摩爾紋圖案自動去除技術綜述
2024-03-23 08:04:08亓文法劉宇鑫郭宗明
計算機研究與發展 2024年3期
亓文法 劉宇鑫 郭宗明
(北京大學王選計算機研究所 北京 100080)
在21 世紀這個網絡信息爆炸的時代,數字圖像作為人類認知世界的視覺基礎,已經成為信息記錄、表達、儲存及傳播的重要手段.同時,隨著數碼相機、平板電腦以及智能手機等移動設備的迅速普及,人們可以輕松地獲取各種有意義或有趣的寶貴瞬間作為數字圖像的內容.但是當利用光學鏡頭設備拍攝電子屏幕(如LED 屏、LCD 屏等)或者高頻重復紋理圖案(例如布料、瓷磚等)時,若相機的彩色濾光片陣列(colour filter array, CFA)與拍攝對象條紋之間的空間頻率接近,則拍攝圖像中會出現不規則的點狀、條紋、曲線或者漣漪等形狀的干擾圖案,即所謂的摩爾紋,如圖1 所示.因為從數學上講,2 個具有相近頻率的等幅正弦波被疊加,合成信號的振幅將會根據2個頻率之間的差異而發生隨機變化[1].摩爾紋圖案的出現嚴重降低了拍攝圖像的視覺質量和美感價值,并且會影響后續的傳統圖像處理效果,比如圖像超分[2]、圖像分割[3]、人臉識別[4-5]等.依據拍攝硬件設備、方向角度以及距離遠近的差異,摩爾紋圖案存在著形狀各異、頻譜廣泛、紋理隨機以及顏色復雜等動態特性.因此,拍照圖像中的摩爾紋圖案自動去除面臨著巨大的挑戰.

圖1 不同尺度、頻率和顏色的摩爾紋Fig.1 Moiré pattern of different scales, frequencies, and colors
理論上講,摩爾紋去除可以視為傳統的圖像修復處理,其目的是消除拍照圖像中的摩爾紋圖案噪聲,重建圖像的高頻細節以及恢復顏色空間信息[6].摩爾紋圖案去除算法的輸入為一幅包含摩爾紋圖案的污染圖像,輸出則為一幅去除摩爾紋圖案并進行了顏色空間信息恢復的干凈圖像.由于摩爾紋圖案和原始圖像信號在空域和頻域的混合范圍都很廣,傳統的圖像去噪[7-8]、去網紋[9-10]和去模糊[11]等圖像修復算法不能有效地直接應用于摩爾紋圖案去除任務.比如,圖像去噪任務通常假定噪聲僅存在高頻帶中,但摩爾紋的分量不規則地分布于從低頻到高頻的各個子帶中,即表現為在不同圖像之間甚至同一圖像中的不同區域,摩爾紋圖案都會隨機占據不同能量的頻域子帶;圖像去網紋技術消除的圖像紋理通常是均勻分布的,但是摩爾紋圖案的分布疏密不均勻;圖像去模糊技術則要求圖像噪聲的顏色或者強度變化幅度相對一致,而在實際場景中CFA 的顏色分布不均衡,使得摩爾紋圖案在RGB 顏色通道中分別顯示不同的強度.為了抑制摩爾紋圖案的產生,最常用的方法是在成像之前添加一些預處理,例如,在相機鏡頭前面放置一個抗混疊濾波器[12-13],并對CFA 的輸出圖像應用相對復雜的插值算法[14-15].由于光學濾波器會導致高頻信息丟失,并導致圖像過度平滑,這些預處理方法在實踐中發揮的能力很有限.因此,大部分的工作聚焦于圖像去摩爾紋的后處理方法研究,尤其是針對拍攝后的屏幕圖像.
早期的摩爾紋圖案去除研究工作主要是基于摩爾紋生成模型展開的,其中利用了摩爾紋圖案的特定先驗知識和前提假設.考慮到常用的Bayer 型CFA通常會對采集的顏色通道分量進行插值處理后才能得到拍照后的全彩色圖像,因此通過改進圖像插值算法可以有效抑制摩爾紋干擾現象的發生[16-17].為了充分考慮顏色通道的相關性,更高性能的圖像插值算法被提出,如梯度插值方法[18]、自適應插值方法[19]、加權系數插值方法[20]等.該類方法得到的修復圖像能夠較好地保留圖像的細部邊緣特征,但算法實現過于復雜,難以在實際場景中得到廣泛應用.通過對摩爾紋圖案的空間結構統計特征和頻域能量分布特性進行分析,經過摩爾紋污染的拍攝圖像可以被視為摩爾紋圖案和背景自然圖像的非線性疊加[21-22].Liu 等人[23]和Yang 等人[24]分別基于加性模型提出了用于紋理圖像摩爾紋和屏攝圖像摩爾紋的消除方法,通過圖像分解模型實現摩爾紋圖案和背景自然圖像的區分,并同時保留圖像細節以及保證圖像銳度.Fang 等人[25]將污染屏攝圖像描述為潛在層和摩爾紋圖案層,結合潛在層的分段常數特性,提出了一種凸模型來解決摩爾紋消除問題.Sasada 等人[26]和Sidorov 等人[27]基于摩爾紋圖案具有特定形狀(如條紋、點狀或單色)的假設來進行檢測,并將摩爾紋圖案與背景層相分離,實現摩爾紋圖案的去除和背景顏色通道信息的恢復.另外,由于摩爾紋圖案可以視為一種高頻噪聲,很多學者通過對圖像頻域能量信號進行分析,并應用相應濾波器將摩爾紋圖案作為特定頻率信號去除.常見的濾波器包括中值濾波器[28-29]、高斯陷波濾波器[28]、DoG(difference of Gaussians)[30]、非線性濾波器[31-32]、自適應濾波器[33]等.但是該類方法使用到的濾波器通常是經過人工設計的,去除摩爾紋圖案后的圖像會出現局部過平滑現象,部分圖像細節缺失.另外,當背景自然圖像中的感興趣區域(region of interest, ROI)跟摩爾紋圖案具有同樣的高頻特性時,基于濾波的摩爾紋圖案消除方法就會失效.總之,基于傳統信號處理的方法通常依賴于摩爾紋圖案生成的先驗知識,計算復雜度高,而真實世界中的摩爾紋圖案往往具有不同的形狀和頻域特征,此時該類方法的處理效率較低.
近年來,基于卷積神經網絡(convolutional neural network, CNN)的學習方法得到了長足發展,成為計算機視覺和圖像處理領域的一場革命.CNN 在圖像分類和圖像識別方面取得成功后,同樣在低水平視覺和圖像處理任務中也被證明是非常有效的,包括圖像超分辨率[34-35]、去馬賽克[36]、圖像去噪[37]和圖像重建[38]等.Abraham[39]將CNN 方法引入摩爾紋圖案處理領域,提出了一種利用小波分解和多輸入深度卷積神經網絡模型來檢測計算機屏幕拍攝圖像(屏攝圖像)中的高頻摩爾紋噪聲圖案.由于摩爾紋圖案跨越很寬的頻域范圍,Sun 等人[40]利用一種多分辨率全卷積神經網絡(deep multiresolution fully convolutional neural network, DMCNN)自動去除屏攝圖像中的摩爾紋圖案,該網絡在計算如何消除每個頻帶內的摩爾紋偽影之前,對輸入圖像進行非線性多分辨率分析.之后,更多基于空域的多尺度CNN 模型[1,41-46]被相繼提出,屏攝圖像中的摩爾紋圖案去除性能得到顯著提高.除了考慮摩爾紋圖案的空間特征外,Zheng 等人[47]提出了可學習的多尺度帶通濾波器,以處理頻域中摩爾紋圖案的多樣性.此外,空間域和頻域變換也被用來探究摩爾紋圖案的互補特性,高效地實現自然圖像和紋理的恢復.然而,文獻[1,41-47]的方法基于監督學習需要大量的可以成對的干凈圖像-摩爾紋圖像進行訓練,其模型性能在很大程度上取決于訓練對的特性.為了解決這一限制,最近研究了使用生成性對抗網絡(generative adversarial network,GAN)的無監督學習算法[48-50],由摩爾紋圖案生成網絡和摩爾紋圖案去除網絡組成.生成網絡負責生成摩爾紋圖案以構造摩爾紋和干凈圖像的偽配對集,然后使用生成的偽配對數據集以有監督的方式對摩爾紋圖案去除網絡進行訓練,以有效地去除摩爾紋圖案.
