基于Hadoop的分布式日志分析系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
2024-01-23 15:19:30周德楊成慧羅佃斌
現(xiàn)代信息科技 2023年23期
周德 楊成慧 羅佃斌

摘? 要:網(wǎng)絡(luò)日志解析是確保監(jiān)控系統(tǒng)穩(wěn)定運(yùn)行和檢測(cè)故障的重要任務(wù)之一。然而,日志文件的數(shù)據(jù)量龐大,數(shù)據(jù)格式也相對(duì)復(fù)雜,難以手動(dòng)處理。在此背景下,對(duì)基于Hadoop分布式計(jì)算框架的網(wǎng)絡(luò)日志分析系統(tǒng)的設(shè)計(jì)和實(shí)現(xiàn)進(jìn)行了研究,通過將數(shù)據(jù)分解成塊,并通過多臺(tái)計(jì)算機(jī)并行處理數(shù)據(jù)塊來提高數(shù)據(jù)處理速度和效率。系統(tǒng)使用了Hadoop的MapReduce編程模型來實(shí)現(xiàn)網(wǎng)絡(luò)日志數(shù)據(jù)的解析和處理。實(shí)驗(yàn)結(jié)果表明,相比傳統(tǒng)方法,該系統(tǒng)具有更高的數(shù)據(jù)處理速度和可伸縮性,證明其有效性和實(shí)用性。
關(guān)鍵詞:網(wǎng)絡(luò)日志;Hadoop平臺(tái);分布式計(jì)算;MapReduce;日志分析
中圖分類號(hào):TP311.1? 文獻(xiàn)標(biāo)識(shí)碼:A? 文章編號(hào):2096-4706(2023)23-0057-04
Design and Implementation of Distributed Log Analysis System Based on Hadoop
ZHOU De, YANG Chenghui, LUO Dianbin
(College of Electrical Engineering, Northwest Minzu University, Lanzhou? 730030, China)
Abstract: Network log analysis is one of the important tasks to ensure the stable operation and fault detection of monitoring system. However, log files often contain a massive amount of data with complex formats, making manual processing difficult. In this context, we have researched the design and implementation of a network log analysis system based on the Hadoop distributed computing framework. By breaking down the data into smaller chunks and parallel processing them across multiple computers, we significantly improve the speed and efficiency of data processing. The system utilizes the MapReduce programming model of Hadoop to parse and process network log data. The experimental results demonstrate that this system has a higher data processing speed and scalability compared to traditional method, proving its effectiveness and practicality.
