輕量級空間移位MLP 用于指靜脈分割
2024-04-02 03:42:34曾軍英田慧明陳宇聰顧亞謹鄧森耀尹永宏尤吳杭黃國林甘俊英秦傳波
現代電子技術 2024年7期
曾軍英,田慧明,陳宇聰,顧亞謹,鄧森耀,尹永宏,尤吳杭,黃國林,甘俊英,秦傳波
(五邑大學智能制造學部,廣東江門 529020)
0 引 言
近年來,手指靜脈識別作為流行的第二代生物特征識別工具,相較于其他生物識別技術具有安全性高、準確率高、唯一性、非接觸式采集、不易偽造和低成本等特點,因此受到越來越多的學者關注。在手指靜脈的提取和識別應用中,圖像分割是其中一項主要任務,直接影響到識別的準確率。但是這些主流網絡模型[1-4]的主要工作都集中在開發高效和魯棒性的分割方法上,對指靜脈提取的實時性分割工作很難達到理想效果。此外,這些方法需要消耗大量的計算資源和存儲空間,在嵌入式終端上很難達到運行的條件。相對于占用大量計算和內存資源、對設備要求較高的CNN 架構,以及需要大量數據進行訓練、建立全局依賴的Transformer 架構[5-8],設計一種計算開銷較小、參數數量較少、推理時間更快的分割網絡模型,并保持其良好的分割性能是非常重要的。此外,探索局部性對模型體系結構的影響也同樣具有重要意義。對于上述問題,本文提出了一種基于MLP的輕量級手指靜脈分割網絡模型——S-MLP。該網絡模型采用帶有編碼器、解碼器和跳躍連接的U 型5 層深度網絡結構。同時,在每一個解碼器和編碼器中引用了一種新穎的標記化MLP,這種標記化MLP 能夠將卷積特征映射到抽象的標記空間中,從而降低了計算量,并利用MLP 學習有意義的特征圖信息以進行分割。使用逐深度卷積進一步減少網絡模型參數,同時還能捕捉到重要的圖像特征。為了將局部性引入所提出的方法中,該算法在特征圖中采用窗口劃分的方式,并在每個窗口中執行標記混合投影,以對特征像素點及其周圍特征像素點之間的關系進行建模。