基于深度卷積網絡和卷積去噪自編碼器的水聲信號識別方法
2023-12-13 11:43:46徐劍秋
網絡安全與數據管理 2023年11期
曹 琳,彭 圓,牟 林,孫 悅,徐劍秋
(水下測控技術重點實驗室,遼寧 大連 116013)
0 引言
如何在復雜的海洋環境下對水聲信號進行識別是目前亟需解決的難題。傳統的基于信號特征的水聲目標信號識別方法,特征受時/頻/空域變換算法的制約不可避免地丟失目標信息。深度學習方法能夠自動地通過逐層訓練學習到數據高級的特征表示,從而得到更豐富的特征信息。該方法集特征提取與分類于一體,完成從輸入信號到輸出分類的處理。隨著深度學習在圖像識別、語音識別等領域取得了巨大的成功,國內外學者陸續嘗試將深度學習方法應用于水聲信號識別中。一些學者將卷積神經網絡對水聲信號的時頻譜特征進行學習和識別[1],有效降低了噪聲的影響,分類精度可達98.57%,取得了很好的識別效果,李俊豪等學者根據水聲信號的特點,從水聲信號時頻特征出發設計了深度卷積網絡[2],有助于提取到具有一定物理意義的譜特征,識別率顯著提高。但由于水聲信號的獲取難度大,導致水聲數據樣本是小樣本,樣本較少模型容易產生過擬合的現象。深度自編碼網絡可以對原始數據進行有效的降維,避免模型出現過擬合。陳越超等學者基于降噪自編碼器對水聲數據進行特征提取與識別[3],結果表明,對于不同類型目標與同一目標的不同狀態,降噪自編碼器都能提取可分性特征,識別率也高于其他對比方法。薛靈芝等學者對深度自編碼網絡進行了改進,在最后一層隱藏層的輸入值中加入第一層的特征值,有效地避免了單一通道中由于連乘導致的梯度消失問題[4],結果表明,該算法能有效地對水聲信號進行特征提取和分類,并具有良好的魯棒性。但是自編碼器一般基于全連接的方式構建網絡模型,但是全連接網絡的運算量較大,對實時性要求較高的應用來說有較大的局限性。
