基于多層次自注意力網(wǎng)絡(luò)的人臉特征點檢測
2024-02-29 04:39:54徐浩宸劉滿華
計算機工程 2024年2期
徐浩宸,劉滿華
(上海交通大學(xué)電子信息與電氣工程學(xué)院,上海 200240)
0 引言
人臉特征點檢測又稱人臉對齊,指自動定位人臉上的一系列預(yù)設(shè)基準(zhǔn)點(如眼角、嘴角等),是人臉處理的關(guān)鍵步驟。人臉特征點檢測是許多人臉相關(guān)視覺任務(wù)的基本組成部分,被廣泛應(yīng)用于如人臉識別、表情分析、虛擬人臉重建等領(lǐng)域[1]。
傳統(tǒng)算法在環(huán)境受限條件下的人臉特征點檢測可以得到較準(zhǔn)確的結(jié)果,如主動外觀模型(AAM)[2]、約束局部模型(CLM)[3]等。該領(lǐng)域的挑戰(zhàn)是在非受限環(huán)境下的人臉特征點檢測,在非受限環(huán)境下,人臉會具有受限環(huán)境下所沒有的局部變化及全局變化。局部變化包括表情、遮擋、局部的高光或陰影等,這些局部變化使得一部分人臉特征點偏離正常位置,乃至于消失不見。全局變化包括面部的大姿態(tài)旋轉(zhuǎn)、圖片模糊失焦等,這些全局變化使得大部分人臉姿態(tài)點偏離正常位置。這2 個挑戰(zhàn)需要算法模型對人臉特征點的全局和局部分布有良好的表征,對形狀分布有足夠的魯棒性,對人臉的姿態(tài)朝向有所估計。
研究人員嘗試使用一些傳統(tǒng)的級聯(lián)回歸方法解決在非受限環(huán)境下人臉特征點檢測回歸任務(wù),這些方法可以歸納為級聯(lián)一系列弱回歸器以訓(xùn)練組合成1 個強回歸器。然而這些方法在較淺的級聯(lián)深度后其性能會達(dá)到飽和,精度難以再次提高。
隨著基于卷積神經(jīng)網(wǎng)絡(luò)的發(fā)展,在非受限環(huán)境下的人臉特征點檢測得到極大改善。現(xiàn)有基于卷積神經(jīng)網(wǎng)絡(luò)的方法主要分為基于坐標(biāo)回歸的方法和基于熱圖回歸的方法。基于熱圖回歸的方法通過級聯(lián)Hourglass 網(wǎng)絡(luò)[4]得到像素級的熱圖估計值,準(zhǔn)確率較高,但是由于級聯(lián)網(wǎng)絡(luò)的結(jié)構(gòu)和預(yù)測整個熱圖值,因此參數(shù)量較大且推理時間長。基于坐標(biāo)回歸的方法利用卷積神經(jīng)網(wǎng)絡(luò)直接回歸出特征點的坐標(biāo),參數(shù)量較少且推理時間短,實時性較好。特征點坐標(biāo)精確到像素,需要足夠的空間信息才能保證精度。而基于坐標(biāo)回歸的方法模型隨著網(wǎng)絡(luò)的加深和降采樣,在特征語義信息加深的同時也會丟失空間結(jié)構(gòu)信息,缺乏細(xì)粒度表征能力,精度會有所降低。
本文針對人臉特征點檢測坐標(biāo)回歸方法提出一種多層次自注意力網(wǎng)絡(luò)(HSN)模型,構(gòu)建一種基于自注意力機制的多層次特征融合模塊,實現(xiàn)網(wǎng)絡(luò)的跨層次特征融合,提升用于回歸特征的空間結(jié)構(gòu)信息,彌補細(xì)粒度表征能力不足。此外,設(shè)計一種多任務(wù)同時學(xué)習(xí)特征點檢測定位及人臉姿態(tài)角估計的訓(xùn)練方式,提升模型對人臉姿態(tài)朝向的表征,從而提升模型的準(zhǔn)確性。
1 相關(guān)研究
1.1 傳統(tǒng)的人臉特征點檢測方法
