面向Kubernetes 的容器混合伸縮方法?
2024-01-23 13:37:32柳雪妍蔡志成
計算機與數(shù)字工程 2023年10期
柳雪妍 蔡志成 徐 建
(南京理工大學計算機科學與工程學院 南京 210094)
1 引言
云計算的彈性伸縮能力,使得用戶可以按需地從云計算資源池中獲取或釋放計算資源[1],并且僅需為所使用部分付費,大幅度降低了企業(yè)的成本,同時還滿足用戶快速部署微服務應用的需求。因此,越來越多的互聯(lián)網企業(yè)將它們的微服務遷移到云數(shù)據(jù)中心中。然而,在實際應用中,為了應對實時波動的微服務請求負載,大多數(shù)用戶采用預先給應用分配過量資源的方法,造成了大量的資源浪費和高昂的成本開銷[1]。針對微服務系統(tǒng)負載動態(tài)變化的特點,設計并實現(xiàn)高效的云計算資源調度算法,自動增加或減少分配給應用的資源,從而在保證用戶服務水平協(xié)議(SLA)的前提下,最小化云計算資源的成本,一直是云計算領域的關鍵問題和嚴峻挑戰(zhàn)。
傳統(tǒng)的云計算架構以虛擬機為基本單元進行資源調度,這種大粒度的資源調度存在資源利用率低、虛擬機啟停緩慢等問題[4]。容器技術的出現(xiàn),引發(fā)了云計算資源管理的新革命[1]。相較于虛擬機架構,容器云采用輕量級虛擬化技術,可以快速創(chuàng)建容器和部署應用[3]。以容器為單位進行資源分配和調度,降低了由虛擬機啟動緩慢而導致的資源調度延遲,進一步提高了云計算平臺的性能[2]。
目前,研究人員已提出大量基于虛擬機的動態(tài)資源調度算法。Chenhao Q對現(xiàn)有的云環(huán)境中虛擬機的動態(tài)調度算法進行了較為全面的分析和總結[1]。其中,基于規(guī)則的自動伸縮方法被工業(yè)界廣泛采用,例如亞馬遜的Amazon Auto-Scaling Service[5]。但是這種基于規(guī)則的自動伸縮方法缺乏對資源性能的準確估計,需要充分掌握應用的特征及專家知識以確定適當?shù)拈撝岛筒僮鳌榱藴蚀_估計所需的資源能力,學術界基于排隊理論建立了各種性能模型,例如李磊提出一種基于李雅普諾夫隊列模型的任務和資源調度優(yōu)化策略[2],Cai 采用具有到達率調節(jié)系數(shù)的排隊模型作為前饋控制器以預測所需資源量[6]。另一部分研究者利用機器學習技術,動態(tài)構建特定負載下的資源消耗模型,例如Bitsakos C 使用深度強化學習來實現(xiàn)資源的自動伸縮[7],徐建中等使用反向傳播神經網絡建立一個基于需求預測的云計算彈性伸縮策略[8]。
然而,針對容器云的調度算法研究才剛剛起步。由于基于虛擬機的資源調度和基于容器的資源調度的核心需求是相似的,研究人員通常將基于虛擬機的彈性伸縮算法直接用于基于容器的系統(tǒng)。例如,楊茂等提出一種預測式與響應式相結合的水平伸縮算法[9],屠雪真等設計了一種基于Kubernetes的水平彈性擴縮容系統(tǒng)[10]。這類方法雖然簡單快速,但未考慮到容器本身配置的調整,僅考慮了容器的水平擴展,忽略了容器的垂直擴展。這類方法難以設置恰當?shù)娜萜髻Y源配額,導致集群資源的浪費[11]。
