基于自適應多保真度Co-Kriging 代理模型的地下水污染源反演識別
2024-03-28 08:08:04安永凱張巖祥閆雪嫚長安大學水利與環境學院陜西西安710054長安大學旱區地下水文與生態效應教育部重點實驗室陜西西安710054中國電建集團西北勘測設計研究院有限公司陜西西安710065西北大學城市與環境學院陜西西安710127
中國環境科學 2024年3期
關鍵詞:模型
安永凱,張巖祥,閆雪嫚(1.長安大學水利與環境學院,陜西 西安 710054;2.長安大學旱區地下水文與生態效應教育部重點實驗室,陜西 西安 710054;.中國電建集團西北勘測設計研究院有限公司,陜西 西安 710065;4.西北大學城市與環境學院,陜西 西安 710127)
地下水污染具有存在的隱蔽性和發現的滯后性等特點,致使人們難以直接了解和掌握地下水污染的相關狀況(如污染源的空間位置和釋放歷史),這對地下水污染修復方案合理制定、風險評估以及責任認定帶來極大的困難[1-2].地下水污染源反演識別能夠根據污染場地地下水水位和污染質濃度監測數據,結合現場調查、動態試驗、專業知識和專家經驗等輔助信息,對描述地下水污染的數值模擬模型進行反演求解,從而識別確定含水層中污染源個數、位置和釋放歷史等地下水污染源參數[3-4].
現有地下水污染源反演識別方法主要可分為以下幾類:解析法、直接法、模擬優化法以及隨機統計法[5-6].其中,模擬優化法是地下水污染源反演識別研究中應用最廣泛的方法[7-8].但模擬優化法只能給出污染源參數的“最優解”,無法充分描述其不確定性[9].與模擬優化法不同,應用隨機統計法開展地下水污染源反演識別研究可獲得未知污染源參數的后驗分布,不僅可充分描述其不確定性,且所得到的信息量更大從而能夠為地下水污染修復治理、風險評估等提供更多的參考信息[10-11].然而,應用隨機統計法進行地下水污染源反演識別需成千上萬次地運行地下水溶質運移數值模擬模型,由此產生了龐大的計算負荷及冗長的計算時間[10].建立模擬模型的代理模型是解決該問題的有效途徑[12-13].
代理模型可以用非常低的計算代價對復雜模擬模型的輸入輸出關系進行近似代理[14],根據其構建方式,代理模型可分為兩大類:第一類是響應面代理模型,第二類是多保真度(MF)代理模型[15].前者是僅利用高保真度(HF)模型(即原始模擬模型)輸入輸出樣本構造的數據驅動代理模型,具有易于實施的優點,在水文地質領域得到了廣泛應用[2,16].HF 模型精度高但計算成本也高,導致第一類代理模型的構建仍需昂貴的計算成本,因此學者們提出綜合運用HF模型信息和低保真度(LF)模型信息來構建MF代理模型.其中,LF 模型可通過離散網格粗化、模型降階等簡化方式得到,相比于HF 模型,LF 模型精度較差但計算成本也低,可以提供充足的樣本[17].MF 代理模型旨在通過MF 模擬框架充分挖掘HF 模型和LF 模型之間的相關關系,進而用少量HF 模型樣本和大量LF 模型樣本構建兼顧HF 模型精度與LF 模型效率的代理模型[18].相比于常用的響應面代理模型,MF 代理模型能夠進一步提高計算效率且對模擬模型的逼近精度更高[19-20].但在地下水污染源反演識別研究中,MF 代理模型卻鮮有報道.同時,采用自適應更新多保真度代理模型策略,即將每一輪地下水污染源反演識別結果帶入HF 模型,獲得新的訓練樣本,進而重新構建MF 代理模型,可以有效進一步提升MF 代理模型對模擬模型的逼近精度,以此重新進行地下水污染源反演識別,能夠極大地提高地下水污染源反演識別精度.
