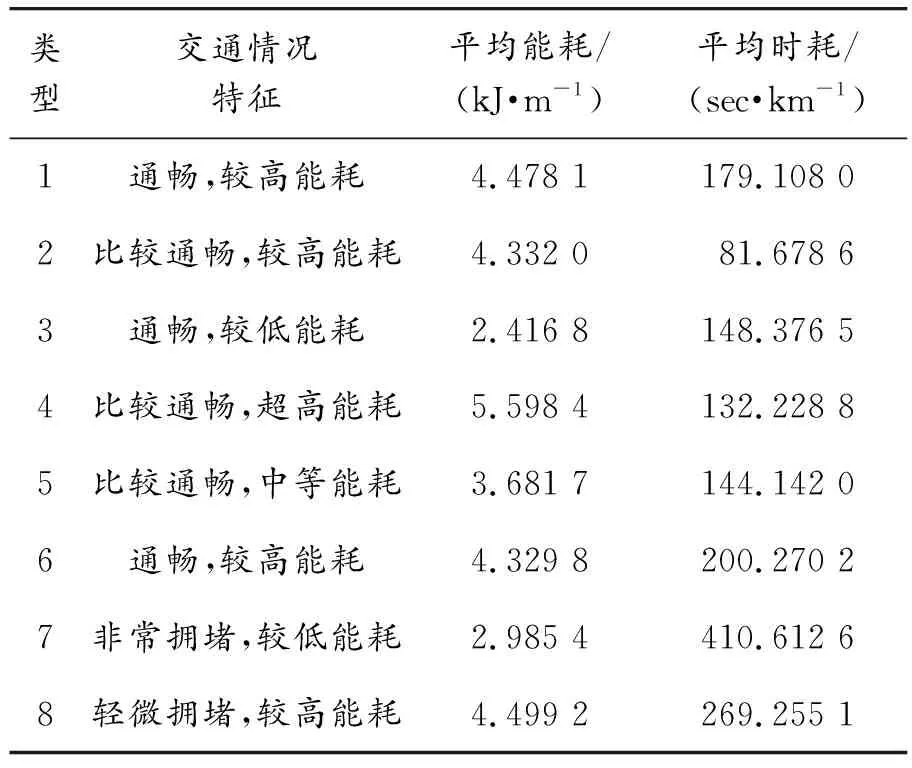
表4 交通情況特征的匹配
2.2 基于RBF神經網絡的數據分類器
在2.1節中,EM算法將歷史駕駛數據分為8個子類型。本節使用聚類后的各個樣本數據中的百度地圖API中的特征參數(即交通狀況、車流方向、車流速度),及其對應的子工況類型來訓練RBF神經網絡[15]。完成訓練后,RBF網絡可以使用百度地圖的車流信息在線對各路段的未來行駛狀況進行分類,其分類結果可作為預測的未來行駛狀態。
圖13表示的RBF神經網絡是一個3層結構的局部逼近網絡。神經元作為分布點的輸入層由表3中微行程數據的特征參數表示。隱藏層使用類高斯徑向基函數(Rj(x))作為激活函數:
(10)
式中:x=(x1,x2,…,xN)是表3中的特征參數的輸入層的輸入向量,表示百度地圖API的特征參數向量;Cj是隱藏層中第j個RBF神經單元的中心向量;σj是這個單位的半徑。而輸出層使用隱藏層結果的加權和作為子條件i的輸出信號。
(11)
