基于集成學(xué)習(xí)的沿海低能見(jiàn)度天氣分類預(yù)報(bào)方法
2024-01-12 11:36:56陳錦鵬林輝吳雪菲黃奕丹程晶晶莊毅斌
熱帶氣象學(xué)報(bào) 2023年5期
陳錦鵬,林輝,吳雪菲,黃奕丹,程晶晶,莊毅斌
(1.福建省災(zāi)害天氣重點(diǎn)實(shí)驗(yàn)室,福建 福州 350001;2.數(shù)字科學(xué)與統(tǒng)計(jì)重點(diǎn)實(shí)驗(yàn)室,福建 漳州 363005;3.漳州市氣象局,福建 漳州 363005;4.福建省大氣探測(cè)技術(shù)保障中心,福建 福州 350001)
1 引 言
氣象能見(jiàn)度作為氣象觀測(cè)的基本要素之一,容易受到各種因素的影響。當(dāng)出現(xiàn)霧、霾、降雨、降雪等天氣現(xiàn)象時(shí),能見(jiàn)度往往轉(zhuǎn)差;另外邊界層變化、大氣低頻振蕩也能造成能見(jiàn)度下降[1]。沿海低能見(jiàn)度天氣會(huì)對(duì)交通、運(yùn)輸和作業(yè)等產(chǎn)生不利影響,因此其預(yù)報(bào)預(yù)警技術(shù)研究具有重要的實(shí)踐意義。
多年統(tǒng)計(jì)來(lái)看,造成閩南沿海地區(qū)低能見(jiàn)度事件的主要原因分別是霾和霧,且上半年的持續(xù)時(shí)間和發(fā)生頻率高于下半年[2]。分析發(fā)現(xiàn),在爆發(fā)性濃霧過(guò)程中除了由海風(fēng)和地面長(zhǎng)波輻射提供的主要冷卻條件外,還存在來(lái)自平流和蒸發(fā)的充足水汽條件以及貼地強(qiáng)逆溫[3]。近年來(lái),關(guān)于低能見(jiàn)度天氣客觀預(yù)報(bào)的研究工作日漸增多。王楠等[4]以相關(guān)性為依據(jù)篩選預(yù)報(bào)因子,分別采用基于Poly、RBF 核函數(shù)的支持向量機(jī)(SVM)方法建立能見(jiàn)度預(yù)報(bào)模型,發(fā)現(xiàn)在檢驗(yàn)樣本中預(yù)報(bào)準(zhǔn)確樣本的誤差整體較小,而在漏報(bào)樣本中有能見(jiàn)度越低誤差越大的特點(diǎn)。謝超等[5]通過(guò)訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型來(lái)獲得能見(jiàn)度集合預(yù)報(bào),試驗(yàn)顯示模型預(yù)報(bào)的誤差與TS 評(píng)分均優(yōu)于模式預(yù)報(bào)。黃輝軍等[6]嘗試將近地層溫差因子作為GRAPES 模式的預(yù)報(bào)變量因子以改進(jìn)海霧預(yù)報(bào),引入后海霧區(qū)域預(yù)報(bào)的準(zhǔn)確率、TS 和HSS 評(píng)分都有明顯提高。黃健等[7]在海霧歷史觀測(cè)資料和再分析資料的基礎(chǔ)上,采用分類與回歸樹(shù)(CART)方法對(duì)海霧發(fā)生發(fā)展的海洋氣象條件進(jìn)行分類分析,建立了決策樹(shù)預(yù)報(bào)模型,對(duì)廣東沿岸海霧的預(yù)報(bào)準(zhǔn)確率可達(dá)到73%以上。俞涵婷等[8]從統(tǒng)計(jì)角度驗(yàn)證了溫差是大霧形成的重要因素,同時(shí)運(yùn)用決策樹(shù)模型進(jìn)行海霧預(yù)報(bào)試驗(yàn),在測(cè)試集數(shù)據(jù)中成功率為0.8,可用于業(yè)務(wù)中對(duì)海霧的判別。
