融合標簽關聯的隱空間數據增強多標簽文本分類方法
2023-12-18 08:58:32苗育華李格格線巖團
現代電子技術 2023年24期
苗育華, 李格格, 線巖團
(1.昆明理工大學 信息工程與自動化學院, 云南 昆明 650500;2.昆明理工大學 云南省人工智能重點實驗室, 云南 昆明 650500)
0 引 言
多標簽文本分類是文本分類的子任務,是從標簽集合中選中具體標簽,為每個實例分配最相關的類標簽子集,目前已廣泛應用在信息檢索[1]、情感計算[2]、情感分析[3]、郵件垃圾郵件檢測[4]和多模態情感分析[5]等領域。多標簽文本分類比單標簽分類更復雜,每個實例都涉及到一個或多個類別,且類別數量不固定,部分類別之間往往是相互關聯的,因此多標簽文本分類是自然語言處理中一個重要而又具有挑戰性的課題。
現如今在多標簽文本分類的任務中,標簽分類變得極為復雜,很多時候都出現了“長尾”分布,也就是標簽不平衡。所謂的標簽不平衡問題,就是指數據集頭部標簽有很多的實例,但是在尾標簽中較少存在甚至只有幾個實例,導致標簽下的數據嚴重不平衡,即可以理解為標簽“長尾”的問題。面對標簽不平衡問題,在數據層面,主要的方法中根據數據本身進行一些替換,構造噪聲數據;在集成算法層面,包括樣本采樣方法、代價敏感學習方法[6]等,主要是在模型訓練階段對訓練實例的樣本進行采樣訓練。
本文從標簽聯系和數據增強的角度出發,利用隱空間數據增強的思想,提出一種融合標簽關聯的隱空間數據增強的多標簽文本分類方法。首先計算出各個標簽相互出現的次數,通過對訓練數據的挖掘,發現各類標簽聯系的先驗知識。在隱空間中,通過標簽之間的聯系來匹配數據,并將標簽的先驗知識和文本特征相結合,創建出一條隱空間下的合成樣本,進而解決類別下數據不平衡的問題。
本文將Mixup 數據增強的方法引入到多標簽文本分類的任務中,在隱空間下通過原始數據和其他相關數據進行結合,有效地提高了多標簽文本分類模型的泛化能力。同時,提出了融合標簽關聯的先驗知識來進行數據策略增強,利用先驗知識改進合成策略,在文本的表示空間下擴增了低頻標簽樣本,提高了多標簽文本分類的效果。實驗結果表明,該方法能應用于一些強大的基礎模型上,并在每種情況下性能都有一定的提升,在具有挑戰性的AAPD 和RCV1-V2 兩個數據集上的微平均F1值分別達到了74.86%和89.05%,相較于基線模型取得了較好的提升。