綜上所述,摩爾紋圖案去除算法主要包括基于傳統信號處理方法和基于深度學習方法.鑒于摩爾紋圖案的頻率分布復雜、顏色通道幅度的不平衡以及外觀屬性不同等特點,深度學習方法在摩爾紋圖案去除方面的性能更加出眾.除了如何構造有效的摩爾紋圖案去除網絡結構外,大規模圖像對的基準數據庫構建對于摩爾紋去除算法的研究和評估也具有重要意義.
本文的主要貢獻包括3 個方面:
1)系統梳理了摩爾紋圖案去除方法的研究脈絡,并進行合理的分類歸納總結;
2)基于相同的公開基準數據庫,選擇主流的基于深度學習方法進行算法實現和性能對比分析,并總結了相應方法的優缺點;
3)對目前的摩爾紋圖案去除算法的研究現狀進行總結,并對未來的研究方向進行展望.
1 基于先驗知識的方法
1.1 圖像濾波
當使用智能手機或數碼相機等設備拍攝屏幕圖像時,由于顯示設備像素和攝像頭傳感器網格之間的混疊,導致傳感器對場景圖像產生欠采樣,因而產生頻率干涉的摩爾紋圖案.為此,數碼相機開發商提出了一種光學低通濾波器(optical low pass filter, OLPF)方案[12],主要是使用2 個透鏡將光信號折射至2 個方向,從而降低信號源的頻率以避免混疊.在此基礎上,Schoberl 等人[13]計算求得了一組可以達到最小信號頻率混疊和最好圖像分辨率的濾波器參數.除了OLPF 這種前置濾波方法以外,“后處理”的濾波方法也在專業領域得到了應用.
Wei 等人[28]提出了一種從掃描透射X 射線顯微鏡圖像中濾除摩爾紋圖案噪聲的后處理方法.該方法包括使用局部中值濾波器半自動檢測傅里葉振幅譜中的譜峰,以及使用高斯陷波濾波器消除譜噪聲峰值.文獻[30]通過使用DoG 對傅里葉圖像進行濾波,分析圖像中的摩爾紋圖案來識別人臉欺騙.盡管高頻濾波器可以檢測摩爾紋圖案,但它無法將其與其他感興趣的高頻對象區分開,這可能會導致誤報.Sidorov 等人[31]通過研究摩爾紋變形模型,基于圖像傅里葉頻譜幅值的閾值化設計了非線性濾波器,解決通過硬件設備在電影到視頻的數字轉換過程中出現的摩爾紋干擾問題,以減少由于摩爾紋圖案的非平穩性而可能出現的振鈴偽影的影響.基于掃描半色調圖像模型,Sun 等人[33]提出了一種基于自適應濾波的去網紋方法,從掃描圖像中恢復出高質量的連續色調圖像.首先,采用基于圖像冗余的去噪算法來降低打印噪聲和衰減失真;然后,使用掃描圖像的屏幕頻率和局部梯度特征進行自適應濾波;最后,使用邊緣保留濾波器進一步增強邊緣的清晰度,以恢復高質量的連續色調圖像.文獻[28-33]的方法均將摩爾紋當成了一種高頻噪聲,通過去除噪聲的方式達到摩爾紋去除的目的.然而,與噪聲不同的是,摩爾紋圖案廣泛分布在圖像的各個頻帶,傳統的基于圖像濾波的方法并不能完全解決摩爾紋去除的問題.
1.2 圖像插值
拍照設備傳感器表面覆蓋了CFA,傳感器則具有感知光線不同色彩強度的能力,其中每個濾光片僅允許RGB 3 原色中的其中一種顏色通過,即CFA僅僅采集到了原始圖像1/3 的信息量.為了重建原始圖像,需要利用插值的方法恢復另外2 個顏色,這種方法也稱為去馬賽克.通過利用顏色通道之間的相關性,邱菊[16]提出了一種基于圖像色差的插值算法進行圖像摩爾紋的去除,并通過將向量的概念引入到插值算法中實現了RGB 通道的3 維插值,恢復后的圖像更加平滑、更接近實際值.在文獻[16]的基礎上,邱香香[17]則利用自適應方法選擇關聯度高的顏色分量來協助判斷通道插值方向,圖像插值結果更為合理.Hamilton[19]通過計算圖像亮度及色度的相近程度確定針對圖像的插值方法;Kimmel[20]提出了以不同權值為基礎的插值方法,權值與鄰域內邊緣的信息密切相關,每個像素缺失的顏色分量由鄰域內像素的顏色分量按照不同的權值計算得到.此外,Hibbard[18]利用圖像在水平和豎直方向上的亮度和色度差計算梯度,然后將得到的梯度值與事先設定的閾值進行比較來確定針對亮度和色度進行插值的方向,最后根據方向做插值運算.這類方法得到的恢復圖像能夠較好地保留圖像前景部分的邊緣細節特征,但算法實現過于復雜,尤其難以在移動設備中實現.
1.3 圖像分解
另外一類常用的“后處理”即為基于圖像分解實現摩爾紋圖案的消除.Liu 等人[23]提出了一種低秩稀疏矩陣分解模型,實現織物圖像摩爾紋的消除.通過對紋理分量和摩爾紋分量分別進行空域和頻域分析,發現摩爾紋分量分布集中,幾乎不與紋理分量的能量混合,于是對紋理分量添加低秩先驗約束,對摩爾紋分量添加稀疏先驗約束以及在其頻域分布內添加位置約束,從而區分摩爾紋分量和紋理分量.后來,Yang 等人[51]改進文獻[23]所提算法,從數碼相機拍攝織物圖像出現摩爾紋的成像原理入手,發現偽彩色波紋狀的摩爾紋主要存在于R,B 這2 個通道,G通道的摩爾紋分量較少,于是將文獻[23]中的方法應用于G 通道的圖像信息,再通過RGB 三通道間的相關性,借助已經恢復的G 通道圖像,并應用導向濾波算法恢復R,B 通道圖像.Ok 等人[52]提出了一種紙質支票上的摩爾紋消除方法,通過前景提取、摩爾紋檢測和摩爾紋消除等操作提高圖像質量.Yang 等人[24]以摩爾紋和背景圖像是加性關系為前提,并結合屏攝摩爾紋的3 通道成像差異和結構相似性,提出了聯合小波域導向濾波和基于高斯混合模型(Gaussian mixed model, GMM)的多相圖層分解模型以消除屏攝摩爾紋圖案.
屏攝圖像I可以看作是背景圖層B、摩爾紋圖層M以及方差為 σ2的高斯噪聲n的疊加,假設有加性模型[17]為:
該模型引入了2 個基于 GMM 的圖像先驗,分別對背景圖層和摩爾紋圖層進行規則化.于是該問題轉化為最小化問題:
在實際情況下,摩爾紋分量與紋理分量在頻域存在能量混疊,因此基于圖像分解方法容易將紋理信息誤判為摩爾紋成分,紋理恢復圖像中存在輕微的振鈴效應.另外,由于導向濾波算法本身固有的缺陷,容易導致恢復圖像的局部出現光暈現象.
基于傳統信號處理的方法探究了摩爾紋圖案的成因以及相關特性的先驗知識,可以用于特定場景下的摩爾紋圖案自動去除,各類方法的具體對比分析如表1 所示.然而鑒于摩爾紋圖像本身具有分布不規則的特性,傳統方法很難將分布在不同頻段的摩爾紋分量去除干凈,因此該類方法的摩爾紋圖案自動去除性能還需要進一步提升.
