基于相對離群因子的標(biāo)簽噪聲過濾方法
2024-02-03 10:41:36侯森寓姜高霞王文劍
自動化學(xué)報 2024年1期
侯森寓 姜高霞 王文劍,2
分類是機器學(xué)習(xí)領(lǐng)域中一項重要的任務(wù),大量研究表明,數(shù)據(jù)質(zhì)量決定著訓(xùn)練出的分類模型的泛化性能[1].隨著人工智能技術(shù)的進(jìn)步,風(fēng)險與挑戰(zhàn)也隨之而來,許多人工智能應(yīng)用領(lǐng)域(如醫(yī)學(xué)診斷、人臉識別和智能駕駛等)需要更高的數(shù)據(jù)質(zhì)量,以保證模型的準(zhǔn)確率(Accuracy,Acc)[2-4].然而,由于對數(shù)據(jù)實施可靠標(biāo)記通常是昂貴而耗時的,對于實際的機器學(xué)習(xí)來說,數(shù)據(jù)普遍包含噪聲是一個不容忽視的問題[5].因此,實施噪聲清除或降低噪聲對模型泛化性能的影響是十分必要的.
監(jiān)督學(xué)習(xí)中的數(shù)據(jù)噪聲主要分為特征噪聲和標(biāo)簽噪聲兩種類型[6].特征噪聲是指觀測到的特征與真實特征存在誤差的數(shù)據(jù),例如由于物聯(lián)網(wǎng)設(shè)備故障,部分?jǐn)?shù)據(jù)采集到錯誤、缺失或不完整的特征值[7];標(biāo)簽噪聲是指觀測到的實例標(biāo)簽與真實標(biāo)簽不一致的數(shù)據(jù),例如在醫(yī)療診斷中,由于專家標(biāo)記的不一致性,造成病例數(shù)據(jù)標(biāo)簽錯誤[8].文獻(xiàn)[9]從統(tǒng)計角度考量,提出標(biāo)簽噪聲主要有完全隨機噪聲、隨機噪聲和非隨機噪聲三類.它們通過噪聲樣本與其特征和標(biāo)簽的關(guān)聯(lián)性進(jìn)行區(qū)分,完全隨機噪聲的產(chǎn)生獨立于數(shù)據(jù)樣本的特征值和標(biāo)簽類別;隨機噪聲和非隨機噪聲的產(chǎn)生與數(shù)據(jù)的特征或標(biāo)簽類別之間存在一定的關(guān)聯(lián)性,這種關(guān)聯(lián)可能是由于標(biāo)簽分配過程中的系統(tǒng)性、主觀性錯誤或模糊類別邊界等原因造成的.
根據(jù)機器學(xué)習(xí)任務(wù)的不同,標(biāo)簽噪聲在分類與回歸任務(wù)中,又分別稱為類別型標(biāo)簽噪聲和數(shù)值型標(biāo)簽噪聲[9].在分類任務(wù)中,無論是特征噪聲還是類別型標(biāo)簽噪聲都會影響模型的泛化性能,但研究表明,標(biāo)簽噪聲比特征噪聲具有更大的危害性.一方面,數(shù)據(jù)通常具有多個特征,而標(biāo)簽是唯一的;另一方面,每個特征對于分類模型學(xué)習(xí)的重要性不盡相同,而標(biāo)簽的正確與否對模型學(xué)習(xí)有著更大的影響.因此,處理分類任務(wù)中的標(biāo)簽噪聲問題顯得至關(guān)重要.
解決分類任務(wù)中的標(biāo)簽噪聲問題可以從算法層和數(shù)據(jù)層2 個層面考慮.在算法層面的處理依賴于構(gòu)建對標(biāo)簽噪聲具有魯棒性的模型(如重構(gòu)損失函數(shù)和加權(quán)集成等方式),通過提高模型對噪聲的容忍,以減少其受標(biāo)簽噪聲的影響.但是,魯棒模型并不能完全魯棒[10].數(shù)據(jù)層面的處理是通過標(biāo)簽噪聲過濾的方法提高數(shù)據(jù)質(zhì)量[11],標(biāo)簽噪聲在訓(xùn)練前就已經(jīng)被識別并處理掉.顯然,標(biāo)簽噪聲過濾更直接有效.
針對分類任務(wù)中的類別型標(biāo)簽噪聲問題,本文從離群點與噪聲的相關(guān)性出發(fā),提出相對離群因子(Relative outlier factor,ROF),以評估數(shù)據(jù)的噪聲概率,并據(jù)此構(gòu)建標(biāo)簽噪聲過濾方法.本文主要貢獻(xiàn)有以下3 個方面:
1)基于離群點檢測算法提出相對離群因子,它可以對數(shù)據(jù)每個樣本點進(jìn)行噪聲概率評估,依據(jù)該評估,可以實現(xiàn)噪聲檢測和初步的過濾;
2)以提高模型泛化能力為目標(biāo),根據(jù)1)提出的噪聲概率評估方法,設(shè)計基于相對離群因子的集成過濾方法(Label noise ensemble filtering method based on relative outlier factor,EROF),使得噪聲過濾更加穩(wěn)定精確;
3)在標(biāo)準(zhǔn)數(shù)據(jù)集的實驗結(jié)果表明,本文方法與現(xiàn)有的噪聲過濾方法相比,能更有效地提升數(shù)據(jù)質(zhì)量和模型的泛化性能.
1 相關(guān)工作
本節(jié)主要介紹已有的標(biāo)簽噪聲過濾方法和離群點檢測算法,并對這些方法進(jìn)行簡單歸納和總結(jié).
1.1 標(biāo)簽噪聲過濾方法
標(biāo)簽噪聲過濾方法一般是指檢測并過濾訓(xùn)練數(shù)據(jù)中的噪聲樣本,通過該方法提升數(shù)據(jù)質(zhì)量,以確保訓(xùn)練出的模型性能.
早期過濾算法是利用分類模型對噪聲的敏感性來檢測標(biāo)簽噪聲.常見做法是將分類器對樣本的預(yù)測標(biāo)簽和樣本觀測標(biāo)簽的一致性作為識別標(biāo)簽噪聲的指標(biāo)之一[12].這個方法被稱為分類過濾,文獻(xiàn)[13]提出運用K折交叉驗證方法,將測試集上錯誤分類的樣本直接視為噪聲刪除.然而,分類過濾面臨著“先有雞,還是先有蛋”的悖論[14],該過濾方法必須有精確的分類器,而在含噪數(shù)據(jù)集上,大概率訓(xùn)練出較差的分類器.
由于集成學(xué)習(xí)的廣泛應(yīng)用,基于不同集成策略的過濾方法應(yīng)運而生,代表性方法有多數(shù)投票過濾器(Majority vote filter,MVF)[15]、動態(tài)集成過濾器[16]和高一致性隨機森林(Random forest,RF)過濾器[17].這些過濾方法的主要思想都是通過多個基分類器的預(yù)測結(jié)果組合后的正確程度,來識別噪聲.集成過濾器通常比單一基過濾器具有更好的精度,但其本質(zhì)上還是基于模型預(yù)測的過濾方法,仍存在上述的悖論問題,且計算成本通常更大.
更為常見的是基于近鄰模型的過濾方法,通常需要借助K近鄰(K-nearest neighbors,KNN)模型實現(xiàn).如編輯近鄰[18]過濾器、全近鄰[19]過濾器、互近鄰(Mutual nearest neighbor,MNN)[20]過濾器.這些過濾器對近鄰參數(shù)k的選取過于敏感.近鄰感知[21]過濾算法采用迭代搜索思想,解決參數(shù)k的自適應(yīng)問題,但仍存在一定的維度災(zāi)難問題.
在準(zhǔn)確性和可靠性方面,依賴分類器和近鄰模型識別標(biāo)簽噪聲的效果均不理想,Xia 等[22-24]提出基于相對密度(Relative density-based,RD)的過濾方法和基于完全隨機森林(Complete random forest,CRF)的過濾方法,并擴(kuò)展應(yīng)用于多分類數(shù)據(jù)集的噪聲過濾中.RD 利用樣本的相對密度來衡量樣本的噪聲強度,CRF 通過構(gòu)建完全隨機樹來衡量樣本被異類樣本包圍的水平,進(jìn)而確定樣本的噪聲強度.為解決其中的硬閾值問題,基于自適應(yīng)投票策略的相對密度過濾器vRD[24]算法和自適應(yīng)完全隨機森林過濾器Adp_mCRF[25]算法被相繼提出.但是,這兩種方法都使用隨機劃分測試集的分類精度作為自適應(yīng)指標(biāo),導(dǎo)致在噪聲比例(Noise ratio,NR)較高時,過濾效果下降.