在MLP 中引入了移位操作,通過水平和垂直兩個方向空間移動,將來自不同位置的特征進行聚合,以提取對應軸向移位的局部信息,從而引入了局部性。由于標記化特征的維度較少,且MLP 相對于卷積和Transformer 更為簡單,考慮到減小模型大小可能會影響分割性能,因此該算法在每個層后面添加一個參數量極少的注意力模塊Triplet Attention[9],它可以使模型的注意力集中在指靜脈紋路上,抑制網絡模型提取無關信息。
1 方 法
1.1 網絡結構
S-MLP 整體結構如圖1 中的A 部分所示,由沙漏狀的深度可分離卷積為基礎模塊組成編碼器、解碼器和跳躍連接的U 型結構。圖1 中的B 部分顯示了結構的處理過程:首先,通過3×3 逐層卷積提取深度方向特征,從而得到具有較強表達性的特征圖;接下來,利用沙漏狀的雙層1×1 的點卷積層將特征維度先壓縮再擴展,從而在提取到充足的通道特征信息的前提下減少卷積帶來的巨大開銷;最后,通過一層3×3 的逐層卷積來補充在點卷積過程中丟失的空間特征信息。在沙漏狀深度可分離卷積中間使用由文獻[10]提出的標記MLP 模塊。

圖1 S-MLP 總體網絡結構
1.2 Shifted MLP
Shifted MLP 利用通道投影、垂直偏移和水平偏移來提高局部信息的提取能力。通過對特征圖的維度進行軸向移動,可以獲得來自不同維度的信息流,從而捕獲局部依賴關系。特征圖軸向移動方法具體步驟為:
1)通道投影將特征映射為線性層;
2)分別在水平和垂直上進行空間移動特征,將不同位置的特征轉移至同一位置。
當特征重組時,將不同空間位置的信息組合在一起,從而獲取更多的局部特征以提高性能。在移動中引入基于窗口的注意,以向全局模型添加更多的局域性,使得MLP 更加關注特征的局部細節。
1.3 標記MLP
