基于深度學習的霧霾天氣下的車牌號碼識別方法
2024-03-05 08:15:34楊云王靜姜佳樂
液晶與顯示 2024年2期
楊云, 王靜, 姜佳樂
(陜西科技大學 電子信息與人工智能學院, 陜西 西安 710021)
1 引言
隨著我國經(jīng)濟社會的發(fā)展,車輛數(shù)目迅速增長,給交通管理帶來了巨大的挑戰(zhàn)。車輛的車牌號碼識別現(xiàn)已成為智慧交通系統(tǒng)的重要一環(huán),在緩解交通壓力問題上起著至關(guān)重要的作用。車牌識別技術(shù)主要應(yīng)用于城市交通、高速公路、停車場及小區(qū)出入口等。隨著機動車數(shù)量的持續(xù)增長,公路運輸負荷越來越重,與交通有關(guān)的治安和刑事案件逐年上升。為了有效遏制城市內(nèi)車輛亂停、闖紅燈、逆行等違章行為,城市內(nèi)各個路口大力安裝檢測系統(tǒng),而車牌識別系統(tǒng)是其重要組成部分,可應(yīng)用于交通違法行為的檢測,更加方便道路管理以及更好地滿足刑偵、治安等業(yè)務(wù)的需求。我國高速公路發(fā)展迅速,將車牌識別技術(shù)應(yīng)用于高速公路便于進行收費管理,同時便于交警對違反交規(guī)的車輛進行監(jiān)控。停車場和小區(qū)出入口的車輛管理僅靠人工記錄是非常困難的,車牌識別技術(shù)的應(yīng)用可以節(jié)省人力、提高效率。
目前的車牌檢測、識別模型有著較好的效果,但應(yīng)用在霧霾、雨雪等場景下往往會出現(xiàn)大量漏檢。因此研究復(fù)雜場景下的車牌識別十分必要。
目前已有的車牌檢測方法主要包括傳統(tǒng)的識別方法和基于深度學習的識別方法。傳統(tǒng)的識別方法流程主要包括:對彩色圖像進行灰度化、濾波處理、邊緣檢測[1]、車牌的粗定位、車牌細定位、字符分割以及字符識別。通過人工提取車牌特征實現(xiàn)車牌識別的方法受環(huán)境影響大,且識別準確率低[2]。相比于傳統(tǒng)的檢測方法,基于深度學習的算法提高了車牌識別的魯棒性,不僅在停車場、高速公路等簡單場景下有良好的檢測效果,而且在車牌傾斜、圖像模糊等復(fù)雜情況下也有更加穩(wěn)定的魯棒性。目前目標檢測主要以單階段目標檢測和雙階段目標檢測為主。雙階段目標檢測先對目標進行定位,然后進行識別,因此檢測精度較為準確,但很大程度上降低了檢測速度。單階段目標檢測將目標定位和識別過程相統(tǒng)一,更適合對目標進行實時檢測[3]。
郝達慧等[4]用YOLOv5網(wǎng)絡(luò)進行車牌檢測,并設(shè)計LPCRNet網(wǎng)絡(luò)對車牌字符進行識別,車牌檢測準確率達98.6%,字符識別準確率達88.9%。楊杰等[5]提出了霧霾環(huán)境下基于Zynq的實時車牌識別系統(tǒng),系統(tǒng)著重強調(diào)實時性。田智源等[6]提出了一種基于自適應(yīng)去霧算法的霧霾天氣下的車牌識別系統(tǒng),提出一種新型的車牌檢測和車牌識別模型且達到了較高的車牌識別率。毛曉波等[7]提出了基于PSO-RBF神經(jīng)網(wǎng)絡(luò)的霧霾天氣下的車牌識別算法,使用改進的暗原色先驗去霧算法對車牌圖像進行預(yù)處理,然后對預(yù)處理后的圖像進行車牌定位、字符分割和字符識別。
本文采用雙階段目標檢測算法,提出了一種霧霾天氣下的車牌號碼識別方法。使用圖像去霧算法對圖像進行預(yù)處理。設(shè)計了車牌檢測網(wǎng)絡(luò)ACG_YOLOv5s,引入CBAM注意力機制、自適應(yīng)特征融合網(wǎng)絡(luò)ASFF模塊以及Ghost卷積模塊來搭建檢測網(wǎng)絡(luò)。最后用LPRNet網(wǎng)絡(luò)對檢測到的車牌進行識別,從而實現(xiàn)霧霾天氣下的車牌號碼識別。
2 車牌識別流程總體設(shè)計
車牌檢測和識別流程如圖1所示。