總體來(lái)看,目前對(duì)于海霧的預(yù)報(bào)方法主要包括天氣學(xué)方法、統(tǒng)計(jì)預(yù)報(bào)方法和數(shù)值預(yù)報(bào)方法,天氣學(xué)方法對(duì)預(yù)報(bào)員的主觀經(jīng)驗(yàn)依賴性較高,預(yù)報(bào)準(zhǔn)確率和可靠性較低;單純的統(tǒng)計(jì)預(yù)報(bào)方法缺乏對(duì)海霧過(guò)程物理規(guī)律的描述,多依賴于歷史觀測(cè)資料或數(shù)值預(yù)報(bào)資料的質(zhì)量和數(shù)量[9]。而數(shù)值預(yù)報(bào)方法作為氣象預(yù)報(bào)的主流發(fā)展方向,離不開(kāi)客觀化、自動(dòng)化的后處理訂正技術(shù)。輕量梯度提升機(jī)(Light Gradient Boosting Machine,LightGBM)作為目前集成學(xué)習(xí)代表性算法之一,面對(duì)結(jié)構(gòu)化數(shù)據(jù)時(shí)具有比較出色的普適性、準(zhǔn)確性和可解釋性,在各大數(shù)據(jù)挖掘競(jìng)賽與各個(gè)行業(yè)領(lǐng)域中的應(yīng)用相當(dāng)廣泛。如何將LightGBM 算法更好地應(yīng)用于低能見(jiàn)度天氣預(yù)報(bào)預(yù)警業(yè)務(wù)之上,是非常值得探究的問(wèn)題。在上海區(qū)域的能見(jiàn)度預(yù)報(bào)試驗(yàn)中,基于WRF 模式的LightGBM 訂正模型在驗(yàn)證集上的平均絕對(duì)誤差相對(duì)于原始預(yù)報(bào)提升比例可達(dá)47.2%[10]。但交叉驗(yàn)證中的數(shù)據(jù)集來(lái)自于同分布隨機(jī)采樣,缺乏時(shí)間相關(guān)性,不足以體現(xiàn)模型在實(shí)際業(yè)務(wù)中面對(duì)未知數(shù)據(jù)的預(yù)測(cè)能力。
此外,福建漳州地區(qū)現(xiàn)有的沿岸、島嶼和浮標(biāo)自動(dòng)站過(guò)于稀疏,探測(cè)范圍也極為有限,過(guò)少的觀測(cè)樣本不利于模型訓(xùn)練與測(cè)試。本試驗(yàn)嘗試引入遠(yuǎn)距離無(wú)線電(Long Range Radio,LoRa)探測(cè)數(shù)據(jù),與自動(dòng)站觀測(cè)數(shù)據(jù)進(jìn)行融合以擴(kuò)充數(shù)據(jù)集。LoRa 是一種窄帶物聯(lián)網(wǎng)通信技術(shù),其信號(hào)衰減對(duì)天氣要素變化敏感,尤其是與相對(duì)濕度、風(fēng)速存在一定的相關(guān)性。目前漳州沿海及海上地區(qū)已部署LoRa 觀測(cè)組網(wǎng),通過(guò)能見(jiàn)度反演算法得到高時(shí)空分辨率的LoRa 海霧探測(cè)數(shù)據(jù)[11],可在一定程度上彌補(bǔ)傳統(tǒng)觀測(cè)手段的不足。
本文提出的低能見(jiàn)度天氣分類預(yù)報(bào)技術(shù)本質(zhì)是應(yīng)用集成學(xué)習(xí)對(duì)數(shù)值預(yù)報(bào)進(jìn)行統(tǒng)計(jì)訂正,融合了數(shù)值模式擅長(zhǎng)環(huán)流形勢(shì)預(yù)報(bào)與集成學(xué)習(xí)擅長(zhǎng)統(tǒng)計(jì)規(guī)律挖掘的優(yōu)勢(shì)來(lái)進(jìn)一步推導(dǎo)低能見(jiàn)度天氣的可能性。試驗(yàn)中應(yīng)用2020年數(shù)據(jù)集進(jìn)行建模和訓(xùn)練,以2021年數(shù)據(jù)集進(jìn)行測(cè)試,充分考察模型的擬合能力和泛化能力,驗(yàn)證了該模型具有優(yōu)于模式原始預(yù)報(bào)甚至傳統(tǒng)統(tǒng)計(jì)方法的預(yù)測(cè)能力。同時(shí)也探究了試驗(yàn)過(guò)程中遇到的樣本不均衡、特征構(gòu)造和模型融合等問(wèn)題,為集成學(xué)習(xí)在能見(jiàn)度預(yù)報(bào)方面的應(yīng)用和數(shù)值模式訂正技術(shù)的發(fā)展提供參考。
2 資 料
本文采 用2020 年3 月—2021 年7 月 漳州地區(qū)沿海與島嶼自動(dòng)站的逐小時(shí)能見(jiàn)度觀測(cè)數(shù)據(jù)作為實(shí)況資料,共包含10 個(gè)站點(diǎn)(圖1)。由于沿海自動(dòng)站分布過(guò)于稀疏,難以精細(xì)體現(xiàn)能見(jiàn)度要素的空間分布,故將相應(yīng)的LoRa 探測(cè)數(shù)據(jù)與其進(jìn)行融合作為補(bǔ)充(詳見(jiàn)3.3.1 節(jié)),最后得到網(wǎng)格化的能見(jiàn)度實(shí)況資料。
