多流殘差網絡結合改進SVM模型的面部表情識別
2023-12-12 03:01:32郝秉華
重慶理工大學學報(自然科學) 2023年11期
郝秉華,吳 華
(內蒙古財經大學 計算機信息管理學院, 呼和浩特 100010)
0 引言
隨著科技迅速發展,基于人工智能(artificial intelligence,AI)技術的目標識別算法不斷更新,其中,面部表情識別技術作為人機交互的重要組成部分,已被廣泛應用到生物識別、臨床檢測、課堂檢測等領域[1]。但面部表情比正常的目標識別更復雜,需要更細粒度的特征學習能力來保證識別精度,導致現存的AI識別算法難以取得預期效果。因此,實現基于AI算法的面部表情穩定識別仍是一個充滿挑戰的任務。
目前,面部表情識別算法主要分為基于傳統的識別方法和基于AI技術的深度學習算法。傳統方法包括特征提取及特征分類兩方面[2],主流算法有主成分分析(principal component analysis,PCA)、局部二值(local binary pattern,LBP)特征、光流法、幾何法等。例如,錢勇生等[3]提出結合LGRP(local gabor rank pattern,LGRP)與多特征融合方法識別面部表情,該方法首先提取輸入圖像的Gabor多方向與多尺度特征,然后引入Otsu閾值及Hear小波分割法進一步提取表情特征,最后進行分類并輸出結果;Bougourzi等[4]提出基于融合變換深淺特征的面部表情識別算法,通過將PCA變換后的深層與手工特征結合,實現對靜態圖像中6個基本面部表情的識別;胡敏等[5]提出一種基于幾何和紋理特征的表情層級分類方法,利用表情特征自身分布規律對其進行識別判定。雖然傳統方法可識別基本的面部表情,但大多忽略了對圖像的預處理操作,導致識別錯誤率較高且耗時長[6]。
隨著人工智能技術的不斷更新,大量學者提出基于深度學習的面部表情識別算法,主要流程包括圖像預處理、特征提取及表情結果分類等階段。Rajan等[7]提出基于最大增強卷積神經網絡(convolutional neural network,CNN)和長短記憶網絡(long short-term memory,LSTM)的人臉表情識別網絡,首先對輸入圖像進行預處理,消除照明差異、保留細微特征,后使用卷積神經網絡提取特征,最后將特征圖與LSTM層結合并輸出結果。