基于深度學(xué)習(xí)的標(biāo)簽噪聲過濾方法利用神經(jīng)網(wǎng)絡(luò)強大的表示學(xué)習(xí)能力捕獲數(shù)據(jù)底層結(jié)構(gòu),從而識別和過濾噪聲.例如,Lu 等[26]依據(jù)神經(jīng)網(wǎng)絡(luò)對樣本預(yù)測置信度進(jìn)行噪聲識別和過濾;Han 等[27]基于深度神經(jīng)網(wǎng)絡(luò)對于噪聲數(shù)據(jù)的記憶時效性,提出“Coteaching”深度學(xué)習(xí)范式,此方法通過訓(xùn)練兩個深度神經(jīng)網(wǎng)絡(luò)對標(biāo)簽噪聲數(shù)據(jù)進(jìn)行遺忘,緩解誤差累積,從而在高標(biāo)簽噪聲環(huán)境下,訓(xùn)練出更具魯棒性的模型.但基于深度學(xué)習(xí)的方法通常需要大量的計算資源和數(shù)據(jù)來訓(xùn)練模型,數(shù)據(jù)量較少會導(dǎo)致模型過擬合,無法泛化到新的數(shù)據(jù).
Xiong 等[28]基于離群點與噪聲具有一定相似性的特點,提出利用離群點檢測技術(shù),完成噪聲過濾的方法,但該方法將離群點視為噪聲的思想有失偏頗.Zhang 等[29]提出基于穩(wěn)健深度自動編碼器的離群點檢測技術(shù)過濾噪聲,該方法將檢測出的離群點作為候選誤標(biāo)記數(shù)據(jù),再經(jīng)過一種基于重構(gòu)誤差最小化方法,驗證最終視為噪聲的樣本,但其本質(zhì)仍是將樣本是否為離群點作為噪聲檢測的基礎(chǔ).
1.2 離群點檢測算法
離群點檢測技術(shù)相較于類別型標(biāo)簽噪聲過濾技術(shù)更為成熟,出于簡潔性、有效性、多樣性等多方面考量,本節(jié)簡要介紹6 種主流的離群點檢測算法.
1)K近鄰[30]離群點檢測算法通過評估數(shù)據(jù)點與其第k近鄰數(shù)據(jù)的距離,來檢測離群程度.
2)局部離群因子(Local outlier factor,LOF)[31]檢測算法利用局部鄰域密度的概念,來檢測離群點.
3)基于連通性離群因子[32]檢測算法在LOF 算法基礎(chǔ)上,根據(jù)數(shù)據(jù)點的鏈接偏移程度,來評價其離群度.
4)為緩解維度災(zāi)難問題,基于角度的離群點檢測[33]算法提出運用數(shù)據(jù)點與其近鄰之間角度的加權(quán)方差,來檢測離群程度.該方法能更精確地給出高維空間中數(shù)據(jù)點的離群因子.
5)單類支持向量機(Support vector machine,SVM)[34]通過數(shù)據(jù)點到超平面邊界的距離,來計算離群值.
6)基于近鄰隔離的離群點算法[35]使用孤立球模型,實現(xiàn)離群因子的度量,其中離群因子更高的數(shù)據(jù)點被半徑更大的超球體所孤立.
2 基于相對離群因子的集成過濾方法
本節(jié)主要介紹相對離群因子的計算及應(yīng)用,并據(jù)此提出基于相對離群因子的集成過濾方法.
2.1 相對離群因子
為更形象地展示相對離群因子的相關(guān)概念與計算過程,在人工生成的二分類數(shù)據(jù)集上進(jìn)行模擬實驗,其中包括34 個真實數(shù)據(jù)點和6 個類別型標(biāo)簽噪聲點,選用K近鄰分類(K-nearest neighbors clasifier,KNNC)模型作為基分類器(近鄰參數(shù)k設(shè)置為1).圖1 兩個子圖分別為在不含噪聲數(shù)據(jù)集和包含噪聲數(shù)據(jù)集中,訓(xùn)練所得的分類模型決策邊界圖,顯然圖1(b)的決策邊界相對于圖1(a)更復(fù)雜混亂,并且圖1(b)中部分處于決策邊界的正常樣本也被錯分了,這表明類別型標(biāo)簽噪聲對分類模型產(chǎn)生一定負(fù)面影響.因此,有效處理類別型標(biāo)簽噪聲是提高分類模型泛化能力的關(guān)鍵.
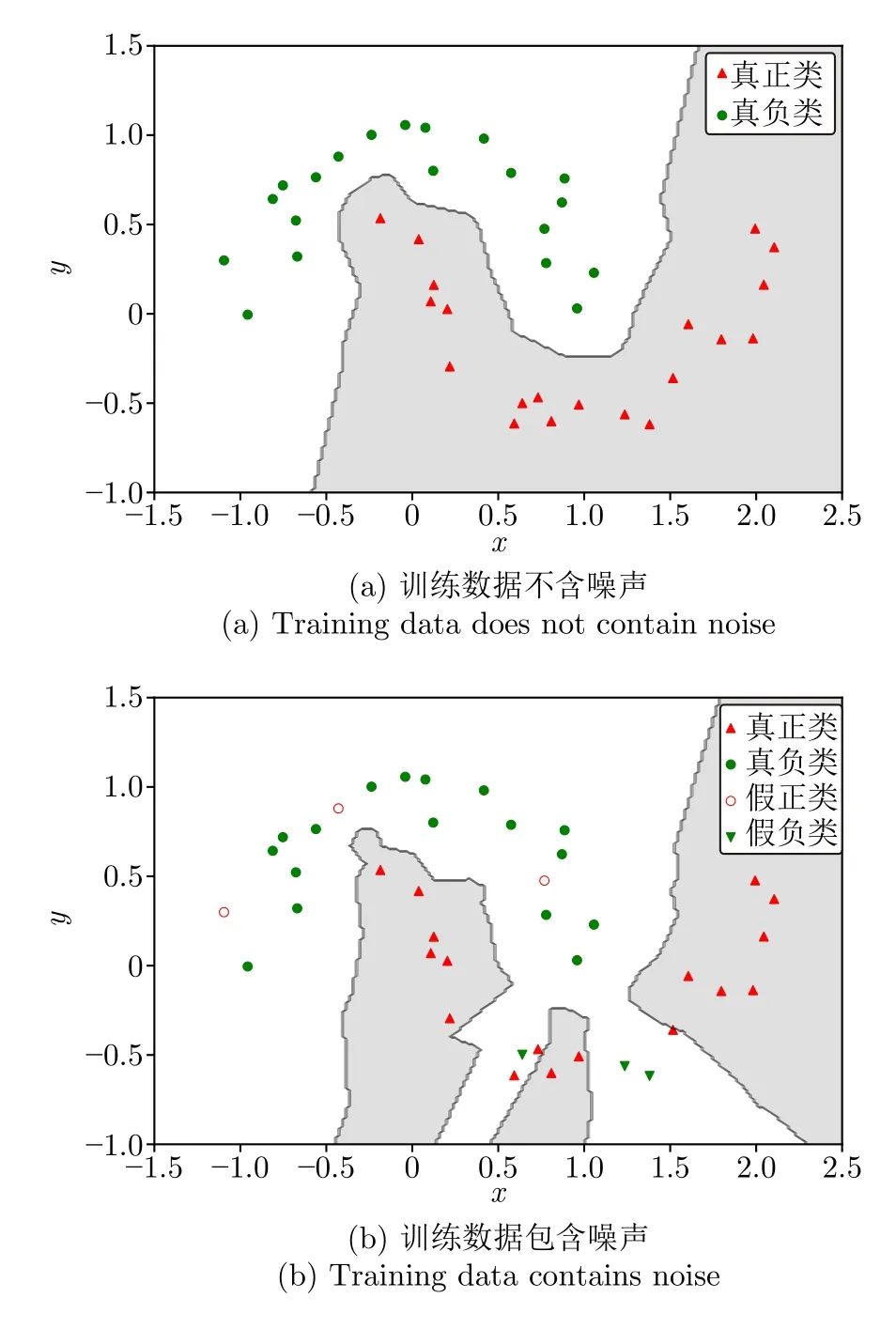
圖1 不同含噪情況下的分類模型決策邊界Fig.1 Decision boundary of classification model in different cases with noise
定義1.同質(zhì)樣本與異質(zhì)樣本
圖2 兩個子圖分別展示了圖1(b)包含噪聲數(shù)據(jù)集中,同質(zhì)樣本和異質(zhì)樣本的選取過程.如圖2(a)所示,樣本A=(xa,ya) 且有ya=正類,根據(jù)定義1,觀測標(biāo)簽為正類的樣本均為A的同質(zhì)樣本,其中包括兩個剩余的假正類樣本B和C;同理,如圖2(b)所示,A的異質(zhì)樣本為觀測標(biāo)簽是負(fù)類的全部樣本,包括三個假負(fù)類樣本D、E和F.

