
基于改進YOLOv5s的森林煙火檢測算法研究
2024-02-05 12:36:50李虹紀任鑫陳軍鵬耿榮妹蔡驍張艷迪
科技創新與應用 2024年5期
李虹 紀任鑫 陳軍鵬 耿榮妹 蔡驍 張艷迪


摘? 要:該文提出一種基于改進YOLOv5s的森林煙火檢測算法,通過引入GSConv輕量化卷積和消除網格敏感度的策略,在原始YOLOv5s模型的基礎上優化。在煙火數據集上進行廣泛的實驗,同時將改進的算法部署到無人機上進行真機測試。實驗結果表明,經過改進的模型在森林煙火檢測任務中取得顯著的性能提升。模型的平均精度達到90.65%,且檢測耗時僅為4.1 ms,滿足煙火檢測的高精度和實時性要求。這一研究為森林煙火檢測算法的實際應用提供有力支持,具有重要的實際意義和應用價值。
關鍵詞:森林煙火檢測;YOLOv5s;GSConv輕量化卷積;消除網格敏感度;實時性
中圖分類號:S762.32? ? ? 文獻標志碼:A? ? ? ? ? 文章編號:2095-2945(2024)05-0007-05
Abstract: This paper proposes an improved forest fire detection algorithm based on YOLOv5s. The algorithm enhances the original YOLOv5s model by introducing the GSConv lightweight convolution and a strategy to eliminate grid sensitivity. Extensive experiments are conducted on a forest fire dataset, and the proposed algorithm is successfully deployed on a drone for real-world testing. The experimental results demonstrate significant performance improvements achieved by the enhanced model in forest fire detection. The average accuracy of the model is 90.65%, and the detection time is only 4.1 ms, which meets the high precision and real-time requirements of pyrotechnic detection. This study provides a strong support for the practical application of forest fire detection algorithm, and has important practical significance and application value.
Keywords: forest fire detection; YOLOv5s; GSConv lightweight convolution; elimination of grid sensitivity; real-time
隨著溫室效應的增強,全球氣候進一步變暖,世界范圍內年平均降雨量減少,森林中的枯枝敗葉增多,進而導致森林火災頻發。森林火災具有燃燒時間長、難以控制的特點,這會嚴重破壞林木資源、毀滅動植物、嚴重危及人民群眾的生命財產安全,給人們帶來難以估計的損失[1]。據統計,我國自1950年開始,全國年均森林火災案例超過13 000起,由森林火災造成的傷亡人數達到580 人之多,超過653 000 hm2的林地面積被破壞[2]。