如圖1 中的C 部分所示,標記MLP 包括兩個移位操作層、一個GeLU 層、一個特征編碼層、一個歸一化層(LayerNorm, LN)和一個重投影層。值得注意的是,該算法使用GeLU[11]和LN 來代替常用的ReLU 激活函數和BN 層,這兩種在Transformer 中被廣泛使用,GeLU 相較于ReLU 激活函數性能表現更好,LN 沿著特征向量序列進行規范化。
特征圖經過平移操作后,在標記化MLP 模塊中,首先將特征通過嵌入投影操作轉換成特征向量并將它們映射編碼成“標記”信息;接著,采用3×3 的卷積核對這些標記進行卷積操作,然后,將這些“標記”跨越寬度傳遞給一個移位的MLP;接下來,這些特征“標記”通過深度可分離卷積層(DW-Conv)進行處理,重復上述操作,將“標記”再次跨越高度傳遞給一個移位的MLP;最后,將這些特征“標記”再次傳遞給深度可分離卷積進行層處理,使用殘差連接并將原始標記作為殘差添加到輸出的移位特征中,補充特征信息,應用層歸一化(LN)并將輸出特征傳遞給下一個模塊。
標記MLP 塊中特征圖的計算可以總結為:
式中:X表示輸入特征圖;T表示標記化;W 表示寬度;H 表示高度;DWConv 表示逐深度卷積;LN 表示歸一化層。
1.4 輕量型注意力模塊Triplet Attention
SE[12]和CBAM[13]注意力模塊在CNN 模塊中被證實是有效的。但是,它們引入的額外參數量不能被忽視。Triplet Attention 模塊可以在不涉及任何降維的情況下對注意力進行建模,并且用一種參數極小的注意力機制來模擬通道和空間注意力。如圖1 中的D 部分所示,在前兩個分支中,旋轉操作對輸入的張量X分別沿高度(H)和寬度(W)兩個軸逆時針旋轉90°。然后通過映射變換操作,由標準卷積層和批歸一化層生成形狀為1 ×H×C和1 ×C×W的中間輸出張量,這些中間輸出將被用于計算通道和高度(寬度)的跨維度交互。再經過順時針90°旋轉,恢復特征向量。對于第三個分支,與前面不同的是輸入張量X的通道通過Z-pool 輸出。最終,通過簡單平均將三個分支的輸出張量匯總。