式中:ωij是隱藏層中第j個單元與輸出層中第i個輸出之間的鏈接權重;ωi是第i個輸出的位移。 最后將輸入數據x分類為子條件ε,得到最高的輸出yi如下:
(12)
式中,ε是最高輸出的簇標簽,代表車輛的交通情況特征。
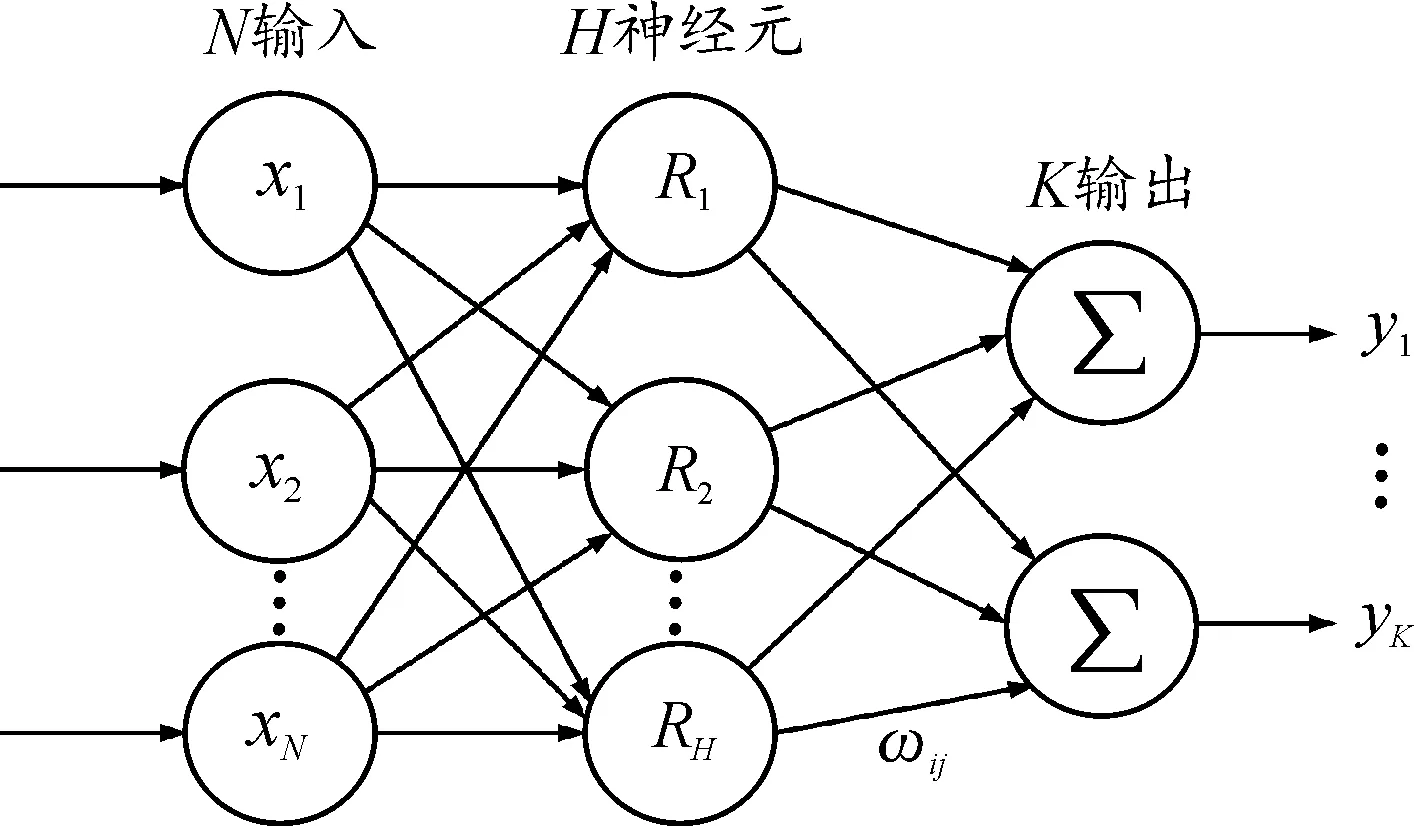
圖13 N輸入、H隱神經元、K輸出的RBF網絡
本節介紹了RBF網絡分類器的使用過程。車輛在行駛前,通過百度地圖API獲取實時車流信息,即表3中的交通狀況與車流方向和速度。完成訓練的RBF網絡根據實時車流信息,對各路段的行駛狀態進行分類預測,進而獲得未來行駛工況。根據RBF網絡給出的分類結果(即未來行駛工況的類型),同時參考圖11和圖12中能耗與時耗的數學期望,以及表4中交通情況特征的描述,即可預測得到車輛未來行駛工況的子類型及其平均能耗與時耗。
3 實車上路實驗
3.1 實驗條件與背景
通過實車上路試驗,以驗證本文提出的在線預測算法的準確性。為保證實驗的可靠性,所采取的實驗路線與采集歷史數據時的路線保持一致,如圖7所示。測試車輛于下午17∶35出發,為下班高峰期。