傳統的火災預防方法有紅外探測器檢測、衛星遙感等方式,這些方法對于森林火災的檢測都有明顯的不足。基于紅外探測器的檢測距離過短,易受環境干擾,并不適合用來檢測森林火災。衛星遙感雖能在檢測范圍上達到最大化,但檢測性能主要偏向于大面積森林火災,火災早期因面積較小不易被衛星遙感探測,不能及早提醒消防人員撲火,因此容易延誤火災撲滅的最佳時機。
隨著深度學習和圖像處理技術的快速發展,為森林火災識別提供了新的手段,可以及時發現并撲滅森林火災。無人機搭載深度學習平臺,巡檢過程中快速準確識別出煙火等目標,為人們提供最佳的撲滅森林火災的時機。
1? YOLOv5算法介紹
YOLO[3-4]系列算法,因其高準確率和實時性而在學術界和工業界廣受歡迎。最新發布的YOLOv5提供了4種網絡模型:YOLOv5x、YOLOv5l、YOLOv5m和YOLOv5s。雖然這些模型在結構上相同,但區別在于網絡深度和權重。其中,YOLOv5s是最輕量級的模型,擁有最小的網絡寬度和深度,以及最快的檢測推理速度。
考慮到實際應用的需求,本文選擇了YOLOv5s作為改進模型。如圖1所示,該模型的網絡結構分為3部分:骨干網絡、頸部網絡和檢測頭。骨干網絡采用了CSPDarknet架構,這是一種高效的特征提取模塊。它通過疊加多個BottleneckCSP模塊和SPP(Spatial Pyramid Pooling Fast,空間金字塔池化)模塊,有效地捕獲不同尺度和層次的特征信息,從而提升模型的感知范圍和檢測能力。頸部網絡位于骨干網絡和檢測頭之間,其作用是進一步整合和加工骨干網絡提取的特征。在YOLOv5s中,頸部網絡采用FPN+PAN結構,通過卷積和上采樣操作,實現了不同分辨率特征的融合,從而使模型在多尺度上都能夠有效地捕捉目標信息。檢測頭是模型的最后一部分,它使用頸部網絡融合得到的特征進行目標檢測預測。在YOLOv5s中,檢測頭負責生成候選目標框,對目標進行分類和位置回歸,從而實現了目標檢測任務。
2? 模型的改進
2.1? GSConv輕量化卷積
深度學習模型的非線性表達能力與卷積網絡的復雜度之間存在一定的正相關性。然而,復雜模型通常需要大量的計算資源。因此,在有限的成本內構建強大模型不應簡單地依賴于無限增加模型參數的數量。Howard等[5]提出了輕量化網絡,該網絡在計算資源有限的環境中表現出色,能夠以更少的計算資源實現高效推理,從而滿足實時性能需求。受到Howard等的啟發后,許多輕量化模型采用深度可分離卷積來代替普通卷積。然而,深度可分離卷積在特征提取過程中將輸入圖像的通道信息分離,從而破壞了通道之間的信息融合,導致模型的檢測精度降低。Zhang等[6]提出的ShuffleNet 引入了“channel shuffle” 操作,通過在通道維度上進行信息混洗,以增強通道之間的交互性,從而提高特征表示能力。盡管該方法改進了深度可分離卷積以實現通道信息交互,但其檢測精度仍無法達到普通卷積的水平。
為了在提高檢測速度的同時不降低檢測精度,本文引入了一種新的方法[7],即結合了普通卷積、深度可分離卷積和“channel shuffle” 操作的混合卷積,稱為GSConv。如圖2所示,首先通過普通卷積生成高維特征,然后使用深度可分離卷積將高維特征進行轉換,把普通卷積生成的特征完全混合到深度分離卷積中。接著將這2個特征進行拼接,并通過“channel shuffle” 操作,將不同組的特征圖混洗在一起,以增強不同組之間的信息交互。這種設計有效地減少了計算量和參數數量。
在對YOLOv5s模型的改進中,保留了骨干特征提取網絡中的普通卷積,把頸部(Neck)普通卷積層使用GSConv替換,如圖3所示。實驗結果表明,GSConv和普通卷積在精度上基本保持一致。普通卷積在計算過程中最大程度地保留了通道之間隱藏的信息,從而保留了語義信息,然而深度可分離卷積會破壞這種聯系。本文采用的GSConv通過混合普通卷積和深度可分離卷積的特征,恢復了通道之間的信息交互。需要注意的是,GSConv并沒有替YOLOv5s模型中的所有普通卷積層。這一決策是出于對骨干網絡的考慮,骨干網絡負責對輸入圖像的尺寸進行壓縮和通道擴展,輸出的高通道的低分辨率特征包含了豐富的語義信息和多級感受野。如果在模型的所有階段都使用GSConv,模型的網絡層將變得更加深,網絡訓練可能會出現不收斂的和梯度爆炸。實驗表明,這一改進的網絡模型在保持YOLOv5s的檢測精度的同時,通過輕量化設計,加快了推理速度。
