基于深度殘差網(wǎng)絡(luò)的接轉(zhuǎn)站工藝流程異常工況診斷
2024-01-06 03:08:16張蕊侯磊劉珈銓孫省身張坤杜鑫李興濤
石油科學(xué)通報 2023年6期
張蕊 ,侯磊,劉珈銓,孫省身,張坤,杜鑫,李興濤
1 中國石油大學(xué)(北京)機械與儲運工程學(xué)院,北京 102249
2 中國石油長慶油田分公司長慶工程設(shè)計有限公司,西安 710021
3 中國石油長慶油田分公司第十二采油廠,合水 745000
4 中國石油國際勘探開發(fā)有限公司,北京 102249
0 引言
接轉(zhuǎn)站作為油氣田地面集輸系統(tǒng)的關(guān)鍵節(jié)點,既有設(shè)備集中、運行連續(xù)性強的生產(chǎn)特點[1],還容易出現(xiàn)來流比例劇烈波動和設(shè)備運行故障等工況異常[2]。目前油田生產(chǎn)現(xiàn)場對接轉(zhuǎn)站場的工況診斷主要依靠操作員工經(jīng)驗。對于簡單設(shè)備的異常數(shù)據(jù),操作員工尚能進行初步診斷,但對整個站場的大量SCADA實時監(jiān)測數(shù)據(jù),僅靠經(jīng)驗和知識難以實現(xiàn)快速分析處理[3]。閾值報警系統(tǒng)本應(yīng)及時準(zhǔn)確地反饋異常信號[4],但實際應(yīng)用中其對多模態(tài)過程適應(yīng)性差,“假報警”“不報警”問題突出,亟待發(fā)展適用于接轉(zhuǎn)站場的智能診斷方法。
油氣處理工藝流程的診斷方法包括基于知識的方法、基于模型的方法及數(shù)據(jù)驅(qū)動方法[5]。目前站場應(yīng)用較多的是基于知識的方法。趙自愿[6]利用模糊故障樹分析法對原油集輸系統(tǒng)關(guān)鍵設(shè)備進行異常分析,用CAFTA軟件對現(xiàn)場集輸流程進行仿真,求取關(guān)鍵設(shè)備在一定工作時間內(nèi)的可靠度。方一宇[7]采用QRA法對接轉(zhuǎn)站中的壓力容器進行風(fēng)險評價,對接轉(zhuǎn)站系統(tǒng)的危害因素進行有效識別,量化了接轉(zhuǎn)站系統(tǒng)風(fēng)險等級。
上述基于知識的方法雖能用于對油氣站場的異常模式及危害度進行定量分析,但難以在系統(tǒng)輸入與輸出之間建立精確數(shù)學(xué)模型。數(shù)據(jù)驅(qū)動方法只需建立具有分類功能的數(shù)學(xué)模型[8],就能直接對SCADA數(shù)據(jù)進行處理,以實現(xiàn)站場狀態(tài)的實時診斷與評估。
在數(shù)據(jù)驅(qū)動方法中,異常工況診斷被視為時間序列數(shù)據(jù)的分類[9],具體包括統(tǒng)計分析方法、淺層學(xué)習(xí)方法和深度學(xué)習(xí)方法。統(tǒng)計分析方法、淺層學(xué)習(xí)方法均需要豐富的專業(yè)領(lǐng)域知識來確定時頻域特征[10],在復(fù)雜學(xué)習(xí)任務(wù)中的信息表征能力存在局限性[11],不適用于具有非高斯分布、非線性特性的儲運站場過程數(shù)據(jù)。深度學(xué)習(xí)方法是一種用多個隱含層對特征數(shù)據(jù)進行逐層非線性轉(zhuǎn)換從而實現(xiàn)數(shù)據(jù)特征抽象提取的算法[12],適于處理高維海量數(shù)據(jù),能夠自動提取非線性數(shù)據(jù)特征,通過組合足夠多的變化,理論上可以無限逼近任意復(fù)雜函數(shù)。
