基于改進DeepLabV3+算法的高分影像地物分割研究
2024-01-10 08:30:30龍北平劉錕銘占小芳李恒凱
江西科學(xué) 2023年6期
龍北平,劉錕銘,占小芳,李恒凱
(1.江西省地質(zhì)局地理信息工程大隊,330001, 南昌; 2.江西理工大學(xué),341000, 江西,贛州)
0 引言
隨著遙感技術(shù)的進步及設(shè)備的更新,通過無人機獲取遙感影像成為一個主流趨勢,且通過無人機影像實現(xiàn)分類的方法在農(nóng)業(yè)、林業(yè)、環(huán)境監(jiān)測、城市規(guī)劃、災(zāi)害響應(yīng)等領(lǐng)域中得到廣泛應(yīng)用。無人機以其靈活性高、操作簡便等優(yōu)勢,可獲取具有豐富空間和光譜信息的遙感影像,為地物分類提供更準確的特征。無人機所獲取的高分辨率遙感影像使得目標對象的幾何、紋理和光譜特征等更加明顯,從而為目標對象信息的提取與分類提供了大量的新特點[1]。早期的遙感圖像的分割主要為基于邊緣監(jiān)測[2]和影像特征[3]的分割方法。然而,新特征增加的同時也伴隨著干擾和冗余信息的增加,這導(dǎo)致傳統(tǒng)的遙感信息提取方法已不足以滿足實際需求。為此需要一種全新的手段,對高分辨率遙感影像的信息進行高精度提取與分類。
當前,計算機與數(shù)據(jù)資源的高度結(jié)合,為深度學(xué)習技術(shù)的發(fā)展起到了強力的推動作用,使得深度學(xué)習成為當下熱門的研究領(lǐng)域[4]。深度學(xué)習方法不僅能夠深入挖掘地物的深層次特征信息,還為高分辨率遙感影像地物的分類提供了新的思路[5]。雖然牛全福等[6]的研究證明傳統(tǒng)的隨機森林方法對耕地、林地、草地和灌木具有較好的可分性。但面對海量的遙感數(shù)據(jù),深度學(xué)習方法似乎是更佳的選擇,因此越來越多的學(xué)者將深度學(xué)習方法應(yīng)用于遙感影像的圖像分類、地物類型的識別和地物信息的提取等領(lǐng)域[7]。徐麗坤等[8]通過大量實驗優(yōu)化了深度信念網(wǎng)絡(luò)模型的網(wǎng)絡(luò)層數(shù)、神經(jīng)元個數(shù)和迭代輪次等參數(shù),構(gòu)建出最優(yōu)深度信念網(wǎng)絡(luò),并將該模型與傳統(tǒng)的淺層網(wǎng)絡(luò)分類器進行對比,證明了該方法在高分辨率遙感影像的分類研究中具有較高的分類精度。朱袁杰等[9]利用卷積神經(jīng)網(wǎng)絡(luò)(CNN)能夠根據(jù)特定場景語義來分析訓(xùn)練影像的優(yōu)勢,對南京市建鄴區(qū)城市綠地用地進行分類,結(jié)果表明,該模型的分類準確度高達87.74%。然而,隨著大量數(shù)據(jù)的堆疊,影像特征信息的豐富,這些經(jīng)典的深度學(xué)習模型在地物分類的精度上再有所提升是相對較難的。
