基于深度Q網絡的云演藝延遲敏感業務QoE優化
2024-03-22 03:05:28李宛青李樹鋒劉健章胡峰
中國傳媒大學學報(自然科學版) 2024年1期
關鍵詞:資源
李宛青,李樹鋒,劉健章,胡峰
(中國傳媒大學信息與通信工程學院,北京 100024)
1 引言
隨著互聯網的普及,多種多樣的業務應用不斷涌現,超高清視頻流、云計算、物聯網等領域的快速增長給網絡資源的高效分配提出了新的挑戰[1]。隨著信息技術的不斷發展和普及,云計算作為一種高效、靈活的計算模式逐漸滲透到了各行各業。其中,云演藝作為云計算的一個重要應用領域之一,為用戶提供了多樣化、便捷的娛樂體驗[2]。然而,云演藝服務中延遲敏感業務的體驗質量(Quality of Experience,QoE)受到了延遲問題的嚴重影響。演藝延遲敏感業務是指需要低延遲、高實時性的音視頻傳輸和交互式應用,如在線直播、視頻會議、互動游戲等,高延遲會導致視頻卡頓、聲音不同步等問題,從而影響用戶觀看體驗[3]。當前,盡管云計算技術已經取得了長足的發展,但在云演藝延遲敏感業務的QoE優化方面仍存在著挑戰。傳統的網絡優化方法往往難以有效地適應云演藝業務的特點,特別是在延遲敏感和大規模用戶同時訪問的情況下。因此,尋找一種更加有效、智能的優化方法來改善云演藝延遲敏感業務的QoE,是當前云計算領域急需解決的問題之一[4]。本文重點關注以塊(block)形式發送數據的延遲敏感應用程序。
神經網絡(Neural Network,NN)由大量人工神經元組成,能夠接受來自外部環境或數據源的輸入信息,通過前向傳播和反向傳播過程進行訓練。Q學習算法(QLearning)迭代更新Q值函數,通過估計在每個狀態下采取每個動作的長期回報值,最終獲得最優策略。