一種基于鯨魚優化算法的網絡流量組合預測模型
2024-01-27 16:44:03李詩雅田中大
電腦知識與技術 2023年36期
李詩雅 田中大
摘要:現代網絡流量的自相似性、周期性、混沌性、多尺度性和其他特性使得預測網絡流量具有挑戰性。因此,該文提出了一種基于鯨魚優化算法(WOA)的變分模態分解(VMD),結合了隨機配置網絡(SCNs)對網絡流量進行預測。首先,該文對網絡流量數據集進行VMD分解,同時引入WOA對VMD分解中分解個數K和懲罰參數α進行優化。其次,利用SCNs模型對分解后得到的分量進行預測,最后,累加每個分量的預測結果,得出最終網絡流量預測值。該組合預測模型(WOA-VMD-SCNs)旨在提高網絡流量預測的準確性,對實際收集的網絡流量數據進行預測,驗證本文提出模型的有效性。
關鍵詞:網絡流量預測;鯨魚優化算法;變分模態分解;隨機配置網絡;組合預測模型
中圖分類號:TP273? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)36-0066-04
開放科學(資源服務)標識碼(OSID)
0 引言
中國互聯網信息中心于2023年3月發布《第51次中國互聯網絡發展狀況統計報告》中提到,截至2022年12月,全國網民數量為10.67億,比2021年12月增加了3 549萬,達到75.6%的網絡普及率[1]。此外,全年移動互聯網接入流量達2 618億GB。網民數量的增長帶來網絡流量的激增,隨著智能手機的普及和大多數人使用流量數據的計劃以及視頻、游戲等各種大流量網絡應用的快速發展,數據流量呈指數型增長,網絡流量負荷急劇增加,網絡擁塞時有發生,網絡流量可以反映整個網絡的運行狀態和資源狀況[2]。為了管理這種爆炸性增長,需要準確的網絡流量預測來規劃網絡容量。在分配網絡資源的過程中,傳統的基于業務運行狀況的資源配置方式由于缺少對未來業務運行狀況的預測,極易造成網絡擁塞和資源浪費。對網絡流量進行精確的預測有助于運營商盡早對可能發生的擁塞做出反應,并在此之前對網絡進行擴容、調整和優化[3]。在缺乏快速準確的網絡流量預測模型的情況下,網絡運營商將面臨風險。因此,網絡流量的建模和預測對于有效的網絡流量管理是必要的。
成功預測網絡流量的關鍵在于模型的選擇和設計,目前有三種預測模型:線性、非線性和組合模型。大多數傳統的線性時間序列預測模型由自回歸模型、自回歸移動平均模型和自回歸綜合移動平均模型組成,雖然這些方法的模型簡單,計算復雜度低,處理速度快,但預測模型不可避免地會產生明顯的預測誤差。它們不能反映準確的網絡服務的突發性和長期性的相關性,并且其參數的設置需要人工經驗獲得,僅限于短期流量數據。線性模型對實現精確預測具有挑戰性。相比之下,非線性系列預測模型能有效地跟蹤復雜的系統。非線性預測模型正在變得越來越廣泛,如支持向量機(SVM)、灰色模型(GM)、神經網絡和深度學習。SVM的預測精度在很大程度上取決于核參數,適合于小樣本;GM的高預測精度只適合于具有穩固規律性的流量數據。神經網絡具有良好的自組織和自學習能力,能夠很好地描述網絡流量數據的非線性特征。然而,神經網絡訓練過程中的輸入節點數量、輸出節點數量、網絡層數量、每個層中的節點數量以及其他設置方法沒有明確的理論基礎,通常是基于經驗來設置這些超參數。基于深度學習的回歸預測模型的訓練成本很高,這需要大量的訓練樣本和時間來達到令人滿意的程度。上述線性或非線性模型均為單一預測模型,傳統的線性和非線性模型不足以描述流量的多尺度特征,從而影響了預測的準確性。因此,當前的研究傾向于關注組合模型,而不是傳統的線性和非線性模型。一般來說,組合預測模型包括兩個以上的預測模型,并且可以組合一些分解算法或優化算法。總體而言,網絡流量組合預測模型是一個值得深入研究的方向,具有一定的競爭力。
