基于Spark平臺的異常流量實時檢測
2024-01-27 16:44:03閻紅燦王小雨劉盈
電腦知識與技術 2023年36期
閻紅燦 王小雨 劉盈

摘要:傳統的流量檢測方法在大規模、大流量網絡環境下不能滿足對異常流量檢測的準確性和實時性要求,基于此,該文構建了一個基于spark平臺的分布式流量實時檢測模型。該模型使用LibPcap、Flume、SparkStreaming實現分布式流量采集、上傳和實時計算,以滿足大流量場景下實時性需求;通過CNN網絡提取流量載荷內容特征和雙向流量統計特征,基于Stacking算法進行模型融合,提高了檢測準確性;使用CIC-IDS-2018數據集對該模型進行了測試。實驗結果表明,該模型能夠滿足大流量環境下異常流量檢測的準確性和實時性要求。
關鍵詞:SparkStreaming;分布式流量檢測;CNN;Stacking;模型融合
中圖分類號:TP393? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)36-0062-04
開放科學(資源服務)標識碼(OSID)
0 引言
隨著網絡技術的發展,針對互聯網的攻擊手段愈來多樣化,其所帶來的威脅也在不斷提升,對流量進行異常檢測也越顯必要。當前的入侵檢測模型主要有基于統計分析的檢測方法[1-3],對流量特征進行統計分析并建立特征庫,通過對比特征庫的方式來識別異常流量;基于分類的檢測方法[4-7],通過訓練分類器來識別正常和異常流量;基于聚類的檢測方法[8-11],通過相似度和聚類將流量數據聚合成不同的類來達到流量檢測的目的,屬于無監督學習算法。
無論是基于統計、分類還是聚類的檢測方法,都需要提取好流量的特征才能進行下一步工作,因此需要解決大量數據處理的問題。作為一個分布式計算平臺,Spark具有高性能、低延遲、可擴展等特性[12],非常適合處理大量流量數據,而且基于機器學習的流量檢測方法具有準確率高、擴展性強等特點。本文將二者結合起來,設計一個異常檢測模型可滿足海量流量環境下對準確率和實時性的要求。
1 相關知識概述
1.1 處理大流量數據相關技術
1)Spark
Spark是一個基于內存的并行計算框架[13],其核心組件有分布式圖計算框架GraphX、結構化數據查詢模塊SparkSql、實時流計算引擎SparkStreaming[14]、機器學習模塊MLib。其中,SparkStreaming 是為了解決大數據環境下的實時計算而誕生的,它引入了DStream作為抽象數據表示,存儲的是伴隨著時間窗口變化的數據序列,支持對數據流通過map、join、reduce、window等函數進行復雜的實時計算,為異常檢測模型提供了流量清洗和實時計算的功能。
2)Flume
Flume是一個基于數據流的分布式日志采集、聚合和傳輸系統[15],具有高可用、高可靠等特點。Agent是Flume的核心組件,包括Source、Sink、Channel三個部分。Source用來收集數據并將數據序列化成Event,之后Channel將經過序列化的數據Event進行緩存,再由Sink將數據發送到目的地。每一個Flume采集服務由許多Agent串聯形成,在異常檢測模型中扮演流量采集和上傳的角色。
3)Kafka
Kafka是一個基于發布-訂閱的分布式消息服務[16],支持實時數據處理。Kafka包含Producer、Topic、Partition、Consumer等組件,Produce將數據發布到Topic,Consumer根據Topic從broker中讀取數據。由于Kafka使用了磁盤順序讀寫、零拷貝、批量壓縮等技術,使其能夠實現每秒幾十萬的超高吞吐量,適合大數據環境下的實時流處理,在異常檢測模型中被用來緩存流量數據。
