基于物候特征和全連接神經網絡相結合的小麥自動識別研究
2024-03-23 08:02:30郭雪星陸國政申乾榮
中國種業 2024年3期
郭雪星 陸國政 王 強 申乾榮
(北京華云星地通科技有限公司,北京100081)
面對氣候變化和糧食安全的挑戰[1],全球各國共同面臨著確保糧食供應平衡的任務[2-3]。因此,對于國家有關部門來說,快速、及時、有效獲取大范圍內作物種植面積的空間分布信息十分重要,對于指導作物生產、促進農業發展,并確保國家糧食安全具有關鍵意義。
國內外學者的研究表明,利用時序遙感影像植被指數和農作物物候特征進行作物種類識別,是一種行之有效的方法。近年來,國內外諸多專家學者基于不同的衛星數據,從不同角度、不同層次、運用不同的方法對冬小麥面積的提取進行了研究[4-6]。以往的研究大多在獲取冬小麥分布信息方面取得了很大的成就,但這些研究很多是基于單一物候期[7-8]或多物候期的單一特征指數時間序列[9-10],沒有考慮不同物候期作物的特征以及不同物候期之間的關系。基于單一特征指數時間序列的作物分布信息提取受其他特征的影響,相似特征指數時間序列對作物的效應也會影響提取精度[11],而多物候特征通過考慮作物在整個生長周期中多個特征指標的變化,可以減少這些因素的影響。Ni 等[12]考慮到不同物候期的差異,開發出了一種多物候特征合成方法,提取了水稻分布信息,結果顯示該分類方法在水稻分布信息提取上表現較好。如果僅選取單時相光學影像,會因為“異物同譜”而產生漏錯分等問題[13-14]。劉佳等[15]采用HJ 時間序列數據,利用農作物全生育期波譜特征曲線提取了河北衡水的主要作物類型,通過基于NDVI 閾值的決策樹的分類方法,對各類農作物的種植面積進行了遙感識別和分類。賈樹海等[16]基于不同作物類型物候特征的差異,提取三期遙感影像不同的NDVI 特征值和影像特征信息,利用監督分類方法對花生種植情況進行了分類和制圖。
盡管利用遙感監測各種農作物生長狀況的技術已經比較成熟,在某種農作物的一定區域內的種植分布面積研究也取得了一定的成就,但在具有多種農作物和植被的大面積耕地上,如何快速且有效地對農作物進行分類的研究還不夠,無論是方法的可操作性或是結果精度的驗證上都還存在著一些問題[17],比如過高的分辨率會增加數據量、計算時效性等問題。本研究的主要目的是利用FY-3D MERSI 產品數據,探尋河南省內不同植被在冬小麥生長期內NDVI 時間序列曲線變化的特征,從而建立一種能夠快速和高效提取冬小麥種植面積的方法,并通過對FY-3D 衛星數據的研究,經過相關處理后提高該方法的精度,以期能夠為利用遙感數據對冬小麥進行大范圍識別和種植面積提取提供一種新的且行之有效的研究思路。
1 材料與方法
1.1 研究區概況河南省位于中國的中部,地理坐標在31°23′~36°22′N,110°21′~116°39′E 之間(圖1),屬典型的亞熱帶季風氣候,四季明顯,溫度變化較大。夏季炎熱潮濕,冬季寒冷干燥,春季溫暖多風,秋季涼爽宜人,日照時間較長,光能資源充足。截至2023 年,其常住人口超過1 億,是中國人口最多的省份之一。河南省還是中國重要的農業和工業基地之一,擁有廣闊的農田和豐富的農產品資源,主要種植水稻、小麥、玉米、棉花等作物,在冶金、化工、機械制造、能源等領域具有一定的實力。近年來,河南省逐漸加大了對高新技術產業的發展力度,涵蓋了電子信息、生物醫藥、新材料等領域。