1 相關工作
討論常見的多標簽文本分類方法,主要包括機器學習算法和現在比較成熟的神經網絡方法,還討論了當前對多標簽文本分類下標簽不平衡問題的解決方法。
1.1 問題轉換方法
多標簽文本分類是單標簽分類的分支,在二分類任務中的技術已經相當成熟。問題轉換方法就是將復雜的問題轉化為一個更簡單的問題。在這種思想下,將原始多標簽文本分類問題轉換為多個二分類問題或者多類分類的問題。二元相關性算法(Binary Relevance,BR)[7]就是典型的問題轉換方法。LP(Label Powerset)[8]為每一個可能的標簽組合提供一個獨特的類,將任務轉換為標簽組合的多類分類問題。基于分類器鏈(CC)的方法[9]是對BR 算法的一個改進,將任務轉化為二元分類問題鏈。但是該方法的問題就是通過分類鏈的順序和先前分類器的預測得到標簽的預測準確度,對模型性能有著很大的影響,而且不能預測沒有出現在當前標簽組合內的標簽。
1.2 算法自適應方法
基于算法自適應的方法擴展了傳統的標簽分類技術,采用合適的算法直接處理多個標簽數據來解決多標簽文本分類。ML-DT[10]算法借鑒了決策樹根據信息增益篩選特征生成分類器的思想來解決多標簽分類。Elisseeff 等人提出排名支持向量機(Ranking Support Vector Machine, Rank-SVM),使用一個新的度量,采用支持向量機訓練來處理多標簽問題[11]。ML-KNN(Multi-Label K-Nearest-Neighbor)[12]算法是在內部構建一個BR分類器,通過K 近鄰的方法處理多標簽數據,然后計算每個標簽的先驗概率和條件概率。
1.3 神經網絡方法
深度學習方法發展快速,在自然語言處理領域內的任務中得到了廣泛的應用。G.Kurata 提出使用卷積神經網絡(CNN)進行分類[13],J.Nam 等人基于RNN 的Seq2Seq 來建模,借助RNN 依次產生的標簽序列來捕獲標簽之間的相關性[14]。Chen 等人將CNN 和RNN 進行了融合[15],Yang 等人提出了SGM 方法,將注意力機制融入Seq2Seq 框架[16]。雖然有一些方法提出了改進,但是能否學到標簽之間的相關性還有待商榷。 隨著Transformer 和BERT 的提出,Sun 等人將BERT 應用到文本分類中,介紹了一些調參和改進的方法,進一步挖掘BERT 在文本分類中的應用[17]。深度學習算法大大提高了多標簽文本的分類效果,但仍有很大的提升空間。