Keywords: network log; Hadoop platform; distributed computing; MapReduce; log analysis
0? 引? 言
隨著計(jì)算機(jī)技術(shù)的發(fā)展,數(shù)字化建設(shè)正在飛速推進(jìn),越來越多的系統(tǒng)被廣泛采用。為了保障系統(tǒng)的安全、方便故障排查以及實(shí)時(shí)監(jiān)控運(yùn)行狀況,查看日志已經(jīng)成為必要手段。管理員可以通過查看某一段時(shí)間內(nèi)的事件記錄,以及分析各個(gè)日志文件,來獲取有用信息。然而,日志數(shù)據(jù)量大且難以直接理解,僅僅依靠手動(dòng)查看難以挖掘其中的潛在價(jià)值。因此,日志分析和挖掘變得愈發(fā)重要。然而,傳統(tǒng)的技術(shù)難以應(yīng)對(duì)這些海量日志數(shù)據(jù)的存儲(chǔ)和計(jì)算量,在這種情況下,分布式計(jì)算技術(shù)成為備受關(guān)注的焦點(diǎn)。作為Apache Software Foundation旗下的著名開源項(xiàng)目,Hadoop一直致力于分布式計(jì)算技術(shù)的發(fā)展。近年來,Hadoop已經(jīng)成功地應(yīng)用于多個(gè)領(lǐng)域,包括網(wǎng)頁(yè)搜索、日志分析、廣告計(jì)算和科學(xué)實(shí)驗(yàn)等[1-3]。著名的社交網(wǎng)絡(luò)平臺(tái)Facebook就使用了由若干個(gè)節(jié)點(diǎn)組成的Hadoop集群,來進(jìn)行網(wǎng)站日志分析和數(shù)據(jù)挖掘。此外,像Amazon等許多IT巨頭也在使用Hadoop。因此,本文旨在探討如何利用Hadoop的技術(shù)模式,來構(gòu)建一個(gè)高效的分布式日志分析系統(tǒng)。這樣的系統(tǒng)將能夠更好地挖掘日志中蘊(yùn)藏的價(jià)值信息,從而提升系統(tǒng)管理水平以及改善用戶體驗(yàn)。
1? Hadoop平臺(tái)及重要組件
網(wǎng)絡(luò)行業(yè)的巨擘Google對(duì)Hadoop的具體應(yīng)用主要是通過他們自己開發(fā)的MapReduce框架來實(shí)現(xiàn)大規(guī)模數(shù)據(jù)處理。MapReduce是一個(gè)分布式計(jì)算框架,可以并行計(jì)算任務(wù)并返回結(jié)果。谷歌利用MapReduce框架進(jìn)行搜索引擎索引構(gòu)建、網(wǎng)絡(luò)爬蟲數(shù)據(jù)的處理和分析等大規(guī)模數(shù)據(jù)處理任務(wù)。
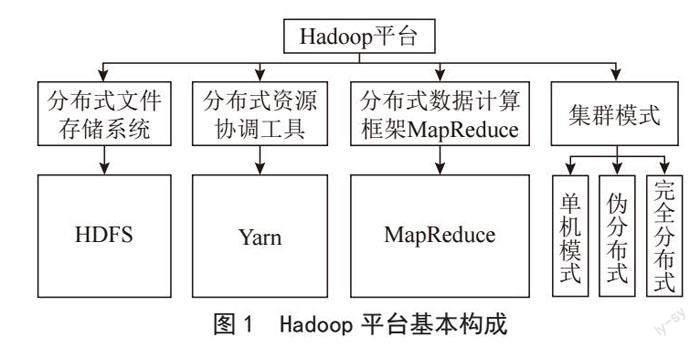
Hadoop平臺(tái)的基本構(gòu)成如圖1所示,Hadoop的三大核心組件分別是Hadoop分布式文件系統(tǒng)(HDFS)、MapReduce和YARN(Yet Another Resource Negotiator)。HDFS是一個(gè)分布式文件系統(tǒng),可以將大量數(shù)據(jù)存儲(chǔ)在集群的多個(gè)節(jié)點(diǎn)上,通過副本機(jī)制保證數(shù)據(jù)的可靠性和容錯(cuò)性。MapReduce是一個(gè)分布式計(jì)算框架,通過將任務(wù)分解成多個(gè)子任務(wù)并行計(jì)算,最后將結(jié)果合并返回,實(shí)現(xiàn)大規(guī)模數(shù)據(jù)的處理和分析。YARN是Hadoop的資源管理器,負(fù)責(zé)集群中的資源管理和任務(wù)調(diào)度,將不同的計(jì)算框架(如MapReduce、Spark等)進(jìn)行統(tǒng)一管理和調(diào)度[4]。Hadoop集群模式通常有三種形式:?jiǎn)螜C(jī)模式、偽分布式模式和完全分布式模式。