圖2 樣本A 的同質(zhì)、異質(zhì)樣本Fig.2 Homogeneous and heterogeneous samples of sample A
定義2.絕對離群因子
離群點是數(shù)據(jù)集中明顯異常的數(shù)據(jù)點.離群點檢測的目的是檢測出與正常數(shù)據(jù)差別較大的數(shù)據(jù)點.基于不同的離群點檢測方法,對于數(shù)據(jù)集中的每個樣本,總能給出一個離群程度的度量,定義該度量值為絕對離群因子(Absolute outlier factor,AOF).根據(jù)定義1,每個樣本點均有相對于其同質(zhì)、異質(zhì)樣本的一對絕對離群因子.
根據(jù)給定的距離度量方式,在D中找出與p最近的k個點,假定其中距p第k近的為樣本點qk,樣本點p的絕對離群因子基于其到第k近鄰樣本的距離進(jìn)行計算:
假定y p=正類,其同質(zhì)樣本集合記為D+,異質(zhì)樣本集合記為D-,則樣本點p的同質(zhì)絕對離群因子定義為:
同理,樣本點p的異質(zhì)絕對離群因子定義為:
基于離群點與噪聲點的相似性,標(biāo)簽噪聲往往具有更高的同質(zhì)絕對離群因子值.然而,并不能主觀地認(rèn)為離群因子越高,其為標(biāo)簽噪聲的概率就越大,即絕對離群因子與噪聲概率并不是強正相關(guān)關(guān)系[22].例如標(biāo)簽噪聲位于出現(xiàn)概率相近的邊界區(qū)域,則該樣本點的離群因子值并不會表現(xiàn)得很高;而離群因子值較高的樣本也不一定是標(biāo)簽噪聲,它可能是由于樣本本身的特征噪聲導(dǎo)致的低概率事件.
以圖1(b)的人工包含噪聲數(shù)據(jù)集為例,圖3 四個子圖分別給出了基于KNN 離群點檢測算法(近鄰參數(shù)k設(shè)置為5)計算部分樣本點兩類絕對離群因子的結(jié)果.其中,A為假正類樣本,是噪聲樣本;G為真負(fù)類樣本,是正常樣本.
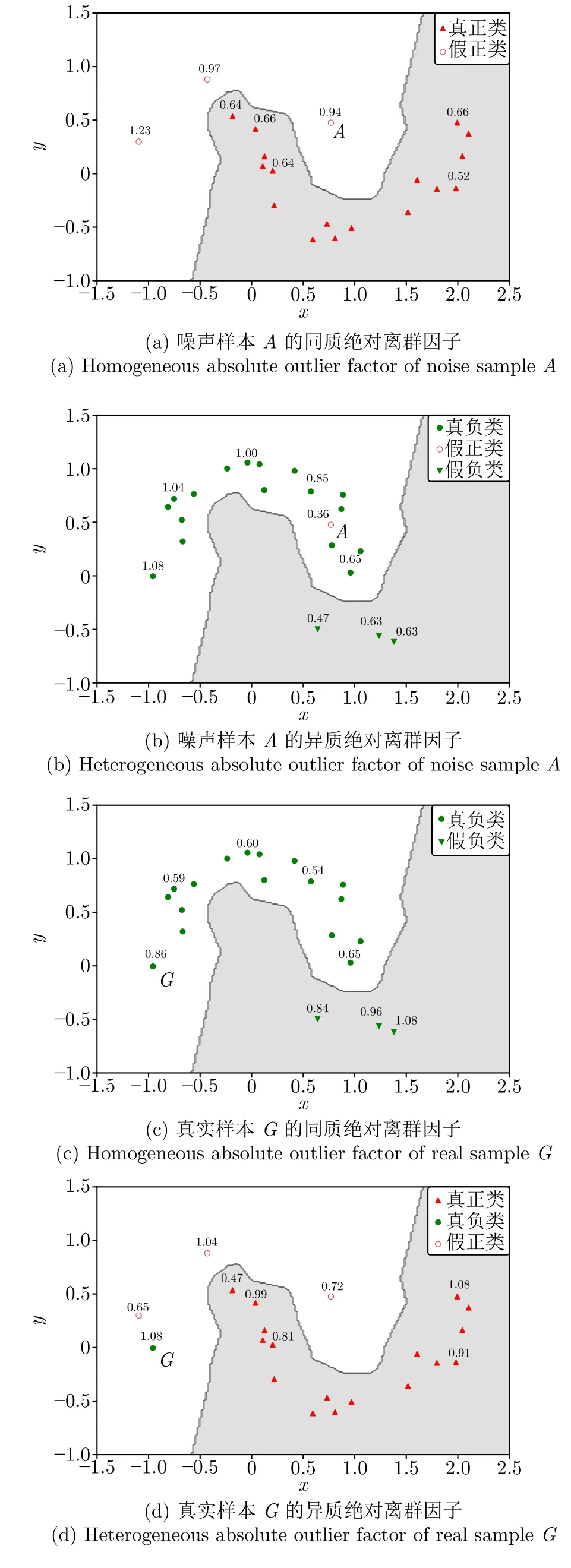
圖3 噪聲樣本A 與真實樣本G 的絕對離群因子Fig.3 Homogeneous and heterogeneous absolute outlier factor results of noise sample A and real sample G
如圖3(a) 所示,A點的同質(zhì)絕對離群因子f(A)=0.94,顯然該值相較于其他真正類樣本更高;而圖3(b) 顯示其異質(zhì)絕對離群因子g(A)=0.36,這是由于A被大多數(shù)與其相反標(biāo)簽的樣本點包圍,導(dǎo)致A點在異質(zhì)樣本環(huán)境中,具有更低的異質(zhì)絕對離群因子.因此,可以得出含噪樣本的同質(zhì)絕對離群因子往往高于異質(zhì)絕對離群因子的結(jié)論.
在圖3(c)和圖3(d)中,真實樣本G由于離數(shù)據(jù)集群較遠(yuǎn),故其兩類離群因子都偏高,特別是其同質(zhì)絕對離群因子相較于部分噪聲樣本,反而更高.這也印證了絕對離群因子與噪聲概率間并不是強正相關(guān)關(guān)系.但是,它的同質(zhì)絕對離群因子0.86 低于其異質(zhì)絕對離群因子0.65,該大小關(guān)系符合其為正常點的事實.基于以上分析,提出相對離群因子的定義來估計樣本的噪聲概率.
定義3.相對離群因子
設(shè)有二分類數(shù)據(jù)集D,假定有樣本點p=(xp,yp),定義樣本p的相對離群因子為:
類似地,若y p=負(fù)類,定義樣本p的相對離群因子為:
相對離群因子可用于識別類別型標(biāo)簽噪聲,ROF值越大的樣本,標(biāo)簽噪聲的概率也越高.為確定相對離群因子評估噪聲概率的有效性,沿用KNN 離群點檢測算法(近鄰參數(shù)k設(shè)置為5),計算圖1(b)中數(shù)據(jù)的相對離群因子值,部分計算結(jié)果如圖4 所示.其中標(biāo)簽噪聲點(即含噪正類與含噪負(fù)類樣本)的相對離群因子分別為2.49、2.27、2.23、1.79、1.71和1.54.這些值都遠(yuǎn)大于真實數(shù)據(jù)點的相對離群因子值.由圖4 可以看出,靠近分類邊界或遠(yuǎn)離集群的真實樣本,其同質(zhì)絕對離群因子值偏大,導(dǎo)致相對離群因子也偏大,但相對離群因子值并沒有超過噪聲樣本,這說明相對離群因子與樣本噪聲概率的相關(guān)關(guān)系更強,在噪聲的判別上,相對離群因子比絕對離群因子更可靠.
