計算機編程代碼優劣評價系統的設計與研究
2024-01-12 05:40:56李真成
微型電腦應用 2023年12期
李真成
(天津交通職業學院, 經濟管理學院, 天津 300110)
0 引言
目前,高級語言編程開發平臺中,對高級語言進行預編譯或者試解析,從而發現其語法錯誤并給出報錯,已經成為平臺軟件功能開發的必要技術。文獻[1]提出的技術僅可保障該平臺下開發的高級語言程序段的可用性,對其算法優化過程和持續優化結果并不能提供必要輔助。文獻[2]指出,近年來使用第三方插件對程序代碼做出基于人工智能的算法優化成果評價,成為編程過程服務軟件開發中的重要任務。文獻[3]通過計算機編程技術對計算機編程代碼進行分析,以實現編程工作環境直接對編程代碼質量的深度評價,而非傳統模式下僅對編程代碼的可編譯性進行評價,是當前高級語言計算機輔助編程環境搭建工作的重要技術革新方向[4]。
1 數學算法視角下的計算機編程優化任務分解
以往程序員績效管理中,其代碼質量評價標準為代碼可編譯,可正常運行,導致大部分程序員的代碼質量較差,大部分開發工時用于對代碼漏洞的修補工作,使開發成本激增。大部分程序開發工作面臨“技術綁架”的管理壓力[5]。
傳統模式下,計算機編程優化的評價指標,主要包括以下三個方面。
第一,代碼本身的優化。IT界將計算機代碼本身分為兩種[6]:一種只有編程者本人能看懂,如果間隔時間過長,其本人也很難看懂,這種代碼效率較低,縮進、注釋都較為混亂,但企業無法對該編程者取消合作關系;另一種所有編程者對照技術文檔都能看懂,這種代碼縮進、注釋等都實現了標準化,技術文檔較為清晰,但每個編程者均不存在不可替代性。所以,對程序員來說,降低代碼優化程度,或者說降低代碼質量,可以獲得更穩定的工作,延長開發時間,獲得更高的個人收益。這一利益趨向與開發公司的利益沖突。