圖1 車牌識別流程總體設(shè)計Fig.1 Overall design of license plate recognition
首先使用AOD-Net算法對圖像進行去霧操作,利用去霧操作可獲取更多的車牌特征信息,得到相較于原始車牌圖像更清晰的圖像。然后使用基于YOLOv5改進后的ACG_YOLOv5s網(wǎng)絡(luò)作為車牌檢測網(wǎng)絡(luò)。最后將ACG_YOLOv5s網(wǎng)絡(luò)檢測出來的車牌輸入到車牌識別網(wǎng)絡(luò)中,對車牌號碼進行識別。
3 霧天圖片處理
AOD-Net(All-One Dehazing Network)算法基于大氣散射模型[8],是一種基于CNN的去霧網(wǎng)絡(luò)模型[9]。AOD-Net模型在無霧的條件下仍具有較好的性能,適合應(yīng)用于車牌號碼識別。
在霧霾天氣下拍攝的圖片質(zhì)量會因霧霾的存在而受到很大的影響,在很大程度上降低了目標檢測的準確率。霧霾天氣下,拍攝設(shè)備接收到的光源主要來自光源經(jīng)過空氣中懸浮粒子發(fā)生散射形成的大氣光以及反射光衰減后到達拍攝設(shè)備的光。霧天成像的數(shù)學模型[10]如式(1)所示:
式中:I(x)表示霧霾圖片,J(x)表示清晰無霧圖片,A表示全球大氣的光照強度,t(x) 表示透射率,透射率可以表示為式(2):
式中:β表示大氣散射率,d(x)為拍攝目標到傳感器的距離。透射率越小意味著霧霾越大,1-t(x)值也會更大,大氣光照進入到拍攝設(shè)備的光線就越強。
由式(1)可得,清晰無霧圖片J(x)的計算公式如式(3)所示:
AOD-Net算法的模型如圖2所示,AOD-Net包括K值估計模塊和復(fù)原圖像模塊(清晰圖像生成模塊)兩部分。
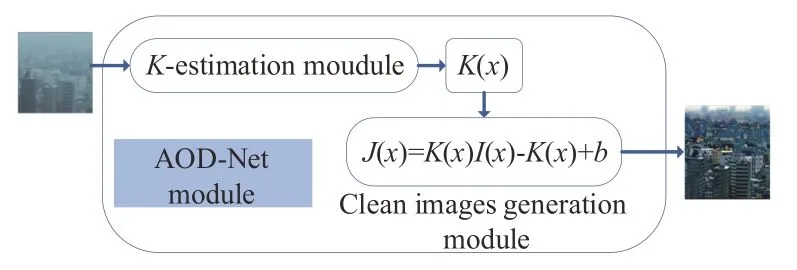
圖2 AOD-Net模型Fig.2 AOD-Net model
AOD-Net將有霧圖像輸入到K值估計模塊中。K值估計模塊通過一系列卷積和拼接操作來提取圖像中的特征信息進而得到變量K(x),然后復(fù)原圖像模塊可利用K(x)得到無霧圖像。
對式(3)進行變形得到:
式中,b是一個常量。聯(lián)立式(3)和式(4),可得K(x)的值為:
從式(5)可以得出,K(x)與輸入的有霧圖像I(x)、大氣光照強度A和透射率t(x)有關(guān),K(x)隨著輸入的有霧圖像的變化而變化。AOD-Net算法采用對大氣的光照強度A和透射率t(x)的聯(lián)合估計,即將其統(tǒng)一為K(x)變量,通過最小化無霧圖像和模型的輸出結(jié)果J(x)之間的誤差而訓練模型。
K值估計模塊網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示。網(wǎng)絡(luò)由五層卷積層和三層連接層構(gòu)成,采用了多尺度的特征融合方式。卷積層的作用是為了提取圖像特征,影響卷積層輸出結(jié)果的因素有卷積核大小、卷積核個數(shù)、步幅和填充。其中步幅是卷積核滑動的像素個數(shù)。卷積核會按照一定的規(guī)律在特征圖上滑動,最后對卷積核的值和特征圖對應(yīng)位置上的像素值相乘相加再疊加偏置項得到特征圖的輸出。連接層是將多個特征圖在通道維度上進行拼接。第一層連接層融合了Conv1層和Conv2層特征,將第一層卷積和第二層卷積的輸出作為第三層卷積的輸入。第二層連接層融合了Conv2層和Conv3層特征,將第二層卷積和第三層卷積的輸出作為第四層卷積的輸入。第三層連接層融合了Conv1層、Conv2層、Conv3層、Conv4層特征,即將前四層卷積的輸出作為第五層卷積的輸入。最后將拼接結(jié)果通過Conv5卷積層來估計K值。利用三層連接層將不同卷積層的特征信息進行融合,減少了在卷積過程中的特征信息損失。該神經(jīng)網(wǎng)絡(luò)的5層卷積層卷積核大小分別為1×1、3×3、5×5、7×7、3×3,5層網(wǎng)絡(luò)中都各有3個卷積核,因此AOD-Net也是一個輕量級網(wǎng)絡(luò)。
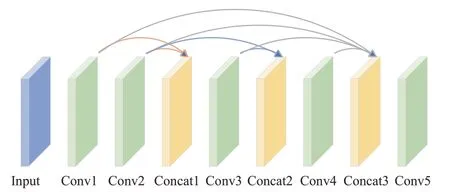
圖3 K值估計模型Fig.3 K-value estimation model
復(fù)原圖像模塊將K值作為自適應(yīng)參數(shù)由霧霾圖像估計清晰圖像。利用估計得到的K(x),再結(jié)合輸入霧霾圖像I(x)和常量b,可根據(jù)式(4)計算出去霧后的圖像J(x)。
本文首先用AOD-Net算法對車牌圖片進行預(yù)處理,抑制霧霾對車牌識別的影響。去除霧霾效果如圖4所示。從圖4可以看出,AOD-Net算法抑制霧霾效果顯著。去霧后的圖像,便于車牌的檢測和識別。