因此,針對已有研究存在的不足,本文針對基于Kubernetes 的真實異構容器云環(huán)境,提出了一種基于排隊、深度性能模型和快速啟發(fā)式規(guī)則的容器資源混合伸縮算法MMHV。對比實驗表明,本算法能夠在保證微服務請求服務質量的前提下,使得容器資源配額隨工作負載變化而動態(tài)調整,從而提高異構集群的資源利用率、有效降低云計算資源的成本。
2 Kubernetes容器云
Kubernetes[11]是Google開源的一個大型容器集群管理系統(tǒng)。其作為容器云的核心基礎和事實標準,已經成為當今互聯(lián)網企業(yè)的云基礎設施核心要素。它可以為容器化的云原生應用提供部署、運行、服務發(fā)現(xiàn)、資源調度、擴縮容等功能。
如圖1 所示,Kubernetes 集群由一個Master 和多個Node 組成。Master 是集群的控制節(jié)點,其上運行著Kubernetes API Server 等集群管理相關的關鍵進程。這些進程實現(xiàn)了整個集群的資源管理、Pod 調度、系統(tǒng)監(jiān)控和糾錯等自動化管理功能[12]。Node 是集群中的工作節(jié)點,其上運行著多個Pod,每個Pod 中運行著一個應用程序的一組(一個或多個)容器,一般場景中,每個Pod 只包含一個容器。Kubernetes 直接管理Pod 而非容器,Pod 是Kubernetes 中資源調度的基本單位。同一微服務的用戶請求被Nginx Ingress Controller 分發(fā)到并行容器中。資源控制中心可以通過Kubernetes 提供的客戶端接口采集集群的運行數(shù)據(jù),實現(xiàn)應用性能的實時監(jiān)控,并根據(jù)資源調度方法動態(tài)調整分配給應用的資源。

圖1 Kubernetes中容器云的架構圖
本文的目標是針對基于Kubernetes 的真實容器云環(huán)境,設計容器數(shù)量和配置自動伸縮算法,在保證滿足用戶請求響應時間上限約束(由SLA 指定)的同時,降低微服務的資源成本。
3 水平自動伸縮機制
Kubernetes 已有的水平自動伸縮控制器(HPA),可基于CPU 利用率實現(xiàn)Pod 數(shù)量的自動伸縮[13]。在使用HPA 時,用戶需事先設定CPU 利用率的目標值。在每個控制周期,HPA 控制器根據(jù)Pod 的實時CPU 利用率與用戶設定目標值的比例計算所需的目標副本數(shù)量,具體計算公式如下:
其中,Cr和Cv分別是當前副本數(shù)及當前CPU 利用率,Dr和Dv分別是目標副本數(shù)及目標CPU 利用率。當Pod 的目標副本數(shù)與當前副本數(shù)不同時,HPA 就向Pod 的副本控制器發(fā)起Scale 操作,調整Pod的副本數(shù)量,完成擴縮容操作。