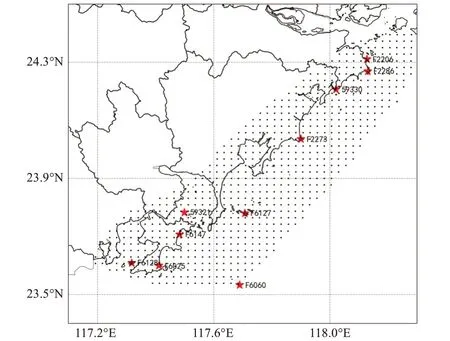
圖1 漳州地區(qū)沿海與島嶼自動(dòng)站(紅色)以及LoRa探測(cè)格點(diǎn)(黑色)分布
另外,采用EC-thin 歷史數(shù)據(jù)作為預(yù)報(bào)資料。其時(shí)間分辨率為3 h,空間分辨率為0.125 °×0.125 °。預(yù)先根據(jù)業(yè)務(wù)經(jīng)驗(yàn)挑選出與能見(jiàn)度關(guān)聯(lián)較強(qiáng)的預(yù)報(bào)因子作為模型的待選特征,具體包括2 m 露點(diǎn)(d2)、2 m 相對(duì)濕度(rh2)、2 m 氣溫(T2)、10 m 風(fēng)場(chǎng)U分量(u10)、10 m 風(fēng)場(chǎng)V分量(v10)、海平面氣壓(msl)、925 hPa比濕(q925)和1 000 hPa比濕(q1000)、925 hPa 氣溫(T925)和1 000 hPa 氣溫(T1000)、低云量(LCC)、總云量(TCC)等共計(jì)12 類預(yù)報(bào)產(chǎn)品。這些變量均來(lái)自于模式的直接輸出產(chǎn)品,基本反映了邊界層內(nèi)的氣象環(huán)境條件。
從逐小時(shí)、逐格點(diǎn)的角度制作樣本數(shù)據(jù)集:對(duì)于每個(gè)實(shí)況融合后的格點(diǎn)而言,在預(yù)報(bào)資料中選取以其為中心的16 點(diǎn)平均值(覆蓋邊長(zhǎng)為0.375 °的矩形區(qū)域)作為該點(diǎn)的特征變量。建模的目的在于挖掘特征變量與格點(diǎn)水平能見(jiàn)度級(jí)別之間的映射關(guān)系。定義水平能見(jiàn)度小于500 m 的樣本為正類樣本,反之則為負(fù)類樣本。觀察樣本分布(表1)可發(fā)現(xiàn)正負(fù)類樣本數(shù)量懸殊,如2020 年正負(fù)比率不足0.6%,屬于極小概率事件,嚴(yán)重的樣本不均衡問(wèn)題會(huì)導(dǎo)致模型訓(xùn)練出現(xiàn)顯著偏離,試驗(yàn)中需加以解決。分別將2020 年和2021 年數(shù)據(jù)集作為訓(xùn)練集和測(cè)試集,避免由于打亂時(shí)間順序而出現(xiàn)數(shù)據(jù)信息泄露,充分考察模型面對(duì)完全陌生的“未來(lái)”數(shù)據(jù)的預(yù)測(cè)能力。

表1 2020年與2021年正負(fù)類樣本分布
3 研究方法
3.1 低能見(jiàn)度天氣的日變化特征
漳州沿海地區(qū)低能見(jiàn)度天氣具有鮮明的日變化特征。從2020年不同程度的低能見(jiàn)度天氣頻次統(tǒng)計(jì)可以發(fā)現(xiàn),無(wú)論是能見(jiàn)度在3 000 m以下或是500 m 以下的天氣均以下半夜最多見(jiàn)(圖2)。具體來(lái)看,前者在05 時(shí)(北京時(shí)間,下同)頻次最高,06時(shí)以后頻次急劇下降,在00—12 時(shí)之間呈現(xiàn)單峰型分布;而后者在04 時(shí)頻次最高,在08 時(shí)頻次次高,在下半夜至上午時(shí)段亦呈現(xiàn)單峰型分布,且04—08時(shí)發(fā)生頻次顯著高于其他時(shí)間。這表明了夜間的冷卻條件極為重要,也反映了引入日變化的時(shí)間參數(shù)作為模型的特征變量是很有意義的。
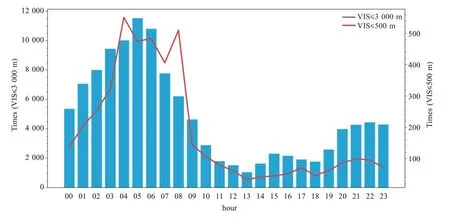
圖2 3 000 m以下(藍(lán)色柱狀)和500 m(紅色折線)以下的低能見(jiàn)度時(shí)刻發(fā)生頻次的日變化
3.2 LoRa探測(cè)數(shù)據(jù)的可用性
