一種分層注意力機制與用戶動態偏好融合的序列推薦算法
2024-03-05 01:41:06閆猛猛汪海濤賀建峰
小型微型計算機系統 2024年3期
閆猛猛,汪海濤,賀建峰,陳 星
(昆明理工大學 信息工程與自動化學院,昆明 650500)
0 引 言
隨著移動設備和互聯網技術的發展,推薦系統已經成為人工智能領域最流行和最重要的應用之一.其在幫助用戶緩解信息過載方面發揮著重要作用.在傳統推薦領域中,大多數推薦系統通過靜態方式對用戶項目關系進行建模.但在現實世界中,用戶不僅存在較為穩定的長期偏好,還存在隨時間發生動態變化的近期偏好.與傳統推薦系統不同的是,序列推薦系統通過用戶歷史行為的時間戳對項目進行排序,并專注于序列模式挖掘,以預測用戶可能感興趣的下一項目.
在序列推薦系統中,個性化馬爾可夫鏈分解(Factorizing Personalized Markov Chains,FPMC)首次嘗試將用戶長期偏好和近期偏好結合用于學習用戶表示[1].近年來,越來越多的深度學習技術被引入到序列推薦任務中,并大幅度提高了推薦性能.例如,GRU4Rec[2]應用循環神經網絡(Recurrent Neural Network,RNN)對序列信息進行建模,RNN可以通過循環結構更好的提取序列中項目之間的關系[3].為了建模更好地保持長期依賴性并緩解梯度消失與梯度爆炸的問題,RNN的變體,尤其是雙向長短期記憶網絡(Bidirectional Long Short-Term Memory Network,BiLSTM)[4]和門控循環單元(Gated Recurrent Unit,GRU)也應運而生.然而,RNN認為時間依賴性是單調變化的[5],這代表著當前時間步的輸入比之前時間步的輸入更為重要,這對用戶近期偏好的建模有很大的負面影響.因此,當利用RNN學習用戶表示時,考慮RNN中隱藏狀態之間的局部依賴模式是十分必要的.此外,RNN和卷積神經網絡(Convolutional Neural Network,CNN)的各種組合已被廣泛用于自然語言處理和計算機視覺等領域[6-8],但現階段對其在序列推薦領域的應用較少.最近,自然語言處理領域中的TextCNN[9]在短文本分類任務中表現出色.受此啟發,本文使用TextCNN提取RNN隱藏狀態之間的局部序列模式作為用戶近期偏好.
在上述研究中,項目嵌入方法往往占有重要的地位.已有方法往往僅基于單一項目信息來學習項目表示.對于一個具體項目來說,單一項目信息含義十分有限,不足以全面表示一個完整的項目,這可能就會導致推薦系統的推薦準確率降低.項目的每種信息都包含其余項目信息不具備的某些特征.例如,一部電影包含電影標題、電影類別兩種信息,一張圖片包含圖片標題、圖片顏色和圖片紋理3種信息.本文統一采用項目標題信息和項目類別信息來表示一個項目.此外在同一項目中,不同的項目信息具有不同的重要性.例如,一個項目的標題信息包含了豐富的語義,那么該項目的標題特征權重應該高于類別特征權重.在同一項目標題信息或項目類別信息中,不同單詞對項目信息的最終表示也具有不同的重要性.因此本文設計了一種層次化的注意力機制用于學習項目準確的表示.
Transformer完全依賴于自注意力機制,在文本序列建模方面取得了較為先進的性能[10].在自然語言處理領域中,對傳統自注意力機制與相對位置信息結合的探索已經比較常見,例如XLNET[11]、T5[12]和Transformer-XL[13]等先進方法.上述3種方法都是在Google[14]的研究基礎上進行的某種改進,比如XLNET即是Google所提相對位置編碼方法的完全展開式,并將其中的相對位置設置為兩個可以訓練的向量.一些現有的序列推薦算法將自注意力機制引入到序列推薦領域中,并取得了較好的實驗結果[15,16].但現有的自注意力機制只關注輸入序列中元素之間的相關性,忽略了序列中元素的相對位置信息,不能完整的捕獲序列模式.目前一種常見的解決方法是將位置編碼添加到其輸入中,例如SASRec[17]中的自注意力機制,然而這并沒有考慮相對位置信息對推薦性能的影響.基于此,本文在Google所提方法的基礎上對傳統自注意力機制進行改進,以使其適用于序列推薦領域.具體體現在改進相對位置距離的計算方式和嵌入方法.