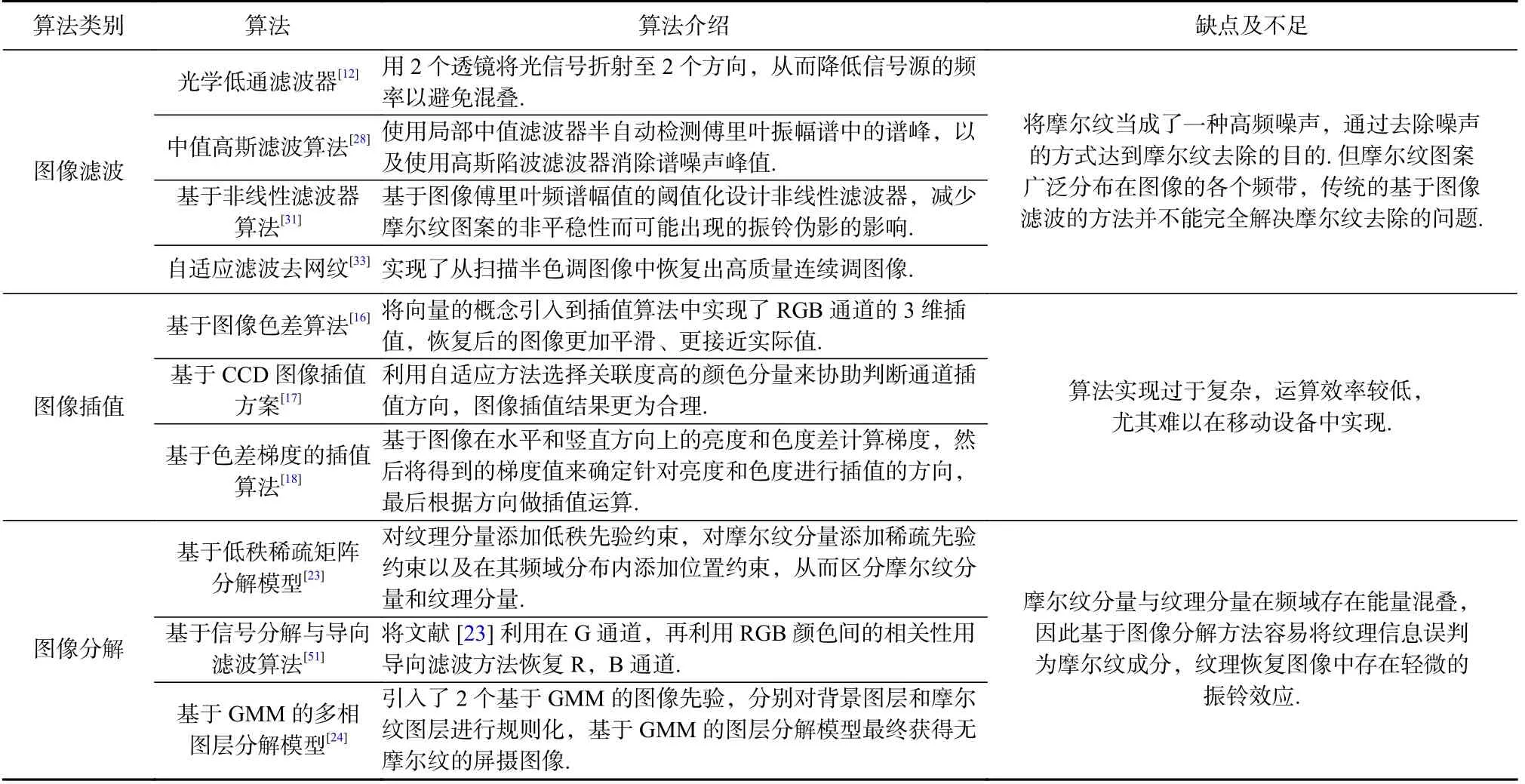
Table 1 Comparative Analysis of the Morié Removal Algorithms Based on Prior Knowledge表1 基于先驗知識的摩爾紋去除算法對比分析
2 基于深度學習的方法
2.1 基于卷積神經網絡(CNN)方法
基于CNN 的摩爾紋去除方法主要包括基于圖像空間域的分析模型和基于圖像頻域的分析模型,以下分別選取具有代表性的網絡結構模型進行介紹.
2.1.1 基于圖像空間域的CNN 模型
由于摩爾紋圖案跨越很寬的頻域范圍,Sun 等人[40]最先嘗試利用CNN 去除摩爾紋圖案,提出了一種基于DMCNN 的摩爾紋去除方法,其網絡結構如圖2 所示.該網絡共有5 個平行的分支,最頂層的分支是在輸入圖像原始的分辨率下處理,下層的分支通過由上層分支做下采樣得到.每個分支分別做各自的卷積操作,最后進行反卷積運算將各個分支的結果上采樣到原始圖像的分辨率后相加,從而得到輸出的恢復圖像.Liu 等人[41]提出了由1 個粗尺度網絡和1 個細尺度網絡組成的2 段式摩爾紋去除方法DCNN(deep CNN),在粗尺度網絡上對輸入圖像做降采樣,利用堆疊的殘差塊去除摩爾紋,然后利用細尺度網絡上采樣至原始的分辨率.

圖2 DMCNN[40]模型架構Fig.2 The architecture of DMCNN[40] model
以DMCNN 為基礎,為了利用不同尺度特征映射之間的關系,Gao 等人[42]提出了一種基于深度學習的多尺度特征增強(multi-scale feature enhancing, MSFE)摩爾紋去除網絡模型,并利用多尺度的結構從多個分辨率上提取與摩爾紋無關的上下文.該方法以U-net網絡模型[53]為基礎,首先利用殘差網絡模塊,將輸入圖像下采樣到4 個不同的尺度中,每個分支在特征增強處理過程中,實現將所在分支的特征與所有低于所在分支分辨率的特征相融合,最后將每個分支利用殘差模塊做上采樣處理,不同分支的采樣結果融合后得到最終的輸出圖像.
針對摩爾紋圖案的頻率分布復雜、顏色通道幅度的不平衡以及外觀屬性不同等特點,He 等人[43]提出了MopNet(Moiré pattern removal neural network)神經網絡模型用于摩爾紋圖案去除,具體包括:
1) 多尺度特征聚合.首先提取圖像的多尺度特征,然后通過級聯[54]和SE (squeeze-and-excitation) 塊[55]進行特征融合.SE 塊通過計算每個通道的歸一化權重來重新加權特征圖,所產生的聚合特征可以用于如下數學方法表示:
其中S E為SE 塊操作,Cat表示串聯,Fi表示從多尺度提取器gm獲得的不同頻帶的特征圖,NUi是用于將特征圖轉換為相同空間大小的非線性上采樣.
2) 信道方向目標邊緣預測器.利用網絡來預測無摩爾紋目標圖像的通道方向邊緣映射Ep,并使用Sobel 算子將每個顏色通道的Esr,Esg,Esb的單獨邊緣映射用于增強源圖像Is,邊緣預測器為
其中ge為信道邊緣預測器,Epr,Epg,Epb表示R,G,B信道的預測邊緣圖.
3) 基于屬性的摩爾紋模式分類器.摩爾紋圖案的精確描述可以更好地指導學習過程,因此,使用多標簽分類器C來描述摩爾紋圖案的頻域C0、顏色C1和形狀C2這3 個外觀屬性,并通過連接3 個上采樣標簽映射獲取屬性信息:
然后將這種模式屬性的預測輸入到目標輸出的推理中,為摩爾紋圖案的外觀提供輔助指導.
MopNet 的所有核心組件都是專為摩爾紋圖案的獨特特性而設計的,包括使用多尺度特征聚合以解決復雜頻率問題、使用通道方向的目標邊緣預測器以檢測顏色通道之間的不平衡幅度,以及使用屬性感知分類器以表征不同外觀,并更好地建模摩爾紋圖案.
為了克服MopNet 以及MSFE 模型存在的多尺度信息交換和融合的不足,Yang 等人[44]提出了一種基于高分辨率的摩爾紋去除網絡(high-resolution deMoiré network,HRDN),以充分探索不同分辨率特征映射之間的關系.HRDN 由3 個主要部分組成:并行高分辨率網絡、連續信息交換模塊和最終特征融合層,其結構如圖3 所示.HRDN 網絡是一種帶有殘差塊的并行多尺度架構,它可以在處理較低分辨率的同時保持全分辨率,并處理不同尺度的不同頻率.為了充分利用不同特征圖之間的關系,HRDN 使用信息交換模塊和最終特征融合層在整個網絡中不斷地交換信息,以充分融合從低層到高層的特征,反之亦然.通常情況下像素損失函數會導致過度平滑,從而減少細節和邊緣紋理.為此,HRDN 通過定義邊緣增強損失函數來保留邊緣細節,L可以表示為

圖3 HRDN[44]模型架構Fig.3 The architecture of HRDN[44] model
其中CLoss表示L1 Charbonnier 損失,S Loss表示L1 Sobel 損失,分別定義為:
其中N代表批量大小,和Y分別表示HRDN 的輸出去摩爾紋圖像和原始背景干凈圖像.