在使用LoRa 探測(cè)數(shù)據(jù)之前,需要初步評(píng)估LoRa 探測(cè)數(shù)據(jù)的準(zhǔn)確性和可用性。以上述10 個(gè)沿海和島嶼自動(dòng)站的能見(jiàn)度觀測(cè)資料為參照標(biāo)準(zhǔn),對(duì)空間分辨率為1 km 的網(wǎng)格化的LoRa 探測(cè)數(shù)據(jù)進(jìn)行檢驗(yàn)。考慮到所選自動(dòng)站的能見(jiàn)度觀測(cè)儀可能存在偏差以及實(shí)際業(yè)務(wù)中更加關(guān)注能見(jiàn)度在3 000 m以下的天氣,故只篩選出同一小時(shí)內(nèi)至少存在相鄰兩個(gè)自動(dòng)站能見(jiàn)度小于3 000 m 的時(shí)次樣本進(jìn)行檢驗(yàn)。
根據(jù)能見(jiàn)度要素在空間分布上具有一定的連續(xù)性,采用鄰域檢驗(yàn)法進(jìn)行檢驗(yàn),即假設(shè)自動(dòng)站周邊一定范圍的區(qū)域內(nèi)能見(jiàn)度等級(jí)與該站點(diǎn)一致。隨著鄰域半徑增大,參與檢驗(yàn)的格點(diǎn)數(shù)也越多;但當(dāng)領(lǐng)域半徑過(guò)大時(shí),上述假設(shè)可能會(huì)失效。以能見(jiàn)度分類閾值為500 m、鄰域半徑為2 000 m 的檢驗(yàn)為例,參與檢驗(yàn)站點(diǎn)的平均結(jié)果如表2 所示,其TS 評(píng)分和準(zhǔn)確率分別接近60%和94%以上,漏報(bào)率略多于空?qǐng)?bào)率,但均未超過(guò)1/3,表明了具有較理想的可用性。

表2 LoRa探測(cè)數(shù)據(jù)的檢驗(yàn)指標(biāo)(能見(jiàn)度分類閾值為1 000 m、鄰域半徑為2 000 m)
3.3 數(shù)據(jù)預(yù)處理
3.3.1 實(shí)況資料合成
單純使用自動(dòng)站的能見(jiàn)度觀測(cè)資料在范圍和數(shù)量上都會(huì)受到較大的限制,不利于模型的訓(xùn)練和測(cè)試。在LoRa 探測(cè)數(shù)據(jù)可用性較好的基礎(chǔ)上,將相距3 km 內(nèi)的自動(dòng)站觀測(cè)數(shù)據(jù)與LoRa 探測(cè)數(shù)據(jù)進(jìn)行指數(shù)權(quán)重合成以獲得網(wǎng)格化的實(shí)況數(shù)據(jù)。該合成方式的優(yōu)點(diǎn)在于權(quán)重隨著距離快速減少,又始終保持正值[12]。具體公式如下:
對(duì)于某一格點(diǎn)而言,V為融合能見(jiàn)度,Vd為L(zhǎng)oRa 探測(cè)能見(jiàn)度,Vo為自動(dòng)站能見(jiàn)度,R為該格點(diǎn)與最鄰近站點(diǎn)的距離,即距離自動(dòng)站3 km 以外的格點(diǎn)值只取LoRa 探測(cè)值,反之則根據(jù)與自動(dòng)站的距離進(jìn)行指數(shù)權(quán)重合成,離自動(dòng)站越遠(yuǎn)則LoRa 探測(cè)值的權(quán)重越大。
3.3.2 新特征構(gòu)造
模型的輸入特征好壞在很大程度上決定了模型的預(yù)測(cè)能力上限。雖然來(lái)自于模式直接輸出產(chǎn)品的特征變量足以描述邊界層內(nèi)大氣環(huán)境條件,但是與低能見(jiàn)度天氣過(guò)程之間的映射關(guān)系還不夠顯著,諸如水汽、冷卻、弱風(fēng)和穩(wěn)定層結(jié)等氣象條件可以通過(guò)構(gòu)造新的特征變量以得到更好地描述。
在水汽和弱風(fēng)條件方面,分別增加2 m 溫度露點(diǎn)差(T2-d2)和10 m 全風(fēng)速(uv10)作為新的特征變量。此外,增加925 hPa 與2 m 溫差(T2-T925)、925 hPa 與1 000 hPa 溫差(T1000-T925)、1 000 hPa與2 m 溫差(T2-T1000)等三個(gè)特征變量。由于低能見(jiàn)度天氣具有日變化規(guī)律,還可以引入樣本所屬的時(shí)刻作為時(shí)間參數(shù)特征。將原先的特征稱為初始特征,加入6個(gè)新特征后稱為全特征。
