一種修正學(xué)習(xí)率的梯度下降算法
2024-01-05 07:21:28姜文翰姜志俠孫雪蓮
長春理工大學(xué)學(xué)報(自然科學(xué)版) 2023年6期
姜文翰,姜志俠,孫雪蓮
(長春理工大學(xué) 數(shù)學(xué)與統(tǒng)計學(xué)院,長春 130022)
近年來神經(jīng)網(wǎng)絡(luò)已成為人工智能的核心框架,廣泛應(yīng)用于語音識別、圖像分類、自然語言處理等領(lǐng)域[1]。 其中,卷積神經(jīng)網(wǎng)絡(luò)(CNN)在人體活動識別、句子分類、文本識別、人臉識別、目標檢測和定位、圖像表征等方面有著廣泛的應(yīng)用[2-5]。
神經(jīng)網(wǎng)絡(luò)中,梯度下降算法是求解參數(shù)最重要、最基礎(chǔ)的方法[6]。 然而隨著數(shù)據(jù)規(guī)模的不斷擴大,傳統(tǒng)的梯度下降算法已不能有效解決大規(guī)模機器學(xué)習(xí)問題[7-9]。因此,梯度下降算法成為機器學(xué)習(xí)研究的焦點。隨機梯度下降算法(SGD)是梯度下降類算法中最基礎(chǔ)的方法。針對SGD 易陷入鞍點、局部極小值點、學(xué)習(xí)率不變等問題[10],一方面,動量梯度下降法利用之前下降的梯度方向保持慣性,可以克服SGD 易陷入鞍點、局部極小值點等問題[11]。 另一方面,AdaGrad 利用步長除以歷史梯度平方和作為每步的更新步長,引出自適應(yīng)步長的概念。 但隨著迭代次數(shù)增加,梯度累加和會越來越大,AdaGrad 學(xué)習(xí)率會迅速減小,導(dǎo)致參數(shù)不再更新。RMSProp 使用梯度平方的滑動指數(shù)平均改善這一問題。Adam 在RMSprop 基礎(chǔ)上引入一階動量。 盡管Adam 在多領(lǐng)域的應(yīng)用中已經(jīng)取得良好的結(jié)果,但在AMSGrad 中已經(jīng)通過反例公開了其在某些情況下是發(fā)散的。 隨著Adam 的廣泛應(yīng)用以及大量Adam 變體的出現(xiàn),關(guān)于Adam收斂性的充分條件已經(jīng)引起深度學(xué)習(xí)和優(yōu)化領(lǐng)域的廣泛關(guān)注[12-13]。
在Adam[14]算法基礎(chǔ)上,利用梯度的指數(shù)加權(quán)平均改進學(xué)習(xí)率,提出了MonAdam 算法。該算法改善Adam 算法學(xué)習(xí)率分布較為極端的現(xiàn)象,從而提升神經(jīng)網(wǎng)絡(luò)的收斂性。隨后對MonAdam算法進行了收斂性分析,給出相應(yīng)結(jié)論。最后,在非凸測試函數(shù)和神經(jīng)網(wǎng)絡(luò)中進行實驗分析。實驗結(jié)果表明,與其他優(yōu)化算法相比MonAdam算法具有較好的收斂性。