傳統(tǒng)人臉特征點檢測以傳統(tǒng)算法為主,通過多訓(xùn)練級聯(lián)回歸器來構(gòu)建算法。COOTES 等[2]提出AAM 算法,該算法根據(jù)人臉的整體外觀、形狀、紋理參數(shù)化建立模型,通過迭代搜索特征點位置,并應(yīng)用平均人臉修正結(jié)果,最大化圖像中局部區(qū)域的置信度以完成置信度檢測。CRISTINACCE 等[3]在AAM算法的基礎(chǔ)上,棄用全局紋理建模方法,利用一系列特征點周圍局部紋理約束模型,構(gòu)建CLM 算法[3]。DOLLAR 等[5]提出級聯(lián)姿態(tài)回歸器(CPR),通過級聯(lián)一系列回歸器實現(xiàn)預(yù)測值的不斷修正細(xì)化,以得到最終預(yù)測值。
1.2 基于深度學(xué)習(xí)的人臉特征點檢測方法
近年來,基于深度學(xué)習(xí)的人臉特征點檢測方法表現(xiàn)出了遠(yuǎn)優(yōu)于傳統(tǒng)算法的性能,大致可以分為基于坐標(biāo)回歸的方法與基于熱圖回歸的方法。基于坐標(biāo)回歸的方法使用卷積神經(jīng)網(wǎng)絡(luò)直接從圖片輸入中回歸出特征點坐標(biāo)值。SUN 等[6]提出一種三級級聯(lián)的卷積神經(jīng)網(wǎng)絡(luò),從粗到細(xì)地定位人臉特征點。GUO 等[7]基于MobileNet 結(jié)構(gòu)做進(jìn)一步的輕量縮減,提出一種可以在移動設(shè)備上也能實時運行的網(wǎng)絡(luò)結(jié)構(gòu),且針對不同的特殊數(shù)據(jù)類別自適應(yīng)地加權(quán)訓(xùn)練。FENG 等[8]針對面部特征點檢測這一特定任務(wù),設(shè)計一種WingLoss 損失函數(shù),使得損失函數(shù)在大誤差時的梯度為常數(shù),在小誤差時得到比L1 與L2 更大的誤差值。ZHANG 等[9]提出一種多任務(wù)學(xué)習(xí)框架,同時優(yōu)化人臉特征點定位及姿態(tài)、表情、性別等面部屬性分類。基于熱圖回歸的方法為每個特征點預(yù)測1張熱圖,得到每個像素位置的概率置信度值,然后從熱圖中估計得到坐標(biāo)值。受Hourglass 在人體姿態(tài)估計方面的啟發(fā),Hourglass 網(wǎng)絡(luò)成為很多業(yè)界使用熱圖回歸法的主干網(wǎng)絡(luò)。YANG 等[10]使用有監(jiān)督的面部變換歸一化人臉,然后使用Hourglass 回歸熱圖。DENG 等[11]提 出JMFA 網(wǎng) 絡(luò),通過堆 疊Hourglass 網(wǎng)絡(luò),在多視角人臉特征點檢測上達(dá)到較高的精度。文獻(xiàn)[12]提出LAB 網(wǎng)絡(luò),利用額外的邊界線描述人臉圖像的幾何結(jié)構(gòu),從而提升特征點檢測的準(zhǔn)確性。熱圖中背景像素會逐漸收斂于零值,而WingLoss 函數(shù)在零點不連續(xù),導(dǎo)致無法收斂。針對該問題,WANG 等[13]提出一種改進(jìn)的自適應(yīng)WingLoss 函數(shù),使其能適應(yīng)真實值熱圖不同的像素強度,當(dāng)損失函數(shù)在零值附近時接近于L2 Loss,因此可支持熱圖回歸訓(xùn)練。
1.3 卷積神經(jīng)網(wǎng)絡(luò)中的特征融合方法