楊鼎康等[8]提出集成網絡模型,使用多種網絡獲得不同語義的特征并將其融合,提高模型學習能力,同時使用對抗網絡生成特定表情圖像,以平衡數據分布。宋玉琴等[9]提出嵌入注意力機制和多尺度的表情識別算法,通過疊加不同尺寸的卷積提取多尺度特征,利用空間通道注意力機制提高特征表達能力,有效提升識別算法的準確率。雖然上述研究方法大多都能夠提取表情特征,但針對表情細微特征的區分能力仍然較差,導致對相似表情特征之間的識別精度不穩定。
針對上述問題,本文中提出一種多流交互殘差結合改進SVM模型的面部表情識別算法。首先,為防止輸入圖像信息缺失導致算法識別率低,提出一種自適應多流信息增強模塊(adaptive multi-stream information enhancement module,AM-SIEM)預處理輸入圖像,并增強面部表情特征,降低網絡參數;其次,在特征提取階段提出殘差交互融合模塊(residual interactive fusion module,RIFM),進一步從多流信息中提取面部表情特征,突出關鍵識別信息;最后,使用改進支持向量機方法來分類面部表情,進一步提高算法的準確度及魯棒性。
1 理論基礎
1.1 殘差網絡
深度學習網絡的特征提取能力與精度會隨著網絡加深而提高,然而當層級達到一定程度時,訓練與測試精度會迅速下滑,導致網絡性能下降[10]。為此,He等[11]提出一種殘差網絡ResNets(residual networks),將殘差連接應用于深度網絡時,可良好地改善訓練過程中因梯度消失而導致的網絡性能下降問題。如圖1所示,將輸入直接添加到輸出中,使高層專注于殘差部分學習,避免低層特征丟失導致模型退化。輸出如式(1)所示。
Y=F(X)+X
(1)
式中:X、Y分別為輸入、輸出;F(·)為網絡內部處理結果。
1.2 支持向量機模型
支持向量機(SVM)是一種用于分類和回歸的模型,其主要原理為求解如式(2)所示的凸二次規劃問題[12]。
(2)
式中:αi與αj分別為第i和j個樣本的拉格朗日因子;C為懲罰參數;x、y為樣本與類別的向量值;K(xi,xj)為核函數。由式(2)得到最優解α*,再進一步由式(3)得到位移項b*。
(3)
最終,對于采用高斯核函數的支持向量機分類決策函數如式(4)所示,其中x代表新的觀測數據。
(4)
2 本文算法
2.1 整體框架