圖1 河南省研究區示意圖
1.2 數據源及預處理(1)遙感數據。本研究使用風云衛星遙感數據服務網提供的歸一化植被指數(NDVI 產品),該數據集是全球10°×10°分幅的250m 及0.05°分辨率等經緯度投影植被指數的旬合成產品。選取數據日期為2019 年10 月至2020 年6月、2020 年10 月至2021 年6 月、2021 年10 月至2022 年6 月、2022 年10 月至2023 年6 月,每月有上旬、中旬、下旬3 旬數據,河南冬小麥整個關鍵生育期共27 組數據。(2)其他數據。本研究除了使用遙感數據外,還使用了矢量數據和采樣點數據。矢量數據用于行政邊界的確認和遙感數據的裁剪。采樣點數據主要是通過Google 高清底圖進行冬小麥樣本點的選取,作為后續模型分類和精度驗證。(3)數據預處理。歸一化植被指數(NDVI 產品)是分塊數據,根據研究目的,本文選取河南省冬小麥生育期的數據,按照河南省行政邊界進行拼接、投影、裁剪、格式轉換等預處理工作,采用Python 編程方式進行數據批量自動處理。處理結果如圖2 所示。
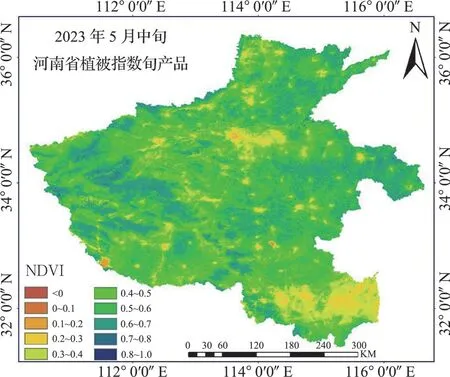
圖2 河南省植被指數處理結果圖
1.3 研究方法冬小麥自動識別研究的技術路線如圖3 所示,首先進行遙感數據的獲取和預處理,然后進行河南省冬小麥的物候特征分析,篩選出冬小麥生長發育期的時序遙感數據,從而計算時間序列的NDVI 數據。由于冬小麥樣本較少,本文采用K 均值聚類分析方法,在研究區內隨機取一些點,對不帶標簽的隨機點進行聚類分析,得到最佳聚類效果。基于冬小麥的時序NDVI 光譜分析,最終確定冬小麥的類別,結合機器學習的方法(全連接神經網絡),迭代出最優分類規則進行冬小麥識別。基于識別出來的冬小麥的結果,尋找同期高清Google 影像,通過目視解譯得到冬小麥數據作為精度驗證的檢驗源,采用數據匹配和精度檢驗指標方法進行精度驗證。
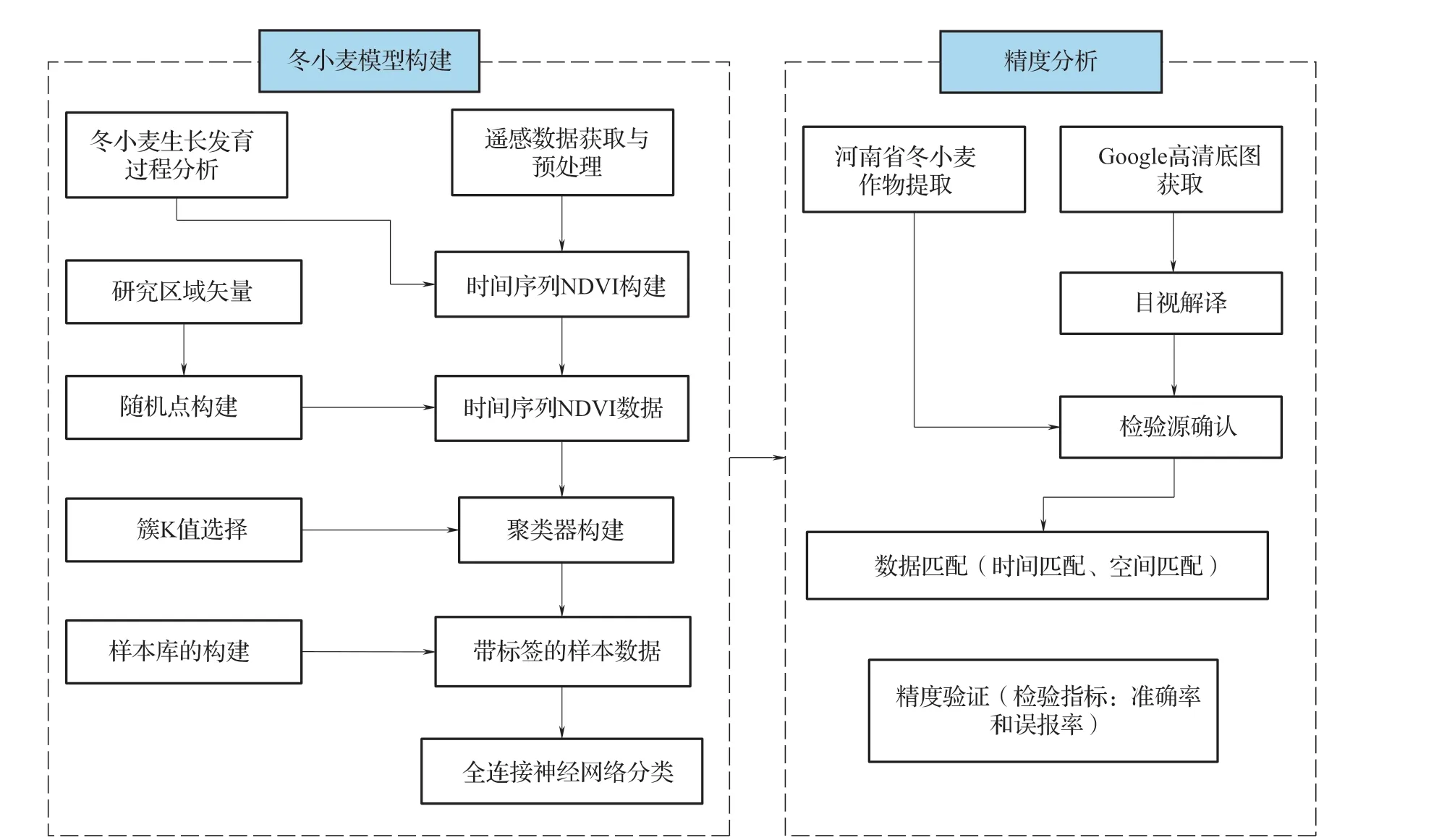
圖3 冬小麥遙感自動識別流程圖
1.3.1 物候特征分析提取作物的物候數據對于農業決策、研究氣候變化和生態系統變化非常重要。為了更準確描述作物生長發育規律,可以結合遙感時序數據和作物物候數據。遙感時序數據可以提供大范圍的地表信息,而作物物候數據則可以提供作物生長發育的具體信息。這兩種數據的結合使用可以幫助制圖者提高分類精度,同時也為農業決策和研究提供了重要的數據支持。冬小麥的物候歷(表1)是冬小麥播種面積的重要參考信息,可以根據溫度變化和生長發育規律來確定。通過提取冬小麥的物候歷,可以更精確地區分冬小麥與其他地物,從而提高制圖的準確性和可靠性。