行駛路線中的渝南大道(3、4、5、6)通常會出現嚴重堵車,而南濱路與巴濱路(9、10、11、12、13、14、15)的路況則相對通暢。實驗包含多種類型的工況數據(如擁堵工況與通暢工況),此布置能滿足實驗對數據多樣性的需求。本實驗路段全長20.6 km,行駛時間大約50 min,因此SOC設置為0.7,保證電量的充足以滿足行駛需求。實驗條件總結如表5所示。
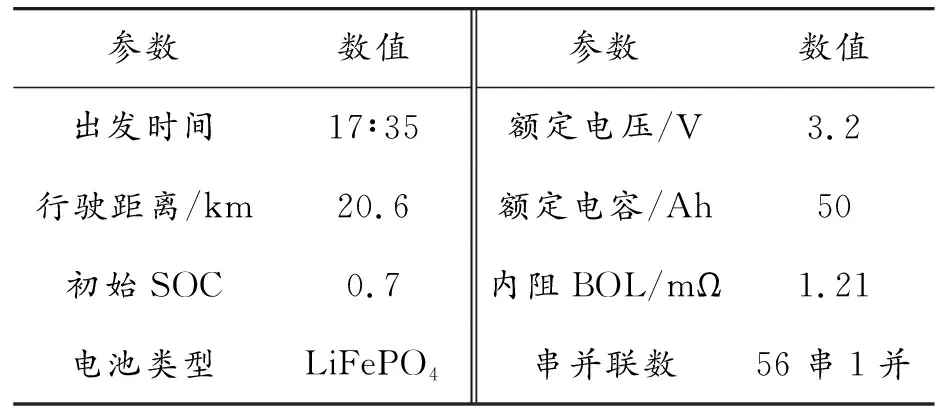
表5 實驗條件參數
3.2 實驗結果分析
圖14為實車路試實驗的結果數據,包括通過云端服務器記錄的實車數據和對應的預測數據。因為本實驗使用的是純電動汽車,其SOC變化量直接對應著整車能耗水平,所以本文用SOC變化趨勢表征整車能耗,包括實際值與預測值。在時域中(圖14(b)),SOC實際值(即整車能耗)呈非線性,且波動較大,導致預測困難。而在空間域中(圖14(a)),SOC實際值相對更為線性,故預測更為容易且準確。這說明本文選擇在空間域進行預測,即1.4節將行駛數據按空間域劃分為16段,是合理的,且可以簡化預測的難度。
