智能電網下的用電設備故障預測與診斷技術
2023-12-14 11:10:16王金利
通信電源技術 2023年19期
王金利
(國網河北省電力有限公司故城縣供電分公司,河北 衡水 253800)
0 引 言
在傳統電力系統中,故障的預測和診斷主要依靠人工經驗與周期性巡檢,存在診斷效率低、準確性不高等問題。然而,在智能電網中,大數據和人工智能等新興技術的應用為解決這一問題提供了新的可能性。本研究旨在探索基于智能電網的用電設備故障預測與診斷技術,通過充分利用大數據、機器學習以及數據分析等方法,實現對用電設備故障的準確預測和及時診斷。通過提前發現潛在的故障跡象,并給出相應的應對措施,避免故障的發生,提高電力系統的可靠性和安全性。
1 傳統方法和技術在用電設備故障預測與診斷方面的局限性
1.1 依賴人工經驗和周期性巡檢
傳統方法通常依賴于工作人員的經驗和巡檢活動,存在主觀性和依賴性高的問題。這種方式需要大量的人力投入和時間成本,并且無法實時監測設備的運行狀態與潛在故障跡象。
1.2 效率和準確性有限
由于手動巡檢和人工診斷的限制,傳統方法往往不具備高效和準確的故障診斷能力。故障的發現可能會延遲,導致進行維修和維護的反應時間變長,增加了故障對系統的影響。
1.3 難以應對復雜故障模式
傳統方法通常只能檢測和預測部分故障模式,難以應對復雜的故障情況。電力系統中的設備故障具有多樣性和復雜性,包括電氣故障、機械故障、熱故障等各種類型。傳統方法在面對這些復雜的故障模式時,往往無法提供準確的預測和診斷結果。
2 針對用電設備故障預測與診斷存在問題的解決對策
2.1 引入智能傳感器和實時監測技術
引入智能傳感器和實時監測技術是在企業人力資源管理中提高效率與準確性的重要舉措之一[1]。隨著物聯網和人工智能技術的快速發展,企業可以利用智能傳感器和實時監測技術來獲取用電設備的相關數據,并進行持續地監測和分析。這種方法可以減少對人工經驗的依賴,提高員工管理的科學性和精準性。
智能傳感器可以感知并測量環境中的各種物理參數,如溫度、濕度、壓力等。在企業人力資源管理中,智能傳感器常常被應用于監測用電設備的運行狀態和能耗情況。傳感器通過與用電設備連接,實時收集相關的數據,并將其發送給數據處理平臺。智能傳感器監測的用電設備運行狀態和能耗情況如表1所示。

表1 智能傳感器監測的用電設備運行狀態和能耗情況
如表1所示,通過對這些數據的分析和比較,企業可以發現異常情況,進行能源管理和優化,并做出相應的調整和決策,以提高能源利用效率、降低成本。
實時監測技術則利用物聯網和云計算等技術手段,使得企業可以遠程監測與分析用電設備的數據。通過將傳感器采集到的數據上傳至云平臺或服務器,企業可以實現對設備運行狀態的實時監測和分析,包括設備的運行時間、能耗情況、故障情況等。基于這些數據,企業可以進行能耗分析和預測,優化設備的運行效率,并提出相應的改進措施。
引入智能傳感器和實時監測技術可以帶來多方面的好處,通過實時監測,企業可以了解用電設備的運行狀態和能耗情況,及時掌握潛在問題,減少因設備故障而造成的生產停工和損失。此外,通過數據分析和挖掘,企業可以深入了解設備的能耗模式和優化空間,采取合理的節能措施,降低能耗成本,提高企業的競爭力。
2.2 建立故障診斷的數據分析模型
建立故障診斷的數據分析模型,可以幫助提高電力系統故障診斷的準確性和效率[2]。通過使用大數據分析技術、機器學習算法和專業領域知識相結合,可以從海量的電力監控數據中挖掘隱藏的故障模式和特征,給定一個包含n個樣本的數據集D,其中每個樣本由輸入特征向量x組成,可以表示為{x1,x2,...,xn}。根據領域知識、經驗或其他啟發方法來確定聚類中心的個數K。更新每個聚類的中心位置,計算該聚類內所有樣本的平均特征值,作為新的聚類中心。使用K-means算法可以將相似的樣本聚集在一起,形成具有相似特征的聚類。從而可以挖掘出具有相似故障模式和特征的樣本群組,為故障診斷提供有價值的信息。本研究將介紹故障診斷的數據分析流程和關鍵步驟,并分析其中的挑戰與解決方案。