2 實驗與結果分析
2.1 評估數據集
本次實驗采用了三個數據集。其中,山東大學MLA 實驗室創建的SDU-FV 數據集共采集了106 個人的左右手食指、中指和無名指的指靜脈圖像,每個手指采集6 張圖片,共計636 類、3 816 張圖片,大小為320×240。香港理工大學指靜脈數據集HKPU包含來自156個人的3 132 張手指圖像,分別采集了每個人的食指和中指,大小為513×256。
UTFVP 數據集是由荷蘭特文特大學創建,共包含60 個人的兩張左右手食指、中指、無名指圖像,數據集包含1 440 張PNG 格式圖像,大小為672×380。
2.2 實驗設置
本文將各個數據集隨機選取80%作為訓練集,剩余20%作為測試集。本文PC 端實驗環境配置為NVIDIA RTX A4000 顯卡,對NVIDIA 嵌入式終端JETSON NANO、JETSON TX2、JETSON XAVIAR NXJETSON 進行了相關實驗,驗證了提出算法的結構和思想,以及在終端上實現的可行性。
2.3 消融實驗
為了研究每個模塊的具體作用,本文方法在SDUFV數據集中設置了如下實驗:
1)不使用任何模塊;
2)僅使用位置嵌入操作(PE);
3)添加標記MLP 模塊;
4)添加只對水平轉移的操作;
5)添加先對垂直進行轉移操作,再對水平進行轉移操作;
6)最終的S-MLP 模型。
消融實驗結果如表1 所示,通過表中數據可以得出結論:S-MLP 模型的高效性受益于每個模塊的貢獻,在使用了標記MLP 后,Params 僅增加了6.177K,但是Flops 和Mult-Adds 分別減少了0.51G 和3M,Dice 提高4.1%、AUC 提高了0.15%、Acc 提高了0.08%。