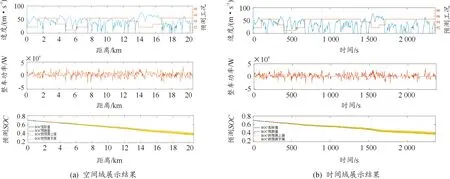
圖14 實車上路結果
圖14(a)的第1類型包含多種擁堵與通暢工況,說明本文的實驗設置能夠滿足數據多樣性的要求。圖14(a)的第2行子圖為實時的整車功率。
圖14(a)的第3行子圖是對車輛SOC的估計值,其SOC預測值、SOC的預測上限和下限由3σ準則所確定。具體而言,圖15表示某一預測工況下的平均能耗概率分布直方圖,近似符合正態分布,圖中間的紅線為平均能耗期望μ。根據平均能耗μ可計算出的SOC的變化趨勢對應于圖14(a)、(b)第3行中的橙色實線。圖15左右的2條紅色虛線則為期望減或者加一個單位的標準差,即(μ-σ)或者(μ+σ),對應圖14(a)中的綠色虛線和紫色虛線,表示預估能耗的上/下限,即預測SOC的下/上限。根據3σ準則,2條虛線之間的直方柱面積占總體直方圖面積的68.27%,即實驗中的平均能耗分布在此區間(μ-σ,μ+σ)的概率為0.682 7,當實驗偏差超過此區間時,認為數據預測不合格。在圖14中,代表實際SOC的藍色實線始終位于代表預測值上/下限的紫色虛線與綠色虛線所形成的黃帶中,并且與橙色實線(預測SOC的數學期望)非常接近,這說明此預測結果較為準確。
