基于深度學習的用氣趨勢預測與管網氣量調配算法
——以中國石油西南油氣田公司為例
2024-03-15 02:15:34吳玙欣周欽宇楊云杰鄧啟志趙詠譚卓鄧覓
天然氣技術與經濟 2024年1期
吳玙欣 周欽宇 楊云杰 鄧啟志 趙詠 譚卓 鄧覓
(1.中國石油西南油氣田公司川西北氣礦,四川 江油 621700;2.中國石油西南油氣田公司數字智能技術分公司,四川 成都 610051)
0 引言
隨著兩化融合(信息化和工業化的高層次深度結合)的不斷加深,為了更好地降本增效,提高企業運營效率,各大油氣企業加快了各類信息系統建設的腳步[1]。其中,生產實時數據的采集、分析與應用可支撐生產過程的自動化控制,保障油氣田生產運行的可靠性和安全性[2]。中國石油天然氣股份有限公司西南油氣田分公司(以下簡稱西南油氣田)現已實現天然氣生產實時數據的采集、傳輸和存儲,通過現場層(單井和閥室RTU)、監控層(SCS 站控、RCC區域控制中心)、調度層(氣礦調度中心)和應用層(生產數據平臺、生產運行管理平臺、生產指揮管理系統、A2等應用系統)的數據互聯,實現了生產數據自動采集、遠程集中監控、關鍵閥門遠程控制、遠程視頻監控等應用[3]。但目前,利用人工智能等算法技術對實時數據進行挖掘、分析和應用的程度還不夠,依靠傳統經驗的生產決策不能較好地支撐業務管理[4]。因此,研究如何使用實時數據支撐業務管理和生產決策,進一步提升油氣田智能化建設水平,顯得尤為關鍵。
為深化數據利用,西南油氣田某氣礦接入pSpace 實時數據與A2 系統生產數據,構建一套應用系統,研究利用深度學習神經網絡對終端用戶的用氣量進行趨勢預測,實現市場需求變化的提前感知,支撐生產運行計劃的制訂。同時研究一種管網氣量調配的算法,從最少調配次數和最接近標定產能兩種角度提供井口產量的調配建議,有效減少了井口產量調整的時間與人工成本。
1 異常值檢測
為使獲取的數據真實有效,需要對數據進行異常值檢測和數據篩選,該功能模塊集成了基于分布的異常值檢測N-Sigma、基于聚類的異常值檢測DBSCAN[5],實現了異常檢測結果的在線可視化分析。圖1 展示了2023 年4 月13-14 日雙探3 井的歷史數據通過DBSCAN 異常值檢測后的正常運行區間和可視化結果。通過異常值檢測,去除數據中可能存在的異常值,對數據進行清洗,保證使用數據的準確性,可生成工藝參數的正常運行區間,減少人為分析工藝運行情況的工作量。
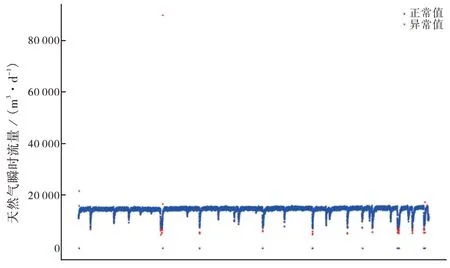
圖1 雙探3井DBSCAN異常值檢測結果
2 用氣量趨勢預測
2.1 時間序列預測技術
時間序列是一組按時間變化而變化的隨機變量,它通常是在相等間隔的時間段內依照給定的采樣率對某種潛在過程進行觀測的結果[6]。時間序列數據本質上反映的是某個或者某些隨機變量隨時間不斷變化的趨勢,而時間序列預測的核心就是從歷史的序列數據中挖掘出變化規律,并利用該規律對后續時間對應的數據做出預估[7]。針對不同場景,時間序列預測目標可以分成點估計、概率預測和區間預測三種不同類型。其中,點估計方法認為時間序列預測模型輸出的是預測值;概率預測方法認為時間序列本身就是一組隨機過程,因此更傾向于估計出時間序列在未來的分布;區間預測則描述預測值可能的上下限[8]。