近年來,DeepLabv3+語義分割網(wǎng)絡(luò)逐漸出現(xiàn)在大眾視野[10]。DeepLabv3+模型是DeepLabV1模型不斷改進優(yōu)化得到的,最初的DeepLab V1是于2014年提出的第一個版本,采用了全卷積網(wǎng)絡(luò)(Fully Convolutional Network)的思想來進行語義分割。該模型使用了空洞卷積(Atrous Convolution)來增大感受野,并引入了條件隨機場(Conditional Random Field)進行細化。隨后的DeepLabV2則是在其基礎(chǔ)上引入了空洞空間金字塔池化(ASPP)模塊,用于捕捉不同尺度下的上下文信息。ASPP模塊通過多尺度空洞卷積和金字塔池化的結(jié)合,提高了分割模型對多尺度物體的理解能力。DeepLabV3則是為了進一步提升模型的收斂性和穩(wěn)定性引入了殘差連接和批歸一化技術(shù),同時使用了更為強大的主干網(wǎng)絡(luò)。在2018年所提出的DeepLabv3+引入了空洞可分離卷積(Depthwise Separable Convolution)來減少參數(shù)量和計算量,并采用了更大的感受野和更密集的特征金字塔,使其能夠處理更為復(fù)雜的遙感影像,極大提升影像的分類精度[11]。同時,其具有清晰的網(wǎng)絡(luò)結(jié)構(gòu)和能夠捕獲多尺度信息的優(yōu)點,在遙感影像信息解譯提取方面得以廣泛應(yīng)用。文獻[12]利用DeepLabv3+模型對復(fù)雜分辨率影像中養(yǎng)殖用海信息進行提取并分類,并將分類結(jié)果與傳統(tǒng)的機器學(xué)習分類結(jié)果進行對比,證明了DeepLapv3+的準確性和有效性。文獻[13]利用DeepLapv3+提取高分辨率遙感影像的典型要素,實現(xiàn)了對分割信息邊界的優(yōu)化,結(jié)合形態(tài)學(xué)濾波處理,要素邊界輪廓明顯優(yōu)于初始分割結(jié)果。文獻[14]基于DeepLapv3+模型,從樣本數(shù)據(jù)平衡的角度出發(fā),調(diào)整權(quán)重系數(shù),使DeepLabV3+模型對于遙感影像中建筑垃圾的分割mIoU達到82%。
上述文獻研究表明,基礎(chǔ)的DeepLapv3+網(wǎng)絡(luò)在很多領(lǐng)域均能取得顯著成效,可應(yīng)用于高分辨率遙感影像地物分類研究中。但基礎(chǔ)的DeepLabv3+網(wǎng)絡(luò)依舊存在缺陷,如訓(xùn)練速度慢、邊緣目標分割精度低等問題。針對上述問題,本文以尋烏縣作為研究區(qū)域,提出一種引入雙注意力機制的DeepLabv3+網(wǎng)絡(luò)模型,以期彌補DeepLabv3+算法缺陷,為高分辨率遙感影像的地物分類提供方法借鑒。
1 研究區(qū)和數(shù)據(jù)
1.1 研究區(qū)域概況
尋烏縣(115°21′22″~115°54′25″E,24°30′40″~25°12′10″N)位于江西省贛州市東南邊境(圖1),處于廣東、福建、江西三省交匯地界,該縣總面積約為2 300 km2,屬亞熱帶季風氣候,雨量充足,氣候溫和,是典型的丘陵山區(qū)農(nóng)業(yè)縣。

圖1 研究區(qū)地理位置及部分無人機影像
1.2 研究數(shù)據(jù)
本研究所使用的數(shù)據(jù)來自于實地采集的高分辨率無人機遙感影像,包括有分布在尋烏縣內(nèi)的12景影像。影像有紅、綠、藍三個波段,空間分辨率均為0.5 m,每張影像的大小均在10 000像素×10 000像素以上。將所采集到的無人機影像進行影像校正、去噪及影像增強等預(yù)處理后,得到無人機正射影像。由于受到計算機GPU內(nèi)存限制,需要對原始影像進行裁剪,通過調(diào)用GDAL庫,將其批量裁剪為大小為256像素×256像素的影像,再通過目視解譯的方法在影像上標繪出不同的地物類型作為樣本標簽,構(gòu)成地物類型數(shù)據(jù)集。最終,按照4:1的占比將數(shù)據(jù)集分為訓(xùn)練集與測試集。
