深度學習模型訓練的優(yōu)化器實驗設計
2024-01-31 13:23:40張波肖杰
電子制作 2024年2期
張波,肖杰
(茅臺學院,貴州仁懷,564507)
0 引言
深度學習的研究范圍較廣,深度學習是目前人工智能的重點研究領域之一,人工智能的眾多領域,包括語音處理,計算機視覺,自然語言處理等[1~2],體現了許多學科結合交叉的特點。而深度學習實驗課程中通常會以卷積神經網絡進行展開教學,CNN 的基本結構由輸入層,卷積層(卷積層),池化層(池層,也稱為采樣層),全連接層及輸出層構成[3~5]。通過對CNN 的學習可以幫助學生更好地理解深度學習算法和系統的運行和實現過程。目前高校在教學過程中,都相對比較重視實際動手的操作能力,只有開展相對的實驗課程,讓學生更好地參與到整個教學過程中,主動思考,從而提高學習能力和創(chuàng)新能力[6~7]。深度學習模型的訓練是一個迭代優(yōu)化的過程,其中優(yōu)化器的選擇對最終模型的性能至關重要。優(yōu)化器的作用是根據模型在訓練過程中的損失函數,自適應地調整模型的參數,使得損失函數最小化。因此,選擇一個合適的優(yōu)化器策略對于模型的收斂速度和性能具有重要影響。為了評估和選擇最佳的優(yōu)化器策略,設計一系列實驗來比較不同優(yōu)化器在相同數據集和模型架構下的性能。
本文通過遷移學習方法搭建了VGG19 網絡架構[8],在此架構的基礎上通過對AdaGrad、RMSProp 和Adam 三種不同優(yōu)化器理論學習,在模型訓練中加深對優(yōu)化器的理解。
1 實驗前期準備
■1.1 kaggle 平臺
kaggle 平臺主要是通過企業(yè)或者研究者在平臺上發(fā)布數據和問題,并提供獎金給能解決機器學習、數據分析等領域的大量用戶關注,目前平臺用戶已超過85 萬人。鑒于kaggle 平臺優(yōu)勢,本次實驗的貓狗數據集也是從kaggle 平臺下載。
■1.2 數據預處理
