基于深度卷積神經(jīng)網(wǎng)絡(luò)的汽車圖像分類算法與加速研究
2024-04-02 03:42:46黃佳美張偉彬熊官送
現(xiàn)代電子技術(shù) 2024年7期
黃佳美,張偉彬,熊官送
(北京自動(dòng)化控制設(shè)備研究所,北京 100074)
0 引 言
隨著城市化建設(shè)不斷發(fā)展,我國對交通建設(shè)的需求也不斷增長,成為了世界上在交通領(lǐng)域基礎(chǔ)設(shè)施建設(shè)方面最快的國家之一,但車輛管控問題、道路交通問題、車輛違章問題等層出不窮,很難做到全面、有效的管理。例如搶占公交專用車道,會(huì)造成車輛停站時(shí)間較長,市民乘車不方便等問題,更容易導(dǎo)致壓車現(xiàn)象出現(xiàn),進(jìn)而造成新的交通擁堵。馬路上的攝像頭每天拍攝下許多汽車照片,如何在大量的圖片中篩選出汽車的圖片,并且識(shí)別出車輛種類,這時(shí)車輛識(shí)別就顯得尤為重要。傳統(tǒng)的手動(dòng)分類方式需要耗費(fèi)大量的時(shí)間和精力,且容易出現(xiàn)主觀性誤判的情況[1]。而深度學(xué)習(xí)作為新一代計(jì)算模式,近年來在眾多領(lǐng)域中發(fā)揮了重要作用[2],以卷積神經(jīng)網(wǎng)絡(luò)為代表的深度學(xué)習(xí)算法在計(jì)算機(jī)視覺處理領(lǐng)域中發(fā)揮著巨大的作用,如圖像分類、目標(biāo)檢測等具體應(yīng)用[3-6]。隨著近年來智慧交通系統(tǒng)的快速發(fā)展,利用深度神經(jīng)網(wǎng)絡(luò)區(qū)分公交車道上的公共汽車與非法停留的車輛是一個(gè)很好的解決途徑,能夠有效地減少交通堵塞并打擊社會(huì)車輛在高峰時(shí)期非法占用公交車道的行為。
神經(jīng)網(wǎng)絡(luò)在PC 端訓(xùn)練完成后需要進(jìn)行模型部署。模型部署是指把訓(xùn)練好的模型布置在特定環(huán)境中運(yùn)行的過程,可以將神經(jīng)網(wǎng)絡(luò)部署在服務(wù)器上,通過網(wǎng)絡(luò)調(diào)用進(jìn)行預(yù)測,或者部署在嵌入式設(shè)備上,實(shí)現(xiàn)嵌入式端數(shù)據(jù)分析處理。模型部署要解決模型框架兼容性差和部署后模型運(yùn)行速度慢這兩大問題[7]。隨著物聯(lián)網(wǎng)時(shí)代的來臨和邊緣計(jì)算的興起,未來社會(huì)的發(fā)展趨勢是萬物互聯(lián)和萬物感知,因此在嵌入式端部署深度學(xué)習(xí)算法具有重要的現(xiàn)實(shí)意義[8-10]。