圖4 AOD-Net模型的去霧效果對比Fig.4 Comparison of AOD-Net model dehazing effect
4 車牌檢測網(wǎng)絡(luò)ACG_YOLOv5s
4.1 YOLOv5結(jié)構(gòu)基本原理
YOLOv5有YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x五個版本[11],這幾個模型的結(jié)構(gòu)基本相同,不同的是模型的深度和寬度,即在網(wǎng)絡(luò)的同一位置,卷積核的個數(shù)不同以及卷積層的數(shù)量不同。這5個版本的模型大小依次遞增,YOLOv5相比于YOLOv3等具有模型小的特點,適合嵌入式設(shè)備使用。
YOLOv5包含輸入端、骨干網(wǎng)絡(luò)Backbone、頸部Neck層和輸出層4大模塊[12],其網(wǎng)絡(luò)結(jié)構(gòu)如圖5所示。

圖5 YOLOv5網(wǎng)絡(luò)結(jié)構(gòu)Fig.5 YOLOv5 network structure
YOLOv5網(wǎng)絡(luò)輸入640×640的RGB圖像,如果原圖像尺寸不是640×640,則通過縮放將其尺寸變成640×640之后再輸入網(wǎng)絡(luò)。
YOLOv5主干網(wǎng)絡(luò)包括Focus模塊、CBL結(jié)構(gòu)、C3結(jié)構(gòu)、SPP結(jié)構(gòu)。YOLOv5中圖片通過Focus結(jié)構(gòu)會將輸入圖片的尺寸縮減1/2,通道擴充為4倍。例如輸入圖片的大小為3×608×608,經(jīng)過切片操作[13]后,得到12×304×304的特征圖。CBL結(jié)構(gòu)由卷積、批量歸一化和激活函數(shù)組成。C3層包含CBL結(jié)構(gòu)和殘差結(jié)構(gòu),能夠記錄梯度變化,增強網(wǎng)絡(luò)學習能力。SPP是空間金字塔池化層,該模塊先通過一個卷積模塊將通道數(shù)減半,然后分別做卷積核分別為5、9、13的最大池化,將3次最大池化的結(jié)果與未進行池化操作的特征進行融合。
YOLOv5網(wǎng)絡(luò)中Neck層用于特征融合。隨著網(wǎng)絡(luò)深度的加深,所得特征圖的特征信息變強,目標檢測效果更好,但是減弱了目標的位置信息,容易損失小目標的信息。YOLOv5采用特征金字塔(FPN)和路徑聚合網(wǎng)絡(luò)(PAN)結(jié)構(gòu)將特征進行多尺度融合,加強了對小目標的檢測。FPN以上采樣的方式將深層的特征信息傳遞融合到淺層,PAN結(jié)構(gòu)以下采樣的方式將淺層信息傳遞融合到深層,使不同尺寸的特征圖都包含強語義信息和強位置信息。
Head層是預(yù)測輸出部分,主要負責對骨干網(wǎng)絡(luò)提取的特征圖進行多尺度目標檢測。
4.2 融合注意力機制
注意力機制的核心思想是強調(diào)特征圖中的重要信息,在深度學習目標檢測領(lǐng)域效果顯著,在提高模型性能的同時也在一定程度上降低了計算量。
混合注意力機制CBAM[14](Convolutional Block Attention Module)采用將空間和通道相結(jié)合的方式,相比于只關(guān)注通道的SEnet(Squeeze-and-Excitation Networks)取得了更好的效果,其結(jié)構(gòu)如圖6所示。空間和通道相結(jié)合使目標檢測能力在通道和空間維度上得到提升。對于網(wǎng)絡(luò)中某層輸入特征圖F,先根據(jù)原特征圖計算通道注意力向量MC(F),輸入特征圖F與其相乘可得中間特征圖F',再由F'計算空間注意力向量MS(F'),MS(F')與F'相乘,得到CBAM輸出結(jié)果F″,如式(6)~(7)所示:

圖6 混合注意力機制Fig.6 Mixed attention mechanism
通道注意力模塊結(jié)構(gòu)如圖7所示。對于網(wǎng)絡(luò)結(jié)構(gòu)中某一層特征圖F(設(shè)其結(jié)構(gòu)為H×W×C),分別對其進行平均池化和最大池化,得到平均池化特征圖(1×1×C)和最大池化特征圖(1×1×C),減少了單一的池化操作對特征信息的影響。所得兩個特征圖通過一個共享網(wǎng)絡(luò)(Shared MLP)得到兩部分結(jié)果,將這兩部分結(jié)果相加并通過Sigmoid函數(shù)可得通道注意力向量MC(F),計算如式(8)所示:

圖7 通道注意力模塊Fig.7 Channel attention module
空間注意力模塊更關(guān)注位置信息,其結(jié)構(gòu)如圖8所示。

圖8 空間注意力模塊Fig.8 Spatial attention module
將網(wǎng)絡(luò)中某一特征圖F'(設(shè)其結(jié)構(gòu)為H×W×C)從空間維度上分別進行平均池化和最大池化,得到兩部分結(jié)構(gòu)為H×W×1的特征圖,然后拼接兩部分特征圖并進行一次7×7卷積操作,最后將結(jié)果送入Sigmoid函數(shù)可得空間注意力向量MS(F'),計算公式如式(9)所示:
針對YOLOv5的3層預(yù)測輸出部分,網(wǎng)絡(luò)淺層輸出的特征圖有較大的尺寸適合檢測小目標,因車牌圖像(94×24)相較于輸入圖片(640×640)尺寸較小,通過多次實驗發(fā)現(xiàn),將CBAM加入到淺層預(yù)測輸出層之前,可以加強網(wǎng)絡(luò)在訓練過程中對關(guān)鍵特征的提取,抑制不重要的特征信息,達到提高檢測目標精度的目的。CBAM融合到原始YOLOv5網(wǎng)絡(luò)的位置如圖9所示。