3.4 建模方法
梯度提升決策樹(shù)(Gradient Boosting Decision Tree,GBDT)的基本原理是不斷通過(guò)擬合殘差(真實(shí)值與預(yù)測(cè)值的偏差)來(lái)迭代學(xué)習(xí)新的決策樹(shù),再將所有決策樹(shù)的單獨(dú)預(yù)測(cè)進(jìn)行相加即得最終結(jié)果,因此可以由如下公式表示:
其中X代表輸入特征,F(xiàn)代表決策樹(shù),Θn為決策樹(shù)的超參數(shù)(如最大深度、葉子節(jié)點(diǎn)數(shù)等),N為決策樹(shù)的個(gè)數(shù)。LightGBM 每次選擇能夠帶來(lái)最大信息增益的節(jié)點(diǎn)進(jìn)行切分,即保證切分前后的信息熵差值為最大。特征種類越多、樣本數(shù)據(jù)量越大時(shí),LightGBM 越有計(jì)算成本上的優(yōu)勢(shì),這主要由于LightGBM 采用的兩種創(chuàng)新技術(shù):基于梯度的單側(cè)采樣(Gradient-based One-Side Sampling)和互斥特征捆綁(Exclusive Feature Bundling)。前者的目的是縮減用于計(jì)算信息增益的樣本數(shù)量,后者則能夠減少用于參與分裂點(diǎn)篩選計(jì)算的特征數(shù)量[13]。在幾乎相同的精度上,LightGBM 可以使傳統(tǒng)GBDT的訓(xùn)練過(guò)程加速20倍以上[14]。
邏輯回歸(Logistic Regression,LR)算法也是一種用于解決二分類問(wèn)題的算法。該算法基于數(shù)據(jù)服從伯努利分布的假設(shè),在給定條件概率分布的基礎(chǔ)上運(yùn)用極大似然估計(jì)求解最優(yōu)參數(shù)。具體是使用Sigmoid 函數(shù)將線性回歸的預(yù)測(cè)值映射為(0, 1)上的概率值,最終公式如下:
其中θ為L(zhǎng)R 模型超參數(shù),可用梯度下降法尋找最優(yōu)解。LR 算法的運(yùn)行效率高、可解釋性強(qiáng),適合作為基準(zhǔn)算法進(jìn)行對(duì)比。
本研究依靠LightGBM 模型來(lái)挖掘同一時(shí)刻內(nèi)某點(diǎn)能見(jiàn)度V與該點(diǎn)附近的氣象條件X之間的映射關(guān)系,即認(rèn)為存在V=f(X)。此外,LightGBM能夠從信息熵和信息增益[15]的角度來(lái)考察各類特征重要性,后續(xù)將據(jù)此對(duì)特征變量的貢獻(xiàn)大小進(jìn)行排序。
3.5 評(píng)估指標(biāo)
LightGBM 模型的輸出是預(yù)測(cè)概率值,在應(yīng)用命中率、TS 評(píng)分等傳統(tǒng)分類指標(biāo)時(shí)需要事先確定分類概率閾值,不同的閾值所對(duì)應(yīng)的指標(biāo)也有所不同,如此不利于全面跟蹤和評(píng)估模型性能的變化。本試驗(yàn)引入受試者工作特征曲線下面積(Area Under ROC Curve,AUC)評(píng)分[16]對(duì)模型表現(xiàn)進(jìn)行跟蹤檢驗(yàn),受試者工作特征曲線(Receiver Operating Characteristic Curve,ROC 曲線)是指遍歷模型所有分類概率閾值后,在以偽陽(yáng)性率(False Positive Rate,F(xiàn)PR)為橫坐標(biāo)、以真陽(yáng)性率(True Positive Rate,TPR)為縱坐標(biāo)的坐標(biāo)系中由一系列不同閾值的點(diǎn)組成的曲線,其中FPR、TPR計(jì)算公式如下:
NA 為預(yù)報(bào)和實(shí)況均出現(xiàn)低能見(jiàn)度天氣的次數(shù),NB 為漏報(bào)次數(shù),NC 為空?qǐng)?bào)次數(shù),ND 為預(yù)報(bào)和實(shí)況均未出現(xiàn)低能見(jiàn)度的次數(shù)。AUC 為0.5 時(shí)說(shuō)明預(yù)測(cè)完全是隨機(jī)的;AUC在0.5以上才能說(shuō)明模型具有正向預(yù)測(cè)價(jià)值;AUC 越接近1,則模型預(yù)測(cè)效果越趨于完美[17]。