卷積神經(jīng)網(wǎng)絡(luò)的底層特征包含大量的空間結(jié)構(gòu)信息而缺乏語義信息,隨著網(wǎng)絡(luò)的加深和降采樣,高層特征具備豐富的語義信息而丟失空間結(jié)構(gòu)信息。運用單獨的高層卷積網(wǎng)絡(luò)特征對于精細(xì)任務(wù)來說是不足的。學(xué)界也有一些工作探索在1 個卷積神經(jīng)網(wǎng)絡(luò)中運用不同卷積層的有效性,如特征金字塔網(wǎng)絡(luò)(FPN)通過融合低層次的高分辨率特征與上采樣后的高層次高語義特征得到不同分辨率的特征,以支持不同尺度的目標(biāo)檢測任務(wù)[14]。HARIHARAN 等[15]嘗試使用卷積神經(jīng)網(wǎng)絡(luò)中的所有特征,以提升網(wǎng)絡(luò)在定位任務(wù)中的精度。LONG 等[16]在分割任務(wù)中結(jié)合不同深度間更高層及更精細(xì)的特征。XIE 等[17]在邊緣檢測任務(wù)中設(shè)計1 個整體嵌套的網(wǎng)絡(luò)框架,網(wǎng)絡(luò)的旁路輸出被加到較底層的卷積層后,以提供深層監(jiān)督訓(xùn)練。
簡單級聯(lián)不同卷積層特征會增加大量的參數(shù)量,同時將較多中間卷積層相結(jié)合時不能捕捉層間的交互關(guān)系。受Transformer 網(wǎng)絡(luò)[18]中自注意力機制的啟發(fā),本文將每個網(wǎng)絡(luò)塊的特征視為不同的網(wǎng)絡(luò)特征提取器,并運用自注意力機制建模層與層之間的交互融合。
2 本文方法
本文所提基于多層次自注意力網(wǎng)絡(luò)HSN 的人臉特征點檢測算法的總體流程如圖1 所示。其中實線框為訓(xùn)練與測試時的通用流程與數(shù)據(jù),虛線框為僅在訓(xùn)練過程中所使用的流程及數(shù)據(jù)。在算法測試時流程分為數(shù)據(jù)預(yù)處理及HSN 模型計算2 個階段。對于輸入圖像,首先人臉識別后進(jìn)行歸一化處理。在模型訓(xùn)練階段,對于沒有人臉姿態(tài)角真值的數(shù)據(jù)集須額外計算1 個擬真值,并在數(shù)據(jù)增強后用于網(wǎng)絡(luò)訓(xùn)練。對于有遮擋、表情、局部高光或陰影等細(xì)分類的數(shù)據(jù)集,其分類真值將用于損失函數(shù)的計算。

圖1 基于多層次自注意力網(wǎng)絡(luò)的人臉特征點檢測算法流程Fig.1 Procedure of facial landmark detection algorithm based on hierarchical self-attention network
人臉特征點示意圖如圖2 所示。針對未提供人臉姿態(tài)角真值的數(shù)據(jù)集,本文提出計算1 個擬真值用于網(wǎng)絡(luò)訓(xùn)練,方法如下:將該數(shù)據(jù)集和訓(xùn)練集的所有正臉圖像經(jīng)由雙眼外側(cè)2 點旋轉(zhuǎn)至水平矯正后,選取如圖2 圓點所示的14 個點作為基準(zhǔn)點,統(tǒng)計訓(xùn)練集全部平均點作為該數(shù)據(jù)集的標(biāo)準(zhǔn)人臉。將人臉大致視為剛體,將每張圖像的14 個基準(zhǔn)點相對標(biāo)準(zhǔn)人臉計算其旋轉(zhuǎn)矩陣,然后計算3 個歐拉角作為該數(shù)據(jù)集的人臉姿態(tài)角擬真值。由于訓(xùn)練數(shù)據(jù)涉及坐標(biāo)及姿態(tài)角,因此本文數(shù)據(jù)增強僅使用了圖像翻轉(zhuǎn)方法。