1.2 模型融合應用的機器學習算法
1)支持向量機
支持向量機是一種有監督的學習算法,其基本思想就是讓支持向量到超平面的距離最大化。使用核函數來解決非線性問題,通過求解對偶拉格朗日函數來進行優化,其最后的決策函數如:
[y=signi=1mj=1mαiαjyiyjkxi,xj+b]? ? (1)
其中,
2)邏輯回歸
邏輯回歸是一個基于概率的分類算法,常被應用于二分類問題,也可以被擴展多分類模型,其在線性回歸的基礎上加入了Sigmoid函數,使最終的預測值落于[0,1]區間,從而達到分類的目的。Sigmoid 函數如下:
[fx=11+e-x]? ? ? ? ? ? ? ? ? ? ? ? ? (2)
3)隨機森林
隨機森林是利用bagging策略將多個決策樹組合進行分類預測的一種算法單一預測效果準確率可能不高,通過多棵不相關的決策樹組成一個隨機森林,當需要對新樣本預測時,讓每個決策樹都進行預測,然后通過投票加權的機制,選出最終的預測結果,達到提高預測準確度的效果。
4)決策樹
決策樹是一種樹形結構的監督學習算法[17],其葉子節點代表一種預測結果,中間節點代表一種決策,構建算法有C4.5、ID3、CART三種。本文采用CART算法去構建決策樹。CART算法使用二叉樹去構建決策樹,使用最小基尼系數去進行特征選擇。基尼系數公式如下:
[GiniD=1-k=1KCkD2]? ? ? ? ? ?(3)
[GiniD|A=D1DGiniD1+D2DGiniD2]? ? ? ? (4)
其中,|D|表示數據集D的數據總量,D1和D2則表示子樣本集。
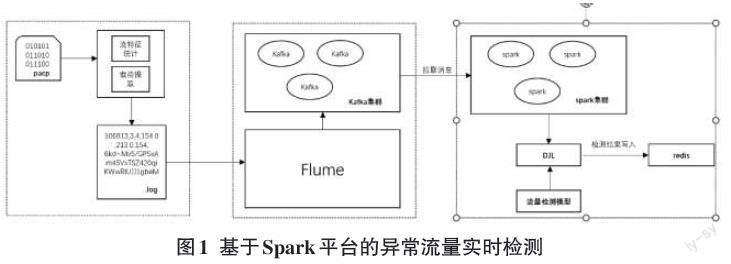
2 基于Spark的異常流量檢測框架
本文提出的基于Spark的檢測框架共分為網絡流量獲取與流量特征提取、流量日志的傳輸、流量實時檢測三個部分。
1)網絡流量獲取與流量特征提取
通過LibPcap去監聽網卡,實時生成Pcap格式數據包,通過CICflowmeter提取流量的數據流統計特征和載荷內容,按當前日期(年-月-日)生成日志文件。
2)流量日志的傳輸
通過Flume,將日志文件上傳到Kafka消息隊列中。
3)流量實時檢測
SparkStreaming[18]與Kafka集群對接,將獲取流量數據載入生產DStream并進行預處理,通過DJL(DJL是一個開源的、無關引擎的Java深度學習框架,提供了一個統一的調用接口,可以用來部署各種深度學習和機器學習模型)去調用訓練好的檢測模型預測流量,最終將檢測結果存儲到redis集群中。
3 基于Spark的分布式異常流量檢測模型
3.1 數據集特征提取及預處理
數據集選用CIC-IDS-2018[19],該數據集類似實際的攻擊數據,包含了最新的常規攻擊流量,其數據采集于周一至五。其中,周一為正常流量,周二至周五的上午和下午分別采集了暴力FTP、DOS、Heartbleed、Web攻擊、滲透、僵尸網絡、DDoS攻擊。
對CIC-IDS-2017數據集中共計48G的Pcap文件,使用CICflowmeter提取83個流量特征和流量前784字節有效載荷。將載荷經過Base64編碼和流量特征一起寫入csv文件中。通過Spark框架去加載和預處理提取好的csv文件,由于數據中存在少量的Nan和Infiniti的臟數據,因此刪除包含臟數據的向量。提取的數據集攻擊類型及數量如下表1所示。