3.6 試驗(yàn)設(shè)計(jì)
根據(jù)時(shí)空對(duì)應(yīng)關(guān)系將實(shí)況融合資料與模式預(yù)報(bào)資料制作成數(shù)據(jù)集。空間上,以預(yù)測(cè)點(diǎn)為中心、邊長(zhǎng)為4×4 格點(diǎn)的矩形區(qū)域內(nèi)物理量平均值作為特征變量;時(shí)間上,選取起報(bào)時(shí)間為20 時(shí)、預(yù)報(bào)時(shí)效包含15~36 h 的預(yù)報(bào)產(chǎn)品進(jìn)行處理。由于2021年部分時(shí)段資料缺失,總共整理出約18萬(wàn)個(gè)樣本。
為了盡量減小樣本極端不均衡對(duì)訓(xùn)練過(guò)程帶來(lái)的影響,試驗(yàn)中運(yùn)用自助聚合(Bootstrap Aggregating,Bagging)技術(shù)進(jìn)行采樣和建模:在負(fù)樣本遠(yuǎn)多于正樣本的數(shù)據(jù)集中,對(duì)大量負(fù)樣本進(jìn)行隨機(jī)采樣50 次,每次可得到與正樣本數(shù)量接近的負(fù)樣本以組成子訓(xùn)練集,即每一份子訓(xùn)練集中的正樣本相同而負(fù)樣本不同。在50份子訓(xùn)練集的基礎(chǔ)上可訓(xùn)練出50 個(gè)不同的基模型,將每個(gè)基模型的預(yù)測(cè)概率進(jìn)行平均處理,則為融合模型。預(yù)先統(tǒng)一設(shè)定基模型的超參數(shù),其中關(guān)鍵超參數(shù)如最大樹(shù)深度為7、葉子節(jié)點(diǎn)數(shù)為2、學(xué)習(xí)率為0.06。
試驗(yàn)共劃分為四組:(a) 基于初始特征的基模型預(yù)測(cè)(RAW-BASE);(b) 基于全特征的基模型預(yù)測(cè)(ALL-BASE);(c) 基于初始特征的融合模型預(yù)測(cè)(RAW-MIX);(d) 基于全特征的融合模型預(yù)測(cè)(ALL-MIX)。此外,以基于全特征的LR方法作為參照試驗(yàn),稱為ALL-LR,在該方法中設(shè)定根據(jù)樣本數(shù)量來(lái)調(diào)整樣本權(quán)重以緩解數(shù)據(jù)不均衡的影響。根據(jù)AUC 評(píng)分對(duì)各類方案的結(jié)果進(jìn)行評(píng)估和對(duì)比。
4 對(duì)比與分析
4.1 特征重要性分析
LightGBM 建模方法可通過(guò)計(jì)算每類特征在分割點(diǎn)產(chǎn)生的信息增益總和來(lái)對(duì)特征重要性進(jìn)行排序,這有助于深入了解低能見(jiàn)度天氣發(fā)生發(fā)展的氣象環(huán)境條件。如圖3 所示,d2的重要性高達(dá)3 000以上,遠(yuǎn)遠(yuǎn)超過(guò)其他特征,這表明了近洋面高度的水汽絕對(duì)含量對(duì)低能見(jiàn)度天氣過(guò)程非常關(guān)鍵。其余特征重要性之間的差異相對(duì)較小,第二為T2-T1000,包括T2-T925也排行第六,可見(jiàn)近地層溫差的作用亦不可忽視。往后從大到小分別為v10、u10、T925、T2-T925、msl、q1000等,主要與弱風(fēng)條件有關(guān)。同時(shí)注意到,uv10和T1000參考意義并不是很大。
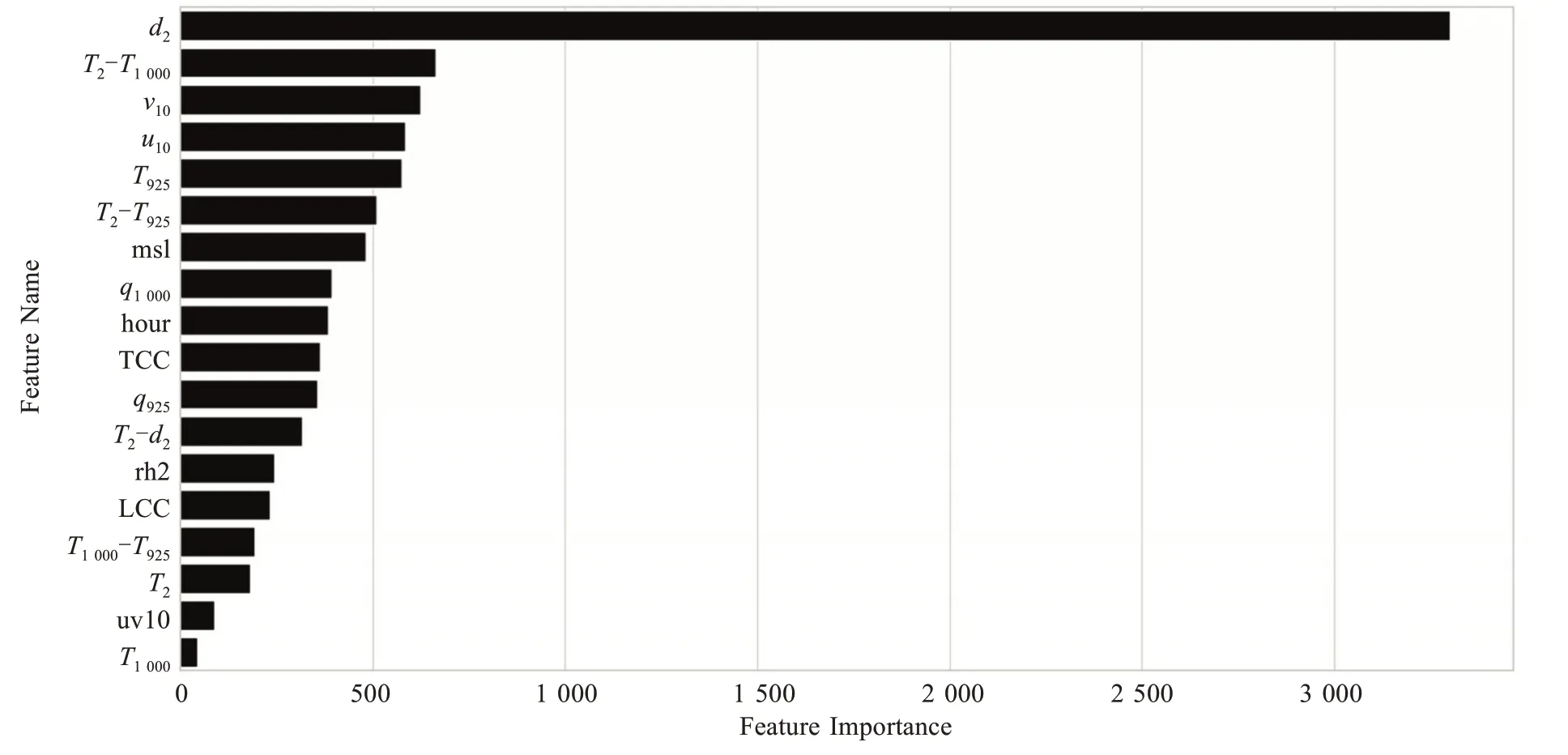
圖3 基于LightGBM的預(yù)報(bào)模型輸入特征重要性排序
4.2 不同方案在訓(xùn)練集和測(cè)試集上的對(duì)比
分別對(duì)五種建模方案進(jìn)行訓(xùn)練。其中四種基于LightGBM 的方案中均包含50 個(gè)基模型,每個(gè)基模型迭代訓(xùn)練1 200 次。RAW-BASE 和ALLBASE方案是對(duì)逐個(gè)基模型進(jìn)行檢驗(yàn),故存在虛線和陰影區(qū)以表示其AUC 評(píng)分的平均值和95%置信區(qū)間。而RAW-MIX和ALL-MIX方案則是對(duì)融合模型的概率進(jìn)行檢驗(yàn)。