盡管HPA控制器簡單有效,但只是從Pod數(shù)量層面進行調整(水平伸縮),在實際應用中還需要對每個Pod 設置恰當?shù)馁Y源配額(CPU 和內存的大小),資源配額過大將導致集群資源的無謂浪費,過小則會導致應用性能不佳。然而,用戶需要對應用程序有足夠了解,并進行大量配置和試驗,才能對Pod設置恰當?shù)馁Y源配額。
4 容器云混合伸縮算法
針對HPA 按CPU 利用率比例調整方法的不足,本文提出的MMHV 采用排隊模型更加準確地描述目標響應時間和所需總處理能力之間的關系;同時利用深度神經網絡建立高精度的單個容器處理能力和不同配置的關系模型;基于排隊模型獲得所需的總能力和深度性能模型,MMHV根據(jù)啟發(fā)式規(guī)則能夠更加快速準確地找到恰當?shù)母北緮?shù)量和資源配額,具體包括:1)基于M/M/1 排隊模型和給定的服務響應時間約束計算當前負載下的目標總處理率;2)以真實的異構容器云的運行數(shù)據(jù)為基礎,使用深度神經網絡建立容器資源配置(CPU 和內存的大小)與請求處理率的關系模型;3)基于集群中異構虛擬機上剩余CPU和內存的大小,采用基于排序和二分搜索相結合的容器資源配置快速搜索方法,獲得使處理率不小于目標值且成本最小的容器資源配置方案。
4.1 容器云排隊模型
如文獻[1]所述,對于單個微服務,可以將其用戶請求處理過程抽象為一個排隊模型。如圖2 所示,一個微服務有n 個并發(fā)Pod。隨機到達的用戶請求進入Nginx負載均衡器維護的共享隊列,Nginx以輪詢的方式將請求轉發(fā)給Pod進行處理。

圖2 用戶請求排隊模型
假設微服務的用戶請求到達率為λ且時間間隔服從負指數(shù)分布,同時所有Pod 的請求處理率之和為μ且請求處理時間也服從負指數(shù)分布,則可以使用單隊列等待制M/M/1排隊模型建模。根據(jù)Little公式,可得到請求的平均響應時間[14]:
4.2 基于深度神經網絡的性能模型
通過觀察采集的樣本數(shù)據(jù),我們發(fā)現(xiàn)CPU、內存的資源量與請求處理率之間是一種非線性關系,因此我們選擇了一種簡單高效的非線性回歸模型MLP(多層感知器)進行建模。MLP[15]是一種監(jiān)督學習算法,它通過訓練數(shù)據(jù)集學習一個函數(shù)f(?):Rm→Ro,其中m 是輸入的維數(shù),o 是輸出的維數(shù)。給定一組特征X=x1,x2,…,xm和一個目標y,它可以準確高效地逼近非線性函數(shù)。具體步驟如下:1)將一個微服務以容器的形式部署在Kubernetes 集群中;2)對運行微服務的Pod 分配不同的CPU 和內存(c,m),使用壓力測試工具發(fā)送并發(fā)請求,并采集請求響應時間數(shù)據(jù),進而得到當前資源配置(c,m)對應的請求處理率μ;3)使用深度神經網絡構建性能回歸模型,以CPU和內存的資源配置(c,m)作為二維的輸入特征,以請求處理率μ作為目標輸出,構建一個具有兩層隱藏層、每層含有100 個神經元的深度神經網絡,并按照80%和20%的比例將樣本數(shù)據(jù)劃分為訓練集和測試集。圖3 是我們實驗中訓練得到的模型,其在測試集上取得了0.985 的分數(shù)(分數(shù)越接近1 說明模型的擬合精度越高)。將CPU 和內存的資源配置(c,m)輸入訓練好的網絡模型f(c,m),即可獲得對應的請求處理率μ。