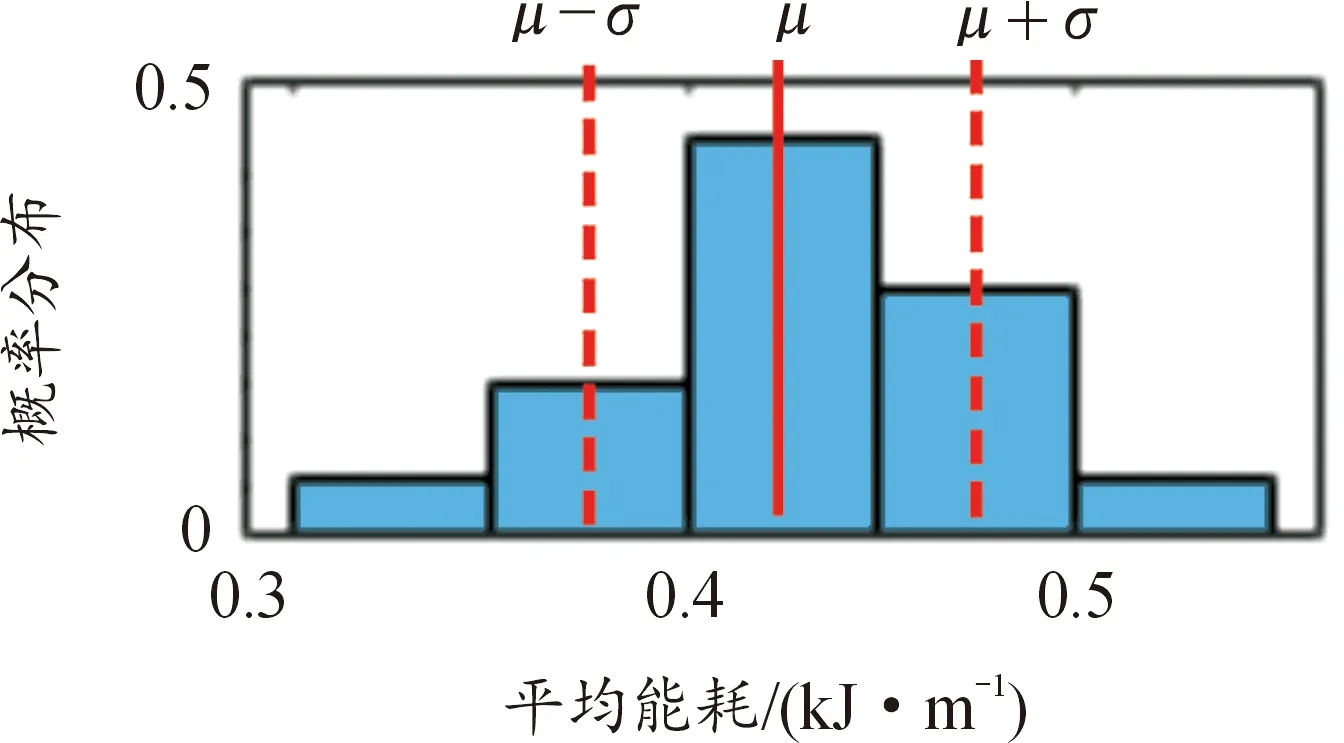
圖15 平均能耗概率分布直方圖示例
表6列出了SOC預測值(數學期望)與SOC實際值的平均誤差,其中誤差最大值僅為0.63%,這說明預測具有較高的準確率。
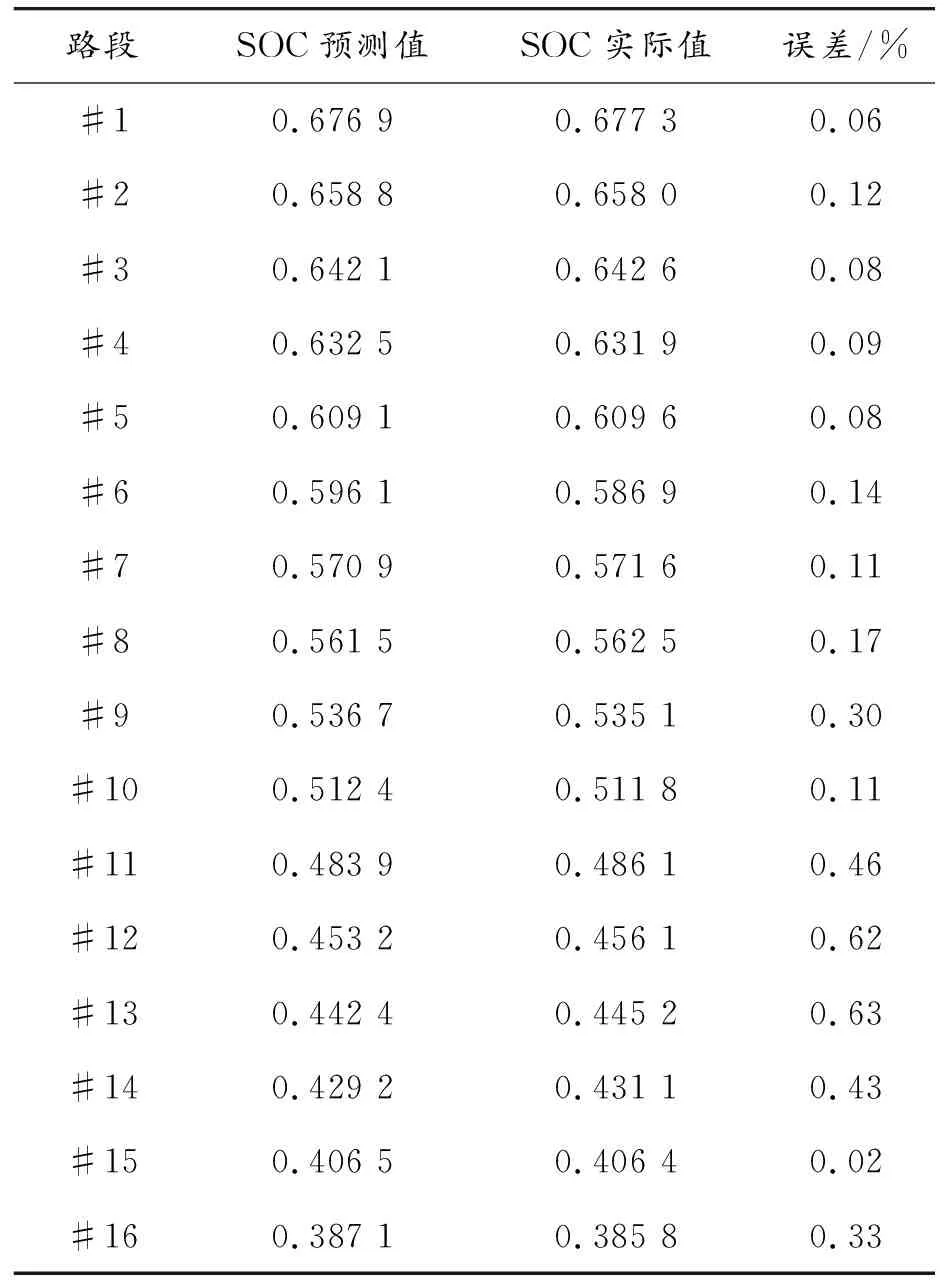
表6 預測值與實際值的誤差百分比
4 結論
為更準確地預測電動汽車的未來行駛工況,搭建了實車在環實驗平臺并利用百度地圖API智能交通系統以獲取實時車流信息。將所采集的歷史行車數據OBD與API實時車流信息相結合,并使用EM聚類分析的結果來訓練RBF神經網絡分類器。而完成訓練的RBF神經網絡可以利用百度API獲取的實時車流信息對車輛進行平均能耗及行駛工況的預測。實車在環實驗證明了預測算法的準確性較高,可滿足預測需求。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
