基于流計(jì)算和大數(shù)據(jù)平臺(tái)的實(shí)時(shí)交通流預(yù)測(cè)
2024-02-22 07:45:08李星輝魏鵬飛
計(jì)算機(jī)工程與設(shè)計(jì) 2024年2期
關(guān)鍵詞:模型
李星輝,曾 碧,魏鵬飛
(廣東工業(yè)大學(xué) 計(jì)算機(jī)學(xué)院,廣東 廣州 510006)
0 引 言
如今,城市每天所產(chǎn)生的交通數(shù)據(jù)量龐大,以深圳某一年的GPS數(shù)據(jù)為例,深圳市每一輛車的實(shí)時(shí)定位數(shù)據(jù)每5 min產(chǎn)生一次,一個(gè)月的深圳市滴滴網(wǎng)約車GPS數(shù)據(jù)就已達(dá)到140 GB,而大數(shù)據(jù)及其可視化技術(shù)的發(fā)展為交通數(shù)據(jù)數(shù)據(jù)挖掘方面提供了便利,不僅為數(shù)據(jù)提供了足夠的存儲(chǔ)空間,而且在實(shí)時(shí)數(shù)據(jù)抓取和預(yù)處理方面貢獻(xiàn)巨大。
近期在交通流預(yù)測(cè)方面,Hsueh等[1]提出用LSTM作為預(yù)測(cè)交通流速度的模型。交通流預(yù)測(cè)模型往往參數(shù)量多,通常是在GPU上以離線的方式訓(xùn)練相當(dāng)長(zhǎng)的時(shí)間,然后部署到實(shí)際的云服務(wù)器中用于實(shí)時(shí)預(yù)測(cè)。但在實(shí)際交通場(chǎng)景中,交通數(shù)據(jù)不斷更新,交通流預(yù)測(cè)模型也需要能隨著數(shù)據(jù)集的更新不斷調(diào)整。因此這里提出一種基于流計(jì)算和大數(shù)據(jù)平臺(tái)的實(shí)時(shí)交通流預(yù)測(cè)方法,在保持一定精度前提下,訓(xùn)練速度比在GPU上跑的更快,可對(duì)實(shí)時(shí)交通流數(shù)據(jù)進(jìn)行捕獲、建模分析和預(yù)測(cè),從而滿足實(shí)時(shí)應(yīng)用的需求。
綜上所述,主要貢獻(xiàn)如下:
(1)提出一種Flink流計(jì)算框架和交通數(shù)據(jù)預(yù)處理方法。
用Kafka消息系統(tǒng)采集交通路段傳感器的數(shù)據(jù),經(jīng)過Flink流式的預(yù)處理后,把數(shù)據(jù)送入到獨(dú)立分布式的大數(shù)據(jù)集群中,實(shí)現(xiàn)了對(duì)交通流數(shù)據(jù)的實(shí)時(shí)抓取—預(yù)處理—分流。
(2)提出一種基于Hadoop大數(shù)據(jù)平臺(tái)的深度學(xué)習(xí)模型并行訓(xùn)練模式,充分利用大數(shù)據(jù)資源與技術(shù)實(shí)現(xiàn)最大程度的數(shù)據(jù)并行。
(3)采用了某個(gè)交通路段的多個(gè)道路傳感器產(chǎn)生的數(shù)據(jù)對(duì)模型進(jìn)行訓(xùn)練和預(yù)測(cè)實(shí)驗(yàn)。利用滑動(dòng)窗口自動(dòng)地選取最近鄰的歷史數(shù)據(jù)集對(duì)模型進(jìn)行訓(xùn)練并用于預(yù)測(cè),追求流式自動(dòng)化和實(shí)時(shí)處理。在保持一定的精度的情況下,探索了比GPU訓(xùn)練方式更快的模式,滿足了實(shí)時(shí)預(yù)測(cè)的要求。
1 相關(guān)工作
1.1 交通流預(yù)測(cè)相關(guān)研究
在交通流預(yù)測(cè)領(lǐng)域里,基本上都是采取先訓(xùn)練模型,然后用實(shí)時(shí)數(shù)據(jù)集去預(yù)測(cè)未來的某個(gè)道路的車速度和流量。Fitters等[2]利用LSTM模型,先基于車流的密度去劃定一些圓形的區(qū)域,提取坐標(biāo)點(diǎn)之間的時(shí)空聯(lián)系作為特征輸入到模型,以預(yù)測(cè)未來某個(gè)路口的交通流量。Chen等[3]以Bi-GRU模型作為主干網(wǎng)絡(luò)預(yù)測(cè)未來道路的車流速度,通過增加GRU模型的層數(shù)讓模型學(xué)習(xí)到的特征更多,從而提高訓(xùn)練精度。Zhang等[4]通過KNN模型與額外的時(shí)間-空間-距離權(quán)重公式結(jié)合去直接預(yù)測(cè)交通流量,整個(gè)過程都將模型運(yùn)行在Spark中得以加速。以上所提到的方法都是采用離線訓(xùn)練和處理的方式,模型參數(shù)量大,需要較長(zhǎng)的訓(xùn)練時(shí)間,很難滿足實(shí)時(shí)性的要求。所以如何讓模型在保持一定精度的情況下,盡可能縮短訓(xùn)練時(shí)間來實(shí)現(xiàn)預(yù)測(cè)實(shí)時(shí)性是亟待解決的問題。