第二,資源調用量的優化。不論是個人電腦還是手機、平板電腦等設備,以及各種嵌入設備和工業設備,其自身具有的計算資源有限,在分布式計算、云計算等軟件運行環境下,網絡帶寬資源、內存總線帶寬資源、顯示總線帶寬資源、其他總線帶寬資源等,也被用于資源調用量的考察。經過充分優化的數學算法,可以使用有限的資源調用量實現目標功能。
第三,系統運行效率的優化。高級語言的編程過程基本無須直接操作上述硬件資源,即便在C族語言中有ASM命令可以嵌入宏匯編語句,但大部分高級語言保留字均封裝了大量可編譯信息。優秀的程序員可以充分利用高級語言的循環結構、分支結構等構件算法,有效壓縮程序執行過程的計算次數,使程序完成相同計算任務以及同樣計算機硬件資源支持條件的前提下,程序可以在最短時間完成計算[7]。
綜上,傳統評價模式主要包括表1中的評價指標。
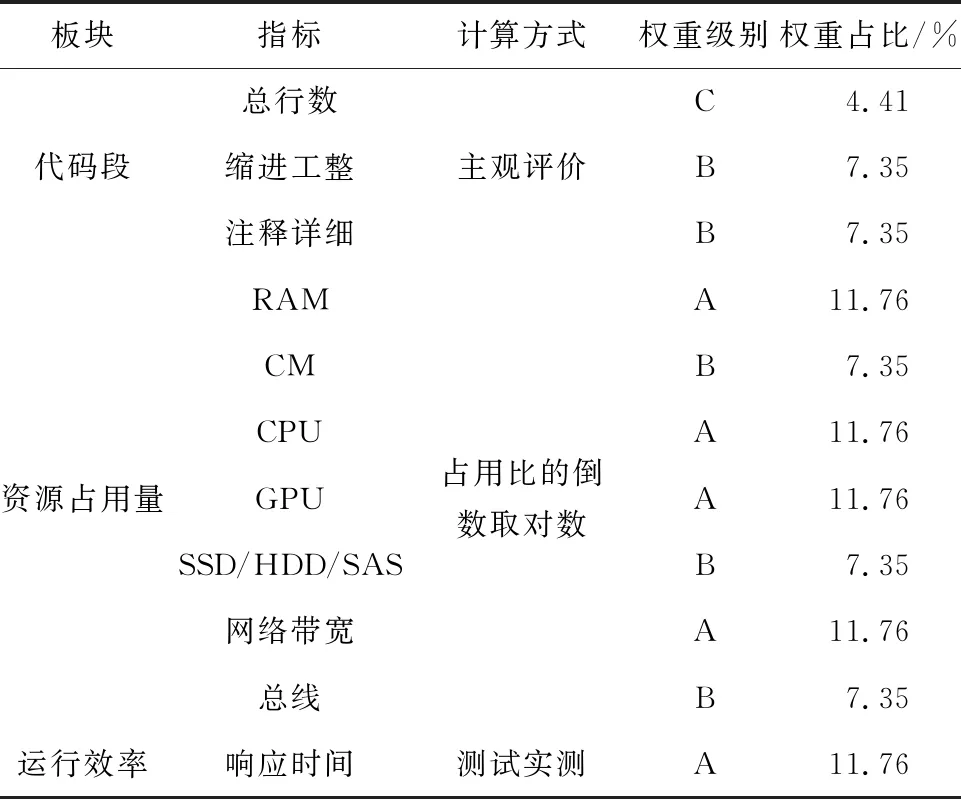
表1 計算機編程優化成果評價因子匯總表
表1中,傳統模式下,對代碼段本身的優化成果無法客觀定義,一般由項目經理、產品經理、測試工程師給出主觀評價,進而對各方意見給出加權平均。但因為在程序開發過程中,代碼段本身的優化過程屬于人事績效管理中沖突最嚴重的部分,所以此處需要利用人工智能給出非主觀評價結果。
2 用于代碼段優化水平整體評價的模糊卷積神經網絡設計
該研究的技術路徑為使用人工智能系統對代碼優劣程度做出包含細節信息的整體評價。其中,人工智能的實現模式為模糊卷積神經網絡。因為該研究設計的評價系統需要對大部分開發場景下的編程代碼做出評價,所以需要構建計算機編程代碼的一般模式并在一般模式下進行數據挖掘分析。
2.1 計算機代碼評價標準的一般模式假設
對于軟件開發工程來說,計算機編程代碼一般分為兩個層次。
其一為面向機器編程的宏匯編語言體系(MASM),當前可用的開發平臺包括IBM公司推出的ASM開發環境、Borland公司推出的C系列開發環境(TC、C++、VC等)、SUN公司推出的JavaBean開發環境[8]。
