海空集群對抗深度強化學習算法研究平臺設計
2024-01-29 00:31:13劉寶宏
軟件工程 2024年1期
劉寶宏




關鍵詞:集群對抗;深度強化學習;平臺設計;并行與分布式運行
0 引言(Introduction)
當前,以深度強化學習為代表的人工智能方法在星際爭霸[1]、王者榮耀[2]等即時策略游戲項目上的應用取得重大進展和突破。深度強化學習算法在復雜軍事博弈對抗領域的應用正在加緊推進,相關科研項目和比賽亟需深度強化學習算法研究平臺的支撐[3-5]。對此,研究人員進行了初步探索和嘗試,吳昭欣等[6]設計了基于深度強化學習技術的智能仿真平臺,但其并不涉及對抗過程;盧銳軒等[7]設計了基于人工智能技術的智能自博弈平臺,支持智能體訓練和自博弈訓練,并進行了一對一空戰仿真試驗。海空集群對抗如果直接使用海空實際裝備進行演習實驗,不僅耗費巨大、效率低,而且風險極高[8]。而如果采用深度強化學習算法解決對抗中的指揮決策問題,先利用仿真系統對算法進行訓練和評價研究,再將算法遷移至實際裝備,這是一條可行路徑。要想這樣,一方面需要研究平臺生成大量的樣本數據用于算法訓練,另一方面,需要研究平臺合理評估算法性能,指導算法的演化改進。
根據海空集群對抗仿真實驗的特點和研究人員的需求,本文設計了一種深度強化學習算法研究平臺(以下簡稱平臺)。在軟件層面,平臺支持設計作戰想定對海空裝備、戰場環境及交戰過程進行仿真;支持與深度強化學習算法進行交互,提供算法所需的訓練數據并執行算法的輸出命令;支持簡單方便地進行算法修改或替換,平臺運行效率高,支持分布式并行運行;在硬件層面,支持對海空集群的計算節點規模進行簡單、方便的水平擴展。
1 平臺架構設計(Platform architecture design)
1.1 應用需求分析
針對海空集群對抗問題具有的跨域跨平臺、計算量大、快速推演等特點,平臺主要需要實現以下功能。
1.1.1 海空集群對抗仿真
在海空裝備實體模型和行為模型的基礎上,能夠針對作戰場景想定,采用計算機仿真的方式對海空集群對抗過程進行仿真推演,并且深度強化學習算法能夠與仿真進行交互,包括仿真的控制、仿真數據的獲取及海空裝備仿真實體的控制決策等。
1.1.2 深度強化學習算法設計
算法設計主要包括兩方面的功能:一是提供典型的深度強化學習算法供用戶直接使用,如深度Q網絡(Deep Q-Network,DQN)[9]、深度確定性梯度(Deep Deterministic Policy Gradient,DDPG)、近端策略優化(Proximal Policy Optimization,PPO)算法等,用戶只需針對特定想定設計算法的輸入、輸出和獎勵函數等,就可以直接進行訓練和評價;二是提供算法自定義擴展開發的功能,用戶能夠自行設計開發相關新算法對智能指揮決策方法進行探索和研究。
平臺需要支持算法訓練和算法評價兩個過程。算法訓練要求平臺能夠對算法的相關參數進行設置,以及對算法過程和訓練結果進行記錄和展示;算法評價要求平臺能夠對算法訓練結束后形成的模型進行有效性評估。
1.1.3 并行與分布式運行支撐
算法訓練學習需要大量的樣本數據,通過在仿真推演中不斷試錯實現學習、訓練和提升,因此要求仿真能夠在并行與分布式運行支撐下快速且高效地生成大量的數據樣本,提高算法訓練的效率。
1.2 平臺軟件架構
平臺由海空集群對抗仿真系統(以下簡稱仿真系統)和深度強化學習系統組成,平臺模塊組成圖如圖1所示。仿真系統采用定步長的時間推進方式,在每個步長都可以通過仿真系統的外部訪問接口控制仿真系統運行、獲取戰場態勢和執行任務命令等。深度強化學習系統通過網絡通信調用仿真系統的外部訪問接口,實現對仿真系統的控制和信息獲取。
