基于雙延遲深度確定性策略梯度的衛星遠程變軌控制
2023-12-18 18:13:49邱鵬鵬張易誠曹海濤鄭君錚
計算機時代 2023年11期
邱鵬鵬 張易誠 曹海濤 鄭君錚


關鍵詞:變軌控制;相對運動;目標軌道;深度強化學習
中圖分類號:TP183 文獻標識碼:A 文章編號:1006-8228(2023)11-90-04
0 引言
近年來,隨著航天技術的發展,航天器相對距離控制已成為一個活躍的研究領域,被廣泛應用于衛星在軌維護、衛星組裝[1],以及空間碎片捕獲[2]等多個場景,航天器相對距離控制要求衛星能夠自主、安全地接近后者到達目標位置。通常,相對距離控制可分為近程控制和遠程控制。近程控制一般要求探索衛星從幾十公里內直接開始搜索目標[3],而遠程控制一般需要協調地面站,獲取目標位置,從而引導探索衛星變軌到近程軌道。解決遠程相對距離控制問題需要制定合理的變軌策略,然而這往往面臨著許多困難。由于空間飛行環境多變且復雜,因此任務實現難度異常艱巨,代價巨大。傳統的基于優化控制的方法,其有效性取決于動態模型的準確性,如果因環境不穩定等因素導致的引導模型的精準度不足,那么飛行任務則極易失敗。因此,需要使用健壯且具有較強自適應能力的策略以應對各類空間飛行問題。
深度強化學習(DRL)是機器學習領域的一個熱門研究課題。智能體根據自身狀態及其他已知信息做出相應的動作,通過與環境的交互作用來獲取獎勵,不斷優化策略指引智能體向獎勵高的方向行動,直到獲得最優策略。因此,一方面DRL 代理能夠降低計算頻率,這使得其廣泛應用于具有有限計算能力的衛星上;另一方面通過減少代理自主性對優化方法的依賴從而降低行為間相關聯性。
針對以上方法及問題,提出一種基于深度強化學習雙延遲深度確定性策略梯度算法(Twin DelayedDeep Deterministic Policy Gradient Algorithm,TD3),從而解決在復雜多變的連續空間環境下的變軌任務。具體來說,通過引入合適的數據處理方式、設置合理的獎勵函數,令衛星與環境不斷進行交互,進而引導衛星做出點火決策的同時更新策略,并最終從高軌道逐步變軌到達目標軌道附近。最后,利用可視化方法驗證TD3 算法解決衛星相對距離控制問題的有效性。本文的貢獻是:①考慮衛星真實情況下間斷性點火特性,解決了在算法控制與狀態變化不同頻率狀況下的衛星橢圓軌道變軌控制;②引入軌道動力學模型,采用動態Z-score 數據處理方法,提出了一種TD3 控制算法,,有效地解決了高軌道、高維度下衛星變軌問題。
1 背景及現狀
隨著航天技術的快速發展,衛星變軌控制引起越來越多的學者關注,這使得變軌飛行可行性和關鍵性技術被充分挖掘,許多方案都取得了良好的效果。
衛星變軌到達目標軌道的問題,本質上是一種相對距離協調控制問題,國際上目前常見的衛星相對距離飛行控制方法包括系繩法、庫侖力法[4]、人工勢函數法[5]、李亞普諾夫函數法等。在庫侖力衛星控制中,采用一定的技術手段使得衛星帶電(正電荷或負電荷),通過控制衛星帶電量來控制衛星受力大小及方向,進而實現衛星變軌到達目標軌道。庫侖力法解決了衛星近距離相對距離控制時設定衛星同性電荷從而避免發生碰撞。然而,庫侖力法受到衛星間的間距限制,它無法支持遠程衛星引導控制。