而神經(jīng)網(wǎng)絡(luò)處理單元是應(yīng)用人工智能的核心組件,決定著神經(jīng)網(wǎng)絡(luò)運(yùn)算的性能和功耗。為了提供更好的運(yùn)算能效比和滿足算法在嵌入式端的應(yīng)用落地,在現(xiàn)有研究的基礎(chǔ)上,本文提出基于FPGA 的嵌入式深度卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)加速,去改進(jìn)對于模型部署后運(yùn)行速度慢的問題。與其他研究相比,本文主要做了以下工作:
1)針對現(xiàn)有占用公交專用車道的問題,在開源數(shù)據(jù)集的基礎(chǔ)上提取訓(xùn)練集并加入遷移學(xué)習(xí)方法進(jìn)行重新訓(xùn)練,使得訓(xùn)練后的模型參數(shù)對公交車分類的精確度更高。
2)對于訓(xùn)練方法,提出基于深度卷積神經(jīng)網(wǎng)絡(luò)的圖像物體分類算法,采用多精度混合訓(xùn)練方法,根據(jù)網(wǎng)絡(luò)結(jié)構(gòu)特性在特征提取部分采用INT8,線性層分類采用FP32,在保證運(yùn)算效率的同時(shí)降低精度損失。
3)對于在FPGA 部署方案,采用匹配靈活硬件加速結(jié)構(gòu)的軟件計(jì)算框架,通過高效的調(diào)度保證硬件加速器中各個(gè)模塊能及時(shí)連續(xù)地工作,從而實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)的高效任務(wù)執(zhí)行。
1 模型選擇與分析
殘差卷積神經(jīng)網(wǎng)絡(luò)能夠有效解決因網(wǎng)絡(luò)深度增加而產(chǎn)生梯度消失的問題。ResNet 是一種深度殘差網(wǎng)絡(luò),在多個(gè)圖像分類基準(zhǔn)數(shù)據(jù)集上都取得了優(yōu)異的性能,實(shí)現(xiàn)了高精度的分類。ResNet 系列網(wǎng)絡(luò)包括ResNet18、ResNet34、ResNet50、ResNet101 等,網(wǎng)絡(luò)模型數(shù)字越大,代表模型越大,所需要的計(jì)算量越大。ResNet50 具有精度高、模型小、易于實(shí)現(xiàn)等優(yōu)點(diǎn)[11-12],綜合考慮,本文所部署的ResNet 網(wǎng)絡(luò)采用ResNet50 網(wǎng)絡(luò)模型。
1.1 數(shù)據(jù)集處理
在基于深度學(xué)習(xí)的圖像分類方法中,圖像被表示為一個(gè)張量,其中每個(gè)張量都代表一個(gè)RGB 圖像,各種圖像作為label,根據(jù)數(shù)據(jù)分布情況排成與張量數(shù)量相等的矩陣表示label,并將輸入數(shù)據(jù)送入深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練,學(xué)習(xí)出最優(yōu)的分類器模型。
