基于嗅覺受體激活關系模擬的氣味感知預測*
2024-02-24 09:02:06左敏胡靜珺顏文婧王瑞東張青川范大維
中山大學學報(自然科學版)(中英文) 2024年1期
關鍵詞:模型
左敏, 胡靜珺, 顏文婧, 王瑞東, 張青川, 范大維
1.北京工商大學農產品質量安全追溯技術及應用國家工程研究中心,北京 100048
2.北京市房山區教師進修學校,北京 102401
人類生理嗅覺系統十分復雜,氣味分子和嗅覺受體(ORs, olfactory receptors)在氣味感知表現中起著關鍵性作用。氣味分子與嗅覺受體結合并激活嗅覺受體,將氣味信號傳遞給大腦(Li et al.,2018),最終,人類對氣味信號的感知被轉化為相應的描述性詞語(Lapid et al.,2011; Debnath et al.,2020;Francia et al.,2021)。受文化、語言和經驗的影響,對于同一個氣味分子人們可能會使用不同的感知詞進行描述(Majid et al., 2018)。因此,對氣味分子的氣味感知進行預測是一項極具挑戰性的任務。為解決這個問題,近年來智能信息研究領域嘗試使用機器學習(ML, machine learning)方法構建氣味感知預測模型(Keller et al., 2017),并獲得了較好的效果。
目前大多數的氣味感知預測模型都是從分子結構出發預測氣味感知,該方式強烈依賴于分子表征(Pattanaik et al.,2020)。通常采用的方法是利用計算機表示方法對分子特征進行描述,進而構建機器學習模型。Shang et al.(2017)基于氣味分子參數(MPs, molecular parameters),采用支持向量機(SⅤM, support vector machine)對1 026 個分子的10 種氣味感知實現了正確率為97.08%的預測。Li et al.(2018)同樣基于MPs,并采用隨機森林算法(RF, random forest)對DREAM(dialogue on reverse engineering assessment and methods)數據集進行氣味感知回歸預測,氣味強度預測的皮爾遜相關性指標達到了近似0.6。Kasyap et al.(2022)采用圖神經網絡(GNNs, graph neural networks)提取分子結構特征并在DREAM 數據集上進行氣味感知多分類預測,模型的AUC指標為0.89。
然而,從生理學機制上看,僅僅考慮分子物化特性無法對氣味感知的形成進行解釋,相似的分子結構可能產生不同的感知,而不同的分子結構也可能會產生相同的感知。研究者已經對人類嗅覺生理學機制進行揭秘,發現激活的嗅覺受體是氣味感知產生的關鍵(Buck,2008)。目前只有少數研究基于氣味分子-嗅覺受體激活關系進行氣味感知預測。Kowalewski et al.(2020)發現,在氣味感知預測任務上,結合嗅覺受體激活特征對氣味分子進行感知預測更具優勢,可取得更好的效果。
本研究首先創新性地構建了嗅覺受體蛋白質關系網絡,通過引入人類嗅覺受體蛋白之間的復雜關系來學習氣味分子和嗅覺受體之間的復雜非線性高維關系。其次,采用圖卷積網絡,在分子拓撲結構和蛋白質網絡結構上提取氣味分子和嗅覺受體蛋白質關系網絡上的關鍵特征,在大規模氣味感知數據集DREAM 上實現對氣味感知的精準預測。最后,基于預測的嗅覺受體激活信息,并結合模型正確決策的解釋性分析,對氣味分子-嗅覺受體活動-氣味感知之間的模式進行分析,為人類嗅覺研究提供新的視角。