單機(jī)模式主要用于開發(fā)和測(cè)試,偽分布式模式提供了與完全分布式模式相似的開發(fā)環(huán)境,但是所有的組件都在同一臺(tái)計(jì)算機(jī)上運(yùn)行,而完全分布式模式是在真正的分布式環(huán)境下運(yùn)行Hadoop,其可以實(shí)現(xiàn)大規(guī)模數(shù)據(jù)處理和分布式計(jì)算。偽分布式模式是常用的實(shí)驗(yàn)環(huán)境,它可以提供類似完全分布式模式的開發(fā)環(huán)境,同時(shí)也可以在一臺(tái)計(jì)算機(jī)上進(jìn)行操作。偽分布式模式可以在單臺(tái)計(jì)算機(jī)上模擬分布式環(huán)境,對(duì)于開發(fā)人員來說,可以在單臺(tái)計(jì)算機(jī)上進(jìn)行Hadoop應(yīng)用程序的編寫、測(cè)試和調(diào)試。同時(shí),在偽分布式模式下模擬多個(gè)計(jì)算機(jī)上的節(jié)點(diǎn),可以更好地理解和掌握Hadoop的分布式特性和運(yùn)行機(jī)制[5]。
2? 系統(tǒng)設(shè)計(jì)
2.1? 系統(tǒng)需求和功能
日志分析系統(tǒng)在保護(hù)系統(tǒng)安全、調(diào)查系統(tǒng)故障和監(jiān)控系統(tǒng)運(yùn)行狀況方面發(fā)揮著關(guān)鍵作用。隨著網(wǎng)絡(luò)和系統(tǒng)的復(fù)雜性增加,日志文件記錄的數(shù)據(jù)量也變得龐大且復(fù)雜。為了有效地管理和分析這些日志數(shù)據(jù),日志分析系統(tǒng)采用了分布式計(jì)算和存儲(chǔ)的方法。
日志分析系統(tǒng)收集來自各個(gè)應(yīng)用程序和系統(tǒng)的日志數(shù)據(jù),并將其存儲(chǔ)到分布式文件系統(tǒng)中,如Hadoop分布式文件系統(tǒng)(HDFS)。這種分布式存儲(chǔ)方案能夠處理大規(guī)模數(shù)據(jù),并提供高可靠性和可擴(kuò)展性。然后對(duì)存儲(chǔ)在分布式文件系統(tǒng)中的日志數(shù)據(jù)進(jìn)行預(yù)處理,通過日志數(shù)據(jù)的解析、標(biāo)準(zhǔn)化、異常檢測(cè)和去重等預(yù)處理操作,過濾掉不需要的信息,提取出有用的信息,并對(duì)數(shù)據(jù)進(jìn)行清洗和格式化,以便后續(xù)的分析和處理。
處理后的數(shù)據(jù)可以進(jìn)行多種分析和處理操作。例如,系統(tǒng)可以統(tǒng)計(jì)訪問次數(shù)、最常見的錯(cuò)誤類型、異常行為的檢測(cè)等。這些分析結(jié)果可以幫助管理員了解系統(tǒng)的使用情況、檢測(cè)潛在的安全問題和故障,并采取相應(yīng)的措施進(jìn)行處理和優(yōu)化[6-8]。
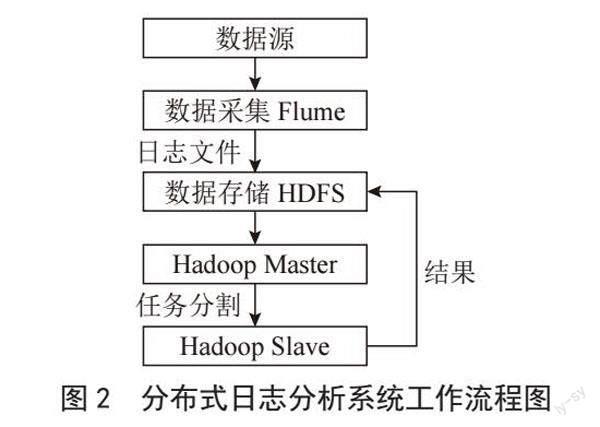
分析和處理的結(jié)果可以重新存儲(chǔ)到分布式文件系統(tǒng)中,以供后續(xù)查詢和可視化。管理員可以通過查詢工具或可視化界面來訪問和查看分析結(jié)果,從而更好地理解系統(tǒng)的運(yùn)行狀況和用戶行為,日志分析系統(tǒng)工作流程圖如圖2所示。總之,日志分析系統(tǒng)通過采用分布式計(jì)算和存儲(chǔ)的方式,能夠處理大規(guī)模、復(fù)雜的日志數(shù)據(jù),并提供有價(jià)值的信息和洞察。它在保護(hù)系統(tǒng)安全、調(diào)查故障和監(jiān)控系統(tǒng)運(yùn)行方面,為管理員提供了強(qiáng)大的工具和支持。通過日志分析系統(tǒng),管理員能夠及時(shí)發(fā)現(xiàn)潛在的問題,優(yōu)化系統(tǒng)性能,并提高整體的安全性和可靠性。
2.2? 系統(tǒng)架構(gòu)
該分布式日志分析系統(tǒng)包含三個(gè)層級(jí):數(shù)據(jù)采集層、數(shù)據(jù)預(yù)處理層和數(shù)據(jù)處理層。