Zhao[13]利用基于批歸一化(BN)的長短時記憶神經(jīng)網(wǎng)絡(luò)(LSTM),自適應(yīng)學(xué)習(xí)原始數(shù)據(jù)的時間動態(tài)信息。Xie[14]利用階層深度神經(jīng)網(wǎng)絡(luò)(HDNN)對田納西-伊斯曼過程(TE過程)進行故障診斷。Chao等[15]利用改進的貝葉斯優(yōu)化和DRN的異常診斷模型,對變電站的熱異常進行診斷。Jiang[16]將堆棧式稀疏自編碼器(SSAE)用于故障診斷,實現(xiàn)了半監(jiān)督學(xué)習(xí)策略。
從網(wǎng)絡(luò)架構(gòu)角度而言,針對其他分類任務(wù)設(shè)計的高深度模型[13-16]直接應(yīng)用于接轉(zhuǎn)站場數(shù)據(jù)時,易出現(xiàn)在訓(xùn)練集表現(xiàn)良好但驗證集精度降低的過擬合現(xiàn)象。從數(shù)據(jù)特性角度而言,接轉(zhuǎn)站場收集數(shù)據(jù)相比公開時間序列數(shù)據(jù)集,樣本量小且維度高,模型存在學(xué)習(xí)不足,難以訓(xùn)練風(fēng)險。從訓(xùn)練成本角度而言,高深度且多核的模型在學(xué)習(xí)過程中耗時長,硬件要求高,訓(xùn)練難度加劇。
深度殘差網(wǎng)絡(luò)(DRN)[17]于2015年被首次提出,是一種先進的深度學(xué)習(xí)模型,它在卷積神經(jīng)網(wǎng)絡(luò)(CNN)結(jié)構(gòu)中加入恒等映射快捷連接,解決了深層網(wǎng)絡(luò)梯度彌散和精度下降的問題,緩解了訓(xùn)練困難,使網(wǎng)絡(luò)在加深過程中既保證精度,又控制速度[18]。
本文以某油田接轉(zhuǎn)站流程為例,將多元時間序列數(shù)據(jù)(MTS)分類方法[19]融入異常診斷體系中,提出一種基于DRN的接轉(zhuǎn)站異常工況診斷方法,能夠自動提取異常特征,實現(xiàn)高精度異常診斷,通過油田生產(chǎn)現(xiàn)場SCADA數(shù)據(jù)對該方法進行有效性驗證。
1 基于DRN 的異常工況診斷方法
1.1 卷積層
卷積層的主要作用是從輸入數(shù)據(jù)中提取特征,對一個有M個特征映射的作為輸入的卷積層,當(dāng)有N個過濾器時,按下式計算第K層的輸出特征[20]:
如圖1 所示,卷積層的局部感知能夠提取監(jiān)測變量的局部特征,接轉(zhuǎn)站過程數(shù)據(jù)中不同時間點,不同變量間的相同變化特性能夠被卷積的權(quán)值共享模式捕獲[21]。