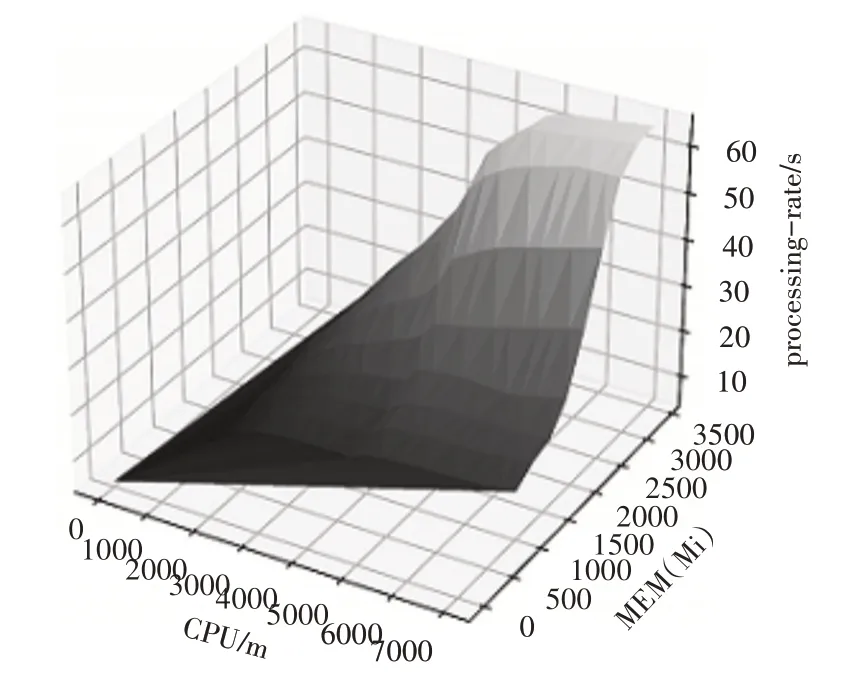
圖3 訓練得到的性能模型
4.3 異構環(huán)境感知的混合伸縮算法
基于上述排隊模型和容器性能模型,本文提出一種異構環(huán)境感知的容器資源混合伸縮方法MMHV,正式描述如算法1所示。
首先,在每個控制時刻t,通過采集集群的運行數(shù)據(jù)獲得集群中各個Node 節(jié)點i 上的可用資源量(ci,mi)、當前時刻t的請求到達率λt,以及請求的平均響應時間yt。如果yt>WSLA,說明資源配置不足需要增加資源;如果λt相較于上一次資源調整時的請求率λs下降超過10%,說明資源配置比較充足,可以減少資源。上述兩種情況均會觸發(fā)資源調整動作。
為了確定適當?shù)馁Y源配置方案,首先基于公式(3)計算出t時刻的目標處理率μo。接著將各節(jié)點i 的可用資源量(ci,mi)以CPU 的大小遞增排序。令Pod 副本數(shù)r 從1 開始遞增,且對于每一種情況,遍歷各節(jié)點的可用資源量(ci,mi),將其輸入訓練好的深度性能模型f(c,m)→μ得到該配置方案對應的處理率μ,直到找到大于或等于目標處理率μo的配置方案(c',m')。若μ恰好 等于μo,計算該配置方案的成本,并將其與最小成本Costmin比較。若μ大于μo,此時雖然可以滿足SLA,但資源可能存在冗余,因此令l=(0,0),?=(c',m'),m=(l+?)/2,以二分法搜索恰好使得μ大于μo的配置方案直到(?-l)小于資源的最小調整量d,此時的Pod 資源請求量組合(c*,m*)及Pod 副本數(shù)r*即為最佳配置方案。最后,利用Kubernetes 的客戶端接口調整Pod 的副本數(shù)及CPU 和內存的大小,完成資源調度。
算法1:異構環(huán)境感知的容器混合伸縮算法MMHV
5 實驗驗證
我們在真實的Kubernetes 集群上驗證所提出的容器混合伸縮方法的性能,并與已有算法進行了對比。
5.1 實驗環(huán)境與參數(shù)設置
本實驗使用兩臺配置為Intel? Xeon? Silver 4210 40 核心CPU 和48GB 內存的服務器搭建了一個Kubernetes 集群,集群由5 臺虛擬機組成:1 臺具有4 核CPU、4GB 內存的Master 節(jié)點,2 臺具有4 核CPU、4GB 內存的Node 節(jié)點,其余2 臺為具有8 核CPU、4GB內存的Node節(jié)點。將一個計算序列累加值和集合查找的微服務應用以容器的形式部署在集群上,并使用JMeter 作為壓力測試工具發(fā)送請求。