2 研究方法
2.1 方法
2.1.1 改進的DeepLabv3+網(wǎng)絡(luò) 經(jīng)典的DeepLabv3+網(wǎng)絡(luò)于2018年[15]提出,該算法在原有的DeepLabv3網(wǎng)絡(luò)上加以完善,添加了編碼-解碼結(jié)構(gòu),使之成為了現(xiàn)階段DeepLab網(wǎng)絡(luò)系列中最優(yōu)秀的網(wǎng)絡(luò)。
首先,原始的Deeplabv3+網(wǎng)絡(luò)的編碼器部分采用Xception網(wǎng)絡(luò)結(jié)構(gòu)[16]來提取特征獲得高層特征,然后將高層特征輸入到ASPP(Atrous Spatial Pyramid Pooling,空洞空間金字塔池化)模塊中,進行影像特征提取,獲得多尺度信息。其中ASPP模塊主要有5個并行分支組成,特征圖輸入后將經(jīng)過1x1卷積,擴張率為6、12、18的3x3卷積和全局平均池化操作,最后對特征融合后的特征圖進行1x1卷積以降低通道密度。最終,通過ASPP能夠識別不同尺度的目標特征信息,有效地分割多尺度目標。解碼器部分主要是將高、低層特征相融合,將編碼器提取的高層特征經(jīng)過4倍上采樣至低層分辨率,將低層特征通過1x1卷積將通道數(shù)降到48,后將上采樣后的高層特征與低層特征融合,再經(jīng)過3x3卷積進一步提取細化后的特征,最后通過上采樣恢復(fù)至輸入圖像大小,輸出模型的最終預(yù)測結(jié)果。
而本研究中將特征提取網(wǎng)絡(luò)更換成更為輕量化的MobilenetV2,來減少模型的參數(shù)量和計算量,從而降低計算機GPU的壓力。MobileNetV2引入了一種新的網(wǎng)絡(luò)結(jié)構(gòu),稱為倒殘差塊(Inverted Residual Block)。這種塊結(jié)構(gòu)能夠在保持模型輕量級的同時提高網(wǎng)絡(luò)的表達能力和學(xué)習能力,通過使用1x1卷積進行特征維度擴展和降維,然后使用3x3的深度可分離卷積進行特征提取。并且,MobileNetV2結(jié)合了多尺度特征表示的方法,通過引入多個不同大小的倒殘差塊和特征融合技術(shù),使網(wǎng)絡(luò)能夠同時處理不同尺度的特征,從而提高對多尺度目標的檢測和分類能力。
同時,本文在原始Deeplabv3+的網(wǎng)絡(luò)結(jié)構(gòu)基礎(chǔ)上進行優(yōu)化,在網(wǎng)絡(luò)的高層次語義特征提取模塊中加入通道注意力機制,對低層次的語義特征加入空間注意力機制,優(yōu)化后的網(wǎng)絡(luò)結(jié)構(gòu)如圖2所示。

圖2 改進Deeplabv3+網(wǎng)絡(luò)結(jié)構(gòu)
2.1.2 通道注意力機制 通道注意力機制通過利用特征的通道間關(guān)系來產(chǎn)生通道注意力圖。因為特征圖的每個通道都被視為特征檢測器,所以通道注意力注重輸入圖像是否有意義。為了更好地計算通道注意力,對輸入特征圖的空間維度進行壓縮。同時,常用平均池化來聚合空間信息,但最大池化在收集特殊特征時能得到更好的效果[17]。所以,本文同時使用了平均池化和最大池化。通道注意力模塊如圖3所示。