1.2 流計(jì)算的相關(guān)研究
流計(jì)算通常是采用基于大數(shù)據(jù)框架的實(shí)時(shí)采集、分析和導(dǎo)出數(shù)據(jù)的工具來實(shí)現(xiàn)的,目前應(yīng)用最多的是SparkStrea-ming和Flink。流計(jì)算被廣泛應(yīng)用到很多領(lǐng)域,這些領(lǐng)域都對(duì)實(shí)時(shí)性要求高和比較依賴于歷史的時(shí)間性或空間性,Kanavos等[5]在冬季天氣預(yù)測(cè)里,SparkStreaming主要負(fù)責(zé)實(shí)時(shí)采集天氣傳感器的各類特征數(shù)據(jù)。在網(wǎng)絡(luò)沖突檢測(cè)領(lǐng)域,Garcia等[6]以SparkStreaming 作為主要框架進(jìn)行網(wǎng)絡(luò)交通流信息的處理。Tun等[7]提出了采用Kafka集群對(duì)輸入流進(jìn)行采集,經(jīng)過SparkStreaming批轉(zhuǎn)換然后進(jìn)行實(shí)時(shí)分析。對(duì)比SparkStreaming微批處理機(jī)制,F(xiàn)link在時(shí)間處理機(jī)制方面有著更為靈活的方式,不但能夠基于當(dāng)前的處理時(shí)間,也能夠基于實(shí)際的事件時(shí)間。Abbas等[8]對(duì)交通擁塞進(jìn)行減緩,在對(duì)交通擁塞的檢測(cè)之前,利用交叉路口的攝像頭捕捉數(shù)據(jù),并對(duì)連同道路設(shè)施信息一起計(jì)算出平均速度、車輛的密度等指標(biāo)。這種方式可以及時(shí)地捕捉到路況的時(shí)空變化。Flink對(duì)數(shù)據(jù)集處理延時(shí)低,但Abbas等[8]并未涉及交通流預(yù)測(cè),本文將Flink實(shí)時(shí)流計(jì)算框架和深度學(xué)習(xí)模型結(jié)合,實(shí)現(xiàn)實(shí)時(shí)采集、處理和訓(xùn)練的一體化。
1.3 并行計(jì)算的研究
Mahmud等[9]和Dafir等[10]對(duì)并行計(jì)算進(jìn)行了分類。首先“垂直并行”是運(yùn)行在同一個(gè)服務(wù)器上并且添加一定的處理器、內(nèi)存和快速硬件,如FPGA;而“橫向并行”則是集成多個(gè)分布式服務(wù)器的系統(tǒng),把工作量分配給多個(gè)服務(wù)器去并行。
“垂直并行”中,GPU最大的特點(diǎn)是它擁有超多計(jì)算核心。圖1為GPU和CPU的組成原理對(duì)比,GPU每個(gè)處理器都相當(dāng)于一個(gè)“核",在實(shí)際的GPU運(yùn)算場(chǎng)景中,這些處理器之間相互獨(dú)立,其計(jì)算能力比起CPU核較弱。GPU相對(duì)于CPU是非常昂貴的資源,以時(shí)空?qǐng)D卷積網(wǎng)絡(luò)[11]和分層結(jié)構(gòu)的圖神經(jīng)網(wǎng)絡(luò)[12]作為主干網(wǎng)絡(luò)的交通流預(yù)測(cè)模型,GPU在離線的情況下訓(xùn)練這些深度學(xué)習(xí)網(wǎng)絡(luò)加速效果很明顯,但是GPU顯存不夠用會(huì)導(dǎo)致訓(xùn)練時(shí)batch大小被限制,GPU的并行效果突破不了瓶頸,在這種情況下,可能需要再引入顯存更大的GPU以滿足需求,但這樣成本太高。
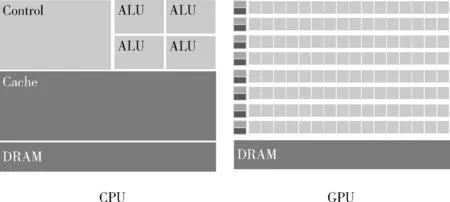
圖1 GPU與CPU內(nèi)部組成對(duì)比
Hadoop大數(shù)據(jù)集群的Yarn資源管理多“核”和內(nèi)存,CPU核計(jì)算單元對(duì)比GPU單個(gè)計(jì)算單元的處理能力要出色,所以從理論上來說利用大數(shù)據(jù)平臺(tái)的多核資源提高并行度,把工作量分配給多個(gè)節(jié)點(diǎn),通過增大每次“喂入”深度學(xué)習(xí)網(wǎng)絡(luò)的batch-size來提升訓(xùn)練速度,有著潛在的優(yōu)勢(shì)。
1.4 分布式計(jì)算框架相關(guān)研究
1.4.1 Spark和Ray