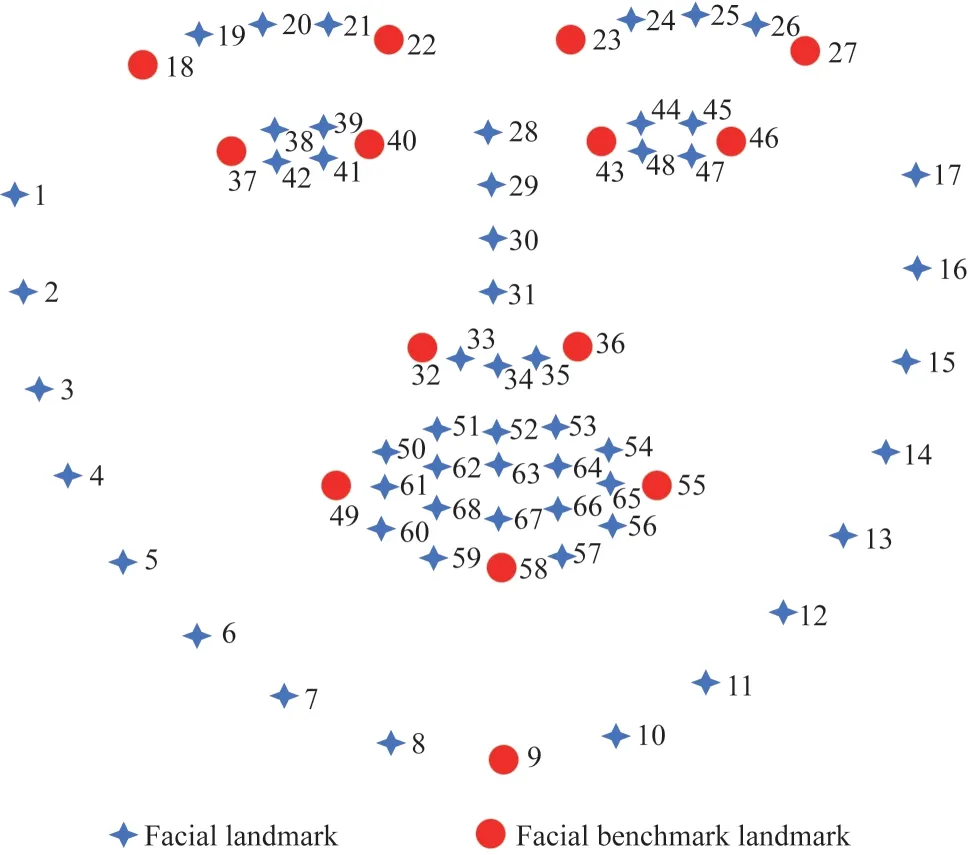
圖2 人臉特征點示意圖Fig.2 Schematic diagram of facial landmark
2.1 數(shù)據(jù)預(yù)處理
大多數(shù)現(xiàn)有人臉特征點檢測方法建立在人臉識別技術(shù)的基礎(chǔ)上,算法在經(jīng)人臉識別后的輸入圖像局部區(qū)域上檢測人臉特征點。部分?jǐn)?shù)據(jù)集提供人臉區(qū)域坐標(biāo)框或直接提供人臉區(qū)域局部圖像。針對未提供該部分?jǐn)?shù)據(jù)的數(shù)據(jù)集,本文直接采用MTCNN 算法[19]進(jìn)行人臉識別,在檢測人臉區(qū)域上繼續(xù)后處理。
2.2 多層次自注意力網(wǎng)絡(luò)
本文提到針對非受限環(huán)境下的人臉特征點檢測算法模型對全局形狀應(yīng)具備足夠的魯棒性,在局部分布上應(yīng)具備細(xì)粒度的表征能力,對人臉位姿朝向應(yīng)有所估計。針對以上問題,本文提出一種基于多層次自注意力的特征融合網(wǎng)絡(luò),網(wǎng)絡(luò)結(jié)構(gòu)如圖3 所示。輸入圖像經(jīng)由主干網(wǎng)絡(luò)、多層次自注意力特征融合模塊后輸出預(yù)測特征點坐標(biāo)及預(yù)測人臉位姿角。
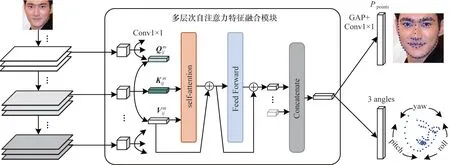
圖3 多層次自注意力網(wǎng)絡(luò)結(jié)構(gòu)Fig.3 Structure of hierarchical self-attention network
2.2.1 主干網(wǎng)絡(luò)
HSN 模型采用ResNet 50[20-21]作為主干網(wǎng)絡(luò),其結(jié)構(gòu)如圖4 所示,由卷積層、池化層及瓶頸卷積塊組成。主干網(wǎng)絡(luò)分為5 個階段來分層學(xué)習(xí)特征,每個階段之間采用步長為2×2 的池化層或卷積層進(jìn)行降采樣。第1 個階段由7×7 的卷積層、BN 層及ReLU激活函數(shù)組成。其他4 個階段均由連續(xù)的瓶頸卷積塊組成,每個瓶頸卷積塊由2 個用于升降維的1×1卷積核,1 個3×3 的卷積核、BN 層和ReLU 激活函數(shù)構(gòu)成。5 個階段的通道數(shù)設(shè)置為64、256、512、1 024和2 048。

圖4 主干網(wǎng)絡(luò)結(jié)構(gòu)Fig.4 Structure of backbone network
2.2.2 多層次自注意力特征融合模塊
現(xiàn)有基于坐標(biāo)回歸的方法多直接基于主干網(wǎng)絡(luò)頂層特征全局平均池化后回歸,雖然該特征因其共享特性具有全局形狀的魯棒性,但是丟失空間結(jié)構(gòu)信息,在局部細(xì)粒度方面表征不足,不足以描述局部細(xì)節(jié)的語義信息。這些方法忽略了中間層的激活,導(dǎo)致細(xì)粒度判別信息損失。本文將主干網(wǎng)絡(luò)層中每個階段的網(wǎng)絡(luò)塊都視為不同的特征提取器,將各個特征塊的激活視為不同特性的響應(yīng),并通過自注意力機制捕捉層間關(guān)系,以提升模型細(xì)粒度表征能力。