深度強化學習在解決復雜的非線性控制問題方面具有很大的優勢,因此常被用于處理航天領域的相關研究。為了實現衛星的交會對接,作者引入近端策略優化算法(Proximal Policy Optimization,PPO),設定防碰撞區域以及安全區域,結合相對軌道的動力學方法[6]。為了解決近距離的航天器對接問題,介紹了一種能夠在真實航天器平臺上使用的基于分布式深度確定性策略梯度的算法[7] (Distributed DistributionalDeep Deterministic Policy Gradient,D4PG),用于擬合出最佳制導軌跡從而反饋到常規控制器上以進行衛星軌跡跟蹤。然而,上述基于深度強化學習的衛星變軌控制策略大都基于衛星間距僅為幾千米的范圍,目前針對衛星遠程相對控制的文章少之又少。因此,本文將采用TD3 算法來解決衛星在橢圓軌道變軌下到達目標軌道問題。
4 仿真實驗及結果分析
4.1 實驗環境及參數
實驗中,衛星和地球的半徑分別90km、6371km,質量分別為4474kg、5.965E24kg。
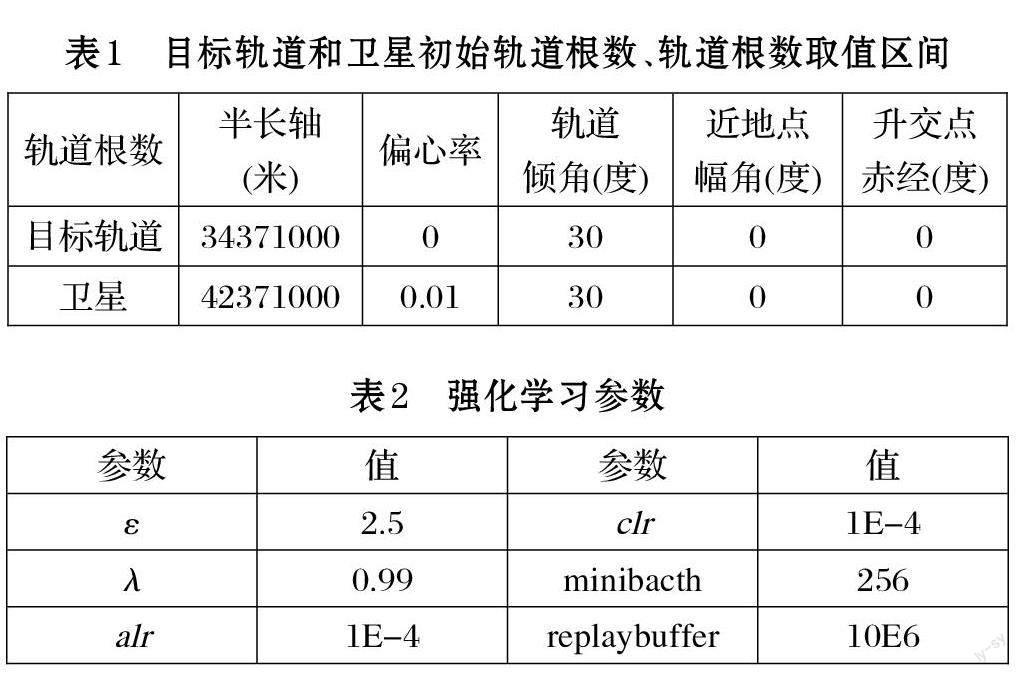
衛星軌道根數半長軸、偏心率、軌道傾角、近地點幅角、升交點赤經取值范圍分別為[6.371E3,3.6E7]、[0,1]、[0,π]、[0,π]、[0,2π]。初始化目標軌道和探索衛星的軌道六根數如表1 所示。設定衛星初始真近點角為0,則可以計算出衛星的初始位置矢量和速度矢量分別為:(3.02E7,0,1.91E7)、(0,2798.17,1615.52);同時,可以計算出目標軌道加速度和速度大小分別為:0.34m/s^2、3403.32m/s。我們設定衛星點火作用時間為一秒鐘,依據網絡輸出的動作,可計算出相應的速度變化量和位置變化量。同時,在下一次點火動作到來之前,衛星受萬有引力作用自由飛行五分鐘。
定義神經網絡為三層全連接層,即5*128*128*3。神經網絡狀態輸入為衛星軌道根數,網絡輸出為三軸方向的加速度,其取值范圍為[?10m/s^2,10m/s^2]。同時,TD3 算法中參數具體設置如表2 其中,ε表示高斯噪聲的均方誤差,λ 表示式⑺中的目標函數折扣因子,alr 和clr 分別表示Actor 網絡與Critic 網絡的學習率。minibacth 表示從replaybuffer 采樣的最小單元。同時將噪聲切割的上下限c 設置大小為5。
在獎勵設置中,獎勵系數α1,α2,α3,γ1,γ2分別為20,10,10,100,100, 而βi = 15, i = 1…5。獎勵函數設計為偏差的一次反比例函數。
4.2 結果分析
在本文中,我們設定衛星距離目標軌道500 米以內即判定系統收斂。經過TD3 算法引導,系統產生的獎勵與軌跡圖分別如圖1 和圖2 所示。從圖1 中看出系統在約300 步左右就收斂,系統獎勵值收斂在-1E-5附近。從圖2 中可以看出衛星從開始位置逐漸變軌到終點位置從而到達目標軌道(更淺色的圓)附近。
我們同樣利用TD3 算法與DDPG 算法進行實驗,如圖3 所示。對比圖3(a)可以看出,經過了Z-score 數據處理過的網絡更加穩定,也更加適用于處理像衛星這樣各數據量級不在同一量級上的問題;而對比圖1與圖3(b)易看出,我們所提出的基于Z-score 的TD3算法相較DDPG 算法具有更快的收斂特性。
5 總結
本文提出在深度強化學習下的TD3 控制算法,來處理衛星通過遠程變軌到達指定目標軌道的問題。實驗結果表明,該算法能夠有效解決衛星變軌到達目標軌道的控制問題。然而在本算法中,并未考慮多顆衛星情況,真實空間任務多是基于多衛星完成的,接下來考慮多個衛星在強化學習作用完成到達目標軌道任務。