HRDN 模型在圖像分解和圖像融合中都保留了摩爾紋分量在不同尺度下的綜合特征,摩爾紋去除效果有了明顯改進.但是在每一個尺度中,僅通過一系列卷積操作,無法提取完整的特征信息.為此,Cheng等人[45]提出了一種基于多尺度動態特征編碼的摩爾紋去除網絡(multi-scale convolutional network with dynamic feature encoding for image deMoiréing, MDDM).該算法首先利用降采樣的方式將輸入圖像分成6 層尺度,分辨率最高的一層僅做卷積運算,將基于通道的動態特征編碼的殘差模塊作用于從第2 層到第6 層尺度的分支,以實現在復雜的紋理背景下區分干凈圖像與被摩爾紋污染的圖像數據.MDDM 通過動態特征編碼來增強模型處理動態復雜紋理的能力,并將全局殘差學習方法應用于網絡中每個分辨率的分支;它使用殘差塊在每個特征級別和頻帶上模擬干凈圖像和摩爾紋圖像之間的差異,即每個分支上的摩爾紋圖案.在動態特征編碼的過程中,利用自適應實例歸一化(adaptive instance normalization,AdaIN)方法[56]將額外的旁路分支引入至每個主干尺度分支中,以對不同空間分辨率的圖像特征進行編碼.具體地,在AdaIN 中,首先計算特征圖的均值和方差:
其中H和W分別表示特征圖的高度和寬度,和是動態特征編碼分支中第i個編碼層的特征xenc的均值和方差.在計算摩爾紋圖案的統計值后,MDDM 使用這些值通過AdaIN 動態調整主干分辨率分支的參數:
其中 μi和表示來自主干分支的統計信息,xi表示來自主干分支中第i個殘差塊的特征圖.
在MDDM 的基礎上, Cheng 等人[46]又進一步提出了改進的MDDM+模型.整個網絡由原來的6 個分支減少為3 個分支,每個分支中基于通道的動態特征編碼的殘差模塊的數目保持一致,這樣可以大幅度減少存儲模型所需的參數數目,同時也改進了模型在不同分辨率的尺度間參數不平衡的現象.另外,考慮到摩爾紋的頻域分布特征,引入了基于小波分解的特殊損失函數,即分別對網絡的輸出圖像和ground truth 圖像I做小波變換,小波損失表示為
其中N表示一個批量大小, ε為一個常數, ε=E-6,W即小波分解操作.
綜上,除了將單幅圖像作為輸入外,Liu 等人[1]提出了一種基于多幀及多尺度的摩爾紋圖案去除(multiframe and multi-scale for image deMoiréing, MMDM)網絡.MMDM 使用多幅圖像作為輸入,多尺度特征編碼模塊用于低頻信息增強.MMDM 有3 個關鍵模塊:新設計的多幀空間變換網絡(multiframe spatial transformer network, M-STN)、多尺度特征編碼模塊(multiscalefeature encoding module, MSFE)和增強非對稱卷積塊(enhanced asymmetric convolution block, EACB).其中M-STN 自動對齊相同場景下的多幀輸入圖像,MSFE用于多頻率信息的提取,最終EACB 用于圖像的重建.在NTIRE2020(New Trends in Image Restoration and Enhancement 2020)挑戰賽中,本方法在摩爾紋去除賽道上獲得第2 名.
2.1.2 基于圖像頻域的CNN 模型
除了針對摩爾紋分量在空域上的分布特征展開研究外,一些學者還嘗試提取摩爾紋分量在圖像頻域內的特征并進行摩爾紋去除[47,57-61].Zheng 等人[47]認為摩爾紋去除的過程可通過式(12)表示
其中Imoire與Iclean分別為包含摩爾紋的污染圖像和去除摩爾紋后的干凈圖像,Nmoire為污染圖像中的摩爾紋分量,ψ-1是ψ的反函數,即將污染圖像中的顏色色調恢復為原始干凈圖像色調.基于此理論提出的基于多尺度帶通CNN(multi-scale bandpass CNN, MBCNN)網絡分別解決了2 個子問題:1)紋理恢復問題.在摩爾紋紋理去除模塊(Moiré texture removal block,MTRB)中集成了一種可以學習的帶通濾波器,以學習去除摩爾紋前后的頻率特征.2)顏色恢復問題.首先利用全局色調映射模塊(global tone mapping block,GTMB)校正圖像的全局色彩,然后利用局部色調映射模塊(local tone mapping block, LTMB)對局部色調逐個進行像素級別的微調.模型首先將輸入圖像分成4 個大小相等的子圖像,網絡結構由3 個分支構成,每個分支依次執行特定比例的摩爾紋去除和色調映射,最終輸出上采樣后的圖像,并與上層分支融合.在前2 個分支中,將當前分支的特征與下一層分支的輸出結果相融合,然后再進行一系列的色調處理和摩爾紋去除,以消除因縮放操作引起的紋理和顏色錯誤.
摩爾紋分量Nmoire表示為

圖4 原始的及改進的MTRB 模型架構Fig.4 Architecture of original and of improved MTRB models
在損失函數中引入了改進的Sobel算子損失(advanced sobel loss, ASL),定義為
在提取摩爾紋分量特征時,MBCNN 中的每個摩爾紋去除模塊都用一組相同的權值作用于經過一系列卷積運算得到的頻譜中.鑒于摩爾紋的多尺度頻域分布特征,Zheng 等人[60]在原有的MBCNN 基礎上做了2 方面改進,這里稱為MBCNN+:
1) 將摩爾紋去除模塊MTRB 中帶通濾波器LBF 變為基于不同塊大小的帶通濾波器(multi-blocksize LBFs),即由原來經過k個擴張卷積運算后的結果進行最終的一次頻域反變換,轉變為每一次擴張卷積操作后都進行一次頻域反變換,以達到學習摩爾紋分量不同尺度、不同頻域特征的目的,最后將k個不同尺度結果累加后送入FSL,改進后的MTRB+結構如圖4(b)所示.
2) 在計算損失函數時,由原來的ASL運算變為基于不同擴張尺度的ASL,即DASL:
Liu 等人[61]設計了一種基于小波域的雙分支網絡(wavelet-based dual-branch network,WDNet).Liu 等人認為在頻域中更容易去除摩爾紋圖案,首先使用小波變換將包含摩爾紋的輸入圖像分解為不同的頻帶;經過小波變換后,摩爾紋在某些小波子帶中更加明顯,在這些子帶中,摩爾紋更容易去除.該模型具有密集分支和擴張分支的雙分支網絡,分別負責恢復近距離和恢復遠距離信息.同時,WDNet 還設計了一種空間注意力機制,稱為密集分支中的方向感知模塊,以突出具有摩爾紋圖案的區域.
2.2 基于生成式對抗網絡(GAN)方法
流行的基于監督學習的方法需要大量的成對訓練圖像,這在實際應用中難以獲取和對齊.為此,基于GAN 的非監督學習方法被應用于摩爾紋去除[48-50].Yue 等人[49]提出了一種無監督的生成式對抗性摩爾紋去除網絡(unsupervised generative adversarial network for Moiré removal,MR-GAN),這是基于無監督學習的摩爾紋去除的首次嘗試,為使用未配對的訓練數據進行無監督摩爾紋去除開辟了一條途徑.
具體地,在進入網絡訓練之前,首先根據圖像不對稱的徑向梯度分布[64]去除摩爾紋圖像中存在的暈角,校正后的圖像亮度比原始屏幕拍攝圖像更加均勻.在MR-GAN 網絡中存在2 個生成器,即摩爾紋去除生成器和摩爾紋重構生成器.摩爾紋去除生成器Gm→c是將一幅摩爾紋圖像Im轉化成相應的干凈圖像;摩爾紋重構生成器Gc→m是將一幅干凈的圖像轉化為摩爾紋圖像.Gm→c和Gc→m形成一個循環,并受到循環一致損失的約束,以在沒有訓練對的情況下同時訓練生成器Gm→c和Gc→m.這2 個生成器具有相同的網絡結構,核心結構均是9 個殘差模塊的堆疊.同時,網絡同樣存在2 個結構相同的鑒別器:在大尺度上鑒別摩爾紋圖像與干凈圖像,在小尺度上鑒別摩爾紋圖像與干凈圖像,核心結構是數個卷積層+ NL(non-local)層[65]+Leaky ReLUs 的堆疊,最后再加1 層卷積.為了訓練MR-GAN,集成了許多損失函數來學習真實的無摩爾紋圖像生成器和有效的鑒別器,具體包括:
1) 生成器的損失函數.為了在沒有真實監督的情況下學習有效的生成器,該方法首先提出了一組自我監督的損失函數?self,包括在像素級別 ?pcyc和特征級別 ?fcyc的循環一致損失、身份損失 ?idt、余弦相似度損失?cos以及內容泄漏損失 ?cl.因此,自監督損失表示為
其中 λ1, λ2, λ3, λ4, λ5分別為加權參數.另外,與傳統的對抗性損失不同,該方法提出了一種雙尺度對抗性損失分別對應于MR-GAN 中的2 個鑒別器組.為了確保網絡在訓練中穩定,利用 LSGAN 損失函數[66]定義大尺度特征的對抗損失:
其中?self確保生成的結果包含足夠的原始信息,和指導生成器得到預期結果.