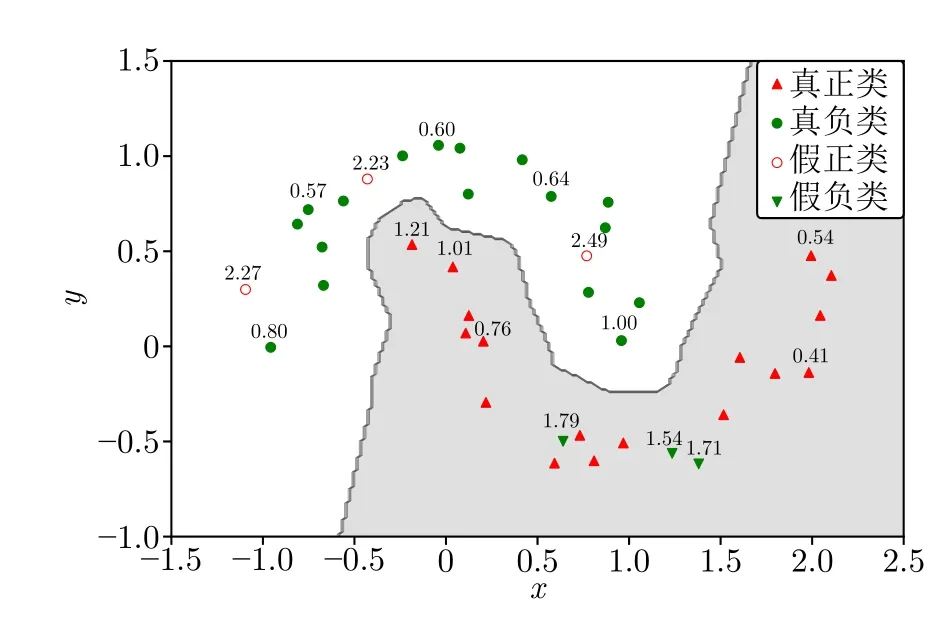
圖4 數(shù)據(jù)的相對離群因子Fig.4 Relative outlier factors for data
總之,計算樣本的相對離群因子能夠評估其是噪聲的概率,從而有效檢測類別型標(biāo)簽噪聲.據(jù)此提出基于相對離群因子的標(biāo)簽噪聲過濾算法,主要步驟如算法1 所示.
算法1.基于相對離群因子的過濾算法
輸入.分類數(shù)據(jù)集D,離群檢測模型p,參數(shù)為過濾閾值t或過濾比率r.
輸出.去噪數(shù)據(jù)集D′,噪聲集N.
初始化.噪聲集N=?.
1)根據(jù)式(3)、式(4),利用離群檢測模型p計算全部樣本的同質(zhì)、異質(zhì)絕對離群因子;
2)根據(jù)式(5)、式(6),計算全部樣本的相對離群因子;
3)將數(shù)據(jù)按相對離群因子大小降序排列;
4)將相對離群因子大于過濾閾值t的樣本或前n×r個樣本加入噪聲集N中;
5)得到去噪數(shù)據(jù)集D′=D-N.
該算法的時間復(fù)雜度主要取決于基離群檢測模型計算每個類別離群因子的復(fù)雜度.以KNN 離群點檢測算法作為基檢測模型為例,若采用K維樹算法加速搜索K近鄰[36],算法1 的時間復(fù)雜度為O(mnlogn),其中m為類別數(shù),n為樣本數(shù).當(dāng)類別數(shù)與樣本數(shù)均較大時,類別數(shù)對算法的時間開銷會顯著增加.但在實際中,數(shù)據(jù)集的類別數(shù)通常遠(yuǎn)小于樣本數(shù),因此算法1 的時間復(fù)雜度可近似為O(nlogn).
2.2 基于相對離群因子的集成過濾方法
對于不同分布的數(shù)據(jù),基于單一基離群點檢測模型計算的相對離群因子無法始終保持噪聲概率評估的精確性.鑒于現(xiàn)有成熟的離群點檢測技術(shù),提出基于相對離群因子的集成過濾方法,該方法采取貪心策略確定最優(yōu)聯(lián)合檢測器,以保證迭代過濾后的數(shù)據(jù)能訓(xùn)練出最優(yōu)泛化性能的分類模型,主要步驟如算法2 所示.
算法2.基于相對離群因子的集成過濾算法
輸入.分類數(shù)據(jù)集M,單次迭代過濾比率r′,基離群檢測器池P=
輸出.去噪數(shù)據(jù)集M′.
1)計算獲得基檢測器排名池P′:
a)利用算法1 (輸入.分類數(shù)據(jù)集D=M,離群檢測模型p=pk,過濾比率r=r′),獲得m個不同的去噪數(shù)據(jù)集;
b)通過交叉驗證,獲得分類模型在不同去噪數(shù)據(jù)集上的準(zhǔn)確率Acc;
c)將檢測器按對應(yīng)的準(zhǔn)確率降序排列,得到基檢測器排名池P′.
初始化.迭代輪數(shù)k=1,緩沖噪聲池N*=?,緩沖去噪池M*=M,最大準(zhǔn)確率M Acc=0.
2)利用算法1 (輸入.分類數(shù)據(jù)集D=M,離群檢測模型p=pk,過濾比率r=r′),得到噪聲集Nk;
3) 同時更新緩沖噪聲池N*=N*+Nk和緩沖去噪池M*=M-N*;
4)通過交叉驗證,獲得分類模型在緩沖去噪數(shù)據(jù)集D*的準(zhǔn)確率;
5) 若A cc>MAcc,則同時更新M Acc=Acc和去噪數(shù)據(jù)集M′=M*;否則,回溯兩個緩沖池N*=N*-Nk,M*=M+N*;
6)若k<m,令k=k+1,并重復(fù)執(zhí)行步驟2)~6);否則,停止循環(huán),獲得最終的去噪數(shù)據(jù)集M′.
算法2 的主要流程如圖5 所示,其中黃色區(qū)域表示需要重復(fù)計算的步驟,灰色區(qū)域表示緩存的步驟.算法2 利用多種互補的基離群點檢測算法,尋求聯(lián)合檢測模型的最優(yōu)解,算法主要分為基檢測模型排名階段(步驟1))和迭代聯(lián)合過濾階段(步驟2)~6))兩個階段.基檢測模型排名階段檢測出的噪聲為聯(lián)合過濾階段提供多樣的去噪組合,因此在實際運行中,無需反復(fù)調(diào)用基檢測器進(jìn)行噪聲識別.
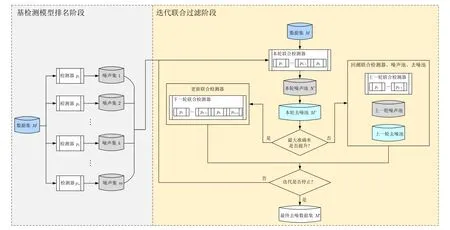
圖5 EROF 算法流程示意圖Fig.5 Flowchart diagram of the EROF Algorithm
該算法的時間復(fù)雜度仍主要取決于基離群點檢測算法的復(fù)雜度,以第1.2 節(jié)的6 種基檢測器為例,其中LOF 算法擁有最高的時間復(fù)雜度為 O (n2),在此情況下,該算法的時間復(fù)雜度 T (EROF)=O(n2).如果基檢測器池加入其他模型,則該算法的時間復(fù)雜度與基檢測器池中獨立檢測器的最高時間復(fù)雜度相同.
3 UCI 數(shù)據(jù)集實驗
本節(jié)介紹基于相對離群因子的集成過濾方法在UCI 標(biāo)準(zhǔn)數(shù)據(jù)集上的實驗框架、基檢測器對比、參數(shù)確定、實驗結(jié)果與相關(guān)分析.
3.1 實驗框架
實驗采用來自UCI 的20 個標(biāo)準(zhǔn)數(shù)據(jù)集,詳細(xì)信息見表1.這些數(shù)據(jù)集主要來自真實世界數(shù)據(jù),例如,第14 號Isolet 數(shù)據(jù)集包含美國英語字母的語音樣本,由不同發(fā)音者朗讀錄制;第20 號Letter 數(shù)據(jù)集基于20 種不同字體的黑白矩形像素,顯示26 個大寫英文字母,特征包括長/寬比、最大水平和垂直筆畫數(shù)、筆畫密度等.為驗證各過濾算法的有效性,實驗將每個數(shù)據(jù)集按7:3 的比例,隨機劃分為訓(xùn)練集和測試集,并在訓(xùn)練集上完全隨機制造一定比例的人工標(biāo)簽噪聲.首先,用本文過濾方法與其他主流過濾算法過濾訓(xùn)練集后,進(jìn)行各項指標(biāo)的對比;然后,用去噪后的訓(xùn)練集訓(xùn)練分類模型;最后,在測試集上,對比其泛化性能.由于實驗中的人工噪聲為完全隨機添加,為降低實驗結(jié)果的偶然性,實驗結(jié)果采用不同隨機加噪10 次的平均值.