1 研究方法
1.1 研究框架
本研究首先基于人類嗅覺受體蛋白質關系網絡構建嗅覺受體激活預測模型,通過圖卷積方法分別提取氣味分子和嗅覺受體蛋白的特征。其次,基于嗅覺受體激活預測模型的模擬結果,融合分子摩根指紋,基于DREAM 數據集實現對氣味感知的回歸預測。
工作流程如圖1所示。

圖1 氣味感知預測工作流程圖Fig.1 Olfactory perception prediction workflow diagram
1.2 蛋白質特征構建
1.2.1 嗅覺受體蛋白質關系網絡構建本研究收集了43 個經過生物實驗驗證的確定可以被特定配體激活的人類嗅覺受體(Ⅴassar et al.,1993; Mata‐razzo et al.,2005; Jacquier et al.,2006; Neuhaus et al.,2006; Braun et al.,2007; Fujita et al.,2007;Keller et al.,2007; Menashe et al.,2007; Schmiede‐berg et al.,2007; Cook et al.,2009; Saito et al.,2009; Jaeger et al.,2013; Topin et al.,2014; Shirasu et al.,2014),采用One-Hot編碼表示嗅覺受體蛋白氨基酸序列。嗅覺受體蛋白質三級結構信息有兩個不同的來源。經過實驗驗證的結構來自于Uniport 蛋白質數據庫,未知的嗅覺受體蛋白質三級結構則采用AlphaFold 蛋白質3D 結構預測模型進行預測。
嗅覺受體蛋白質關系網絡以嗅覺受體蛋白質作為節點,其氨基酸序列作為節點特征,嗅覺受體蛋白質三級結構的相似關系作為邊。根據已獲得的嗅覺受體蛋白質三級結構,本研究采用TMscore (template modeling score)方法計算蛋白質之間的相似度。TM-score 是一種用于評估蛋白質結構拓撲相似性的指標,通過比較兩個蛋白質全局結構的相似性來評估它們的匹配程度,其取值范圍介于0 到1 之間。TM-score 低于0.17 被認為對應于隨機選擇的不相關蛋白質(Zhang et al.,2004),而大于0.5 則表示具有相似的折疊狀態(Xu et al.,2010)。 TM-score的計算公式為
其中Ltarget是目標蛋白質的氨基酸序列長度,Lcommom是在模板結構和目標結構中均存在的殘基數量,dt是模板和目標結構中第t對殘基之間的距離,d0(Ltarget)是用來歸一化距離的距離尺度。獲得嗅覺受體蛋白質三級結構相似度后,可以構建嗅覺受體蛋白質關系網絡。
1.2.2 蛋白質圖卷積特征圖卷積(graph convo‐lution)是一種適用于處理具有節點間關聯關系的圖數據的卷積操作方法。在本研究中,嗅覺受體蛋白質關系網絡表示為Gp=(Vp,Ep),其中節點集合Vp表示嗅覺受體蛋白氨基酸序列集合,邊集合Ep表示嗅覺受體蛋白質三級結構之間的相似度集合。每個節點的特征向量定義為vp,vp∈Vp,邊的特征向量定義為ep,ep∈Ep。
嗅覺受體蛋白質關系網絡是通過對嗅覺受體蛋白氨基酸序列和嗅覺受體蛋白質三級結構相似度進行編碼得到的。嗅覺受體蛋白氨基酸序列被編碼為一個具有20 種氨基酸和331 個序列位置的特征向量,其維度為[20,331],嗅覺受體蛋白質三級結構間相似度被編碼為一個維度為1 的特征向量。