在多業務資源調度研究領域,將神經網絡與Q學習算法相結合受到了廣泛關注。Chmieliauskas等[5]提出了一種基于深度強化學習與Q-Learning的蜂窩網資源分配算法,以最大限度實現有限頻譜資源的合理利用。他們的研究旨在通過智能資源分配來降低延遲和提高用戶體驗。實驗結果顯示,他們的算法與其他算法相比收斂速度有所提高,并在傳輸速率與優化能耗方面有明顯改進,有效解決在多目標條件下的資源調度問題。因此,本文將神經網絡作為Q學習的函數逼近器,實現了在復雜環境中學習并優化多業務資源塊分配策略。
深度Q網絡(Deep Q-Network,DQN)是深度強化學習(Deep Reinforcement Learning,DRL)中的一種重要方法,已在眾多領域取得了顯著成果,包括圖像處理、自動駕駛、游戲和自然語言處理。Burhanuddin等[6]在無人機到無人機場景下探索了一種基于Actor-Critic(AC)與DQN的DRL算法,并通過仿真驗證此算法在QoE方面優于Greedy算法,最終實現了穩定的視頻傳輸與長期優化。
深度Q 網絡結合了神經網絡和Q-Learning 算法,具有自適應性和智能性,能夠根據不同業務的需求進行資源分配決策[7]。此方法在資源分配問題中具有廣泛的應用潛力,特別是在延遲敏感業務領域[8-10]。
針對以上問題,本文旨在基于DQN 等深度強化學習技術,探索并提出一種針對云演藝延遲敏感業務資源調度算法,使得模型能夠自適應地根據不同業務需求進行資源分配,提高資源利用率和用戶體驗。另外,本文提出了一種在深度強化學習中將神經網絡用于近似Q值函數的方法,利用神經網絡架構和資源估計技術,從實時網絡信息中學習并動態調整資源的調度。這一算法在資源分配決策上具有靈活性和智能性,能夠為不同類型的業務提供優化的服務。仿真結果表明,與Reno 算法、Actor-Critic 算法相比,本文所提算法可以有效提高用戶體驗質量。