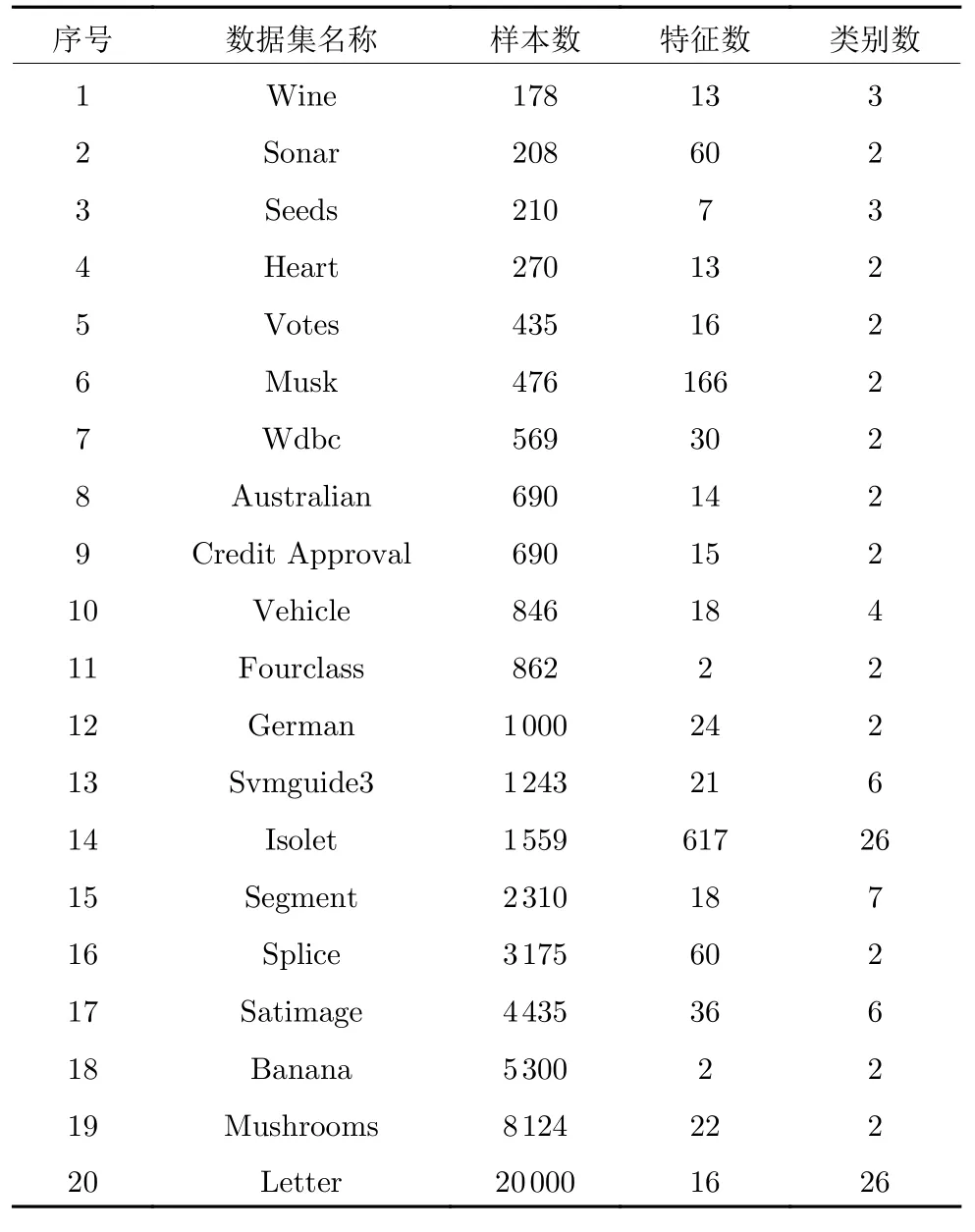
表1 數(shù)據(jù)集信息Table 1 Information of data sets
為驗證算法的有效性,實驗采用準(zhǔn)確率、噪聲過濾準(zhǔn)確率(Noise filter accuracy,NfAcc)、查準(zhǔn)率(Precision,Pre)、召回率(Recall,Re)、特異度(Specificity,Spec)和F1 值六種噪聲識別評價指標(biāo),分別定義如下:
式中,真實結(jié)果是正常且預(yù)測結(jié)果也是正常的樣本,為真正常(True positive,TP);真實結(jié)果是噪聲且預(yù)測結(jié)果是正常的樣本,為假正常(False positive,FP);真實結(jié)果是正常且預(yù)測結(jié)果是噪聲的樣本,為假噪聲(False negative,FN);真實結(jié)果和預(yù)測結(jié)果均是噪聲的樣本,為真噪聲(True negative,TN).在評價指標(biāo)中,Acc、NfAcc、Pre、Re和F1 越高,表明算法的噪聲識別性能越好;S pec越高,表明噪聲過濾程度越高,但過高的Spec意味著算法可能存在過度清洗問題.
實驗設(shè)置10%、20%、30%、40%四種不同的噪聲比例,選用的六種對比過濾算法及參數(shù)設(shè)置分別為互近鄰過濾器(近鄰參數(shù)k設(shè)置為3)、多數(shù)投票過濾器(基分類器為1NN、C4.5 和樸素貝葉斯)、相對密度過濾器(近鄰參數(shù)k設(shè)置為5,過濾閾值rd設(shè)置為1)、完全隨機森林過濾器(隨機樹棵數(shù)Ntree設(shè)置為50,過濾閾值NI-threshold設(shè)置為5)、基于自適應(yīng)投票策略的相對密度過濾器(近鄰參數(shù)k設(shè)置為5)和自適應(yīng)完全隨機森林過濾器(隨機樹棵數(shù)Ntree設(shè)置為50).所有過濾算法還與不進(jìn)行任何過濾(No filtering,NoF)的情況進(jìn)行對比.
最后,在分類性能對比實驗中,測試所用的分類模型包括KNNC 模型、支持向量機分類模型、Adaboost 分類模型和隨機森林,分類模型的泛化性能用測試集上的分類準(zhǔn)確率來度量.
3.2 基檢測器對比
本節(jié)實驗在Wine 數(shù)據(jù)集上,驗證基檢測器的多樣性,采用基于KNN 和LOF 的兩種ROF 過濾算法,分別使用ROF_KNN 和ROF_LOF 表示算法名稱.噪聲比例NR和過濾比率r均設(shè)置為20%.通過隨機鄰域嵌入降維技術(shù),對數(shù)據(jù)集進(jìn)行加噪和去噪的可視化結(jié)果如圖6 所示.其中,黑色邊框標(biāo)記的樣本為未能正確識別出的噪聲樣本.ROF_KNN和ROF_LOF 都實現(xiàn)了良好的噪聲過濾效果.但兩個算法在噪聲檢測上并不完全相同.ROF_KNN未能過濾的部分噪聲樣本被ROF_LOF 成功過濾;反之,亦然.這表明,多種基檢測器間存在互補效應(yīng),結(jié)合多種基檢測器進(jìn)行噪聲檢測和過濾可提高噪聲過濾的準(zhǔn)確性和可靠性.因此,在后續(xù)實驗中,本文使用第1.2 節(jié)介紹的6 種基檢測器的組合,作為EROF 算法的默認(rèn)基離群檢測器池.

圖6 Wine 數(shù)據(jù)集上,基檢測器噪聲過濾對比Fig.6 Comparison of base detector noise filtering on Wine
3.3 參數(shù)確定
本節(jié)實驗主要驗證過濾比率r對EROF 算法迭代過濾效果的影響.一般情況下,算法2 逐步迭代過濾的過程會使實際過濾噪聲的比率超過r,因此令r在[0,0.3]區(qū)間內(nèi),間隔0.01,連續(xù)取值,圖7為在部分?jǐn)?shù)據(jù)集上,加入4 種不同比例的人工噪聲并用EROF 過濾后,準(zhǔn)確率隨過濾比率r的變化圖,其中灰色帶寬為最優(yōu)r值的集中區(qū)域.可以看出,當(dāng)r值集中在[0.04,0.16]時,展現(xiàn)的過濾能力較為優(yōu)秀;當(dāng)r值過低時,過濾樣本數(shù)量較少,導(dǎo)致大部分噪聲仍未去除,準(zhǔn)確率基本無變化;當(dāng)r值超過0.15 后,由于迭代集成緣故,在過濾噪聲的過程中,可能去除過多的真實樣本,導(dǎo)致不同噪聲比例情況下的準(zhǔn)確率都呈現(xiàn)下降趨勢.因此,在后續(xù)實驗中,本文使用r=0.1 作為EROF 算法的默認(rèn)參數(shù).

圖7 過濾比率 r 對過濾效果的影響Fig.7 Influence of filtering ratio r on filtering effect
3.4 UCI 實驗結(jié)果與分析
3.4.1 噪聲識別性能
圖8 給出了各算法在4 種噪聲比率下,各項指標(biāo)的比較結(jié)果,該實驗結(jié)果取自各算法在20 個數(shù)據(jù)集上的平均值.