假定輸入圖像I,經(jīng)由主干網(wǎng)絡(luò)后第s階段輸出高度為h,寬度為w,通道數(shù)為c的特征Xs∈Rh×w×c。定義特征Xs中高度為i,寬度為j位置處的特征向量為網(wǎng)絡(luò)階段數(shù)為L,網(wǎng)絡(luò)在不同階段間經(jīng)過步長為2的下采樣,故Xs前t階段對應(yīng)位置的特征向 量以最后階段的輸出特征圖相對位置為準(zhǔn),組合m個階段對應(yīng)位置的對應(yīng)特征向量作為該位置的多層次特征向量維數(shù)為,f1×1為1×1 的卷積核及相應(yīng)的BN層,用于統(tǒng)一不同特征塊的通道數(shù)至則
本文所提的多層次自注意力特征融合模塊如圖3 所示。3 個1×1 的卷積核分別用于將輸入特征轉(zhuǎn)換成查詢向量、索引向量、內(nèi)容向量并組合為矩陣形式然后利用自注意力層對 多層次特征向量建模,計算查詢向量和索引向量間的內(nèi)積并歸一化作為相關(guān)系數(shù),經(jīng)Softmax 激活后加權(quán)內(nèi)容向量,獲得表征
輸出表征展平并經(jīng)過2 層前饋神經(jīng)網(wǎng)絡(luò)后連接得到最終輸出特征。自注意力層及前饋神經(jīng)網(wǎng)絡(luò)均有跳躍連接結(jié)構(gòu)。上述結(jié)構(gòu)在不同位置處共享權(quán)重,輸出特征經(jīng)由全局平均池化后連接輸出層。
2.2.3 損失函數(shù)
為優(yōu)化網(wǎng)絡(luò)對人臉整體朝向姿態(tài)的估計,以提升特征點定位的準(zhǔn)確性,本文網(wǎng)絡(luò)在輸出預(yù)測特征點坐標(biāo)的同時輸出預(yù)測人臉姿態(tài)角,并將其加入到損失函數(shù)中以優(yōu)化訓(xùn)練。損失函數(shù)由特征點坐標(biāo)的損失函數(shù)與位姿角的損失函數(shù)加權(quán)得到:
其中:N為每次迭代訓(xùn)練圖像數(shù);U為圖像細(xì)分類類別數(shù)量;ωu為各細(xì)分類權(quán)重,本文采用各類別圖像占比的倒數(shù)加權(quán),以增加模型對稀少數(shù)據(jù)的敏感性,即ωu=Nt/Nu,Nt為訓(xùn)練集圖像總數(shù),Nu為訓(xùn)練集第u類圖像總數(shù);Lθ和Ld分別為位姿角和特征點坐標(biāo)的損失函數(shù);α為平衡2 項損失函數(shù)的超參數(shù)。本文中位姿角損失函數(shù)Lθ定義如下:
其中:Δθz為人臉的3 個姿態(tài)角預(yù)測值與真值的差值,z∈{1,2,3}。
本文特征點損失函數(shù)Ld選用WingLoss[8]:
其中:P為預(yù)測特征點數(shù);為特征點p坐標(biāo)預(yù)測值與真值的L2 距離;σ,?為超參數(shù);?為保證曲線連續(xù)的常數(shù),
3 實驗結(jié)果與分析
為測試本文所提出方法的性能,采用人臉特征點檢測領(lǐng)域最常用的2 個數(shù)據(jù)集300W 數(shù)據(jù)集[22]以及WFLW 數(shù)據(jù)集[12]上進(jìn)行包括消融實驗在內(nèi)的一系列實驗。
3.1 數(shù)據(jù)集
300W數(shù)據(jù)集重新標(biāo)定了包括XM2VTS、FRGC Ver.2、LFPW、HELEN、AFW、iBUG 6 個人臉數(shù)據(jù)集的人臉特征點數(shù)據(jù),提供68 個人臉特征點坐標(biāo),在其分支數(shù)據(jù)集300W-LP 中提供人臉位姿角數(shù)據(jù)。本文遵照前人方法的實驗設(shè)置[12],取用來自LFPW、HELEN、AFW 數(shù)據(jù)集總共3 148 張圖像作為訓(xùn)練集,來自LFPW 和HELEN 的測試集以及iBUG 總共689 張圖像作為測試集圖像。測試圖像包含普通圖像及有挑戰(zhàn)圖像2 大類。由于300W 數(shù)據(jù)集不包含細(xì)分類數(shù)據(jù),因此損失函數(shù)中細(xì)分類權(quán)重統(tǒng)一為1。