圖9 融入CBAM后部分網(wǎng)絡(luò)結(jié)構(gòu)Fig.9 Part of the network structure after integration into CBAM
4.3 ASFF替換PANet結(jié)構(gòu)
卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)中的淺層特征關(guān)注的主要是目標的位置信息,經(jīng)過不斷卷積所得到的頂層特征更加關(guān)注語義信息,為了提高目標檢測效能就需平衡不同層級的特征圖信息。YOLOv5在頸部特征融合網(wǎng)絡(luò)中采用了PANet結(jié)構(gòu),PANet采用雙向融合的方式雖可以豐富特征層的語義信息但賦予了不同層的特征圖相同的權(quán)重。在車牌識別中,車牌圖像形狀類似,尺寸不會有太大的差異,因此對于淺層網(wǎng)絡(luò)中尺寸小的特征圖,由于預(yù)測的是較大尺寸的目標,所以應(yīng)賦予其較小的權(quán)重,PANet結(jié)構(gòu)不是很好的選擇。
自適應(yīng)空間特征融合[15](Adaptively Spatial Feature Fusion,ASFF)結(jié)構(gòu)如圖10所示。ASFF結(jié)構(gòu)的核心思想是自適應(yīng)地學習各尺度特征融合的空間權(quán)重,通過自適應(yīng)學習到的權(quán)重可對網(wǎng)絡(luò)賦予不同特征層不同比重的權(quán)值,從而突出重要特征信息,且當某層特征圖匹配某個目標時不會忽視其他特征圖的信息,解決了不同層級的特征圖之間特征著重點不一的問題。

圖10 ASFF網(wǎng)絡(luò)結(jié)構(gòu)Fig.10 ASFF network structure
圖10中x1、x2、x3分別是來自YOLOv5網(wǎng)絡(luò)的Head層預(yù)測輸出部分的3個特征層,xm→n表示xm經(jīng)過特征縮放以后生成與xn層相同尺寸的特征圖。以ASFF-3為例,該層得到新的特征如圖10所示,x1、x2、x3層的特征圖分別與來自3個特征層上通過訓練得到的權(quán)重參數(shù)α3、β3、γ3相乘,再將相乘結(jié)果求和即可得ASFF-3層的融合特征圖。融合公式如式(10)所示:
由于采用相加的方式,所以要求特征縮放以后的特征圖尺寸和通道數(shù)都要相同,就需要用到1×1卷積調(diào)整通道數(shù)。表示l層所求特征圖(i,j)位置處的特征表示從m級調(diào)整到n級所得特征圖中映射位置(i,j)處的特征向量表示映射到l層網(wǎng)絡(luò)自主訓練得到的權(quán)重。計算如式(11)所示:
在YOLOv5網(wǎng)絡(luò)中,3層檢測層所包含的語義信息側(cè)重點不同。淺層檢測層更容易識別小目標,所以對于目標較小的車牌圖像,淺層檢測層應(yīng)賦其較大的權(quán)重,以降低小目標的漏檢率。因此本文在YOLOv5網(wǎng)絡(luò)PANet結(jié)構(gòu)之后引入ASFF模塊,加強對小目標的檢測。
4.4 Ghost卷積替換
Ghost卷積[16]模塊與傳統(tǒng)卷積不同,其結(jié)構(gòu)如圖11所示。首先對輸入特征圖進行少量傳統(tǒng)卷積操作得到中間特征圖,然后對中間特征圖進行線性變化運算得到Ghost特征圖,最后拼接中間特征圖以及線性變化運算所得Ghost特征圖得到最終的結(jié)果。Ghost卷積與傳統(tǒng)卷積相比,采用將傳統(tǒng)卷積和線性變化操作結(jié)合的方式,所需計算參數(shù)量明顯降低;而傳統(tǒng)卷積操作是對輸入特征圖所有通道進行卷積操作,需要計算大量的參數(shù)。