2 資源調度環境架構
2.1 典型環境架構
圖1展示了多業務資源調度場景下的典型環境架構,其中有數個發送方和接收方共享一個鏈接。根據不同應用程序數據集生成數據塊,經過塊調度模塊與帶寬估計模塊進行調度后,以數據包的形式離開發送方進入鏈路。在這一過程中,鏈路的總可用帶寬、最小延遲均根據網絡跟蹤做出相應變化。如果數據到達時刻的速率超過帶寬,等待被發送的數據包將被臨時儲存在隊尾的先入先出(First Input First Output,FIFO)隊列中。當最后一個數據包到達接收方時,就可以計算這一業務塊的完成時間,最終將其在模擬器內用于QoE 計算。
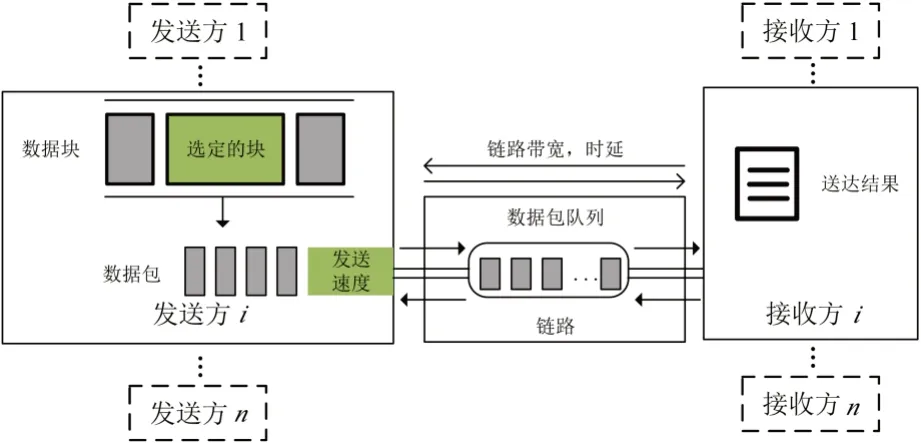
圖1 多業務資源調度場景典型環境架構
為了保證實驗環境支持數據塊形式傳輸,并為數據塊增添有效傳輸時限,本文使用ACM 2021 Multimedia Grand Challenge 開源模擬器,數據塊遞送模擬器架構如圖2 所示,其中主要包括三部分:調度方案、環境、QoE模型。結合圖1,在模擬之前根據環境設置多個發送方與接收方,二者經過鏈路進行數據的傳遞。每個發送方在每條鏈路中模擬一個應用程序跟蹤列表,每條鏈路中基于不同的網絡跟蹤進行相應的模擬,其中應用程序跟蹤用于模擬應用程序的數據模式,網絡跟蹤用于模擬當前網絡條件。
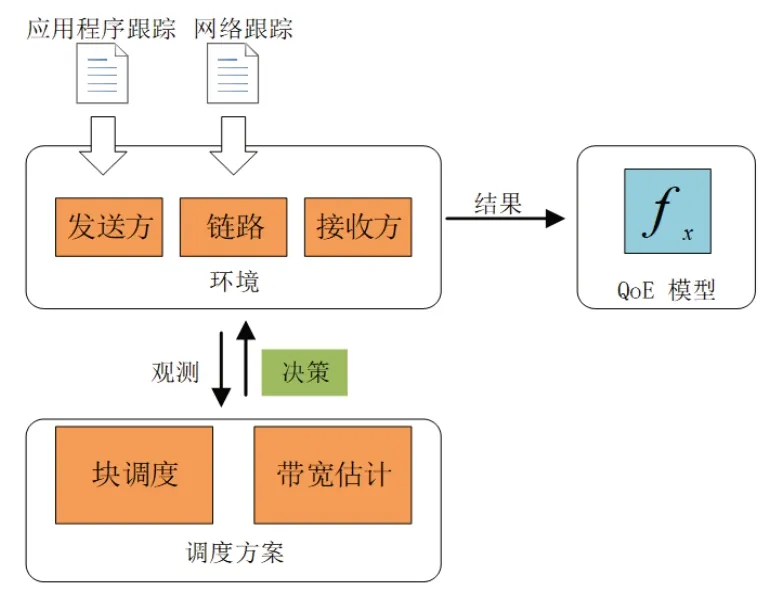
圖2 數據塊遞送模擬器架構
2.2 QoE模型
在網絡通信或數據傳輸領域,QoE通常用于評估用戶對于服務、應用或內容的整體體驗和滿意度。多媒體應用QoE通常會由于所選方法的不同發生顯著的變化,當數據塊及時到達時,用戶感知的質量通常得到改善。本文在基于數據塊的優先級對QoE進行計算的基礎上,考慮了數據塊的緊急程度,將QoE建模為式(1):