綜上所述,本文提出一種基于分層注意力機制與用戶動態偏好融合的序列推薦算法,命名為HASRec.本文的主要貢獻有以下幾點:
1)通過分層注意力機制從不同項目信息中學習項目的統一表示.和以往引入輔助信息的推薦算法不同的是,分層注意力機制中的SAR、詞級注意力機制和特征融合模塊能夠有效的選擇重要的單詞和項目信息.
2)在利用RNN對用戶長期偏好建模的基礎上,引入TextCNN對RNN隱藏狀態之間的用戶近期偏好進行建模.同時提出一種有效的融合策略對用戶的長期和近期偏好進行動態融合,生成更為準確的用戶整體偏好.
3)改進傳統的自注意力機制,緩解其無法對序列中元素的相對位置信息進行建模的問題,命名為相對位置信息增強的自注意力機制(Self-Attention Mechanism Enhanced By Relative Position Information,SAR).
4)在兩個真實公開的數據集上進行大量實驗,實驗結果表明提出的HASRec算法在評估指標HR@N與NDCG@N上較其他方法都有提升.
1 相關工作
序列推薦算法的早期工作主要依賴于馬爾科夫鏈(Markov Chain,MC)和因式分解模型[1,18].例如,Shani等人[18]使用基于馬爾可夫決策過程(Markov Decision Processes,MDPs)的方法對序列模式進行建模.Kabbur 等人[19]提出的FISM直接對項目矩陣進行矩陣分解(Matrix Factorization,MF)操作,因此無法學習得到明確的用戶表示.由于深度神經網絡的飛速發展,近年來研究人員提出了許多基于RNN的方法來對用戶交互序列中的序列模式進行建模.例如,Hidasi等人[20]通過引入一種新的排名損失來改進GRU4Rec中的梯度消失問題,命名為GRU4Rec++.Quadrana等人[21]開發了一種基于RNN的分級推薦模型,捕獲用戶在當前會話中的近期偏好.Zhao等人[22]使用具有兩層隱含層的BiLSTM網絡學習用戶的長期偏好.盡管基于RNN的方法很有效,但它們嚴重依賴于過去的隱藏狀態.
除RNN外,CNN和注意力機制也被用來建模序列之間的序列模式.Yan等人[23]提出一種可擴展的2D卷積神經網絡,通過捕獲用戶近期訪問序列來學習用戶的近期偏好.Tang等人[24]提出了一種卷積序列嵌入模型Caser,對用戶項目交互序列分別使用垂直和水平卷積操作,以學習用戶行為的局部特征.Yuan等人[25]提出了一種基于CNN的生成模型NextItRec,以改進Caser對序列長期依賴的學習.Gehring等人[26]使用一種完全基于CNN的架構,固定捕獲每個卷積核大小內的位置信息,這種架構已經被證明可以結合相對位置信息再次提升性能.Li等人[27]提出了一種基于注意力機制的推薦模型NARM,通過引入注意力機制對GRU4Rec進行擴展,提高了GRU對長期依賴的建模能力.Kang等人[17]受到Transformer的啟發,提出一種完全基于自注意力機制的序列推薦算法SASRec,其將可學習的位置嵌入與原始輸入結合作為算法的輸入.在SASRec的基礎上,Li等人[28]提出一種基于時間間隔感知的自注意力機制TiSASRec,對序列中項目的絕對位置以及項目之間的時間間隔進行建模.Ma等人[29]提出一種層次化的門控網絡HGN,該網絡捕獲項目過渡關系和用戶長期偏好,并使用門控機制從用戶歷史行為中識別重要項目及其潛在特征.為了捕獲用戶偏好隨時間的變化,Rossi等人[30]提出了TGN通用歸納框架,該框架能夠在表示為事件序列的連續時間動態圖上運行.Kumar等人[31]提出了JODIE模型,其使用一種投影算子來學習和預測用戶和項目的未來嵌入.Zhang等人[32]發現JODIE等模型并不能生成充分的時間嵌入,因此提出了一種基于常微分方程來模擬信息傳播的CoPE模型來解決上述問題.
2 HASRec算法
HASRec由項目嵌入層、偏好學習層和點擊預測層3部分組成.模型的整體框架如圖1所示.