綜上所述,本文綜合利用卷積神經網絡(CNN)和卷積去噪自編碼器(CDAE)的優勢,構建了適應水聲信號的深度卷積網絡和卷積去噪自編碼器(CDAE-CNN),將水聲信號的Lofar譜特征作為模型的輸入,進行特征提取和分類,利用更少的參數學習更豐富的特征,實現對水聲信號的分類。
1 深度神經網絡
1.1 卷積神經網絡
卷積神經網絡(CNN)是被設計用來處理多維數組數據的神經網絡[5],例如時間序列數據和圖像數據。它在圖像檢測、語音識別等領域表現優異。卷積網絡具有局部連接、權值共享、池化以及使用多個網絡層的特點[5],可以識別數據中的局部模式,利用更少的參數獲得更豐富的特征。一般卷積神經網絡結構中的基本組件都是卷積層、池化層交替使用的,其后跟著全連接層,對于分類任務而言,需要經過Softmax操作后進行最終的分類輸出。
卷積層是CNN的核心層,主要是通過卷積核提取輸入數據的特征,它是在做卷積過程中的濾波算子。卷積核大小的設置決定了卷積網絡提取樣本特征的能力的強弱,將卷積核的高(h)和寬(w)設置成w>h的矩形能夠提取圖像中與頻率相關的特征,相反,將卷積核的高和寬設置成w
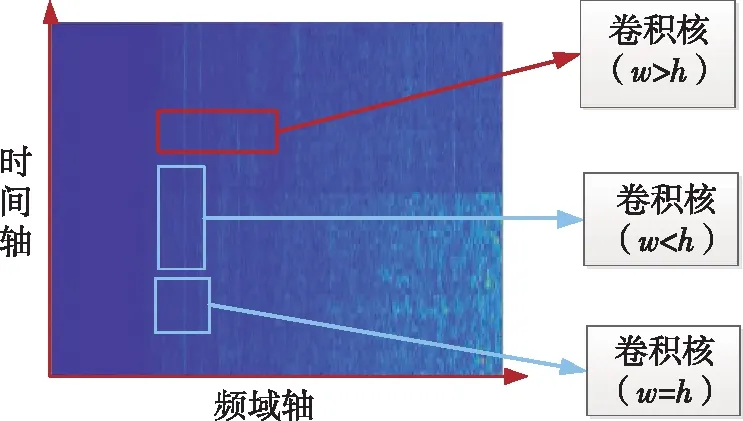
圖1 卷積核尺寸
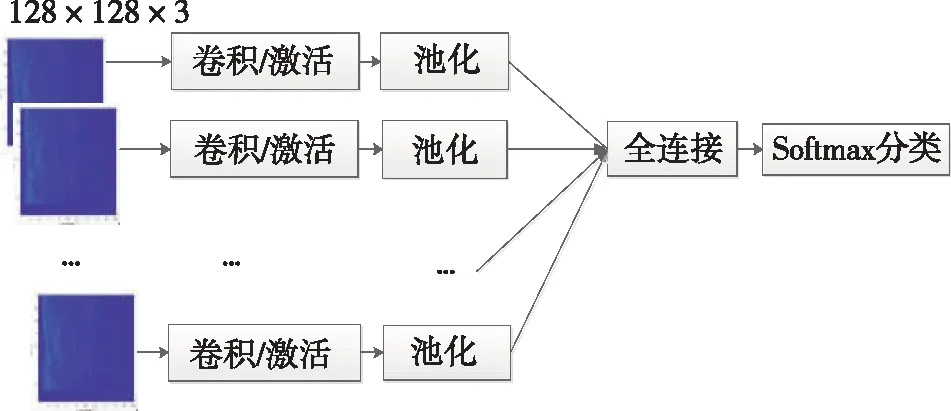
圖2 卷積神經網絡結構
1.2 卷積去噪自編碼器
自編碼器是一種經過無監督訓練后能將輸入復制到輸出的神經網絡[6]。該網絡由兩部分組成:編碼器和解碼器,編碼器可以用h=f(x)表示,式中x為輸入數據,f為編碼函數,h為x的特征表達,解碼器可以用解碼函數r=g(h)表示,式中g為解碼函數,r為輸出數據,它們之間通過隱藏空間相連接。