1.4 解決標簽不平衡策略
數據增強方法在解決數據不平衡方面有著一定的改進。數據擴展是一種范圍從基于規則到基于可學習的生成方法,而且上述所有方法基本上都保證了擴展數據[18]的有效性。文獻[19]僅用于對文本分類的數據增強的綜述。Zhang 等人將敘詞表應用于數據增強,使用來自WordNet 的同義詞典,根據它們的相似性對同義詞進行分類[20]。Min 等人交換數據的主語和賓語,而且還將謂語動詞轉換成被動語態,以此來達到數據增強的目的[21]。V.Verma 等人提出一種在嵌入空間中生成偽樣本(x~,y~)的Manifold Mixup 方法[22]。
2 模 型
面對多標簽文本分類任務,已有方法沒有很好地解決標簽不平衡問題。本文從標簽聯系和數據增強的角度出發,利用隱空間數據增強的思想,提出了一種融合標簽關聯的隱空間數據增強的多標簽文本分類方法。模型整體框架如圖1 所示。
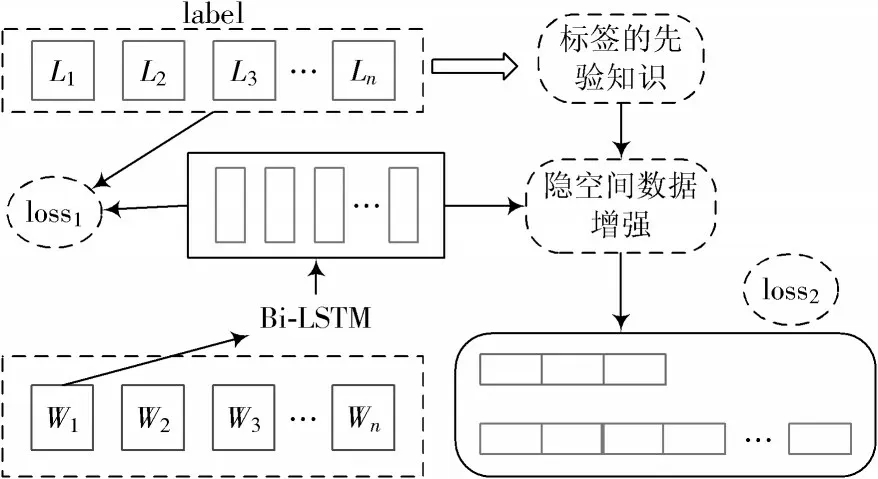
圖1 模型整體框架
2.1 符號表示


2.2 模型架構
2.2.1 編碼層
本文模型的編碼層包括詞嵌入層、編碼層和結構化注意力層,詞嵌入層使得詞序列xi= (w1,w2,…,wk,…,wn)經過詞嵌入了詞序列的低維向量E= (e1,e2,…,ek,…,en),其中ek∈Rd表示第k個詞元素,為驗證數據增強方法的適用性,分別以Bi-LSTM 和Bert 作為模型的編碼器,將E作為輸入,傳入編碼器,通過訓練得到數據集對應的隱狀態H= (h1,h2,…,hk,…,hn),其中hk表示每條數據的隱狀態。在編碼后,利用結構化自注意力機制將隱狀態H作為輸入,得到:
式 中:注 意 力 權 重 矩 陣A∈Rr×n;Ws1∈Rda×(2u+d);Ws2∈Rr×d是注意力層的參數。da、r為模型的超參數,da為注意力層的隱狀態維度,r為注意力機制的個數。
由文本詞序列的隱狀態表示H和注意力權重矩陣A得到句子的嵌入矩陣M=AH,最終通過M中的r個向量拼接得到文本的向量X= (X1,X2,…,Xi,…,XN)。
2.2.2 隱空間數據增強