WFLW 數(shù)據(jù)集包括7 500 張圖像的訓(xùn)練集及2 500 張圖像的測試集,提供98 個人臉特征點坐標(biāo)以及包括大姿態(tài)角、夸張表情、極端光照、化妝、遮擋、模糊6 項細(xì)分類數(shù)據(jù)。在本文方法中增加第7 類普通類,包含所有不在其他所有類中的數(shù)據(jù),以便細(xì)分類權(quán)重的計算。
3.2 實驗設(shè)置與測試指標(biāo)
本文模型的搭建與訓(xùn)練,數(shù)據(jù)集的測試均在PyTorch 框架下進(jìn)行。本文中特征融合模塊選擇融合最后3 個階段的特征,損失函數(shù)平衡項α取值為1,特征點損失函數(shù)WingLoss中σ取值為10,?取值為2。本文訓(xùn)練與測試時Batch_size設(shè)置為96,使用AdamW 優(yōu)化器優(yōu)化訓(xùn)練,學(xué)習(xí)率設(shè)置遵照5×10-7~1×10-5的余弦退火策略,模型訓(xùn)練迭代次數(shù)Epoch設(shè)為300。
為方便與現(xiàn)有方法進(jìn)行對比,本文使用標(biāo)準(zhǔn)化平均誤差(NME,計算中用NNME)以及錯誤率(FR,計算中用FFR)衡量性能。本文的NME 指標(biāo)按照雙眼外眼角間距離進(jìn)行歸一化。NME 和FR 如式(5)和式(6)所示:
其中:N為測試圖像數(shù);P為預(yù)測特征點數(shù);Yp和分別為人臉特征點坐標(biāo)的真值以及預(yù)測值;d為歸一化因子;NNMEn為具體每張測試圖像的NME 值。
3.3 與現(xiàn)有方法的比較
在300W 數(shù)據(jù)集上測試本文所提方法HSN 的性能,并與現(xiàn)有方法進(jìn)行對比,實驗結(jié)果如表1 所示,加粗表 示最優(yōu)數(shù)據(jù)。表1 中AnchorFace[23]、Wing、PFLD 為基于 坐標(biāo)回 歸的方 法,LAB[12]、MobileFAN[24]、HRNetV2[25]為基于熱圖回歸的方法,LDDMM-Face[26]是基于形狀模型的其他方法。從表1 可以看出,本文所提的HSN 模型在基于坐標(biāo)回歸方法中表現(xiàn)出優(yōu)異的性能,NME 降至3.23%。在有挑戰(zhàn)圖像大類中,本文模型的NME 降至5.12%,驗證HSN 模型補充坐標(biāo)回歸方法特征細(xì)粒度表征不足的假設(shè)。在與HRNetV2 等熱圖回歸方法、LDDMM-Face 等形狀模型對比時,本文模型在各指標(biāo)對比上也具有一定的優(yōu)越性。
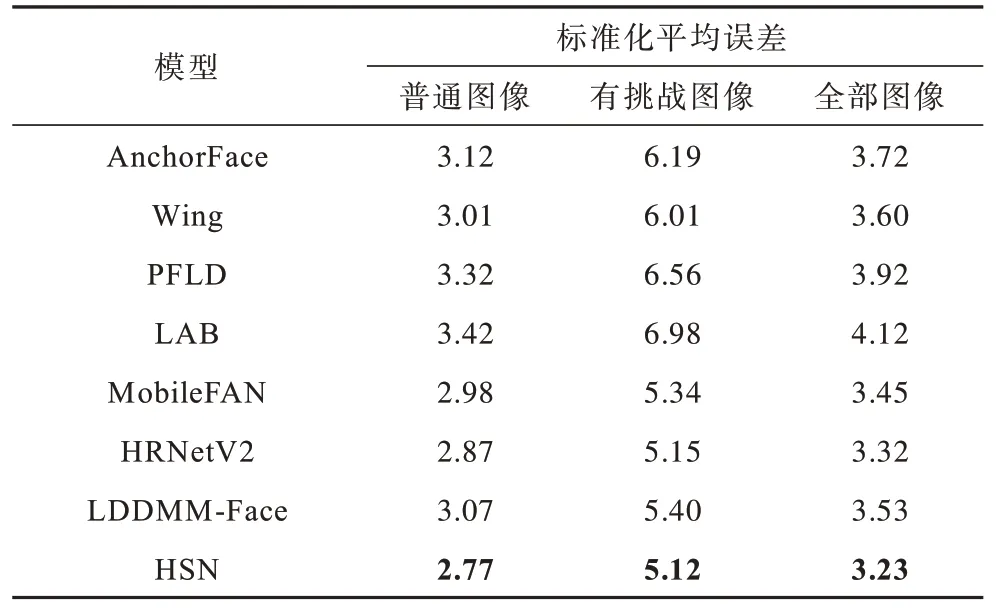
表1 在300W 數(shù)據(jù)集上不同模型的標(biāo)準(zhǔn)化平均誤差對比Table 1 Normalized mean error comparison among different models on the 300W dataset %