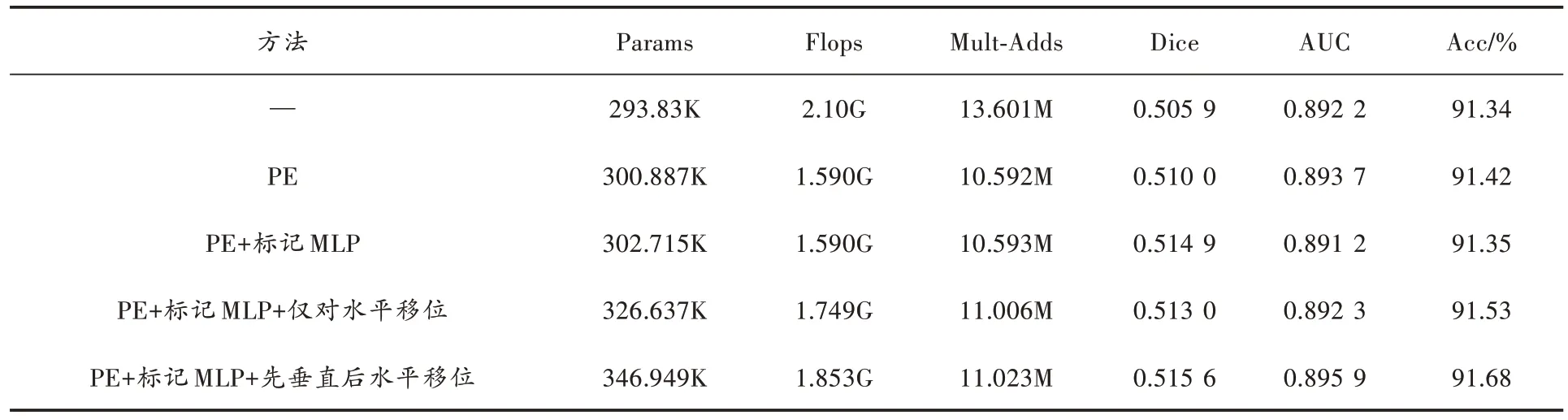
表1 各模塊消融后評價指標對比
2.4 與其他網絡模型實驗對比
觀察表2 與表3 的實驗數據可以發現,與所有的卷積結構和Transformer 結構模型相比,S-MLP 模型取得了更好的分割性能。S-MLP 模型的Params 僅有346.949K、Flops 僅有1.853G、Mult-Adds 僅有11.023M,相較于參數大小為31.042M 的UNet,Params 僅有其1.09%,Flops 和Mult-Adds 分別占其0.42%和0.31%。在模型參數大幅下降的情況下,S-MLP 模型Dice 指標達到了0.515 6,比UNet 提高了4.19%,AUC 提升了1.49%,Acc 提升了0.21%。與經典分割網絡模型DenseUNet、R2UNet、ResUNet 和AttentionUNet 相比,S-MLP 在參數量、Dice 系數和AUC 指標中同樣表現出了優異的性能。相較于所有卷積結構的網絡模型,它是最輕量的網絡模型。由于Transformer 特有的網絡結構,SwinUNet 與TransUNet的Params 達到驚人的108.496M 和116.922M。此外,SwinUNet 的缺陷在于需要提供大量的數據進行訓練,否則模型容易發生過擬合現象。SDU-FV 數據集明顯沒有達到這種需求,所以導致Dice、AUC 和Acc 表現的非常差。TransUNet 的編碼和解碼結構部分是卷積層,在一定程度上彌補了數據不足問題,但在參數量和性能指標上依然要低于S-MLP 模型。
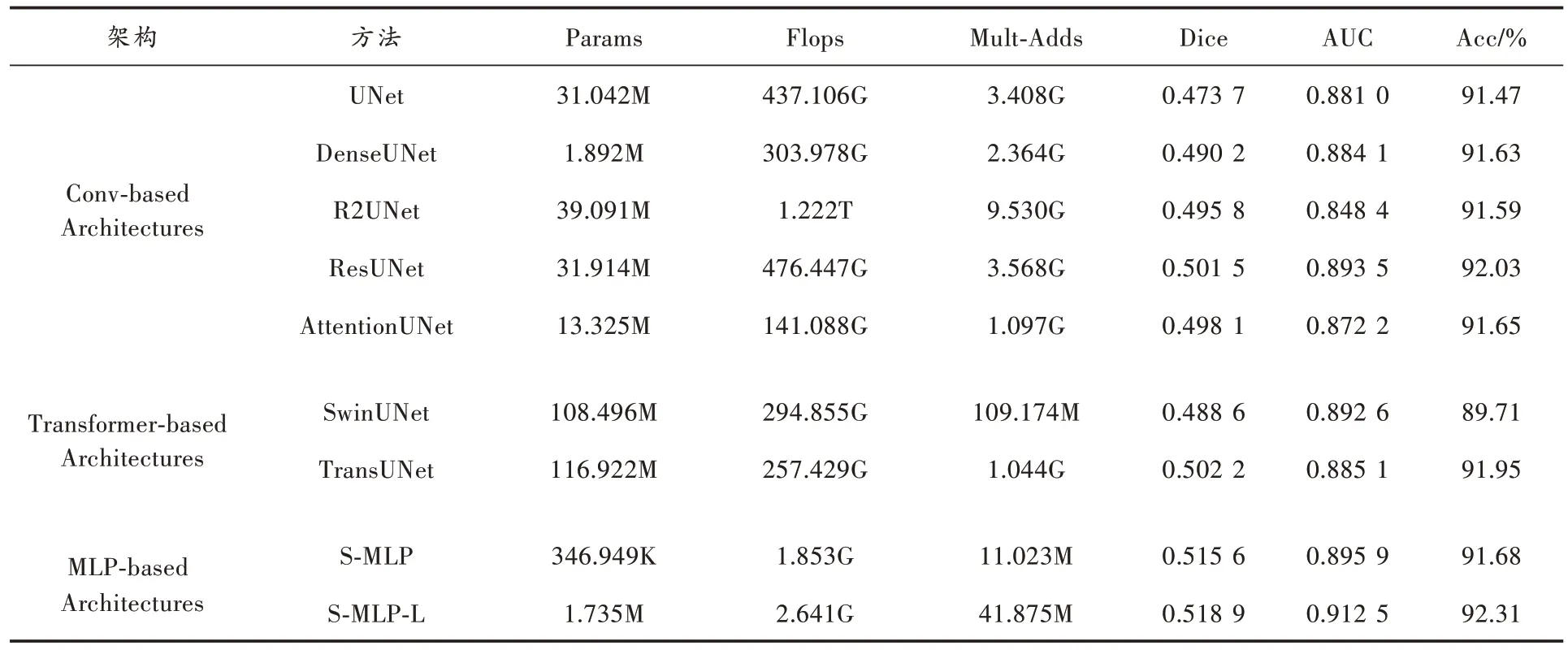
表2 S-MLP 模型在SDU-FV 數據集與其他模型效果對比