圖11 Ghost卷積Fig.11 Ghost convolution
在不考慮偏置項的情況下,設(shè)使用傳統(tǒng)卷積所需的網(wǎng)絡(luò)參數(shù)為p1,使用Ghost卷積所需的網(wǎng)絡(luò)參數(shù)為p2,計算公式如式(12)和式(13):
其中:n表示傳統(tǒng)卷積卷積核個數(shù)即輸出特征圖通道數(shù),c表示輸入特征圖通道數(shù),k表示傳統(tǒng)卷積卷積核大小,d表示線性操作卷積核大小,s?c。
兩者參數(shù)量之比如式(14)所示:
設(shè)使用傳統(tǒng)卷積浮點型計算量為F1,使用Ghost卷積的浮點型計算量為F2,計算公式如式(15)~(16)所示:
兩者浮點型計算量之比如式(17)所示:
其中,h'和w'分別表示原始特征圖的高和寬,其它含義同上。當k與d大小相等時,通過式(14)和式(17)計算得出,Ghost卷積與傳統(tǒng)卷積相比,所需參數(shù)量和計算量均為傳統(tǒng)卷積的1/s。
本文用Ghost卷積模塊替換原YOLOv5網(wǎng)絡(luò)中所有普通卷積模塊,在保持模型效果的同時減少了模型的參數(shù)。
5 車牌識別網(wǎng)絡(luò)LPRNet
LPRNet(License Plate Recognition Network)用于車牌號碼識別,是第一個沒有使用RNN(Recurrent Neural Networks)的輕量級網(wǎng)絡(luò)[17],支持識別變長字符車牌,在光線暗、視角差、強光等復(fù)雜情況下有較好的魯棒性。LPRNet網(wǎng)絡(luò)模型小且高效,適合部署到嵌入式設(shè)備上。
在車牌傾斜角度大、雨雪天氣、強光等特殊環(huán)境下,車牌識別成為一項復(fù)雜而重要的任務(wù),所以一個強大的車牌識別系統(tǒng)應(yīng)能夠在不同的環(huán)境下有較好的適應(yīng)性。早期的車牌識別過程包含字符分割和字符識別兩個階段。字符分割包括投影分割法、平均分割法等,它以二值化圖像作為輸入,因此分割質(zhì)量易受圖像噪聲、模糊等的影響。而LPRNet在識別車牌時采用端到端的識別方法,在免于對車牌圖像進行分割的同時減輕了網(wǎng)絡(luò)訓練過程中數(shù)據(jù)標注的工作量,極大提高了訓練效率。
LPNNet整體架構(gòu)是CNN(Convolutional Neural Network,CNN)+CTC Loss[18],骨干網(wǎng)絡(luò)以RGB圖像作為輸入。為了利用局部字符的上下文信息,使用寬卷積(1×13的卷積核)取代了基于LSTM(Long Short-Term Memory)的RNN(Recurrent Neural Networks,RNN)網(wǎng)絡(luò)。網(wǎng)絡(luò)最終輸出字符序列因網(wǎng)絡(luò)的輸出編碼和車牌字符長度存在不相等的情況,而以往將輸出編碼和字符長度進行對齊可能會導致模型無法收斂,因此采用CTC Loss(Connectionist Temporal Classification Loss),解決了輸入和輸出序列未對齊的問題,避免了對車牌圖像進行分割而進行端到端的訓練。
6 實驗
6.1 實驗平臺
在實驗中,ACG_YOLOv5s網(wǎng)絡(luò)訓練、LPRNet網(wǎng)絡(luò)訓練環(huán)境是Ubuntu20.04操作系統(tǒng)、python 3.8編程語言,使用Pytorch深度學習框架,顯卡型號為NVIDIA RTX A4000。兩部分實驗部分參數(shù)設(shè)置如表1所示。

表1 網(wǎng)絡(luò)訓練部分參數(shù)設(shè)置Tab.1 Parameters setting in the network training section
6.2 數(shù)據(jù)準備
CCPD數(shù)據(jù)集主要采集于合肥市,包含的車牌圖片中車輛省份主要為皖,所拍攝的圖片涉及雨天、模糊、雪天、傾斜等復(fù)雜情況。
本文YOLOv5網(wǎng)絡(luò)實驗數(shù)據(jù)集包括兩部分。一部分來源于CCPD2019數(shù)據(jù)集中的CCPD-weather。CCPD-weather是在雨、雪、霧天氣的情況下拍攝的,其部分圖片如圖12所示,選取其中的5 999張。另一部分是通過在網(wǎng)上搜尋到各個不同省份的帶有背景的車牌圖片,并利用Python的第三方庫pillow對該部分數(shù)據(jù)進行霧霾增強,效果如圖13所示。這部分數(shù)據(jù)共13 857張。CCPD數(shù)據(jù)集可根據(jù)其文件命名規(guī)則得到對應(yīng)的標簽。對于沒有標簽的數(shù)據(jù),利用labelmg對圖片進行標注,生成xml文件,然后用Python腳本將xml文件轉(zhuǎn)化成txt文件。