圖1 模型整體框架圖Fig.1 Overall framework of the model
2.1 預備知識
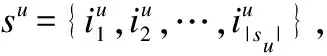
2.1.1 傳統自注意力機制
提取用戶交互序列中最近的n個交互作為傳統自注意力機制的輸入.類似于之前的方法[17],對輸入序列s={i1,i2,…,in}使用一個可學習的項目嵌入矩陣G∈|su|×d,將項目序列嵌入為E={e1,e2,…,en},其中ei∈d,輸出為O={o1,o2,…,on},其計算過程如下:
Q=EWq,K=EWk,V=EWv
(1)
(2)
O=softmax(A)V
(3)
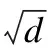
2.1.2 SAR

(4)
(5)

圖2 SAR的計算過程Fig.2 Calculation process of SAR
(6)
(7)
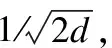
2.2 項目嵌入
在項目嵌入層中,本文使用了兩種不同的項目信息,分別是項目標題和項目類別.
2.2.1 標題特征提取
標題特征提取模塊旨在從項目標題信息中學習項目的表示.標題特征提取模塊由3部分組成,分別是標題嵌入、多頭SAR和詞級注意力機制.設標題的單詞序列為{w1,w2,…,wL}.
標題嵌入:使用查詢操作和一個可學習的單詞嵌入表MI∈V×d,將標題單詞序列嵌入為L×d,其中L為標題中單詞的個數.
多頭SAR:能夠很好的提取輸入本身的內容信息和相對位置信息.由于標題中的一個詞可能與多個詞都有內在聯系,所以使用多頭SAR來學習標題的上下文表示,計算過程如下:
(8)
(9)
(10)
(11)
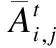

(12)
(13)
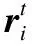
(14)
2.2.2 類別特征提取

2.2.3 特征融合

(15)
(16)

(17)
2.3 用戶偏好學習
2.3.1 長期偏好學習
長期偏好學習用于從用戶的歷史交互序列中學習用戶的長期穩定偏好.如圖1所示,其由2部分組成:BiLSTM和加性注意力機制.取用戶u交互序列中最近的n個交互作為用戶長期序列,表示為su={i1,i2,…,in},將其輸入到項目嵌入層中,最終輸出{v1,v2,…,vn}.
BiLSTM:可以順序提取序列上下文信息來學習用戶的長期偏好.其每個時刻輸出的隱藏狀態都由當前時刻的輸入vt、前一時刻的隱藏狀態ht-1和前一時刻的記憶單元ct-1所決定.在第t個時間步,單向LSTM的計算過程如下:
ft=sigmoid(Wfht-1+Ufvt+bf)
(18)
it=sigmoid(Wiht-1+Uivt+bi)
(19)
(20)
(21)
ηt=sigmoid(Woht-1+Uovt+bo)
(22)
ht=ηttanh(ct)
(23)

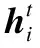
(24)


(25)
(26)
其中,ht為t時刻輸入的項目it的表示,Wl和bl為加性注意力機制中可訓練的參數.用戶u的最終長期偏好lu是注意力權重加權的項目上下文表示的總和,計算公式為:
(27)
2.3.2 近期偏好學習
將BiLSTM最后k個時刻的輸出作為用戶近期交互序列,表示為{hn-k+1,hn-k,…,hn}.對于BiLSTM來說,當前的項目或者隱藏狀態總會比前一個更重要,這極大的損害了用戶近期偏好的建模.近期偏好學習旨在通過融合加性注意力機制的TextCNN對BiLSTM隱藏狀態之間的近期序列進行建模.
TextCNN:將用戶近期交互序列拼接為一個k×d的向量矩陣H,其中hi∈d為矩陣H的第i行.將矩陣H作為TextCNN的輸入,h×d是池化層用來提取用戶局部特征的濾波器,其中h為濾波器的高度,卷積操作可表示為:
(28)
其中,f是ReLU激活函數,b為偏置項,yi表示使用高度為h、寬度為d的濾波器對矩陣H中指定區域hi:i+h-1進行卷積操作后生成的特征.使用該過濾器對矩陣H中所有區域進行卷積操作,最終表示為y=[y1,y2,…,yk-h+1],其中y∈k-h+1.然后進行最大池化操作得到濾波器高度為h時的卷積結果