在界定“整本書閱讀”這一概念時,不少學(xué)者用結(jié)構(gòu)主義二元對立的方法來闡釋,從與“篇章閱讀”相對立的角度,認為“整本書閱讀”首先在閱讀材料上不再是一篇節(jié)選文章的含英咀華,而是一本有著獨立精神、獨特思想價值,能夠作為一個連續(xù)性整體給讀者別樣閱讀感受的完滿集合,閱讀材料更長,也更具復(fù)雜性,完成這一復(fù)雜閱讀任務(wù)的時間更長,表現(xiàn)出來的閱讀行為也更具連續(xù)性。其次,不同于“列書單式”閱讀時代,僅僅是“讀”的粗淺要求,整本書閱讀是以“讀透”,讀出長進為硬性指標的深層次閱讀。在整本書閱讀課上,教師是引導(dǎo)者、傾聽者,更多的時候是調(diào)控者、記錄者。整本書閱讀教學(xué)策略是在師生共同閱讀中生成的。
1 自適應(yīng)學(xué)習(xí)率
Adam 算法[14]作為神經(jīng)網(wǎng)絡(luò)最常用的優(yōu)化算法之一,在保存動量梯度算法的梯度指數(shù)衰減平均值(即一階矩mt)基礎(chǔ)上,同時保存RMSprop算法的梯度平方指數(shù)衰減平均值(即二階矩vt)[15],表達式如下:
2.1組間總有效率對比 研究組銀屑病患者總有效率經(jīng)評定為92.5%,對照組經(jīng)評定為57.5%,組間具統(tǒng)計學(xué)差異(P<0.05);研究結(jié)果如表1所示。
Adam 算法參數(shù)更新公式為:
其中,θt是第t步更新的參數(shù)向量;α為學(xué)習(xí)率;和分別為一階矩和二階矩的偏差校正;ε為一個充分小的正值。Adam 算法結(jié)合兩種算法的優(yōu)點,具有快速初始化的良好性能,但Luo 等人[16]舉出了在某些非凸函數(shù)上Adam 算法仍不能收斂到最優(yōu)解的反例。
采用ResNet-18 神經(jīng)網(wǎng)絡(luò)[17]訓(xùn)練CIFAR-10數(shù)據(jù)集,利用TensorboardX 在圖1 中畫出訓(xùn)練5個EPOCH 的學(xué)習(xí)率分布圖。圖中x軸代表學(xué)習(xí)率,且學(xué)習(xí)率經(jīng)過以e為底的log 縮放,y軸代表迭代次數(shù),高度代表學(xué)習(xí)率出現(xiàn)的頻數(shù)[18]。
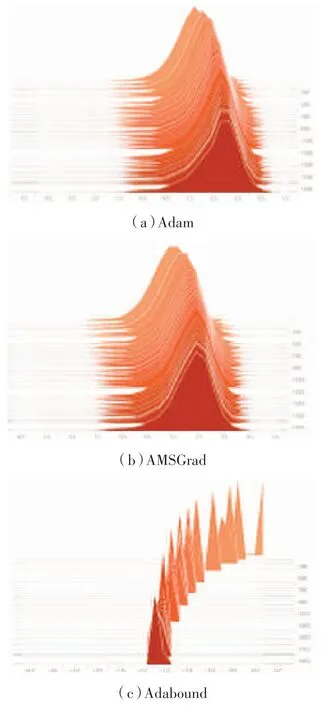