本次用到的貓狗分類數據集是由kaggle 平臺2013 年公開發(fā)布的,并用于計算機視覺競賽。貓狗數據集大小為543M,經過解壓后包含訓練集(12500 張貓狗照片)和測試集(12500 張貓狗照片),其中訓練集用于模型參數的更新,驗證集用于調整超參數(如學習率)和早停等策略。由于模擬實際生活中數據樣本少的情況,因此利用python 中的os,shutil 庫去創(chuàng)建4000 張圖像作為一個新的數據庫,其分組情況如表1 所示。其中2000 張用于訓練,1000 張用于驗證,1000 張用于測試。

表1 新數據庫分組情況
為了使分組好的數據能被深度網絡直接使用,還需要對原始數據進行預處理,首先是數據向量化,圖片數據是以JPG 格式存儲,不能直接使用,因此需要將其轉換成浮點張量的格式。其次是標準化輸入值,如果數據特征差異大,送入深度網絡后,會導致網絡梯度變化劇烈,參數更新大,導致網絡無法收斂,因此這樣是不安全的,必須進行標準化。通常的標準化是使其特征平均值為0,標準差為1。
■1.3 模型搭建
由于本次運用的數據集較小,為了使性能依舊出眾,將采用深度學習中非常熱門的遷移學習[9~11],遷移學習指的是一個預訓練的網絡模型重新運用到另一個任務中,本文中的預訓練模型是通過ImageNet 數據集訓練的,ImageNet數據集中包含許多動物類別,其中也包含了不同種類的貓和狗,因此其提取的基礎特征具有可移植性,能應用到貓狗分類問題中。因此我們使用在ImageNet 數據集上訓練的VGG19 網絡的卷積基從貓狗圖像中提取基礎通用特征,然后在這些特征的基礎上訓練一個貓狗分類器。模型的搭建步驟如下:
A.從Keras 庫中導入VGG19 模型。
B.由于ImageNet 數據集訓練的網絡輸出有1000 個類別,不符合本次實驗,因此去掉模型最后的密集分類器。
C.加入新的密集分類器,同時凍結卷積基,保證卷積基的參數不被訓練時破壞。
D.通過新建立的數據集,訓練新添加的密集分類器。
2 優(yōu)化器原理
在深度學習領域中我們對網絡模型架構進行設計是非常關鍵的,同時也是最受關注的。比如應該有多少層,每一層的應該怎么連接。由于本文是對優(yōu)化器進行研究,因此對架構的設計不做具體展開說明,而重點放在另一個非常重要的關鍵點上,即對優(yōu)化器的探討。