本文中設計了一種結合深度學習與SVM的面部表情識別算法,結構如圖2所示。相比傳統算法,本文方法利用深度學習技術進行特征提取,在泛化能力和魯棒性等方面有著傳統方法不具備的優勢。相比普通的深度學習算法,本文使用SVM進行表情分類,模型可解釋性強,便于調整參數,且SVM具有較少的超參數,模型更加穩定,不容易過擬合。
當圖像輸入到網絡時,首先經過自適應多流信息增強模塊,增強面部表情圖像的多流空間信息,并提升特征關聯程度;然后將處理后的特征圖傳輸到殘差交互融合模塊,進一步對其進行交互提取,突出面部關鍵特征;最后使用改進的支持向量機進行分類。下面將詳細介紹各模塊。

圖2 本文網絡框架
2.2 自適應多流信息增強模塊
為確保信息完整的同時增強輸入圖像的特征,提出自適應多流信息增強模塊(adaptive multi-stream information enhancement module,AM-SIEM),該模塊由多流信息收集模塊(multi-stream information collection module,M-SICM)和權重注意模塊(weighted attention module,WAM)組成,結構如圖3所示。

圖3 自適應多流信息增強模塊
圖3(a)為多流信息收集模塊,該模塊包括3條分支,每條分支主要由批量歸一化層(batch normalization,BN)、卷積核(Conv)、激活函數(ReLU)組成。BN層主要用于將輸入圖像的特征值調整到相近范圍,防止因特征值差距過大導致梯度消失,提高信息表征能力[13]。經過歸一化處理后,將特征圖輸入到3條分支,即分別使用1×1、3×3、5×5大小卷積來收集不同尺度的多流空間特征信息。其中,1×1卷積單元主要收集圖像的細微特征,5×5卷積單元用于擴大感受野,3×3卷積單元則作為本文網絡的主干分支,傳輸主要信息。最后使用ReLU激活函數輸出,確保信息穩定輸出。ReLU激活函數公式如下。
(5)
由式(5)可以看出,當輸入大于零時,函數可有效維持原有輸出,當輸入小于零時,輸出為零,因此,該函數在一定程度上可抑制無效特征。為防止單一卷積導致收集信息不完整的問題,在激活函數后使用元素相乘的操作將大尺度特征結合到鄰級小尺度中,提高信息關聯程度的同時進一步擴大小尺度特征的感受野。然后使用Conv-ReLU結構降低維度,緩解學習壓力。
受自注意力網絡[14]啟發,提出的權重注意力模塊如圖3(b)所示,該模塊由L1和L22條分支組成,能夠將L1特征權重轉移到L2主干分支中。首先,為避免L2分支的主干特征權重較大而抑制其他分支權重,使用平均池化(Average pooling)來對其進行平滑處理,如式(6)所示。