實驗通過重放WikiBench 提供的用戶訪問維基百科的歷史流量數(shù)據(jù)[16]進行壓力測試。并設響應時間上限為WSLA=0.1s。實驗參考阿里云通用型ecs.g6.large實例按量付費的定價,根據(jù)官方文檔可計算得出CPU 的單價為每小時0.14 元/核,內存的單價為每小時0.0275 元/Gi。調度算法的控制時間間隔為300s。
5.2 實驗結果與分析
本文從請求響應時間和資源成本兩方面將MMHV 算法與HPA 算法[13]以及同樣使用了M/M/1排隊模型的UCM算法[6]進行了對比。
圖4、圖5、圖6 分別顯示了HPA 算法、UCM 算法和MMHV 算法的響應時間分布情況。可以看出,三種算法的大多數(shù)響應時間都小于WSLA,其中HPA 算法的響應時間波動性最小,MMHV 算法次之,UCM 算法波動性最大。這是由于UCM 算法以虛擬機為基本單位進行資源調度,在調度時刻虛擬機創(chuàng)建和啟動延遲導致請求響應時間波動和SLA違反率變大,而HPA 算法和MMHV 算法以容器為單位進行調度,可以快速地創(chuàng)建啟動容器完成資源調整動作,減少響應時間的波動及SLA違反率。

圖4 HPA算法響應時間分布
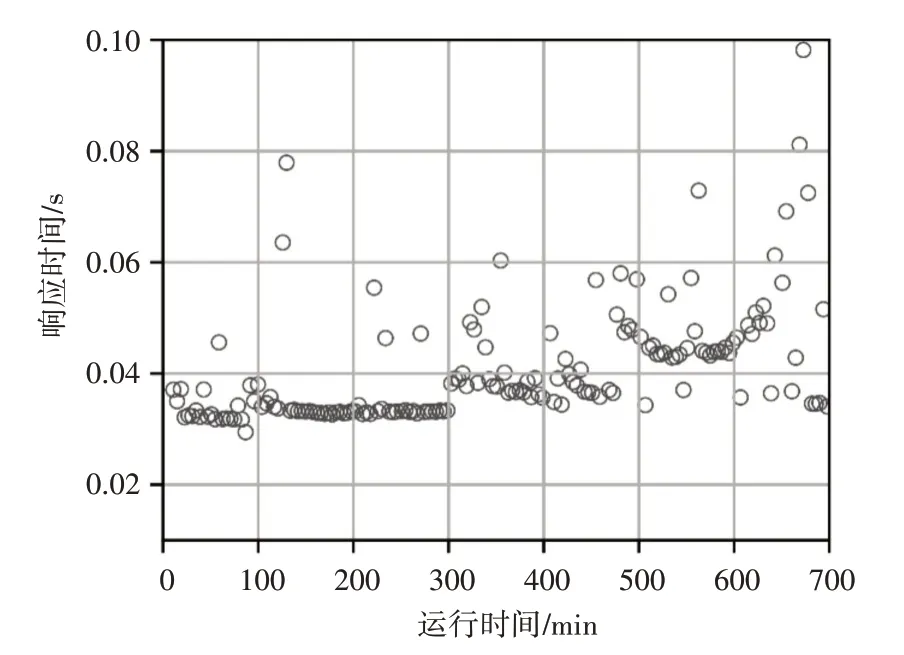
圖5 UCM算法響應時間分布
圖7 顯示了三種算法的累計資源成本隨時間的變化曲線,可以看出在相同的負載下,MMHV 算法所需的資源成本最低。UCM 算法以虛擬機為單位進行租賃,在某臺虛擬機的利用率較低但又不能直接關閉的情況下,仍然需要為它付費,這種大粒度的租用方式必然導致資源成本最高。而HPA 和MMHV按照資源的使用量計費,因此它們消耗的資源成本相對較低。與HPA 算法動態(tài)調整Pod 的數(shù)量相比,MMHA 由于可以更加細粒度地調整Pod 的資源配額,使得容器資源供應量更加接近資源需求量,減少了不必要的資源開銷,因此資源消耗成本最低。

圖7 三種算法資源成本對比
6 結語
已有的容器調度算法大多只在容器數(shù)量上水平伸縮,這種方法沒有考慮底層物理資源的剩余情況,難以設置恰當?shù)娜萜髻Y源配額,導致集群資源的浪費。針對上述問題,本文提出了一種面向Kubernetes 的容器混合伸縮方法,該方法采用排隊模型計算應用所需的處理能力,以基于深度神經網絡的容器性能模型為基礎,將處理能力映射為具體的容器混合伸縮配置方案。基于Kubernetes 集群上的實驗結果表明,在保證服務水平協(xié)議(SLA)的前提下,該方法相較于Kubernetes 自帶方法和其他方法資源消耗成本最低。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
江蘇安全生產(2023年1期)2023-02-08 05:58:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
小天使·一年級語數(shù)英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