蛋白質圖卷積特征的構建方法如下:
1.3 分子特征構建
1.3.1 分子摩根指紋在本研究中,任意分子圖表示為Gm=(Vm,Em),其中節點集合Vm表示原子集合,邊集合Em表示化學鍵集合。每個原子的特征向量定義為vm,vm∈Vm,化學鍵的特征向量定義為em,em∈Em。
摩根指紋(Morgan fingerprints)方法是一種用于描述分子結構的化學指紋方法。它基于分子的拓撲結構,對于節點v通過遞歸遍歷分子的鄰居節點u∈Rv,Rv是與節點v相連的節點集合,并將鄰居節點的特征向量進行累積求和。然后,將累積特征向量Fu與連接邊的信息Gu,v進行異或操作,并通過哈希函數進行映射,最終得到摩根指紋。摩根指紋計算公式
1.3.2 分子圖卷積指紋分子圖卷積指紋基于分子拓撲結構進行分子特征提取,分子和化學鍵的特征基于原子符號、相鄰原子、相鄰氫原子、隱含價、芳香性以及化學鍵類型等進行編碼。具體如表1所示。

表1 分子特征向量構成Table 1 Molecular feature vector composition
對分子圖進行圖卷積操作
1.4 預測模型
1.4.1 SⅤM支持向量機(SⅤM, support vector machine)是一種常用的監督學習算法,其基本原理是尋找一個最優的超平面,將樣本空間分成兩個不同類別,并最大化樣本與超平面之間的間隔。對每一個樣本數據,SⅤM決策函數
其中x是輸入樣本特征向量,WSVM是決策函數的權重矩陣,bSVM是偏置項,sign是符號函數。
1.4.2 ELM極限學習機(ELM, extreme learning machine)通過隨機初始化輸入層和輸出層之間的權重,然后利用解析解的方式直接計算隱藏層的權重。這使得ELM 能夠快速地訓練神經網絡,并在很短的時間內生成準確的預測結果。對每一個樣本數據,ELM決策函數
其中x是輸入樣本特征向量,HELM(x)是基于輸入特征計算得到的隱藏層輸出矩陣,WELM是輸出層到隱藏層的權重矩陣,bELM是偏置項。
1.4.3 XGBoostXGBoost 是一種基于梯度提升樹的集成學習算法。它通過迭代訓練多個弱分類器(通常是決策樹),并將它們組合成一個強大的模型。對全部N個樣本數據,XGBoost的目標函數
其中LossXGB(yn,)是第n個樣本的損失函數,yn是樣本n的標簽,是樣本n的預測值,Ω(Φ)表示模型中的每個子模型的正則化項,Q是決策樹的個數,γ是正則化系數。
1.4.4 BP 神經網絡BP(back propagation)人工神經網絡模型基于反向傳播算法,通過不斷調整網絡中連接權重和偏置,使網絡能夠學習輸入與輸出之間的高維非線性映射關系。
BP神經網絡的標準前向傳播公式為
其中P表示訓練樣本的個數。
1.5 SⅤD-PCA
基于奇異值分解(SⅤD, singular value decom‐position)的主成分分析(PCA, principal component analysis)是一種常用的降維技術。SⅤD-PCA 的優點是可以處理高維數據,并且對異常值具有較好的魯棒性。
給定一個數據矩陣XSP,首先對XSP進行標準化處理獲得矩陣,使得每個特征均值為0,方差為1。然后,對標準化后的數據矩陣進行SⅤD分解