Spark繼Mapreduce后,在工作負(fù)載方面表現(xiàn)較優(yōu)越。近幾年頻繁項(xiàng)集挖掘相關(guān)算法(FIM)被部署在了Hadoop Mapreduce上,但是由于磁盤IO的問題,Mapreduce在FIM這種高迭代的算法上效率不高,Singh等[13]把FIM的其中一種算法Eclat的思想設(shè)計(jì)成Spark的RDD框架下的邏輯,使之并行化,并且通過不斷地增加可用核數(shù)和數(shù)據(jù)集的大小優(yōu)化效率,展現(xiàn)出了可擴(kuò)展性。Zarindast等[14]在Spark RDD的框架下設(shè)計(jì)識(shí)別高速公路擁堵的模型和邏輯,其模型能夠展現(xiàn)范圍更大的時(shí)空擁堵特征,其計(jì)算能力之高與覆蓋范圍之廣得益于高效Spark分布式數(shù)據(jù)處理系統(tǒng)。
Ray[17]分布式計(jì)算框架吸收了Spark在數(shù)據(jù)邏輯上的好處并且具備了像Yarn一樣的資源管理功能。在Ray的遠(yuǎn)程調(diào)用函數(shù)中可以自由定義多個(gè)遠(yuǎn)程節(jié)點(diǎn)并按需分配計(jì)算資源。Ray的分布式應(yīng)用能直接無縫地集成到Spark數(shù)據(jù)處理的流水線中,在Spark平臺(tái)中Ray給予其更為靈活的資源分配與調(diào)度方式。
1.4.2 分布式集群下的深度學(xué)習(xí)
深度學(xué)習(xí)與大數(shù)據(jù)平臺(tái)的結(jié)合在電商領(lǐng)域,Mishra等[15]基于Analytics Zoo,把商品推薦算法關(guān)聯(lián)規(guī)則分析和協(xié)同過濾算法部署在分布式計(jì)算平臺(tái)上取得了一定的成效,展現(xiàn)了Spark集群的可擴(kuò)展性,比起單機(jī)模式在訓(xùn)練精度和速度上大大提升。Haggag[16]基于SparkDL,通過不同的節(jié)點(diǎn)數(shù)和并行度,對(duì)比在不同的配置下網(wǎng)絡(luò)沖突檢測(cè)算法的訓(xùn)練速度。
以上方法基于分布式集群加快模型訓(xùn)練速度的,但是對(duì)于節(jié)點(diǎn)的每個(gè)任務(wù)的資源分配無法細(xì)化,而Ray可以進(jìn)一步操控資源的分配,使資源利用率和擴(kuò)展性更高和更強(qiáng)。
2 系統(tǒng)架構(gòu)與問題建模
2.1 系統(tǒng)架構(gòu)
整個(gè)系統(tǒng)架構(gòu)如圖2所示,主要包括兩大部分:一個(gè)是基于Flink流計(jì)算的環(huán)境部署;另一個(gè)是分布式深度學(xué)習(xí)的環(huán)境部署。

圖2 實(shí)時(shí)交通預(yù)測(cè)系統(tǒng)架構(gòu)
2.1.1 數(shù)據(jù)抓取、預(yù)處理和采集
首先實(shí)時(shí)的交通數(shù)據(jù)都分別存于Mysql,總共有307個(gè)傳感器的數(shù)據(jù),F(xiàn)link對(duì)這些數(shù)據(jù)進(jìn)行校驗(yàn),對(duì)異常數(shù)據(jù),如塞車或者速度檢測(cè)異常的數(shù)據(jù)實(shí)時(shí)過濾。這些數(shù)據(jù)源源不斷地流入到Kafka并在某個(gè)Topic中進(jìn)行存放,然后Flink再把這些數(shù)據(jù)從Kafka“沉積”到HDFS文件系統(tǒng)。
2.1.2 滑動(dòng)窗口選取數(shù)據(jù)集
數(shù)據(jù)進(jìn)入HDFS文件系統(tǒng)后,本文采用滑動(dòng)窗口形式選取數(shù)據(jù),每過一段時(shí)間從HDFS中選取最近的歷史序列數(shù)據(jù)作為大數(shù)據(jù)并行框架下預(yù)測(cè)模型的輸入來訓(xùn)練模型。
每當(dāng)有新的數(shù)據(jù)進(jìn)入,即新增一小時(shí)的數(shù)據(jù)進(jìn)入HDFS,負(fù)責(zé)采集最新數(shù)據(jù)集的窗口就會(huì)以若干小時(shí)為單位去移動(dòng)(具體多少個(gè)小時(shí)由實(shí)際的交通場(chǎng)景去確定)并進(jìn)行實(shí)時(shí)預(yù)測(cè),如圖2所示。
2.1.3 大數(shù)據(jù)平臺(tái)下的數(shù)據(jù)并行環(huán)境
大數(shù)據(jù)并行的環(huán)境主要包括SparkonYarn和RayonSpark兩個(gè)方面。
第一,SparkonYarn作為Spark的其中一種運(yùn)行模式,將Spark應(yīng)用部署在Yarn上,SparkonYarn流程如圖3所示。