其中x為用于平衡優先級和緊急程度的權重參數,默認值為0.9。priorities是每個數據塊的優先級和權重列表,urgency表示數據塊的緊急程度。通過調整x的值,可以加強或減弱優先級和緊急程度對QoE的影響。
3 資源調度算法
3.1 擁塞控制算法
3.1.1 Reno算法
擁塞控制算法Reno 是一種用于傳輸控制協議(Transmission Control Protocol,TCP)的算法,用于控制數據包在網絡中傳輸的速率。Reno 算法基于擁塞避免和快速恢復的概念,通過動態調整發送數據包的數量來維持網絡的穩定性[11]。
該算法主要包括三種狀態:慢啟動(Slow Start)、擁塞避免(Congestion Avoidance)和快速恢復(Fast Recovery)。在慢啟動階段,擁塞窗口(cwnd)設為初始值,并以指數增長的方式逐漸增加,直到達到慢啟動閾值(ssthresh),ssthresh與cwnd計算如式(2):
其中ACK為標志位,用來確認序號有效。對ssthresh進行減半處理,ssthresh與cwnd的表達式如式(3)、式(4):
其中α作為調節參數,取0.5。如果發生丟包,算法會進入快速恢復狀態,然后根據情況調整閾值和cwnd,最終恢復到擁塞避免狀態。算法過程描述如表1:

表1 Reno擁塞控制算法過程描述
3.1.2 Actor-Critic算法
Actor-Critic的架構包括兩個部分:
·策略網絡Actor:觀察網絡狀態,結合數據傳輸速率、丟包情況等輸出選擇動作,包括增加、保持、減少發送速率;