圖1 卷積核示意圖Fig. 1 diagram of convolution kernel
1.2 激活層
激活層通過對加權(quán)輸入進行非線性組合以產(chǎn)生非線性決策邊界,非線性變換能夠使網(wǎng)絡(luò)存儲信息量大大增加[20]。如圖2 所示,常見激活函數(shù)包括邏輯函數(shù)(Sigmoid)、雙曲正切函數(shù)(tanh)、線性校正單元(ReLU)等。
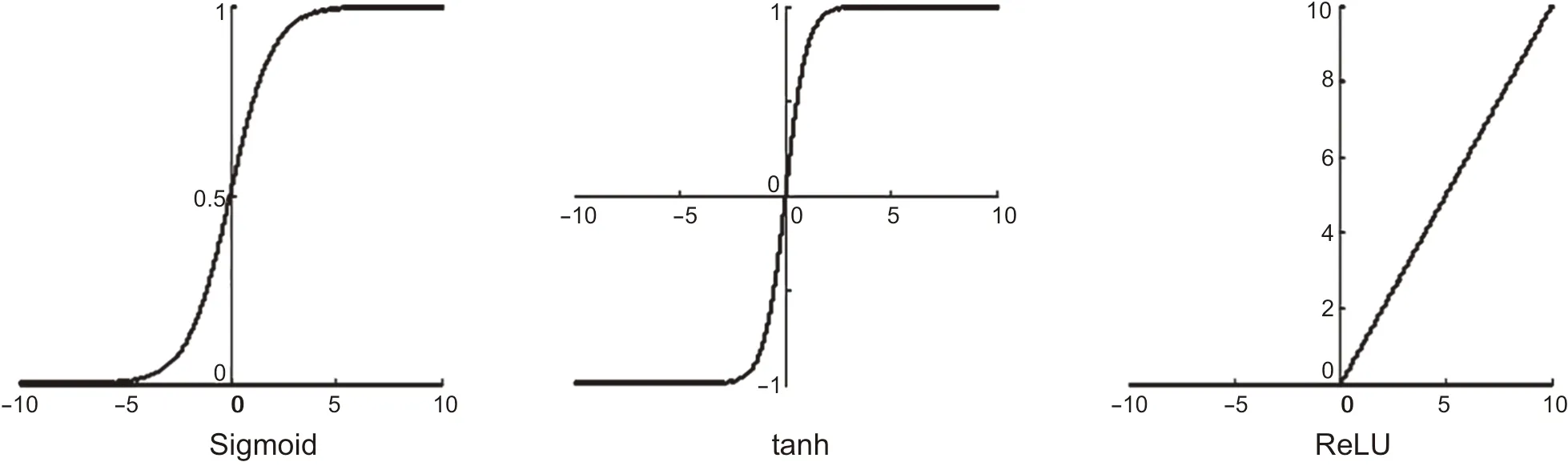
圖2 激活函數(shù)示意圖Fig. 2 Schematic diagram of activation function
Sigmoid型函數(shù)定義見下式,它是兩端飽和的S型曲線函數(shù)。
Sigmoid型激活函數(shù)的優(yōu)點是神經(jīng)元輸出可以直接看作概率分布,神經(jīng)網(wǎng)絡(luò)可以更好地和統(tǒng)計學(xué)習(xí)模型相結(jié)合,并且它將不同尺度的特征擠壓到一個受限空間[20],適應(yīng)于特征相差較復(fù)雜的場景,本文采用Sigmoid作為激活函數(shù)。
1.3 殘差連接
殘差連接是DRN的核心部分。殘差結(jié)構(gòu)如圖3 所示,DRN在卷積神經(jīng)網(wǎng)絡(luò)(CNN)的基礎(chǔ)上通過卷積層之間的殘差連接實現(xiàn)多層網(wǎng)絡(luò)的直接輸出,避免了卷積神經(jīng)網(wǎng)絡(luò)的梯度消失問題。
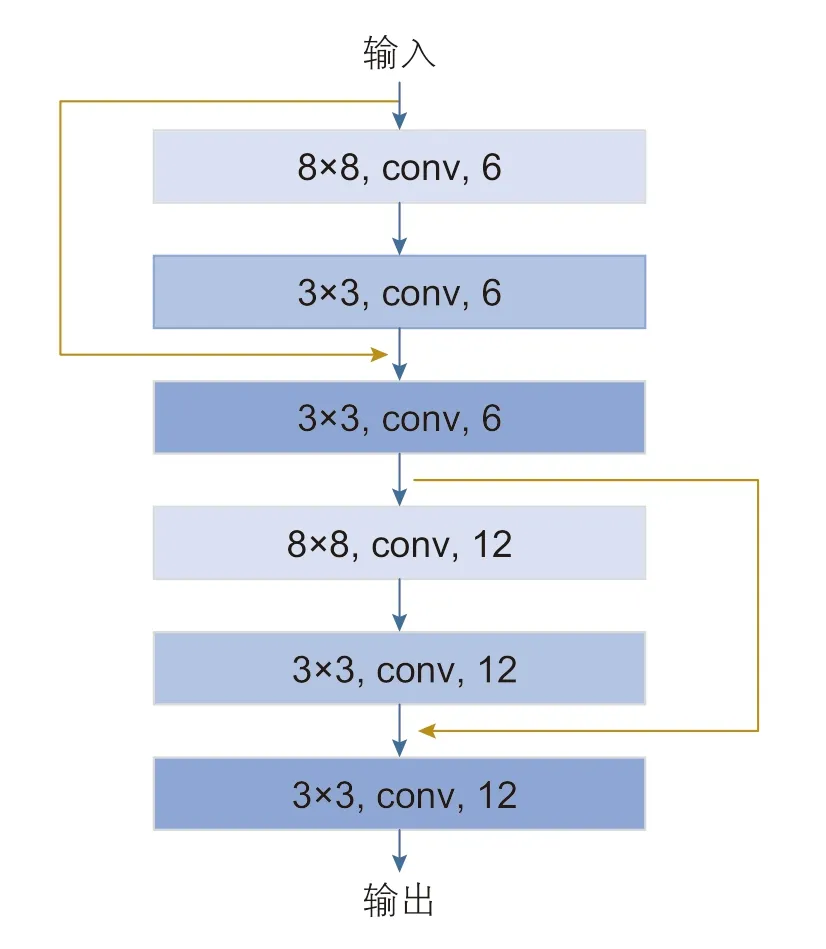
圖3 殘差結(jié)構(gòu)示意圖Fig. 3 Diagram of residual structure
假設(shè)多個殘差塊堆疊,則從第i個殘差塊到第j個殘差塊的信息向前傳遞如下式[17]:
在誤差反向傳播過程中,網(wǎng)絡(luò)優(yōu)化的梯度見下式[18]:
式中,L為損失函數(shù),項保證了底層網(wǎng)絡(luò)都能接收到這個梯度,緩解訓(xùn)練困難問題。
1.4 全局平均池化層
GAP層(Global Average Pooling)對最后一層卷積的特征圖進行平均池化操作。如圖4,當(dāng)有K個特征圖時,池化結(jié)果為K個1×1 的特征圖,這些特征圖直接輸入Softmax層后產(chǎn)生K個類別的置信度,起到取代傳統(tǒng)全連接層的效果[22]。
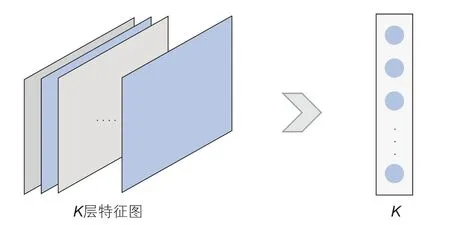
圖4 GAP示意圖Fig. 4 Schematic diagram of GAP
全局平均池化層能夠簡化模型訓(xùn)練參數(shù),避免傳統(tǒng)全連接層過擬合風(fēng)險,提高模型泛化能力。
1.5 批量歸一化層
批量歸一化(BN)層對模型上一層進行歸一化操作,通過特征映射將輸出數(shù)據(jù)轉(zhuǎn)化為具有相同尺度的標(biāo)準(zhǔn)正態(tài)分布,保證樣本特征在同一量綱范圍,緩解模型內(nèi)部協(xié)方差偏移問題[20],可表示為