表1 河南省冬小麥物候歷
1.3.2 聚類分析K 均值聚類分析是一種常用的無監督學習算法,用于將數據集中的觀測值劃分為K個不同的簇。該算法的目標是使得同一簇內的觀測值相似度最高,而不同簇之間的觀測值差異最大化。在進行K 均值聚類分析時,首先需要選擇合適的K值,即簇的數量。然后,根據給定的距離度量(如歐氏距離或曼哈頓距離),計算觀測值之間的距離,并將它們分配到最近的簇中。通過迭代的方式,更新每個簇的質心(即簇內觀測值的平均值),并重新分配觀測值,直到滿足停止(如固定迭代次數或簇分配不再改變)。
1.3.3 全連接神經網絡分類全連接神經網絡是一個常見的人工神經網絡模型,也被稱為多層感知機(Multilayer perceptron)。它由多個神經元(節點)組成的網絡層連接在一起,神經元之間相互連接。全連接神經網絡的算法步驟主要包括以下幾個方面。
(1)數據預處理:對輸入數據進行必要的預處理,包括歸一化、標準化、特征縮放等操作,以確保數據具有合適的數值范圍和分布。
(2)網絡架構設計:確定神經網絡的數量,以及它們之間的連接方式。還需要選擇適當的激活函數和損失函數。
(3)初始化參數:初始化網絡中的權重和偏置,可以使用隨機初始化的方式,如服從正態分布或均勻分布的隨機數。
(4)前向傳播:通過前向傳播計算每個神經元的輸出。從輸入層開始,通過每一層的權重和偏置進行加權求和,并經過激活函數得到下一層的輸出。
(5)計算損失:將前向傳播得到的輸出結果與真實標簽進行比較,計算損失函數的值,衡量網絡輸出與真實值之間的差異。
(6)反向傳播:通過反向傳播算法計算每個神經元的梯度,并根據梯度下降法則更新權重和偏置,以減小損失函數的值。這一步是全連接神經網絡的核心步驟,它將誤差從輸出層向前傳播,不斷調整權重和偏置。
(7)參數更新:根據反向傳播計算得到的梯度,使用優化算法(如梯度下降法)更新網絡中的權重和偏置,使損失函數逐漸減小。
(8)重復訓練:不斷重復步驟4 到步驟7,直到達到預定的停止條件,例如達到指定的訓練輪數、損失函數收斂等。
(9)預測與評估:使用訓練好的全連接神經網絡進行預測,并評估模型的性能。可以使用測試數據集進行驗證,計算準確率、精確率、召回率等指標。
1.3.4 精度分析本文精度分析主要通過檢驗源數據和待檢驗數據的時空間匹配,選用質量檢驗指標進行冬小麥提取結果的精度驗證。
(1)數據匹配方法:本文基于Google 高清影像底圖數據,采用目視解譯方法,篩選出河南省小麥樣本數據作為精度分析的檢驗源,利用時間匹配方法和空間匹配方法,進行檢驗源和待檢驗源的數據匹配處理。時間匹配方法是以FY-3D 衛星的歸一化植被指數(NDVI)的時間為準,找鄰近的Google影像。空間匹配方法則是以FY-3D 衛星的冬小麥識別產品空間分辨率為250m,根據Google 影像目視解譯的小麥樣本數據的經緯度,尋找125m范圍內最近冬小麥識別產品像元,進行空間匹配處理。
(2)冬小麥識別評價指標描述:如表2 所示,以檢驗源(Google)冬小麥識別產品為參考,若檢驗源冬小麥識別結果為冬小麥,而FY-3D 冬小麥識別結果為非冬小麥,則定義為漏判;檢驗源冬小麥識別結果為非冬小麥,而數據集冬小麥識別結果為冬小麥的情況,則定義為誤判。