數(shù)據(jù)采集層:數(shù)據(jù)采集層的任務(wù)是從各種數(shù)據(jù)源中收集日志數(shù)據(jù)并存儲(chǔ)在HDFS分布式文件系統(tǒng)中。為了實(shí)現(xiàn)這個(gè)過程,該系統(tǒng)使用了Apache Flume工具,用于采集日志文件并將其存儲(chǔ)到HDFS中。
數(shù)據(jù)預(yù)處理層:數(shù)據(jù)預(yù)處理層的任務(wù)是對(duì)原始的日志數(shù)據(jù)進(jìn)行解析、清洗和過濾等操作,然后將其傳遞到數(shù)據(jù)處理層。在該系統(tǒng)中,使用Hadoop對(duì)采集到的日志數(shù)據(jù)進(jìn)行了預(yù)處理,預(yù)處理結(jié)果保存在HDFS中的文件目錄下[9]。
數(shù)據(jù)處理層:數(shù)據(jù)處理層的任務(wù)是對(duì)預(yù)處理后的日志數(shù)據(jù)進(jìn)行分析和挖掘,包括日志聚合、異常檢測(cè)、關(guān)聯(lián)分析和機(jī)器學(xué)習(xí)等操作。在該系統(tǒng)中,數(shù)據(jù)處理層使用Hadoop對(duì)預(yù)處理后的數(shù)據(jù)進(jìn)行分析和挖掘,并生成有價(jià)值的信息。系統(tǒng)需要對(duì)預(yù)處理后的數(shù)據(jù)進(jìn)行分析和處理,例如統(tǒng)計(jì)每天的訪問次數(shù)、用戶的訪問次數(shù)等,以滿足用戶的分析和查詢需求[10]。通過這個(gè)系統(tǒng),可以獲取日志數(shù)據(jù)分析后的結(jié)果,并通過各種分析技術(shù)挖掘出數(shù)據(jù)中的潛在價(jià)值。
3? 系統(tǒng)實(shí)現(xiàn)
3.1? 數(shù)據(jù)采集層
使用Apache Flume來采集日志文件系統(tǒng)的日志文件,并將采集到的數(shù)據(jù)保存到HDFS分布式文件系統(tǒng)中。Flume的數(shù)據(jù)流通常包括三個(gè)主要組件:Source(數(shù)據(jù)源),Channel(通道)和Sink(數(shù)據(jù)存儲(chǔ)器)。本文使用exec source作為數(shù)據(jù)源,即通過執(zhí)行shell命令來讀取指定的日志文件。然后使用HDFS sink將讀取的數(shù)據(jù)寫入到HDFS的指定目錄中的文件中。
以下是整個(gè)過程的步驟實(shí)現(xiàn):
在安裝和配置Flume之前,首先安裝并配置Java和Hadoop環(huán)境。并下載和解壓縮Flume二進(jìn)制文件。其次在conf目錄下創(chuàng)建一個(gè)新的配置文件來配置數(shù)據(jù)源和數(shù)據(jù)存儲(chǔ)器。具體則需要為exec source指定日志文件路徑,為HDFS sink指定HDFS目錄路徑等。啟動(dòng)Flume需要使用flume-ng命令,并指定Flume配置文件的路徑。執(zhí)行以上命令后,F(xiàn)lume將開始讀取指定的日志文件,將數(shù)據(jù)寫入到HDFS的指定目錄中。Flume會(huì)使用exec source讀取日志文件,將數(shù)據(jù)寫入到memory channel中。再次,HDFS sink從channel中獲取數(shù)據(jù),并將數(shù)據(jù)寫入到HDFS目錄中的指定文件中。最后驗(yàn)證數(shù)據(jù)是否被成功寫入到HDFS文件中。
3.2? 數(shù)據(jù)預(yù)處理層
將存儲(chǔ)在HDFS中的數(shù)據(jù)進(jìn)行預(yù)處理,最終將結(jié)果存儲(chǔ)在HDFS中的email_log_with_date.txt文件中。在這個(gè)過程中,在執(zhí)行Hadoop相關(guān)操作之前必須要確認(rèn)Hadoop集群環(huán)境是否正常。確保集群中所有的節(jié)點(diǎn)都處于正常運(yùn)行狀態(tài),Hadoop的各項(xiàng)服務(wù)也已經(jīng)啟動(dòng)。使用Hadoop MapReduce程序?qū)?shù)據(jù)進(jìn)行處理。該系統(tǒng)中,需要對(duì)每一行數(shù)據(jù)進(jìn)行處理,提取出其中的電子郵件地址和日期。使用TextInputFormat類讀取輸入文件,使用MapReduce程序?qū)斎胛募M(jìn)行處理,提取出每一行中的電子郵件地址和日期,并輸出到一個(gè)新的文件中。程序的主要步驟如下:
Mapper階段:讀取輸入文件的每一行,使用正則表達(dá)式提取出電子郵件地址和日期,將其作為鍵值對(duì)輸出,鍵是電子郵件地址,值是日期。
Reducer階段:收集來自Mapper的鍵值對(duì),將具有相同電子郵件地址的鍵值對(duì)歸并在一起,并輸出到輸出文件中。將處理結(jié)果存儲(chǔ)到HDFS中,并檢查處理結(jié)果。
3.3? 數(shù)據(jù)處理層
統(tǒng)計(jì)每天訪問次數(shù):要求統(tǒng)計(jì)網(wǎng)站每天的訪問次數(shù)和訪問人數(shù),將日志預(yù)處理后的數(shù)據(jù)進(jìn)行統(tǒng)計(jì)。將數(shù)據(jù)輸入第一個(gè)Map任務(wù)中,在鍵值對(duì)轉(zhuǎn)換過程中不需要關(guān)心哪個(gè)用戶登錄,只統(tǒng)計(jì)這一天用戶登錄次數(shù)。
統(tǒng)計(jì)各用戶訪問次數(shù):要求統(tǒng)計(jì)每個(gè)用戶的訪問次數(shù)并按用戶的訪問次數(shù)排序,將日志預(yù)處理后的數(shù)據(jù)進(jìn)行統(tǒng)計(jì),在鍵值對(duì)轉(zhuǎn)換流程中,shuffle過程其實(shí)是會(huì)涉及鍵的排序,shuffle會(huì)對(duì)鍵進(jìn)行排序,利用這一點(diǎn),達(dá)到用戶訪問次數(shù)排序的目的。
4? 實(shí)驗(yàn)和分析
4.1? 數(shù)據(jù)集
使用Apache Flume來采集日志文件系統(tǒng)的日志文件,并將采集到的數(shù)據(jù)保存到分布式文件系統(tǒng)HDFS中,采集結(jié)果部分內(nèi)容如圖3所示。
4.2? 統(tǒng)計(jì)每天訪問次數(shù)
要求統(tǒng)計(jì)網(wǎng)站每天的訪問次數(shù)和訪問人數(shù),采集數(shù)據(jù)集預(yù)處理結(jié)果如圖4所示。將數(shù)據(jù)輸入第一個(gè)Map任務(wù),在鍵值對(duì)轉(zhuǎn)換流程中,因?yàn)椴恍枰y(tǒng)計(jì)哪個(gè)用戶登錄,只統(tǒng)計(jì)這一天有多少用戶登錄,把鍵值key設(shè)置為:日期,value設(shè)置為:1。Map輸出結(jié)果中key值為用戶訪問時(shí)間,value值為count計(jì)數(shù)1,再經(jīng)過reduce對(duì)其Map輸出結(jié)果進(jìn)行疊加得到統(tǒng)計(jì)結(jié)果,按每天訪問次數(shù)統(tǒng)計(jì),統(tǒng)計(jì)結(jié)果如圖5所示。
4.3? 按用戶統(tǒng)計(jì)訪問次數(shù)
要求統(tǒng)計(jì)每個(gè)用戶的訪問次數(shù)并按用戶的訪問次數(shù)排序,待統(tǒng)計(jì)日志數(shù)據(jù)內(nèi)容與統(tǒng)計(jì)每天訪問次數(shù)實(shí)驗(yàn)中相同,在鍵值對(duì)轉(zhuǎn)換流程中,shuffle過程其實(shí)是會(huì)涉及鍵的排序,shuffle會(huì)對(duì)鍵進(jìn)行排序,利用此特征,達(dá)到用戶訪問次數(shù)排序的目的,本次實(shí)驗(yàn)涉及兩個(gè)Map任務(wù),第一個(gè)Map任務(wù)與按時(shí)間訪問統(tǒng)計(jì)次數(shù)中相類似,但是key值為:email_address,再通過reduce疊加之后,得到中間數(shù)據(jù),作為第二個(gè)Map任務(wù)的輸入數(shù)據(jù),第二個(gè)Map任務(wù)的輸入數(shù)據(jù)如圖6所示,該Map任務(wù)是對(duì)數(shù)據(jù)進(jìn)行key值和value值進(jìn)行分割后互換,再進(jìn)行結(jié)果統(tǒng)計(jì),實(shí)驗(yàn)結(jié)果如圖7所示。