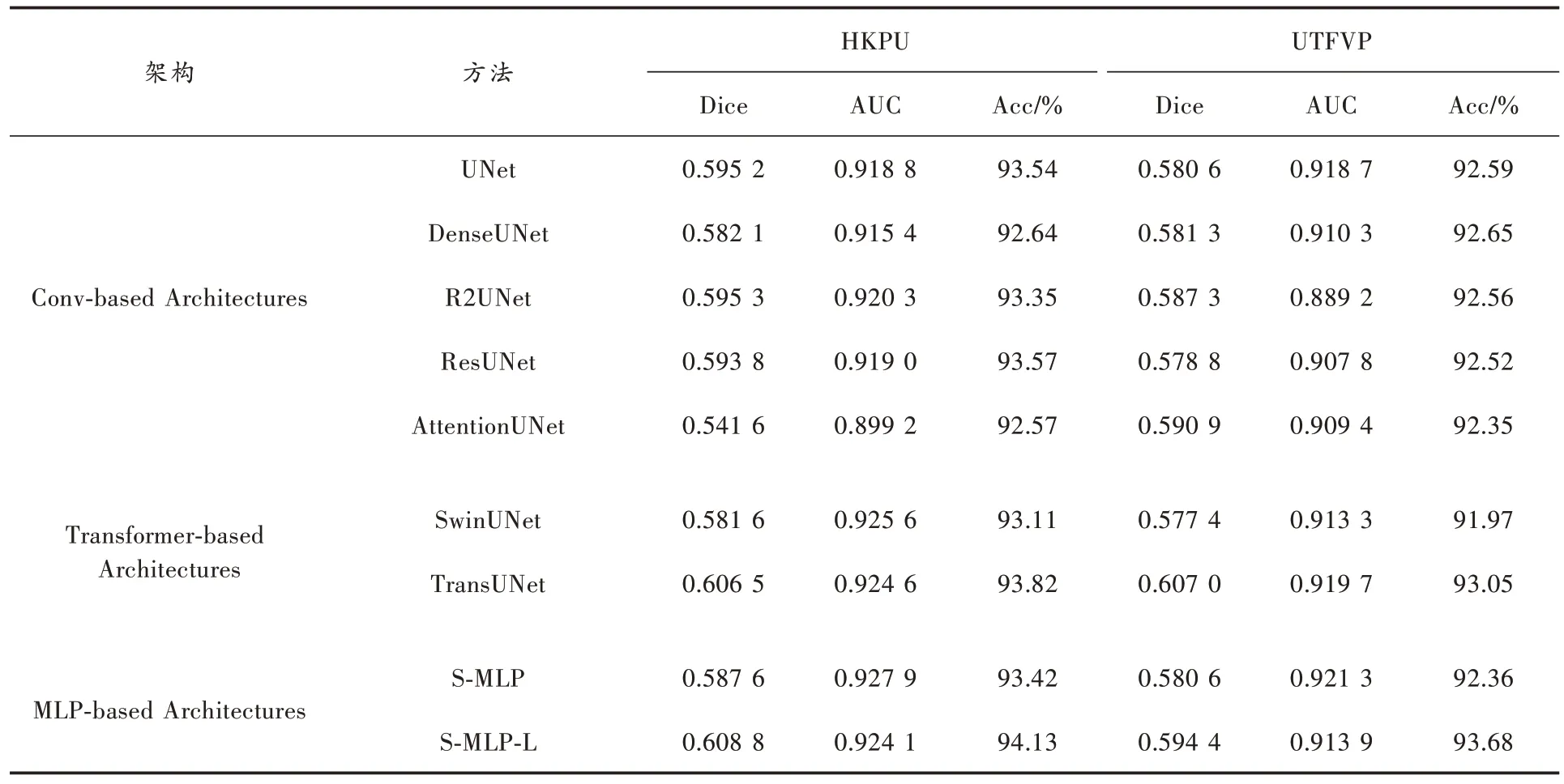
表3 S-MLP 模型在HKPU 數據集和UTFVP 數據集與其他模型效果對比
由此可見,標記MLP 將特征信息投影到更高的維度,極大減少了計算量,使得S-MLP 模型在參數量和計算復雜度上已經超越了基于CNN 和Transformer 結構的網絡模型。S-MLP 模型的整體結構和對特征圖的移位操作既有UNet 的將底層特征的位置信息和深層的語義信息相融合的能力,又有SwinTransformer 結構在窗口中建立特征像素與局部像素的依賴關系,并且計算復雜度更低。輕量級注意力模塊Triplet Attention 的加入,使得本文方法更加專注于指靜脈區域,抑制背景區域的影響,進一步提高了分割性能。
2.5 在嵌入式平臺實驗
在三個NVIDIA 嵌入式平臺中,從算力的角度來看NX>TX2>NANO。
表4 記錄了所提方法與其他網絡模型的實驗結果,需要注意的是,由于NANO 平臺算力較低,顯存僅有4 GB,因此在此平臺上無法運行參數量和計算復雜度巨大的UNet、SwinUNet 和TransUNet 網絡模型。從三個NVIDIA 嵌入式平臺的實驗結果來看,本文方法在Dice和AUC 兩個重要性能指標中都取得了最優結果,證明了輕量化的S-MLP 網絡模型以極少的參數量不僅在PC端超越了基于CNN 和Transformer 結構的網絡模型,在NVIDIA 嵌入式平臺同樣取得了優秀的性能表現,這是另外兩種結構所不具備的。
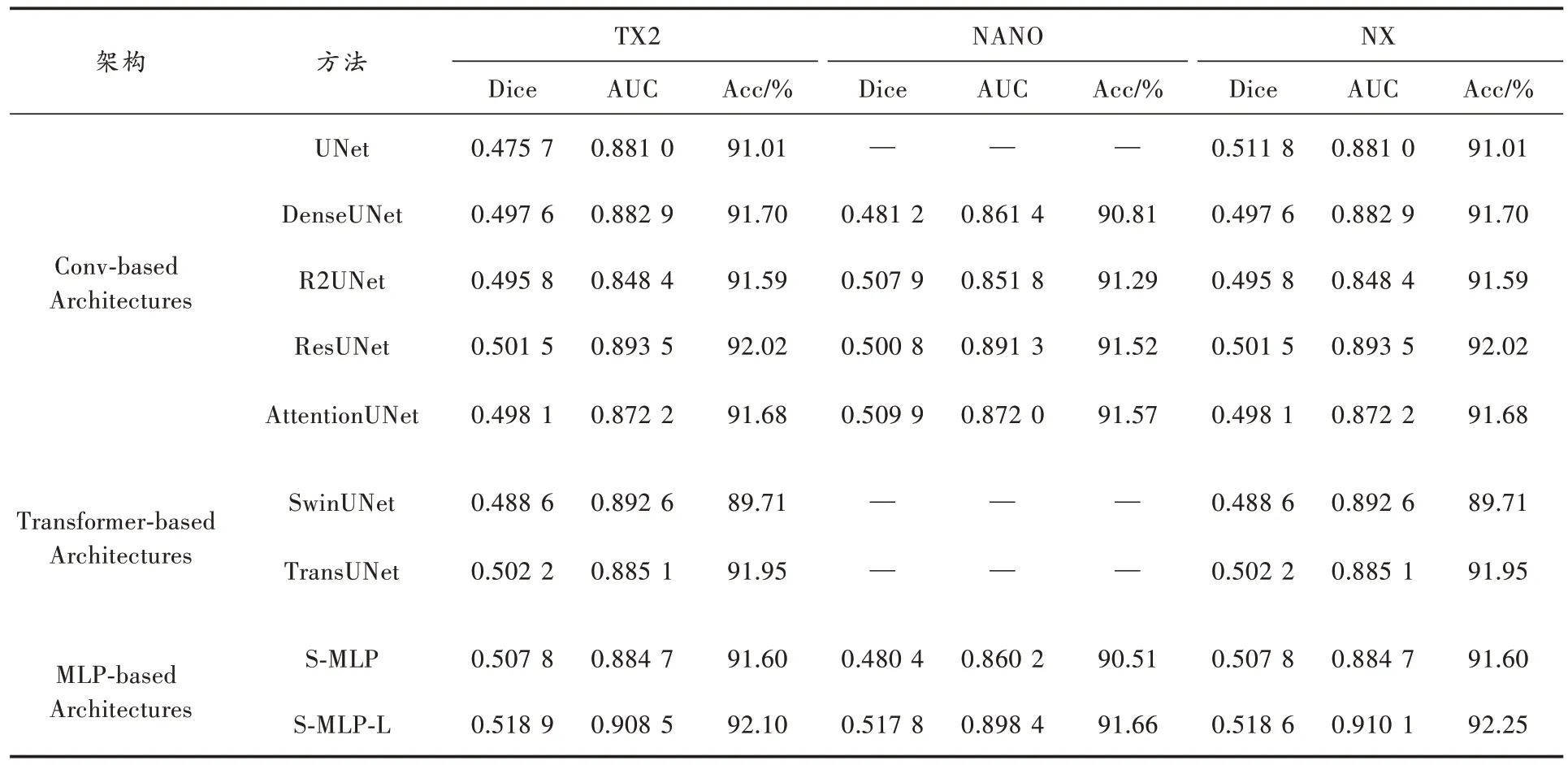
表4 S-MLP 網絡模型與其他網絡模型在NVIDIA 嵌入式平臺實驗結果對比
2.6 可視化分割效果