圖1 ResNet-18 網(wǎng)絡(luò)訓(xùn)練CIFAR-10
AMSGrad 算法[19]提出一種通過對二階矩取大的方法,即:
此式為氣體部分編寫程序可用的積分公式, 其中可以看出: 半徑方向最大網(wǎng)格節(jié)點數(shù)為NK, 每兩個相鄰的網(wǎng)格節(jié)點距離為ΔR. 從球坐標最大半徑處開始向球心積分, 網(wǎng)格節(jié)點數(shù)i 依次減小1, 半徑依次減小ΔR. 對每一個網(wǎng)格節(jié)點數(shù)i , 對應(yīng)一個具體的半徑R, 此處根據(jù)當?shù)亓鲌鲋导拜椛浒l(fā)射系數(shù)計算出它的輻射值, 并且根據(jù)此處到球心之間的每一個網(wǎng)格節(jié)點的當?shù)亓鲌鲋导拜椛湮障禂?shù), 計算出具體的半徑R處對球心的輻射照度值.
由圖1(b)可知AMSGrad 算法改善了Adam 算法存在極端學(xué)習(xí)率的問題。但AMSGrad 算法只考慮了Adam 算法中學(xué)習(xí)率處于極大值時的情形,未考慮極小值是否對收斂性有影響,所以在實際問題中的表現(xiàn)差強人意[16]。Luo 等人[16]提出Adabound 算法,使用學(xué)習(xí)率裁剪技術(shù):
本文在Adam 算法中利用梯度信息加權(quán)平均的思想修正自適應(yīng)學(xué)習(xí)率,即將參數(shù)vt更新過程中的替換為,從而得到MonAdam 算法。公式如下:
2 MonAdam 算法及分析
2.1 MonAdam 算法
將Adam 算法與SGD 算法結(jié)合。其中,自適應(yīng)學(xué)習(xí)率的下界ηl(t)是t的非遞減函數(shù),上界ηu(t)是t的非遞增函數(shù)。在學(xué)習(xí)率裁剪過程中,會發(fā)現(xiàn)學(xué)習(xí)率在幾輪迭代后迅速縮減到一個小的區(qū)間,如圖1(c)所示。
其中,β3為修正自適應(yīng)學(xué)習(xí)率的指數(shù)衰減率;是第t步的梯度加權(quán)平均;是自適應(yīng)學(xué)習(xí)率的梯度。MonAdam 算法描述如下:
(1)初始參數(shù)θ0,初始化m0= 0,v0= 0,=0,= 0,超參數(shù)β1,β2,β3∈[ 0, 1) ,學(xué)習(xí)率α,常數(shù)ε,損失函數(shù)f(θ),最大迭代次數(shù)T。
精準扶貧視域下西南邊疆民族地區(qū)思想和文化扶貧工作存在的問題與對策 ……………………………………… 張志巧(6/35)