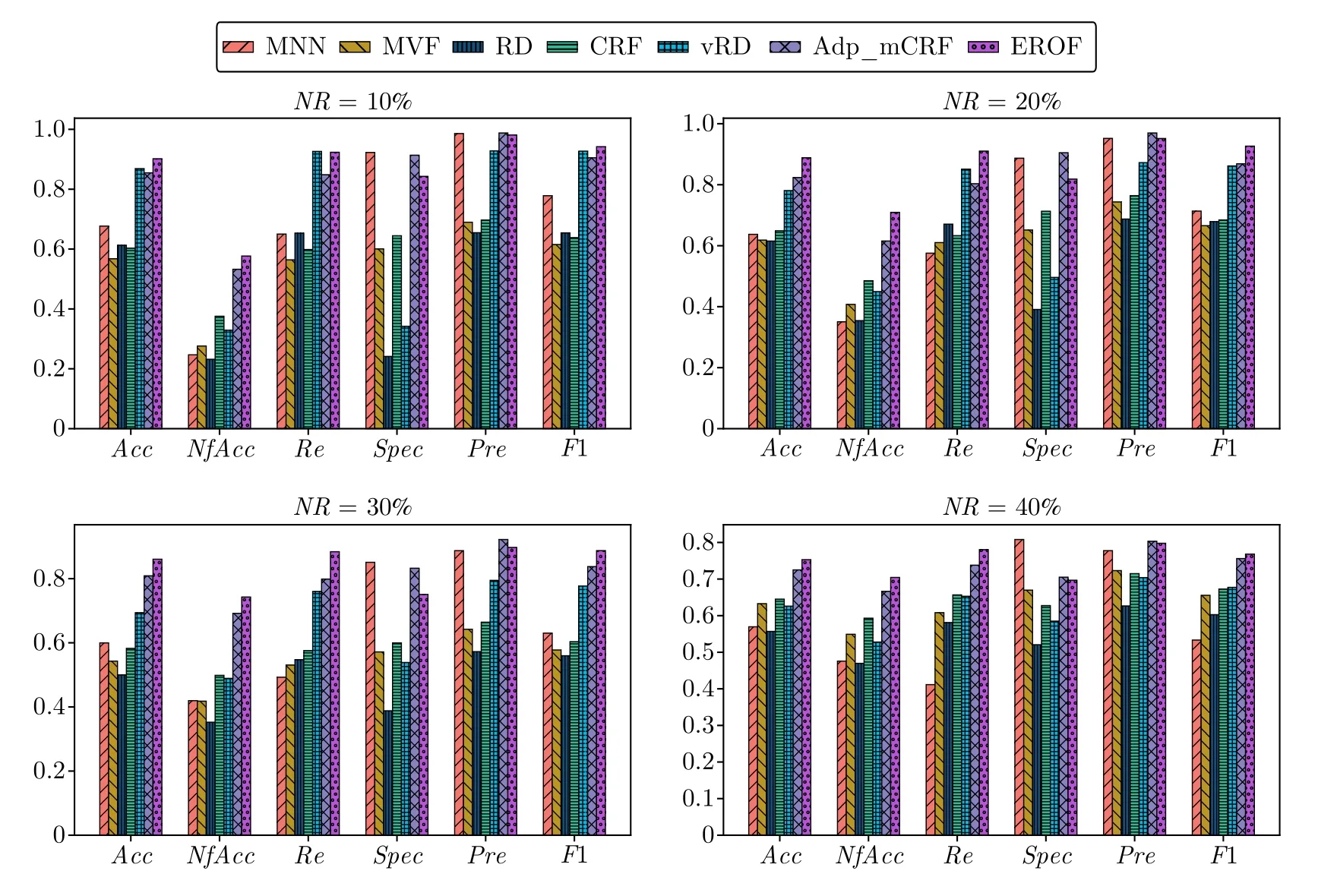
圖8 各算法噪聲識別性能指標(biāo)比較Fig.8 Comparison for noise recognition performance indicators of each algorithm
由準(zhǔn)確率和噪聲過濾準(zhǔn)確率可以看出,當(dāng)噪聲比例在10%~30%時,EROF 的噪聲識別能力較其他算法有顯著優(yōu)勢;當(dāng)噪聲比例增大至40%后,由于默認(rèn)設(shè)置的r值達(dá)不到40%噪聲比例的最優(yōu)r值,該優(yōu)勢雖有所減弱,但最終結(jié)果仍優(yōu)于其他算法.可以看出,基于分類預(yù)測的MVF 算法在高噪比例下,很難保持良好的過濾效果,這是分類模型本身的預(yù)測準(zhǔn)確性無法保證導(dǎo)致的.
從特異度的角度分析,MNN 和Adp_mCRF算法更傾向于盡可能地將噪聲去除干凈,因此Spec表現(xiàn)較為良好.受聚類效果和迭代停止指標(biāo)的不確定性影響,vRD 算法的Spec表現(xiàn)最差.EROF 是以提升分類模型泛化性能為最終目的,并不總將全部噪聲剔除,而是保留部分對模型影響較小的噪聲,該特性使其Spec表現(xiàn)相對偏低.
從查準(zhǔn)率和召回率看,EROF 的召回率要遠(yuǎn)高于其他算法,這是由于其盡可能地保留了真實樣本,也代表其誤刪真實樣本的情況很少發(fā)生.但EROF查準(zhǔn)率的優(yōu)勢不夠穩(wěn)定,MNN 和Adp_mCRF 算法在查準(zhǔn)率上更占優(yōu)勢.因此,由Pre和Re兩項指標(biāo)的調(diào)和平均F1 值來對比,更能體現(xiàn)算法的綜合性能.在10%~30% 的噪聲比例實驗中,EROF的F1 值穩(wěn)定保持在0.9 左右,而其余算法的F1 值均接近或低于0.8.只有在40%噪聲比例下,EROF的F1 值才跌破0.8,這也是由于其在高噪情況下的保守過濾引起的.總之,EROF 的F1 值在不同噪聲比例的實驗中,都保持著穩(wěn)定的優(yōu)勢.
圖9 對比了不同噪聲比例下,7 種算法在20 個數(shù)據(jù)集中,各項指標(biāo)最優(yōu)次數(shù)的占比比例.在20%和30%噪聲比例實驗中,在除查準(zhǔn)率和特異度外的其他評價指標(biāo)上,EROF 都保持著巨大優(yōu)勢.Adp_mCRF和MVF 算法的噪聲過濾準(zhǔn)確率相較于其他算法更高,但仍無法超越EROF 在不同噪聲比例下的最優(yōu)占比.