加性注意力機制:為了將TextCNN中不同高度濾波器提取的不同特征融合成一個具有統一表示的組合特征,引入加性注意力機制來對其進行處理:
(29)
(30)

(31)
2.3.3 偏好動態融合
對于用戶u來說,用戶的長期偏好和近期偏好在不同的上下文中具有不同的重要程度.偏好動態融合模塊旨在通過動態融合用戶長期偏好和近期偏好生成用戶的整體偏好,具體融合過程可表述如下:
λu=sigmoid(Wuqu+Wllu+Wggu+bu)
(32)
Fu=(1-λu)lu+λugu
(33)
其中,Wu、Wl和Wg為可訓練參數,lu為用戶的長期偏好,gu為用戶的近期偏好,bu為偏置項,λu負責控制用戶近期偏好所占權重.最終輸出的用戶整體偏好為Fu.
2.4 點擊預測
點擊預測層用于預測用戶點擊每個候選項目的概率.首先,將候選項目輸入到項目嵌入層生成候選項目的表示rcd.其次,將用戶u的交互序列輸入到HASRec中,生成該用戶的整體偏好Fu.候選項目被點擊的概率由Fu和rcd的內積計算得到,即:
(34)
2.5 算法訓練與優化
對算法進行訓練時,損失函數使用負對數似然函數,計算過程如下:
(35)
其中,z為項目集合中項目的個數,pi=1表示正樣本,即用戶已經與該項目進行了交互,pi=0表示負樣本,即用戶與該項目尚沒有發生交互.
3 實 驗
3.1 實驗設置
3.1.1 數據集
本文在兩個公開數據集MovieLens-1M和Amazon-Book上進行實驗,其評分區間均為1~5,評分被視為隱式反饋.MovieLens-1M數據集包含6040個用戶對3952部電影的1000209條評分記錄.Amazon-Book數據集是亞馬遜數據集中最大的子數據集,其包含8026324個用戶對2935525個商品的22507155條評分記錄.
為保證實驗可靠性,對兩個數據集進行預處理操作.首先篩選出項目元數據中缺少標題或類別信息的項目,過濾掉與這些項目產生交互的歷史序列.其次,丟棄其中交互少于5次的用戶和項目.
3.1.2 對比方法
·BPR[34]:一種基于貝葉斯個性化排序的推薦方法,它通過優化不同用戶交互序列之間的成對偏好來學習用戶和項目的潛在表示.
·FPMC[1]:是序列推薦中最經典的方法之一,它通過整合MF與MC對用戶序列進行建模并捕獲用戶的一般興趣.
·GRU4Rec[2]:一種基于RNN實現會話推薦的方法,本文將每個用戶的交互序列視為一個會話.
·Caser[24]:通過CNN捕獲多級別的用戶行為序列模式,同時使用水平與垂直卷積核來捕獲多級別的用戶行為序列模式.
·BERT4Rec[35]:采用深度雙向自注意力機制,通過完形填空任務依次模擬兩個方向的用戶行為.
·FDSA[36]:利用自注意力機制分別對項目粒度和特征粒度的用戶偏好進行建模,特征主要分為類別特征和文本特征,在本文中將文本設置為項目的標題.
·JODIE[31]:使用一種耦合RNN模型從一系列時間交互中學習和預測用戶和項目的嵌入.
·LSSA[37]:通過分層注意力機制捕獲用戶的長期偏好和近期偏好,以此預測用戶的下一步行為.
3.1.3 實驗細節
本文使用作者原始論文中提供的Caser和BERT4Rec代碼,并基于公開資源實現FPMC和GRU4Rec.對于HASRec等其他算法,在PyTorch中統一實現.HASRec使用Adam優化器優化,標題特征提取模塊和用戶偏好學習模塊中的注意力頭數設置為2,學習率設置為10-4.
3.1.4 評價指標
采用leave-one-out評估方法評價推薦性能.具體來說,將用戶交互序列的最后一個項目作為測試集,將倒數第2個項目作為驗證集,其余的項目作為訓練集.與之前的工作類似[34],根據項目的流行度抽取100個沒有與用戶發生過交互的項目,并與測試集中的基本事實項目配對,任務是對這101個項目進行排序,最后選取前10個項目作為該用戶的推薦列表.為了驗證推薦算法的準確率與性能,使用以下2個評價指標:
HR@10:命中率,是常用的衡量召回率的指標,用來表示Top-10推薦列表中是否包含正樣本,強調算法的準確性.計算公式如下:
(36)
其中,|u|表示用戶集合中的用戶數量,hits(i)表示推薦列表中是否存在第i個用戶訪問的值,滿足條件時為1,否則為0.
NDCG@10:歸一化折損累計增益,在命中率的基礎上考慮位置因素,在Top-10推薦列表中位置越靠近末端值越小,不包含正樣本的情況下,其值為零.rank表示命中項目在推薦列表中的位置,計算公式如下:
(37)
3.2 實驗結果及分析
3.2.1 整體性能分析
在本節中,為證明HASRec算法的推薦效果,將其和各個對比方法之間的整體性能作比較.根據表1的實驗結果可以得出以下結論:
1)BPR是目前較為優秀的非序列推薦算法,然而在兩個數據集上的任意序列推薦算法的性能都較BPR好,證明了捕獲用戶交互序列模式的重要性.
2)序列推薦算法中,GRU4Rec、Caser和BERT4Rec等算法的推薦性能較FPMC好,充分證明了深度神經網絡可以學習比MF等方法更好的項目和用戶表示,同時證明了神經網絡能夠更好的對用戶交互序列建模.
3)FDSA在兩個不同數據集上表現出較GRU4Rec等算法更為優秀的推薦性能,這得益于FDSA使用了類別和標題特征來豐富項目和用戶的表示.同時FDSA的推薦性能較HASRec差,這意味著對序列中元素相對位置信息進行建模的SAR優于FDSA中使用的自注意力機制.
4)LSSA較JODIE具有更好的性能,主要原因是LSSA同時考慮用戶的長期和近期偏好,并加入自注意力機制來捕獲用戶交互序列中的有效信息,這使得其推薦性能優于JODIE和其余對比方法,充分顯示了融合用戶長期和近期偏好的有效性.
5)HASRec在兩個數據集上的推薦性能優于LSSA和其它對比方法,這得益于分層注意力機制可以捕獲更高層次的復雜非線性特征,并利用TextCNN更為充分的對用戶交互序列進行建模,以及SAR對序列中元素相對位置信息的捕獲.
3.2.2 項目嵌入層的有效性分析
本節在MovieLens-1M數據集上對項目嵌入層中的各組件的有效性進行分析.首先根據不同的組合生成幾種HASRec的變體:HASRec-1對算法中整個項目嵌入層進行遮掩操作,僅運用與LSSA類似的嵌入方法;HASRec-2僅包含項目嵌入層中的類別特征提取模塊;HASRec-3僅包含項目嵌入層中的標題特征提取模塊.其次,為驗證本文所提算法中項目標題信息和類別信息的有效性,在項目嵌入層新增評分信息用于學習新的項目嵌入,命名為HASRec-4.在HASRec-4中,首先將評分信息嵌入為低維稠密向量,又由于評分信息一般為1~5之間的具體數字,因此不需要使用太過復雜的神經網絡對其進行學習,本文使用多層感知機(Multilayer Perceptron,MLP)學習項目中評分信息的表示,最后在特征融合模塊中使用注意力機制對3種不同特征進行融合.實驗結果如表2所示.