仿真系統由想定模塊、海空環境模型模塊、海空裝備模型模塊、交戰裁決模型模塊和系統外部訪問接口等組成。
想定模塊主要包括想定基本信息設置、兵力部署、條令規則設置、作戰任務規劃、想定打開與保存等功能,用于定義和設置作戰對抗問題初始狀態,如戰場區域、推演方、作戰時間、作戰兵力、作戰目標、作戰行動等。
海空環境模型模塊用于生成海空集群交戰的戰場環境信息,包括海域、島礁和空域等三維模型,海空集群在此環境模型中進行作戰活動。
海空裝備模型模塊由海上艦艇模型和空中戰機模型組成,采用參數化建模框架,將模型向下一級分解,分為機動模型子模塊、偵察模型子模塊、火力模型子模塊和任務處理子模塊。
機動模型子模塊是指平臺的機動能力,主要包括平均速度、最大速度、航程、爬升率等信息。偵察模型子模塊是指平臺具有的偵察能力,主要包括雷達、紅外和可見光等偵察設備的偵察范圍,以及對各類目標的發現概率等;火力模型子模塊是指平臺上所搭載的火力單元,主要包括各類炮、導彈等。各個型號的海空裝備的參數化建模框架相同,只是具有不同的參數值。
交戰裁決模型模塊對海空裝備的交火行為進行裁決,給出海空裝備的受損信息,更新其狀態。武器目標火力毀傷裁決過程如下所示。
(1)加載相關信息,主要加載進攻武器戰技指標參數、目標裝甲防護能力、進攻武器到目標的距離、戰場環境等信息。
(2)將所需的參數傳入擊中概率計算規則進行計算,返回擊中概率。
(3)采用隨機數生成器生成0~1的隨機數。
(4)比較隨機數與擊中概率,如果隨機數小于等于擊中概率,則判定為擊中,否則為未擊中,結束流程。
(5)傳入毀傷計算規則所需的參數進行毀傷計算,例如對艦船目標毀傷的計算規則如下:艦船被擊中1發反艦導彈則判為失去動力無法機動,被擊中2發反艦導彈則判為失去防空能力,被擊中3發反艦導彈則判為擊沉等。
(6)輸出毀傷結果,結束流程。
系統外部訪問接口包括系統控制接口、態勢獲取接口和控制命令接口等。系統控制接口用于深度強化學習系統控制仿真系統的啟動、停止、加載想定等;態勢獲取接口用于深度強化學習系統獲取當前仿真系統內各個系統和實體的狀態,如仿真的時間、雙方海空裝備的狀態、環境信息等;控制命令接口用于響應深度強化學習系統調用的任務指令,如機動、開火、偵察裝備的開機和關機等控制命令。
仿真系統在具體實現時劃分為仿真內核與顯示模塊,仿真內核關注仿真的高效推演計算,不包括界面顯示,其推演過程展現由顯示模塊完成。仿真內核與顯示模塊的分離,使得算法在訓練時只需要使用仿真內核而無需使用顯示模塊,這樣就可以避免耗費計算渲染資源,加快仿真推演進程;在對算法模型進行評價分析時,同時運用仿真內核和顯示模塊詳細展示海空集群對抗仿真全程,便于用戶直觀地理解戰斗過程。
深度強化學習系統包括深度強化學習算法模塊和接口封裝模塊。深度強化學習算法模塊采用深度神經網絡進行建模,用于控制仿真系統的運行,讀取戰場態勢信息,包括戰場環境信息、敵方兵力部署和狀態信息、我方兵力部署和狀態信息等,采用分布式強化學習算法進行訓練,輸出海空集群的聯合動作,通過接口封裝模塊將動作轉換為單個平臺的控制命令,調用仿真系統的外部訪問接口傳輸給仿真系統進行處理和響應。
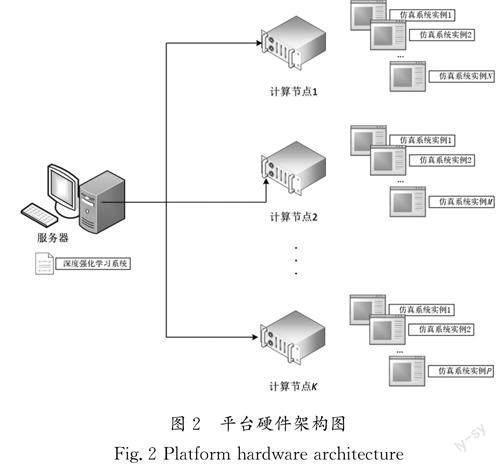
1.3 平臺硬件架構
平臺采用分布式的網絡架構,深度強化學習系統部署在一臺服務器上,仿真系統部署在多臺計算節點上,服務器和計算節點間通過網絡連接,網絡通信采用gRPC等協議,平臺硬件架構圖如圖2所示。每臺計算節點上可以運行多個仿真系統實例,實現分布式并行和加速,從而使訓練樣本的生成速度和算法的學習效率大大提高,具有良好的擴展性。服務器和計算節點可以根據需要配置圖形處理單元GPU,實現仿真和算法的高效運行和訓練。