(2)t從1 開始進行T次循環(huán)迭代。
(3)計算gt= ?θft(θt- 1)。
(5)計算mt=β1?mt-1+ (1 -β1)?gt。
肯普夫說:“當然,在美國西海岸、中國都有一些‘懷才不遇’的研究人員,他們愿意來歐洲尋找一個良好的科研位置。”肯普夫認為,現(xiàn)在是快速實施人工智能戰(zhàn)略的時候了。他說:“聯(lián)邦政府已經(jīng)承諾未來幾年將提供30億歐元的科研經(jīng)費。”正確使用這筆資金非常重要。他說:“最好將研究資金用于推動工業(yè)應(yīng)用數(shù)字化的進一步發(fā)展”,“因為在這個領(lǐng)域我們歐洲人,尤其是德國作為工業(yè)基地有著明顯的優(yōu)勢。”
(8)若滿足終止條件,則保存當前解θt。
其中,β1、β2分別是一階矩和二階矩的指數(shù)衰減率[14];mt- 1、vt- 1分別是第t- 1 步中的一階矩和二階矩;gt為第t步的梯度。
2.2 初始化偏差修正
文獻[14]中對E[vt]與E[gt2]進行分析,得到vt需進行偏差修正的結(jié)論,用以糾正初始化vt為零帶來的偏差。E[]與E[gt]之間的關(guān)系如下:
采用ResNet-18 神經(jīng)網(wǎng)絡(luò)訓(xùn)練CIFAR-10 數(shù)據(jù)集,利用TensorboardX 在圖3 中畫出訓(xùn)練5 個EPOCH 的學(xué)習(xí)率分布圖。 從圖3(a)中可知Adam 算法學(xué)習(xí)率分布區(qū)間較為廣泛。對比圖3(b)可知MonAdam 算法一定程度上改善了Adam算法學(xué)習(xí)率分布較極端情況。
證明:對比文獻[14]中定理4.1 的證明過程可知,只需重新證明MonAdam 中的的上界即可。
圖2 表示MonAdam 算法在VAE 中訓(xùn)練MNIST數(shù)據(jù)集對10 個EPOCH 的損失圖。圖中橫軸代表學(xué)習(xí)率并取以10 為底的對數(shù),縱軸代表VAE 中的損失,VAE 損失是重構(gòu)誤差與KL 散度誤差兩項之和[20]。其中,超參數(shù)選取β3∈{ 0 .001,0.01,0.1} ,log10(α)∈[ -5, - 1 ]。
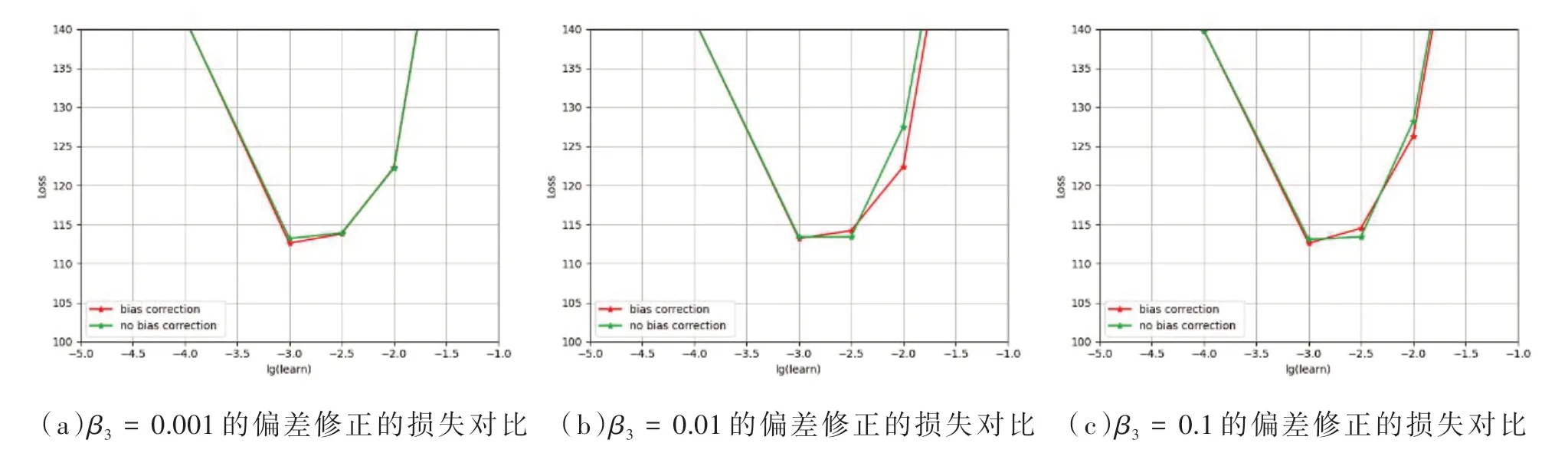
圖2 變分自編碼器(VAE)訓(xùn)練MNIST 數(shù)據(jù)集
由圖2 可知在訓(xùn)練初始階段,算法進行偏差修正時結(jié)果較優(yōu),可以防止產(chǎn)生較大的初始化偏差。