圖3 SparkonYarn整體流程
第二,RayonSpark把Ray部署在了Spark大數(shù)據(jù)集群之上,首先,使用conda-pack打包Python環(huán)境,在運(yùn)行時(shí)分發(fā)到各個(gè)節(jié)點(diǎn)上。其次,Spark會(huì)在Driver節(jié)點(diǎn)上啟動(dòng)一個(gè)Spark上下文的實(shí)例,SparkContext會(huì)在整個(gè)集群?jiǎn)?dòng)多個(gè)Spark executor執(zhí)行Spark的任務(wù)。除了Spark上下文之外,RayonSpark設(shè)計(jì)中還會(huì)在Spark Driver中創(chuàng)建一個(gè)Ray上下文的實(shí)例,利用現(xiàn)有的Spark上下文將Ray在集群里啟動(dòng)起來,Ray的進(jìn)程會(huì)伴隨著在Spark executor,包括一個(gè)Ray 主節(jié)點(diǎn)進(jìn)程和其它的Ray從節(jié)點(diǎn)進(jìn)程,圖4為RayonSpark整體架構(gòu)建立流程。

圖4 RayonSpark整體架構(gòu)建立流程
結(jié)合相關(guān)工作所述,把大數(shù)據(jù)平臺(tái)的Yarn和Spark、Ray兩個(gè)分布式框架進(jìn)行整合,使得從數(shù)據(jù)邏輯方面到資源調(diào)度方面可控性高,可擴(kuò)展性強(qiáng)。
2.2 問題建模
本文基于大數(shù)據(jù)平臺(tái),采用LSTM作為交通流預(yù)測(cè)模型,LSTM部署在遠(yuǎn)程大數(shù)據(jù)平臺(tái),結(jié)合基于Flink的實(shí)時(shí)流計(jì)算模式,以及部署在大數(shù)據(jù)平臺(tái)多節(jié)點(diǎn)的資源分配算法,本文提出了一種基于流計(jì)算和大數(shù)據(jù)平臺(tái)下LSTM的實(shí)時(shí)交通流預(yù)測(cè)方法RT-LSTM(real-time LSTM)。在后面對(duì)比實(shí)驗(yàn)中,與之對(duì)比的是離線模式下GPU的訓(xùn)練方式G-LSTM(GPU-LSTM)和基于CPU和內(nèi)存的方式(CM-LSTM)。
2.2.1 LSTM模型
(1)LSTM模型包含輸入門Zi、遺忘門Zf和輸出門Zo,其計(jì)算公式見式(1)~式(4),其中xt,ht分別為t時(shí)刻的輸入和隱藏層輸出
Z=tanh(W(xt-1,ht))+b
(1)
Zi=σ(Wi(xt-1,ht))+b1
(2)
Zf=σ(Wf(xt-1,ht))+b2
(3)
Zo=σ(Wo(xt-1,ht))+b3
(4)
(2)長(zhǎng)期記憶Ct、短期記憶ht和最后的輸出Yt的計(jì)算見式(5)~式(7)
Ct=Zf·Ct-1+Zi·Z
(5)
ht=Zo·tanh(Ct)
(6)
Yt=σ(W′·ht)
(7)
其中,t指輸入序列的長(zhǎng)度,W開頭的參數(shù)與輸入和隱藏層維度的拼接的維度一致,需訓(xùn)練參數(shù)有W、Wi、Wf、Wo和W′這5個(gè)參數(shù)矩陣。
2.2.2 多個(gè)遠(yuǎn)程節(jié)點(diǎn)的資源分配算法
在Ray_on_Spar和Spark_on_Yarn的環(huán)境部署完畢后,在大數(shù)據(jù)平臺(tái)開啟多個(gè)訓(xùn)練節(jié)點(diǎn),并把所準(zhǔn)備的資源分配到這些節(jié)點(diǎn)上,最后得到多個(gè)遠(yuǎn)程工作節(jié)點(diǎn)。具體實(shí)現(xiàn)過程如下。
首先獲取Ray的上下文,從Ray上下文獲取到每個(gè)executor所分配的core數(shù)和executor數(shù),而在Ray層,可以再次劃分子節(jié)點(diǎn)數(shù),見算法1的過程(1)至(4)所示。
接著Ray分布式框架開啟多個(gè)遠(yuǎn)程節(jié)點(diǎn)(Remote Runner),并根據(jù)每個(gè)executor的所分配的core數(shù)、executor數(shù)和子節(jié)點(diǎn)worker數(shù)(worker_per_node)分配資源,Ray 把參數(shù)Params分配給對(duì)象 obj,并且形成遠(yuǎn)程工作節(jié)點(diǎn)Remote Runner的公式可表示成如算法1的過程(4)。其中RemoteRunner的類型即為obj的類型,而此處的對(duì)象類型是基于Pytorch的分布式訓(xùn)練器,本文2.2.3給出其定義。