(6)
式中:R為特征值的個數;vn為對應特征值。
使用與主干網絡和鄰級分支大小相等的卷積單元提高對應分支的特征維度;將ReLU和Sigmoid激活函數結合,不僅可以抑制無用信息,還可以利用Sigmoid激活函數特征轉移權重,如式(7)所示。
(7)
圖3(b)中的i、j分別代表不同分支下特征權重注意力中的卷積核大小,設置規則如下:
Algorithm1: Convolution kernel size setting rules
Input: Connect=I1,I2,I3;
Output:i,j;
If Connect==I1:
i=1,j=1;
If Connect==I2:
i=1,j=3;
If Connect==I3:
i=3,j=5;
Return:i,j
此外,當模塊連接I1時,L1分支輸入為單位矩陣。
2.3 殘差交互模塊
在面部表情圖像信息增強的基礎上,設計一種殘差交互模塊來提取面部特征,包括深度提取模塊(deep extraction module,DEM)和殘差交互機制(interactive residual mechanism),結構如圖4所示。

圖4 殘差交互模塊
圖4(a)為深度提取模塊結構,首先,該模塊使用Conv-ReLU結構對輸入特征進行初步處理,減少特征通道數量,緩解網絡學習壓力;其次,由于最大池化(Maxpooling)操作在提取圖像深度特征時會損失少量信息[15],因此,分別將3條過濾器大小為2×2、4×4、6×6的最大池化并聯來增強圖像特征,并將輸入特征與最大池化結果使用拼接層(Concat)融合,避免信息丟失;最后,使用卷積單元減小特征圖像通道,提取圖像的深度特征。該模塊最終使用SiLU激活函數輸出,相比于ReLU激活函數,SiLU對于負樣本權重的影響進行一定程度的減弱,而不是直接賦值為零,因此可以保留更多信息[16],公式為:
(8)
圖4(b)為殘差交互機制結構,該結構輸入為3條附帶面部表情的特征流,將3條特征數據流拼接成一個整體,增加特征之間的關聯性;通過卷積和激活的操作提取多條特征流之間的交互特征,計算多流特征之間的聯系;將交互特征與各個原分支的特征進行相加,重新融合并賦予對應分支特征。該機制能輸出對應分支所提取的空間尺度特征,提高后續判斷和分類的準確率。考慮到每個分支得到的特征不同,因此在第一層使用Leaky ReLU函數,避免因特征梯度過大導致神經元死亡。第二層使用Sigmoid函數作為最終輸出,防止信息丟失。