其二為面向對象的高級語言編程體系,該編程體系包含了運行在C語言編譯架構上的GUI開發體系,解釋型代碼架構上的偽編譯腳本開發體系(B語言架構下的VBS腳本、C語言架構下的C#腳本等),當前開發環境中常用的JSP、PHP腳本代碼,部分服務器端開發任務,也采用了這種偽編譯解釋性代碼體系[9]。
2.2 數據模糊化與數據輸入
程序代碼文本雖然可以結構化為可編譯或可解釋數字化代碼,但其中也包含各種自定義變量名、注釋文本等。所以,程序代碼文本屬于非標準異構數據,應設計數據模糊化算法對代碼段進行逐行分析。其分析流程如圖1所示。
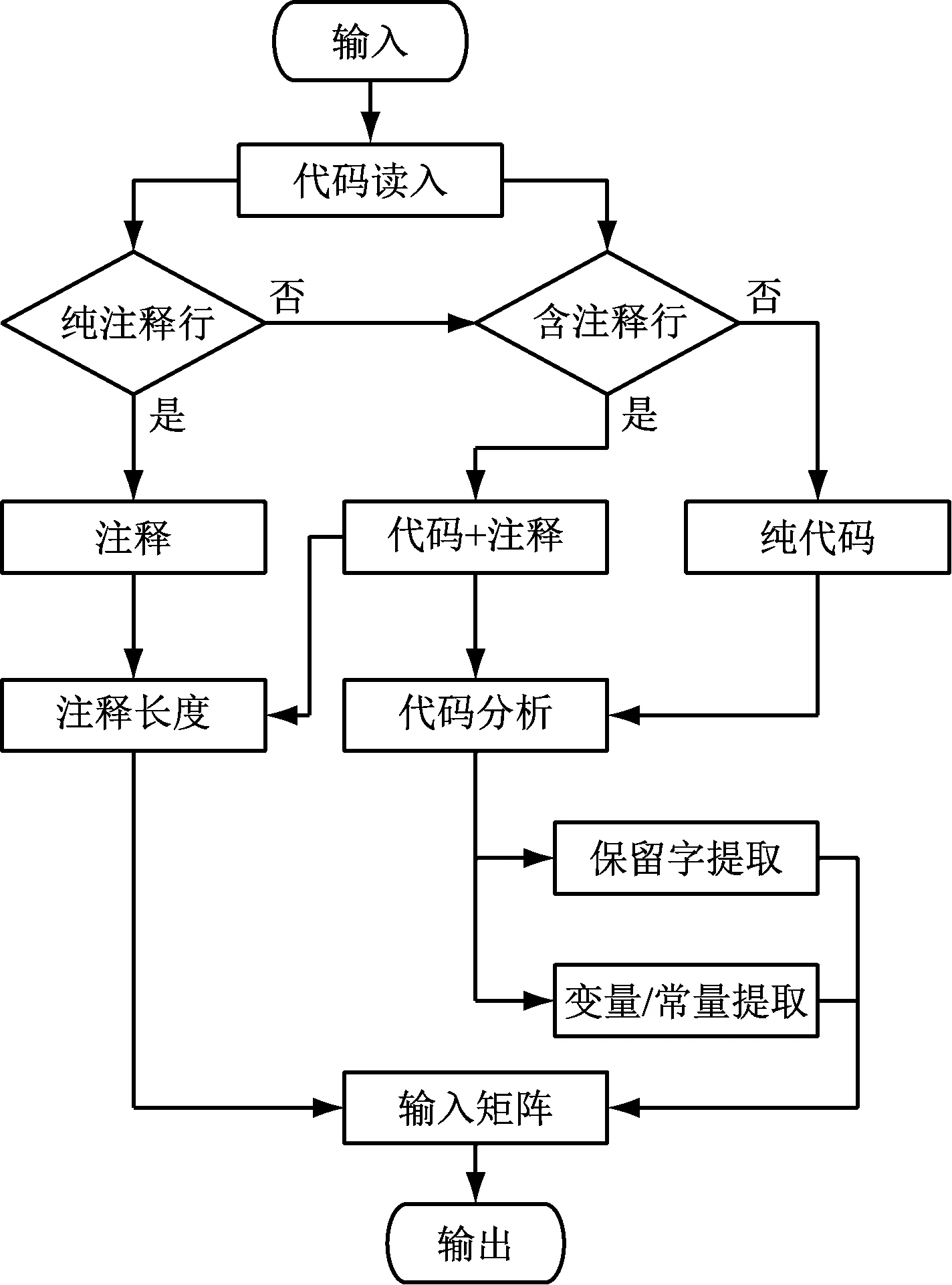
圖1 模糊化算法的流程
圖1中,逐行讀入代碼文本,根據代碼行的注釋標識,分析代碼行的分類,統計代碼行總字符數和注釋字符數,另提取其非注釋部分,提取其保留字和變量名,同時分析變量的數據類型。經過該模糊化過程,形成一個二維矩陣,矩陣的第一控制區間(行)為代碼段的總行數,對每一行構建一組評價值,作為第二控制區間(列),詳見表2。

表2 輸入矩陣第二控制區間定義表
表2中,共給出該輸入矩陣6列n行,n為代碼段的總行數。該輸入矩陣的所有元素,均為整型變量(Integer格式)。在輸入神經網絡時,整型變量將強制轉化為雙精度浮點型變量(Double格式)進行輸入[10]。
2.3 神經網絡具體設計
將上述全部數據深度卷積的統一輸出結果,與逐行數據之間形成逐行優化結果評價,而為了加強對逐行數據的評價,還需要將被評價行的向前5行和向后5行作為參照行。該神經網絡數據流模式詳見圖2。
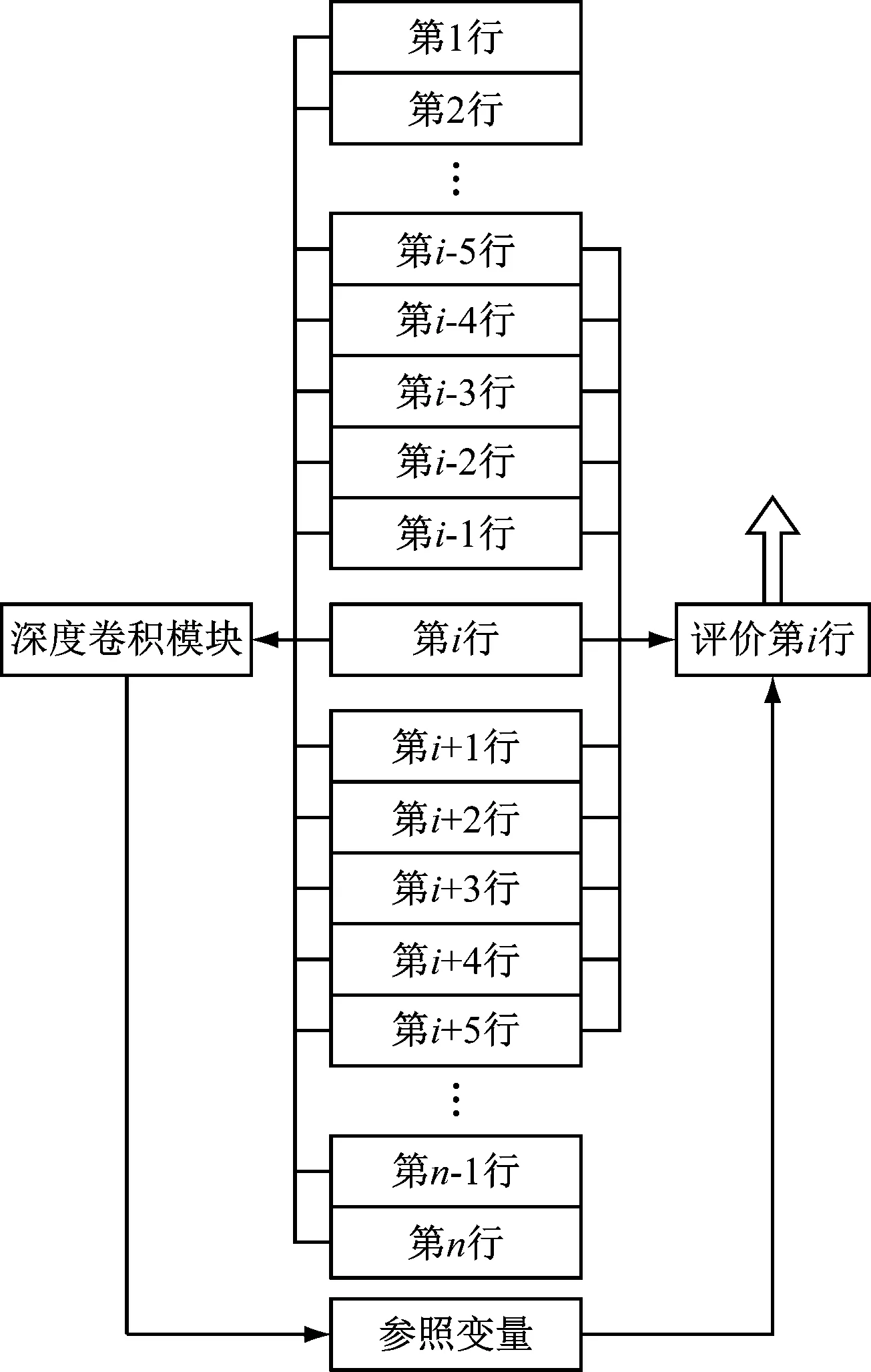
圖2 神經網絡架構數據流圖
圖2中,共設計2個神經網絡模塊。