在訓(xùn)練集上,主要對(duì)比RAW-BASE、ALLBASE 和LR 方案的差異。如圖4 所示,在經(jīng)過(guò)30次迭代訓(xùn)練后,基于LightGBM 的兩種方案就表現(xiàn)出比LR 更高的擬合精度,最終AUC 評(píng)分均達(dá)到了0.9 以上。RAW-BASE 和ALL-BASE 方案的訓(xùn)練曲線比較相似,開(kāi)始時(shí)AUC 評(píng)分的提升率較大,在30~40 代之間后者逐漸與前者拉開(kāi)差距,中后期提升率逐漸減小,AUC評(píng)分處于較高水平,模型存在過(guò)擬合的風(fēng)險(xiǎn),需進(jìn)一步考察其在測(cè)試集上的表現(xiàn)。這表明了引入新特征能夠讓模型更快更好地學(xué)習(xí)到低能見(jiàn)度天氣的發(fā)生規(guī)律。

圖4 模型在訓(xùn)練集上的AUC評(píng)分對(duì)比
在測(cè)試集上,EC-thin 模式對(duì)于樣本能見(jiàn)度的原始預(yù)報(bào)均在3 000 m以上,難以捕捉低能見(jiàn)度天氣發(fā)生的征兆。從圖5 可以看到,經(jīng)過(guò)LR 方法訂正后提升微弱,AUC 評(píng)分仍不足0.71,參考性較差。整體來(lái)看,基于LightGBM 的建模方案訂正效果顯著優(yōu)于LR 方法,前者AUC 評(píng)分均能超過(guò)0.85,在800 次迭代訓(xùn)練后基本趨于收斂,穩(wěn)定性較好,反映了基于LightGBM 的建模方法具有優(yōu)秀的非線性擬合能力。
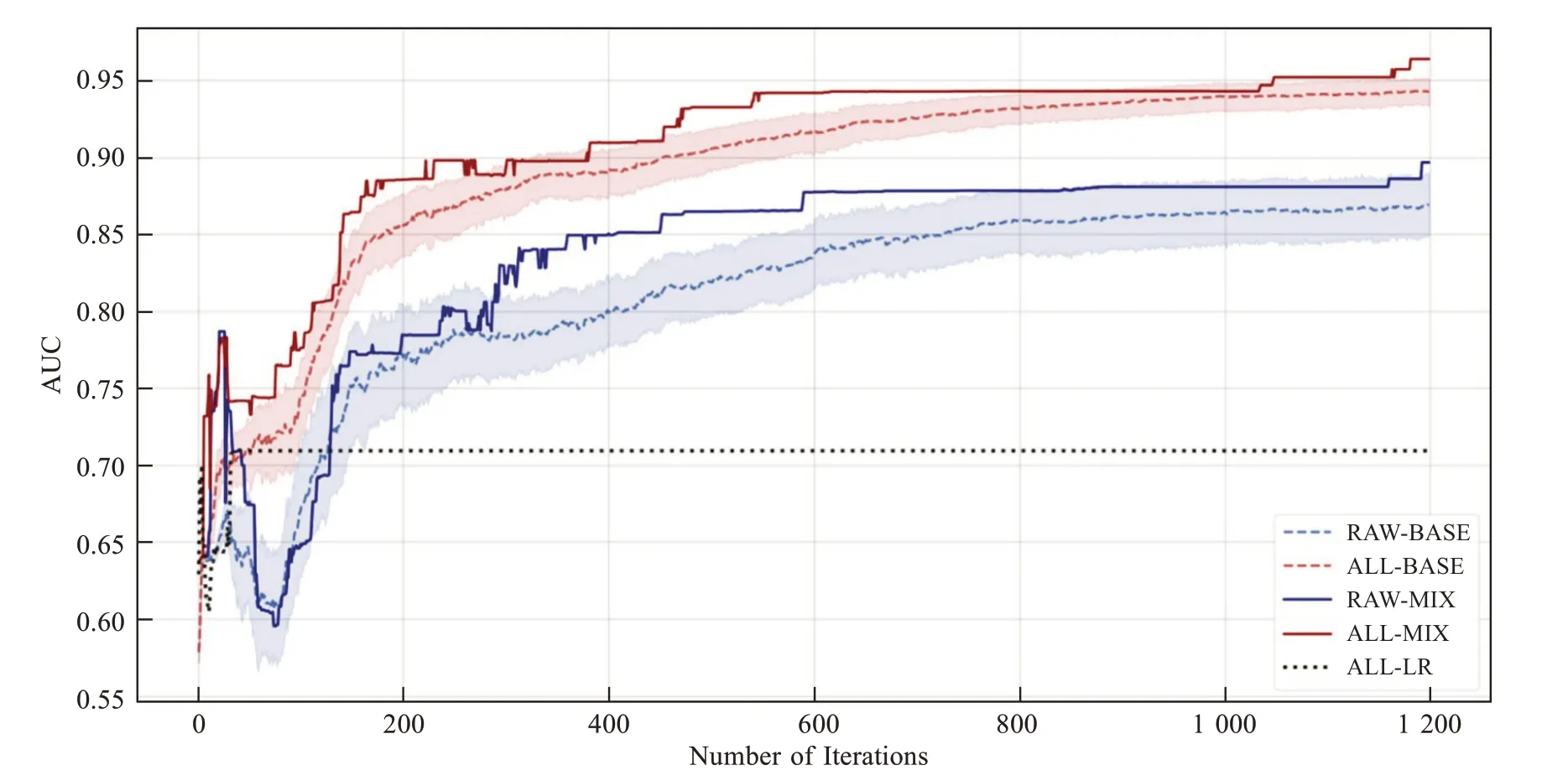
圖5 模型在測(cè)試集上的AUC評(píng)分對(duì)比
在四組基于LightGBM 的訂正方案中,模型擬合穩(wěn)定后的AUC 評(píng)分由高到低分別為:ALLMIX、ALL-BASE、RAW-MIX、RAW-BASE。基于全特征的訂正方案(ALL-MIX 和ALL-BASE)相比于原始特征(RAW-MIX 和RAW-BASE)具備更優(yōu)越的改善作用,前者在1 000 代之后集中于0.94附近,后者仍分布在0.87 上下。新特征的構(gòu)造和引入也縮小了基模型的振蕩區(qū)間,有效削弱模型隨機(jī)性,也使得200 代之前的AUC 評(píng)分提升更加迅速和平滑。
模型融合與否也會(huì)小幅影響其預(yù)測(cè)能力。經(jīng)過(guò)平均處理后的融合模型(RAW-MIX 和ALLMIX)表現(xiàn)基本與50 個(gè)基模型(RAW-BASE 和ALL-BASE)中的最優(yōu)者相當(dāng),更重要的是融合模型可以解決實(shí)際業(yè)務(wù)中我們難以提前得知哪個(gè)基模型為最優(yōu)的問(wèn)題。與基模型相對(duì)平穩(wěn)的能力提升不同,融合模型在測(cè)試集上的AUC 變化曲線呈現(xiàn)階躍式上升,且在接近1 200代時(shí)再次超過(guò)基模型,甚至還存在繼續(xù)優(yōu)化的潛力。這些現(xiàn)象說(shuō)明了融合模型能夠逼近甚至超越最優(yōu)基模型,既避免了基模型選擇困難,還可以加速模型優(yōu)化過(guò)程,提高模型學(xué)習(xí)效率,使其更早進(jìn)入穩(wěn)定收斂狀態(tài)。總之,對(duì)比試驗(yàn)驗(yàn)證了LightGBM 模型相對(duì)于傳統(tǒng)訂正方法具有更大的潛力,而新特征引入和模型融合的技巧能夠?qū)τ喺Чa(chǎn)生正貢獻(xiàn),尤其是構(gòu)造合理的新特征對(duì)模型的提升幅度更為突出。
4.3 最優(yōu)建模方案在測(cè)試集上的分析