去噪自編碼器是與自編碼器具有相同的結構[3],只是在訓練樣本中向x中加入了噪聲,得到估計值x′,訓練時學習從含噪聲的輸入中去除噪聲獲得純凈的輸入,這樣就增強了模型對信號的特征提取能力。傳統的自編碼器最小化以下目標[6]:
L(x,g(f(x)))
(1)
其中L是一個損失函數,懲罰g(f(x))與x的差異。
而去噪自編碼器最小化為[6]:
L(x,g(f(x′)))
(2)
其中x′是被某種噪聲損壞的x的副本,圖3是去噪自編碼器的模型結構圖。
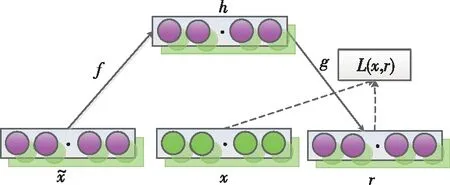
圖3 去噪自編碼器結構

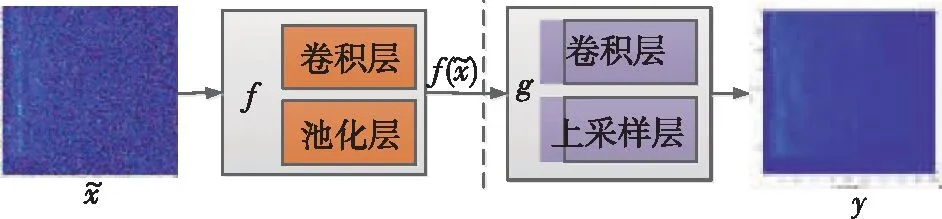
圖4 卷積去噪自編碼器結構
2 模型結構介紹
本文結合CDAE和CNN特點設計適合水聲Lofar譜的分類網絡(如圖5所示)。模型主要由三個網絡組合而成,即網絡1、網絡2和網絡3,網絡1和網絡2主要是CDAE網絡結構。其中網絡1中主要由卷積層、激活層和池化層交替4次組成編碼器。第一個卷積層采用64個卷積核,第二個卷積層采用32個卷積核,第三個卷積層采用16個卷積核,第四個卷積層采用8個卷積核,每個卷積層的卷積核大小都設置成3×3,激活層采用ReLU函數來激活,它能更好地增加模型的非線性,并簡化模型來學習水聲信號中更復雜的關系。池化層采用最大池化來對特征進行降維,同時降低卷積層對特征位置的敏感性。128×128×3的水聲Lofar譜圖經過網絡1的編碼器后輸出被壓縮成16×16×8的特征,壓縮后的特征雖然保留了水聲信號中最重要的信息,但是大部分的細節信息都丟失了,這時需要解碼器來獲取更多水聲信號的細節信息。