由于提取的流量特征中包含不同的量綱和數量集,所以對提取流量特征進行了均值方差歸一化處理。公式如下:
[x*=x-μδ]? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(5)
其中,μ為所有樣本數據的均值,σ為所有樣本數據的標準差。
3.2 基于CNN網絡載荷特征和流統計特征融合
CNN是一種為處理多維數據特別設計的前饋神經網絡[20],通常由卷積層、全連接層三部分組成。
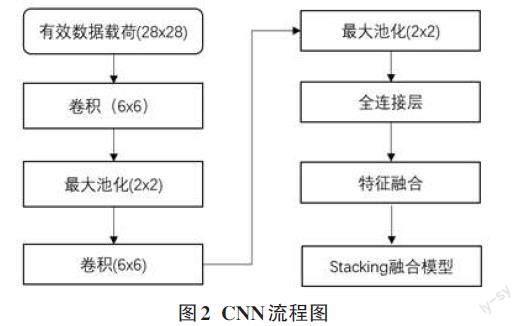
本方案提出的檢測模型的輸入有兩個,分別為83維的流量統計特征和784字節的有效載荷內容。將784字節的有效載荷內容看作成28×28的數字矩陣輸入CNN網絡生成載荷空間特征,然后再與流量統計特征融合生成融合特征向量。其流程如圖2所示。
1)將784字節的有效載荷處理28×28圖像矩陣。
2)卷積層使用4×4的卷積核,步長取1,對輸入的載荷矩陣做卷積運算,得到相應的特征圖,然后再使用RELU函數對特征圖進行處理。
3)將池化層窗口大小設置為2×2,步長設置為1,降維激活層得到特征圖。
4)將得到的72維有效載荷特征與統計特征進行融合處理,然后使用融合特征訓練分類模型。
3.3 Stacking集成學習檢測模型
模型訓練的目的是穩定并且在各個方面都表現良好的模型,但現實中的情況往往不理想。如果使用單一的機器學習算法對融合特征數據進行訓練,由于每個機器學習算法有各自優缺點,可能會得到一個在某些方面比較有良好效果的弱分類模型。集成學習原理是訓練多個單一模型,然后再通過一個策略將其組合起來,即便其中存在某個弱分類器,也能通過其他分類器將其錯誤預測結果糾正回來。
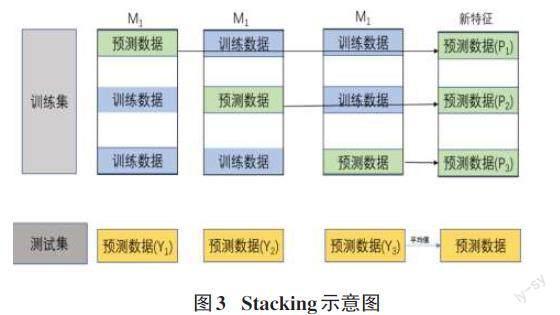
本文使用Stacking[21]集成策略訓練分類模型。Stacking集成策略的原理是使用數據集分別訓練基學習器,然后將數據集輸入訓練好的基學習器中得到次級訓練數據集。最后,再將得到的次級訓練數據集輸入次級學習器中,得到最終的分類模型。但這樣得到的次級訓練數據集往往會出現過擬合現象,因此,常常會使用K折交叉驗證的方法來防止出現過擬合現象。本文中設計的Stacking算法使用了3折交叉驗證的方法,其流程如圖3所示,將訓練數據集均勻劃分成3份,每次取兩份訓練數據集輸入基學習器進行訓練,將剩余的一份預測數據輸入訓練好的模型中得到新的預測數據Pi ,同時對測試數據進行預測,將其結果記為Yi,依此重復3次,將得到的Pi堆疊得到新的特征值記為P,得到的Yi進行加權平均得到新的測試集Y。如果擁有N個基分類器,可以得到N個Y和P,然后將P1,P2,…,Pn按照列進行拼接得到一個N列的訓練數據矩陣,將Y1,Y2,…,Yn按照列進行拼接得到一個N列的測試數據矩陣,使用次級分類器對新的訓練集和測試集進行訓練和預測,最終得到預測結果。
本文使用的基學習器為支持向量機、SVM、隨機森林,次級學習器選擇了邏輯回歸,使用的數據為流統計特征和載荷特征融合后的數據集,并使用Python中的Sklearn庫去訓練模型,相關算法如下。
[基于3折交叉驗證的Stacking算法 輸入:訓練數據集[D={x1,y1,x2,y2,x3,y3}];初級學習器C1,C2,C3,次級學習器C。
輸出:[Hx=h'h1x,h2x,h3x]
[1.for i=1,2,3 do]
[2.? ? ? hi=CiD]
[3.end for]
[4.D'=?]