圖3 通道注意力機制
特征圖分別進行2種池化操作后,得到2個相應(yīng)且不一樣的空間特征描述符,然后將它們分別傳遞到共享網(wǎng)絡(luò),最后,對每個特征求和并輸出特征向量。其過程可用式(1)表示[18]:

(1)
式中,x表示輸入信息,W1和W0分別表示共享網(wǎng)絡(luò)的權(quán)重系數(shù),?表示像素分別進行乘積。
2.1.3 空間注意力機制 空間注意力與通道注意力不同,空間注意力更注重輸入圖像哪里是有意義的地方,與通道注意力相互補充。為了計算空間注意力,沿著通道軸進行池化操作,即每次池化時對比的是不同通道間的數(shù)值,而非同一通道不同區(qū)域的數(shù)值。最后進行組合形成有效的特征描述符。空間注意力模塊如圖4所示。

圖4 空間注意力機制
2.2 模型參數(shù)構(gòu)建及模型評價指標
2.2.1 模型參數(shù)構(gòu)建 根據(jù)本文提出的引入雙注意力機制的V3+MobilenetV2混合網(wǎng)絡(luò)模型對獲取到的尋烏縣無人機高分辨率RGB影像進行訓(xùn)練與優(yōu)化。該模型基于TensorFlow深度學(xué)習框架,網(wǎng)絡(luò)模型的具體參數(shù)設(shè)置如下:首先,學(xué)習率作為網(wǎng)絡(luò)模型重要超參數(shù),在模型訓(xùn)練過程中,學(xué)習率的不同跳動范圍會使得網(wǎng)絡(luò)模型產(chǎn)生過擬合或欠擬合等狀況發(fā)生,為解決這一問題,研究將初始學(xué)習率設(shè)置為0.005,并采用CosineAnnealing(余弦退火)學(xué)習率衰減機制讓學(xué)習率在模型訓(xùn)練過程當中不斷降低,從而加速模型收斂,防止出現(xiàn)過擬合等現(xiàn)象。其次,為降低梯度系數(shù)或梯度存在較大噪聲問題,使用Adam優(yōu)化器,同時將參數(shù)momentum設(shè)置為0.9。最后,使用Focal Loss作為損失函數(shù),用于平衡正負樣本。
2.2.2 輕量級特征提取網(wǎng)絡(luò)與深層次特征提取網(wǎng)絡(luò)對比 本研究以DeeplabV3+模型基礎(chǔ),分別設(shè)計L-DeeplabV3+(Lightweight DeeplabV3+ model,輕量級DeeplabV3+模型)以及D-DeeplabV3+(Deep DeeplabV3+ model,深層次DeeplabV3+模型)進行對比試驗,分別以輕量級網(wǎng)絡(luò)MobilenetV2、深層次網(wǎng)絡(luò)Resnet50作為模型的主干特征提取網(wǎng)絡(luò)進行模型的訓(xùn)練。
2.2.3 雙注意力機制對模型優(yōu)化的有效性驗證 為驗證雙注意力機制對輕量級網(wǎng)絡(luò)模型優(yōu)化的有效性,本研究設(shè)計的DAD-DeeplabV3+(Dual attention mechanism Deep deeplabV3+ network model,雙注意力機制深層次deeplabV3+網(wǎng)絡(luò)模型),以及DAL-DeeplabV3+(Dual attention mechanism lightweight deeplabV3+ network model,雙注意力機制輕量級deeplabV3+網(wǎng)絡(luò)模型)與L-DeeplabV3+、D-DeeplabV3+進行對比試驗。