2.2? 消除網格敏感度
在目標檢測中,預測的目標邊界框會在不同的網格中滑動,輸出相應的錨框值。如圖4所示,在卷積過程中,當滑動到中心網格位置時,將相對于網格左上角的偏移量tx和ty的值傳遞給Sigmoid函數。這一步將偏移量的值限制在0到1之間,然后加上網格的尺寸,從而得到了預測邊界框的中心坐標。當預測的中心點非常接近邊界值時,例如在中心網格的左上角和右下角,Sigmoid函數的值需要趨近于0或無窮大,而網絡很難穩定地達到這種極端值。
為了解決這個問題,在YOLOv5中引入了一個新的scale參數,用于調整Sigmoid函數的輸出。如式(1)所示,bx,y是預測框的中心坐標,scale是一個尺度參數,tx,y是偏移量坐標,δ是Sigmoid函數,cx,y是距離左上角網格的坐標。通過增加tx,y區域的斜率擴大了可取值范圍。隨著尺度參數的增加,發現了一個新問題:在tx,y附近的區域,斜率也隨之增加,如圖5(a)所示。式(2)中b′x,y是bx,y的導數,當tx,y為0時,斜率達到最大值,最大斜率與比例值有關。因此,為了消除柵格敏感性,增加比例值會導致在tx,y附近出現非常大的斜率。而接近0的輸入值tx,y會導致網絡的不穩定性。
為了克服這些問題,受Huang等[8]的啟發對先前的方法進行了改進,將tx,y乘以一個參數α/scale,如式(3)所示,其中α代表一個固定的斜率值。當將消除網格敏感性的方法(在YOLOv4中使用)作為基準時,將參數α設置為2。而在不消除網格敏感性的情況下(類似于YOLOv3的方法),參數α被設定為1。通過對式(3)進行導數分析(如式(4)所示),可以觀察到當tx,y為0時,斜率與α相關。在這種方法中,使用固定值α,而不是可變的尺度值。因此,通過這種方式消除網格敏感性時,曲線的斜率保持不變,如圖5(b)所示。實驗中將參數α設定為2。
3實驗結果與分析
3.1數據集
本文所使用的數據集來源于實際的應用場景,利用標注工具對1 400張圖片進行標注,包含4類:火、煙、水源以及建筑物。為了增強網絡模型的泛化能力和魯棒性,對1 400張圖做數據增強處理,包括隨機裁剪、顏色變換、仿射變換。并將數據集按照訓練集、測試集、驗證集以 8∶1∶1 的比例進行劃分。
3.2評價指標
為了全面評估模型的性能,采用多種不同的評價指標進行衡量和量化。式(5)代表精確率,精確率越高代表檢測正確的目標數量占所有檢測目標數量的比例越高。式(6)代表召回率,召回率較高時,模型能夠找到大部分真實目標,但可能會有一些誤檢測。式(7)、(8)分別代表平均精確率和平均精確率的平均值,用于評估模型在不同閾值下的性能。
上述4式中,TP表示預測為正樣本的正樣本數量,FP表示預測為負樣本的正樣本數量,FN表示預測為正樣本的負樣本數量,m表示標簽的類別數。
參數量是指模型中所有可學習參數的總數量。計算量是指模型在推理或訓練過程中需要執行的總計算操作的數量,計算量可以用來衡量模型的復雜度和計算資源的要求,影響著模型的速度和效率。通常情況下,較高的計算量會導致更長的推理或訓練時間。速度是指處理單幀圖像的時間。
3.3? 輕量化和消融實驗結果
3.3.1? 輕量化實驗結果
為了在輕量化模型的同時保持檢測精度并提升推理速度,把原始YOLOv5s頸部普通卷積替換為GSConv層,并在計算目標預測框時,并在目標預測過程中引入了參數以消除網格敏感度。實驗結果見表1,改進的模型在精度方面提升了3.09個百分點,召回率也提高了2.13個百分點,這表明在目標識別方面,模型不僅減少了誤判,還增強了目標的檢測能力。另外,AP-50 值相對于原始 YOLOv5s 提高了3.25個百分點,參數量減少了0.8 MB,計算量減少了5.7 G,推理速度提高了2.1 ms,實驗結果證明了所采用的改進模型和策略在煙火檢測方面的有效性。