Park 等人[50]提出了一種基于端到端的非對稱循環網絡(an end-to-end unpaired cyclic network,EEUCN),該方法使用未配對的摩爾紋圖像和干凈的圖像數據集.令 χ和 γ分別表示摩爾紋圖像集和干凈圖像集,X∈χ和Y∈γ分別表示摩爾紋圖像和干凈圖像,未配對圖像去摩爾紋的目標就是學習從摩爾紋圖像到干凈圖像之間的映射.如圖5 所示,EEUCN 網絡由2 種類型的GAN 組成:圖5(a)所示的摩爾紋生成網絡和圖5(b)所示的摩爾紋去除網絡.摩爾紋生成網絡主要學習映射GM:γ →χ,通過添加摩爾紋偽影來降低干凈圖像質量;摩爾紋去除網絡則是學習映射GD:χ →γ,以從摩爾紋圖像中去除摩爾紋偽影干擾.摩爾紋生成問題可以分為像素強度退化和摩爾紋圖案生成2 個子問題,相應地,屏攝摩爾紋圖像生成器模型GM可以表示為
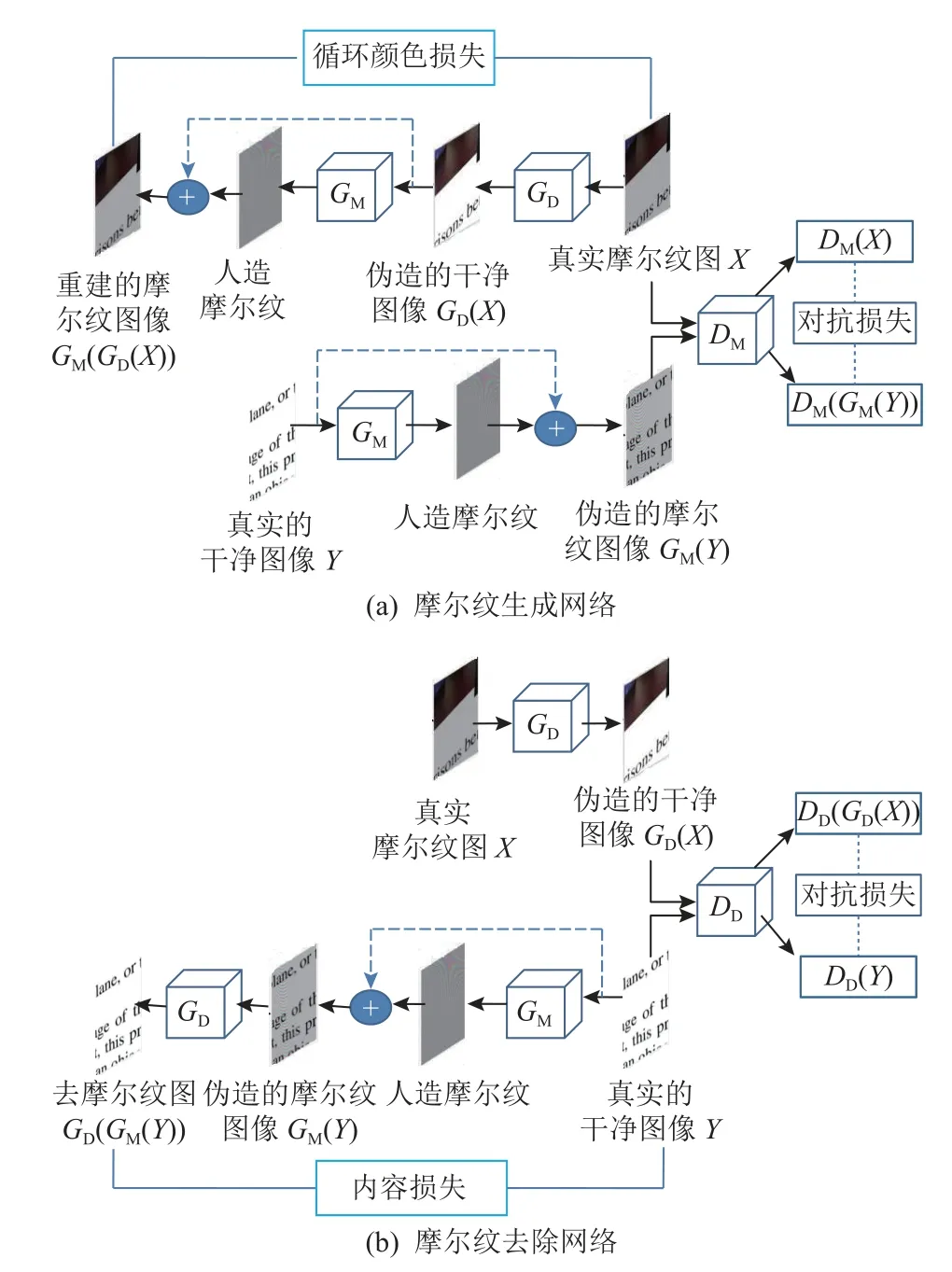
圖5 EEUCN[50]結構Fig.5 The architecture of EEUCN[50]
其中m表示摩爾紋圖案, α用于控制圖像對比度降低的幅度,α ∈(0,1].給定一張干凈的圖像Y,強度退化模塊估計全局強度退化參數α,而摩爾紋生成模塊生成摩爾紋圖案m.
摩爾紋生成網絡構造完偽配對集{γ,GM(γ)}后,EEUCN 利用學習的生成器GM以有監督方式訓練摩爾紋去除網絡,并進行摩爾紋圖案去除,如圖5(b)所示.相應地,摩爾紋去除模型GD可以表示為
因此,類似于上述摩爾紋生成網絡,摩爾紋去除問題也可以分為2 個子問題:摩爾紋偽影去除和全局強度恢復.給定摩爾紋圖像αY+m,摩爾紋去除模塊去除摩爾紋圖案m,強度恢復模塊估計全局強度恢復參數 α.
在EEUCN 中,摩爾紋生成網絡是在已知GD的情況下訓練GM,網絡中的鑒別器DM用于區分真實的摩爾紋圖像與網絡生成的摩爾紋圖像;反之,摩爾紋去除網絡是在已知GM的情況下訓練GD,網絡中的鑒別器DD用于區分真實的干凈圖像與網絡去除摩爾紋后的圖像.2 個網絡的整體結構比較類似,主要區別在于循環顏色一致性是在Y和GD(GM(Y))之間計算的,即所謂的內容損失.具體地,在摩爾紋生成網絡中,循環顏色損失?cycle被定義為重建的摩爾紋圖像和原始摩爾紋圖像之間的 ?1范數,由式(22)給出:
不同于生成網絡,額外的循環損失ASL運算被用于訓練摩爾紋去除網絡,由式(23)給出:
其中Si(·)表示水平、垂直和2 個對角濾波器中Sobel濾波中第i個濾波器得到的邊緣圖.因此,式(23)中的?AS L量化了重建圖像和原始干凈圖像的邊緣圖之間的循環顏色一致性.由于自然圖像包含有意義的邊緣信息,ASL運算用于去除已被檢測為虛假邊緣的摩爾紋偽影.由于摩爾紋圖像的邊緣圖包含大量噪聲,對應于摩爾紋偽影,很難區分真實的和生成的摩爾紋圖像的邊緣圖.因此,EEUCN 只使用ASL運算來訓練摩爾紋去除網絡.
3 訓練數據集構建
摩爾紋去除網絡模型的訓練數據集質量在很大程度上影響了深度學習方法的處理性能,因此訓練數據的收集和對齊工作也至關重要.現實生活中人們通常會通過屏幕拍照和屏幕錄像的方式獲取屏攝圖像,而將視頻文件一般轉化為帶有摩爾紋圖案的圖像幀序列,因此本文主要聚焦于屏攝圖像中的摩爾紋圖案去除研究.目前摩爾紋圖像訓練數據集的構建主要從正向和反向2 個角度展開.所謂正向構建是指通過手機設備拍攝電子屏幕得到包含摩爾紋的屏攝圖像,然后利用圖像處理方法將屏攝圖像進行矯正預處理,并將預處理后的摩爾紋圖像與原始的干凈圖像對齊形成圖像對,例如TIP2018 數據集[40]與MRBI 數據集[67].反向構建方式是指利用馬賽克采樣、重上色等操作處理原始的干凈圖像得到被污染的圖像,用于模擬摩爾紋圖案生成,從而形成干凈圖像和摩爾紋圖像的圖像對,例如在多個國際大型的摩爾紋圖像去除競賽中用到的LCD Moiré數據集[68]及CFA Moiré數據集[69].表2 為4 種數據集間的對比和總結,下面分別對這4 種訓練數據集的構造過程進行簡要介紹.