2.2.4 模型評價指標 對于一個隨機樣本,其模型預(yù)測結(jié)果有以下4種情況:1)真陽性(True Positive,TP),預(yù)測為正樣本,實際也是正樣本;2)假陽性(False Positive,FP),預(yù)測為正樣本,實際為負樣本;3)真陰性(True Negative,TN),預(yù)測為負樣本,實際也是負樣本;4)假陰性(False Negative,FN),預(yù)測為負樣本,實際為正樣本。
交并比IoU是某一類預(yù)測值和真實值的交集和并集之比,像素精度Accuracy為預(yù)測正確樣本數(shù)占總樣本數(shù)的比例,精確率Precision為預(yù)測正確的正樣本數(shù)占預(yù)測為正的樣本數(shù)的比例,召回率Recall為所有的正樣本中被模型成功預(yù)測出來的數(shù)量占的比例。交并比、像素精度、精確度、召回率的計算公式如下:
(2)
(3)
(4)
(5)
本研究以平均交并比mIoU、平均像素精度mPA、平均精確度mPrecision和平均召回率mRecall作為評價指標對模型預(yù)測結(jié)果進行評價,計算公式如下:
(6)
(7)
(8)
(9)
3 結(jié)果與分析
為驗證本文對模型優(yōu)化的有效性,選取尋烏縣域內(nèi)部分無人機遙感影像作為驗證集對模型進行驗證,通過模型的預(yù)測,得到復(fù)墾地、果園、林地、水域、工業(yè)用地、道路、建筑用地及耕地8種地物類別。在相同驗證影像數(shù)據(jù)集內(nèi),通過對輕量級網(wǎng)絡(luò)模型、深層次網(wǎng)絡(luò)模型及加入雙重注意力機制的模型進行對比試驗,所得到的各模型的各項評價指標均值如表1所示。
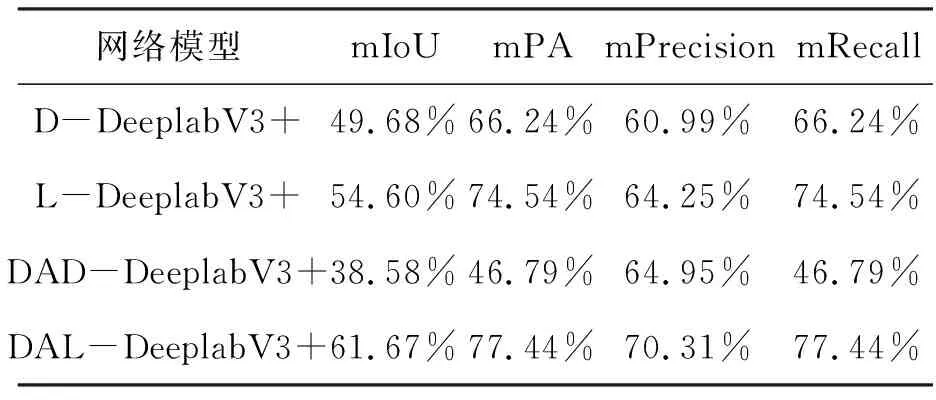
表1 上述各模型評價指標對比
在表1中,輕量化網(wǎng)絡(luò)的表現(xiàn)明顯優(yōu)于深層次網(wǎng)絡(luò),在沒有注意力機制優(yōu)化的模型當中,輕量化網(wǎng)絡(luò)的各項評價指標均值遠高于深層次網(wǎng)絡(luò)模型。且在使用雙重注意力機制對深層次網(wǎng)絡(luò)模型進行優(yōu)化之后,模型的各個評價指標均值不升反降,可見雙重注意力機制對深層次網(wǎng)絡(luò)模型并沒有優(yōu)化效果。但在輕量化網(wǎng)絡(luò)當中加入雙重注意力機制模塊優(yōu)化后,模型的表現(xiàn)顯著提升。
根據(jù)表1所示,本文所提出的DAL-DeeplabV3+模型在各項模型評價指標當中均為最優(yōu)值。相對于效果較好的L-DeeplabV3+而言,DAL-DeeplabV3+模型精度在mIoU、mPA、mPrecision及mRecall4個指標上分別提升了7.07%、2.90%、6.06%、2.90%,全方位地提升了模型的語義分割能力。