為了實(shí)現(xiàn)所需的應(yīng)用落地,基于開源數(shù)據(jù)集從中重新抽取了相關(guān)圖片作為數(shù)據(jù)集。訓(xùn)練前,對數(shù)據(jù)進(jìn)行預(yù)處理,包括刪除重復(fù)項(xiàng)、填補(bǔ)缺失值和去除異常模糊圖片等。最終,本文得到了包含約1 萬張圖片的數(shù)據(jù)集,用于后續(xù)的分析。其中大約70%用于訓(xùn)練,20%用于測試,10%用于驗(yàn)證。本文選取進(jìn)行目標(biāo)分類的數(shù)據(jù)集共包含兩類,分別是公交車輛和其他車輛。圖片是不同大小的RGB 圖像,對數(shù)據(jù)進(jìn)行預(yù)處理,將像素值統(tǒng)一為224×224 的圖片大小,并將圖片放到相應(yīng)分類的文件夾里。目標(biāo)分類數(shù)據(jù)集如圖1 和表1 所示。
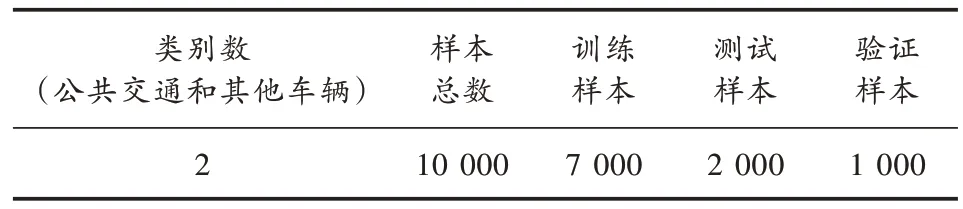
表1 數(shù)據(jù)集

圖1 目標(biāo)分類數(shù)據(jù)集部分示例
1.2 殘差模型
若將輸入設(shè)為X,將某一有參網(wǎng)絡(luò)層設(shè)為H,那么以X為輸入的此層輸出將為H(X)。一般的CNN 網(wǎng)絡(luò)如Alexnet、VGG 等會(huì)通過訓(xùn)練直接學(xué)習(xí)出參數(shù)函數(shù)H的表達(dá)。殘差學(xué)習(xí)則是致力于使用多個(gè)有參網(wǎng)絡(luò)層來學(xué)習(xí)輸入、輸出之間的參差,其中X這一部分作為分支直接輸入,使得網(wǎng)絡(luò)的深度更加穩(wěn)定,而有參網(wǎng)絡(luò)層要學(xué)習(xí)的輸出H(X)用于計(jì)算結(jié)果并預(yù)測損失值。
殘差網(wǎng)絡(luò)模塊如圖2 所示。
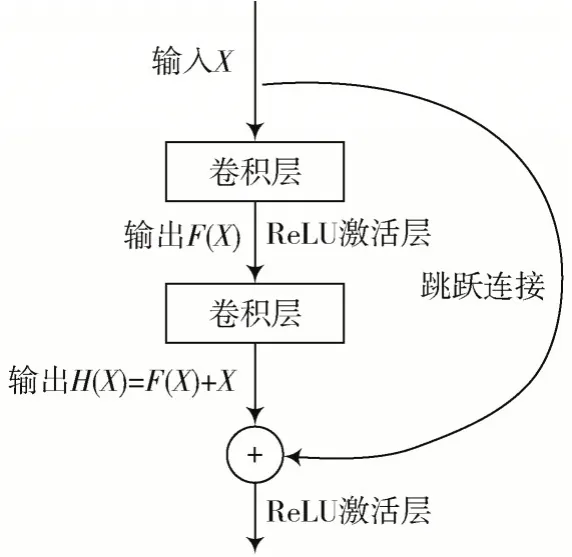
圖2 殘差網(wǎng)絡(luò)模塊
ResNet50 采用殘差連接的結(jié)構(gòu),整體模塊由卷積層、批次歸一化層、特征拼接層、池化、激活函數(shù)等組成。ResNet50 共有50 層,模型的輸入為224×224 的RGB 圖像,經(jīng)過第一層的卷積、池化運(yùn)算之后通道數(shù)增加到64,圖像降維到56×56,進(jìn)入殘差模塊之后,經(jīng)過4 次殘差操作圖像特征圖變?yōu)椋? 048,7,7)。雖然ResNet50 解決了梯度消失問題,但是依舊存在大模型在嵌入式平臺(tái)部署后實(shí)時(shí)性較差的問題。