預(yù)定義好Ray遠(yuǎn)程節(jié)點(diǎn)的相應(yīng)參數(shù)和對(duì)象類型后,接著分配計(jì)算資源,包括子工作節(jié)點(diǎn)和cpu核,最后將所有工作節(jié)點(diǎn)集合起來啟動(dòng)torch分布式模式setup_torch _distributed,setup_torch_distributed的分布式的原理會(huì)在2.2.3詳細(xì)介紹。
算法1:?jiǎn)?dòng)多個(gè)遠(yuǎn)程節(jié)點(diǎn)
輸入:Raycontext:Ray環(huán)境上下文
PC:在Spark on Yarn后獲取每個(gè)executor的所分配的core數(shù)。
N:在Spark on Yarn后獲取executor數(shù)。
W:預(yù)設(shè)的每個(gè)節(jié)點(diǎn)的子工作節(jié)點(diǎn)數(shù)。
TR:TorchRunner(Pytorch模型封裝運(yùn)行器)。
Params:LSTM模型參數(shù)(包括模型結(jié)構(gòu)model、優(yōu)化器optimizer、損失函數(shù)loss、評(píng)判指標(biāo)merics等)。
預(yù)定義函數(shù):R(params)(obj)。
輸出:多個(gè)遠(yuǎn)程工作節(jié)點(diǎn)RW
過程:
(1)Ray_ctx←RayContext.get()
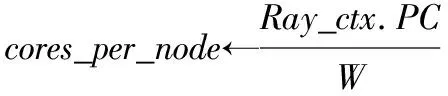
num_nodes←Ray_ctx.N*W
(3)RemoteRunner←R(PC)(TR)
foralli∈{1,2…num_nodes}do
(4)RWi←R(params)(RemoteRunner)
(5) (RWi指的是第i個(gè)RemoteWorker)
endfor forallj∈{1,2…num_nodes}do
RWj←set_up(cores_per_node)
(6)endfor
(7)HW←RW0
(8)addr←HW.set_up_address()
(9)forallk∈{1,2…num_nodes}do
RWk.setup_torch_distributed(addr,k,num_nodes)
endfor
2.2.3 Pytorch分布式訓(xùn)練流程
環(huán)境部署后,需要把RT-LSTM模型參數(shù)打包給訓(xùn)練器,這里所用到的是基于Pytorch的訓(xùn)練器(Torch-Runner),訓(xùn)練器主要負(fù)責(zé)把模型參數(shù)封裝好,并且定義并行度以及已有資源分配方面的參數(shù),比如子節(jié)點(diǎn)數(shù),表示每個(gè)訓(xùn)練器分配多少個(gè)worker去訓(xùn)練。
Pytorch分布式訓(xùn)練通信的后端使用的是gloo或者NCCL,其中NCCL對(duì)應(yīng)于GPU分布式訓(xùn)練,gloo對(duì)應(yīng)于CPU分布式訓(xùn)練(即本文采用的模式)。Pytorch中的數(shù)據(jù)并行訓(xùn)練,涉及nn.Data Parallel(DP)和nn.parallel.Distributed DataParallel(DDP)兩個(gè)模塊。效率較高的是DDP模式,圖5為DDP模式下各設(shè)備(Rank0~Rank4)的參數(shù)傳輸機(jī)制。

圖5 DDP模式參數(shù)傳輸機(jī)制
Pytorch分布式訓(xùn)練流程如圖6所示,第一次循環(huán)后,每個(gè)設(shè)備會(huì)把收到的數(shù)據(jù)和自己的數(shù)據(jù)相加,然后進(jìn)行下一個(gè)循環(huán),經(jīng)過K-1次循環(huán)后,每個(gè)設(shè)備都有其中一部分參數(shù)的完整數(shù)據(jù),比如設(shè)備0有完整的b,設(shè)備1有完整的c。經(jīng)過上述的Scatter-reduce后。后續(xù)再進(jìn)行All_gather過程。這樣經(jīng)過K-1次后,所有的設(shè)備都將具有所有參數(shù)的完整數(shù)據(jù),如圖6所示,下一步將把這些參數(shù)匯總到第一個(gè)設(shè)備RW0上,也如算法2過程的式(5)所示。
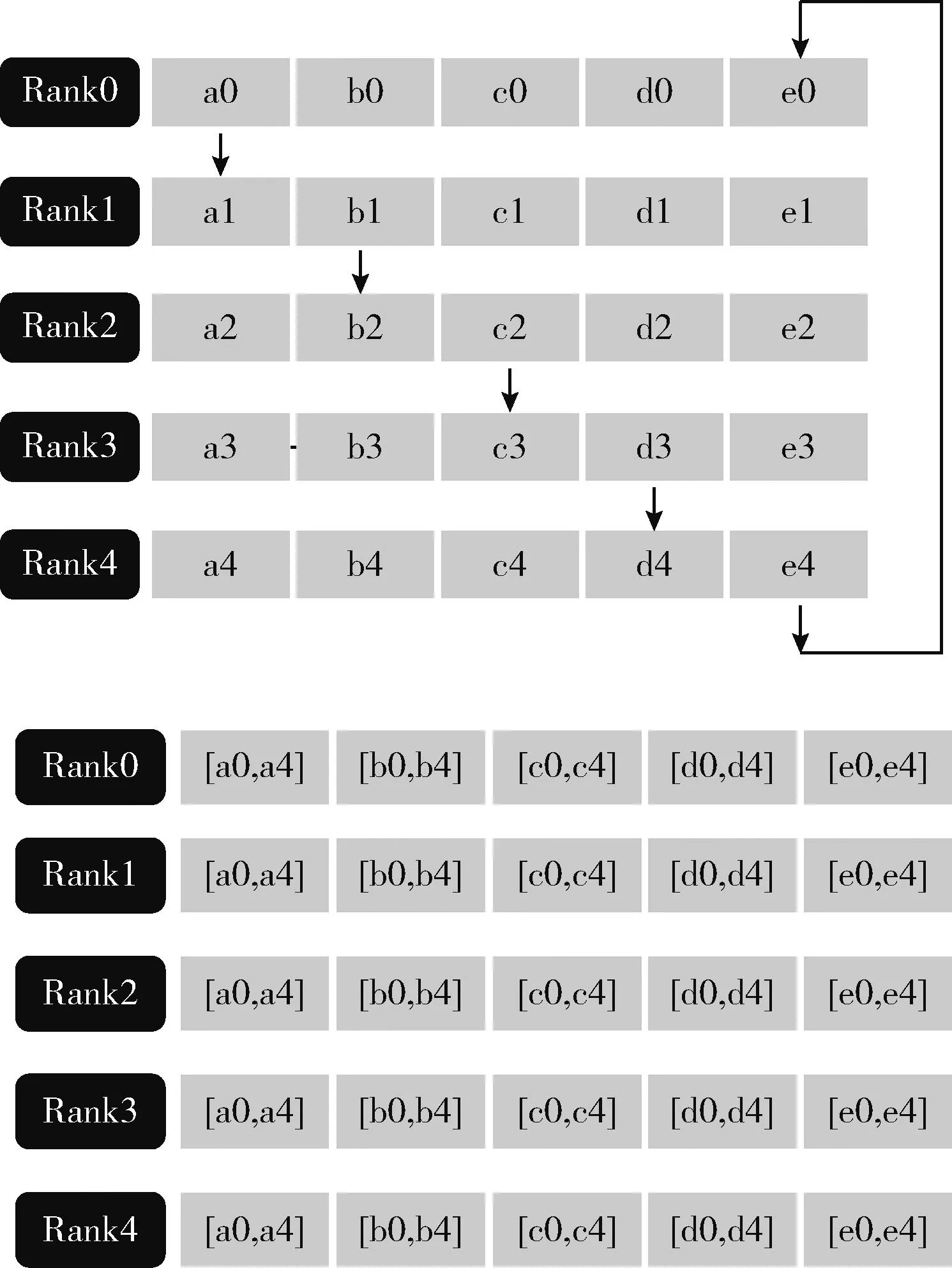
圖6 DDP Scatter-reduce和All_gather