基于此,本文研究應用集成差分進化算法的Co-Kriging 方法建立地下水數值模擬模型的MF 代理模型,在此基礎上,耦合多保真度Co-Kriging 代理模型和MCMC-DREAM(D)算法,并采用自適應更新多保真度代理模型策略進行地下水污染源反演識別,旨在為地下水污染修復治理提供參考.
1 研究方法
技術路線如圖1 所示.

圖1 技術路線Fig.1 Technology roadmap
1.1 Co-Kriging 代理模型
Co-Kriging 代理模型是Kriging 代理模型的一種擴展性形式,由兩組互不干擾的高、低保真度樣本共同構建而成的MF 代理模型[21].相比于只用高保真度樣本建立的Kriging 代理模型,Co-Kriging 代理模型在保持非常高的代理精度的同時,能夠有效降低獲取高保真度樣本所需的時間和計算代價[22].
假設有兩組高、低保真度樣本,分別為{Xh,Yh}和{Xl,Yl}, 其中Xh和Xl為樣本輸入,且Xh?Xl, Yh和 Yl為樣本輸出.這些樣本集合起來表示如下:
式中:nh和nl分別為高、低保真度樣本數量.
使用Zh和Zl分別表示高、低保真度樣本的高斯過程,兩者之間的關系可以使用式(3)表示:
式中:ρ為縮放因子,Zd表示Zh與ρZl之間差異的高斯過程.
參照 Kriging 代理模型中協方差矩陣的結構,Co-Kriging 代理模型的完整協方差結構如式(4)所示[23]:
式中:ψl和ψd為相關矩陣,和可以參照Kriging代理模型求解.
協方差矩陣C中有5個超參數需要優化,分別為θl、θd、pl、pd和ρ.可以使用極大似然估計(Maximum Likelihood Estimate, MLE)獲取上述超參數.
通過使式(5)取得最大值求得θl和pl:
通過使式(6)取得最大值求得θd、pd和ρ:
在獲得超參數之后,可以使用式(7)預測任意一點在高保真度的高斯過程中的響應值.
1.2 差分進化算法
上述Co-Kriging 代理模型的超參數往往需要配合優化算法方可求得,優化算法—差分進化算法(DE).DE 是一種高效的全局優化算法,與遺傳算法的進化流程非常相似,都包括變異、交叉和選擇操作,但這些操作具體定義與遺傳算法有所不同[24].如圖2 所示,DE 的進化流程如下:(1)確定適應度函數、種群大小、縮放因子、交叉概率和進化代數.(2)隨機產生初始種群.(3)計算初始種群的適應度值.(4)對初始種群進行變異和交叉,得到中間種群.(5)計算中間種群的適應度值.(6)在初始種群和中間種群中選擇個體,更新初始種群.(7)判斷是否達到終止條件或最大進化代數,若是,則終止,若否,轉步驟(4).

圖2 差分進化算法的進化流程Fig.2 Process of differential evolution algorithm
1.3 貝葉斯推理
貝葉斯推理源于貝葉斯理論.貝葉斯公式是貝葉斯推理的數學表達,用于表達先驗分布和后驗分布的關系,目前貝葉斯推理被廣泛應用于模型參數識別及不確定性分析[25].貝葉斯公式根據先驗知識設置參數的初始分布,通過分析樣本的概率后,得到參數的后驗分布[26],如式(8)所示:
在實際應用中,除了極個別特別簡單的模型可以通過解析解推斷參數的后驗分布,對于絕大多數的復雜模型,只能通過采樣的方式獲取參數的后驗分布[27-28].馬爾科夫鏈蒙特卡洛(MCMC)能夠從后驗分布采樣并進行統計分析,從而得到后驗分布的統計特征[29-30].目前,MCMC 方法已經開發出了眾多采樣算法.其中,DREAM(D)是在DREAM算法的基礎上改進而來的,與原始DREAM 算法不同的是,它在處理連續型變量的同時能夠有效處理離散型變量,并且能夠保持細致的平衡性和遍歷性[31].