1.3 樣本訓(xùn)練方法
遷移學(xué)習(xí)是指將在某個(gè)領(lǐng)域或任務(wù)上學(xué)習(xí)到的知識(shí)和技能應(yīng)用到新的領(lǐng)域或者任務(wù)中,可有效解決深度學(xué)習(xí)中因?yàn)閿?shù)據(jù)集不足而導(dǎo)致網(wǎng)絡(luò)模型出現(xiàn)過擬合的問題。遷移學(xué)習(xí)大致可以分為:基于特征的遷移方法、基于共享參數(shù)的遷移方法和基于關(guān)系的遷移方法[13]。其中,基于共享參數(shù)的遷移方法結(jié)合了深度學(xué)習(xí)和遷移學(xué)習(xí),通過對包含高質(zhì)量的標(biāo)注數(shù)據(jù)大數(shù)據(jù)集進(jìn)行訓(xùn)練,得到預(yù)訓(xùn)練模型,在此基礎(chǔ)上,采用少量標(biāo)注數(shù)據(jù)的小樣本數(shù)據(jù)集進(jìn)行遷移學(xué)習(xí),完成目標(biāo)分類的任務(wù)。本文采用的是基于共享參數(shù)的遷移方法。
遷移學(xué)習(xí)與傳統(tǒng)學(xué)習(xí)對比如圖3 所示。
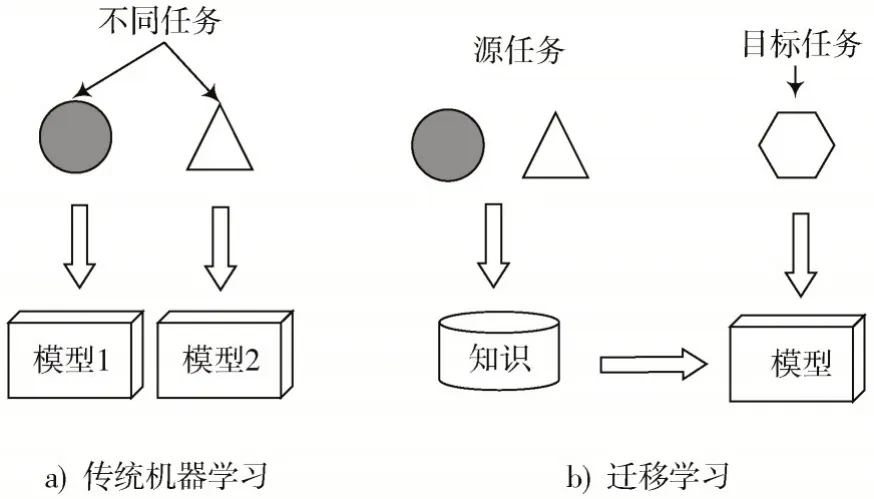
圖3 遷移學(xué)習(xí)與傳統(tǒng)學(xué)習(xí)對比
針對小樣本數(shù)據(jù)集及樣本數(shù)據(jù)相似度高的情況,本文方法保留了預(yù)訓(xùn)練模型中的卷積層、Bottle-Nect 網(wǎng)絡(luò)結(jié)構(gòu)以及預(yù)訓(xùn)練參數(shù),所保留的網(wǎng)絡(luò)結(jié)構(gòu)和預(yù)訓(xùn)練參數(shù)用于提取圖像初始特征,另外的全連接層參數(shù)則進(jìn)行重置,并基于小樣本數(shù)據(jù)集進(jìn)行重新訓(xùn)練。本文對全連接層網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行了改進(jìn),模型訓(xùn)練數(shù)據(jù)處理如圖4所示。
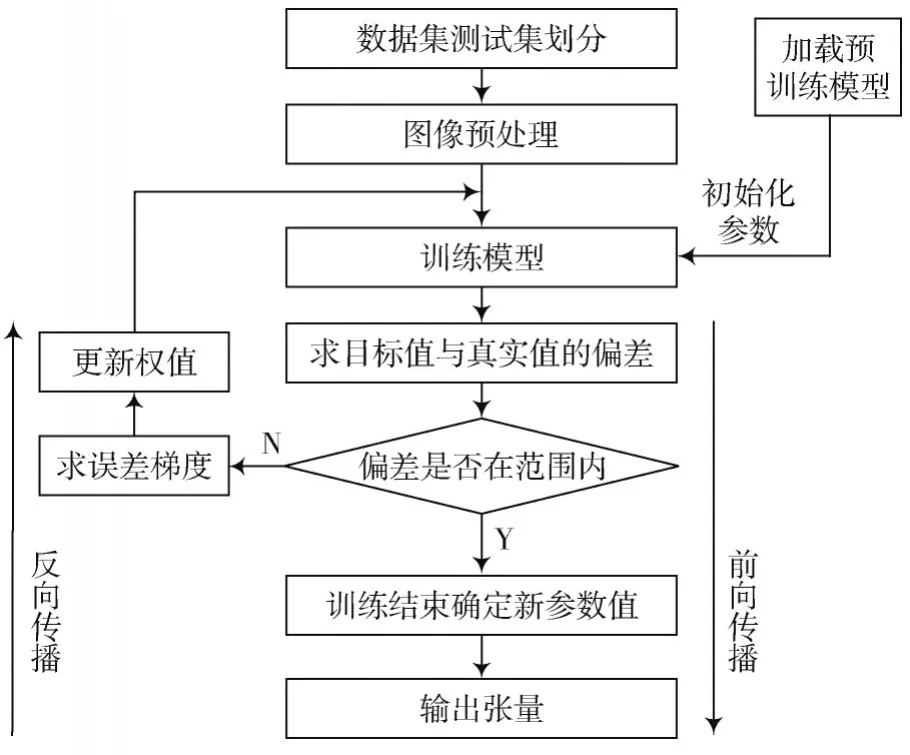
圖4 模型訓(xùn)練數(shù)據(jù)處理
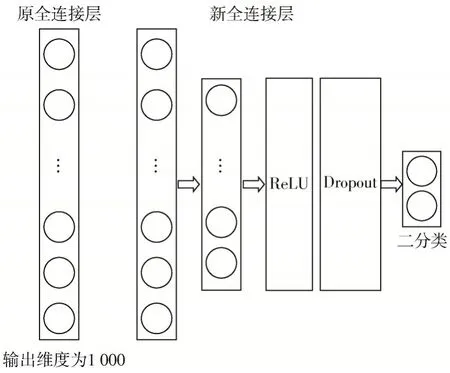
圖5 全連接層網(wǎng)絡(luò)結(jié)構(gòu)
式中:ncorrect為被正確分類的圖片數(shù)量;ntotal為測試集總的圖片數(shù)量。通常認(rèn)為Acc 越高代表模型分類效果越好。
2 FPGA 實(shí)現(xiàn)方法及設(shè)計(jì)結(jié)果
ResNet50 計(jì)算加速系統(tǒng)如圖6 所示。