式中,第l層的經(jīng)過BN操作后的輸入為BN(z(l)),a(l)為神經(jīng)元的輸出,f()為激活函數(shù)。BN(z(l))為凈輸入z(l)的標(biāo)準(zhǔn)正態(tài)分布。
2 接轉(zhuǎn)站工藝流程數(shù)據(jù)集
2.1 接轉(zhuǎn)站工藝流程
某油田轉(zhuǎn)接站位于甘肅區(qū)塊,于2015年建成投運,設(shè)計年處理原油20×104t。主要功能包括原油加熱、油氣分離、原油脫水、凈化油外輸、污水處理及回注等。接轉(zhuǎn)站接收上游5 個輸油點來流,來流通過加熱爐加熱后分別進入溢流沉降罐和三相分離器進行分離。分離油經(jīng)加壓、加熱達到外輸壓力溫度要求,過濾計量后輸往下站。沉降罐和三相分離器的分離水輸往水處理模塊。各設(shè)備分離出的氣體與井場采出氣經(jīng)過氣液分離后作為燃料輸往加熱爐,剩余氣體通過火炬燃燒。
2.2 數(shù)據(jù)集
由接轉(zhuǎn)站自動化監(jiān)控終端采集原始參數(shù),調(diào)取2020年7月至10月的2001 組數(shù)據(jù),整套流程共采集到36 個參數(shù),采集間隔1 h。去除采集異常后形成有5 種工況的36×1800 組數(shù)據(jù)。所有工況如表1 所示。

表1 接轉(zhuǎn)站流程工況列表Table 1 List of operation conditions for block process
接轉(zhuǎn)站流程的36 個監(jiān)測變量如表2 所示。
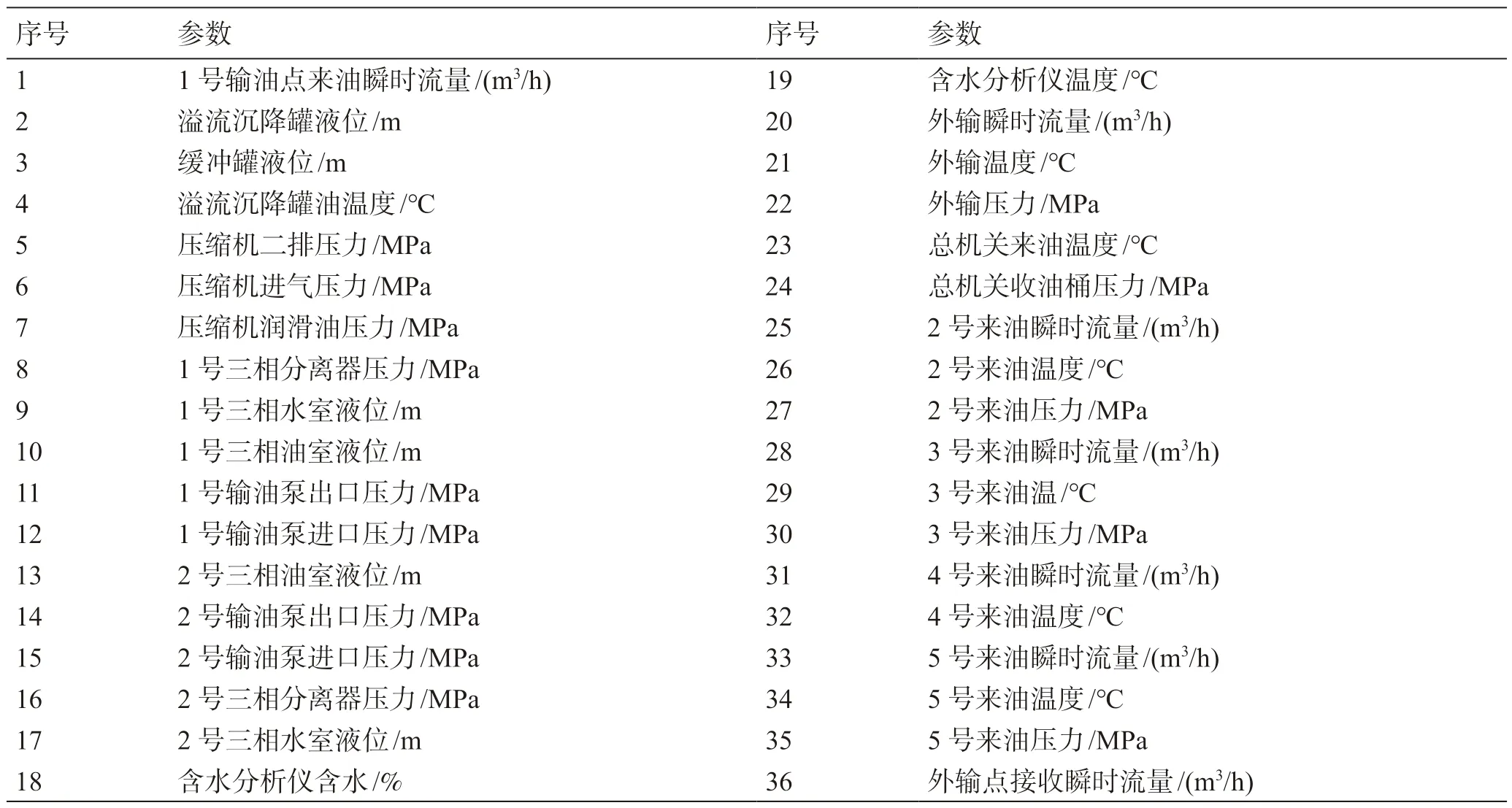
表2 接轉(zhuǎn)站流程監(jiān)測參數(shù)Table 2 Block station process monitoring parameters
3 基于DRN 的接轉(zhuǎn)站工藝流程異常工況診斷
基于深度殘差網(wǎng)絡(luò)的接轉(zhuǎn)站流程異常工況診斷流程如圖5 所示,具體步驟如下:

圖5 接轉(zhuǎn)站異常工況診斷流程Fig. 5 Abnormal operation condition diagnosis process of block station
(1) 數(shù)據(jù)降噪:對原始數(shù)據(jù)進行逐維離散小波降噪。
(2) 入模前處理:重采樣擴容數(shù)據(jù)集形成時間序列樣本,通過正則化手段均衡數(shù)據(jù)分布,劃分訓(xùn)練集和驗證集。
(3) 入模診斷:建立基于DRN的接轉(zhuǎn)站流程診斷模型,根據(jù)診斷評價指標(biāo)進行模型優(yōu)化,得出最優(yōu)模型。
3.1 數(shù)據(jù)降噪
由于現(xiàn)場信號采集器性能不穩(wěn)定或工況波動,SCADA數(shù)據(jù)往往存在強噪聲。數(shù)據(jù)噪聲會掩蓋監(jiān)測變量的真實波動,降低模型對少數(shù)類樣本的識別能力,模型存在同時學(xué)習(xí)噪聲和少數(shù)類的風(fēng)險[23]。由此,需要對數(shù)據(jù)進行降噪處理,減弱采集干擾,增強模型診斷性能。