2.4 改進的支持向量機
為提高網絡對多個小樣本分類任務的準確度,選擇使用支持向量機來保證表情分類的準確性,該方法優于傳統的Softmax方法,相比決策樹更不容易過擬合。但由于傳統支持向量機分類方法大多采用“一對多”的方式,容錯率低。考慮到本文對預處理和特征提取階段的網絡設計,將其改進為“三對多取大”的方式提高分類的容錯率。改進后的算法流程如圖5所示。
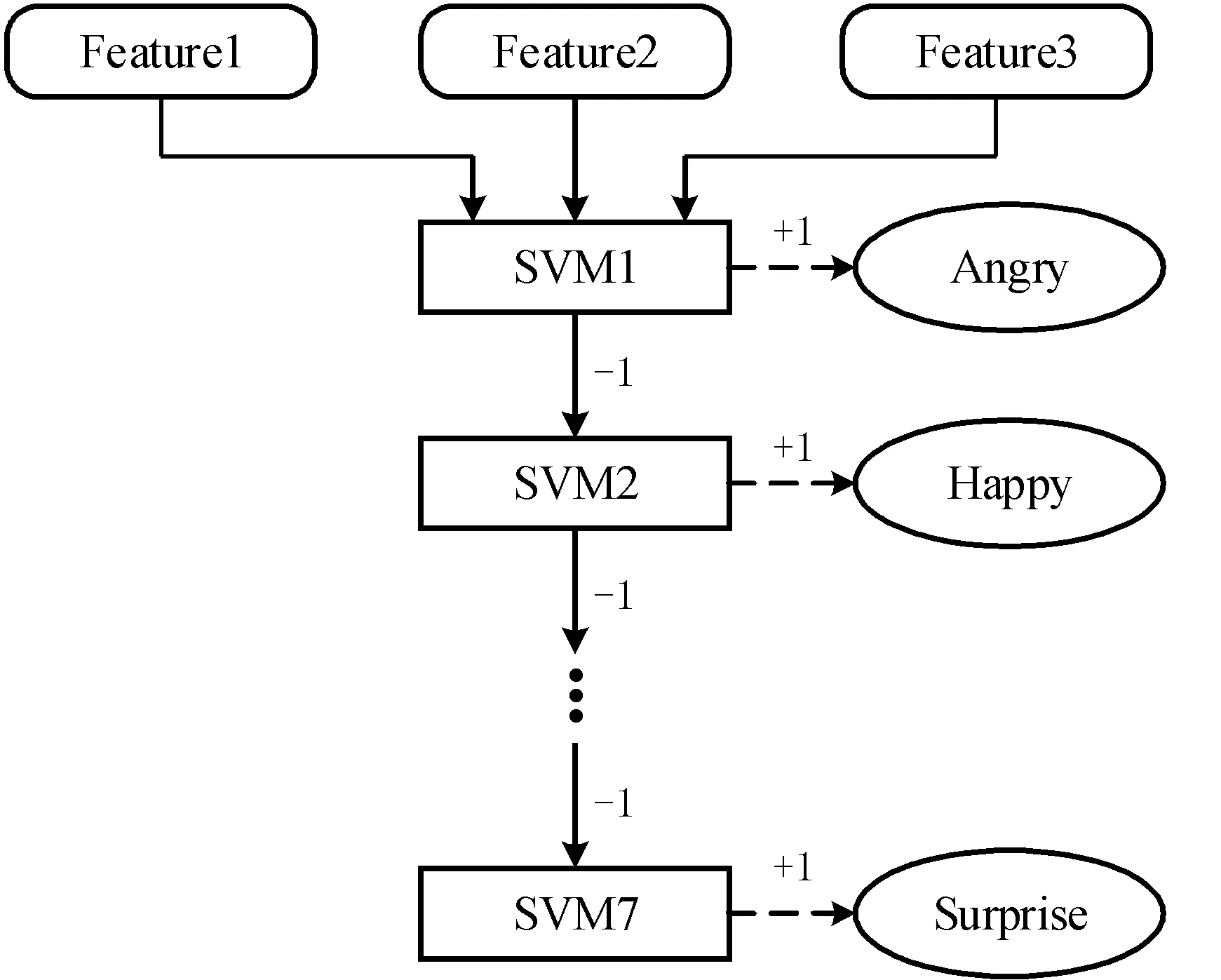
圖5 改進后的SVM算法流程
以CK+[17]數據集為例,將面部表情分為7類,并構造7個子分類器,訓練對應分類器模型。當3個特征圖輸入時,算法流程如下。
步驟1:將特征圖1、2、3依次傳入對應子分類器來判斷特征圖是否為真,若判斷為真,則對應樣本數值+1,其余樣本數值-1。
步驟2:判斷3條分支的特征圖是否全部計算完畢,如果計算完畢,則比較7個樣本數值大小,輸出最大數值對應的樣本。否則,繼續輸入特征圖進行計算。
3 實驗結果和分析
本實驗環境為:GPU為GeForce RTX 3090,CPU為Inter(R) i9-12900H,Unbuntu20.04系統,Pytorch1.10.1框架。訓練網絡時,批量大小(Batch Size)設置為8,優化器為Adam,動態學習率設置為10-6~10-3。SVM中C值取1,σ2取1。當網絡訓練到85epoch時,網絡達到最優。
3.1 實驗數據集
為證明深度SVM模型面部表情識別算法的有效性,選擇在CK+、FER2013[18]及JAFFE[19]數據集上進行實驗。其中,CK+數據集包括123名參與者在各種環境下的表情變化,表情示例如圖6(a)所示;JAFFE數據集由10位參與者在規范控制條件下獲得213張表情圖像,示例如圖6(b)所示;FER2013數據集共有35 887張圖像,選取30 000張作為訓練集,3 000張作為測試集,示例如圖6(c)所示,該數據集包括姿態、旋轉、光照等一系列挑戰,因此本文及對比算法在此數據集上的識別率總體較低。

圖6 數據集圖像示例
3.2 消融實驗
為驗證所提模塊的有效性,在JAFFE數據集中進行消融實驗,結果如圖7所示。