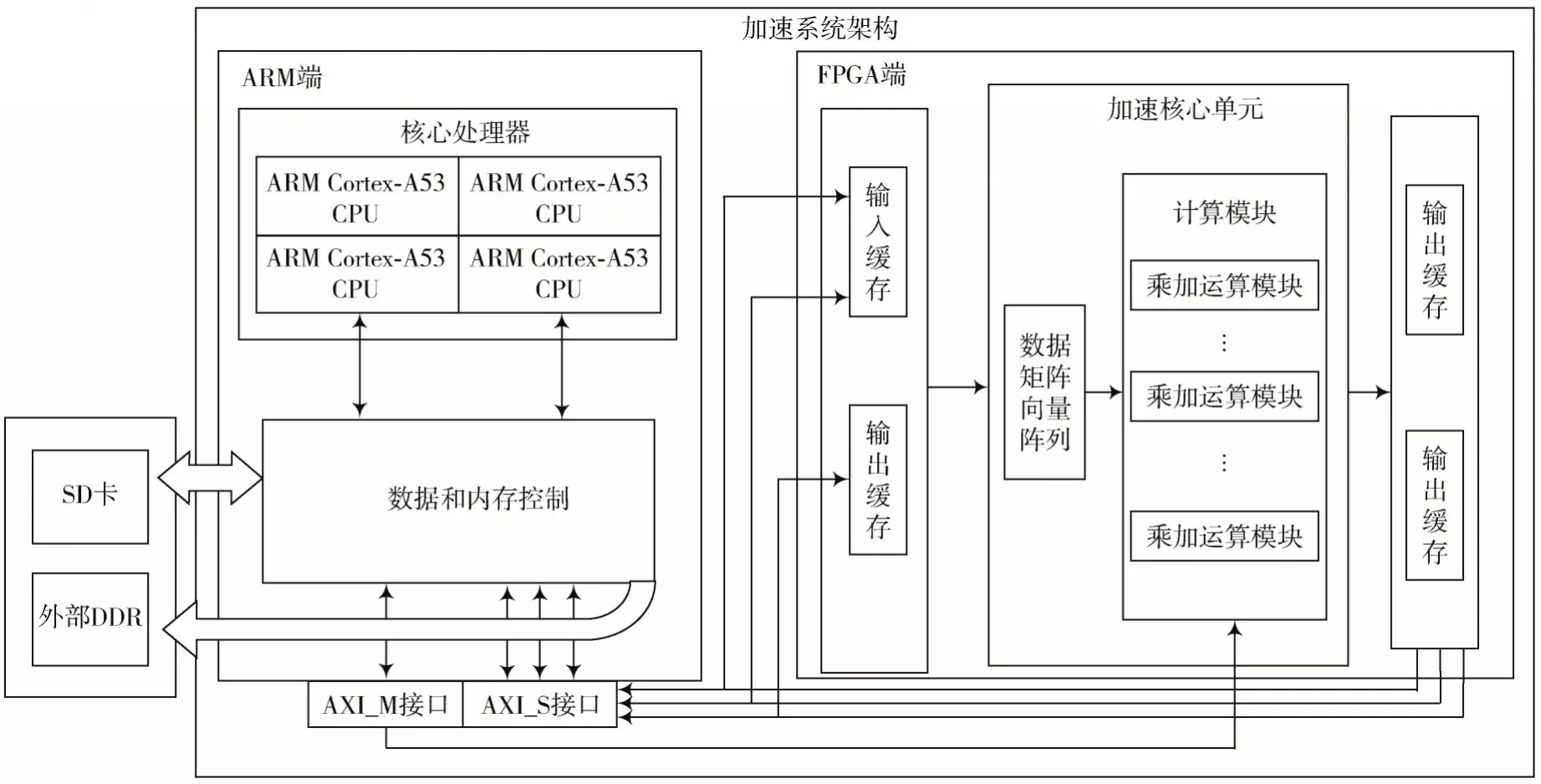
圖6 加速系統(tǒng)架構(gòu)
所述系統(tǒng)包括ARM 和FPGA 平臺(tái)架構(gòu)、片外存儲(chǔ)區(qū)、AXI 接口,所述ARM 平臺(tái)架構(gòu)包括核心處理器、數(shù)據(jù)和內(nèi)存控制器,所述FPGA 平臺(tái)架構(gòu)包括加速核心單元、輸入緩存端和輸出緩存端。使用軟核ARM 作為片上系統(tǒng)的主控,控制外設(shè)、DMA、CNN 加速器來實(shí)現(xiàn)數(shù)據(jù)調(diào)度和操作,為FPGA 設(shè)備設(shè)計(jì)了一個(gè)IP,用于卷積加速的應(yīng)用。
片外存儲(chǔ)區(qū)包括SD 卡和外部DDR,加速核心單元包括數(shù)據(jù)矩陣向量陣列和計(jì)算模塊,緩存區(qū)連接數(shù)據(jù)和內(nèi)存控制器,數(shù)據(jù)和內(nèi)存控制器連接片外存儲(chǔ)區(qū),數(shù)據(jù)和內(nèi)存控制器連接AXI_M 和AXI_S 接口,輸入緩存端連接數(shù)據(jù)矩陣向量陣列,計(jì)算模塊連接輸出緩存端,使用AXI 接口連接計(jì)算模塊。根據(jù)計(jì)算描述生成計(jì)算實(shí)現(xiàn)的過程,總結(jié)如下:
算法: 計(jì)算描述與計(jì)算實(shí)現(xiàn)的映射算法
Input:算法中產(chǎn)生的映射表s,卷積參數(shù)描述Ip
Output:硬件算子隊(duì)列Q
1:根據(jù)I,分配該層卷積中所有數(shù)據(jù)片外存儲(chǔ)地址
本文將協(xié)同過濾算法用于學(xué)生學(xué)習(xí)結(jié)果預(yù)測,將學(xué)生看作用戶,將學(xué)生的學(xué)習(xí)表現(xiàn)看作項(xiàng)目,采用以學(xué)生為主體的協(xié)同過濾算法,尋找與目標(biāo)學(xué)生距離最近的K個(gè)學(xué)生,根據(jù)這K個(gè)學(xué)生的學(xué)習(xí)結(jié)果來預(yù)測目標(biāo)學(xué)生的學(xué)習(xí)結(jié)果。
2:根據(jù)s中的塊級(jí)映射參數(shù)和I,分配每個(gè)塊級(jí)任務(wù)中的數(shù)據(jù)的片上地址
3:進(jìn)行數(shù)據(jù)張量與片上內(nèi)存段的標(biāo)記
4:fori=0 to IC_C,j=0 to OC_C,k=0 to FM_C do
5:根據(jù)s中的細(xì)粒度映射參數(shù),分配每個(gè)細(xì)粒度任務(wù)中的片上數(shù)據(jù)地址