表2 FY-3D 冬小麥識別與檢驗源冬小麥樣本結果
(3)質量檢驗指標:質量檢驗指標包括冬小麥識別準確率PODcm、非冬小麥識別準確率PODncm、冬小麥識別誤報率FARcm、非冬小麥識別誤報率FARncm、總體冬小麥識別準確率HR、KSS評分。各指標計算公式如下。
冬小麥識別準確率PODcm:

式中a 表示匹配時間段內相同空間范圍中FY-3D 衛星數據和檢驗源都檢測到有冬小麥的樣本個數;b 表示檢驗源檢測到冬小麥而FY-3D 為非冬小麥的樣本個數,即FY-3D 冬小麥漏判的樣本個數;c 表示檢驗源為非冬小麥而FY-3D 為冬小麥的樣本個數,即FY-3D 冬小麥識別誤判的樣本個數;d 表示FY-3D 衛星和檢驗源都為非冬小麥的樣本個數,即FY-3D 非冬小麥準確的樣本個數。
2 結果與分析
2.1 聚類分析結果本研究基于冬小麥特有的生育期時間序列物候特征和隨機點的時序植被指數值(NDVI),基于K 均值聚類方法進行聚類分析。如圖4a 所示,聚類簇數量為3 個時,聚類分析結果達到最佳。圖4b~d 分別為此次聚類的樣本結果,基于農作物生育期內的特定物候特征得知,圖4b 為樹草等其他植被,圖4c 為冬小麥,圖4d 為陸地、建筑