然后進行馬爾科夫鏈進化:
(2)對于第i(i=1,2, …,N)條馬爾科夫鏈,產生候選種群的公式(9)如下所示:
(3)定義CR(0 ≤CR ≤ 1)為進行子空間演化的交叉概率,進而決定候選種群是否取代初始種群:
式中:U 為隨機數,從均勻分布 U( 0,1)采樣得到.
(4)計算似然度 p( zi),并進而計算接受率α(θi, zi):
根據接受率 α(θi,zi)的計算結果,判斷是否接受zi.
(5)應用Gelman-Rubin 收斂診斷方法[32]判斷收斂性,計算收斂性判斷指標R:
式中:g 為DREAM(D)算法中的馬爾科夫鏈長度;q 為MC 數目;B 表示q 條馬爾科夫鏈平均值的方差;W 為q 條馬爾科夫鏈內方差的平均值.若R≤12,則認為采樣過程已收斂,結束計算,統計分析待求變量θ的后驗分布;否則重復步驟.
2 數值試驗
2.1 數值算例概述
本文針對2 個數值算例開展研究.算例1:考慮一個二維均質各向同性承壓含水層,該含水層東西長為300L,南北寬為240L,東、西兩側邊界(Γ1和Γ3)均為線性變化的定水頭邊界,南、北邊界(Γ2和Γ4)均為零通量邊界,如圖3(a)所示.算例2:考慮一個二維非均質各向同性承壓水層,該含水層劃分為3 個參數分區,僅對滲透系數進行分區,東西長為300L,南北寬為200L,西北、東南邊界(Γ1和Γ3)均為定水頭邊界,其余(Γ2和Γ4)均為零通量邊界,如圖3(b)所示.2 個算例的模擬期均為900T,模擬區內有1 個地下水污染源,3 個地下水污染觀測井.

圖3 算例含水層平面示意Fig.3 Aquifer plan schematic diagram
本研究假設污染物不會發生化學反應和生物降解作用.算例1:假設污染源初始釋放時間(τ)和釋放強度(q)未知,并作為待識別變量,滲透系數(K)、縱向彌散度(D)、橫向彌散度與縱向彌散度比值(α)和孔隙度(n)等水文地質參數均質且已知,待識別變量先驗分布和水文地質參數取值如表1 所示.算例2:假設污染源初始釋放時間(τ)、釋放強度(q)、3 個分區滲透系數(K1,K2,K3)和縱向彌散度(D)未知,并作為待識別變量,橫向彌散度與縱向彌散度比值(α)和孔隙度(n)等水文地質參數已知,待識別變量先驗分布和水文地質參數取值如表2 所示.

表1 算例1 待識別變量先驗分布和水文地質參數值Table 1 Prior distribution of unknown variables and hydrogeological parameter values for case 1

表2 算例2 待識別變量先驗分布和水文地質參數值Table 2 Prior distribution of unknown variables and hydrogeological parameter values for case 2
根據上述設定的水文地質條件,模擬區地下水流運動數學模型如式(13)所示:
式中:H 為地下水水頭[L];K 為滲透系數[L/T];M 為含水層厚度[L];S 為貯水系數[-];H0和H1為已知函數[L];Γ1、Γ3為第一類邊界條件; Γ2、Γ4為第二類邊界條件.為邊界上某點外法線方向上的單位向量.
模擬區地下水溶質運移數學模型如式(14)所示:
式中:c 為污染質濃度[ M / L3];Dxx和Dyy分別為x、y方向上的水動力彌散系數[ L2/ T ];ux和uy分別為x、y 方向上的實際平均水流速度[ L / T ];f 為源匯項[ M /( L3T )];c0為已知濃度函數[ M / L3];c1為已知對流-彌散通量函數[ M /(L2T )];Γ1、Γ3為第三類邊界條件; Γ2、Γ4為第二類邊界條件.