風(fēng)影急匆匆地又要走了,紅琴也挎著一籃子磨菇要回家了。冷不防她竄上去攔在他的面前,她讓他等一等,隨即就從細腰上取下一根紅色的褲腰帶子,閉上眼睛默默地念了一陣子,然后她將它掛在樹枝上,打了一個丁香結(jié)。他問她什么意思,她笑容滿面,說這個結(jié)就代表著他們這次見面,下次還在這里見面,再打一個結(jié)。她說只要心誠,每次打結(jié)許個愿,等到打了七七四十九個結(jié),心里想什么好事,就能如愿以償了。
2.3 梯度加權(quán)平均的自適應(yīng)學(xué)習(xí)率
觀察兩組血液檢驗結(jié)果,包括平均紅細胞血紅蛋白量、平均紅細胞體積、紅細胞分布寬度、平均血紅蛋白濃度;對比兩者診斷符合情況。
1.2.1 透析前細節(jié)管理(1)根據(jù)不同時間段的心理情況采取不同的心理干預(yù)措施,讓其負面情緒得到充分的宣泄;(2)根據(jù)患者不同的文化背景采用不同的健康宣講方式為患者進行血液透析對病情治療和控制的優(yōu)點、必要性以及透析過程中透析頭身體產(chǎn)生的不適反應(yīng),讓其對血液透析治療的步驟、優(yōu)勢、不適有一定了解,提前做好心理準備,面對透析治療中的帶來的各種困難;(3)在對患進行血液透析前,必須謹慎估測患者當前的干體重,并預(yù)設(shè)最佳脫水值,防止在透析時發(fā)生大規(guī)模的超濾,使血壓急速下降。
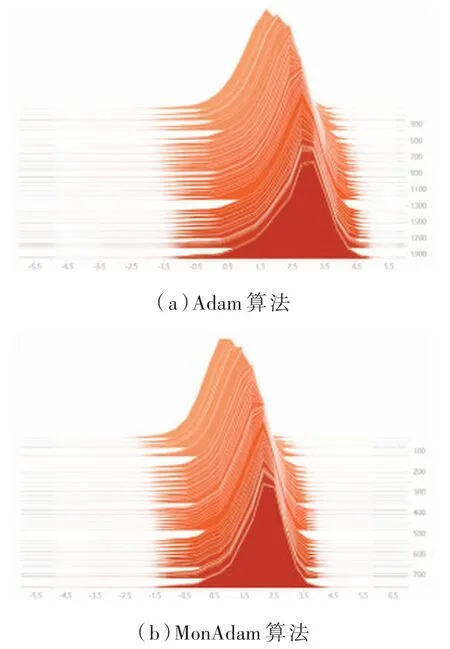
圖3 ResNet-18 網(wǎng)絡(luò)訓(xùn)練CIFAR-10 數(shù)據(jù)集
2.4 收斂性分析
由文獻[14]中定理4.1 可知,設(shè)函數(shù)ft的梯度有界,即?θ∈Rd,則有:
由Adam 算法產(chǎn)生的任意兩個參數(shù)θt之間的距離有界,即:?m,n∈{1 ,…,T},有,。 對于參數(shù)β1、β2∈[ 0,1) ,滿足,令,且β1,t=β1λt-1,λ∈( 0,1) 。對于?T≥1,可以證明Adam 算法的遺憾界為:
試驗選取液固比601,浸取溫度55 ℃,測定浸取時間對Ba2+、OH-濃度以及水溶性鋇存在形式的影響,試驗結(jié)果如圖6、圖7。
如果E[gs]是穩(wěn)定的,則ζ= 0。否則,可以適當選擇指數(shù)衰減率β3,以便為較遠歷史梯度分配較小的權(quán)重,故ζ是足夠小的值[14]。 而項是由初始化引起的,可在算法中除以此項,即對進行偏差修正:
在MonAdam 算法中引入?yún)?shù)β3∈[ 0,1) ,計算:
為驗證管理層能力對企業(yè)研發(fā)投入的直接影響,對全樣本進行回歸,表2第1列和第2列分別是對模型 (1)進行普通混合最小二乘法和固定效應(yīng)模型回歸的檢驗結(jié)果。可以看出,管理層能力對企業(yè)的研發(fā)投入強度的影響均為負。經(jīng)過F檢驗和Hausman檢驗,應(yīng)選擇固定效應(yīng)模型,根據(jù)第2列結(jié)果解釋更合適。這意味著就全樣本而言,面對商業(yè)轉(zhuǎn)化不確定的經(jīng)營環(huán)境,高能力管理者制定研發(fā)決策更為審慎,傾向于根據(jù)其自身專業(yè)能力更好地識別創(chuàng)新機會,減少轉(zhuǎn)化無效或低效的研發(fā)投入以避免企業(yè)陷入經(jīng)營困境,驗證了假設(shè)1。
其中:因為λi∈(0,1),i∈[ 1,…,t],所以不等式:
即:
因此:
3 實驗分析
利用非凸函數(shù)與神經(jīng)網(wǎng)絡(luò)對SGDM、AdaGrad、RMSProp、Adam、MonAdam 五種算法進行對比分析。
3.1 非凸函數(shù)
計算非凸函數(shù)F1(x) 和F2(x)[21]的最小值,應(yīng)用SGDM、Adam、MonAdam 算法進行優(yōu)化。 圖像分別如圖4(a)、圖4(c)所示,收斂情況分別如圖4(b)、圖4(d)所示。
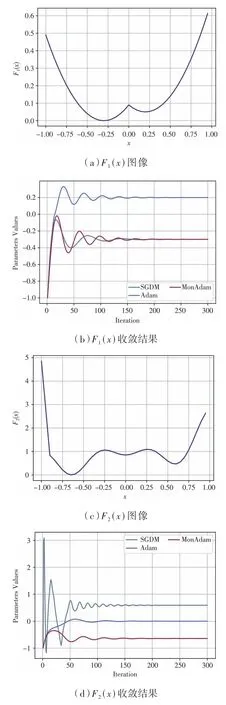
圖4 非凸函數(shù)圖像與收斂結(jié)果
參數(shù)均設(shè)置為β1= 0.95,β2= 0.999,β3= 0.9,α= 0.1,m0= 0,,v0= 0,且均進行300 次迭代。F1(x) 與F2(x) 定義如下:
由圖4(b)可知Adam 算法在非凸函數(shù)F1(x)中陷入了局部極小點,SGDM 與MonAdam 算法收斂到全局最優(yōu)點。 由圖4(d)可知非凸函數(shù)F2(x)中SGDM 與Adam 算法均陷入局部極小點,MonAdam 算法收斂到全局最優(yōu)點。
3.2 測試函數(shù)
選用四個測試函數(shù):
(1)Booth′s 函數(shù):
(2)Matyas 函數(shù):
目前市場上的中藥揮發(fā)油提取設(shè)備型號多樣、功能各異,其質(zhì)量關(guān)系到中藥揮發(fā)油的質(zhì)量。相關(guān)部門應(yīng)盡快加強提取設(shè)備標準化管理,完善《藥品生產(chǎn)質(zhì)量管理規(guī)范》(GMP)或建立相關(guān)政策法規(guī)。由于在提取揮發(fā)油的過程中普遍存在提取工藝與提取設(shè)備不適宜的問題,因此在研發(fā)自動化、智能化揮發(fā)油提取設(shè)備的同時,必須加強提取工藝與設(shè)備的適宜性研究,從而使傳統(tǒng)的低效、高耗能揮發(fā)油提取設(shè)備升級成高效、低耗、綠色的現(xiàn)代中藥揮發(fā)油提取設(shè)備。