·評論網絡Critic:評估Actor 網絡選擇動作的價值,指導Actor網絡更新策略,以獲得更好的決策[12]。
偽代碼如表2:

表2 Actor-Critic算法偽代碼
3.2 資源調度算法
Reno算法作為TCP協議中的一種經典算法,基于擁塞窗口大小的動態調整來控制網絡的擁塞狀態。其主要缺陷之一是在高延遲網絡中表現不佳,并且在面對長距離或高帶寬延遲積(Bandwidth-Delay Product,BDP)的網絡時容易出現性能下降。
這種性能下降部分源于Reno 算法在擁塞控制中對丟包的處理。當出現丟包時,Reno算法采用指數退避的策略,即將擁塞窗口減半,并采用線性增長的方式重新開始。然而,對于高延遲網絡來說,丟包往往被視為網絡擁塞的信號,這導致了Reno 算法過于保守的行為,因此未能充分利用網絡帶寬。
為了克服這些缺陷,本文研究了一種基于強化學習的動態擁塞控制方法。該方法利用神經網絡和Q學習來自適應地調整發送速率,不僅能更好地適應網絡狀況的變化,還能在一定程度上減少對丟包的過度敏感。算法過程描述如表3:

表3 資源調度算法過程描述
DQN是基于深度學習的Q-learning算法,將深度神經網絡技術與價值函數相結合,采用經歷回放、目標網絡的方法進行網絡訓練。Q-function函數可用式(5)描述:
其中st為當前時間片的狀態,ɑt為采取的行為,rt為獎勵,st+1為新的狀態,Eπ表示以策略π進行動作。Q-function函數的最優值函數為式(6):
其中為函數逼近器,α∈(0,1]為學習率,γ為折扣因子(衰減系數)。