3.3.2? 消融實驗
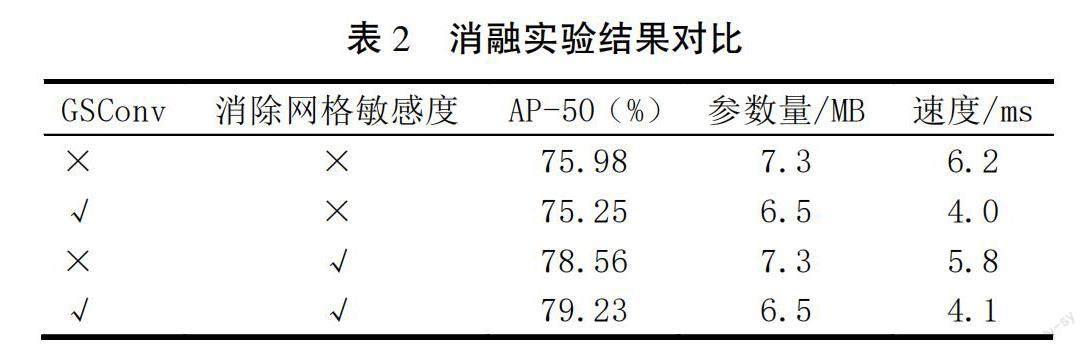
為了驗證各改進模塊的有效性,本文共進行了4組消融實驗,選取訓練最優的訓練權重在驗證集上進行實驗,實驗結果見表2。 其中“√”表示加入該模塊,“×”表示沒有加入該模塊,由表2可知,使用GSConv后,參數量下降,推理速度也提高了2.2 ms,說明該模塊比原來模型更加輕量化;引入消除網格策略后,雖然檢測速度的提升幅度不大,但模型的精確率卻增加了2.58個百分點,有效提升了模型的精確性。
3.3.3? 檢測效果與分析
模型可視化如圖6所示,通過對比可見,原始的YOLOv5在某些情況下存在煙霧目標的漏檢現象,而經過改進的模型則能夠準確地檢測出圖像中所有的煙霧目標,徹底解決了漏檢的問題。此外,不僅在漏檢方面有所改善,改進的模型在目標定位和分類方面也表現出更高的準確性,從而在整體得分上取得了顯著提升,進一步驗證了模型的優越性能。改進的輕量化模型并沒有犧牲準確性來換取推理速度的提升。在實際應用中,經過TensorRT部署后,該改進模型在Windows平臺上的推理速度達到了1 ms,這意味著模型能夠在實時應用場景中快速地進行目標檢測和識別,為實際應用提供了高效的解決方案。
4? 結論
本文在深入研究目標檢測領域的基礎上,提出了一種針對森林煙火檢測的改進算法。通過對YOLOv5s模型進行GSConv輕量化卷積的改進以及消除網格敏感度的優化,成功地提升了模型的檢測性能和推理速度。實驗結果表明,所提出的算法在煙火檢測任務中表現出優越的性能,取得了顯著的平均精度和實時性。將算法應用于無人機實際場景中的真機測試進一步驗證了其有效性和可行性。該研究不僅在理論上提出了創新性的解決方案,還在實際應用中取得了實質性的成果。未來,將繼續深入研究目標檢測領域,進一步拓展算法的適用范圍,為森林火災的預防和控制提供更加可靠和高效的技術支持。
參考文獻:
[1] 王楚.基于改進YOLOv5的森林火災識別方法研究與應用[D].重慶:重慶大學,2022.
[2] 葉錦斌.基于深度學習的森林煙火檢測系統軟件設計與開發[D].廣州:華南理工大學,2022.
[3] 馬慶祿,魯佳萍,唐小垚,等.改進YOLOv5s的公路隧道煙火檢測方法[J].浙江大學學報(工學版),2023,57(4):784-794,813.
[4] 劉洪,王元華,何健,等.YOLOv5算法在山火檢測中的應用[J].興義民族師范學院學報,2022(4):113-118.
[5] HOWARD A, SANDLER M, CHU G, et al. Searching for mobilenetv3[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 1314-1324.
[6] ZHANG X, ZHOU X, LIN M, et al. Shufflenet: An extremely efficient convolutional neural network for mobile devices[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 6848-6856.
[7] LI H, LI J, WEI H, et al. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles[J]. arXiv preprint arXiv:2206.02424,2022.
[8] HUANG L, LI W, SHEN L, et al. High-Performance Fine Defect Detection in Artificial Leather Using Dual Feature Pool Object Detection[J]. arXiv preprint arXiv:2307.16751,2023.