分別對模擬區進行精細離散和粗化離散,建立HF 模型和LF 模型,然后應用MODFLOW 和MT3D分別求解HF 模型和LF 模型.其中,算例1 的HF 模型將模擬區剖分為 800000 個網格(長 1000×寬800),LF 模型將模擬區剖分為2880 個網格(長60×寬48);算例2 的HF 模型將模擬區剖分為375000 個網格(長750×寬500),LF 模型將模擬區剖分為2400 個網格(長60×寬40).
2.2 Co-Kriging 代理模型的建立
本文算例1 待反演識別變量包括污染源初始釋放時間(τ)和釋放強度(q),相應的代理模型輸入則為上述的2 個待識別變量,輸出為3 口監測井在3 個時刻(t=780T ,840T ,900T )監測到的污染物濃度值,共9 個變量;算例2 待反演識別變量包括污染源初始釋放時間(τ)、釋放強度(q)、3 個分區滲透系數(K 1, K 2, K 3)和縱向彌散度(D),相應的代理模型輸入則為上述的6 個待求變量,輸出為3 口監測井在3個時刻(t=780T ,840T ,900T )監測到的污染物濃度值,共9 個變量.
Co-Kriging 代理模型的構建步驟如下:首先,采用拉丁超立方抽樣方法在待識別變量的先驗分布內分別抽取5 個和200 個訓練樣本,將抽取的5 個訓練樣本代入精細離散的HF 模型,同時將抽取的200個訓練樣本代入粗化離散的LF 模型;然后,運轉HF模型和LF 模型,分別得到對應的模型輸出;接下來,基于5 組HF 模型輸入-輸出樣本構建Kriging 代理模型,基于5 組HF 模型和200 組LF 模型輸入-輸出樣本構建Co-Kriging 代理模型,即MF 代理模型;最后,重新采用拉丁超立方抽樣方法在待識別變量的先驗分布內抽取 5 個檢驗樣本,將其分別代入Kriging 模型和MF 代理模型,運轉模型,得到相應的模型輸出,并將它們與HF 模型的輸出結果進行對比分析,從而評估Kriging 代理模型和MF 代理模型的精度.整體的MF 代理模型構建流程如圖4 所示.

圖4 Co-Kriging 代理模型的構建流程[18]Fig.4 Construction process of Co-Kriging surrogate model[18]
由圖5 可以看出,MF 代理模型平均相對誤差均小于Kriging 代理模型,這說明對于相同的輸入,MF 代理模型對HF 模型的逼近精度更高,MF 代理模型比Kriging 代理模型更適合后續地下水污染源反演識別.
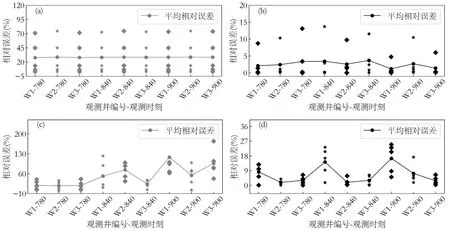
圖5 Kriging 代理模型與MF 代理模型精度Fig.5 Accuracy of Kriging surrogate model and MF surrogate model
對于算例1,HF 模型和MF 模型單次運行時間分別為1964.747s 和0.016s;對于算例2,HF 模型和MF 模型單次運行時間分別為2013.366s 和0.018s.HF 模型單次運行時間較長,在地下水污染源反演識別過程中成千上萬次調用HF 模型,需要數月才能識別完畢,因此,不合適用于地下水污染源反演識別;MF 代理模型單次運行時間十分短,在地下水污染源反演識別過程中需要成千上萬次調用MF 模型,僅需數分鐘便能識別完畢,且對HF 模型的逼近精度很高,十分適合用于地下水污染源反演識別.使用MF 代理模型進行地下水污染源反演還需要考慮構建MF 代理模型的時間,構建MF 代理模型時間花費主要來自運行HF 模型,在本研究中需要運行5 次HF 模型,需要數小時便能完成.總而言之,在地下水污染源反演識別過程中直接調用MF 代理模型所需時間遠遠小于調用HF 模型,更適合用于地下水污染源反演識別.