圖12 CCPD-Weather數(shù)據(jù)集Fig.12 CCPD-Weather dataset

圖13 霧霾增強前后的圖像對比Fig.13 Comparison of the images before and after haze enhancement
LPRNet部分的數(shù)據(jù)是根據(jù)CCPD命名規(guī)則將車牌圖片在原始帶有背景的圖片上裁剪出來,同時根據(jù)命名規(guī)則將圖片名轉(zhuǎn)換成車牌字符,除安徽省外其余省份的圖片通過在網(wǎng)上搜尋得到,共搜集到36 715張,同樣也對該部分數(shù)據(jù)進行了霧霾增強。
兩部分實驗都將數(shù)據(jù)按8∶1∶1劃分為訓練集、驗證集和測試集。
6.3 網(wǎng)絡(luò)模型評價指標
本文對網(wǎng)絡(luò)模型的評價指標主要包含精確率(Precision,P)、召回率(recall,R)、各個類別平均精確率(AP)的平均值(mean Average Precision,mAP)。計算公式如式(18)~(20)所示:
其中:TP表示真實值為正例且預(yù)測為正例的樣本數(shù)量,F(xiàn)N表示真實值為正例且預(yù)測為負例的樣本數(shù)量,F(xiàn)P表示實際負例預(yù)測為正例的數(shù)量,AP表示平均準確率,N為總類別數(shù)。mAP由單類別精確率AP求和后再求均值得到。
6.4 實驗結(jié)果及性能分析
在車牌檢測網(wǎng)絡(luò)訓練完成后,會生成results.csv來保存訓練過程中的數(shù)據(jù)。利用Origin軟件對數(shù)據(jù)進行可視化展示,精確率、召回率、IOU閾值為0.5的平均精準度與訓練輪次的關(guān)系如圖14所示。消融實驗如表2所示。
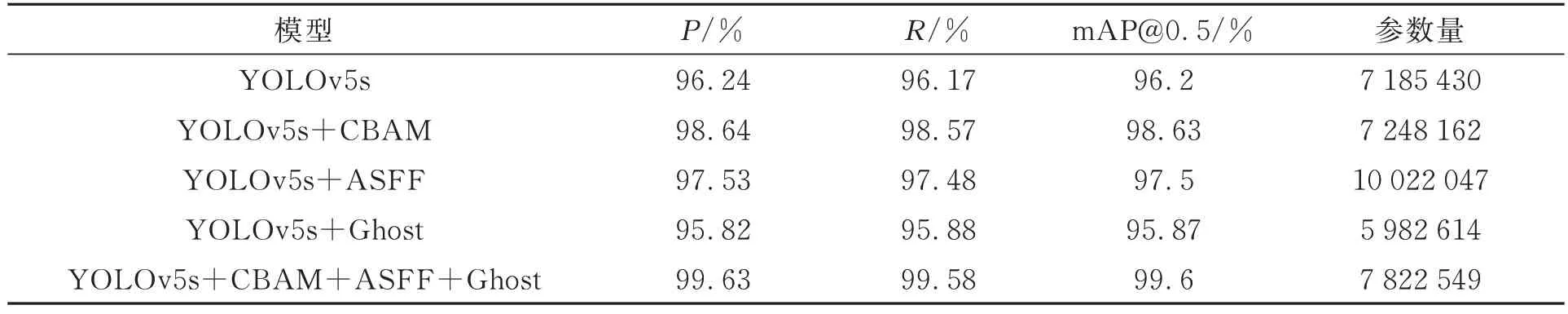
表2 車牌檢測部分消融實驗Tab.2 Partial ablation experiment of license plate detection