6:進(jìn)行細(xì)粒度任務(wù)級(jí)別的數(shù)據(jù)張量標(biāo)記與片上內(nèi)存段的標(biāo)記
7:根據(jù)塊級(jí)任務(wù)中的標(biāo)記與細(xì)粒度任務(wù)級(jí)中的標(biāo)記,確定依賴信息
8:forl=0 to ic_c,m=0 to oc_c,n=0 to fm_c,p=0 to k_c do
9:根據(jù)依賴信息及計(jì)算描述和細(xì)粒度映射參數(shù),生成硬件元算子隊(duì)列Q
10:endfor
11:endfor
加速器的工作過程分為數(shù)據(jù)加載、數(shù)據(jù)處理和結(jié)果輸出3 個(gè)步驟。在數(shù)據(jù)加載階段, 計(jì)算所需的所有數(shù)據(jù)都從片外的動(dòng)態(tài)隨機(jī)存取存儲(chǔ)器傳輸?shù)狡暇彌_區(qū),包括該層的量化后權(quán)重、偏置和特征圖。CPU 在調(diào)用PL端的加速器之前,將這一層的控制信息寫入PL 端的控制寄存器,加速器根據(jù)這些參數(shù)處理數(shù)據(jù)。每一層的輸出結(jié)果必須在下一層數(shù)據(jù)加載前寫回DRAM。
每個(gè)模塊并行地按序執(zhí)行指令,不同模塊間使用和產(chǎn)生的數(shù)據(jù)之間存在依賴關(guān)系,同時(shí)每條指令都需要使用片上存儲(chǔ),同一個(gè)單元RAM 在同一時(shí)間段內(nèi)只能被一個(gè)模塊讀、一個(gè)模塊寫,所以不同模塊之間的指令執(zhí)行既需要保證順序正確,同時(shí)也要保證訪存不會(huì)出現(xiàn)沖突。本設(shè)計(jì)中使用兩種機(jī)制來保證指令流和數(shù)據(jù)流的順序正確以及訪存不會(huì)出現(xiàn)沖突,模塊雖然并行地按序執(zhí)行指令,但指令是否執(zhí)行由每個(gè)模塊中用于處理依賴和內(nèi)存請求信息的頂部模塊決定,指令的執(zhí)行需要滿足兩個(gè)條件,依賴檢查通過以及請求的內(nèi)存未被占用。
緩存順序如圖7 所示。
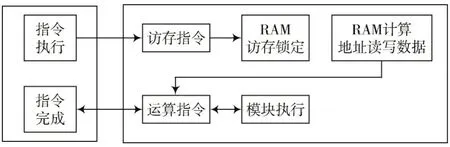
圖7 緩存順序
3 仿真與結(jié)果分析
本文實(shí)驗(yàn)使用Pytorch 深度學(xué)習(xí)框架搭建卷積神經(jīng)網(wǎng)絡(luò),采用ResNet50 模型在圖像數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)。對于所有量化實(shí)驗(yàn),學(xué)習(xí)率最初設(shè)置為0.001,每10 個(gè)epoch 衰減一次,衰減系數(shù)設(shè)置為0.1。將輸入圖像大小統(tǒng)一調(diào)整為224×224 進(jìn)行訓(xùn)練。