算法2的步驟如下:首先根據(jù)device、訓(xùn)練集與測(cè)試集比例,輸入與輸出的序列制作數(shù)據(jù)集,根據(jù)RemoteWorker的數(shù)量分發(fā)數(shù)據(jù)集到每個(gè)工作節(jié)點(diǎn),然后依據(jù)batch_size構(gòu)建批數(shù)據(jù)集,即增加一個(gè)關(guān)于batch的維度,接著多個(gè)工作點(diǎn)開始同時(shí)訓(xùn)練,不斷地以Pytorch分布式DistributedData-Parallel的機(jī)制去更新模型參數(shù),最后匯總到rank為0的device上,并預(yù)測(cè)未來的速度值。
算法2:RT-LSTM分布式訓(xùn)練的算法流程
輸入:epoch:訓(xùn)練迭代次數(shù)
Size:RemoteWorker的數(shù)量
RW:RemoteWorker
W:預(yù)設(shè)的每個(gè)結(jié)點(diǎn)的子工作節(jié)點(diǎn)數(shù)
Para:LSTM模型參數(shù)
X:最近一小時(shí)的各個(gè)傳感器的記錄的車流速度
Device:設(shè)備(CPU或者GPU)
v_path:數(shù)據(jù)文件路徑
train_pct:訓(xùn)練集比例
n_time:歷史時(shí)間序列
out_time:以未來的某個(gè)時(shí)間標(biāo)簽值
Info:訓(xùn)練參數(shù)
數(shù)據(jù)集轉(zhuǎn)換函數(shù):TFD(d,v,train,test,n,o)
數(shù)據(jù)集分發(fā)函數(shù):DistributedSampler(d,s,r)
輸出(output):模型預(yù)測(cè)的未來的15 min個(gè)傳感器的速度值
過程:
(1)Ds←TFD(device,v_path,train_pct,test_pct,n_time,out_time)
(2)foralli∈{1,2…size}do
Di←DistributedSampler(Ds,size,rank)
(其中D={D1,D2…Dsize})
endfor
(4)forallj∈{1,2…size}do
Dataloaderj←Datacreator(Dj,batch_size)
endfor
(5)forallk∈{1,2…epochs}doRWj.train_epochk(Dataloader,Info)
(表示第j個(gè)RW的第k個(gè)epoch,此處多個(gè)RW同時(shí)進(jìn)行訓(xùn)練。)

endfor
(6)Output=RW0.model(x)
3 實(shí)驗(yàn)及分析
3.1 數(shù)據(jù)集
本文的交通數(shù)據(jù)從PEMS 數(shù)據(jù)集中選取,這些數(shù)據(jù)已被廣泛用于測(cè)試大規(guī)模交通流預(yù)測(cè)模型,它們都來自于美國(guó)加州某主要路段300多個(gè)loop傳感器采集的數(shù)據(jù)。傳感器每30 s采集一次,并以5 min為一個(gè)周期聚合。本文采用了2018年兩個(gè)月的數(shù)據(jù),并選用了其中的速度值作為特征進(jìn)行實(shí)驗(yàn)。超參數(shù)優(yōu)化之后,以12作為窗口大小(1 h,12個(gè)5 min)選取數(shù)據(jù)集進(jìn)行預(yù)測(cè)。
3.2 對(duì)比方法
對(duì)比方法根據(jù)并行的理論進(jìn)行分類,首先是基于CPU與內(nèi)存的離線訓(xùn)練模式—CM-LSTM,其次是GPU模式G-LSTM,利用GPU本身的并行機(jī)制,通過調(diào)整batch-size的大小,使之一次性盡可能地處理更多的數(shù)據(jù)。最后是Ray-Spark大數(shù)據(jù)框架并行模式—RT-LSTM,調(diào)整不同并行度(D3、D6、D12)作比較。為了能夠?qū)Ρ炔煌J缴系膶?shí)時(shí)性,這里通過調(diào)整batch-size,使得所用的內(nèi)存和GPU并行模式所用的顯存基本一樣,都約為8 G。
后面的實(shí)驗(yàn)從兩個(gè)方面展開,一方面是在運(yùn)行內(nèi)存基本一樣的情況下,從訓(xùn)練的時(shí)間和誤差(RMSE)去對(duì)比幾個(gè)模式的并行的效果;另一方面通過調(diào)整不同executor數(shù)量、worker_per_node(子工作節(jié)點(diǎn)數(shù))、core數(shù)量,以研究RT-LSTM訓(xùn)練的最優(yōu)化效果。
3.3 實(shí)驗(yàn)設(shè)置
3.3.1 顯卡配置
GPU Memory:11 019 MB
CUDA 版本:11.4