2.3 污染源反演識別
在構建Co-Kriging 代理模型的基礎上,研究應用DREAM(D)算法分別對兩個算例的待識別變量進行反演識別.為保證待識別變量均收斂于穩定的后驗分布采樣過程的收斂性,本文采用Gelman-Rubin收斂診斷方法對DREAM(D)算法采樣過程的收斂性進行檢驗.對于算例1,DREAM(D)算法的采樣過程如圖6(a)和圖6(b)所示.污染源初始釋放時間(τ)和釋放強度(q)這2個待識別變量均能收斂于穩定的后驗分布.對于算例2,DREAM(D)算法的采樣過程如圖7(a)、(b)、(e)、(f)、(i)、(j)所示.污染源初始釋放時間(τ)、釋放強度(q)、3 個分區滲透系數(K 1, K 2, K 3)、和縱向彌散度(D)這6 個待識別變量均能收斂于穩定的后驗分布.

圖6 算例1 待識別變量的采樣迭代過程及其反演識別結果Fig.6 Sampling iteration process and identification results of unknown variables for case 1
在確保采樣過程收斂性后,算例1 選取后1000組樣本進行統計分析,獲得2 個待識別變量的反演識別結果;包括其后驗分布及統計特征值.算例2 選取后10000 組樣本進行統計分析,獲得6 個待求變量的反演識別結果,包括其后驗分布及統計特征值.
由圖6 和圖7 可知,待識別變量后驗分布均存在明顯的峰值,這說明DREAM(D)算法能夠實現對待求變量的有效反演識別.此外,可以明顯看出,算例1的2 個待識別變量的真實值均落在其后驗分布的高密度區域;同時,待識別變量后驗分布的最大后驗概率(MAP)值與其真實值很接近.這說明,DREAM(D)算法能夠得到較高精度的反演識別結果.算例2 的污染源初始釋放時間(τ)和 3 個分區滲透系數(K 1, K 2, K 3)這4 個待識別變量的真實值均落在其后驗分布的高密度區域;同時,待識別變量的后驗分布的MAP 值與其真實值很接近,這說明,DREAM(D)算法對這4 個變量得到良好識別.污染源釋放強度(q)和縱向彌散度(D)這4 個待識別變量的真實值落在其后驗分布的低密度區域,這2 個變量未能得到良好識別.

圖7 算例2 待識別變量的采樣迭代過程及其反演識別結果Fig.7 Sampling iteration process and identification results of unknown variables for case 2
為了進一步提高污染源反演識別精度,采用自適應更新多保真度代理模型策略,即將上一輪污染源反演結果后驗分布的MAP 值代入HF 模型,獲得新的輸入-輸出訓練樣本,訓練新的多保真度Co-Kriging 模型,進而進行下一輪污染源反演識別.分別對算例1 和算例2 進行2 次和3 次自適應更新,待識別變量反演結果如圖8 和圖9 所示.