[5.for? i=1,2,3 do]
[6.? ? ? for j=1,2,3 do]
[7.? ? ? ? ? ?pij=hjxi]
[8.? ? ? ?end for]
[9.D'=D'∪pi1,pi2,…,pij,yi]
[10.end for]
[11.h'=CD'] ]
4 實驗結果
4.1 實驗環境
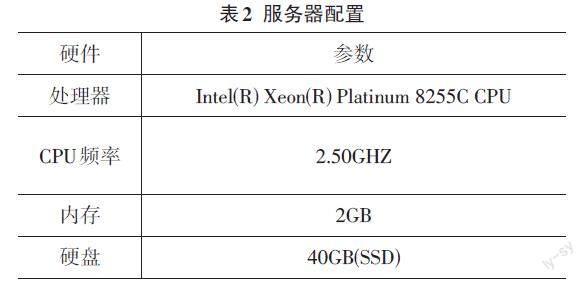
實驗環節使用了3臺Linux 服務器搭建分布式系統框架,單臺服務器的配置如表2所示。
4.2 評價指標
結果測試使用召回率(Recall)、F1值、準確率(Accuracy)、精確率(Precision)對模型進行評估。其公式分別為:
[Recall=TPTP+FN]? ? ? ? ? ? ? ? ? ? ?(6)
[F1=2×Precision×RecallPrecision+Recall]? ? ? ? ? ? ? ? ? ?(7)
[Precision=TPTP+FP]? ? ? ? ? ? ? ? ? ? ? ?(8)
其中,TP代表模型正確預測為正的正樣本,FN代表模型錯誤預測為負的正樣本,FP代表模型錯誤的預測為正的負樣本,TN代表被模型正確的預測為負的負樣本。
4.3 實驗結果與分析
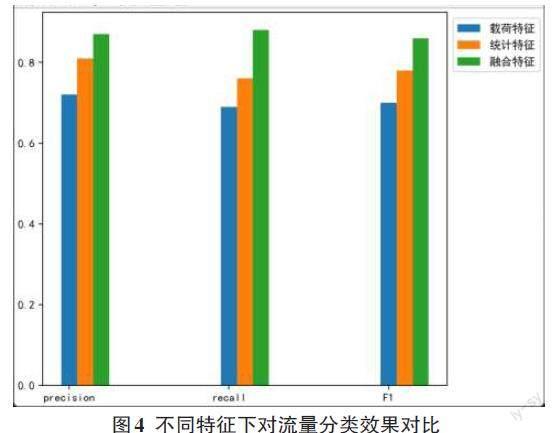
1)特征融合前后對比
選取20%的樣本集作為測試集,80%樣本作為訓練集進行訓練,同時把流量統計特征和內容載荷特征分成兩個特征子集,并設置3組實驗對照,分別為只使用統計特征、只使用載荷特征和使用融合的統計特征和載荷特征,其目的是證明融合特征要比單一特征的分類效果更好,其結果如圖4所示。
實驗結果表明,融合特征下,對流量識別的效果要優于未經融合的特征,其精確率達到了87.7%。
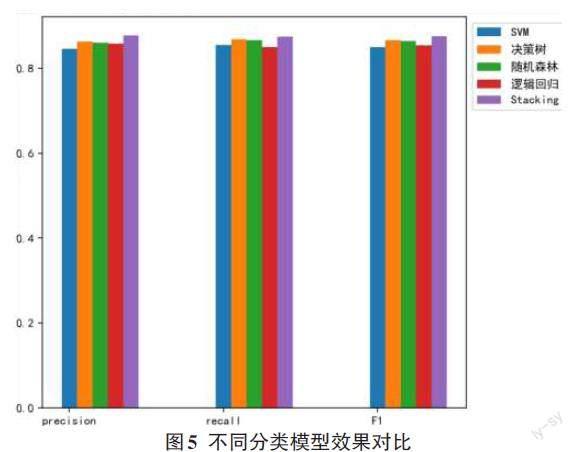
2)模型分類對比
文章對支持向量機、決策數、隨機森林、邏輯回歸和Stacking融合模型的分類效果進行了對比,其目的是驗證Stacking模型的分類效果要優于其他單一分類模型,其結果如圖5所示。
實驗結果表明,Stacking融合模型的分類效果要優于其他單一模型。
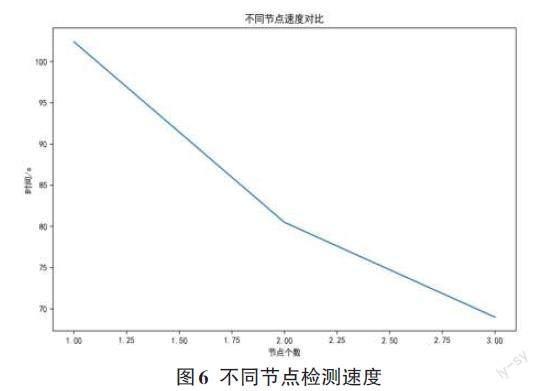
4.4 檢測速度分析
為了測試檢測框架在分布式集群上的速度,分別測試了在1、2、3個節點下檢測1GB流量數據所需要的時間。可以看出,隨著節點的增加,檢測速度越來越快,可以得出分布式架構可以通過增加機器的方式來提高系統的吞吐量和速度,具有很好的擴展性。
5 結束語
本文利用CICflowmeter工具提取了CIC-IDS-2017數據集的流量統計特征和有效載荷,通過CNN網絡提取有效載荷數據特征,并融合流量統計特征訓練了流量異常檢測模型。為了應對海量數據情形,文章結合了Spark、Kafka等大數據中間件處理流量數據和部署模型。最后通過實驗測試,證明了檢測模型的實時性和準確性。
該檢測框架還有許多問題,例如如何進一步提升模型的預測準確度,如何優化Kafka集群獲取更高的吞吐量,如何優化Spark集群進一步提升計算能力,這些問題還有待解決。
參考文獻:
[1] DESFORGES M J,JACOB P J,COOPER J E.Applications of probability density estimation to the detection of abnormal conditions in engineering[J].Proceedings of the Institution of Mechanical Engineers,Part C:Journal of Mechanical Engineering Science,1998,212(8):687-703.