對于連續狀態與動作空間,可以使用NN 來逼近最優動作值函數在參數為θ時,=Qθ。這時,可以將式(7)所表示的迭代過程視為回歸問題,目標是通過上升隨機梯度,估計NN 的參數θ。在深度Q 網絡中,使用值rt+γmaxQθtɑrget更新Qθ,其中Qθtɑrget為目標Q-function。對于數據[st,ɑt,rt,st+1],Q-function的損失函數構造為均方誤差的形式,可由式(9)表示:
神經網絡與Q-learning 相互結合,神經網絡用于逼近Q值函數。智能體通過與環境互動,收集數據并將其用于更新神經網絡的權重,從而改善Q值函數的估計。這個過程將神經網絡中的權重調整為最大化長期獎勵,從而使算法能夠做出更好的決策。
這種基于強化學習的方法通過持續學習和調整來實現自適應的擁塞控制,不僅在網絡變化頻繁的情況下表現更好,而且對丟包的反應更加靈活。相比于Reno 算法,這種方法更能適應各種網絡環境,提高了網絡的傳輸效率和性能。
3.3 塊選擇算法
塊選擇算法通過權衡不同的數據塊屬性來決定下一個發送的數據塊。在本文中,每個數據塊都包含優先級、截止時間等基本屬性。算法首先根據創建時間確定發送順序,即先創建的數據塊先被發送;如果多個數據塊的創建時間相同,則選擇剩余時間周期與截止交付時間比例更高的數據塊作為優先發送對象。若數據塊bi的創建時間為Tcreɑtei,截止交付時間為Tdeadlinei,當前時間節點為Tcur,剩余時間周期與截止交付時間比例為Ri,則如式(10):
塊選擇算法的設計能夠有效管理本文系統中大量待發送的數據塊,根據時間屬性、剩余時間周期與截止交付時間的比例,對多種屬性進行權衡,決定某一時刻應發送的數據塊,從而提高了數據傳輸的效率和系統的整體性能。
4 仿真結果分析
仿真中涉及的參數值如表4所示。
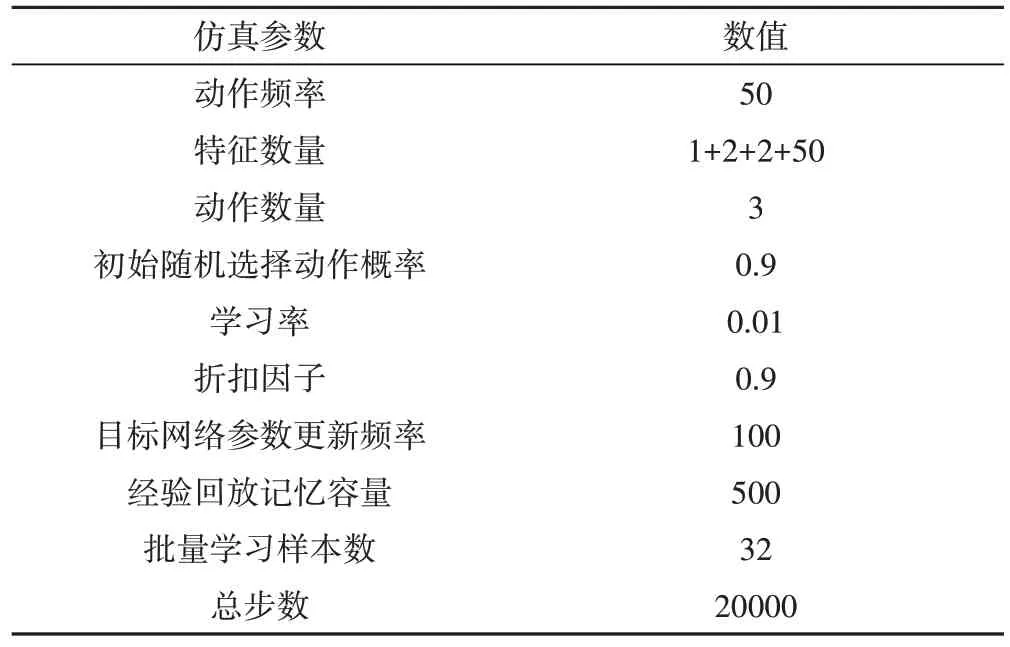
表4 仿真參數