由上述對(duì)比可知,最優(yōu)建模方案為ALL-MIX方案,現(xiàn)對(duì)ALL-MIX 模型和LR 模型作進(jìn)一步評(píng)估。對(duì)于第1 200 代的ALL-MIX 模型而言,通過(guò)搜索TPR 與FPR 之差的最大值可以確定其最佳概率閾值a為0.999 7 左右,即當(dāng)模型輸出概率P≥a時(shí)判斷為水平能見(jiàn)度低于500 m,反之則在500 m以上。同時(shí)計(jì)算ALL-MIX 模型和LR 模型的交叉矩陣(其最佳概率閾值約為0.953 6)以做進(jìn)一步對(duì)比(表3 和表4)。可以發(fā)現(xiàn),兩者的預(yù)報(bào)準(zhǔn)確數(shù)和漏報(bào)數(shù)基本一致,命中率都在98%左右,這是訂正模型對(duì)模式原始預(yù)報(bào)改善作用最突出的方面。與此相反,兩種建模方案的空?qǐng)?bào)數(shù)差距很大,LR 模型的空?qǐng)?bào)數(shù)約為ALL-MIX 模型的8.5 倍,故前者空?qǐng)?bào)率超過(guò)93%,后者則控制在61%左右,表明了融合模型相對(duì)于傳統(tǒng)模型的優(yōu)勢(shì)在于顯著降低了空?qǐng)?bào)率。因此,ALL-MIX模型的TS評(píng)分可以達(dá)到38.71%左右,比LR模型提升了5倍以上。

表3 ALL-MIX方案在測(cè)試集上的交叉矩陣

表4 ALL-LR方案在測(cè)試集上的交叉矩陣
5 結(jié) 論
本文從逐小時(shí)逐格點(diǎn)的角度出發(fā),在2020 年3 月—2021 年7 月漳州地區(qū)融合實(shí)況資料與ECthin模式歷史預(yù)報(bào)產(chǎn)品的基礎(chǔ)上制作數(shù)據(jù)集,將能見(jiàn)度是否低于500 m 作為分類預(yù)測(cè)目標(biāo),應(yīng)用集成學(xué)習(xí)中的LightGBM 算法建立了分類預(yù)報(bào)訂正模型,利用Bagging 技術(shù)和AUC 評(píng)分指標(biāo)在一定程度上克服樣本極端不均衡帶來(lái)的影響,并根據(jù)新特征構(gòu)造和模型融合劃分為四種訓(xùn)練方案進(jìn)行試驗(yàn),同時(shí)設(shè)定基于LR(邏輯回歸)方法的預(yù)測(cè)模型作為基準(zhǔn)試驗(yàn)。經(jīng)過(guò)對(duì)比分析得到如下結(jié)論。
(1)所有訂正方案對(duì)于EC-thin模式原始預(yù)報(bào)能力均有不同程度的提升。在所有表征氣象環(huán)境條件的特征中,d2在建模過(guò)程中產(chǎn)生的信息增益總和最大,即d2對(duì)判斷低能見(jiàn)度天氣發(fā)生發(fā)展最為重要,T2-T1000的重要性次之。
(2)基于LightGBM 方法的訂正模型總體效果優(yōu)于LR 模型。兩者的命中率基本接近,但前者通過(guò)削減空?qǐng)?bào)率而進(jìn)一步優(yōu)化了預(yù)測(cè)能力。其中ALL-MIX(基于全特征的融合模型)建模方案在測(cè)試集上的AUC 評(píng)分相比于LR 模型增加了0.387 7,TS 評(píng)分也提升了7 倍以上。表明了LightGBM 模型在搜尋非線性復(fù)雜規(guī)律方面具有比較優(yōu)秀的擬合能力和泛化能力。
(3)合理構(gòu)造新特征以及對(duì)基模型進(jìn)行平均融合有助于優(yōu)化訂正模型。在四種基于LightGBM 的訓(xùn)練方案中,ALL-MIX 方案可以使模型在測(cè)試集上取得最高的AUC 評(píng)分。對(duì)比試驗(yàn)表明了合理構(gòu)造新特征對(duì)模型的提升幅度更為突出,而模型融合則能夠甚至超越最優(yōu)基模型,既避免了基模型選擇困難,也保持了模型的穩(wěn)定性。
不可忽視的是,本文提出的分類預(yù)報(bào)模型仍然存在空?qǐng)?bào)率較高、分類過(guò)于簡(jiǎn)單等不足,下一步將通過(guò)調(diào)整超參數(shù)和增加分類試驗(yàn)等方法繼續(xù)優(yōu)化和改進(jìn)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