圖4 聚類分析過程圖
等。聚類分析結果如圖5 所示,采用隨機點聚類方法準確得出小麥樣本點,從而為后續全連接神經網絡分類提供充足樣本。

圖5 真實小麥樣本圖和隨機點聚類結果圖
2.2 冬小麥識別結果利用冬小麥物候特征時期的風云三號D 星遙感數據提取NDVI 旬合成數據集和聚類分析得出冬小麥樣本點,采用全連接神經網絡分類方法實現河南省冬小麥種植面積的信息提取,獲得2019 年、2020 年、2021 年和2022 年河南省農作物的分布面積和空間分布格局(圖6)。由圖6 可知,河南省冬小麥種植區域主要分布在河南中部平原地帶和河南南部。

圖6 河南省冬小麥空間分布圖
2.3 精度驗證本研究隨機從Google 高清影像數據,采用目視解譯方法選取1400 個小麥樣本點和600 個非小麥樣本點,共2000 個樣本點作為本次精度驗證的數據,采用質量檢驗指標方法進行精度驗證。從表3、表4 可以得出,2019 年FY-3D冬小麥識別準確率為84.6%,非冬小麥識別準確率為84.3%;2020 年FY-3D 冬小麥識別準確率為86.1%,非冬小麥識別準確率為87.7%;2021 年FY-3D 冬小麥識別準確率為84.1%,非冬小麥識別準確率為82.5%;2022 年FY-3D 冬小麥識別準確率為85.5%,非冬小麥識別準確率為83.6%,歷年整體冬小麥識別準確率為85.1%,非冬小麥識別準確率為84.5%。

表3 2019-2022 年FY-3D 冬小麥識別與檢驗源冬小麥樣本結果

表4 歷年FY-3D 冬小麥識別精度驗證結果
3 討論
在冬小麥分類過程中,單時相圖像無論其具有多少波段,都較難區分同期生長的作物類型,利用多時相遙感信息,考慮冬小麥在不同生長發育階段的光譜差異性原理,發現冬小麥歸一化植被指數在不同物候期存在較大差別。因此通過冬小麥生長期選擇最佳時相的遙感數據,利用時序植被指數和全連接神經網絡機器學習方法進行小麥自動識別研究,可以高效減少其他作物的干擾,提高識別效率,具有實用性。
使用相同判別規則對不同地區的冬小麥進行提取可能會存在一定誤差,因為不同氣候條件會導致作物生長速率和長勢存在差異。此外,FY-3D 影像的250m 分辨率可能會導致混合像元的存在,從而影響冬小麥識別和提取精度。為了提高提取精度,下一步研究重點為探索區域地理環境差異和混合像元對提取精度的影響。
4 結論
本研究以河南省為研究區,利用風云三號D星數據,采用物候特征和全連接神經網絡相結合的方法對河南省冬小麥進行提取,得到歷年河南省冬小麥空間分布情況,主要得出以下結論。
(1)分析河南省冬小麥的物候特征,利用冬小麥植被指數時序變化規律,采用聚類分析和全連接神經網絡分類方法提出較為精準的冬小麥像元,通過該技術可以有效地減少非植被地物對冬小麥提取的干擾,使其能自動實現冬小麥的識別,提高了業務運行效率。而且結合物候特征、時序特征、指數特征的聚類分析和全連接神經網絡的分類方法比一般分類方法具有更高的分類精度和更小的樣本依賴性。
(2)物候特征和全連接神經網絡相結合的方法在河南省冬小麥提取中有相對較好的效果。在進行精度驗證時,本研究以Google 高清影像為數據,目視解譯出的冬小麥和非冬小麥像元作為檢驗源數據,識別河南省冬小麥的準確率為85.1%,非冬小麥準確率為84.5%。歷年河南省冬小麥自動識別結果表明,該方法具有一定普適性和魯棒性。
總體來說,本研究在大尺度范圍上,基于風云衛星D 星遙感數據,結合物候特征、時序特征、指數特征的聚類分析和全連接神經網絡分類方法應用于河南省冬小麥自動識別研究中是可行的,而且為河南省冬小麥自動識別的業務化應用提供了新的思路和方法。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