將在Pytorch 下訓(xùn)練好的模型分別部署至CPU 與加速器上進(jìn)行運(yùn)算,模型部署至邊緣式上需要兩個(gè)步驟:首先將Pytorch 的.pth 模型轉(zhuǎn)換成ONNX 的.onnx 模型;然后采用人工拆解將.onnx 模型轉(zhuǎn)換算子通過SDK 進(jìn)行部署。硬件平臺(tái)選用Xilinx ZU9 開發(fā)板(4 核ARM Cortex-A53+FPGA),加速器使用Vivado 設(shè)計(jì)工具,在Vivado v2018.2中完成綜合與布局布線。
實(shí)驗(yàn)結(jié)果如圖8 和表2 所示。

表2 使用加速器對比

圖8 結(jié)果圖片展示
實(shí)驗(yàn)結(jié)果表明,在200 MHz 工作頻率下,加速器的峰值計(jì)算性能達(dá)到425.8 GOP/s,推測壓縮模型速度達(dá)到30.3 f/s,模塊功耗為3.56 W,是未使用FPGA 加速的推理速度的5 倍。
表3 是加速器中各類資源的使用情況。相比其他加速器方案,本文提出的硬件加速架構(gòu)對FPGA 片上各類資源要求較少。

表3 FPGA 資源消耗與系統(tǒng)功耗
4 結(jié) 語
本文采用軟硬件協(xié)同的方式將深度學(xué)習(xí)領(lǐng)域中的神經(jīng)網(wǎng)絡(luò)模型應(yīng)用于識(shí)別占用公交車道任務(wù)中,設(shè)計(jì)一種基于算子的通用深度卷積神經(jīng)網(wǎng)絡(luò)加速器,并在ARM+FPGA 異構(gòu)平臺(tái)上成功部署,實(shí)現(xiàn)了神經(jīng)網(wǎng)絡(luò)推理加速,并利用ARM 核對加速器進(jìn)行調(diào)度,加快了硬件推理速度的同時(shí)減少了精度損失,最終完成目標(biāo)分類任務(wù)。
在軟件層面,本文利用遷移學(xué)習(xí)的深度學(xué)習(xí)方法,構(gòu)造ResNet50 預(yù)訓(xùn)練模型,克服了傳統(tǒng)網(wǎng)絡(luò)每次添加新的樣本都需要重新進(jìn)行大樣本訓(xùn)練、訓(xùn)練時(shí)間長等缺點(diǎn);在硬件層面,通過合理設(shè)計(jì)硬件架構(gòu)和硬件算子,在保證加速器性能的同時(shí)減少了FPGA 資源消耗。該圖像物體分類算法為實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)在嵌入式平臺(tái)的高效、高速應(yīng)用提供了有效解決方案。
注:本文通訊作者為張偉彬。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