故障診斷的數據分析流程包括數據采集與清洗、特征提取與選擇、模型訓練與評估以及故障診斷結果的解釋與驗證。在數據采集與清洗階段,需要收集電力系統各個關鍵節點的監測數據,包括電流、電壓、功率等。同時,對采集到的數據進行清洗和處理,去除異常值和噪聲干擾,確保數據質量和一致性。計算每個樣本的Zscore,表示每個樣本與整個數據集均值之間的偏差情況,公式為
式中:x為樣本值;μ為數據集的均值;σ為數據集的標準差。設置閾值,判斷Zscore是否超過設定的閾值。若Zscore超過閾值,則將該樣本標記為異常值。使用無監督學習算法(如聚類、密度估計等)或離群值檢測算法(如孤立森林、局部異常因子(Local Outlier Factor,LOF)算法等),根據樣本之間的相似性和分布特征,判斷每個樣本是否為異常值。計算每個樣本與其k近鄰點之間的距離,一般使用歐氏距離或其他距離度量方式。對于每個樣本,計算其k近鄰點的可達距離,即樣本到k近鄰點的最大距離。計算每個樣本與其k近鄰點之間可達距離的平均值,作為該樣本的局部可達密度,表示該樣本的密度情況。
在特征提取與選擇階段,需要從清洗后的數據中提取出能夠反映故障特征的特征變量,如相電壓不平衡度、諧波含量等。同時,還需要根據專業知識和經驗選擇合適的特征變量,以便更好地區分不同故障類型。這一步驟的挑戰在于如何確定哪些特征對故障診斷起到關鍵作用,并如何對特征進行組合和權重設置。模型訓練與評估是故障診斷數據分析的核心步驟,需要使用機器學習算法建立故障診斷模型。常用的機器學習算法包括決策樹、支持向量機以及神經網絡等。這些算法可以通過對已有故障樣本進行訓練,學習出故障模式和規律,并可以對新的未知樣本進行預測和分類。在模型訓練過程中,還需要進行交叉驗證和性能評估,以保證模型的準確性和可靠性。
2.3 建立多模型融合的故障診斷系統
建立多模型融合的故障診斷系統,如圖1所示,能夠綜合分析設備運行狀態,提高故障診斷的準確性和可靠性。通過將不同類型的故障診斷模型相互融合,可以充分利用各個模型的優勢,形成綜合診斷結果,更加全面地了解設備的健康狀況。本研究將介紹多模型融合故障診斷系統的設計原則、實現方法以及其在提高設備運行狀態分析中的應用。
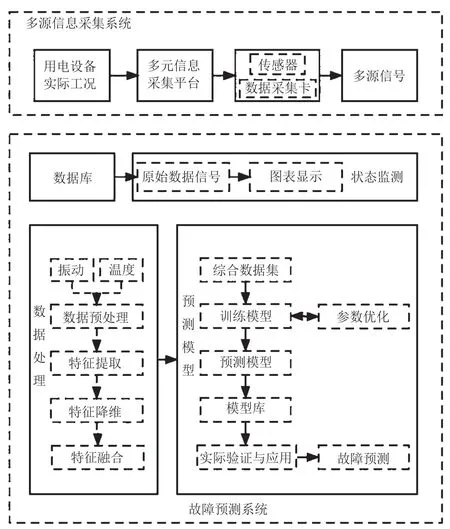
圖1 多模型融合故障診斷系統
設計多模型融合的故障診斷系統需要考慮以下幾個原則[3]。首先是多樣化原則,即選擇不同類型和不同方法的故障診斷模型,覆蓋不同的故障情況。這樣可以增加診斷系統的健壯性,針對不同的故障具備更好的適應性。其次是互補原則,即各個模型之間存在一定的互補性,可以相互補充、支持以及驗證,提高診斷系統的可靠性和準確性。最后是集成原則,即通過特定的算法和策略將各個模型的輸出進行集成,得出最終的綜合診斷結果。
故障診斷模型庫包括基于機器學習的模型,如支持向量機、決策樹、神經網絡等,以及基于規則的專家系統和知識庫[4]。每個模型針對不同類型的故障具備一定的快速判斷能力。然后是模型融合與結果集成,通過合理的算法與策略將各個模型的輸出結果進行集成,形成最終的綜合診斷結果。例如,故障1由支持向量機、決策樹、神經網絡以及專家系統/知識庫共同判斷為Fault A;故障2由支持向量機、決策樹、神經網絡以及專家系統/知識庫一致診斷為Fault C;故障3由支持向量機、決策樹以及神經網絡判斷為Fault D,而專家系統/知識庫判斷為OK。根據這些綜合診斷結果,經系統診斷能夠推斷故障類型并采取相應的處理措施。對于Fault A,可以進行相應的設備維修或更換故障部件;對于Fault C,需開展必要修復或調整設備參數;對于Fault D,需開展相應的設備參數檢查和功能調試,或者對設備進行重新配置。最終,將綜合診斷結果解釋給用戶或相關人員,并進行結果的準確性和可信度評估,確保診斷系統的穩定性與可靠性[5]。
3 結 論
智能電網下的用電設備故障預測與診斷技術是一種有效的手段,可以提高電力系統的可靠性和安全性。通過監測與分析用電設備的運行數據,并利用機器學習算法識別潛在的故障模式和趨勢,能夠及時發現潛在的故障跡象,并采取相應措施來避免設備故障。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