同樣地,在WFLW 數(shù)據(jù)集上本文模型與現(xiàn)有模型進(jìn)行一系列對比,結(jié)果如表2 所示。從表2 可以看出,本文模型HSN 在NME 及FR 2 個指標(biāo)上均取得更高精度,分別為4.55%和3.56%。在各個困難細(xì)分類中,本文模型在大姿態(tài)角及模糊2 類上的NME 分別降到了7.76%和5.17%,驗證本文所提的加入姿態(tài)角預(yù)測輔助訓(xùn)練以及跨層融合方法的有效性和先進(jìn)性。
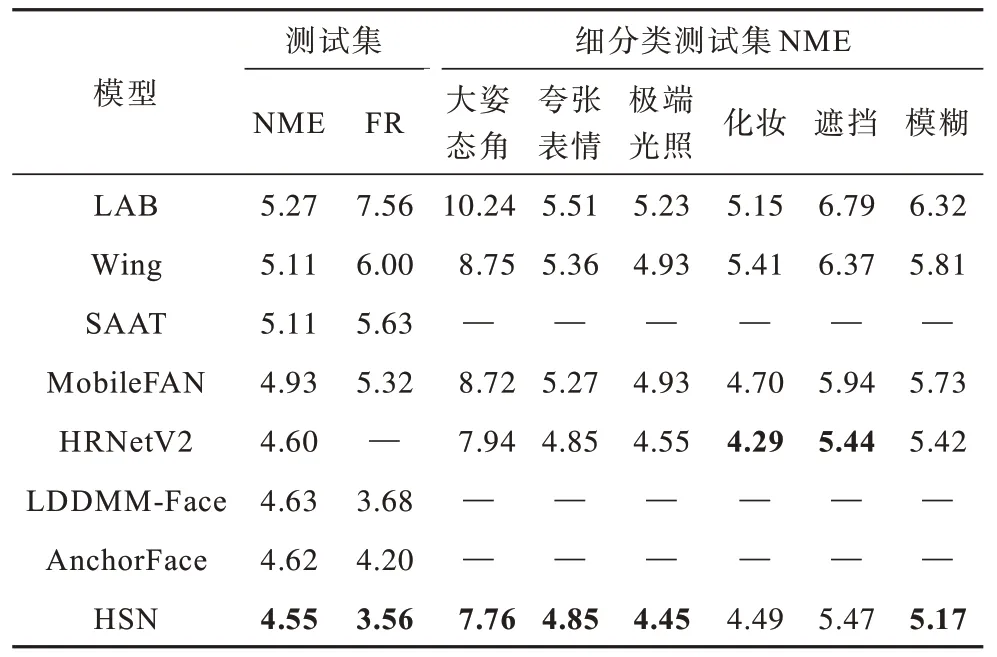
表2 在WFLW 數(shù)據(jù)集上不同模型的評價指標(biāo)Table 2 Evaluation indicators among different models on the WFLW dataset %
3.4 消融實驗
為進(jìn)一步驗證HSN 的有效性,本文在WFLW 數(shù)據(jù)集上進(jìn)行一系列消融實驗。
本文基于提升模型對人臉整體姿態(tài)朝向的表征能力來提高特征點定位精度的假設(shè),設(shè)計多任務(wù)學(xué)習(xí)特征點定位及人臉姿態(tài)角的訓(xùn)練方式,并對細(xì)分類的困難項增加了相應(yīng)的權(quán)重。損失函數(shù)消融實驗結(jié)果如表3 所示。該部分消融實驗所用的網(wǎng)絡(luò)均為僅使用主干網(wǎng)絡(luò)的基準(zhǔn)網(wǎng)絡(luò),不加權(quán)且僅預(yù)測特征點坐標(biāo)作為基線對比。從表3 可以看出,分別添加位姿角預(yù)測損失項(Lθ)和細(xì)分類權(quán)重(ωu)后,HSN在特征點定位的NME 及FR 指標(biāo)均得到有效優(yōu)化,NME 分別下 降0.21 和0.09 個百分 點,F(xiàn)R 分別下 降0.87 及0.44 個百分點。在兩者綜合作用下,NME 和FR 分別下降0.26 和1.29 個百分點。

表3 損失函數(shù)消融實驗結(jié)果Table 3 Results of loss function ablation experiment %
為驗證該特征融合模塊的有效性,本文選取主干網(wǎng)絡(luò)作為基準(zhǔn),融合實驗結(jié)果如表4 所示。首先與最常用的特征融合方法拼接法(Concatenate)與加和法(Addition)進(jìn)行對比,同樣是在融合第4 個和第5 個階段特征的情況下,本文方法能有效改善NME 值,加和法的性能不增反降,而相較于拼接法,本文方法在NME 和FR 2 個指標(biāo)上分別下降0.11 和0.55 個百分點。而后對特征融合的階段數(shù)進(jìn)行實驗,其中融合第3~5 個階段的模型表現(xiàn)出最優(yōu)性能。融合第2~5 個階段的實驗可能是由于第2 個階段的特征缺乏足夠的語義信息而給融合后的特征帶來無效噪聲,導(dǎo)致性能略遜于第3~5 個階段的特征融合網(wǎng)絡(luò)。

表4 特征融合消融實驗結(jié)果Table 4 Results of feature fusion ablation experiment %
3.5 可視化結(jié)果與討論
為進(jìn)一步直觀展示HSN 的有效性,本文將HSN和其他方法在WFLW 數(shù)據(jù)集中的不同困難細(xì)分類測試集上的測試結(jié)果可視化,結(jié)果如圖5 所示。
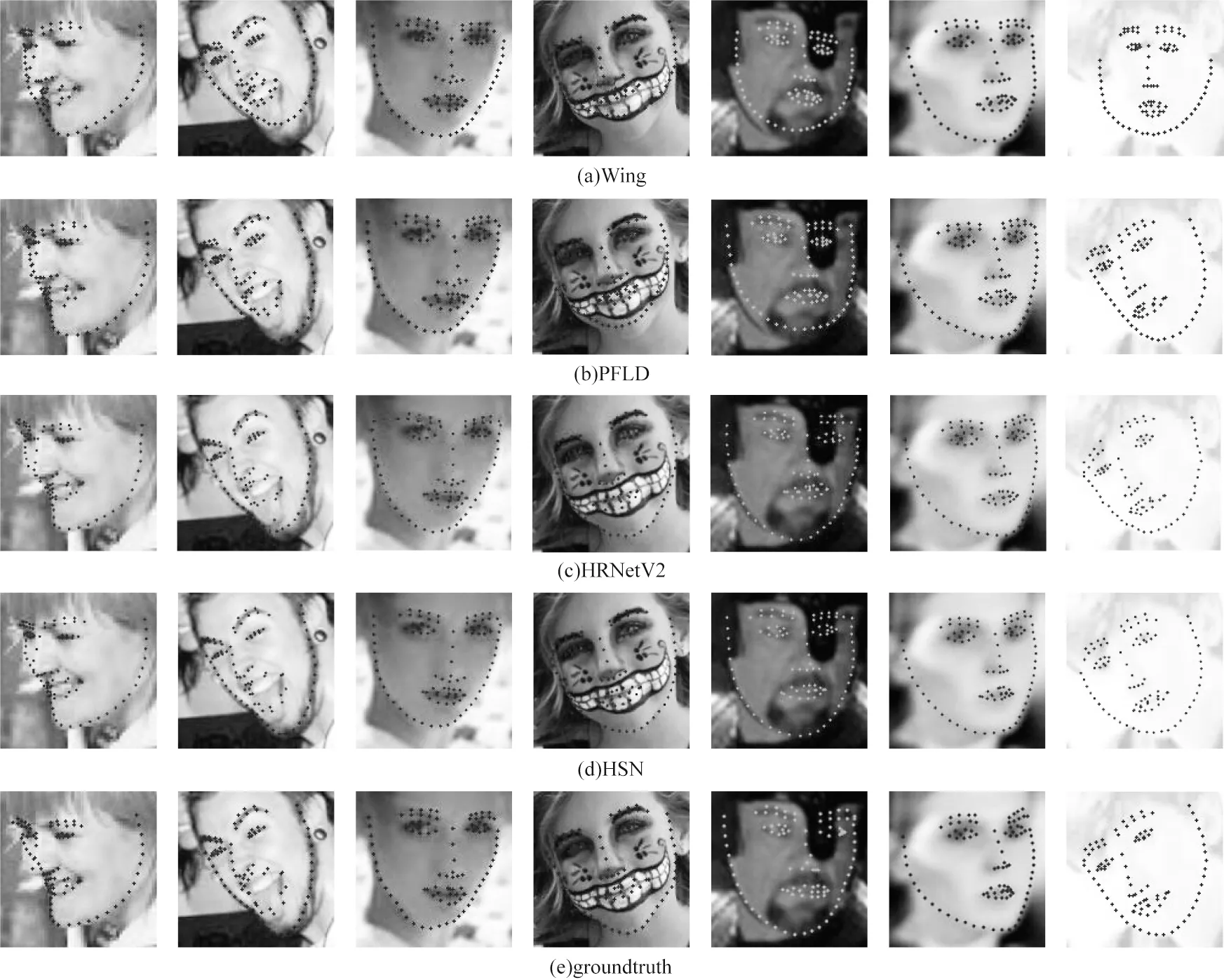