為了驗證本文提出的資源調度算法的有效性,本文數據集由三部分組成:塊軌跡、背景流量軌跡和網絡軌跡。每個應用場景都包含一個或多個塊軌跡,這些塊軌跡可以與任意網絡軌跡組合,模擬在特定網絡條件下使用延遲敏感應用程序的過程。
圖3 以云演藝場景中實時通信(Real-Time Communications,RTC)應用程序為例,將來自RTC 應用程序的流數據分為三類:第一類是控制信號,如預測帶寬、目標比特率設置等,控制信號必須及時到達,才能保證RTC 應用服務的穩定運行;第二類是音頻,即剔除噪聲后的用戶語音數據;第三類是攝像機錄制的視頻。這三種類型的數據具有不同的優先級。錯過控制信號的交付時間可能會導致QoE的嚴重下降,因此這些信號具有最高的優先級。在大多數RTC 應用程序中,音頻比視頻更重要。
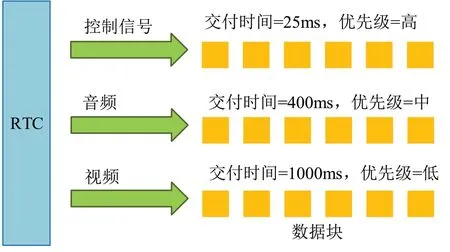
圖3 RTC應用框架
圖4、圖5與圖6分別展示了Reno算法、Actor-Critic算法作為擁塞控制模塊與本文所提算法數據包的傳輸時延、平均傳輸時延。本文算法平均傳輸時延(Lavg)為0.044990s,將Reno算法、Actor-Critic算法作為擁塞控制模塊的資源調度算法時,獲得的平均傳輸時延分別為0.048450s與0.0484375s;本文算法用戶體驗質量(Qqoe)達到了270,將Reno算法作為擁塞控制模塊時的資源調度算法則為212。在相同的時間段內,由于本文算法適當減少對丟包的過度敏感,因此獲得了更低延遲。
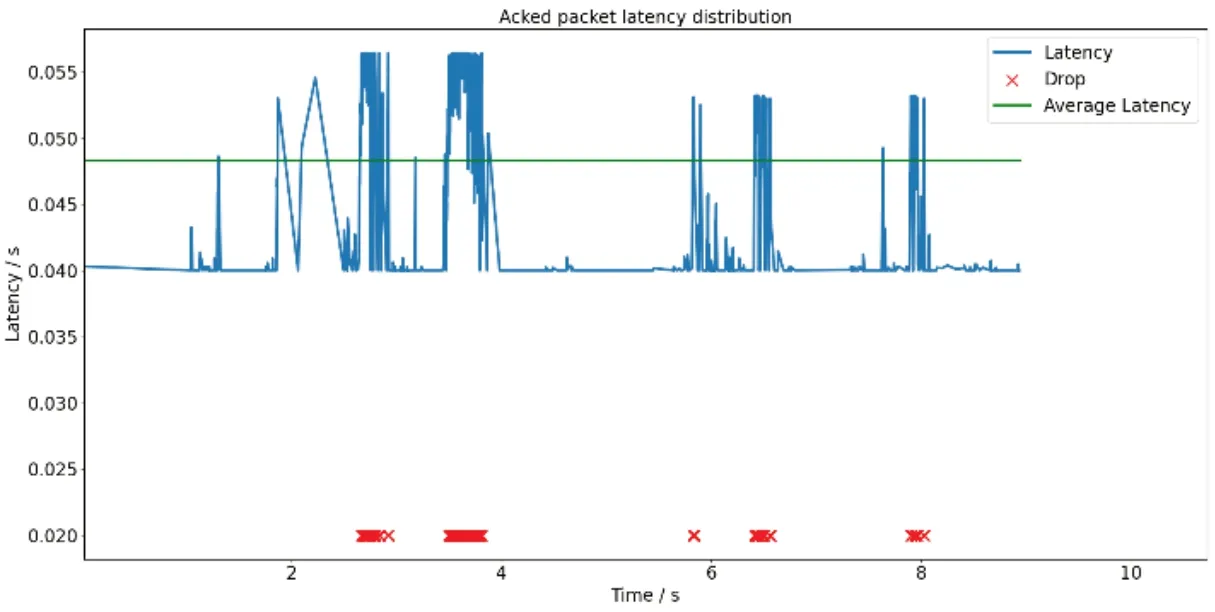
圖4 Reno算法時延
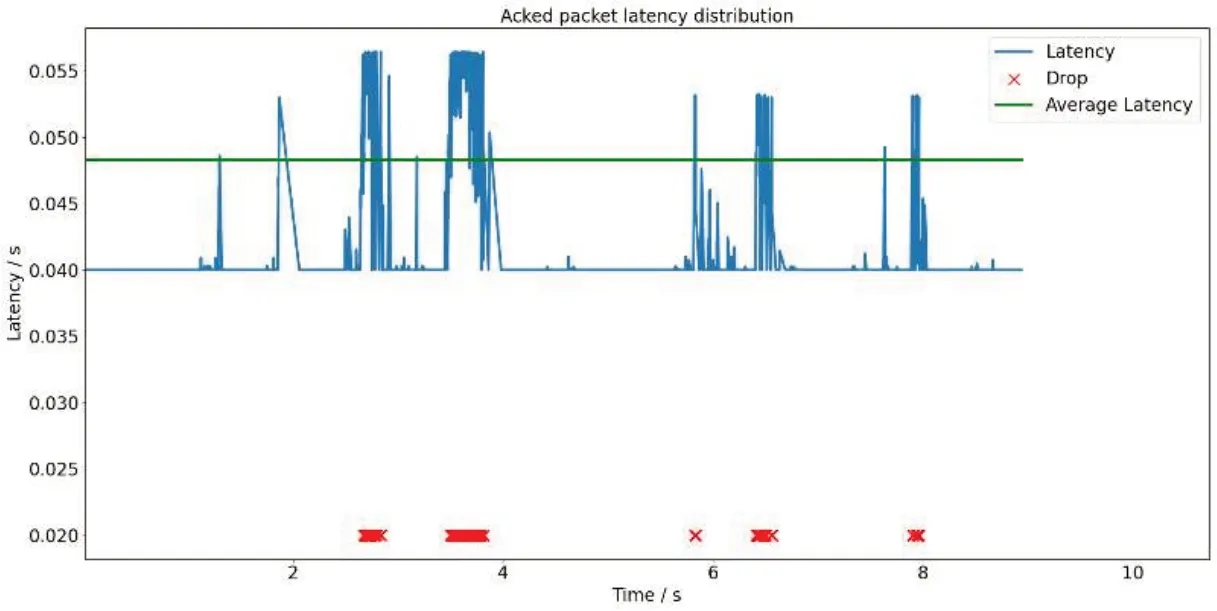
圖5 Actor-Critic算法時延
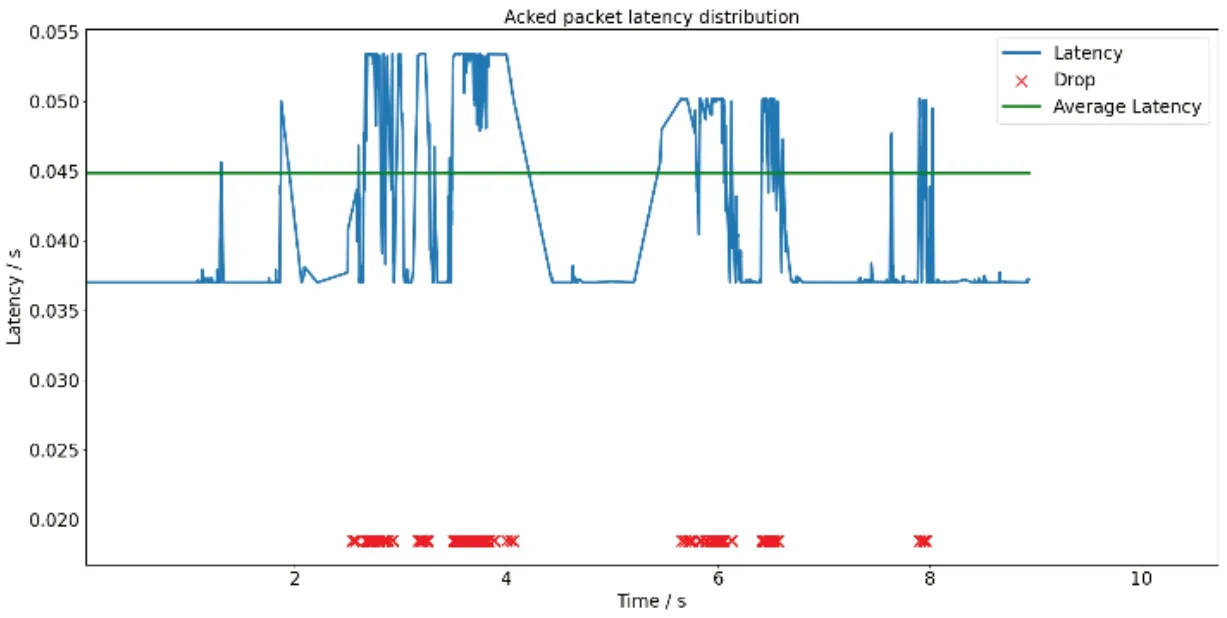