MSIR表示含有自適應多流信息增強模塊、殘差交互模塊及改進后的支持向量機算法的原始網絡;MSIR_AM-SIEM表示去掉自適應多流信息增強模塊的網絡;MSIR_RIM為去掉殘差交互模塊后的網絡;MSIR_SVM表示不使用支持向量機算法(使用softmax損失函數代替)后的網絡。可以看出,原始網絡在訓練76epoch后逐漸平穩,85epoch左右網絡識別率達到最高值。由于MSIR_AM-SIEM去掉了自適應多流信息增強模塊,僅通過輸入圖像來提取特征,導致其訓練時波動較大,可以證明自適應多流信息增強模塊的有效性。MSIR_RIM的準確率最低,此外,使用Softmax的MSIR_SVM準確率也比使用SVM的準確率低,進一步證明了改進后的支持向量機算法可以提高網絡的識別能力,增強魯棒性。

圖7 消融實驗曲線
3.3 數據集結果對比分析
為了證明本文方法的泛化能力,分別在CK+、FER2013、JAFFE數據集進行測試,對比算法如下:DAM-CNN[20]、VGG19[21]、ResNet50[11]、Xception算法[22]、文獻[23-28]的方法,除VGG19、ResNet50、Xception外的實驗結果均取自原論文。結果如表1所示。
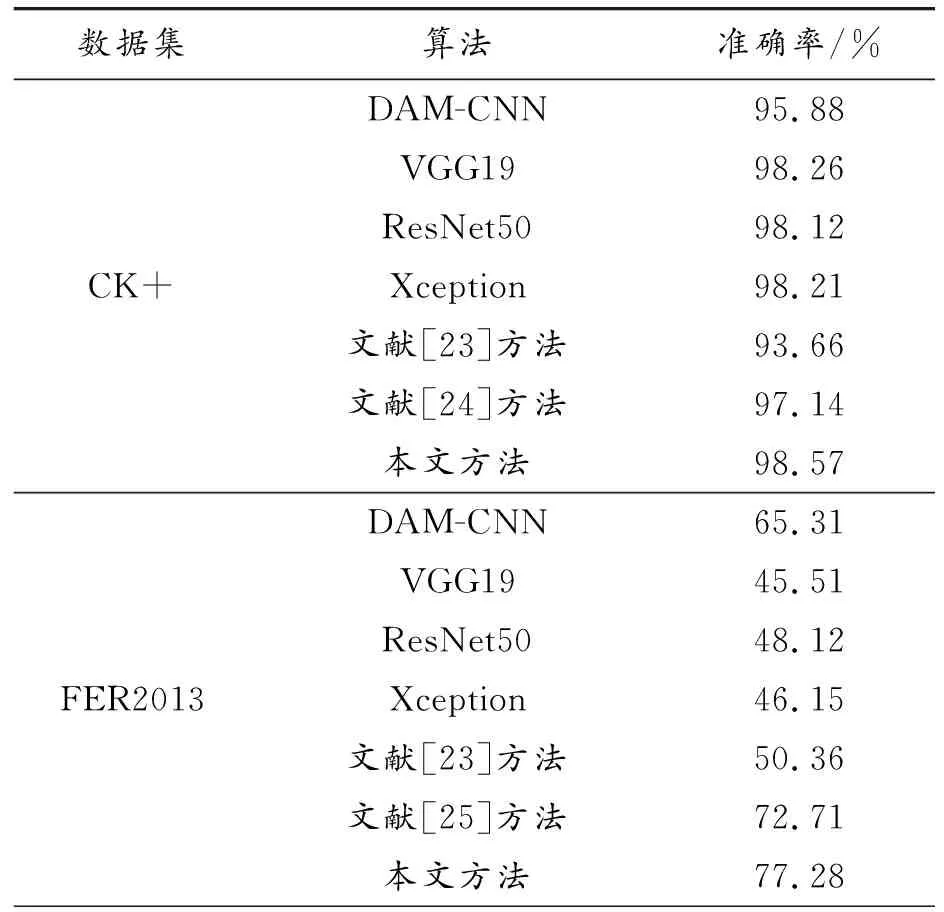
表1 標準數據集下實驗結果
由表1可以看出,在CK+數據集中,所提算法的準確率達到98.57%,比經典的DAM-CNN、結合關鍵點和金字塔卷積算法高出1.43%~2.69%,且均優于新穎的深度學習算法;在FER2013和JAFFE數據集中,本文算法的準確率分別為77.28%、96.24%,證明了所提出的自適應多流信息增強模塊可以增強面部表情信息,提高表情的辨識度。殘差交互模塊可以更好地融合面部信息,SVM能提高模型對面部表情識別的魯棒性。
3.4 表情實驗分析
為了驗證所提算法辨識表情的穩定性,在CK+數據集中挑選了100張識別難度較高的表情圖像進行測試,得到的結果如圖8所示。
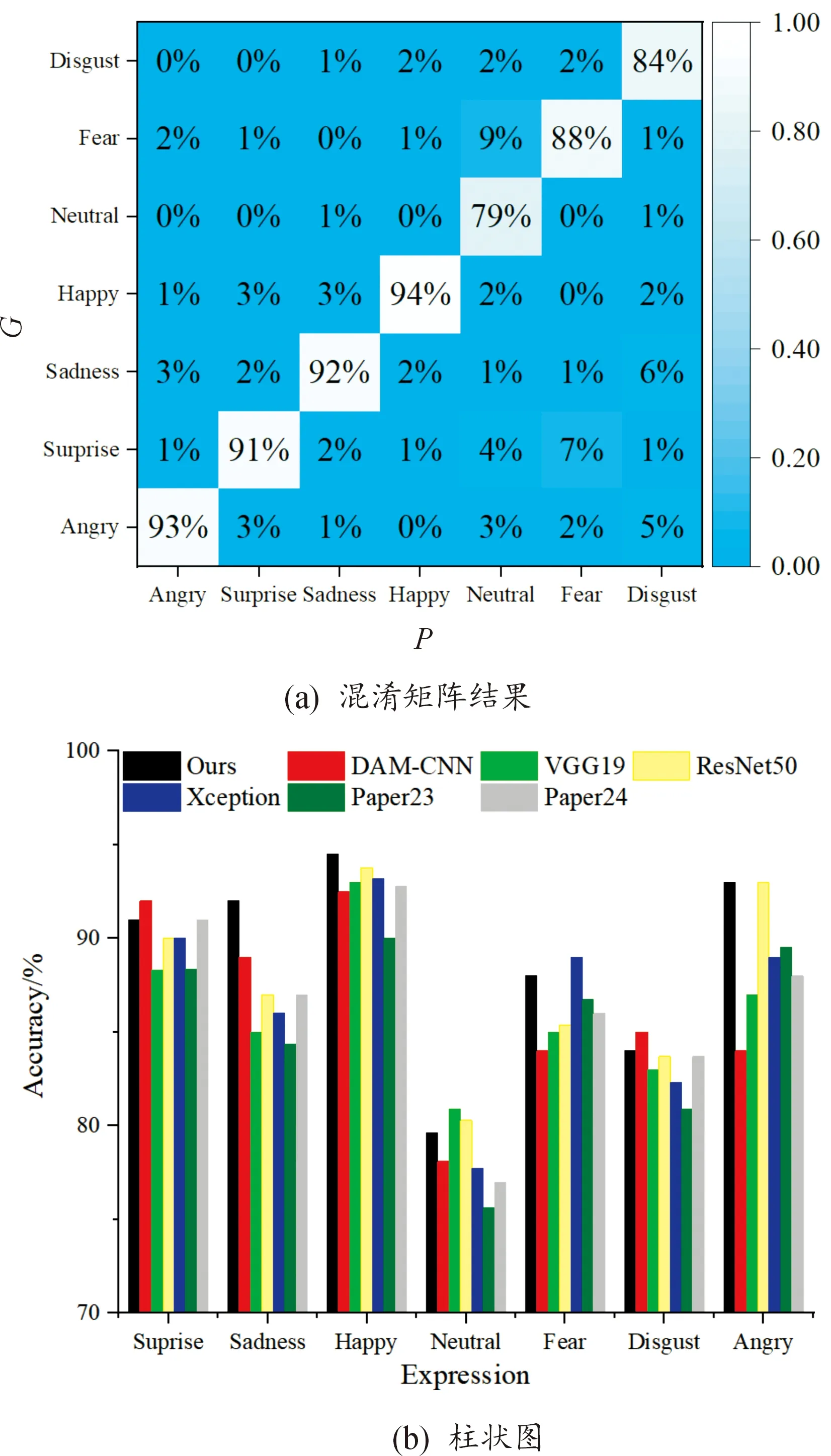
圖8 表情測試結果