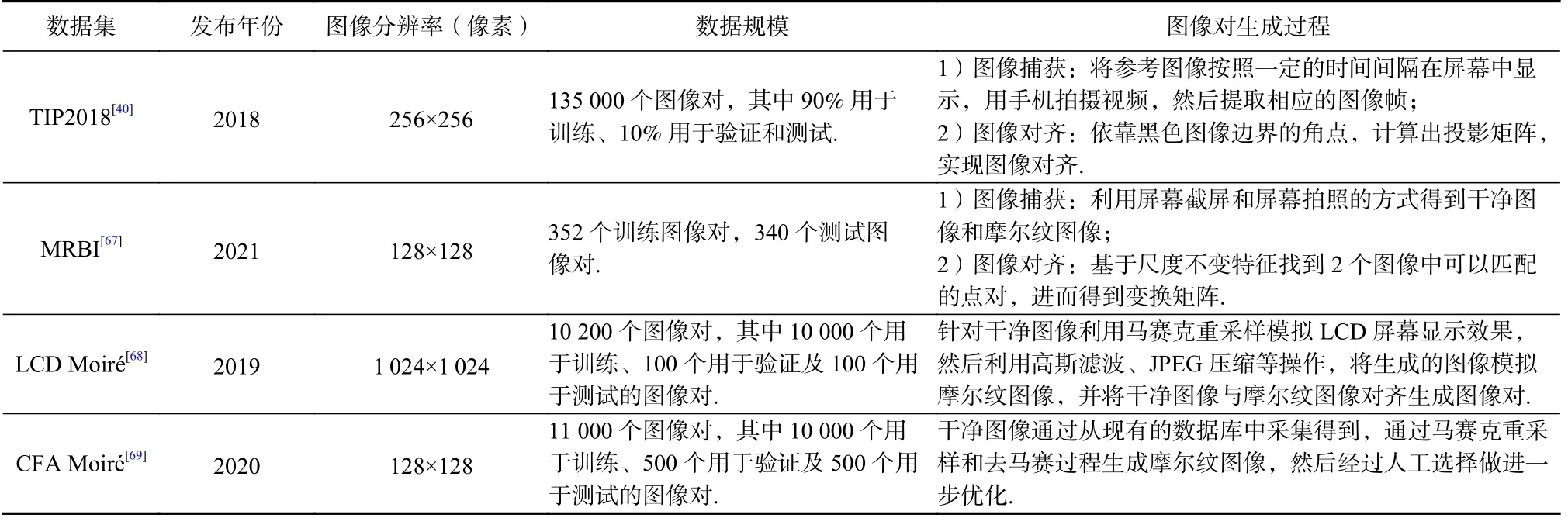
Table 2 Summary and Comparison of Different Training Datasets表2 不同訓練數據集的總結對比
TIP2018 數據集主要包含135 000 個圖像對,每個圖像對包含1 幅被摩爾紋污染的圖像及其對應的未污染參考圖像,其中未受污染的參考圖像來自ImageNet ISVRC 2012 數據集的100 000 幅驗證圖像和50 000 幅測試圖像.在所有圖像中,90%用作訓練集,10%用于驗證和測試.收集這些數據的流程如圖6所示,主要包括2 個步驟:圖像捕獲和圖像對齊.1)圖像捕獲.如圖6(a)所示,每個參考圖像T用黑色邊框增強并顯示在計算機屏幕的中心位置,以最大程度減小受摩爾紋效應的影響.為了增加圖像對齊過程中可以使用的角點數量,該方法進一步從黑色邊框的每條邊擠出一個黑色塊,并用純白色填充黑色邊框(和塊)之外的屏幕其余部分,這使拍攝者能夠輕松地檢測捕獲圖像中的黑色邊框.在圖像采集過程中,拍攝者使用不同型號的智能手機和顯示器屏幕設備,并隨機改變手機和計算機屏幕之間的距離和角度,確保在不同的光學傳感器上捕捉到的摩爾紋圖案S具有多樣性.為了提高圖像捕獲效率,將參考圖像T按照一定的時間間隔在屏幕上連續顯示,并使用手機記錄連續顯示圖像的視頻,然后將拍攝視頻中的幀提取為摩爾紋圖像.2)圖像對齊.實際上,該方法依靠沿著黑色圖像邊界的角點來完成圖像對齊,捕獲圖像S和參考圖像T中的對應點通過單應性關聯,并用具有 8 個自由度的 3×3 投影矩陣表示.為了提高配準精度,附加到圖像邊界的4 個黑色塊將非共線對應點的數量從4 個增加到20 個,利用這些角點來計算投影矩陣,并進一步對齊每對圖像.為了檢測角點,屏攝圖像首先進行二值化處理,利用傳統Harris 角點檢測方法沿黑色圖像邊界的最外邊界搜索角點.然而,由于摩爾紋偽影的存在,圖6(b)所示的20 個角點有時無法可靠地被檢測到,其中某些邊緣像素可能被錯誤地檢測為角點.經過額外的假角點和重復角點消除處理后,所有的20 個角點都可以被成功檢測到,如圖6(c)所示.最后,通過計算出的投影矩陣,該方法可以對齊每個圖像對,配準結果如圖6(c)(f)所示.TIP2018 數據集是第一個被大規模用于摩爾紋去除網絡的訓練數據集,后續很多工作都是基于該數據集進行算法優化和對比評測.

圖6 圖像采集[40]Fig.6 Image acquisition[40]
文獻[67] 指出TIP2018 數據集在視頻模式下錄制往往會使重新捕獲的幀變亮,這使得圖像對之間的亮度差異很小,這與實際的屏幕拍攝圖像效果不符.此外,為了應用圖像對齊算法,TIP2018 數據集中的參考圖像被要求顯示在平板顯示器的屏幕中心位置(以能夠拍攝全部的黑色邊區域),這也限制了摩爾紋圖像的種類.為了克服上述缺陷,文獻[67]通過5 種不同型號的智能手機拍攝3 種不同類型的顯示器屏幕如筆記本電腦、臺式電腦的LED 顯示屏以及電視的LCD 屏來構建MRBI 數據集,其訓練集包含352 幅重新捕獲的帶有摩爾紋偽影的屏幕圖像和相應的原始圖像(通過屏幕截圖獲得).測試集包含由24 種屏幕和相機組合捕獲的 340 幅圖像,它們代表了各種各樣的摩爾紋圖像.具體地,在創建訓練圖像對時,首先對相同內容的屏幕分別通過屏幕截屏和屏幕拍照得到干凈圖像Io和包含摩爾紋的圖像Im;接著對Im縮放使Io和Im這2 幅圖像大小相似;然后利用基于尺度不變的特征變換(scale-invariant feature transform, SIFT)[70]找到2 幅圖像中可以匹配的一系列點構成點對的集合 Ω;然后,隨機從 Ω中選出4 個點對,用RANSAC 算法[71]估計Io和Im之間的變換矩陣H, Ω中的其他點對用于驗證H的準確性.驗證方式是點與的距離是否小于預先設置的閾值 ε,若是,則點對與被稱之為內點.重復上述過程直到所求的變換矩陣H滿足使 Ω中內點的數目最多.最后對Io做矩陣為H的變換得到一個訓練圖像對.通過上述方法構造的MRBI 數據集為圖像去摩爾紋和亮度改善提供了基準,并將會激發更多關于這一主題的工作.
LCD Moiré數據集[68]包含10 200 個合成生成的圖像對(由摩爾紋退化的圖像和干凈的原始圖像組成,10 000 對用于網絡訓練、100 對用于驗證及100對用于測試),是專門為舉辦首次圖像去摩爾紋挑戰賽而創建的.該挑戰賽是與ICCV 2019 聯合舉辦的圖像處理進展(Advances in Image Manipulation,AIM)研討會的一部分.LCD Moiré數據集中的干凈圖像是從ICCV(IEEE International Conference on Computer Vision),ECCV(European Conference on Computer Vision),CVPR(IEEE Conference on Computer Vision and Pattern Recognition)等計算機視覺會議論文中收集,由文本、圖形或等比例組合的文本/圖形組成.摩爾紋圖像的生成相當于模擬使用智能手機在顯示干凈圖像的LCD 屏幕上拍照的過程.具體的思路為:經過RGB圖像的馬賽克重采樣處理,以模擬LCD 屏幕顯示圖像;對圖像應用隨機投影變換以模擬顯示器和相機的不同相對位置和方向,并應用3×3 高斯濾波器;使用Bayer CFA 對圖像重新采樣以模擬原始數據,并添加高斯噪聲以模擬傳感器噪聲;應用簡單的ISP 處理,包括去馬賽克(雙線性插值)和去噪;使用JPEG 壓縮來壓縮圖像以模擬壓縮噪聲,將干凈圖像與摩爾紋圖像對齊,并裁剪出圖像對.為了確保訓練、驗證和測試圖像集中的內容和摩爾紋圖案分布相同,該方法附加了圖像內容平衡和摩爾紋分量平衡等后處理操作.