常用去噪方法有高斯濾波、中值濾波、傅里葉變換等,但它們不能區(qū)分有效信號的高頻部分和噪聲引起的高頻干擾。小波變換的時頻局部化特性能夠保留信號尖峰和信號突變,將高頻信息和高頻噪聲區(qū)分開來并抑制高頻噪聲的干擾[24],適于轉(zhuǎn)油流程的數(shù)據(jù)降噪。
小波變換的時頻局部化特性可以線性表示如下式[25]:
Wx表示含噪混合信號,Wf代表純凈信號,We表示噪聲信號。
采用一維小波離散去噪(DTW1),得到細節(jié)分量(高頻)與近似分量(低頻),對細節(jié)分量進行閾值處理,用處理后的各分量進行小波重構(gòu),得到去噪后的信號。降噪處理前后數(shù)據(jù)變化如圖6 所示。

圖6 降噪處理前后數(shù)據(jù)Fig. 6 Data before and after noise reduction
圖7 表示同一網(wǎng)絡(luò)架構(gòu)下數(shù)據(jù)降噪對診斷準(zhǔn)確率和模型損失的影響。未降噪數(shù)據(jù)在訓(xùn)練時,隨著疊代次數(shù)增加,噪聲特征被模型學(xué)習(xí)并不斷擴大,模型準(zhǔn)確率出現(xiàn)劇烈擾動,并出現(xiàn)過擬合現(xiàn)象。數(shù)據(jù)降噪后模型準(zhǔn)確率提升2.1%,損失下降0.03,過擬合得到糾正,穩(wěn)定性大幅提升。

圖7 降噪對模型準(zhǔn)確率、損失的影響Fig. 7 Influence of noise reduction on model accuracy and loss
3.2 重采樣與正則化
接轉(zhuǎn)站工藝流程的數(shù)據(jù)采集間隔為1 小時,設(shè)定1 個樣本包含10 個數(shù)據(jù)點,共形成180 個樣本。但樣本量少易導(dǎo)致模型訓(xùn)練不足,由此本研究采用樸素重采樣方法,樸素重采樣以一定的采樣間隔在時間序列上移動,讀取數(shù)據(jù)形成多個樣本。采樣間隔越小則樣本相似度越高,模型越容易出現(xiàn)過擬合現(xiàn)象;采樣間隔越大則樣本擴容幅度越小,對模型訓(xùn)練能力提升有限。經(jīng)實驗確定最佳采樣間隔為3 個時間點,最終形成大小為10×36 的630 個樣本,如圖8 所示。
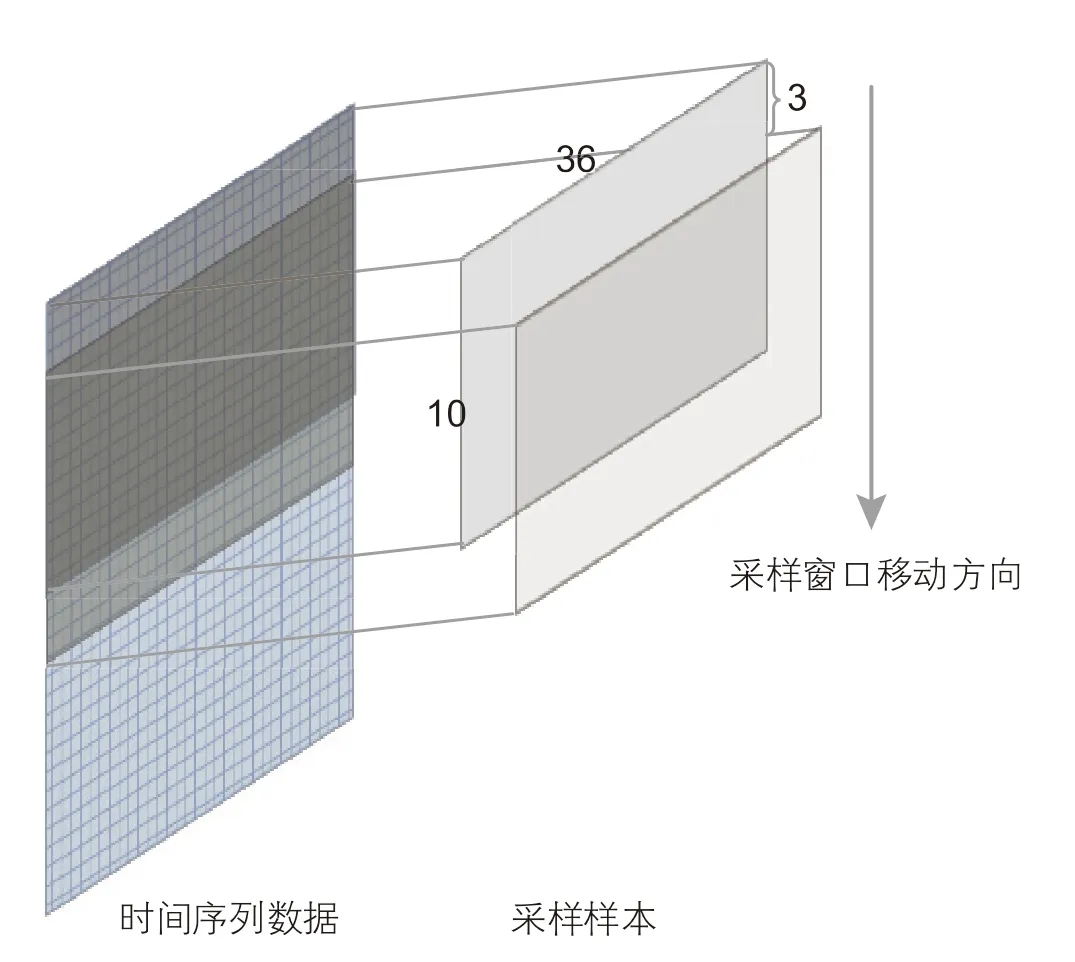
圖8 樸素重采樣原理Fig. 8 The principle of naive resampling
L2 正則化通過對大數(shù)值的權(quán)重向量進行懲罰,使模型傾向于使用所有輸入特征,而不是依賴輸入特征中的小部分特征[20]。L2 正則化可表示為:
其中L()為損失函數(shù),N為訓(xùn)練樣本數(shù)量,f( )為待學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò),θ為參數(shù),e2為L2范數(shù)函數(shù),λ為正則化系數(shù)。