其中C和O是由SⅤD計算得到的矩陣,S是由SⅤD得到的正交矩陣。
PCA 的結果是通過選擇奇異值及其對應的左奇異向量來進行降維。主成分矩陣可以通過以下公式計算得到
其中Z是降維后的數據矩陣。
2 實驗過程
2.1 實驗數據集
2.1.1 數據庫1:氣味分子-嗅覺受體激活關系數據庫本文基于現有發表文獻建立氣味分子-嗅覺受體激活關系數據庫,所有數據都來自于截至在2023 年7 月之前Web of Science 數據庫中收錄的文獻。數據庫共收集了43 個人類嗅覺受體,以及它們對選定的170個化合物的254條激活關系和61條非激活關系數據。
2.1.2 數據庫2:氣味分子-氣味感知關系數據庫DREAM 數據集使用包括強度、愉悅度和熟悉度在內的23 個感知定義氣味感知。數據集包括49 名健康參與者(沒有專業氣味感知訓練)對476種氣味分子產生的21 種氣味感知數據,評分范圍為0~100。本研究選用標記為“高濃度”的數據共405 條。
2.2 嗅覺受體激活預測模型訓練
嗅覺受體激活預測XGBoost 模型參數設置如表2所示。

表2 XGBoost模型參數調節范圍1)Table 2 Parameter adjustment range of XGBoost model
模型評價指標選取準確率(accuracy)、F1-score、受試者工作特征(ROC, receiver operating character‐istic curve)的曲線下面積(AUC, area under the curve)。
2.3 氣味感知預測模型訓練
氣味感知預測模型訓練采用5折交叉驗證,即將數據劃分為大致相等的5個子數據集,依次采用不同數據集作為訓練集和測試集。取5次訓練平均精度的平均值即得到模型精度,這樣得到的模型精度更具有泛化性。
氣味感知預測BP模型參數設置如表3所示。

表3 BP模型參數調節范圍1)Table 3 Parameter adjustment range of BP model
模型評價指標選取R2-score、皮爾遜相關性、均方根誤差(RMSE, root mean square erro)。
3 實驗結果與分析
3.1 嗅覺受體蛋白質關系網絡
本研究使用嗅覺受體蛋白質關系網絡中100%的相似度、前70%的相似度、前50%相似度網絡關系,獲取相關網絡性質指標,并使用基于模塊度的社區發現算法分析網絡的模塊性(Blondel et al.,2008)。分析如表4所示。本研究基于相似度排名前50%的數據繪制出嗅覺受體蛋白質關系網絡圖(圖2)。使用相似度排名前50%的網絡呈現出明顯的3個子模塊,且不存在孤立節點。屬于同一模塊的嗅覺受體具有相似的蛋白質結構,比如,圖2中嗅覺受體OR2J3 與OR2J2 同屬于一個社區模塊,同時,研究也證實它們是人類嗅覺受體中最為相似的嗅覺受體對之一(Crasto et al.,2002)。

表4 嗅覺受體蛋白質關系網絡概覽Table 4 Network overview of olfactory receptor protein relationship

圖2 嗅覺受體蛋白質關系網絡(前50%)Fig.2 Olfactory receptor protein relationship network (Top 50%)
3.2 基于不同特征提取方式的嗅覺受體激活預測結果比較