為融入標簽之間的關系,通過對數據集的分析,統計出各個標簽相互出現的次數,其中標簽對自身的影響為0,構建矩陣L=[L1,L2,…,Li,…,Lk],其維度為k×k,其中k為標簽類別數量。為計算出標簽之間的影響,對Li按行進行歸一化操作,其長度為k,表示其他標簽對當前第i個標簽的影響得分,最終得到得分矩陣L~ =[L~1,L~2,…,L~i,…,L~k]。
本文借鑒Manifold Mixup 方法的思想,在文本的隱藏空間中合成偽樣本。在此基礎上,提出融合標簽關聯的隱空間下的數據增強策略。在合成樣本時采用標簽匹配策略,通過對每條訓練數據的標簽yi與數據集中的所有數據的標簽集合Y= (Y1,Y2,…,Yi,…,YN)進行計算。其中yi的長度為標簽類別長度k,Y的維度為N×k,通過式(2)得到與原始數據(xi,yi)匹配的數據(xj,yj)。
式中:D( )x,y為數據集的文本及標簽特征表示的集合;F(·)表示隨機取出與原始樣本的標簽相近的數據位置。對訓練樣本(xi,yi)和匹配樣本(xj,yj)進行結合,得出偽樣本,公式如下:
式中:λ∈[0,1]為樣本的混合因子,由Beta(α,α)分布采樣得到;α為超參數;f(yj,yi)表示匹配標簽特征yj對于訓練標簽特征yi中每類標簽不一樣的位置;m表示將標簽出現在yj但不在yi中的位置記為1,其他標簽位置記為0;k為 標簽個數;g(m,L~)表示在序列m為1 的位置上,通過得分矩陣L~,得出其他為1 的標簽對當前標簽影響的概率,最終通過伯努利分布得出m對應位置具體標簽分配;G(·)表示將標簽特征集合進行融合,得出偽數據的標簽特征。
2.2.3 損失函數
在計算損失函數時,借鑒Circle Loss 思想[23],基于深度特征學習對相似度優化的觀點,以類內相似度sp最大、類之間相似度sn最小為目標。再結合蘇劍林提出的“softmax +交叉熵”的思想[24],得到:
式中:Ωneg和Ωpos分別代表樣本的正負類別集合;si為非目標類中第i類的得分;sj為目標類中第j類的得分,對于額外的0 類得分s0,使其閾值為0。對于訓練樣本和偽樣本,通過損失函數得到最終的混合損失:
式中:?~1為訓練數據的損失;?~2為偽數據的損失;α∈[0,1]為損失結合的超參數。
3 實 驗
介紹用于實驗的兩個數據集、評價指標和基線方法,并且展示在兩個不同的編碼器下的實驗結果,驗證所提方法的有效性。