一個為深度卷積模塊,用于對全部模糊化數據進行整體評價,其輸入節點量為6×n個。如果程序代碼段總行數為3萬行,則此處輸入數據量為18萬個。采用軟件自適應法,根據輸入數據量構建神經網絡的節點量,節點采用六階多項式回歸函數進行節點設計,每層卷積率為35%,卷積至隱藏層末端確保節點數大于5個。
另一個為逐行評價分析模塊,其輸入節點量包括11×6的矩陣截取段輸入,共55個輸入項,同時包括上述深度卷積模塊輸出的參照模塊,即逐行評價分析模塊共輸入56個輸入項。該模塊分為兩段:第一段占用輸入層及前3層隱藏層,使用對數回歸函數進行節點設計,卷積率為75%;第二段為隱藏層后4層,采用二值化回歸函數進行節點設計,卷積率為55%。
神經網絡的數據訓練中,使所有結果收斂到[0,1]區間內,且評價結果越接近1.000,則認為代碼優化程度越高;反之,評價結果越接近0.000,則認為代碼優化程度越低。將輸出結果構建直方圖,直觀顯示程序員的代碼編寫水平。
3 計算機編程優化評價分析結果討論
該算法最終輸出1個二值化評價序列,最大為1.000,最小為0.000,且絕大部分數據集中在1.000或0.000附近。該序列每個節點對應代碼的每一行,節點數據本身并不能直接反映出代碼的優劣,但對整體序列構建直方圖后,可以直觀觀察代碼整體的開發質量。
針對前文假設中提出的4個開發目標,該評價結果可以在唯一評價結果中給出統一評價。即該評價結果較高(接近1.000)的評價結果,表示代碼綜合滿足上述4個開發目標;反之,該評價結果較低(接近0.000)的評價結果,表示該代碼并不滿足上述4個開發目標。某線上購物平臺真實開發項目團隊30人,其中開發組成員15人,代碼規模36萬行,分為72個功能文件進行開發,開發模型為螺旋式開發模型。軟件試運行期間,使用上述開發團隊產出的代碼作為原始數據測試該系統執行效果。
3.1 評價結果的特異性表達