分子的表征方式在化學領域中尚未形成統一的標準,不同的表征方法各具優勢和局限性。本文對氣味分子和嗅覺受體蛋白分別采用了兩種不同的特征提取方法,并進行對比實驗。結果如表5所示。結果表明,當分別使用圖卷積進行分子特征和嗅覺受體蛋白氨基酸序列特征提取時,采用XGBoost 算法實現了最佳的嗅覺受體激活預測效果,準確率為77%,F1-score 為0.78,AUC 值為0.77。4 種特征提取方式AUC 比較結果如圖3所示。
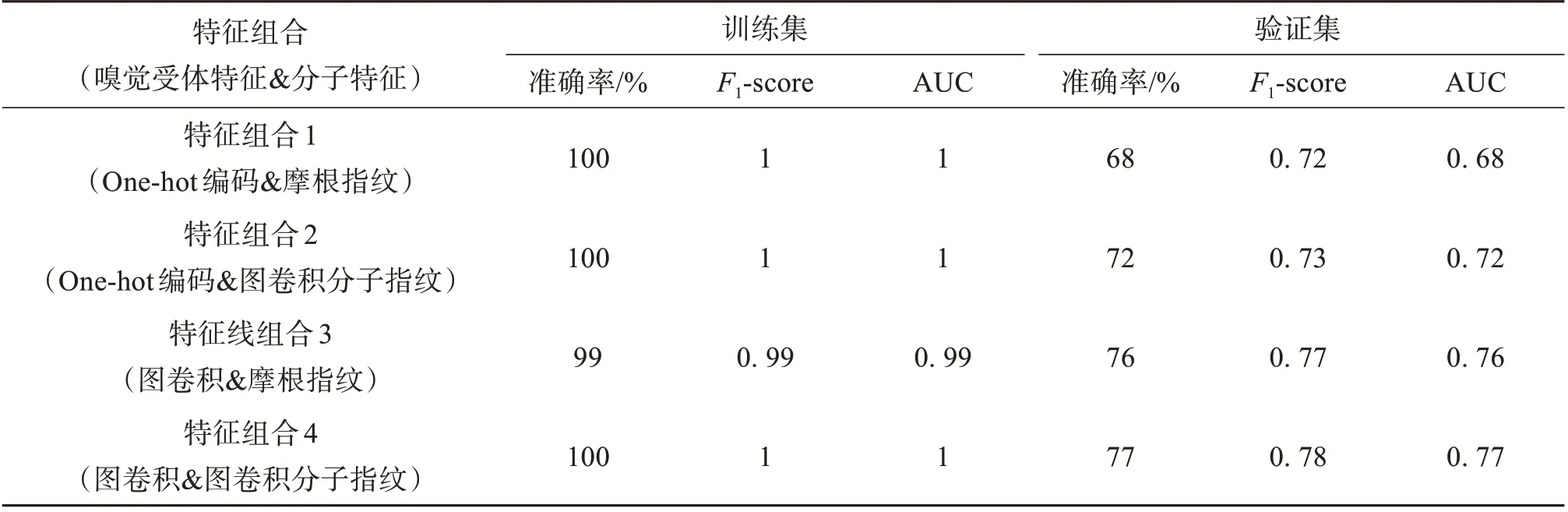
表5 不同分子特征提取方式組合在數據庫1上的準確率、 F1-score和AUCTable 5 Accuracy, F1-score, and AUC of different feature extraction methods for database 1

圖3 不同特征提取方式組合的ROC曲線及AUC值Fig.3 ROC curves and AUC values of different feature extraction methods
3.3 基于不同分類器的嗅覺受體激活預測模型比較
基于圖卷積特征提取,本文采用XGBoost、SⅤM 以及ELM 3 種機器學習方法進行嗅覺受體激活預測,并進行對比實驗,結果如表6所示。實驗結果表明,XGBoost 算法在氣味分子-嗅覺受體激活關系數據庫上表現結果最優,準確率為77%,F1-score 為0.78,AUC 為0.77。3 種分類器的嗅覺受體激活預測模型AUC比較結果如圖4所示。

表6 不同分類器的嗅覺受體激活預測模型在數據庫1的準確率、F1-score和AUCTable 6 Accuracy, F1-score and AUC of olfactory receptor activation prediction models for different classifiers on database 1
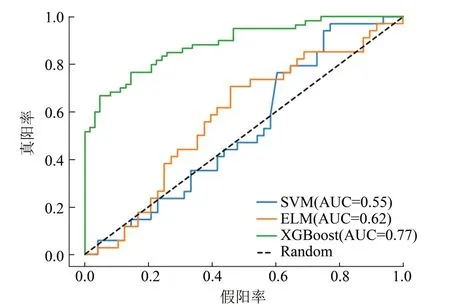
圖4 不同分類器的嗅覺受體激活預測模型的ROC曲線和AUC值Fig.4 ROC curves and AUC values of olfactory receptor activation prediction models for different classifiers
3.4 氣味感知預測結果比較
本研究在嗅覺受體激活預測模型的基礎上,對DREAM 數據集中的化合物與43 個嗅覺受體的激活關系進行預測,將獲得的新氣味分子-嗅覺受體激活關系作為分子特征應用于氣味感知預測模型。在數據集和回歸預測模型相同的情況下,引入氣味分子-嗅覺受體激活關系進行氣味感知預測結果明顯優于僅基于分子結構進行氣味感知預測。實驗結果說明在進行氣味感知預測時,考慮嗅覺受體的活動情況是必要的。實驗結果如表7所示。
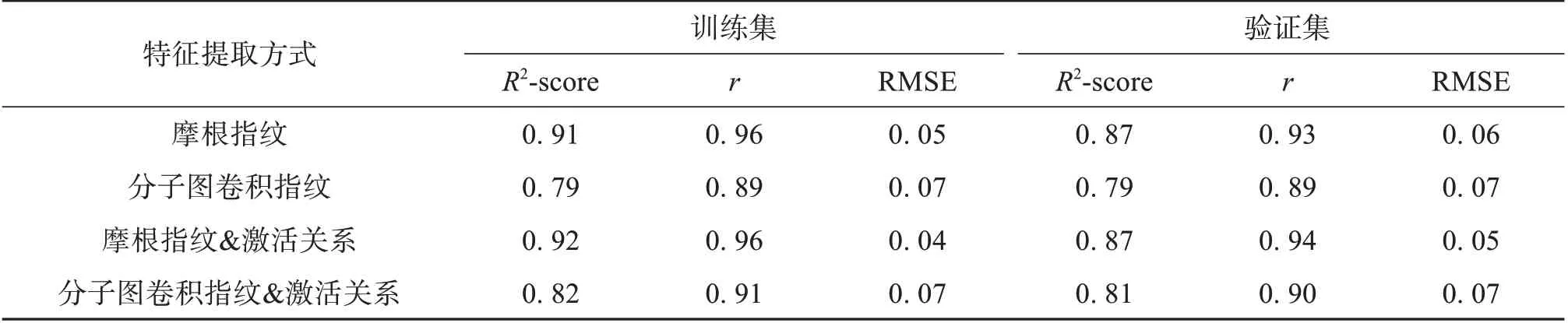
表7 不同特征提取方式在DREAM數據集上的R2-score、 r和RMSETable 7 R2-score, r and RMSE on the DREAM dataset with different feature extraction methods