表2 各組件有效性分析Table 2 Analysis of the effectiveness of each component
根據表2可以看出:HASRec-1的推薦性能較LSSA有所提高,證明了偏好學習層中長期偏好學習、近期偏好學習和偏好動態融合模塊的有效性.根據HASRec-2和HASRec-3的實驗結果可以看出,只帶有標題信息的算法較只帶有類別信息的算法推薦性能更好,這表明項目的標題信息對用戶接下來的行為具有重要影響.此外,僅使用單一項目信息的HASRec-2和HASRec-3較使用普通嵌入方法的HASRec-1性能更低,表明單一信息不足以學習項目的準確表示,這也與本文算法的原始假設相符.HASRec獲得了最佳的推薦性能,證明了項目嵌入層的有效性.當嵌入層新增評分信息后,HASRec-4的推薦性能較其余變體都有所提高,但較HASRec有所下降,這說明評分信息的加入在一定程度上能夠提高算法的性能,但由于評分信息只含有1~5之間的整數,大量的輸入評分信息特征對已經使用了標題信息和類別信息的嵌入層產生了微小的擾動,這就會導致算法的整體性能略微降低.
3.2.3 偏好動態融合分析
為分析用戶偏好學習層中偏好動態融合模塊的有效性,表3展示了在MovieLens-1M與Amazon-Book數據集中參數λ對算法推薦性能的影響.λ為動態偏好融合模塊中決定近期偏好所占權重的參數.當參數λ為0時,表示僅考慮用戶的長期偏好,當參數λ為1時,表示僅考慮用戶的近期偏好,當參數λ為固定值0.5時,表示默認用戶長期和近期偏好重要程度相同.