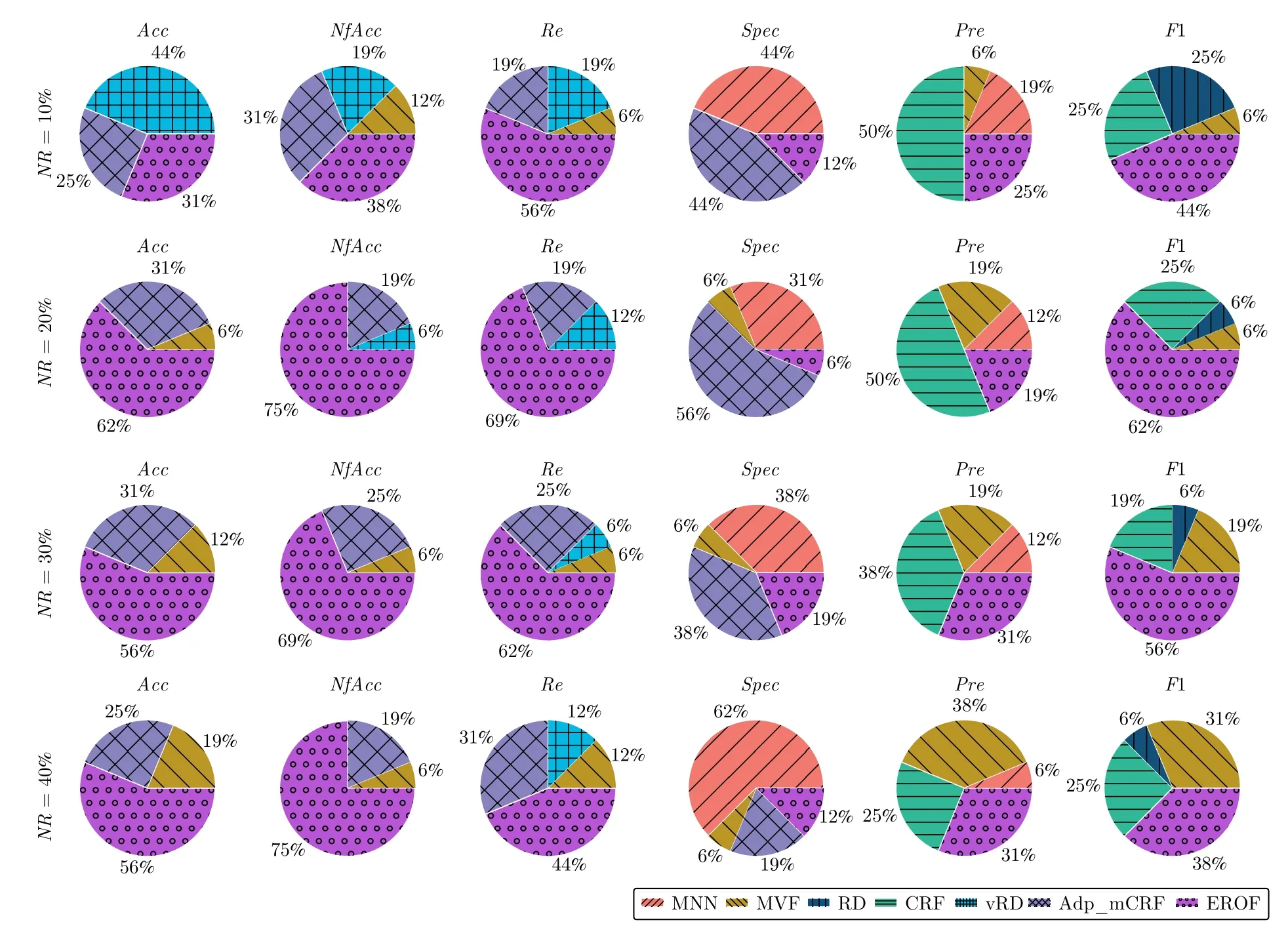
圖9 各算法噪聲識別性能指標(biāo)的最優(yōu)次數(shù)的占比比例Fig.9 Optimal frequency ratio for noise recognition performance indicators of each algorithm
3.4.2 分類模型泛化性能
表2 列出了不同噪聲比例下,用K近鄰分類模型(近鄰參數(shù)k設(shè)置為1)在各種算法過濾后的數(shù)據(jù)集上訓(xùn)練,然后在無噪測試集上預(yù)測的分類準(zhǔn)確率結(jié)果.當(dāng)噪聲比例為10%時,EROF 在第2、3、11 號數(shù)據(jù)集上的分類準(zhǔn)確率表現(xiàn)欠佳,在其余數(shù)據(jù)集上均為最優(yōu),由于噪聲比例偏低,各算法的分類準(zhǔn)確率差距并不明顯.當(dāng)噪聲比例為20%~30%時,EROF 在第1~10 號和第16~20 號數(shù)據(jù)集上的分類準(zhǔn)確率均為最優(yōu).當(dāng)噪聲比例達(dá)到40%后,EROF 的優(yōu)勢略顯不足.總之,在所有數(shù)據(jù)集上,EROF 算法相比于次優(yōu)算法的分類準(zhǔn)確率平均提升了6.76%,最大提升了18.71%;相比于不過濾的分類準(zhǔn)確率平均提升了12.36%,最大提升了55.88%,說明EROF 算法對K近鄰分類模型有著較好的增強效果.
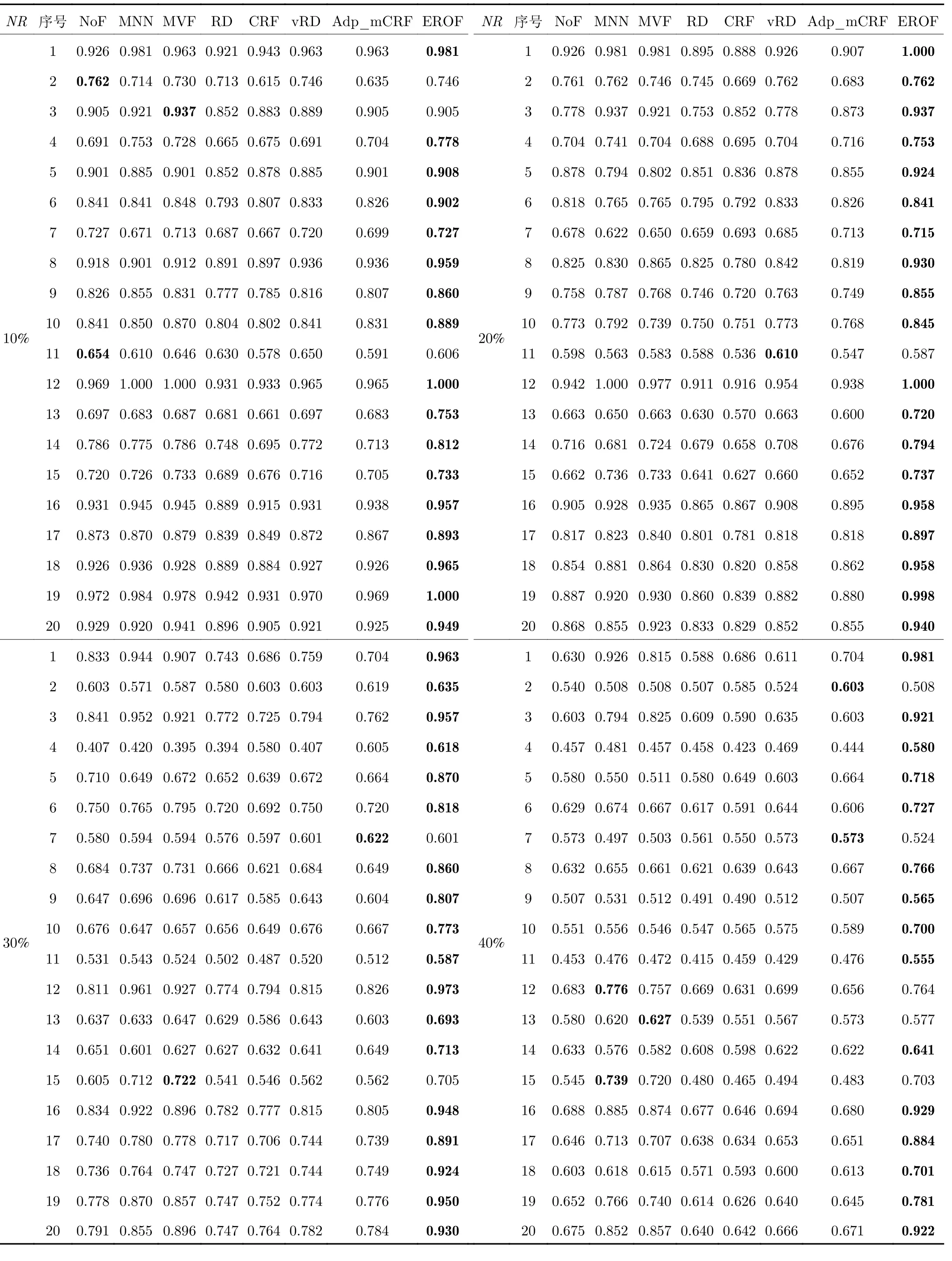
表2 UCI 上,不同噪聲比例下的分類準(zhǔn)確率Table 2 Classification accuracy with different noise ratios on UCI
圖10 給出了各分類模型分類準(zhǔn)確率的臨界差異圖.臨界差異圖能夠顯示算法排名差異的顯著性,算法排名越小表示算法的分類準(zhǔn)確率越高;算法排名之間的距離不超過臨界差異值的用橫線連接,代表算法間的差異不顯著.其中算法的平均排名是基于20 個數(shù)據(jù)集和4 種噪聲比例的分類準(zhǔn)確率計算得出的.由圖10 可知,EROF 算法在4 種分類模型上都取得最優(yōu)的分類準(zhǔn)確率排名.其中,在SVM和RF 模型上,EROF 與Adp_mCRF 算法無顯著性差異;在其他模型上,EROF 算法相較其他算法,都有顯著性優(yōu)勢.所有過濾算法均優(yōu)于不進(jìn)行任何過濾的效果,這印證了過濾算法能夠提升分類模型的泛化性能,而EROF 算法的提升效果最高.