本文使用了VMD算法對網絡流量數據進行分解,VMD算法可以降低復雜度高和非線性強的時間序列非平穩性,分解獲得包含多個不同頻率尺度且相對平穩的分量,適用于非平穩性的序列。首先,本文采用WOA優化VMD參數的方法,降低分解個數K和懲罰參數α對分解效果的影響。其次,利用SCNs模型對分解后的分量進行預測,SCNs具有良好的學習和泛化性能,對非線性映射具有良好的逼近能力,最后,累加每個分量的預測結果,得出最終網絡流量預測值。
1 相關理論概述
1.1 VMD分解
VMD是一種新的自適應信號處理算法,該算法假設信號是由具有不同中心頻率的調幅和調頻信號的多個模態函數疊加而成。使用變分法最小化每個本征模態函數的估計帶寬之和。將本征模態函數解調到相應的基帶,最后提取本征模態函數和相應的中心頻率[4]。對于原始信號[ft],帶約束的變分問題模型可以描述為
[minuK,ωKK?tδ(t)+jπt*uK(t)e-jωKt22 s.t. KuK=f]? ?(1)
式中[uK=u1,u2,…,uK]為各模態函數的K階函數,[ωK=ω1,ω2,…,ωK]為各模態函數的中心頻率;[δt]是脈沖函數。
為了找到上述約束問題的最優解,利用拉格朗日乘法算子λ將約束變分問題轉化為無約束變分問題,如式(2)所示:
[LuK,ωK,λ=αK?tδ(t)+jπt*uK(t)e-jωKt22+f(t)-KuK(t)22+λ(t),f(t)-KuK(t)]? (2)
其中,[α]是次要懲罰因子。
利用乘子交替方向法求解方程(2),得到最優解。
VMD分解的主要步驟如下:
步驟1:初始化各模態函數和中心頻率,給出[u1K]、[ω1K]和[λ1]。將各模態函數從時域變換到頻域并設[n=0]。
步驟2:[uK]的更新公式為
[un+1K(ω)←f(ω)-i≠Kui(ω)+λ(ω)21+2αω-ωK2]? ? ? ? (3)
其中,[uK(ω)],[f(ω)]和[λ(ω)]分別是[uK]、[ft]和[λ]的傅里葉變換。
步驟3:[ωK]的更新公式為
[ωn+1K←0∞ωuK(ω)2dω0∞uK(ω)2dω]? ? ? ? ? ? (4)
步驟4:[λ]的更新公式為
[λn+1(ω)←λn(ω)+τf(ω)-Kun+1K(ω)]? (5)
其中,τ為迭代因子。
步驟5:收斂精度[ε>0],迭代終止條件如下:
[Kun+1K-unK22unK22<ε]? ? ? ? ? ? ? ? ? ? ?(6)
如果滿足式(6)的條件,終止迭代,輸出最終結果;否則,返回到步驟2繼續迭代。
從VMD分解步驟可以看出,在分解信號之前需要確定分解次數K和懲罰參數α,因為K的數值直接影響信號序列的分解效果,K值偏大會造成信號過分解,K值偏小會造成欠分解,α的數值高會導致信息的損失,相反又會導致信息的冗余。因此,確定K和α的最佳參數是必要的。目前,確定K值的最常用方法是在不同的K值下觀測中心頻率。然而,這種方法存在一定的隨機性,且不能確定懲罰參數α。因此,本文提出以包絡熵的極小值為適應度函數的WOA算法優化VMD參數。包絡熵反映了原始信號的稀疏特征,因此當IMF包含較多的噪聲和較少的特征信息時,包絡熵的值較高,反之,包絡熵的值較低。