深度學習中優(yōu)化的過程如圖1 所示。首先把預處理好的數據送入搭建好的網絡架構中,網絡結構的輸出端將得到一個經過網絡初始參數計算的輸出值。輸出值與理想輸出值做運算得到損失函數(loss function),也就是我們要優(yōu)化的函數,有時我們也稱為代價函數(cost function)。對損失函數優(yōu)化通常采用梯度下降(gradient descent)方法。使用梯度下降算法優(yōu)化了單個參數的取值,反向傳播過程則是把梯度下降算法應用到所有參數上,因此加速更新網絡架構的參數,經過多次迭代優(yōu)化我們可以找到損失函數的最優(yōu)值。
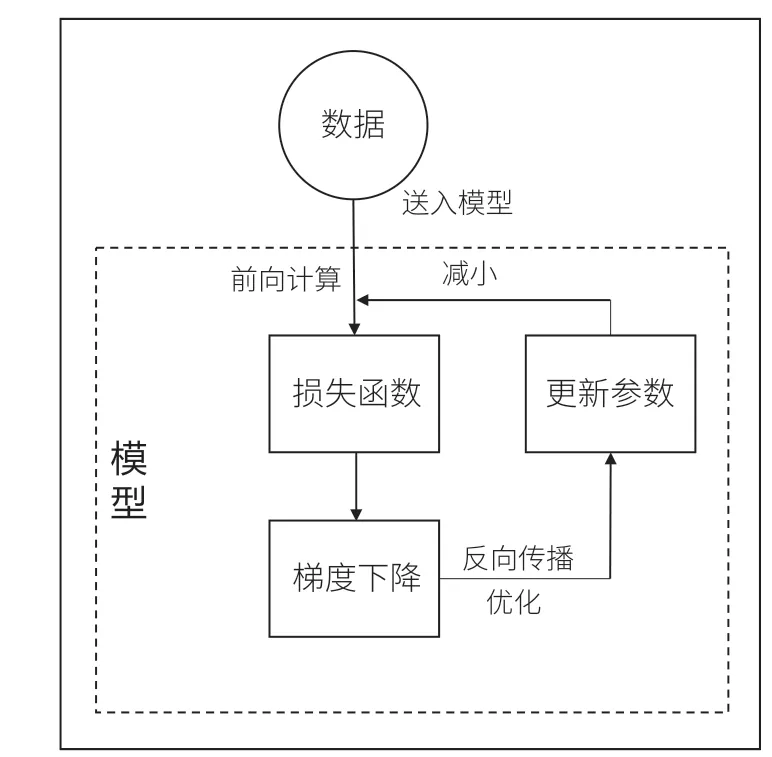
圖1 深度學習的優(yōu)化過程
■2.1 隨機梯度下降
梯度下降法的計算過程就是沿梯度下降的方向求解極小值,優(yōu)化通常指的是通常以最小化損失函數為目標,最小化就等同于最大化函數的負值。但是在實際訓練中,由于模型參數量過大,使用梯度下降算法計算非常消耗時間。因此為了減少參數的更新時間,通常使用隨機梯度下降算法(stochastic gradient descent,SGD)。SGD 算法的核心是隨機選擇小規(guī)模樣本來近似軌跡梯度,而不是針對所有的樣本。因此該算法明顯地降低了計算量[12]。
■2.2 自適應學習率算法
在深度學習中,由于優(yōu)化參數對目標函數的依賴各不相同,如果只設置統一的全局學習率,對于梯度很大的學習過程,由于步長過長收斂速度會很慢,當學習率設置過大時,已經優(yōu)化好的參數反而會震蕩,出現不穩(wěn)定的情況。因此在訓練過程中應該通過一些算法實現學習率的自適應。下面是比較經典的自適應學習率算法。
(1)AdaGrad 算法
AdaGrad 算法是由Jhon Duchi 博士在2011 年提出[13],能獨立地適應所有模型的參數,當梯度比較大時,學習率也相應地增大,而梯度變化平緩時,學習率相應地減小。其具體實現過程如表2 所示。

表2 AdaGrad算法實現過程
(2)RMSProp 算法