2 平臺使用流程(Platform usage process)
平臺使用流程依次分為想定設計、算法訓練和算法評價三個子流程。
2.1 想定設計子流程
想定設計子流程(圖3)實現紅藍對抗場景的設計,主要包括以下步驟。
(1)設置推演方和時間:一般為對抗關系的紅藍雙方,想定時間為對抗開始和結束時間。
(2)部署兵力:將推演方的海空裝備作為兵力在戰場環境模型中進行部署,包括海空裝備的類型、掛載、數量、位置等信息。
(3)設置條令規則:對不同場景下的武器控制規則進行限制,如開火規則分為自由開火(向所有未識別為友方的單元開火)和謹慎開火(僅對識別為敵對方的單元開火),機動規則(設置海空裝備受到攻擊時,是否忽略計劃航線)。
(4)規劃作戰任務:一般情況下,推演雙方中一方的兵力由深度強化學習算法進行控制,另一方的兵力由預先制定的作戰任務規劃或者其他的算法進行控制。作戰任務規劃設計海空兵力的作戰任務,如巡邏任務、打擊任務、攔截任務等,并且規定在不同的條件下實施相應的作戰任務。
(5)保存想定:保存設計的想定,用于算法訓練和評價時進行加載。
2.2 算法訓練子流程
算法訓練子流程(圖4)實現算法訓練生成模型,主要包括以下步驟。
(1)調用仿真系統的外部訪問接口,開啟C 個仿真系統實例,這些實例可以運行于一臺或多臺計算的節點上,能夠通過計算節點IP地址來指定。
(2)啟動仿真系統實例,加載想定,初始化海空裝備狀態。
(3)初始化深度神經網絡參數、學習率等超參數。
(4)在每個時間步,強化學習算法模塊通過調用仿真系統的外部訪問接口,用于獲取當前仿真信息和收集訓練樣本。
(5)判斷訓練樣本數量,當訓練樣本超過設定的閾值時,開始神經網絡的訓練,訓練完成后保存網絡模型,采用訓練的神經網絡為不同的仿真系統實例生成作戰行動。當訓練樣本數不夠時,使用初始化的神經網絡為不同的仿真系統實例生成作戰行動。
(6)采用接口封裝模塊對作戰行動生成作戰命令,調用仿真系統的外部訪問接口傳入命令。
(7)仿真系統內部執行命令、更新狀態,如果對戰完成則重新加載想定進行下一局的仿真推演。
(8)如果算法訓練完成,則結束訓練,獲得保存的網絡模型,供下一步的評價使用。
2.3 算法評價子流程
算法評價子流程(圖5)實現對算法的評價,主要包括以下步驟。
(1)首先調用仿真系統外部訪問接口,開啟一個仿真系統實例,然后啟動仿真系統,加載想定,此時如果要展示戰斗過程,則可以接入顯示模塊。
(2)加載訓練好的深度網絡模型。
(3)深度強化學習算法調用仿真系統的外部訪問接口,獲取當前的仿真信息。
(4)判斷想定是否完成,如果完成則判斷評價是否完成,否則轉到“步驟(6)”。
(5)判斷評價是否完成,如果完成則保存評價結果,結束流程,否則加載想定,轉到“步驟(6)”。
(6)神經網絡模型生成作戰行動。
(7)將作戰行動封裝為控制命令。
(8)調用仿真系統外部接口傳入控制命令。
(9)仿真系統執行命令,更新狀態。
3 結論(Conclusion)
研究海空集群對抗仿真決策控制的深度強化學習算法時,需要對所研究算法產生的大量樣本進行高效訓練并對其結果驗證評價,針對這一問題,算法研究平臺通過軟件和硬件架構設計,仿真內核、顯示模塊分離設計及并行與分布式運行設計,可以快速對所研究的強化學習算法進行訓練,還能對其決策控制效果進行驗證評價。該算法研究平臺避免了直接進行海空裝備實物實驗需要耗費大量時間和可能產生未知風險的問題,滿足了算法研究人員對仿真平臺的需求,能夠提高海空集群對抗仿真過程中深度強化學習算法的研發效率。