3.3.2 Hadoop集群配置
集群節(jié)點(diǎn)數(shù):3
可用RAM:40 960 MB
存儲(chǔ)空間:28.4 TB
3.4 對(duì)比結(jié)果和分析
首先本文在相同的顯存和內(nèi)存的情況下進(jìn)行了實(shí)驗(yàn)一,比較了CM-LSTM、G-LSTM和RT-LSTM大數(shù)據(jù)框架并行兩種模式下模型訓(xùn)練的效果,主要比較它們的訓(xùn)練誤差、訓(xùn)練速度和擬合的效果,表1為整體對(duì)比效果。

表1 各種模式實(shí)驗(yàn)效果對(duì)比
其次,在大數(shù)據(jù)框架并行模式下進(jìn)行了實(shí)驗(yàn)二至實(shí)驗(yàn)四,對(duì)比了不同參數(shù)時(shí)的訓(xùn)練誤差RMSE、訓(xùn)練速度和實(shí)現(xiàn)擬合收斂所需的epoch數(shù),從表1和表2可看出相應(yīng)的對(duì)比效果。而從表3得出計(jì)算資源分配數(shù)量與訓(xùn)練速度的關(guān)系。
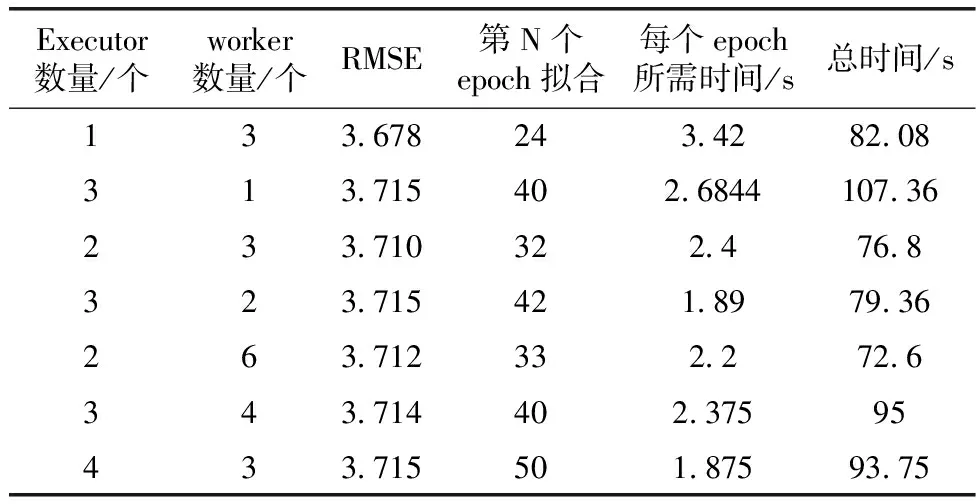
表2 RT-LSTM模式下不同節(jié)點(diǎn)數(shù)和worker數(shù)的對(duì)比

表3 RT-LSTM模式下(工作節(jié)點(diǎn)數(shù)相同)的不同節(jié)點(diǎn)分配的core數(shù)結(jié)果對(duì)比
3.4.1 實(shí)驗(yàn)一
首先對(duì)比的是CM-LSTM、G-LSTM模式和框架并行RT-LSTM的測(cè)試誤差RMSE,RMSE為均方根誤差,從框架下的并行(RT-LSTM)里可以看出,由于數(shù)據(jù)集被分發(fā)了3份、6份和12份分別進(jìn)行訓(xùn)練,訓(xùn)練誤差方面雖然不如G-LSTM模式和CM-LSTM,但是相差不是很大,只相差了大約0.33 km/h,這個(gè)誤差在實(shí)際的場(chǎng)景中是可以接受的,比如預(yù)測(cè)速度值是50.33 km/h,而實(shí)際的速度值是50 km/h。在訓(xùn)練速度方面,對(duì)比的是總訓(xùn)練時(shí)間,總訓(xùn)練時(shí)間等于擬合所需要的epoch數(shù)乘以平均每個(gè)epoch的所需要的時(shí)間,可以看到,在所需內(nèi)存相同的情況下,大數(shù)據(jù)框架并行模式所需總訓(xùn)練時(shí)間最多為93.8 s,比GPU模式總訓(xùn)練時(shí)間要小很多,可見在訓(xùn)練速度方面均優(yōu)于GPU并行,而從表1可以看出,CM-LSTM已經(jīng)完全不具備實(shí)時(shí)性。圖7和圖8分別為不同模式在總訓(xùn)練時(shí)間和訓(xùn)練誤差的對(duì)比。
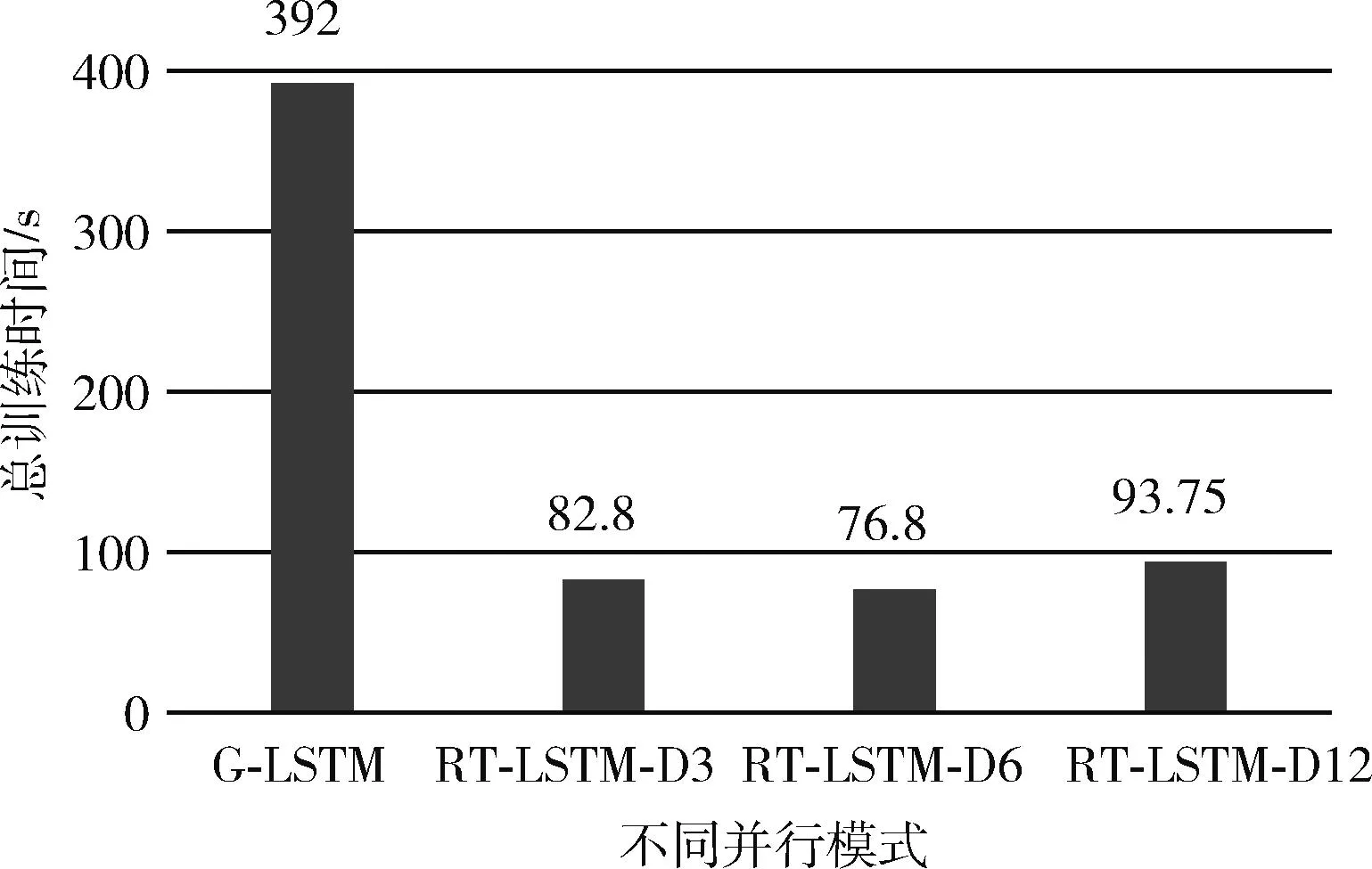
圖7 不同模式總訓(xùn)練時(shí)間對(duì)比

圖8 不同并行模式訓(xùn)練誤差對(duì)比
3.4.2 實(shí)驗(yàn)二
在大數(shù)據(jù)框架并行模式中,不同的TorchRunner數(shù)量對(duì)訓(xùn)練誤差影響不大,但是速度上會(huì)有顯著的區(qū)別,TorchRunner即為總工作節(jié)點(diǎn)數(shù),其數(shù)量等于數(shù)據(jù)并行度(并行度=num_node*worker_per_node),誤差效果方面最好的是并行度為3的情況,誤差為3.678。然而在總訓(xùn)練時(shí)間方面,雖然并行度提高了對(duì)于本來可以一次讓模型的效果達(dá)到擬合收斂的數(shù)據(jù)集,被劃分成了3份,需要一份接著一份地去讓模型進(jìn)行學(xué)習(xí),相當(dāng)于要把訓(xùn)練的“步伐”減緩。圖9和圖10分別為不同工作節(jié)點(diǎn)數(shù)的訓(xùn)練誤差和訓(xùn)練時(shí)間對(duì)比,其中n1w3表示executor數(shù)為1,子工作節(jié)點(diǎn)為3,其工作節(jié)點(diǎn)數(shù)為n*w=3,其它以此類推,圖11為每個(gè)epoch所需的時(shí)間的結(jié)果對(duì)比。
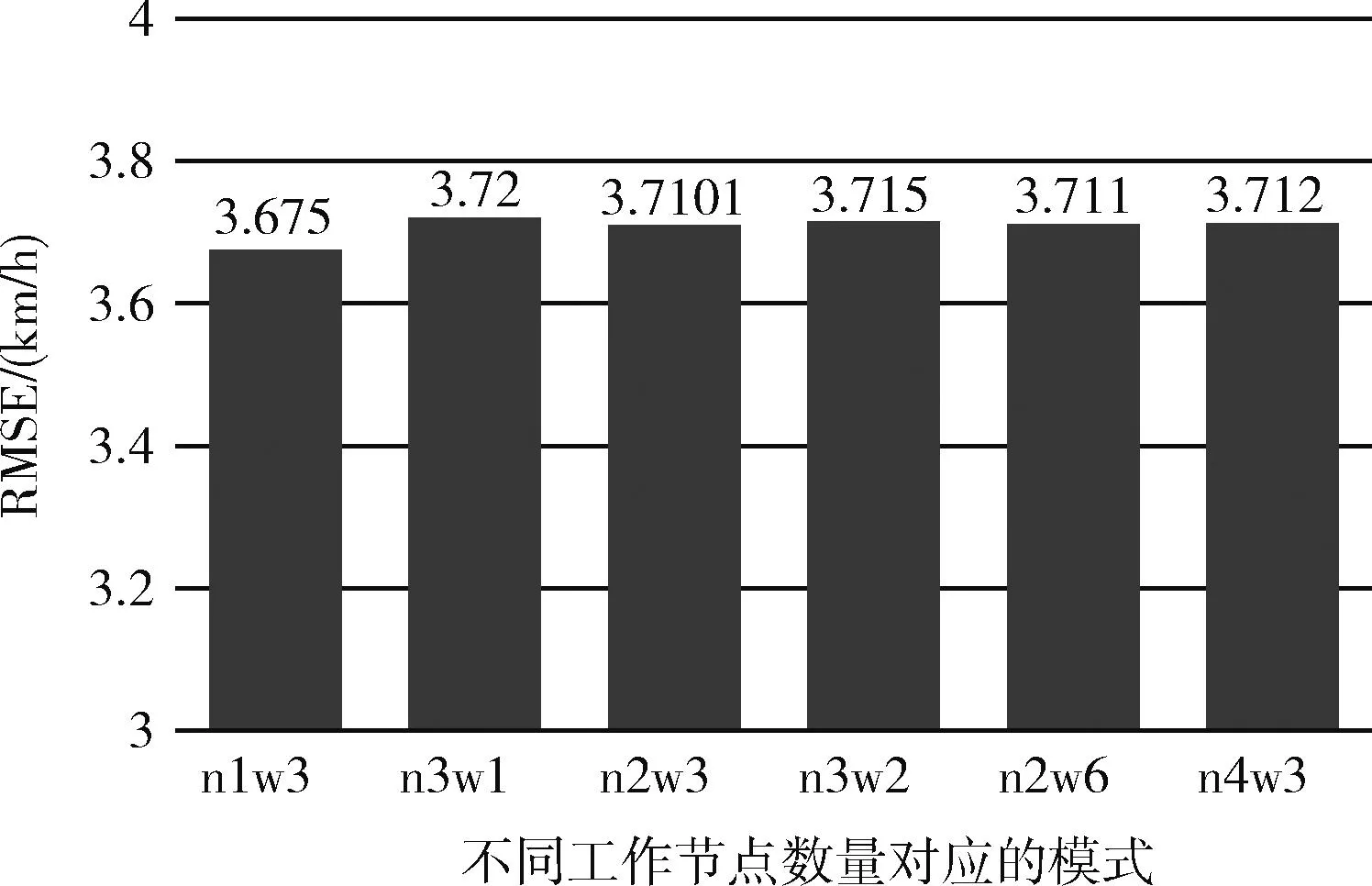
圖9 RT-LSTM下不同工作節(jié)點(diǎn)數(shù)之誤差對(duì)比

圖10 RT-LSTM下不同工作節(jié)點(diǎn)數(shù)之總訓(xùn)練時(shí)間對(duì)比
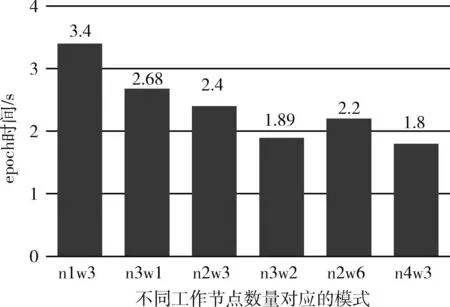