表1中的數(shù)據(jù)為模型各項評價指標均值,所反映的是各個模型的整體性能。為反映出模型對于各類地物的分割能力,將模型運用到各類地物的預(yù)測當中,各模型對于地物的分割精度如圖5所示,本文所提出的DAL-DeeplabV3+模型在復(fù)墾地、園地、林地、水體、道路、建筑用地及耕地這6類地物的分割上具有較高精度,分割精度分別為0.83,0.92,0.82,0.90,0.96,0.84,0.72,而對于工業(yè)用地的分割效果與其他各模型都較差,精度都低于0.5。

圖5 模型分割精度
為了更細致準確地表達各模型對不同地物的分割效果,對比分析不同模型下的各地物分類精度(圖6)。研究結(jié)果顯示,本文所提出的DAL_DeeplabV3+模型在地物交界處能夠分割得更精細,林地以及道路等地物類型的分割結(jié)果與標簽的真實值最接近。在第一組的對比影像當中,地物類型較為簡單,只包含未利用地和林地兩類,本文所提出的模型對影像的預(yù)測值與真實值基本相同,而其他模型都與真實值有一定偏差。同樣,在第二組對比影像中,本文所提出的模型對影像的預(yù)測值也是與真實值較接近的,在地物邊界處其他幾個模型預(yù)測出真實值中不存在的地物類型,而本文所提出的模型并沒有。而在第三組的對比影像當中,由于林地與園地的影像特征接近,模型出現(xiàn)了錯分的情況。
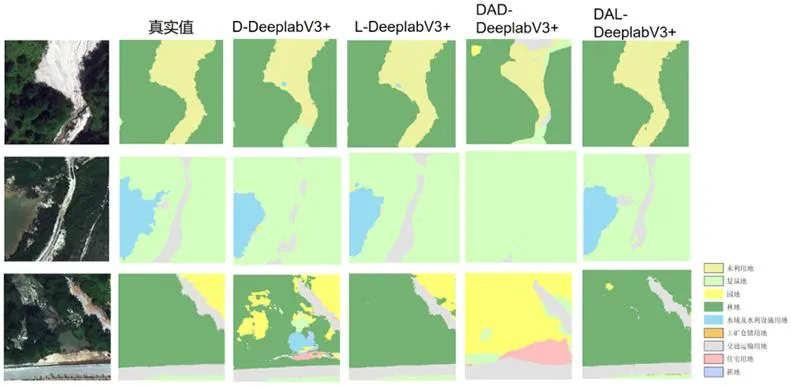
圖6 各模型分類結(jié)果示意圖
總體而言,針對南方山地丘陵地區(qū)的復(fù)雜地物情況,本文所提出的DAL_DeeplabV3+模型對于地物的識別取得較好的效果。在地物分類任務(wù)當中降低了地物錯分的概率,使地物分類更接近地表的真實值,在高分辨率遙感影像地物分類的任務(wù)中能夠較為準確地對地物進行識別、分類。
4 結(jié)論
本研究以DeeplabV3+為基礎(chǔ),針對無人機高分辨率RGB遙感影像,提出加入雙注意力機制的算法:1)在高層次語義特征提取模塊中加入通道注意力機制;2)在低層次語義特征提取模塊中加入位置注意力機制。實驗結(jié)果表明相對于原始算法進行優(yōu)化后的模型在mIoU、mPA、mPrecision以及mRecall4個指標上分別提升了7.07%、2.90%、6.06%、2.90%,有效地提高了高分辨率影像的分類精度。同時,在多個方面提升了深度學(xué)習語義分割模型南方山地丘陵地帶的地物分類精度。
然而,在工業(yè)用地的分類上,各模型的分割精度均不理想。這是由于在尋烏縣域內(nèi)存在較多的礦區(qū)以及各類廠房,工業(yè)用地的地表特征復(fù)雜多樣、模型難以區(qū)分,因此,導(dǎo)致分割精度較低。這也是后期需要對模型進行優(yōu)化的一個方向。從研究結(jié)果也可以看出,模型對于地物類型分割的平均精度不是很高,其原因是應(yīng)為各地物類型之間的分割精度差異較大,多個類型地物的分割精度都在85%以上,少數(shù)類別的地物分割精度較低,從而拉低了整體的精度,其中對于道路的分割精度最高,對于工業(yè)用地的分割精度最低。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
文苑(2018年21期)2018-11-09 01:23:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛(wèi)生(2015年9期)2015-11-10 03:11:12
中國衛(wèi)生(2014年3期)2014-11-12 13:18:12