如圖9 所示,對轉(zhuǎn)油流程數(shù)據(jù)集,36 維數(shù)據(jù)單位、幅值均不一致,L2 正則化通過權(quán)重懲罰,能夠有效均衡數(shù)據(jù)分布,避免模型對個別維度的依賴,增強模型特征利用率,提高模型泛化能力,降低過擬合風(fēng)險。

圖9 正則化對模型準(zhǔn)確率的影響Fig. 9 Influence of regularization on model accuracy
重采樣與正則化后以7:3 的比例將數(shù)據(jù)集劃分為訓(xùn)練集和驗證集,訓(xùn)練集用于模型學(xué)習(xí),驗證集用于驗證模型診斷性能。訓(xùn)練集、驗證集樣本數(shù)分別為441、189。
3.3 DRN診斷模型
為探索適宜接轉(zhuǎn)站流程特點的診斷模型,設(shè)計8種DRN模型架構(gòu),見表3,調(diào)整參數(shù)包括卷積層層數(shù)、卷積核數(shù)量、激活函數(shù)類型、分類層類型,以訓(xùn)練集數(shù)據(jù)對模型進行訓(xùn)練。
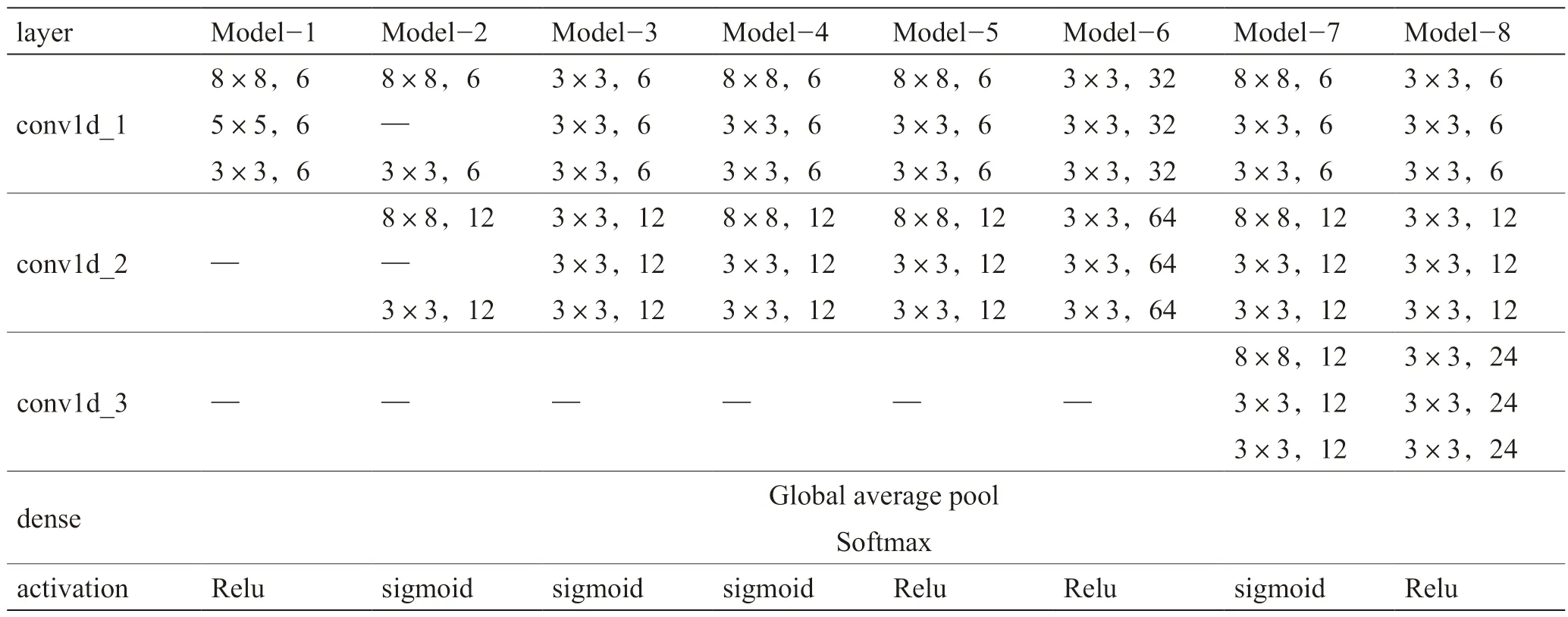
表3 DRN診斷模型Table 3 DRN diagnosed model
以模型4 為例進行說明。1 個樣本矩陣的輸入大小為10×36,其中“10”代表樣本時間長度,即系統(tǒng)運行10 h進行1 次診斷;“36”表示過程變量的數(shù)量,對應(yīng)為轉(zhuǎn)油流程的36 個監(jiān)測變量。模型4 的網(wǎng)絡(luò)架構(gòu)為2 個殘差塊,1 個全局平均池化層和1 個全連接層,每個殘差塊包含3 個卷積層,3 個標(biāo)準(zhǔn)化層和1 個殘差連接結(jié)構(gòu)。殘差塊中的卷積層卷積核大小分別為8×8,3×3,3×3,步幅設(shè)為1;第1 個殘差塊中的卷積層包含6 個過濾器,第2 個包含12 個過濾器。通過全局平均池化層輸出大小為1×12 的樣本,使用“Softmax”的全連接層將輸出轉(zhuǎn)化為1×5向量。
Softmax函數(shù)即歸一化指數(shù)函數(shù),能將任意K維向量Z轉(zhuǎn)換為0 至1 范圍內(nèi)的實數(shù),K維向量σ(Z)總和為1[21],Softmax函數(shù)定義見下式。
Softmax函數(shù)使模型輸出一個長度為5 的向量,其每個值代表對應(yīng)類別的可能性,其中可能性最高的值即為診斷結(jié)果。
3.4 診斷結(jié)果分析
完成DRN模型構(gòu)建后,在以下開發(fā)環(huán)境中實現(xiàn)診斷過程:Windows10 操作系統(tǒng),軟件平臺Python 3.6。硬件開發(fā)環(huán)境為:PC機一臺,Intel(R)Core(TM)I7-6700HQ-CPU- 2.60GHz,8G的DDR3 內(nèi)存、英偉達NVIDIA-GeForce-GTX-960M顯卡。