傳統時間序列預測方法主要是在確定時間序列參數模型的基礎上,求解出模型參數,并利用求解出的模型完成未來預測工作。典型的方法有自回歸綜合移動平均模型(Auto Regressive Integrated Moving Averages,ARIMA)[9]、可捕捉季節性的Holt-Winters 法[10]。基于機器學習的方法中,具有代表性的有支持向量回歸(Support Vector Regression,SVR)[11]、梯度漸進回歸樹(Gradient Boosting Regression Tree,GBRT)[12]、隱馬爾可夫模型(Hidden Markov Model,HMM)[13]。基于深度學習的方法通過多個非線性層來構建以往時間序列的特征表示,從而學習時間序列內部變化規律。
2.2 用氣量趨勢預測模型
用氣量趨勢預測即為根據現場持續采集并累積的用氣量實時數據,對未來一段時間內的用氣量變化趨勢進行預估。在滾動預測窗口大小固定條件下,給定模型輸入序列,期望預測序列[14],基于深度學習進行用氣量趨勢預測。深度學習能夠更好地進行高維數據表征,從而減少對手動特征工程和模型設計的需求,并通過定義損失函數,可以更加便捷地進行端到端的訓練。具體選用的模型為Informer[15]。
Informer 是一類基于自注意力神經網絡的模型,通過Transformer 捕獲長時間序列的依賴關系。其網絡結構如圖2 所示,網絡主體由編碼器和解碼器組成,兩者均使用了ProbSparse注意力層來減少注意力計算的時間復雜度,編碼器中采用了自相關蒸餾操作來縮短每一層的輸入序列長度,而在解碼器中使用了生成式的推理可通過單輪計算獲得序列預測結果。Informer將輸入序列Xt劃分為編碼器輸入Xen和解碼器輸入Xde,并在解碼器輸入的后端用0 值填補,通過多層自注意力的計算建立時間序列的依賴關系,最后通過全連接層計算預測序列中每個時間點位對應的值。

圖2 Informer網絡結構[15]
2.3 數據處理
在構造訓練數據時選取18 個供氣用戶共8 個月的歷史用氣量數據,按分鐘為間隔單位劃分序列,對單位時間內存在的多個值做平均處理。作為訓練數據x,對x進行標準歸一化處理,使其均值μ=0、方差σ=1。xt為歸一化之后的數據,其計算方式如下:
除了使用氣量時間序列數據外,還考慮了時間本身向量化后的值作為額外輸入特征,對年、月、日、小時、分的特征F分別進行歸一化,Ft為歸一化后的時間特征,根據最小值Fmin和最大值Fmax歸一化至[-0.5,0.5]區間內[16]。歸一化時間特征Ft的計算方式為:
2.4 模型訓練
訓練模型采用的損失函數為均方誤差(Mean Square Error,MSE):其計算方式可寫為:
其中,n為訓練時單步迭代使用的數據量,Yi為真實序列,為模型的預測序列。為實現1 小時長度的序列預測,在模型訓練時使用的輸入序列長度Lx為360,其中前240項數據作為編碼器的輸入,120項數據作為解碼器的輸入;預測序列的長度Ly為60;單步迭代使用數據量n為32;數據集迭代輪次為6;訓練集和測試集按7∶3劃分。
2.5 結果分析
該用氣量預測模型在測試集上的預測平均絕對誤差MAE=0.165 9、均方誤差MSE=0.082 1。圖3展示了某用戶用氣量真實序列與模型預測序列的對比,數據進行了歸一化的處理,橫軸為序列長度。由結果可知,該用氣量預測模型能在較低的誤差下預測未來一段時間內的用氣量變化。

圖3 基于Informer實現的小時用氣量預測結果
3 管網氣量調配
3.1 氣量調配算法
為進一步輔助生產決策,構建了一套基于管網匯總氣量的井口產量調配算法,從最少調整次數與最接近標定產能這兩種角度提供調配建議。