使用該算法在Python環境中運行,輸入不同程序員的代碼成果,對其進行評價,分別對其列出直方圖。其中,開發效率較高程序員與開發效率較低程序員的直方圖對比結果如圖3所示。
圖3中,程序員a為在所有程序員中使用深度卷積計算后評價結果最高的人,程序員b是所有程序員中使用深度卷積計算后評價結果最低的人。將開發組成員15人中直接深度卷積結果最低的程序員b(評價結果0.117)與直接深度卷積結果最高的程序員a(評價結果0.935)的直方圖結果進行對比,發現程序員a的整段代碼中除個別行評價結果小于1.000外,絕大多數行的評價結果均為1.000,反之程序員b的整段代碼中除個別評價結果大于0.000外,絕大多數行的評價結果均為0.000。
3.2 非特異性數據的局部特異性表達
為了測試該系統在非特異性程序員的編程代碼評價中的表現,在上述165個樣本中隨機選擇2個程序員的評價結果,如圖4所示。

圖4 非特異性程序員的評價結果對比圖
圖4中,程序員c和程序員d均為隨機選取的在所有程序員中評價結果中等的人。其中,程序員c的綜合評價結果為0.496,程序員d的綜合評價結果為0.358,系統均給出了較為折中的評價成績。但是,因為該算法使用了將數據落點推向[0,1]區間兩側的二值化模塊,其評價結果相對極端。
在上述2個程序員的評價結果中,部分代碼段給出了接近1.000的評價,部分代碼給出了接近0.000的評價。該結果難以對代碼段做出折中評價,但其優勢是可以在直方圖中顯著表達程序代碼的主觀質量。
3.3 評價結果的整體表達
綜合考察該軟件對開發組成員15人的評價結果與開發方技術人員對其代碼的人工審核結果。人工審核組包括甲方工程師、項目經理、開發經理、產品經理等。人工審核組共12人,其中軟件工程師10人,行政管理人員2人,行政管理人員均有10年以上軟件開發工作經驗。其審核方式為人工對其代碼進行打分,滿分10分,最低0分,對比15人的機器評價得分與人工評價得分的統計學關系,得到圖5。