表3 參數λ對推薦性能的影響Table 3 Influence of parameter λ on recommendation performance
根據表3可以觀察到:只考慮用戶的近期偏好總是比只考慮用戶長期偏好的算法性能更好.除此之外,只考慮用戶的近期偏好甚至比將用戶兩個方面的偏好進行簡單的融合更有優勢.從實驗結果可以看出,分別考慮用戶的長期和近期偏好并使用動態融合模塊對其進行動態融合是必要且有效的.
3.2.4 注意力機制與特征融合模塊的有效性分析
在MovieLens-1M數據集上分別針對項目嵌入層中的SAR、詞級注意力機制和特征融合模塊進行消融實驗.
由圖3的實驗結果可以看出:HASRec-Ex1移除SAR后算法的推薦性能下降,證明了SAR能夠充分對項目標題和類別信息進行特征提取.HASRec-Ex2僅保留詞級注意力機制,它可以有效提高推薦性能,這得益于不同的單詞通常具有獨特的含義,證明了詞級注意力機制對學習準確的項目表示是有幫助的.其次,HASRec-Ex3僅保留特征融合模塊,由實驗結果可以看出由于不同的項目信息具有不同的特性,所以對項目不同信息的重要性進行分析是有必要的.最后,HASRec具有最優的推薦性能,可以看出項目嵌入層中的多層注意力機制作用各不相同,缺一不可.

圖3 注意力機制與特征融合的有效性分析Fig.3 Effectiveness analysis of attention mechanism and feature fusion
3.2.5 算法效率分析
本節在MovieLens-1M數據集上對不同算法的效率進行分析,統計算法單個Epoch的平均訓練時間,實驗的顯卡為GTX-1650Ti,實驗結果如表4所示.

表4 不同算法的效率分析Table 4 Efficiency analysis of different algorithms(s)
根據表4可以觀察到,與注重用戶長期和近期偏好的LSSA和以效率著稱的Caser相比,HASRec的平均訓練時間明顯更長,這是因為HASRec采用多種神經網絡對用戶交互序列中更復雜的項目關系進行了提取,從而影響了算法的運行效率.
3.2.6 超參數分析
在本節中,主要分析近期偏好學習網絡中的參數k對算法推薦性能的影響.為動態調整參數k,設定k的最小值為1,最大值為7,步長為1.在MovieLens-1M數據集上進行實驗,實驗結果如圖4所示.

圖4 參數k對推薦性能的影響Fig.4 Influence of parameter k on recommendation performance
從圖4中可以看出,HASRec的推薦性能隨著參數k的變化而變化,具體表現為先上升后下降.當k值為5時,HASRec的推薦效果最佳,當k值逐漸偏離5時,其推薦性能總體上表現為逐級遞減.k值過小時,HASRec無法獲得最優推薦性能,不能充分捕獲歷史交互中的有效信息.k值過大時,則會由于引入噪聲造成推薦性能的下降.
4 結束語
本文提出一種基于分層注意力與用戶動態偏好的序列推薦算法.首先對傳統的自注意力機制進行改進,將相對位置信息融入到自注意力機制中,并將其應用到本文提出算法的項目嵌入層中.項目嵌入層通過標題和類別信息學習項目嵌入,同時為了學習準確的用戶整體偏好,在分別學習用戶長期和近期偏好的基礎上對其進行動態融合.本文在兩個真實數據集上進行了大量實驗,證明了本文所提算法的有效性.在未來,將考慮在保證在同等推薦性能的條件下,嘗試優化模型的運行效率.
猜你喜歡
文苑(2018年21期)2018-11-09 01:23:06
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國衛生(2015年9期)2015-11-10 03:11:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