基于給定的井列表從A2 讀取標定產能,并統計每口井的歷史日產數據,獲得日產量的上限與下限,同時根據實時數據點位獲得當前瞬時流量。本方法定義井產量的可能值存在于0(關井狀態)或最小值與最大值的閉區間(開井狀態)。因此,在下調產量時,為實現最少調整井數,每口井的下調值可能為當前產量(關井時)、當前產量減最小產量、總產量與目標值的差值。在上調產量時,每口井的上調值為最大產量減當前產量、總產量與目標值的差值。同時,為實現最接近產能標定值調配,本方法采用產能標定值的百分比來定義井當前產量與標定產能間的距離,計算公式為:(當前產量-標定產能)/標定產能。若越接近0 則代表越接近產能標定值。在進行調整時,每口井的下調值為當前產量、當前產量減最小產量或標定產能的百分之十、總產量與目標值的差值。在上調產量時,每口井的上調值為最大產量減當前產量或標定產能的百分之十、總產量與目標值的差值。具體計算的流程如圖4 所示。兩種調配算法均優先考慮不進行關井減產,在關井時則通過遞歸查找確保調配方案為最優。若目標產量落在0與最小值區間內或大于所有井最大產量的累計,在上述約束條件下則無法完成調配方案的生成,此時算法會將當前得到的近似解作為結果返回。

圖4 氣量調配算法流程
3.2 氣量調配應用系統
為實現氣量調配算法的實時應用,基于B/S 架構開發了一套氣量智能調配分析系統,后端采用Flask 框架、前端采用Element UI,其基礎的功能模塊包含井列表管理、氣量調配。
列表管理可實現井的增刪和屬性修改,該系統通過綁定井名和實時數據點位獲取A2系統的日產數據與pSpace 實時數據。新增井后,每口井的當前產量采用定時任務從pSpace中讀取。
氣量調配時需選中井列表中對應的井名,輸入目標產量并選擇調配方式,可使用最接近標定產能調節和最小調整次數分別獲取的調配建議。
4 結論
1)生產實時數據是油氣生產的重要資產,目前主要用于生產場景監測、報表數據生成等方面,數據深化應用有很大的挖掘空間,對氣田精細管理、效益提升具有重要意義。
2)通過對生產歷史數據的處理,可對異常值進行分析和過濾,從而獲取能使用分析的數據,并且能生成參數的正常運行區間,對有效數據提取、指導工藝參數運行范圍具有重要意義。
3)通過神經網絡進行用戶用氣量小時趨勢的預測,能較好地捕獲未來一段時間內的用氣量變化趨勢,從而實現需求變化的提前感知。
4)通過構建最少調整次數和最接近標定產能兩種基于管網匯總氣量的井口產量調整算法,可以實現氣井生產管網調配方案的自動計算,減少人工計算分析管網氣量調配的工作量。
5)用氣趨勢預測與管網氣量調配算法和模型仍存在改進的空間,采用的時序預測模型為單變量預測單變量,輸入的特征維度有限,在一定程度上限制了模型的訓練效果,未來可從多變量預測單變量、多變量預測多變量兩種角度出發不斷將算法模型進行迭代;該管網氣量調配算法只考慮了實時產量,壓差、溫度、管網結構、地質條件等因素未涉及在內,可考慮通過全面的管網建模進行更為準確的仿真計算。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
礦山安全信息(2022年40期)2022-04-07 02:16:52
今日農業(2021年14期)2021-11-25 23:57:29
石油與天然氣地質(2021年1期)2021-02-22 14:14:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
今日農業(2020年20期)2020-11-26 06:09:10
數學物理學報(2020年2期)2020-06-02 11:29:24
中國果業信息(2019年10期)2019-11-13 01:21:34
聚氯乙烯(2018年9期)2018-02-18 01:11:34
光學精密工程(2016年6期)2016-11-07 09:07:19