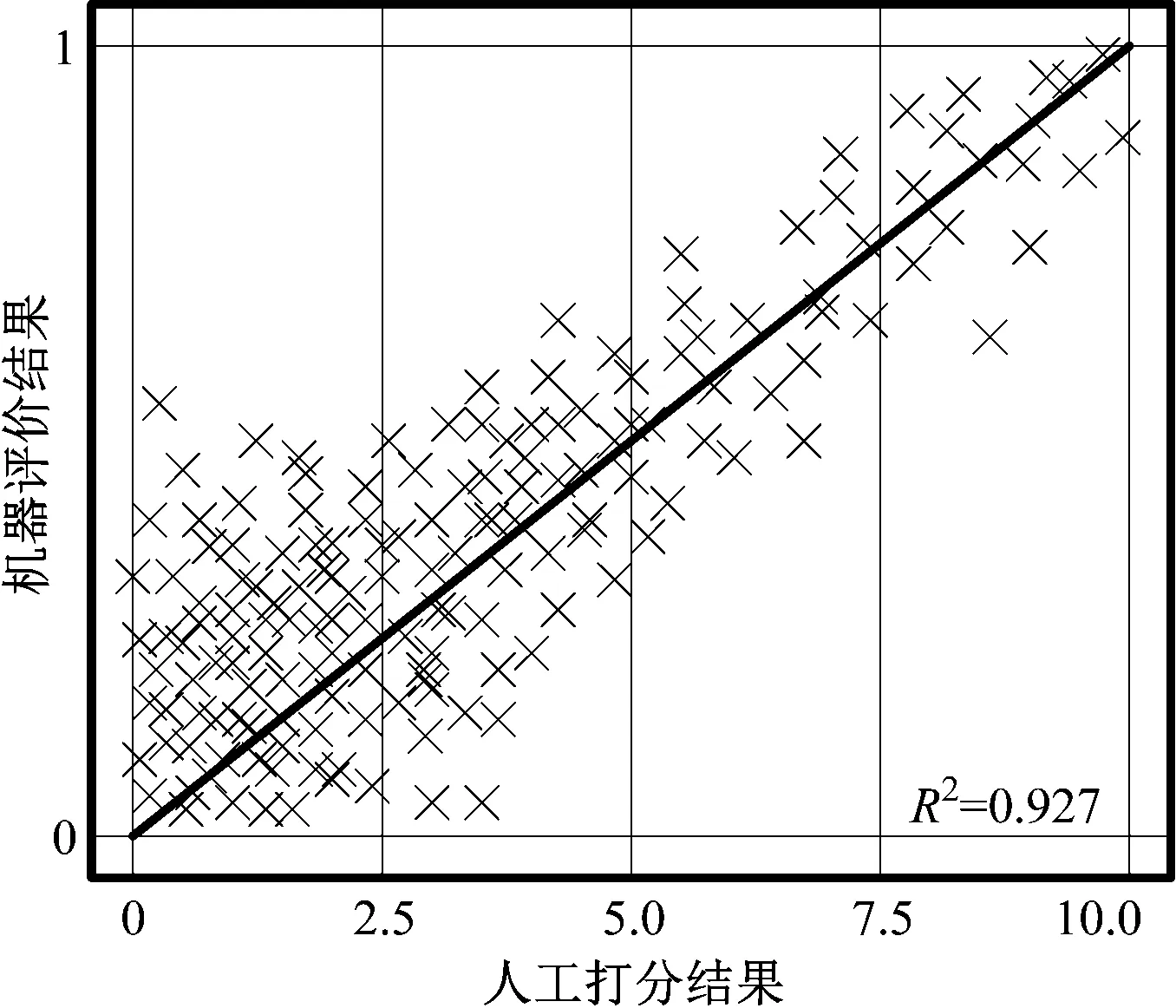
圖5 人工打分與機器評價結果的關聯關系圖
圖5中,人工打分結果與機器評價結果的線性相關關聯度,以R2值評價,達到0.927,而當R2值達到0.800以上時則認為其存在線性相關關系。其中,R2值的統計學意義是決定系數(coefficient of determination),代表回歸平方和與殘差平方和的比值。在此評價結果中,發現評價得分較低的程序代碼,其人工打分與機器打分的離散度更高,即對質量較差的程序代碼,機器打分雖然與人工打分均給出了較低的打分,但二者的差異性較大。考慮到神經網絡算法的基本原理,出現這一問題的主要原因為機器打分可以考慮到的質量較差代碼的主觀因素較少。
4 總結
本研究的評價系統是基于深度卷積模糊神經網絡的編程算法優劣的評價結果,與人工打分結果基本一致,且更具有客觀性。這一技術對程序開發項目管理的客觀績效模式搭建工作有積極意義。同時,針對編程代碼質量進行人工打分過程可能帶入評價者的主觀因素,可能對質量較低代碼給出比機器打分更低的分數。采用機器打分可以給編程能力稍差的編程工作人員更為客觀的評價,這也體現出純客觀評價對基層工作人員的基本尊重。后續研究中,通過增加神經網絡復雜度提升評價精度,從而幫助程序員實現更高質量的計算機編程代碼。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
石油瀝青(2021年4期)2021-10-14 08:50:44
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
現代企業(2015年2期)2015-02-28 18:45:09
中國工程咨詢(2015年2期)2015-02-14 02:59:26