圖5 不同算法的人臉特征點檢測結(jié)果可視化對比Fig.5 Visual results comparison of facial landmark detection using different algorithms
其中,Wing 和PFLD 是基于坐標(biāo)回歸方法,HRNetV2 是基于熱圖回歸方法。從圖5 可以看出,Wing、PFLD 等坐標(biāo)回歸方法雖然保持整體形狀的魯棒性,但是在細(xì)節(jié)位置仍有較大偏差。Wing 僅能預(yù)測大致形狀,在大姿態(tài)角偏轉(zhuǎn)等各種復(fù)雜情況下預(yù)測結(jié)果均不理想。PFLD 對各個圖中人臉整體外輪廓變化等全局變化以及眉毛走向、瞇眼程度等局部變化反饋不到位。HRNetV2 等基于熱圖回歸方法采用熱圖逐點預(yù)測保證了各點的精度,但丟失全局整體形狀的魯棒性,如圖5 中面部外輪廓均存在一定幅度的扭曲,第2 列夸張表情示意圖中將舌尖預(yù)測為嘴部特征點,第7 列模糊2 示意圖中各器官扭曲等。因此,本文方法既保證整體形狀的連續(xù)性,對大姿態(tài)偏轉(zhuǎn)有良好的反饋性能,又能捕捉到各點局部細(xì)節(jié),保證局部各點預(yù)測精度。
本文方法也存在一定的局限性。本文所提的多層次特征融合模塊在優(yōu)化特征點定位精度的同時,使得推理時間從原本的13 ms 增加到17 ms。該模塊使用Transformer 框架中的自注意力機制,當(dāng)前各種芯片對該框架相關(guān)模型優(yōu)化不足,使得在實際應(yīng)用中所需推理時間可能進(jìn)一步增加,這一點有待相關(guān)算子開發(fā)優(yōu)化。此外,本文所提的多任務(wù)同時學(xué)習(xí)人臉特征點定位與姿態(tài)角的學(xué)習(xí)方式依賴數(shù)據(jù)集有角度上的多樣性及姿態(tài)角數(shù)據(jù),而大部分?jǐn)?shù)據(jù)集缺乏該部分?jǐn)?shù)據(jù)。雖然本文提出當(dāng)數(shù)據(jù)集缺乏姿態(tài)角數(shù)據(jù)時的替代姿態(tài)計算算法,但此算法包含將平均人臉作為基準(zhǔn)正臉和將人臉視為剛體的假設(shè),在夸張表情等人臉數(shù)據(jù)與平均人臉相差較大時計算出的姿態(tài)角擬真值可能與實際值相差較大,影響模型擬合從而影響精度進(jìn)一步提升,這一點有待包含姿態(tài)角數(shù)據(jù)的數(shù)據(jù)集擴充或姿態(tài)計算算法的進(jìn)一步優(yōu)化。
4 結(jié)束語
針對人臉特征點檢測的基于坐標(biāo)回歸方法特征缺乏局部結(jié)構(gòu)的細(xì)粒度表征能力、精度較低等問題,本文提出一種基于自注意力特征融合模塊的網(wǎng)絡(luò)算法。采用自注意力機制實現(xiàn)多層次特征融合,以實現(xiàn)不同階段具有不同空間結(jié)構(gòu)語義信息的特征層間交互,使得回歸特征在全局形狀具有魯棒性的同時優(yōu)化局部細(xì)粒度表征能力。提出一種多任務(wù)學(xué)習(xí)特征點檢測定位及人臉姿態(tài)角估計的訓(xùn)練方式,提升算法對人臉整體姿態(tài)朝向的估計以提升特征點定位精度。下一步將優(yōu)化姿態(tài)計算算法以適配更多數(shù)據(jù)集,研究網(wǎng)絡(luò)的跨數(shù)據(jù)集泛化能力,提升網(wǎng)絡(luò)的泛用性。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