信號[α(i)(i=1,2,…,N)]的包絡熵Ep由式(7)表達,其中,[φ(i)]為VMD分解的模態分量經過希爾伯特解調后的包絡信號,[μ(i)]是[φ(i)]的歸一化得到的概率分布序列,N為樣本數,對[μ(i)]的熵值進行運算,就是包絡熵Ep。
1.2 WOA算法
WOA是一種基于鯨魚捕獵獵物行為提出的算法。在鯨魚算法中,每只鯨魚的位置代表一個可行的解決方案。該算法主要包括三個階段:包圍獵物、螺旋泡網覓食、搜索獵物。在一群鯨魚的狩獵過程中,每只鯨魚都有兩種行為:一種是包圍獵物,所有鯨魚都向其他鯨魚移動;另一個是氣泡網,即鯨魚以圓周運動,并噴出氣泡驅趕獵物。在每一代中,鯨魚都會隨機選擇這兩種行為來捕獵。在鯨魚圍繞獵物的行為中,鯨魚會隨機選擇這兩種行為來完成狩獵。
1)包圍獵物
在鯨魚正式捕食前,需要估計獵物的位置,而鯨魚的位置可以被視為要優化的問題的解決方案。當領頭的鯨魚確定獵物的位置時,通過鯨魚與鯨魚之間的信息傳遞,其他鯨魚也會游到目標位置,然后不斷更新位置。
[D=C?X?(t)-X(t)]? ? ? ? ? ? ? ? ? ? ? (8)
[X(t+1)=X?(t)-A?D]? ? ? ? ? ? ? ? ? ?(9)
其中,t表示當前迭代,[X?(t)]表示t代鯨魚確定的獵物的最佳位置矢量,[X(t)]表示其他鯨魚種群的個體位置向量,D表示頭鯨和獵物之間的關系,A和C是控制參數向量。
2)螺旋泡網攝食策略
鯨魚捕食的另一種方式是首先估計獵物與自己的距離,然后慢慢接近獵物的位置。當到達獵物的位置時,會吐出螺旋狀的氣泡來誘捕獵物。
[D=X?(t)-X(t)]? ? ? ? ? ? ? ? ? ?(10)
[X(t+1)=D?ebl?cos(2πl)+X?(t)]? ? ? (11)
其中,[D']表示獵物到第[i]頭鯨魚的距離矢量參數,[b]表示螺旋常數,l是[-1,-2]的隨機數。
由于鯨魚正在捕食,圍繞獵物和螺旋泡捕食這兩種行為可以同時進行,兩者發生的概率都為0.5,可以得到
[X(t+1)=X(t)?-A?D,? ? ? ? ? ? ? ? ?p<0.5D?ebl?cos(2πl)+X?(t),p≥0.5](12)
其中,p是[0,1]的隨機數。
除了氣泡網方法,座頭鯨還隨機搜索獵物,擴大搜索范圍,跳出局部最優狀態。
3)搜索獵物
在WOA算法,每個參與捕獵的鯨是一個可行解X。在獵物搜尋階段,依據鯨類捕食過程中的隨機性,每只鯨類通過相互間的位置信息來更新下一代位置。通過隨機搜索,可以獲得較好的全局最優性。
[D=C?Xrand-X]? ? ? ? ? ? ? ? ?(13)
[X(t+1)=Xrand-A?D]? ? ? ? ? ? ?(14)
其中,[Xrand]是當前種群中隨機鯨魚的位置。
使用收斂因子A的絕對值選擇更新位置的方式。當|A|<1時,鯨魚進入環繞氣泡模式以找到局部最優位置參數;當|A|≥1時,進入全局搜索以避免陷入局部最優。
WOA算法從一組隨機解開始,在每次迭代中,鯨魚根據它們選擇的方式更新自己的位置。WOA具有全局優化的特點,并且可以自適應地改變靈敏度因子,使得WOA算法可以在包圍獵物和捕食螺旋氣泡網的兩種狀態之間輕松切換[5]。此外,WOA只有兩個需要調整的內部參數,在實踐中使用相對簡單。同時,WOA算法可以在迭代過程中提供較高的收斂速度,避免陷入局部最優。