RMSProp 算法是由Hinton 在2012 提出[14],主要是對AdaGrad 算法進行改進,在非凸函數的運用中效果良好,改變梯度積累為指數加權的移動平均。AdaGrad 旨在應用于凸問題時快速收斂。當應用于非凸函數訓練神經網絡時,學習軌跡可能穿過了很多不同的結構,最終到達一個局部是凸碗的區(qū)域。AdaGrad 根據平方梯度的整個歷史收縮學習率,可能使得學習率在達到這樣的凸結構前就變得太小了[15]。RMSProp 采用指數衰減率減少從開始就積累的累計平方梯度,從而實現能夠在找到凸碗狀結構后快速收斂,它就像一個初始化于該碗狀結構的AdaGrad 算法實例。
RMSProp 算法的具體實現過程如表3 所示,相比于AdaGrad,RMSProp 算法引入了一個新的衰減速率參數,用來控制歷史梯度值的衰減。因此,RMSProp 優(yōu)化算法可以解決AdaGrad 算法中由于累計梯度過大,導致學習率過快下降導致模型收斂速度慢的問題,是一種有效且實用的深度神經網絡優(yōu)化算法。由于其良好的性能,在大多數場景會被首先作為優(yōu)化算法調速。

表3 RMSProp算法實現過程
(3)Adam 算法
Adam 算法是由Kingma在2014 提 出[16],“Adam” 這個名字派生自短語“adaptive moments”。是一種結合RMSProp 進行改進的自適應學習率優(yōu)化算法。在Adam 中,動量直接并入了梯度一階矩(指數加權)的估計。Adam 通常被認為對超參數的選擇相當魯棒,盡管學習率有時需要從建議的默認值修改。Adam 算法的具體實現過程如表4所示。

表4 Adam算法實現過程
3 實驗結果與分析
本次實驗采用的電腦為Windows10 操作系統,CPU∶Intel(R) Core(TM) i5-9400F CPU@2.90GHz RAM∶16GB。GPU∶GeForce GTX 1060 6G,選用深度學習TensorFlow 框架。
在對網絡進行評價時,考慮loss 損失和accuracy 準確率。在訓練中,loss 值會隨著次數的增加逐漸趨于0,因此,可以反映網絡的效果;accuracy 準確率是用單獨的測試集對訓練完成的網絡的輸出結果。通過遷移學習方法搭建了網絡模型,對模型進行訓練,當優(yōu)化算法選擇AdaGrad 時,其訓練精度和損失精度如圖2 所示。
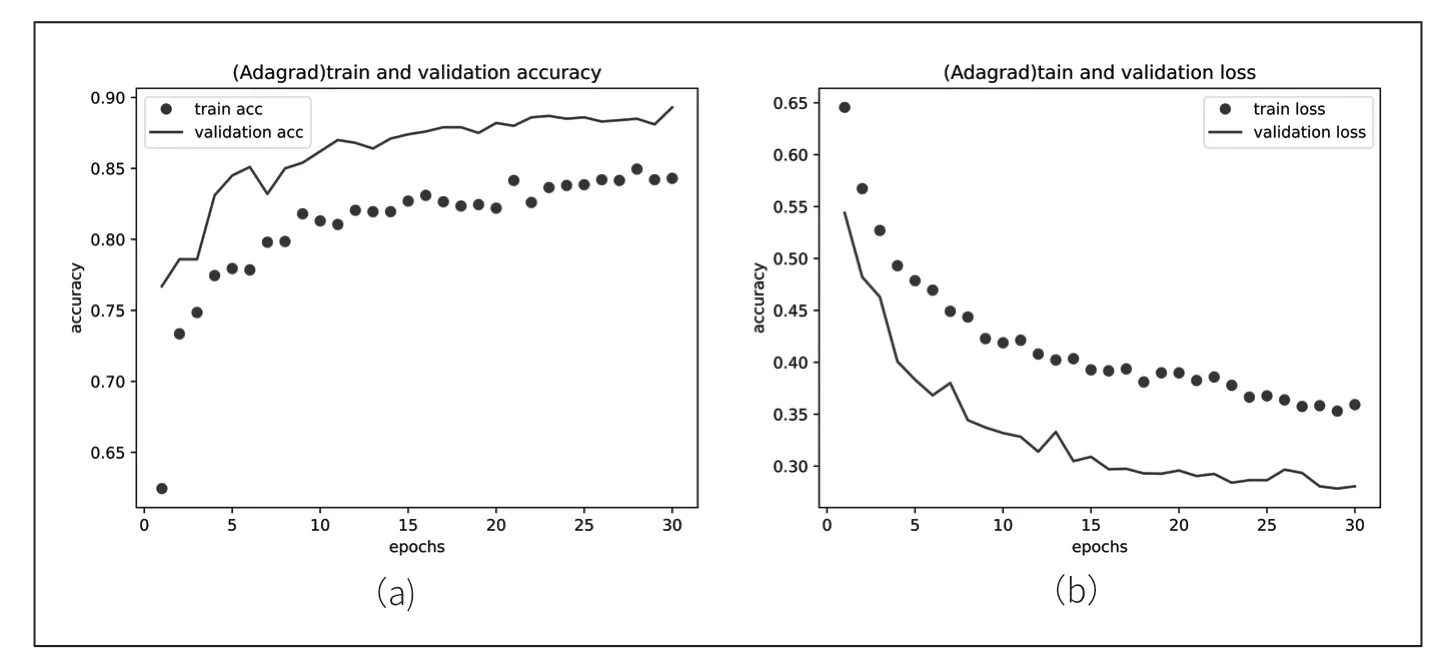