3.1 數據集
采用以下兩個數據集進行試驗驗證:
1) Arxiv Academic Paper Dataset(AAPD)[25]:是 由Yang 等人創建的,考慮到一篇論文可能涉及到一個或者多個學科,最終共收集了54 種學科共計55 840 篇論文的摘要。
2) Reuters Corpus Volume I(RCV1-V2)[26]:是 由Lewis 等人收集路透社新聞專欄報道得到的,共計103 個主題和804 414 篇報道。
3.2 評價指標
基于已有研究[25,27-28],采用漢明損失(HL)和微平均下的F1得分作為主要的評價指標,同時測試微平均下的準確率和召回率。
3.3 基線模型
本文方法將與以下幾個基線模型進行比較:
1) LSTM:應用長短期記憶網絡來考慮文本的順序結構,以及減輕爆炸和消失梯度的問題。
2) Bert:使用以Transformer 為主要框架的雙向編碼表征模型。使用了大量的語料庫進行訓練,在許多自然語言處理的任務中實現了很高的性能。
3) BR、CC、LP、CNN-RNN、SGM 的結果在之前的論文中被引用,其他基線的結果由本文實現,所有算法都遵循相同的數據劃分。
4 實驗結果和分析
4.1 對比實驗
本文提出的基于標簽先驗知識的數據增強方法,分別基于Bi-LSTM 和BERT 兩種編碼器對AAPD 和RCV1-V2 兩個數據集進行處理。將本文方法與基線模型進行對比,結果如表1 和表2 所示。從表1 和表2 可以看出,在使用Mixup 方法后,對基線模型的性能都有一定的提升。
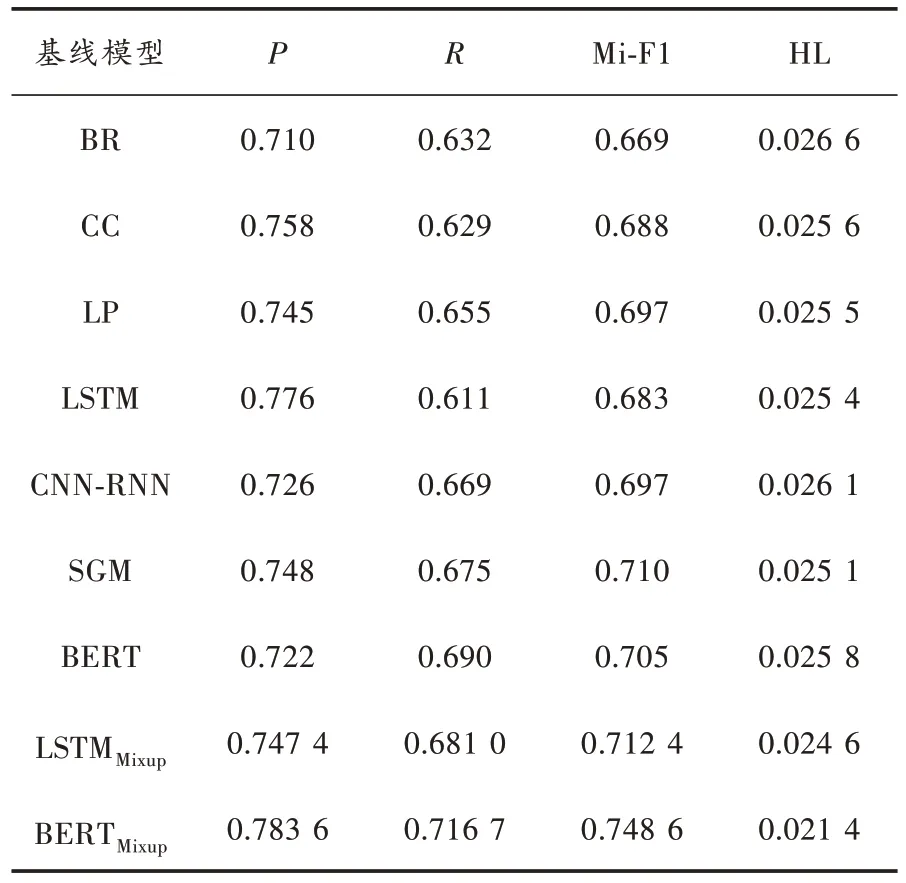
表1 數據集AAPD 在每個算法上的性能
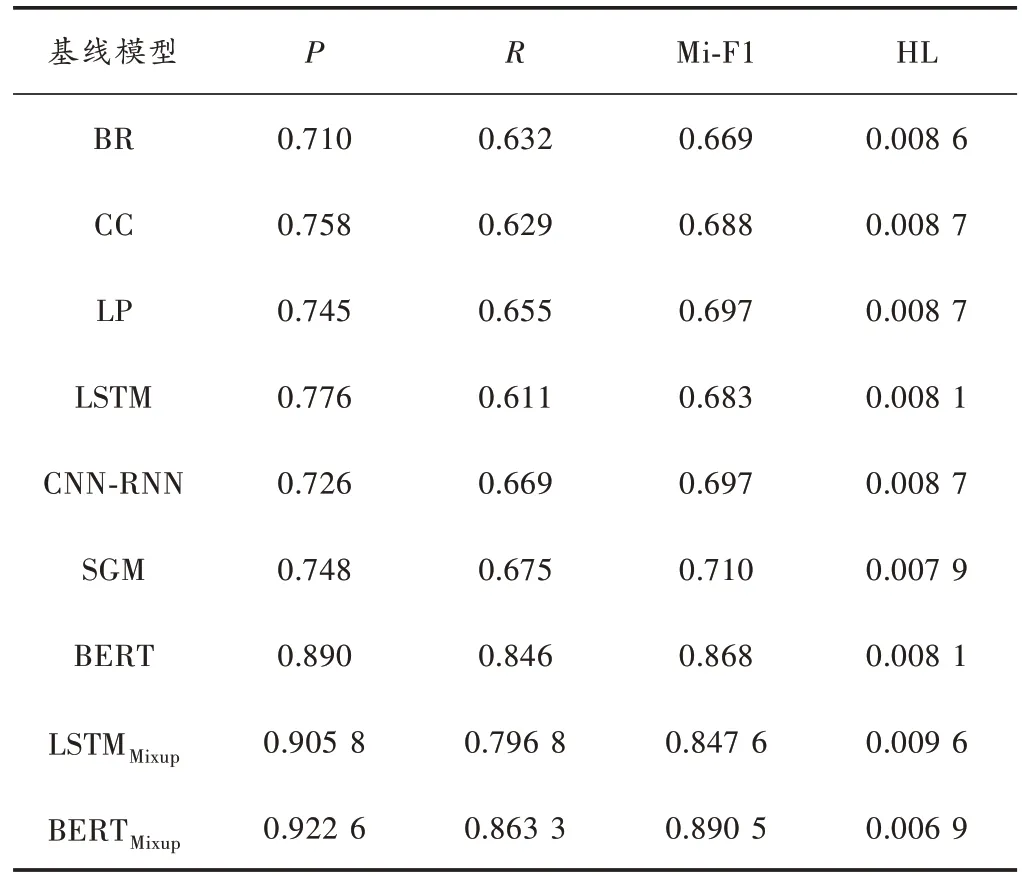
表2 數據集RCV1-V2 在每個算法上的性能
由表1 可知,在處理AAPD 數據集時,對于基線方法中最好的BERT 方法,本文方法基于BERT 編碼的微平均F1值提高了4.2%,漢明損失值0.021 4 較SGM 值0.025 1 提高14.7%。在表2 中,隨著RCV1-V2 的數據集實例數量的增加,不同的基線方法都獲得了一定的提升,可見數據規模對模型也有著一定的影響。