圖8(a)為混淆矩陣結果,其中G為真實值,P為預測結果,可以看出,算法對“高興”表情的識別準確率最高,達到94%;對“中立”“恐懼”“厭惡”表情的識別準確率較低,分別為79%、88%、84%。為了更直觀地展示本文算法在7個表情上的判斷能力,得到的柱狀圖如圖8(b)所示,可以看出本文算法對“生氣”“驚訝”“悲傷”“高興”表情的判斷能力比較穩定,而對“中立”“厭惡”的判斷能力較弱,主要原因可能為:① 由于目前缺少公開的表情數據集,本文挑選的數據存在一定誤差,導致不同表情存在相似特征,降低了對相似表情的識別準確率;② 由于該實驗是在正常數據集訓練得到的權重來對表情進行測試的,因此對相近表情的辨識度較低;③ 每個參與者的面部特征均有差異,存在某參與者的“中立”表情相似于其他參與者的非中立表情,因此導致本文算法判斷失誤。
3.5 算法輕量化分析
為了評估本文算法對輸入表情圖像的預測速度,分別將所提網絡與VGG19、ResNet50、Xception算法在相同環境下訓練出對應預訓練模型,然后選取100張面部表情圖像進行預測,得到的平均參數量與預測時間如表2所示。
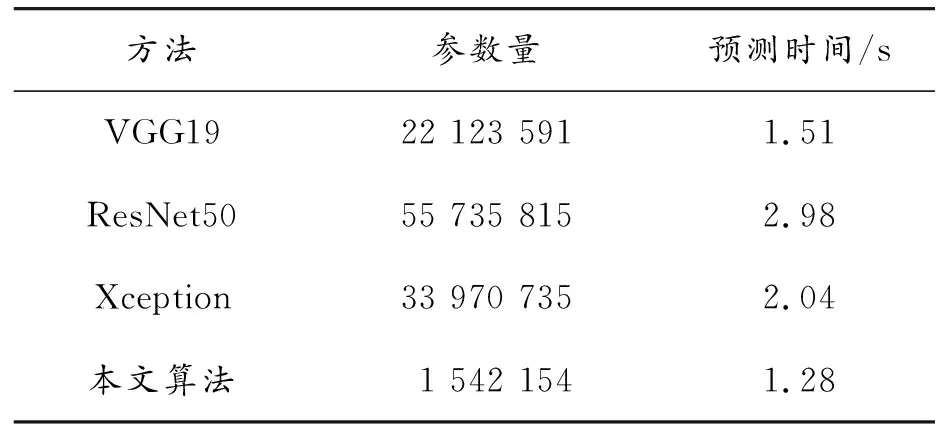
表2 平均參數量與預測時間
從表2可以看出,相較于對比算法,本文算法的參數量僅為1.5 M,這是因為表情識別屬于小樣本識別任務,對模型規模沒有嚴格要求,因此本文在深度學習模型的通道數和深度方面作了一定的縮小。除此之外,本文算法采用SVM進行分類,相比其他方法使用全連接層,SVM參數要少很多。平均預測時間為1.28 s,優于以上對比算法,計算時間主要消耗在SVM分類方面,因為SVM不適合使用GPU計算,因此消耗了一定的時間,但總體上能夠證明所提算法在保證準確率較高的前提下實現了網絡模型的輕量化任務。
4 結論
針對現存算法難以穩定識別面部表情的問題,提出一種多流交互殘差結合改進SVM模型的面部表情識別算法,提出的自適應多流信息增強模塊可以增強面部表情圖像的關鍵特征信息,提升信息間關聯程度;殘差交互模塊可以進一步突出面部表情,提高識別準確率;改進的支持向量機方法使用3條分支特征判別表情類別,提高算法的魯棒性。大量實驗結果證明,該算法在CK+、FER2013、JAFFE數據集中的測評指標均優于現存的經典及新穎算法,網絡模型在參數量及預測速度上更具優勢,具有更可觀的實用價值。然而,由于目前缺少公開的面部表情數據集,導致本文算法在表情實驗中,對“中立”“厭惡”表情的判斷能力較弱,在后續工作中將進一步提升網絡對相似表情的判斷能力。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