2020 年,CVPR 的圖像恢復增強競賽(NTIRE)提供了一個新的摩爾紋圖像訓練數據集CFA Moiré Dataset[69],該數據集由10 000 個訓練圖像對、500 個驗證圖像對和500 個測試圖像對組成.其中干凈的圖像從現有的圖像數據庫中采集或者裁剪后得到,圖像質量較高,內容涵蓋了服裝、建筑等高頻重復圖案.相應的摩爾紋圖像通過馬賽克重采樣和去馬賽克過程生成,其中摩爾紋偽影圖案出現在圖像高頻區域.數據集構建分為2 步:首先,通過傅里葉頻域中摩爾紋偽影的量化自動選擇符合條件的圖像對,即測量清潔圖像和去馬賽克圖像之間的頻率變化;然后,通過人工選擇進一步優化選擇的圖像對,將已經被污染的干凈圖像從數據集中刪除.
4 實驗對比分析
隨著不同拍攝設備和顯示設備的廣泛普及,摩爾紋圖像的呈現也趨于多樣化.由于摩爾紋圖案不規則,且不均勻地分布在圖像中的不同空域及不同頻域段中,其分布特征無法通過先驗知識準確獲取.另外,當摩爾紋分量與圖像中的紋理分量出現混疊時,基于先驗知識的圖像處理方法無法將其準確區分,因此基于特定先驗知識的傳統圖像處理方法在摩爾紋去除方面愈加受限.而在訓練數據集構建逐漸完善的情況下,深度學習方法的處理性能更加顯著,并逐漸成為主流方法.目前的神經網絡模型主要利用CNN 卷積神經網絡模型和GAN 對抗網絡,通過提取空域或頻域中的特征信息達到摩爾紋去除的目的.本節主要將基于深度學習的摩爾紋圖案去除方法進行簡單回顧總結,并分別對各種方法的優缺點進行定性的對比分析.另外基于相同的公開數據集,我們選取了部分代表性工作進行了算法實現,并給出了定量的性能對比結果.
4.1 深度學習方法對比分析
首先,在基于CNN 空域算法中,DMCNN[40]模型和DCNN[41]較早地將深度學習方法應用于摩爾紋圖像去除,并實現了不同分辨率分支下的特征提取.由于摩爾紋不規則地分布在圖像的多個頻段中,因此,提取圖像的多尺度特征信息成了學者們的共識.但是此類方法在每一個尺度上提取的特征過于簡單,且忽略了不同尺度特征之間的聯系,因此具有一定的局限性.例如:當圖像中出現大面積彩色條紋分布的摩爾紋時,摩爾紋去除的效果不理想.MSFE[42]模型是基于DMCNN 提出的,其明顯的缺陷是僅僅將低分辨率的特征嵌入到了高分辨率特征中,而高分辨率的特征沒有融合進低分辨率的特征中,因此對比DMCNN 模型優勢不明顯.相對于DMCNN 而言,MopNet[43]考慮了更多的摩爾紋圖案的不同屬性特征,但是沒有綜合分析這些特征在多個不同尺度間的聯系,而且針對邊界的提取無法獲得復雜的紋理特征.因此,MopNet 無法準確區分出污染圖像中的紋理區域和摩爾紋區域.HRDN[44]在上采樣和下采樣的過程中針對不同的尺度做了較為充分的信息交換,但每個尺度中提取的特征信息不夠充分.MDDM[45]模型的分層數目過多,各個尺度之間仍然缺乏信息的交互,同樣存在低分辨率分支中沒有融合進高分辨率信息的現象.并且高分辨率的分層卷積數目少,低分辨率的分層卷積數目多,理論上應該反過來,因為高分辨率的分支擁有更多的特征.相較于MDDM,改進后的模型MDDM+[46]不僅視覺效果得到明顯的改善,而且存儲的參數數量由8.01 MB 變為3.57 MB,實用性進一步提高.但相較于HRDN 模型,MDDM+仍存在各分支間缺少信息交互的特點.
在基于CNN 頻域算法中, MBCNN[47]在提取摩爾紋分量DCT 頻域特征時,每個摩爾紋去除模塊可以根據多尺度頻域特征采用不同的權值.相對于MBCNN,MBCNN+[60]在網絡結構設計和損失函數中改進了不同尺度特征提取和融合的方式,因此取得更好的輸出圖像視覺效果.WDNet[64]則是基于小波域實現,與傅里葉變換和離散余弦變換相比,小波變換既考慮了空間域信息,又考慮了頻域信息.在小波合成中,不同的小波帶代表如此廣泛的頻率范圍,這是幾個卷積層即使是大核也無法實現的.
基于GAN 的摩爾紋圖案去除方法是最近2 年提出的,較好地解決了CNN 方法依賴大量對齊的訓練對的問題.該類方法的處理性能跟CNN 方法相比還有一定的差距,但為摩爾紋圖案去除方法研究提供了一種新的思路.
綜上所述,不同的網絡模型架構具有各自的優勢和劣勢,具體的對比分析如表3 所示.
4.2 實驗結果討論
在本節中,我們基于相同的公開的數據集,分別選擇不同類別中有代表性的方法進行了算法實現和性能對比實驗.CNN 空域算法模型選擇:首次使用的DMCNN[40]訓練模型;融合多尺度特征聚合、信道方向目標邊緣預測器和模式分類器的MopNet[43]訓練模型;不同尺度間特征能夠較充分融合的HRDN[44]訓練模型.在CNN 頻域算法模型方面,我們選取了基于DCT 頻域特征信息提取的MBCNN[47]訓練模型.相應地,在GAN 網絡模型中,我們選取了目前性能最好的EEUCN[50]模型.測試環境為torch1.8.0,GPU3090,數據集選用TIP2018 數據集.在摩爾紋圖案去除算法性能的評估方面,我們采取了類似ICCV 2019 AIM[69]和2020 CVPR NTIRE[70]競賽的評判規則,分別計算了在TIP2018 數據集上取得平均的PSNR值和SSIM 值.
首先,在模型預處理階段,我們在Sun 等人[40]預處理方法的基礎上,對TIP2018 數據集中的摩爾紋圖像進行了重采樣和歸一化處理.為了保證每個模型訓練數據的一致性和公平性,我們加載了MopNet[43]的預訓練模型對上述數據再次進行預處理操作,預處理后的圖像樣本尺寸統一為256×256 像素.據此,我們分別針對不同的網絡模型采取不同的訓練方式.
1) DMCNN 方法.使用Adam 優化器,學習率設置為0.000 1,當損失不下降時縮減學習率為原來的90%,共計訓練50 個epoch.
2) MopNet 方法.訓練模式分為2 個階段: 第1階段,訓練邊緣提取模型和分類模型直到模型收斂,2 個模型分別訓練50 個epoch 和20 個epoch;第2 階段,使用Adam 優化器,學習率最初設置為0.000 2,并隨著訓練線性衰減,共計訓練150 個epoch.
3) HRDN 方法.使用Adam 優化器,學習率設置為0.000 1,當損失不下降或每訓練10 個epoch 時下降為原來的50%,共計訓練50 個epoch.
4) MBCNN 方法.使用Adam 優化器,學習率設置為0.000 1,共計訓練100 個epoch.
5) EEUCN 方法.使用AdamW 優化器,學習率設置為0.000 1,在訓練100 個epoch 后,學習率縮減為原來的10%,共計訓練150 個epoch.由于EEUCN 是使用unpair 數據集的方法,我們基于文獻[50] 提供的LCD Moire 上非成對的數據集進行訓練,并使用TIP2018 數據集進行測試.
不同的訓練模型在TIP2018 數據集上取得平均的PSNR 值和SSIM 值如表4 所示,其中部分圖像在不同模型上得到的去除摩爾紋圖像效果如圖7 所示.