[2] SOULE A,SALAMATIAN K,TAFT N.Combining filtering and statistical methods for anomaly detection[C]//Proceedings of the 5th ACM SIGCOMM conference on Internet measurement - IMC '05.October 19-21,2005.Berkeley,California.ACM,2005:31.
[3] PASCOAL C,DE OLIVEIRA M R,VALADAS R,et al.Robust feature selection and robust PCA for Internet traffic anomaly detection[C]//2012 Proceedings IEEE INFOCOM.Orlando,FL,USA.IEEE,2012:1755-1763.
[4] SANTOS DA SILVA A,WICKBOLDT J A,GRANVILLE L Z,et al.ATLANTIC:a framework for anomaly traffic detection,classification,and mitigation in SDN[C]//NOMS 2016 - 2016 IEEE/IFIP Network Operations and Management Symposium.Istanbul,Turkey.IEEE,2016:27-35.
[5] 李澤一,王攀.基于代價敏感度的改進型K近鄰異常流量檢測算法[J].南京郵電大學學報(自然科學版),2022,42(2):85-92.
[6] 鄭黎明,鄒鵬,賈焰,等.基于多維熵序列分類的骨干網上流量異常檢測[J].中國通信,2012,9(7):108-120.
[7] 莊政茂,陳興蜀,邵國林,等.一種時間相關性的異常流量檢測模型[J].山東大學學報(理學版),2017,52(3):68-73.
[8] SATOH A,NAKAMURA Y,IKENAGA T.A flow-based detection method for stealthy dictionary attacks against Secure Shell[J].Journal of Information Security and Applications,2015,21:31-41.
[9] 宗文澤,吳永明,徐計,等.基于DTW-kmedoids算法的時間序列數據異常檢測[J].組合機床與自動化加工技術,2022(5):120-124,128.
[10] 史小艷,陳松燦.基于單簇聚類的非對齊多視圖異常檢測算法[J].中國科學:信息科學,2021,51(12):2037-2052.
[11] 吳英友,胡剛義,唐靜,等.基于兩階段聚類的設備狀態異常檢測方法[J].艦船科學技術,2021,43(15):163-168.
[12] ALEXEEV B,CAHILL J,MIXON D G.Full spark frames[J].Journal of Fourier Analysis and Applications,2012,18(6):1167-1194.
[13] ZHANG Z H,LIU Z F,LU J F,et al.The sintering mechanism in spark plasma sintering - Proof of the occurrence of spark discharge[J].Scripta Materialia,2014,81:56-59.
[14] ZAHARIA M,XIN R S,WENDELL P,et al.Apache spark[J].Communications of the ACM,2016,59(11):56-65.
[15] BALAANAND M,KARTHIKEYAN N,KARTHIK S.Envisioning social media information for big data using big vision schemes in wireless environment[J].Wireless Personal Communications,2019,109(2):777-796.
[16] NOGHABI S A,PARAMASIVAM K,PAN Y,et al.Samza[J].Proceedings of the VLDB Endowment,2017,10(12):1634-1645.
[17] LASHKARI A H,DRAPER-GIL G,MAMUN M,et al.Characterization of Tor Traffic using Time based Features C].ICISSp,2017: 253-262.
[18] GIL J A,SENDYK M.Spark model for pulsar radiation modulation patterns[J].The Astrophysical Journal,2000,541(1):351-366.
[19] 杭夢鑫,陳偉,張仁杰.基于改進的一維卷積神經網絡的異常流量檢測[J].計算機應用,2021,41(2):433-440.
[20] JI S W,XU W,YANG M,et al.3D convolutional neural networks for human action recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(1):221-231.
[21] 李穎之,李曼,董平,等.基于集成學習的多類型應用層DDoS攻擊檢測方法[J/OL].計算機應用,2022:1-9.(2022-04-19).https://kns.cnki.net/kcms/detail/51.1307.TP.20220416.0837.00
【通聯編輯:代影】
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