圖2 AdaGrad 優(yōu)化算法的精度與損失
由圖2 可知,開始訓練時學習率較大,準確率上升較快,到達第10 個epochs 時,梯度平方積累過大,導致學習率減小,所以可以發(fā)現第20~30epochs 訓練率上升過慢。當優(yōu)化算法選擇RMSProp時,其訓練精度和損失精度如圖3 所示。
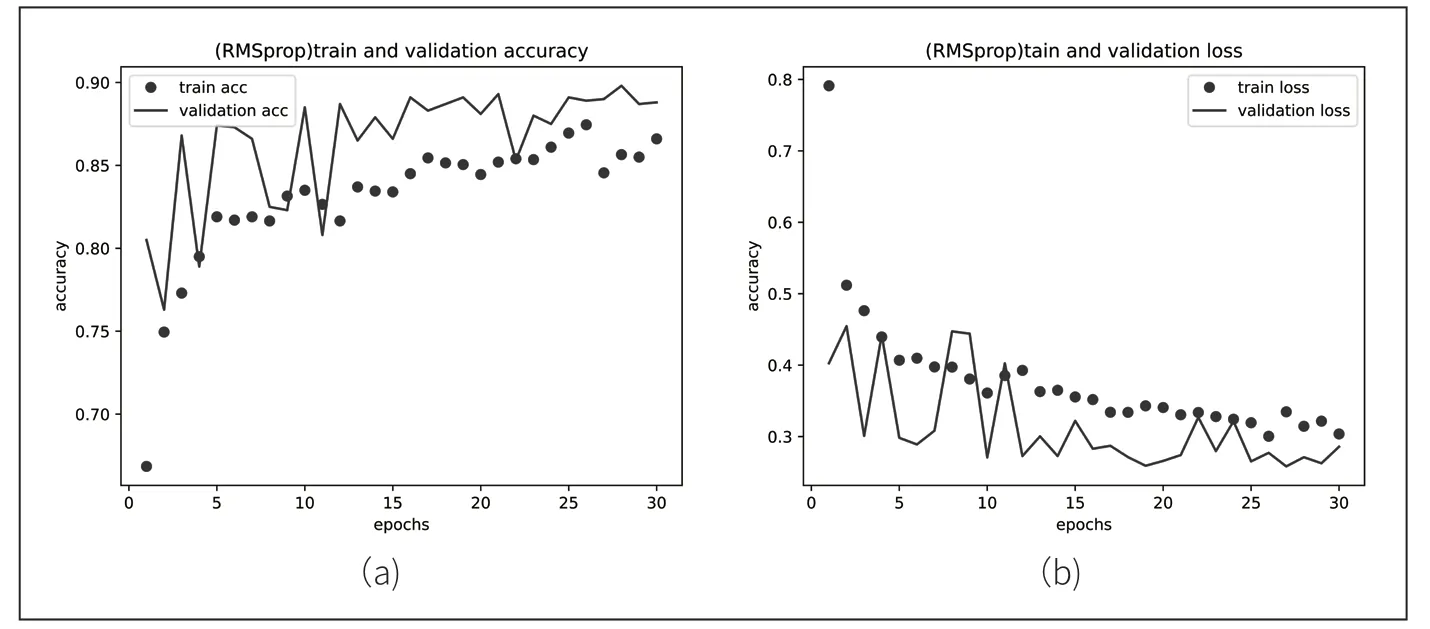
圖3 RMSprop 優(yōu)化算法的精度與損失
由圖3 我們可以發(fā)現RMSProp 算法訓練準確率優(yōu)于AdaGrad 優(yōu)化算法,因為增加了歷史梯度衰減率,可以減小歷史梯度對當前參數優(yōu)化的影響。當優(yōu)化算法選擇Adam時,其訓練精度和損失精度如圖4 所示。

圖4 Adam 優(yōu)化算法的精度與損失
從圖4 可得,訓練的準確率是三種優(yōu)化算法中最高的,達到了86.3%。但是由于二階動量是固定時間步內的累積,隨著時間步的變化,遇到的數據可能發(fā)生巨變,使得二階矩的偏差可能會時大時小,不是單調變化。這就導致在訓練后期引起學習率的震蕩,因此很明顯觀察到訓練準確率后期波動較大。三種優(yōu)化算法準確率精度、損失精度如表5 所示。

表5 三種優(yōu)化算法對比
4 結語
目前各種各樣的優(yōu)化器層出不窮,選擇一個合適的優(yōu)化器對模型訓練有著很大的幫助。本文通過設計合理的實驗來比較不同優(yōu)化器的性能,基于深度學習的VGG19 架構,使用三種不同的優(yōu)化算法對模型進行訓練,優(yōu)化器對模型的訓練效果產生不同的影響,由實驗結果可知,優(yōu)化器并不是對所有的模型都能適用,通過實驗的設計,可以讓學生更深入、更直觀地看見優(yōu)化器的具體實現效果,可以選擇最佳的優(yōu)化器策略來訓練深度學習模型,從而提高模型的性能和收斂速度。在進行實際應用中,實驗設計和評估過程應該與具體任務和數據集的特點相結合,以獲得更準確和有效的實驗結果。同時學生可以對優(yōu)化算法的工作原理更加理解深刻。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