網絡2為模型結構種的解碼器,主要由上采樣層、卷積層和激活層交替3次組成,其中每個上采樣層的窗口大小被設置成2×2。第一個卷積層采用8個卷積核,第二個卷積層采用16個卷積核,第三個卷積層采用3個卷積核,用于恢復水聲Lofar譜圖原RGB通道數,每個卷積核的大小都設置為3×3。在訓練前,對水聲Lofar譜數據集添加噪聲系數為0.15的隨機噪聲,這樣就能保證構建的CDAE提取出水聲Lofar譜圖的穩定特征。此外,為了適應水聲信號自身的特點,本文將CNN的結構進行了改進,設計了網絡3用于對水聲Lofar譜圖進行分類(如表1所示),該網絡卷積層的卷積核設置成了w>h大小,提取水聲Lofar譜圖中穩定的特征信息。由于本文使用的數據集樣本量較小,為了防止網絡模型在訓練過程中出現過擬合,本文在全連接層的后面加入了Dropout層,以簡化網絡模型的結構。
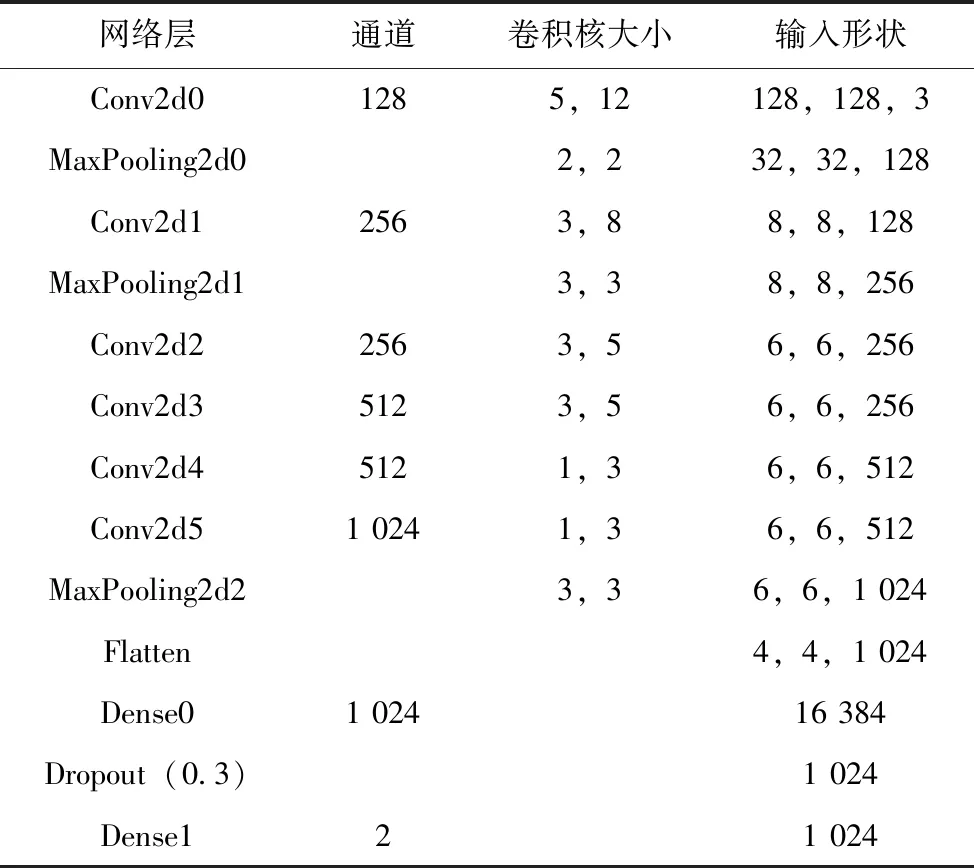
表1 網絡3的CNN網絡模型結構
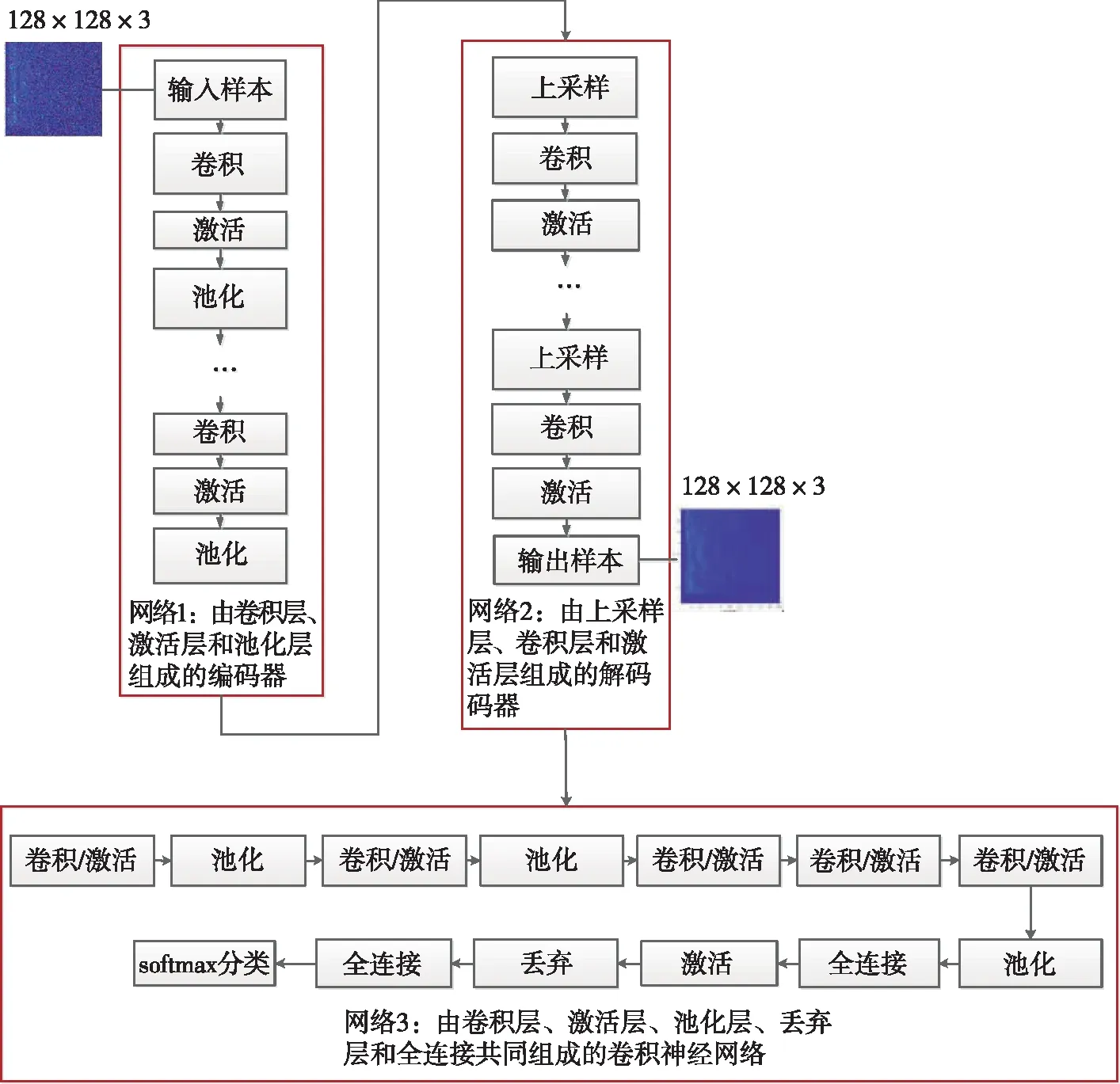
圖5 CDAE-CNN網絡模型結構圖
3 模型實驗與結果分析
3.1 數據集
本文使用實測的水聲信號對方法的有效性進行驗證,現有數據的種類為A、B兩類目標,共713個樣本,每個數據樣本時長10 s。首先對水聲原始音頻信號進行FFT處理,得到Lofar譜數據集,將Lofar譜圖像結構被統一調整成128×128×3。訓練時將所有的數據隨機劃分為82%的訓練集,為604個樣本,18%的測試集,為109個樣本,數據集情況如表2所示。
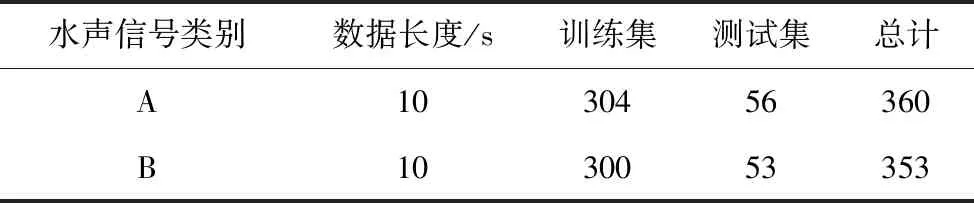
表2 水聲信號數據集
3.2 模型訓練結果分析