5? 結(jié)? 論
基于Hadoop的系統(tǒng)具有高可靠性和可擴(kuò)展性的特點(diǎn),可以應(yīng)對(duì)大規(guī)模數(shù)據(jù)處理的需求:
1)分布式日志分析系統(tǒng)相比傳統(tǒng)系統(tǒng)具有更高的數(shù)據(jù)處理速度。通過并行計(jì)算和分布式存儲(chǔ),系統(tǒng)能夠更快地處理大規(guī)模的日志數(shù)據(jù),提供實(shí)時(shí)或接近實(shí)時(shí)的分析結(jié)果。
2)具有良好的可伸縮性。可以根據(jù)數(shù)據(jù)量的增長(zhǎng)和需求的變化,靈活地?cái)U(kuò)展計(jì)算資源,以應(yīng)對(duì)不斷增長(zhǎng)的日志數(shù)據(jù)和分析任務(wù)。
3)成本降低。傳統(tǒng)的日志分析系統(tǒng)通常需要昂貴的硬件設(shè)備和專門的日志分析軟件,相比之下,基于Hadoop的系統(tǒng)可以利用廉價(jià)的商用硬件構(gòu)建大規(guī)模集群,并使用開源的Hadoop框架和工具,從而降低了系統(tǒng)的成本。
4)具有高度的容錯(cuò)性和可靠性。通過數(shù)據(jù)冗余和自動(dòng)故障恢復(fù)機(jī)制,系統(tǒng)可以保證在計(jì)算節(jié)點(diǎn)故障或數(shù)據(jù)損壞的情況下,仍能完成日志分析任務(wù),并保持?jǐn)?shù)據(jù)的完整性和可靠性。
參考文獻(xiàn):
[1] 程苗,陳華平.基于Hadoop的Web日志挖掘 [J].計(jì)算機(jī)工程,2011,37(11):37-39.
[2] 陳彬.基于Hadoop框架的海量數(shù)據(jù)運(yùn)營(yíng)系統(tǒng)研究 [J].自動(dòng)化技術(shù)與應(yīng)用,2020,39(3):178-181.
[3] 付偉.基于Hadoop的Web日志的分析平臺(tái)的設(shè)計(jì)與實(shí)現(xiàn) [D].北京:北京郵電大學(xué),2015.
[4] APACHE.Hadoop官方文檔 [EB/OL].[2023-04-03].https://hadoop.apache.org/docs/stable/.
[5] 周少珂,王雷,崔琳,等.大數(shù)據(jù)Hadoop技術(shù)完全分布式集群部署 [J].工業(yè)控制計(jì)算機(jī),2021,34(8):101-103.
[6] 賈文鋼,高錦濤.基于HDFS的海量日志數(shù)據(jù)冗余點(diǎn)過濾算法仿真 [J].計(jì)算機(jī)仿真,2021,38(12):241-244+249.
[7] 陸勰,羅守山,張玉梅.基于Hadoop的海量安全日志聚類算法研究 [J].信息網(wǎng)絡(luò)安全,2018(8):56-63.
[8] 張平.并行計(jì)算模型MapReduce的工作原理探究 [J].吉林廣播電視大學(xué)學(xué)報(bào),2021(6):154-157.
[9] 李博,顏靖藝.基于Hadoop的流量日志分析系統(tǒng) [J].桂林航天工業(yè)學(xué)院學(xué)報(bào),2021,26(4):412-420.
[10] 祁春霞.基于Hadoop的網(wǎng)絡(luò)日志瀏覽器訪問者統(tǒng)計(jì) [J].信息技術(shù)與信息化,2021(1):110-112.
作者簡(jiǎn)介:周德(1997—),男,漢族,甘肅武威人,碩士研究生在讀,研究方向:大數(shù)據(jù)分析與挖掘;通訊作者:楊成慧(1982—),女,漢族,甘肅蘭州人,教授,博士研究生,研究方向:計(jì)算機(jī)系統(tǒng)仿真與建模、智能控制;羅佃斌(1997—),男,漢族,山東德州人,碩士研究生在讀,研究方向:智能控制。