1.3 SCNs原理
Wang和Li于2017年提出了SCNs,區別于以往的隨機權重神經網絡,SCNs依賴于訓練數據,通過有監督的方式,對隱參數進行自適應選取,并通過線性回歸方法對其輸出權值進行評價,從而確保網絡具有良好的收斂性。其優點是有較好的穩定性和泛化能力,有足夠的學習能力,有良好的快速數據建模潛力。
對于有L-1個隱藏節點的N個樣本,SCN 的輸出如公式(15)所示。
[fL-1(x)=j=1L-1βjgjwTjx+bj] (15)
此刻的網絡誤差如公式(16)所示。
[eL-1=f-fL-1=eL-1,1,…,eL-1,m]? ? ? (16)
SCNs首先構建了一個小型的網絡,然后通過添加隱藏節點,逐步構建了一個學習模型。該算法依賴于訓練樣本的自適應選取輸入權值和偏置范圍,并使用了監督機制。具體如公式(17)所示。
[eL-1,q,gL2?b2gδL,q,q=1,2,…,m]? ? ? ? ? ? (17)
其中,[δL,q=1-r-μLeL-1,q2], [0<∥g∥<bg]并且[bg∈R+]。
使用最小二乘法計算隱藏層的輸出權重矩陣,如公式(18)所示。
[β1,β2,…,βL=argminβf-Lj=1βjgj2]? ? ? ? (18)
SCN的基本模型如公式(19)所示。
[fL=fL-1+βLgL]? ? ? ? ? ? ? ? ? ? (19)
SCNs的構建過程不是用固定的體系結構訓練模型,而是從一個小規模的網絡開始,遞增地添加隱藏節點,直到達到可接受的容差,然后用當前的學習器解決全局最小二乘問題,以找到輸出權重。
2 仿真實驗
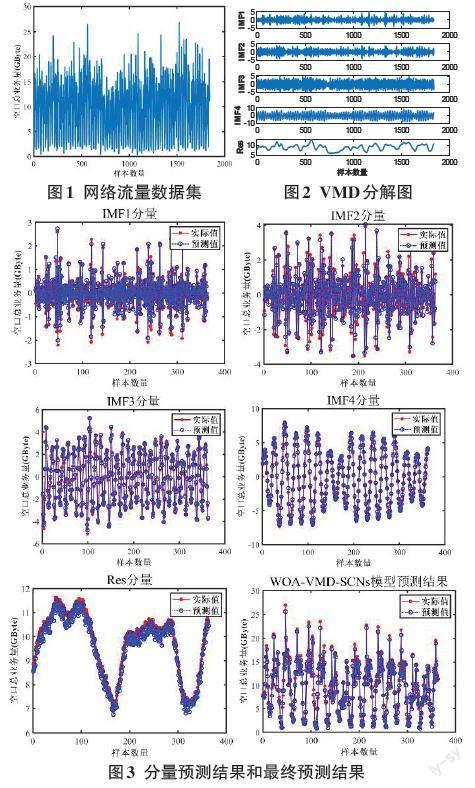
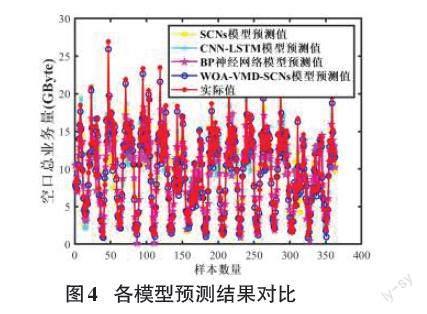
本文采用實際獲得的網絡流量數據集進行VMD分解,該數據集共收集了1 840組網絡流量數據,所有數據均來自中國大連加工區內的大連開發區4G基站的每小時流量數據,數據收集期為2020年9月1日0:00至2020年11月16日15:00,采樣時間間隔為1小時,每天24組,共76天,編號從1到1840。網絡流量數據的可視化結果如圖1所示。本文選擇了1到1 472號的樣本數據進行模型訓練,1473到1 840號的樣本數據用于模型驗證。WOA基本參數設置情況為:種群數量設置為20,最大迭代次數設置為30,維度設置為2,適應度函數為包絡熵,優化后的VMD最佳參數為K=5,α=100。VMD分解圖如圖2所示。利用相關系數可以有效分析IMF和Res分量與原始網絡流量數據的相關性,通常相關系數小于0.1為虛假分量及噪聲分量剔除標準。分解后的IMF分量和Res分量的相關系數分別為0.851,0.881,0.924,0.963和0.987。從中可以看出,每個分量與原始數據集的相關性都很高,證明了即使通過數據分解,原始網絡流量數據仍具有較好的還原度,即每個分量仍然保留了原始數據的一些特征。通常,原始的網絡流量序列由于各種因素而高度復雜。因此,本文利用VMD算法將復雜序列分解為幾個簡單的分量,所得到的分量具有比原始流量序列更簡單的結構,VMD分解有效地減少了模型的復雜性,由分解結果可知,VMD分解出的高頻成分變化趨勢比較穩定,這對預測是有利的;低頻分量雖然波動較大,但是這種誤差是有限度的。由于最終預測值是各個分量預測值的累積,因此,VMD分解對預測的準確性具有重要意義。