3.4.3 算法效率
由于部分小規(guī)模數(shù)據(jù)集無法體現(xiàn)算法時間開銷差異,本文選取Isolet、Mushrooms 和Letter 三個代表性數(shù)據(jù)集進(jìn)行實驗,各算法在這三個數(shù)據(jù)集上的時間開銷對比如圖11 所示.Adp_mCRF 在構(gòu)建隨機樹時,需要隨機劃分特征進(jìn)行數(shù)據(jù)孤立,導(dǎo)致其在高維數(shù)據(jù)上效率最低.EROF 算法在多分類任務(wù)中,需要根據(jù)類別重復(fù)劃分同質(zhì)或異質(zhì)樣本,并計算相對離群因子,因此在有26 個類別的Isolet和Letter 數(shù)據(jù)集上,時間開銷較其他算法更高.與昂貴的模型學(xué)習(xí)算法和超參數(shù)優(yōu)化算法相比,優(yōu)秀的噪聲過濾能顯著提升模型精度.EROF 算法在保證過濾效果的同時,相對合理地控制了時間開銷,因此,其時間開銷是可以接受的.

圖11 時間開銷對比Fig.11 Running time comparison
4 MNIST 數(shù)據(jù)集實驗
為進(jìn)一步驗證本文算法對非隨機標(biāo)簽噪聲識別和過濾的有效性,本節(jié)在MNIST 標(biāo)準(zhǔn)數(shù)據(jù)集上進(jìn)行噪聲過濾實驗與相關(guān)分析.
4.1 實驗框架
MNIST 是一個被廣泛使用的手寫數(shù)字圖像數(shù)據(jù)集,由60 000 個用于訓(xùn)練和10 000 個用于測試的28×28像素的灰度圖像組成.這些圖像表示從0到9 的手寫數(shù)字,每個數(shù)字大約有6 000 個圖像樣本.在MNIST 數(shù)據(jù)集中,某些數(shù)字之間的相似性很高,它們在書寫模糊的情況下,很難區(qū)分,可能會出現(xiàn)標(biāo)簽噪聲的概率也更高.因此,本節(jié)實驗除了在訓(xùn)練集上加入比例為10%的完全隨機噪聲外,還采用成對翻轉(zhuǎn)的噪聲轉(zhuǎn)移矩陣加入非隨機標(biāo)簽噪聲[27],其中非常相似類的翻轉(zhuǎn)概率設(shè)置為30%.
實驗采用Adam 優(yōu)化器,以0.001 的學(xué)習(xí)率迭代訓(xùn)練神經(jīng)網(wǎng)絡(luò)200 次,其中神經(jīng)網(wǎng)絡(luò)具有2 個隱藏層,分別包含500 和300 個神經(jīng)元,可用于處理784 維輸入,并進(jìn)行10 個分類任務(wù)[37].通過10次隨機實驗,對不同算法的噪聲過濾效果進(jìn)行對比,記錄6 種噪聲識別性能評估指標(biāo)和測試集上的分類精度.
4.2 MNIST 實驗結(jié)果與分析
表3 列出了在MNIST 數(shù)據(jù)集上,7 種算法對非隨機噪聲的識別性能.其中,在Acc、NfAcc、Re和F1 值上,EROF 算法均表現(xiàn)出穩(wěn)定優(yōu)勢.盡管EROF 算法的S pec值偏低,但其優(yōu)秀的NfAcc值表明它能精確地過濾掉數(shù)據(jù)中的噪聲樣本.此外,0.851 的Re值說明,EROF 算法在過濾時優(yōu)先保留正確樣本,而不是進(jìn)行無差別的過濾.這種噪聲過濾模式有助于神經(jīng)網(wǎng)絡(luò)更好地學(xué)習(xí)數(shù)據(jù)的內(nèi)在規(guī)律,從而提高模型的泛化性能.

表3 MNIST 上的噪聲識別性能Table 3 Noise recognition performance on MNIST
圖12 展示了經(jīng)過不同算法過濾后,神經(jīng)網(wǎng)絡(luò)模型在測試集上的分類準(zhǔn)確率,其中陰影帶狀區(qū)域代表對應(yīng)算法在10 次隨機實驗中的波動范圍.可以看出,除MVF 算法外,其他過濾算法在測試集上的分類準(zhǔn)確率均顯著優(yōu)于不進(jìn)行任何過濾的效果.其中EROF、Adp_mCRF 和vRD 算法的準(zhǔn)確率波動較小,說明高質(zhì)量的訓(xùn)練數(shù)據(jù)加速了神經(jīng)網(wǎng)絡(luò)擬合新數(shù)據(jù)的過程.
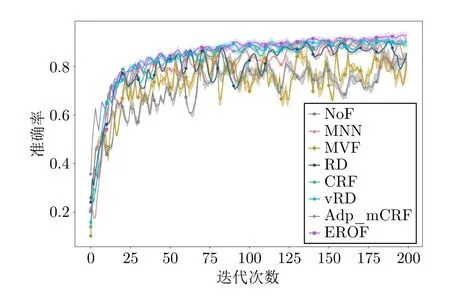
圖12 不同算法過濾后的準(zhǔn)確率Fig.12 Accuracy after filtering by different algorithms
圖13 給出不同過濾算法在最后10 次迭代的平均測試精度.在迭代末期,EROF 算法的平均測試精度達(dá)到了0.925,為所有算法中的最高值且隨機實驗對其導(dǎo)致的偏差幅度在所有算法中最小,表明EROF 算法具有優(yōu)秀的精確性和穩(wěn)定性.
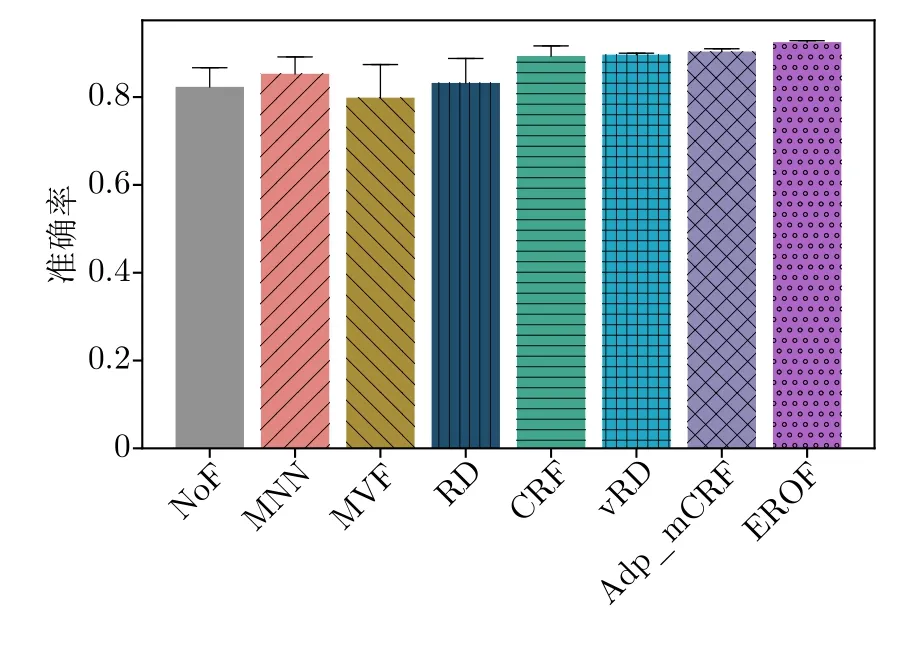
圖13 MNIST 上,最后10 次迭代的平均測試精度Fig.13 Average accuracy over the last 10 epochs on MNIST
5 結(jié)束語
本文提出基于相對離群因子的集成過濾方法,利用基離群點檢測算法,為樣本提供標(biāo)簽噪聲的概率評估,再依據(jù)此評估實現(xiàn)迭代集成過濾.與現(xiàn)有算法相比,該算法以提升分類準(zhǔn)確率為最終目的,在保證數(shù)據(jù)信息盡量不丟失的同時,能更精確地過濾掉對分類模型影響較大的噪聲樣本;并且該算法通過集成多種互補的離群點檢測算法,保證了其優(yōu)秀的魯棒性.在不同噪聲比例和類型下,該算法均表現(xiàn)出良好的過濾效果和對分類模型的提升能力.為解決分類任務(wù)中的類別型標(biāo)簽噪聲過濾問題,提供一種新的思路.
由于過濾比率r和基離群點檢測模型對本文算法的過濾效果有一定影響,因此如何自適應(yīng)設(shè)置過濾比率r和選擇用于集成的基離群點檢測模型,還有待進(jìn)一步研究.此外,離群點檢測算法針對數(shù)值型標(biāo)簽噪聲問題同樣有效,基于離群點檢測算法的相關(guān)噪聲學(xué)習(xí)方法在數(shù)值型標(biāo)簽噪聲過濾和回歸模型優(yōu)化問題上的應(yīng)用,值得持續(xù)關(guān)注與探索.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46