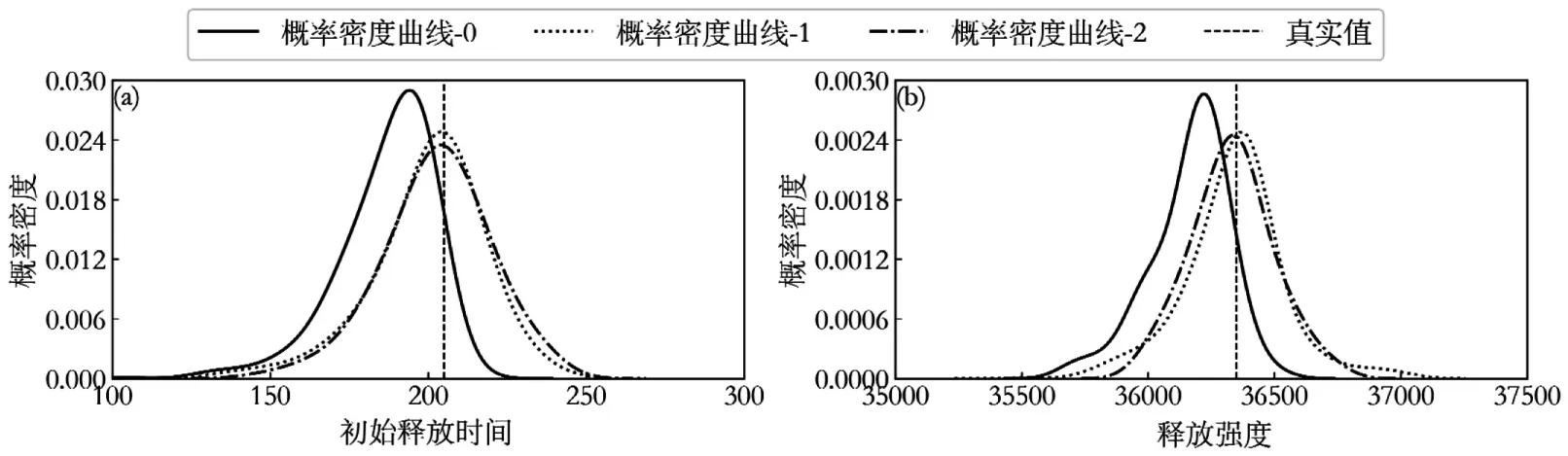
圖8 算例1 待識別變量反演識別結果Fig.8 Identification results of unknown variables for case 1
概率密度曲線的MAP 值越靠近真實值,說明反演識別結果越好.由圖8 可以看出,經過1 次自適應更新后,待識別變量的MAP 值與其真實值更加接近,表明自適應更新策略能夠顯著提升污染源反演精度.經過2 次自適應更新后的污染源反演結果與經過1 次自適應更新后基本一樣,沒有顯著差別,表明自適應更新策略有助于得到高精度且穩定的污染源反演結果.由圖9可以看出,經過3次自適應更新后,污染源釋放強度(q)、滲透系數(K2)和縱向彌散度(D)的MAP值與其真實值更加接近,表明自適應更新策略能夠顯著提升反演精度.滲透系數(K1,K2)的MAP 值與更新前無明顯差別,初始釋放時間(τ)的MAP 值稍微遠離其真實值,表明自適應更新策略未能夠提升反演精度,原因在于模型輸出值(污染物濃度)對初始釋放時間(τ)不敏感和DREAM(D)算法進行參數識別本身存在一定隨機性,故而難以提升反演識別精度.綜合算例1和算例2,采用自適應更新多保真度代理模型策略能夠進一步提升污染源反演識別精度.

圖9 算例2 待識別變量反演識別結果Fig.9 Identification results of unknown variables for case 2
因此,基于Co-Kriging 代理模型和DREAM(D)算法的地下水污染源反演識別是可行有效的.然而,本文構建的Co-Kriging 代理模型只適合于當前水文地質條件和模型時空離散,當水文地質條件和模型時空離散變化時,需要重新構建Co-Kriging 代理模型.
3 結論
3.1 相比僅基于高保真度模型輸入-輸出樣本構建的Kriging 代理模型,聯合運用高保真度和低保真度模型輸入-輸出樣本構建的Co-Kriging 代理模型對模擬模型的逼近精度更高.
3.2 耦合多保真度 Co-Kriging 代理模型和MCMC-DREAM(D)算法能夠得到較高精度的污染源反演結果,且能夠大幅度減小計算負荷;同時,采用自適應更新多保真度代理模型策略能夠進一步提升污染源反演識別精度.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