表3展示了SCNs模型預測的IMF和Res分量的預測結果,將各分量的預測結果疊加整合得到了最終網絡流量預測結果。為了驗證本文提出模型的有效性,分別與SCNs模型、CNN-LSTM模型和BP神經網絡模型的預測結果進行對比。
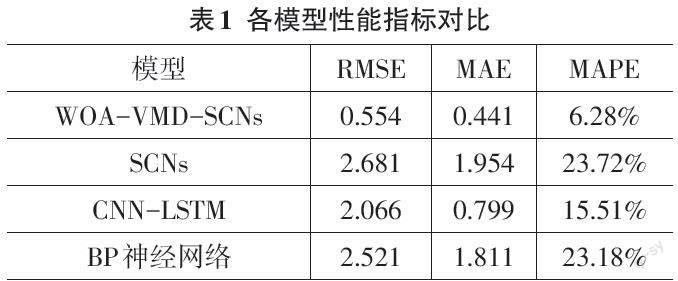
表1展示了各模型的性能指標,通過比較性能指標得出,與SCNs模型相比,基于WOA-VMD-SCNs預測模型的RMSE、MAE、MAPE指數分別下降了79.33%、77.43%、73.52%;與CNN-LSTM模型相比,本文提出的模型的RMSE、MAE、MAPE指數分別下降了73.18%、44.81%、59.51%;與BP神經網絡模型相比,本文提出的預測模型的RMSE、MAE、MAPE指數分別下降了78.02%、75.64%、72.91%;從圖4可以看出,與其他模型相比,本文所提出的模型表現良好,預測結果與實際驗證數據基本吻合,所提出的模型能夠精確地捕捉數據的模式。綜上所述,基于WOA-VMD-SCNs預測模型顯示出了良好的擬合效果和較低的預測誤差。
3 結論
根據網絡流量的特征,本文提出了一種WOA-VMD-SCNs的網絡流量組合預測模型。其優勢為:1)VMD通過獨立選擇模式分解的數量,分解的分量更具規則性,同時過濾掉噪聲,提高了噪聲魯棒性,使后續的模型預測性能得到顯著提高。2)引入WOA算法獲得VMD分解的最佳參數。3)SCNs避免了局部極小值的存在,具有良好的泛化性能和顯著的表示能力。與深度神經網絡相比,SCNs具有更低的訓練復雜度和更快的學習速度。
參考文獻:
[1] 中國互聯網絡信息中心.第51次中國互聯網絡發展狀況統計報告[R].北京:CNNIC,2023.
[2] SUN X C, WEI B, GAO J H, et al. Spatio-Temporal Cellular Network Traffic Prediction Using Multi-Task Deep Learning for AI-Enabled 6G[J]. Journal of BeiJing Institute of Technology, 2022, 31(5): 441-453.
[3] SELVI K T,THAMILSELVAN R.An intelligent traffic prediction framework for 5G network using SDN and fusion learning[J].Peer-to-Peer Networking and Applications,2022,15(1):751-767.
[4] XIONG B R,MENG X Y,XIONG G,et al.Multi-branch wind power prediction based on optimized variational mode decomposition[J].Energy Reports,2022,8:11181-11191.
[5] SAMANTARAY S,SAHOO A.Prediction of suspended sediment concentration using hybrid SVM-WOA approaches[J].Geocarto International,2022,37(19):5609-5635.
【通聯編輯:代影】