Table 4 Quantitative Comparison of Different Network Models表4 不同網絡模型的容量對比

圖7 在TIP2018 驗證數據集上的對比結果Fig.7 Comparison of results for the validation set in TIP2018
如表4 和圖7 所示,DMCNN[40]是利用多尺度卷積神經網絡去除摩爾紋圖案的初步嘗試,在摩爾紋分量的去除和圖像色調恢復方面,相比其他模型而
言,該模型輸出結果不太理想.EEUCN[50]是利用GAN 網絡去除摩爾紋圖案的嘗試,其思想是先利用摩爾紋生成網絡在干凈的圖像中添加摩爾紋圖案,然后利用監督學習方法去除摩爾紋圖案.由于模擬生成的摩爾紋圖案與真實的摩爾紋圖案之間存在一定的差異,當訓練數據集和測試數據集不同時,該模型輸出的去摩爾紋圖像存在較大的顏色失真,例如圖7(g)所示的第8 幅圖像中的多個顏色分量被誤刪除.諸如MopNet[43],HRDN[44],MBCNN[47]等有監督的多尺度卷積神經網絡則可以得到較理想的圖像質量.但由于MopNet 僅通過邊界提取區分摩爾紋分量與圖像分量,導致如圖7(d)中第4 幅圖像的前景區域、第5 幅圖像的人臉區域、第6 幅圖像的翅膀區域、第9 幅圖像的瓢蟲區域等局部摩爾紋圖案去除不干凈,另外第8 圖像中的復雜區域則產生嚴重的色調失真.HRDN 在特征提取和融合階段具有相對充分的信息交換過程,在TIP2018 數據集中取得較高的PSNR 值和SSIM 值.但由于該模型中各尺度特征提取不夠充分,當處理包含特殊的復雜摩爾紋圖案時,HRDN 方法處理的圖像視覺效果不很理想,如圖7(e)中的第2 幅、第6 幅中出現了形狀復雜的彩色摩爾紋圖案,HRDN 未能準確提取出摩爾紋分量.MBCNN 通過提取摩爾紋圖像的頻域特征,并進行頻域中摩爾紋分量去除,同時融入了色調恢復過程,則在有監督學習的卷積神經網絡模型中取得了較為理想的視覺效果.其中SSIM 值明顯高于其他模型,則說明該模型輸出去除摩爾紋圖像在亮度、對比度、結構上與原始干凈圖像保持較好的一致性,如圖7(f)所示,MBCNN能夠較好地處理各種復雜特殊的摩爾紋圖案.
5 總結與展望
圖像去摩爾紋是一項重要的圖像修復任務,其目的是從污染圖像中去除摩爾紋干擾圖案并恢復底層干凈的圖像.傳統的基于先驗知識的方法具有算法效率高、不需要大規模訓練等優點,能夠較好地處理頻域或空域分布特征相對簡單的摩爾紋圖案.比如當利用智能手機或者數碼相機拍攝布料、織物、瓷磚等高頻重復紋理靜態圖案時,在頻域中摩爾紋的能量是集中的,與圖像的紋理能量有一定的差距.因此,基于圖像分解的方法則可以更好地分離2 種不同能量,進而有效去除摩爾紋圖案.對于掃描的半色調圖像而言,摩爾紋圖案可能會呈現周期性的網紋干擾性質,利用傳統圖像濾波的方法性能可能會更好;基于圖像差值的方法在去除摩爾紋圖案的同時,可以更好地恢復圖像亮度信息和色彩空間信息.
然而,與圖像去噪任務中均勻分布的噪聲和超分辨率任務中缺失的高頻細節不同,屏幕拍攝的摩爾紋圖案具有廣泛分布的頻譜和復雜紋理的動態特性,這使得圖像去摩爾紋任務面臨著巨大挑戰.傳統的基于信號處理的摩爾紋去除方法需要基于特定的先驗知識和模型,因此圖像修復效果存在較大的提升空間.基于深度學習的摩爾紋去除方法則通過在不同尺度上探究摩爾紋圖案和背景圖像之間的內在相關性,并考慮不同尺度之間的特征融合,在圖像質量改善方面取得較好的性能.但是基于CNN 的網絡模型需要大規模的摩爾紋污染圖像和原始干凈圖像的訓練集對的支撐,數據集構造的質量也會嚴重影響算法性能,而相關數據集對的構造難度較大,在很多情況下無法完成.綜上,針對目前摩爾紋圖案去除方法存在的問題,為了進一步提高網絡模型的實用性,以下3 個技術方向值得進一步關注.
1) 摩爾紋成因描述模型構建
在早期階段,人們對于摩爾紋的研究大多基于數學模型,從摩爾紋的成因出發,研究摩爾紋的頻域和空域特征.不同的成像模式也會造成摩爾紋特性表現的差異,通過對摩爾紋成因的深入研究,我們可以構建更為準確的摩爾紋消除模型.一方面,摩爾紋成因分析有利于特定場景下的摩爾紋圖案去除.劉芳蕾[21]通過對紋理圖像中摩爾紋分量的頻域稀疏特性和紋理分量的空余低秩特性的分析,構建圖像分解模型實現了紋理層與摩爾紋的分離.張雪[22]針對屏攝圖像中摩爾紋能量分布非常分散、高頻信息難以區分等特點,并結合屏攝摩爾紋和圖像背景的結構性差異,提出了基于GMM 的多相圖像分解方法,在保留背景圖像結構的同時擾亂摩爾紋結構,從而避免塊效應并降低算法的時間復雜度.另一方面,精確的摩爾紋成因描述模型也可以輔助深度學習模型的訓練,促進網絡結構優化,提升摩爾紋圖案消除算法性能.鑒于摩爾紋圖案的復雜特性和成因差異,現有描述摩爾紋成因的數學模型缺乏通用性,需要未來進一步的深入研究.
2) 真實場景下的通用摩爾紋去除網絡研究
目前基于深度學習的摩爾紋圖案去除網絡大都是采用實驗室環境下采集和模擬生成的數據集進行訓練和評估的,在某些情況不能完全適用于現實場景中具有復雜特征的污染圖像,模型泛化性能較低.由表2 可知,規模最大的TIP2018 數據集最接近于真實場景下的摩爾紋圖案效果,但其圖像采集過程也存在圖像分辨率低、摩爾紋場景簡單、拍攝角度單一等問題.而實際需要處理的摩爾紋圖案往往具有分辨率高,且摩爾紋顏色、形狀、邊界、密度等復雜多變的特點.為此,我們需要從以下方面展開深入研究,以探索真實場景下的摩爾紋圖案去除方案:①利用人工智能和計算機視覺技術,在真實場景下構建更大規模的摩爾紋圖案數據集,包含不同分辨率、不同場景、不同摩爾紋強度等多種特征;②充分探索不同分辨率特征映射之間的關系,將不同尺度下的摩爾紋顏色、形狀、邊界、密度等多種特征信息進行融合和交換,然后通過學習和解耦得到更加通用的摩爾紋圖案相關語義特征,而忽略無關特征,從而構建高效和高魯棒的通用摩爾紋去除網絡模型結構;③基于對抗神經網絡GAN 的訓練模型,在網絡生成器和鑒別器中引入基于多尺度特征融合的CNN 卷積神經網絡,將會成為摩爾紋去除技術的一個重要研究方向.
3) 基于移動終端的泛化應用拓展
隨著移動互聯網技術的飛速發展和智能移動終端設備的全面普及,利用智能移動終端進行信息捕獲、處理、存儲和共享等成為主流應用方式,比如圖像美化[72]、OCR 識別[73]和水印提取[74]等.由于屏攝圖像中通常會受到摩爾紋干擾圖案的嚴重干擾,基于移動終端的摩爾紋去除應用存在諸多不足之處:①硬件設備的多樣性和不同設備之間的差異性導致了摩爾紋圖案的頻域特征分布更加不規則,深度學習網絡模型的泛化性能普遍較低;②現有的基于深度學習的摩爾紋去除網絡模型大多都是部署在服務器端,其網絡結構復雜、訓練數據龐大、計算資源配置高,較難直接部署于計算能力有限的移動終端設備;③深度學習算法與移動終端應用結合的研究有待深入,鮮有直接應用于移動終端的輕量級深度學習模型被提出,基于移動終端的摩爾紋去除方法實時性較差.為此,需要在2 個方面進行基于移動終端的摩爾紋去除網絡模型的優化和構建:①利用低秩近似分解、網絡剪枝和網絡量化對已有的深度學習網絡進行模型壓縮和加速優化;直接設計輕量化的網絡結構,并將訓練完成的深層網絡模型完全運行于移動終端設備.②結合邊緣計算技術,通過神經網絡前向推理框架[75]將優化后的深度學習模型部署至移動端的應用系統.
總之,基于深度學習的摩爾紋圖案去除模型的部署輕量化、計算低配化、性能普適化以及操作實時化將成為移動終端泛化應用的重要研究目標.
作者貢獻聲明:亓文法提出了文章框架結構和研究思路,并撰寫論文;劉宇鑫負責完成實驗并撰寫論文;郭宗明提出指導意見并修改論文.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