圖2 展示了SDU-FV、HKPU 和UTFVP 三個指靜脈數據集在各種網絡模型下的分割結果可視化圖。從圖中可以觀察到UNet 網絡模型的分割效果并不理想,部分指靜脈的細節部位并沒有很好的分割出來;TransUNet 在性能指標上雖然優于基于卷積結構的網絡模型,但是在可視化圖中依然存在血管分割斷裂的情況;S-MLP 網絡模型不僅在分割性能指標上表現出色,在可視化分割效果圖中分割出的血管形態更平滑,符合人體指靜脈血管特點。
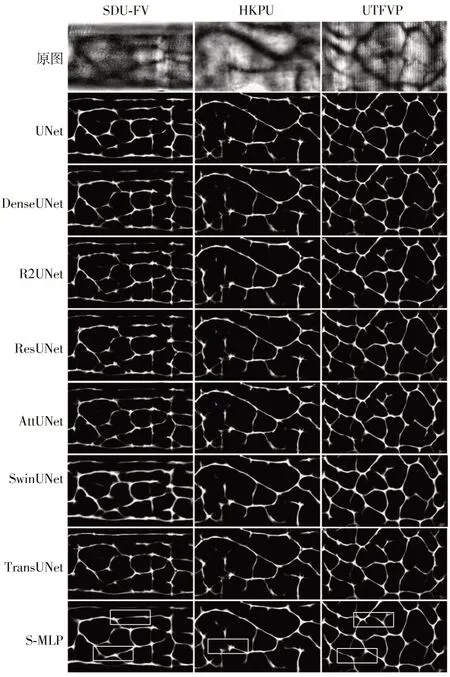
圖2 各個網絡模型在SDU-FV、HKPU 和UTFVP數據集上的實際分割效果圖
3 結 語
本文提出的算法能夠有效地解決現有基于CNN 和Transformer 結構模型的內存資源占用問題,并在嵌入式平臺上表現出色。S-MLP 是一種輕量級指靜脈紋路分割網絡模型,采用Shifted MLP 對特征圖進行軸向移位使網絡模型更關注特征圖局部位置信息;使用標記MLP塊標記和投影特征信息;最后在每一層之間添加輕量級的注意力模塊Triplet Attention,分別在三個分支上對空間維度和通道維度進行跨維度交互,建立起空間注意力,解決了模型輕量化導致性能下降的問題。S-MLP 在三個指靜脈分割數據集上都取得了最優的分割性能并且參數量最少,在算力有限的嵌入式終端中仍能取得先進的性能。
注:本文通訊作者為秦傳波。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
鐵道通信信號(2018年2期)2018-04-18 12:18:23
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
電鍍與環保(2016年3期)2017-01-20 08:15:32
光學精密工程(2016年6期)2016-11-07 09:07:19
單片機與嵌入式系統應用(2014年9期)2014-03-11 15:35:13