用準(zhǔn)確率(ACC)、精確率(PRE)和敏感性(TPR)3個指標(biāo)來評價模型診斷性能。表4 為定義的總體工況混淆矩陣。

表4 工況的混淆矩陣Table 4 Confusion matrix of working conditions
準(zhǔn)確率(ACC)評估模型的全局準(zhǔn)確程度;精確率(PPV)表示模型對異常數(shù)據(jù)識別的準(zhǔn)確程度;敏感性(TPR)表示模型對異常數(shù)據(jù)的敏感程度,敏感性越高,漏診概率越低。ACC、PPV和TPR可定義為:
每次診斷導(dǎo)入一個樣本矩陣,每個樣本矩陣包含從時刻t-1 到時刻t的36 個變量的時間序列數(shù)據(jù),以診斷t時刻的轉(zhuǎn)油流程的運行狀態(tài)。
表5 中列出了表4 中各模型的驗證集總準(zhǔn)確率、敏感性和精確率。模型4 具有最高的驗證集總準(zhǔn)確率和敏感性,為最佳模型。模型4 的完整網(wǎng)絡(luò)參數(shù)如表6 所示,網(wǎng)絡(luò)結(jié)構(gòu)如圖10 所示。

表5 測試集診斷結(jié)果Table 5 Diagnostic result on testing set
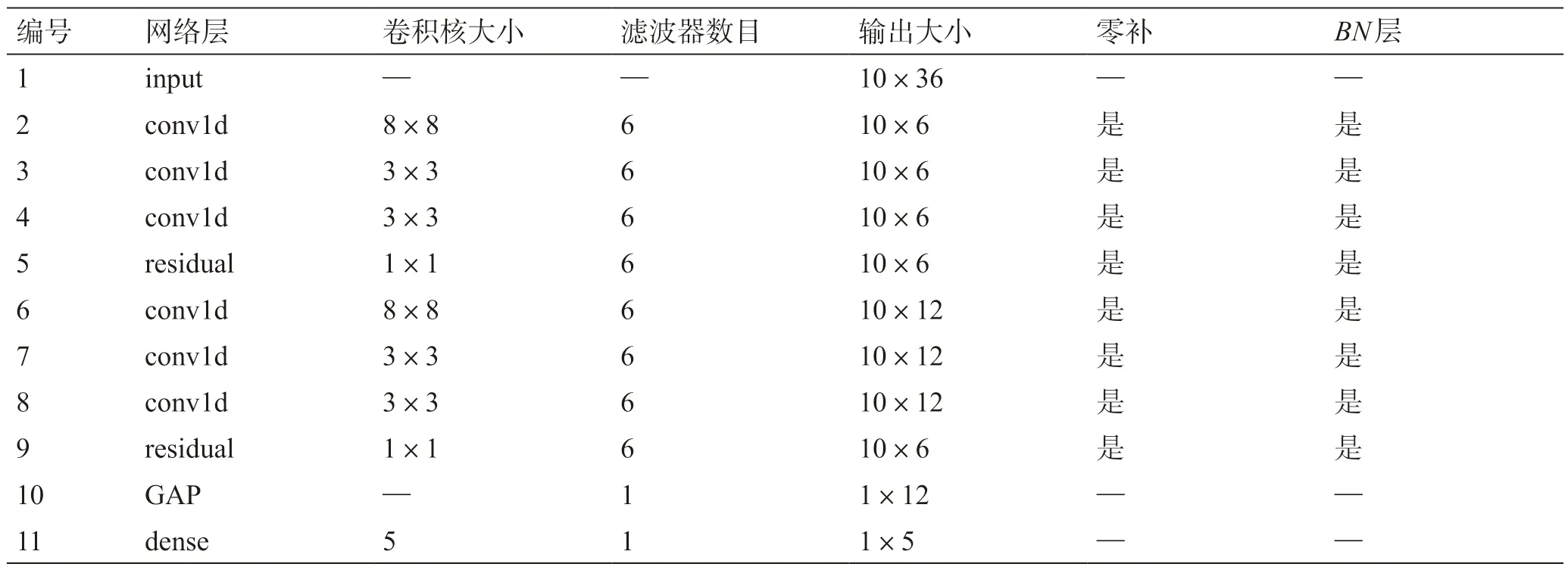
表6 模型4 完整架構(gòu)參數(shù)(輸入大小為一個樣本矩陣)Table 6 Model 4 complete architecture parameters (input size is a sample matrix)

圖10 模型4 結(jié)構(gòu)示意圖Fig. 10 Model 4 structure diagram
圖11 為模型4 訓(xùn)練和驗證階段的準(zhǔn)確率曲線及損失曲線。在441 個訓(xùn)練樣本矩陣中,訓(xùn)練數(shù)據(jù)集的準(zhǔn)確率為97.50%,模型損失為0.113。對于包含189 個樣本矩陣的驗證數(shù)據(jù)集,模型準(zhǔn)確率為97.35%,模型損失為0.139。

圖11 模型損失和準(zhǔn)確率圖Fig. 11 Model loss and accuracy diagrams
所有5 類工況的診斷結(jié)果混淆矩陣如圖12 所示。5 類工況分別取得了99.2%、100%、85.7%、100%、92.3%的精確率。其中,第3 類工況的診斷精度最低,在14 個測試樣本中2 個樣本被劃分為第1 類工況;第5 類工況的13 個測試樣本中1 個樣本被劃分為第1 類工況。
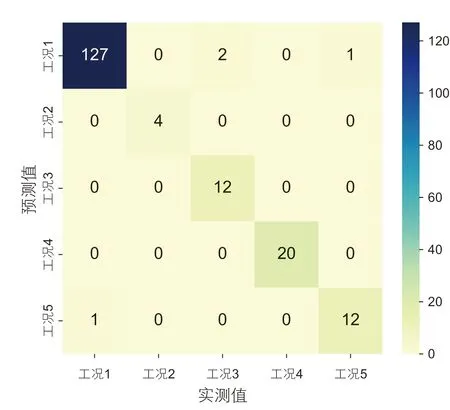
圖12 驗證集診斷結(jié)果混淆矩陣圖Fig. 12 confusion matrix of test diagnostic result
3.5 工況相關(guān)性分析
多元互信息值可以反映兩個矩陣之間共享信息量的大小,定義如下[26]:
其中,Y是有k個可能值的多項式隨機變量,P(y)是它對應(yīng)值的概率分布,X是一個多元隨機變量。在Y=y條件下,X遵循參數(shù)為μy和∑c的多元正態(tài)密度分布。