本文在TensorFlow框架下利用水聲Lofar譜數據集對設計的CNN、CDAE-CNN網絡模型進行訓練,訓練學習率設置為0.000 5,動量超參數設置為0.9,訓練批次大小為16。
經過100次的迭代后,分別得到CNN網絡模型和CDAE-CNN網絡模型的訓練損失率(如圖6、圖7所示),水聲Lofar譜圖的識別測試準確率如表3所示。
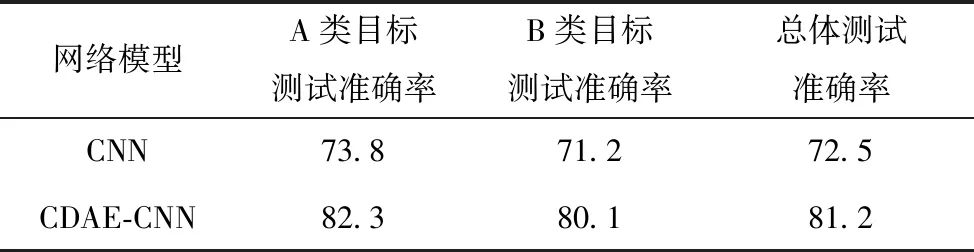
表3 不同方法的測試準確率對比 %
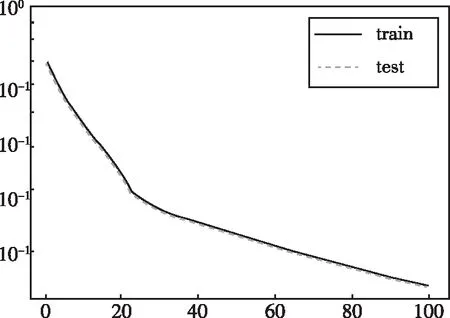
圖6 CNN模型訓練過程損失率曲線
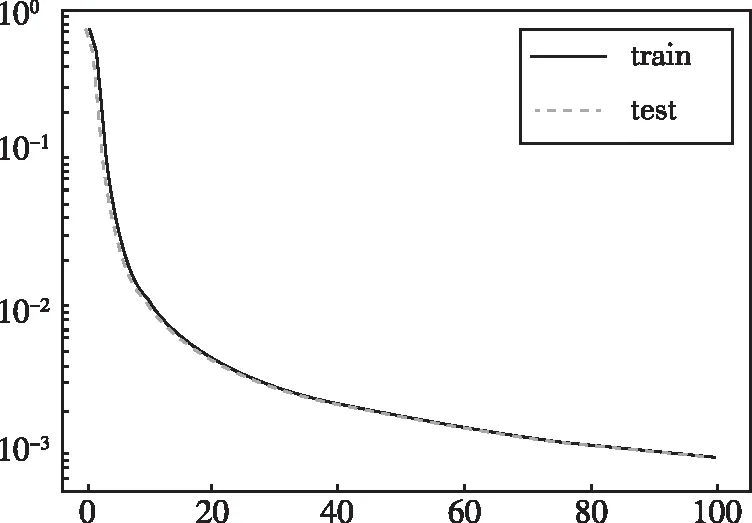
圖7 CDAE-CNN模型訓練過程損失率曲線
從圖6、圖7的模型訓練損失率曲線中可以看出,CDAE-CNN模型的擬合效果較好,另外,從表3中可以看出,與CNN方法進行對比,本文提出的CDAE-CNN模型的測試準確率更高。
4 結論
本文根據水聲信號的特點,設計了卷積網絡與卷積去噪自編碼器的組合網絡,通過卷積去噪自編碼器對輸入數據進行降維和特征提取,將卷積神經網絡中卷積核的形狀進行了改進,以適應水聲信號Lofar譜中頻率隨時間穩定分布的特點,提取出用于識別的更穩定的特征。針對水聲數據集樣本量較小,模型容易出現過擬合的問題,在CNN全連接層的后面加入了Dropout層,試驗結果表明,本文提出的模型的總體測試準確率為81.2%,性能高于CNN網絡。
本文的不足之處在于所使用的數據類型單一,數據集樣本量較少,下一步需繼續擴充數據集,同時充分考慮海洋環境對數據集的影響,不斷優化網絡模型參數,提升模型的泛化性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