圖14 訓練模型參數(shù)對比Fig.14 Comparison of training model parameters
本文利用檢測網(wǎng)絡(luò)生成的權(quán)重文件對測試集進行測試。由圖14和表2可知,原始的YOLOv5s模型的P、R、mAP@0.5分別為96.24%、96.17%、96.2%。改進后的網(wǎng)絡(luò)模型ACG_YOLOv5s相比于原YOLOv5s模型mAP提升了3.4%,達到99.6%,且P和R都有一定程度的提升。YO-LOv5s網(wǎng)絡(luò)在加入CBAM注意力機制后,相比于原YOLOv5s模型mAP@0.5提升了2.43%,因此CBAM注意力機制對模型效果的提升發(fā)揮了很大的作用。原YOLOv5s網(wǎng)絡(luò)在引入ASFF模塊后,相比于YOLOv5s網(wǎng)絡(luò)mAP@0.5提升了1.3%。ASFF模塊的引入雖增加了參數(shù)量,達到了10 022 047,但同時提升了模型的性能,因此本文保留了ASFF模塊,并用Ghost模塊降低了引入ASFF模塊帶來的參數(shù)量增加問題的影響,使得目標檢測在維持良好效果的前提下參數(shù)的計算量大幅減少。由表2可以看出,在YOLOv5s網(wǎng)絡(luò)中引入Ghost模塊之后,P、R、mAP@0.5相比于原YOLOv5s網(wǎng)絡(luò)有所下降,但很大程度上減少了參數(shù)量。
主流檢測網(wǎng)絡(luò)不同算法實驗結(jié)果對比如表3所示。由表3可知,與Faster-RCNN、YOLOv3、YOLOv4、YOLOv5S相比,本文的檢測準確率和mAP@0.5都有一定的提升。本文的權(quán)重文件大小是Faster-RCNN的1/24,是YOLOv3的1/17,在提升檢測效能的同時減少了模型的內(nèi)存占比,適合將其部署到嵌入式等設(shè)備。本文提出的ACG_YOLOv5s網(wǎng)絡(luò)模型與原YOLOv5s相比,檢測速度有所下降,但可滿足實際應(yīng)用的需要。

表3 主流檢測網(wǎng)絡(luò)性能比較Tab.3 Comparison of mainstream detection network performance
為了避免對定位到的車牌進行分割,本文重新訓練了LPRNet網(wǎng)絡(luò),實現(xiàn)了免分割車牌字符識別。用LPRNet部分的數(shù)據(jù)集對LPRNet訓練所得模型進行測試,準確率可達96%。最后分別在無霧和有霧的環(huán)境下測試,測試結(jié)果如圖15、16所示。可看出本文方法不僅可識別清晰的車牌圖像,而且在原始圖片使用AOD-Net算法對車牌圖像去霧之后,圖像變得清晰,經(jīng)過車牌檢測網(wǎng)絡(luò)和字符識別網(wǎng)絡(luò)可對車牌號碼進行正確識別且達到了較高的準確率。

圖15 清晰圖像車牌識別結(jié)果Fig.15 Recognition results of license plate with clear image

圖16 霧霾圖像測試結(jié)果Fig.16 Test results of foggy images
7 結(jié)論
本文提出了基于深度學習的車牌識別算法,可對清晰圖像以及霧霾天氣下的車牌圖片進行檢測和識別。先用AOD-Net算法對圖像進行預(yù)處理,得到去霧后的圖像;然后用ACG_YOLOv5s網(wǎng)絡(luò)對車牌進行檢測;最后用LPRNet對車牌進行識別。對YOLOv5網(wǎng)絡(luò)改進如下:首先在YOLOv5網(wǎng)絡(luò)頸部加入CBAM注意力機制,提高模型的抗干擾能力,讓網(wǎng)絡(luò)加強對關(guān)鍵特征的提取。其次用ASFF模塊替換原YOLOv5網(wǎng)絡(luò)中的PANet結(jié)構(gòu),賦予3層輸出檢測層上的特征圖不同的權(quán)重,加強對小目標的檢測。最后將網(wǎng)絡(luò)中的傳統(tǒng)卷積替換為Ghost卷積,在保持原模型效果的同時減少網(wǎng)絡(luò)訓練過程中的參數(shù)。
實驗結(jié)果表明,ACG_YOLOv5s相比于原YOLOv5s模型,mAP提升了3.4%,可達99.6%。LPRNet的識別準確率達96%。兩個模型總大小為15.72 MB,所占內(nèi)存空間較小。由于本文收集到的31省的霧霾天氣下的車牌數(shù)據(jù)相較于CCPD等大型數(shù)據(jù)集較少,學習到的車牌字符的特征有限,下一步將繼續(xù)增加數(shù)據(jù)集,爭取進一步提升車牌的識別準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