其中基于BERT 編碼方式的本文方法的微平均F1值最高,為0.890 5。對于兩個數據集同時使用本文方法,發現基于BERT 編碼方式優于基于LSTM 方式,在AAPD 數據集上提升了3.62%,在RCV1-V2 的數據集上提升了4.29%。表1中展示的兩個數據集實驗結果,證實了本文方法比已有處理大型數據集的方法都具有顯著的優勢。
4.2 消融實驗
標簽先驗知識的數據增強策略是本文方法的重要組成部分,為驗證對多標簽文本分類模型的影響,本文進行兩組消融實驗。第一組實驗在隱空間數據增強構建合成數據的過程中,移除標簽先驗知識對合成標簽的影響,標記為(raw_mix);第二組實驗在模型訓練過程中移除了隱空間數據增強策略,標記為(att)。數據集AAPD 和RCV1-V2 加入Mixup 方法性能前后對比的結果如表3 所示。
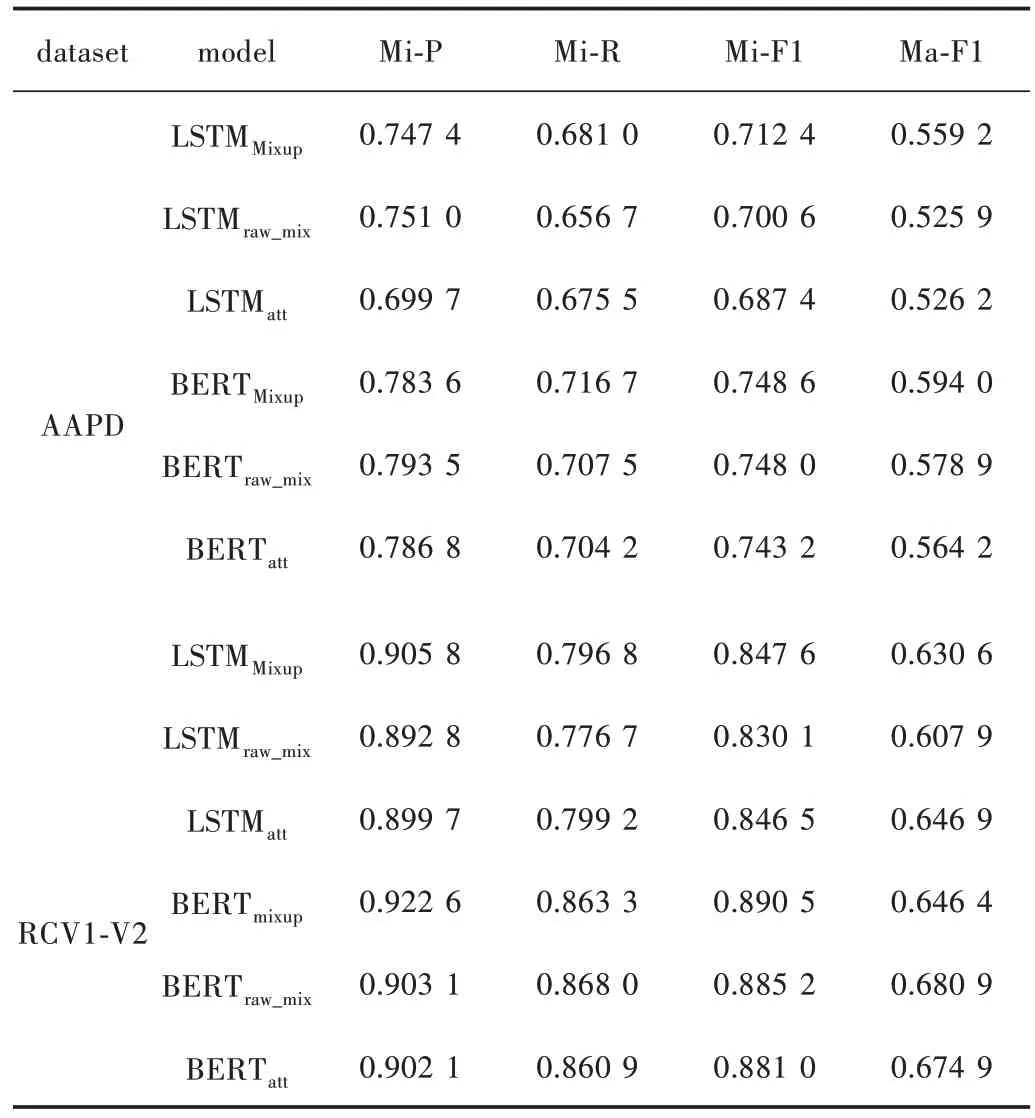
表3 數據集AAPD 和RCV1-V2 加入Mixup方法前后性能對比結果
由表3 可知,在移除標簽先驗知識對合成標簽的影響后,基于BERT 編碼時,AAPD 和RCV1-V2 兩個數據集融入隱空間數據增強方法對于性能有著一定的提升,且在數據集實例較少的AAPD 上,宏平均F1值從0.564 2到0.594 0,上升了約3 個百分點。
在移除隱空間數據增強策略后,基于LSTM 編碼方式下在AAPD 數據集上微平均F1提升了2.5%,基于LSTM 編碼方式在AAPD 數據集上宏平均F1值提升了2.98%。但隨著數據規模的增大,在RCV1-V2 數據集上整體提升較小。
5 結 語
本文提出一種利用標簽之間的先驗知識在隱空間進行數據增強的方法,以解決多標簽文本分類任務中類別不平衡的問題。相比于其他解決標簽不平衡方法,本文方法摒棄了傳統的數據增強的思想,無需額外的人工標注和對數據集進行擴建,也不用降采樣或過采樣,只在模型的隱空間中的特征層進行拼接數據的創建,以及通過對長尾標簽下的數據進行一定的構建。實驗結果表明,在具有挑戰性的多標簽數據集上隱空間Mixup 優于有競爭力的基線,也驗證了本文提出方法的合理性。在未來的任務中,Mixup 思想可以進一步應用于其他自然語言處理的分類任務。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