(3)McCormick 函數(shù):
(4)Sphere 函數(shù):
社會主義協(xié)商民主是中國共產(chǎn)黨和中國人民的偉大創(chuàng)造,最初起源于新民主主義時期作為各革命階級聯(lián)盟的統(tǒng)一戰(zhàn)線,體現(xiàn)為階級民主,即各革命階級為爭得民主,實施革命階級間的政治聯(lián)合與協(xié)商,在實踐中又通過統(tǒng)一戰(zhàn)線的合作形式和組織形式推動社會主義協(xié)商民主的發(fā)展[11]。
對MonAdam 算法性能進行檢驗。
實驗中該算法參數(shù)設(shè)置為:β1= 0.9,β2= 0.999,β3= 0.01。前三種測試函數(shù)學(xué)習(xí)率α= 0.001,第四種測試函數(shù)學(xué)習(xí)率α= 0.02。實驗結(jié)果如圖5和表1 所示。
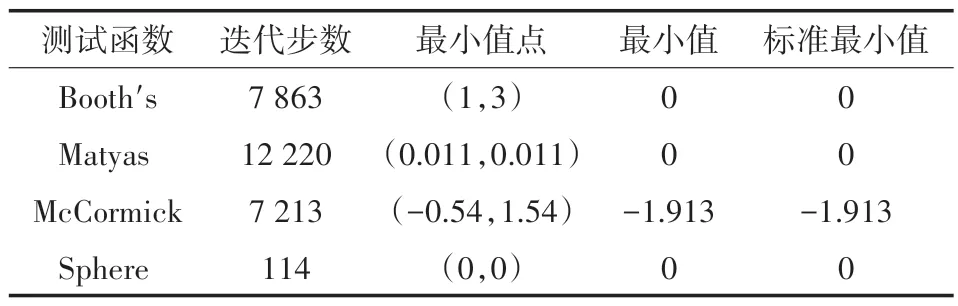
表1 測試函數(shù)結(jié)果
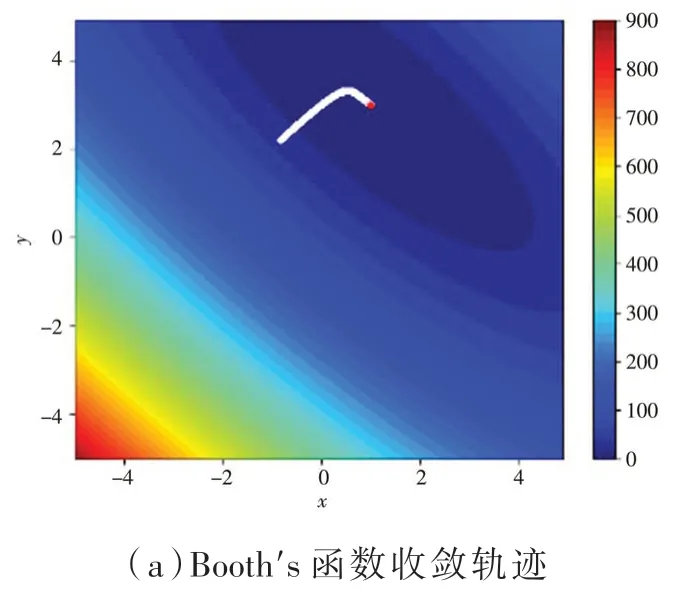
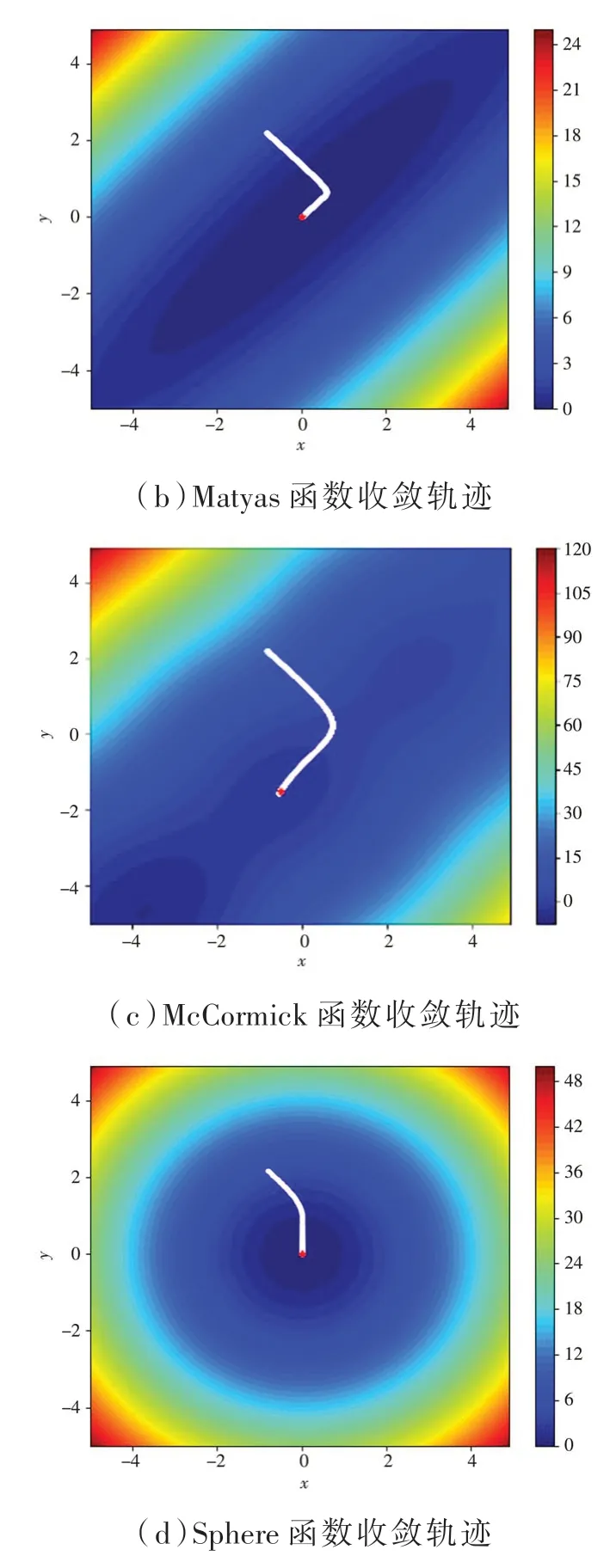
圖5 收斂情況
如表1 所示,在四種測試函數(shù)中MonAdam 算法均達到全局最小點。可見,MonAdam 算法收斂情況較優(yōu)。
3.3 神經(jīng)網(wǎng)絡(luò)實驗
首先在圖像分類任務(wù)中,選取常見的數(shù)據(jù)集進行算法性能測試[22]。CIFAR10 和CIFAR100 數(shù)據(jù)集均由60 000 張圖像組成,其中50 000 張用于訓(xùn)練,10 000 張用于測試。本文使用ResNet-34求解CIFAR-10/100 數(shù)據(jù)集,比較SGDM、AdaGrad、RMSProp、Adam 以及MonAdam 算法的收斂效果。
實驗參數(shù)設(shè)置:α= 0.001,β1= 0.9,β2= 0.999,β3= 0.01,ε= 10-8,m0= 0,,v0= 0,momentum = 0.9。所有優(yōu)化算法均進行200 次迭代。其中,對ResNet-34 深度神經(jīng)網(wǎng)絡(luò)采用學(xué)習(xí)率預(yù)熱技術(shù),在150 輪次后使得學(xué)習(xí)率衰減10。