為量化接轉(zhuǎn)站各工況間的相關(guān)性大小[27],計算工況間的多元互信息值,如圖13 所示。工況1 與工況3及工況5 的相關(guān)程度最低,證明其在網(wǎng)絡(luò)診斷過程中最易發(fā)生誤診。工況2 與其他工況間的相關(guān)程度最高,證明其在網(wǎng)絡(luò)診斷過程中最易于識別,這驗證了上述DRN的診斷結(jié)果。同時,模型對樣本量最少的工況2達到了100%的準(zhǔn)確率,證明本模型有效避免了各類樣本的不均衡性限制。

圖13 各工況間的多元互信息值Fig. 13 Mutual information values among different conditions of samples
3.6 與其他模型的對比
為驗證所提出模型在接轉(zhuǎn)站的應(yīng)用優(yōu)勢,分別采用支持向量機(SVC)、卷積神經(jīng)網(wǎng)絡(luò)(CNN)、全卷積神經(jīng)網(wǎng)絡(luò)FCN)、多層感知機(MLP)與殘差神經(jīng)網(wǎng)絡(luò)(DRN)進行比較。最終診斷結(jié)果為各模型參數(shù)調(diào)整后的最優(yōu)結(jié)果,診斷結(jié)果見表7。

表7 機器學(xué)習(xí)算法診斷結(jié)果對比Table 7 Comparison of diagnostic results of machine learning algorithms
與淺層模型SVC及MLP相比,所提出的DRN模型的總精確率有顯著提升,表明模型能夠有效學(xué)習(xí)小樣本工況的特征;與深度模型CNN及FCN相比,所提出的DRN模型在測試集中未出現(xiàn)過擬合現(xiàn)象,表明模型泛化能力較強。
4 結(jié)論
(1)針對接轉(zhuǎn)站數(shù)據(jù)噪聲強、干擾大、數(shù)據(jù)量小的問題,采用小波方法進行降噪,根據(jù)重采樣方法進行樣本擴容,通過正則化手段均衡各維數(shù)據(jù)分布,有效提升了模型準(zhǔn)確率和泛化能力。
(2)提出8 種不同的DRN架構(gòu),以測試集ACC、PRE與TPR作為評價指標(biāo),確定適用于接轉(zhuǎn)站流程的最佳DRN診斷模型,實現(xiàn)對異常工況97.35%的診斷精度,證明了診斷模型的準(zhǔn)確性。
(3)通過基于多元互信息值的相關(guān)性分析方法,量化5 類樣本間的相關(guān)程度,表明互信息值的大小能夠反映診斷難易程度,證明了診斷結(jié)果的可靠性。
(4)與經(jīng)典機器學(xué)習(xí)模型SVC、CNN、FCN及MLP對比,DRN模型精確率分別提升4%、17%、10%、32%,表明模型能夠?qū)π颖竟r的特征進行有效學(xué)習(xí),診斷模型的泛化性顯著提升,該方法對其他油氣站場的異常診斷具有一定意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