圖6 本文算法時延
通過圖7,本文展示了Reno 算法與本文算法的窗口更改過程。可以看出,在丟包頻繁的時間內,Reno 算法的擁塞窗口出現較大波動,并出現了頻繁的波動現象。而本文算法不僅考慮了丟包事件,還綜合考慮了其他網絡狀態和特征,在丟包事件發生時擁塞窗口的改變更加穩定,能夠更快地適應帶寬的改變,并且能夠更高效地利用網絡帶寬。
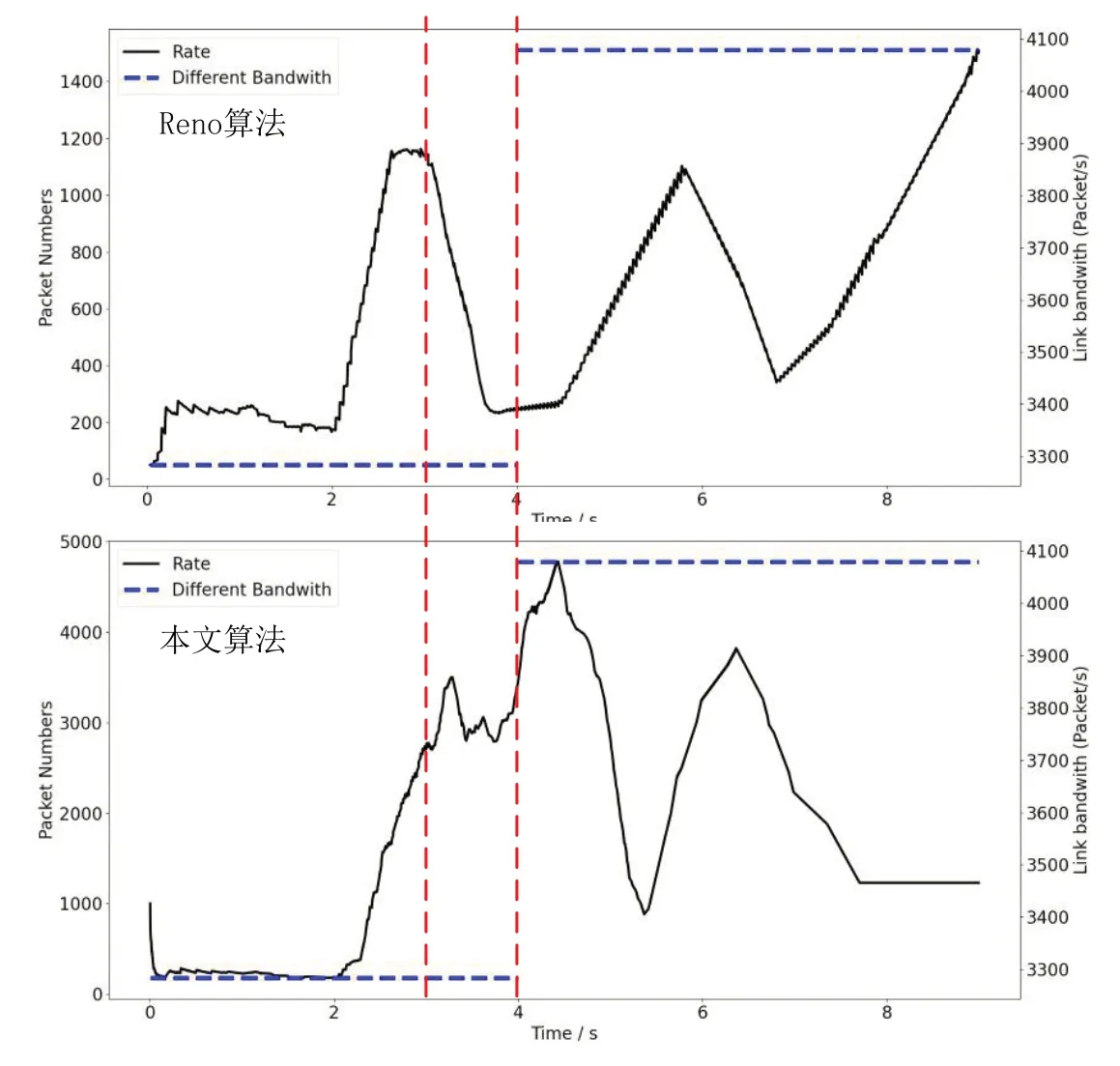
圖7 Reno算法與本文算法擁塞窗口更改過程
5 結論
本文設計了一種基于DQN 的延遲敏感業務資源調度算法:首先,本文說明了DQN 用于延遲敏感業務的優勢,基于強化學習對擁塞控制實現自適應改變,使得算法有能力進行動態的持續學習。其次,本文對比了在相同的排隊算法條件下,Reno 算法、Actor-Critic 算法與本文所提算法在傳輸不同優先級數據包的延遲過程,比較了在不同網絡狀態下本文算法與Reno算法、Actor-Critic算法窗口更改過程。仿真結果表明,本文算法在動態丟包策略與時延上優于Reno算法、Actor-Critic 算法,本文算法在網絡發生頻繁變化時窗口改變較Reno 算法更穩定,最終本文算法用戶體驗質量遠優于Reno算法。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
資源節約與環保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
藝術品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
當代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