如圖6(b)、圖7(b)所示,MonAdam 算法在實驗中均有較快的收斂速度和較好的泛化性能。 如表2 所示,MonAdam 算法在ResNet-34 模型中兩個測試集的準確率分別可達93.77%、73.79%。
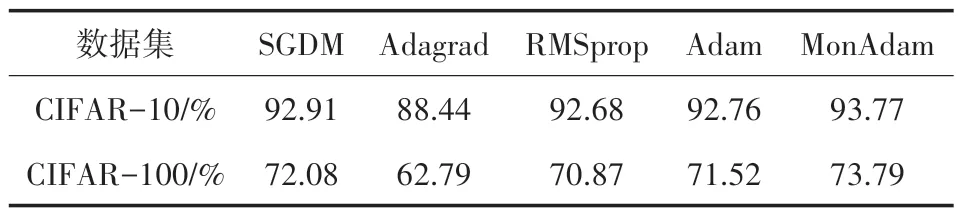
表2 ResNet-34 的測試集準確率
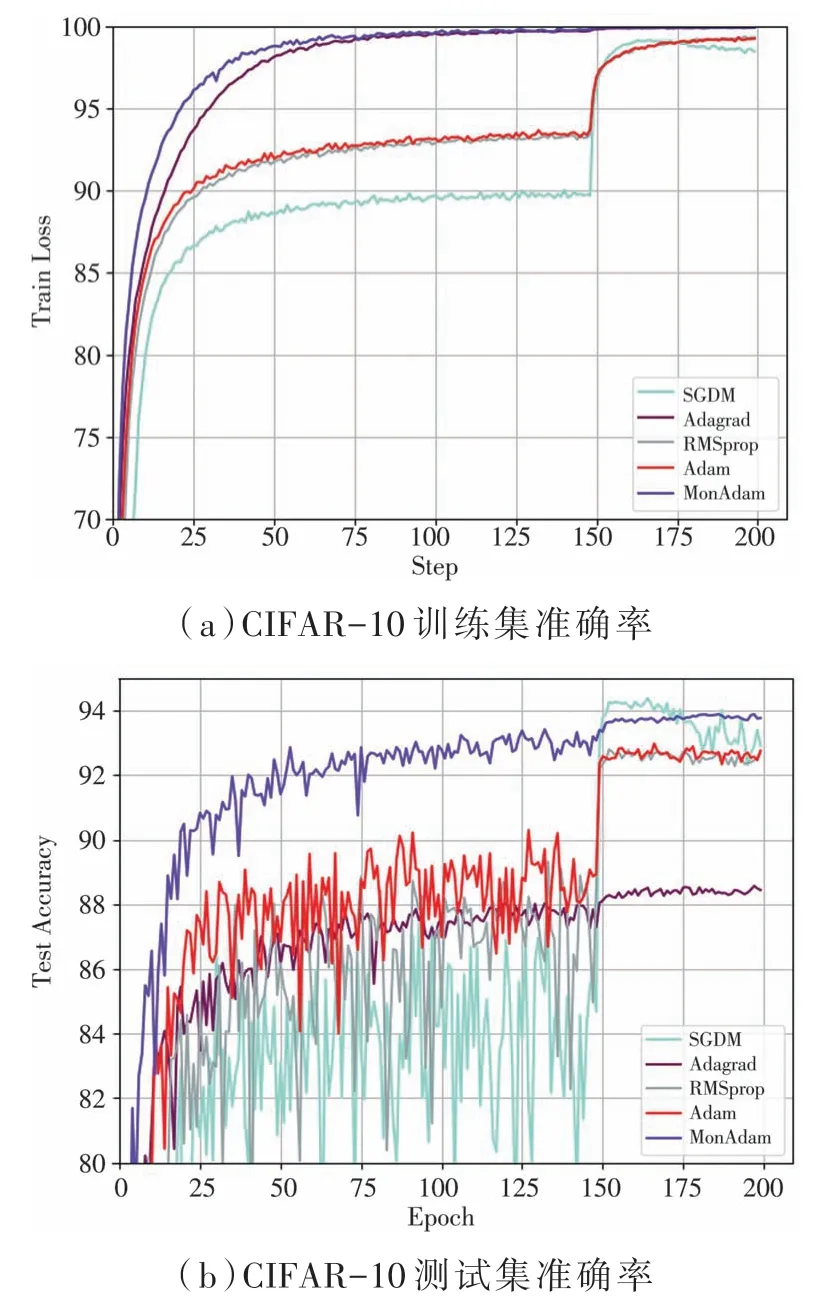
圖6 利用ResNet-34 訓(xùn)練CIFAR-10 數(shù)據(jù)集
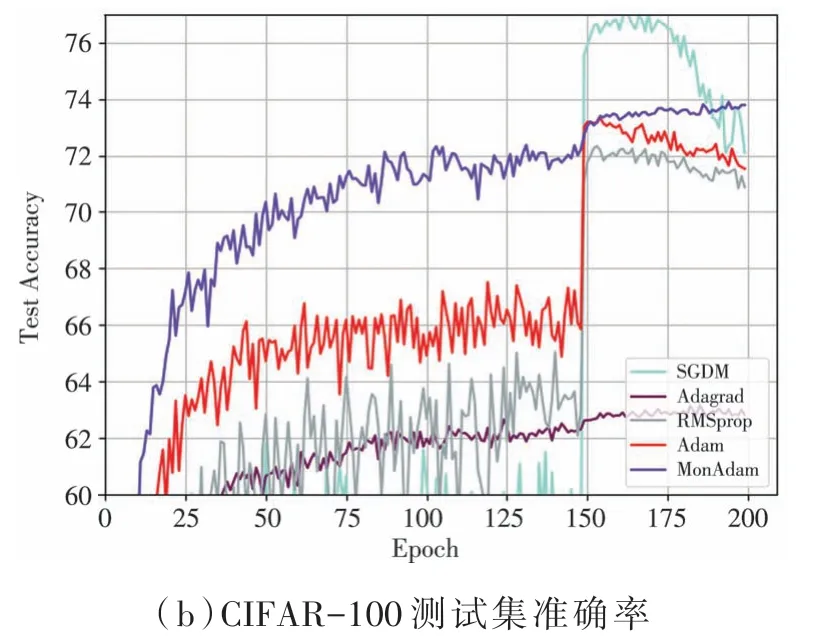
圖7 利用ResNet-34 訓(xùn)練CIFAR-100 數(shù)據(jù)集
為衡量MonAdam 算法的適用性,利用長短時記憶神經(jīng)網(wǎng)絡(luò)(LSTM)[23]在PTB 數(shù)據(jù)集中進行語言建模實驗。實驗中使用困惑度作為衡量指標,困惑度越小則代表對新文本有較好的預(yù)測作用。如表3 所示,MonAdam 的困惑度最小,即具有良好的優(yōu)化結(jié)果。
4.用氯化鈉3.5 g、碳酸氫鈉2.5 g、氯化鉀1.5 g、葡萄糖20 g、氟哌酸散4 g、加水1 000 ml,充分搖勻溶解,每次口服80~100 ml,每日早晚各1次。
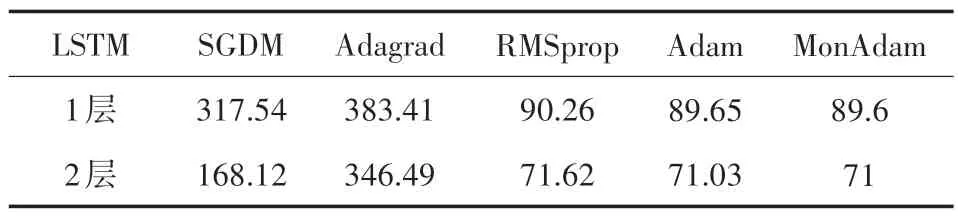
表3 PTB 數(shù)據(jù)集的困惑度
綜上所述,在非凸函數(shù)與CIFAR10/100 數(shù)據(jù)集中MonAdam 算法和Adam 算法相比,準確率均有一定程度提升。 而在語言建模任務(wù)中,RMSprop 算法、Adam 算法和MonAdam 算法收斂性能相當,在圖8 中困惑度在下降過程中出現(xiàn)大量重合,故可知MonAdam 仍然有較出色的表現(xiàn)。
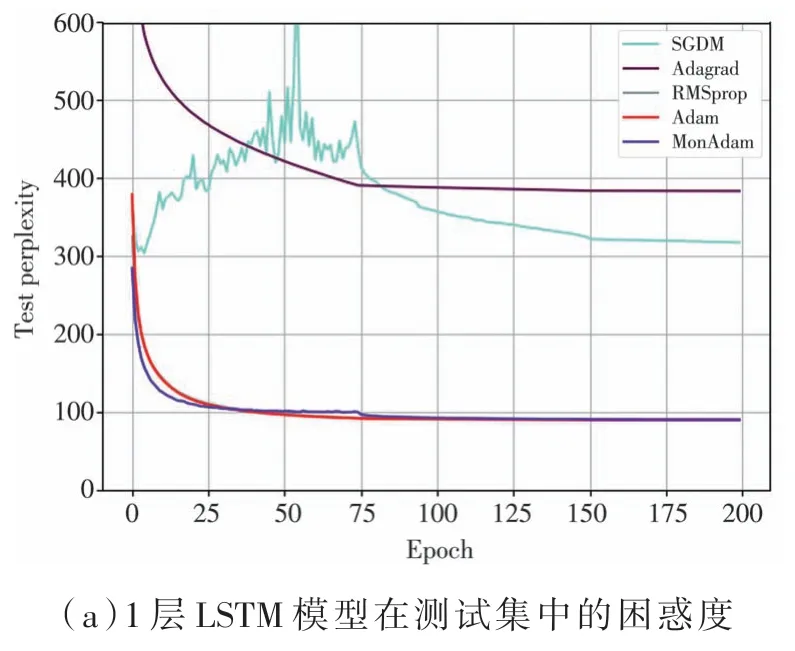
圖8 利用LSTM 訓(xùn)練PTB 數(shù)據(jù)集
4 結(jié)論
由于梯度下降算法過程簡單、易于實現(xiàn)、具有相對良好的收斂性等特點,成為了神經(jīng)網(wǎng)絡(luò)中常用的參數(shù)更新算法。但仍具有收斂速度相對較慢、易陷入鞍點、局部極小點、泛化能力差等問題[24]。通過對Adam 算法中學(xué)習(xí)率的修正,提出MonAdam算法。本文通過改善學(xué)習(xí)率的分布,完善Adam 算法的收斂性。 未來的工作可以考慮將提出的修正學(xué)習(xí)率思想應(yīng)用于AdaNorm[25]、RMSProp、AdamW[26]、AdaBound、Nadam[27]等算法中。