在3.3 節中,對于嗅覺受體激活預測任務,圖卷積特征提取方法明顯優于摩根指紋特征提取。然而,在本節的氣味感知預測任務中,摩根指紋方法表現更優。這是由于圖卷積方法和摩根指紋方法對分子特征表達方式不同造成的。圖卷積方法基于圖結構進行特征提取,考慮了原子之間的連接關系,在捕捉分子的全局信息上具有優勢。而摩根指紋根據分子的物理化學性質進行有效編碼,更擅長總結分子的理化特征(Cereto-Massagué et al.,2015; Duvenaud et al.,2015; Kipf et al.,2016)。
3.5 氣味分子-嗅覺受體激活-氣味感知模式
本研究通過嗅覺受體蛋白質關系網絡,整合了DREAM 數據集和氣味分子-嗅覺受體激活關系信息。采用基于奇異值分解的主成分分析方法對嗅覺受體在特定氣味感知中的貢獻進行分析。嗅覺受體對21 種氣味感知的貢獻度歸一化后的結果如圖5所示。大部分嗅覺受體會對特定氣味感知產生較高的貢獻度(Audouze et al.,2014)。

圖5 嗅覺受體對氣味感知貢獻度Fig.5 Olfactory receptor contribution to olfactory perception
此外,本研究采用密度聚類算法(Campello et al.,2020),對來自DREAM 數據集的405 個氣味分子的43 個嗅覺受體激活特征進行聚類,將分子分為4個類別,并繪制了氣味分子-嗅覺受體激活-氣味感知模式圖。如圖6所示,產生激活關系少于20條的嗅覺受體并沒有被繪制,DREAM 數據集中氣味感知評分低于5 分的氣味感知描述詞沒有被繪制。

圖6 氣味分子-嗅覺受體激活-氣味感知模式Fig.6 Odor molecule-olfactory receptor activation-olfactory pattern
研究結果表明,經由氣味分子-嗅覺受體激活關系對分子進行分類在氣味感知上出現了明顯的模式上的不同。例如,“腐爛(decayed)”只與第1類分子激活的3個嗅覺受體相連;“花(flower)”只與第4類分子激活的4個嗅覺受體相連等,本研究部分結果與已得到的生物實驗結果驗證一致(Chaput et al.,2012; El Mountassir et al.,2016; Keller et al.,2016)。本研究同時嘗試了使用SMⅠLES分子表達式和摩根指紋對分子進行聚類,所獲得的結果難以提取出明顯的氣味分子-嗅覺受體激活-氣味感知模式。
4 結 語
本研究旨在提出一種基于數據驅動方法的氣味感知預測和分析的新解決方案。首先,構建了嗅覺受體蛋白質關系網絡,采用圖卷積方法以獲得更全面有效的嗅覺受體蛋白特征。在嗅覺受體激活關系數據的基礎上,構建了嗅覺受體激活預測模型。其次,面向DREAM 數據集并引入其嗅覺受體激活數據,以提供必要的生理信息補充,實現對氣味分子感知的精準預測。最后,對模型形成的正確決策機制進行解釋分析,并總結了氣味分子-嗅覺受體激活-氣味感知模式。研究結果表明,綜合考慮氣味分子特征和氣味分子-嗅覺受體激活關系構建預測模型,能夠獲得更好的預測結果,并獲得對人類氣味感知模式的有效總結。
盡管研究結果仍需要進一步驗證,但本研究為進一步探索和理解氣味感知機制提供了有價值的參考和啟示。未來的工作將面向更多的氣味感知數據集進一步優化模型,基于數據驅動技術進一步學習氣味分子與嗅覺受體激活的對接模型,為氣味感知的預測提供更多有用的信息,進一步推進人類嗅覺機理研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