圖11 RT-LSTM下不同工作節(jié)點(diǎn)數(shù)之epoch時(shí)間對(duì)比
3.4.3 實(shí)驗(yàn)三
RT-LSTM模式中,在同樣的工作節(jié)點(diǎn)數(shù)量下,也就是數(shù)據(jù)并行度一樣的情況下,子工作節(jié)點(diǎn)數(shù)對(duì)模型的訓(xùn)練也有所影響,每個(gè)節(jié)點(diǎn)的worker數(shù)主要影響的是節(jié)點(diǎn)的每次訓(xùn)練的batch-size。雖然在環(huán)境準(zhǔn)備時(shí),所分配給每個(gè)節(jié)點(diǎn)的core資源是一樣的,worker_per_node數(shù)量越高,單個(gè)工作節(jié)點(diǎn)每次訓(xùn)練的batch-size會(huì)越小,batch的數(shù)量會(huì)提高,但是由于RT-LSTM的多核的環(huán)境下并行度隨著子工作節(jié)點(diǎn)數(shù)量的提高而變高,所以如圖12所示,每個(gè)epoch需要的時(shí)間減少,即訓(xùn)練速度加快。此外,由于batch-size減小使每次epoch對(duì)參數(shù)的更新次數(shù)增加了,訓(xùn)練“步伐”加快,因此收斂所需要的迭代次數(shù)降低,從而縮短了總訓(xùn)練時(shí)長(zhǎng),如圖13所示。

圖12 不同worker_per_node數(shù)目之單個(gè)epoch時(shí)間對(duì)比

圖13 不同worker_per_node數(shù)目之總訓(xùn)練時(shí)間對(duì)比
3.4.4 實(shí)驗(yàn)四
對(duì)于每個(gè)訓(xùn)練節(jié)點(diǎn),給予其不同數(shù)量的core資源,訓(xùn)練速度也會(huì)有提高。若分配給工作節(jié)點(diǎn)的core數(shù)量越高,即可運(yùn)行的資源會(huì)更多,訓(xùn)練速度越快,但是達(dá)到一定數(shù)量情況下,由于不是所有的core會(huì)參與到訓(xùn)練中,所以訓(xùn)練速度會(huì)到達(dá)一個(gè)瓶頸就不再上升。圖14為相同訓(xùn)練節(jié)點(diǎn)數(shù)的情況下分配資源不同的實(shí)驗(yàn)對(duì)比,其中C6表示6個(gè)core。

圖14 不同core分配數(shù)量的單個(gè)epoch時(shí)間對(duì)比
3.5 交通路況可視化
為了可視化交通流的速度預(yù)測(cè)效果,從307個(gè)傳感器中選取位于PaloAlto至Giltroy路段的26個(gè)作為研究對(duì)象,傳感器在主干道路的分布如圖15所示,若以一小時(shí)窗口大小的數(shù)據(jù)作為模型預(yù)測(cè)的輸入,把窗口末尾5 min作為當(dāng)前的時(shí)間,其部分傳感器車速值分布如圖15上所示,而未來15 min內(nèi)傳感器的速度預(yù)測(cè)值分布如圖15下所示。
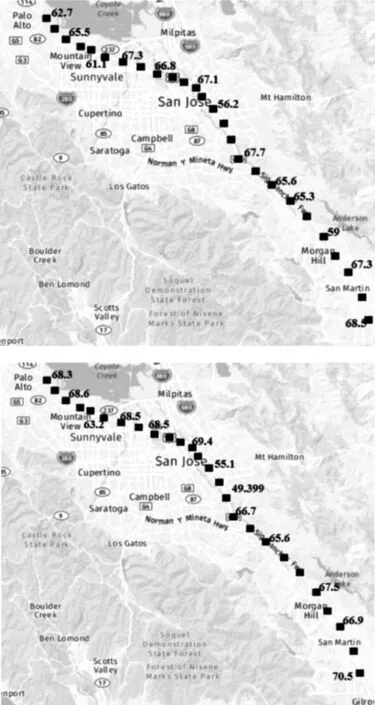
圖15 當(dāng)前速度值和未來15 min內(nèi)的速度預(yù)測(cè)值分布
4 結(jié)束語(yǔ)
本文設(shè)計(jì)一種基于Flink流計(jì)算框架和大數(shù)據(jù)平臺(tái)結(jié)合的實(shí)時(shí)交通流預(yù)測(cè)方法,并采用該方法對(duì)實(shí)際交通路段中的多個(gè)傳感器產(chǎn)生的海量數(shù)據(jù)進(jìn)行實(shí)時(shí)捕捉、存儲(chǔ)和建模分析,實(shí)現(xiàn)了對(duì)該路段交通流的實(shí)時(shí)預(yù)測(cè)。探討和比較了CM-LSTM、G-LSTM和大數(shù)據(jù)框架下RT-LSTM并行模式下模型訓(xùn)練效果。實(shí)驗(yàn)結(jié)果表明,在大數(shù)據(jù)框架下的多節(jié)點(diǎn)同時(shí)訓(xùn)練的橫向并行模式,比起縱向并行模式(G-LSTM),橫向并行模式訓(xùn)練速度大大提升,并且又能保持一定的預(yù)測(cè)精度。但并行的訓(xùn)練方式在數(shù)據(jù)集分布不均勻時(shí),還是存在收斂速度慢和效果相差較大的風(fēng)險(xiǎn),如何去把控?cái)?shù)據(jù)集的分布問題、訓(xùn)練的并行度以及模型收斂問題是未來需要進(jìn)一步探索的。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
