基于ECAPA-TDNN網(wǎng)絡(luò)改進(jìn)的說話人確認(rèn)方法
2024-04-03 21:06:12張家良張強(qiáng)
電腦知識與技術(shù) 2024年1期
張家良 張強(qiáng)

關(guān)鍵詞:說話人確認(rèn);語音特征;ECAPA-TDNN;感受野;多尺度特征
0 引言
說話人確認(rèn)技術(shù)是判斷某段測試語音是否來自所給定的說話人,是“一對一”的判別問題。該技術(shù)已經(jīng)應(yīng)用于許多實(shí)際的領(lǐng)域,如智能家居、金融安全、刑偵破案等。近10年來,說話人確認(rèn)技術(shù)得益于深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Network,DNN) 強(qiáng)大的學(xué)習(xí)能力得到了快速發(fā)展。
鑒于DNN強(qiáng)大的特征提取能力,在說話人確認(rèn)領(lǐng)域已經(jīng)廣泛應(yīng)用。2014年,Variani[1]等人基于DNN的基礎(chǔ)上,提出了一種具有幀級別說話人聲學(xué)特征的模型,將訓(xùn)練好的DNN從最后一個隱藏層提取的說話人特定特征的平均值作為說話人的模型,稱為d-vector。相對于i-vector[2],d-vector在小規(guī)模文本相關(guān)的說話人確認(rèn)任務(wù)上有著更好的性能。由于d-vector只能提取幀級別的特征,Snyder[3]等人提出了x-vector,其主要利用多層時延神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)(Time-delay Neural Net?work,TDNN)和統(tǒng)計池化層,將幀級別的輸入特征轉(zhuǎn)化為句子級別的特征表達(dá)。此外,楊宇奇[4]還在TDNN 的基礎(chǔ)上建立多分支聚合TDNN網(wǎng)絡(luò)的方式來提取說話人的嵌入特征。
近年來,研究者開始將卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用到說話人確認(rèn)領(lǐng)域。Nagrani[5]基于循環(huán)神經(jīng)網(wǎng)絡(luò)提出了VG?GVox模型。在殘差網(wǎng)絡(luò)(Residual Networks,ResNet) [6]的基礎(chǔ)上,Chung[7] 等人提出ResNetSE34L,ResNe?tSE34V2模型,采用不同尺度的卷積核提升多尺度特征的表達(dá)能力。此外,Desplanques 等人[8]還在基于TDNN 的x-vector 架構(gòu)上,提出了ECAPA-TDNN 模型,采用引入SE-Net[9]模塊、通道注意機(jī)制和多層特征融合等增強(qiáng)方法,進(jìn)一步擴(kuò)展時間上下文,該模型已成為說話人確認(rèn)領(lǐng)域最優(yōu)秀的框架之一。
盡管當(dāng)前大部分說話人確認(rèn)網(wǎng)絡(luò)都采用了更深、更復(fù)雜的網(wǎng)絡(luò)結(jié)構(gòu)來提升特征提取能力,但這也導(dǎo)致模型的參數(shù)和推理時間倍增。鑒于此,本文提出一種改進(jìn)的ECAPA-TDNN模型,采用VoxCeleb1公開數(shù)據(jù)集進(jìn)行實(shí)驗,結(jié)果表明,相對于原模型,在說話人特征提取能力方面實(shí)現(xiàn)了明顯提升。
1 相關(guān)工作
1.1 ECAPA-TDNN 模型
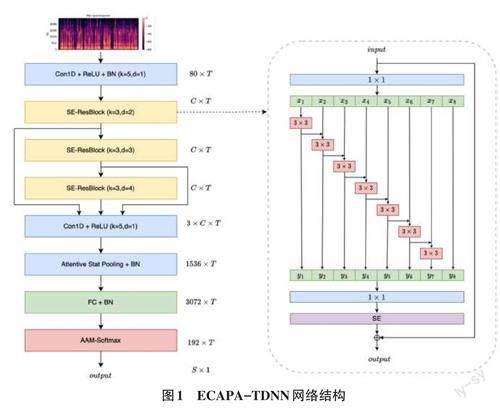
ECAPA-TDNN是一種基于音頻信號的說話人識別模型。模型如圖1所示,該模型參數(shù)包括T、C、K、d 和S,分別代表輸入的音框數(shù)目、卷積通道數(shù)目、卷積核大小、空洞卷積擴(kuò)張率和說話人數(shù)目。在本系統(tǒng)中,T為300個frame的固定值,C為512,S為訓(xùn)練數(shù)據(jù)集的說話人數(shù)目。輸入特征為80維的說話人特征向量乘T,輸入后經(jīng)過Conv1D+Relu+BN層處理,緊接著是三層1D 的擠壓激勵的Res2Block(SE-Res2Block),這些層采用不同的空洞擴(kuò)張率,分別為2、3、4。接下來一層是Cov1D+Relu,將不同擴(kuò)張率的SE-Res2Block 輸出進(jìn)行結(jié)合,形成多層特征融合(MFA)。再經(jīng)過At?tentive Statistical Pooling(ASP)層,進(jìn)行加權(quán)平均值和加權(quán)標(biāo)準(zhǔn)差聚合后進(jìn)行池化,最后通過全連接層,生成192維的說話人特征向量。最后一層采用AAMSoftmax算法進(jìn)行分類,將192維度的說話人嵌入向量進(jìn)行分類,輸出數(shù)據(jù)集訓(xùn)練的說話人數(shù)目。
1.2 提高模型嵌入向量維度
在ECAPA-TDNN模型中,通過將嵌入向量的維度從原本192維調(diào)整至512維度,可以更準(zhǔn)確地捕捉和識別不同說話者之間的語音差別,從而提升模型的準(zhǔn)確性。具體來說,說話人的特征在低維度下可能會變得模糊或失真,而高維度的嵌入可以更好地保留這些特征。此外,在進(jìn)行分類任務(wù)時,使用高維度的嵌入還可以提高模型對于訓(xùn)練數(shù)據(jù)特征的擬合能力,從而得到更好的分類效果。
1.3 改進(jìn)的SE-Res2Block
ECAPA-TDNN 模型中最重要的部分就是SERes2Block,如圖2(a) 所示,將SE-Block 添加到Res2Block模塊的末端。SE代表著壓縮(Squeeze)和激勵(Excitation),其用于增強(qiáng)卷積神經(jīng)網(wǎng)絡(luò)的表達(dá)能力,學(xué)習(xí)特征通道之間的關(guān)系,并根據(jù)特征通道的重要性對它們重新加權(quán)。在Res2Block模塊中,說話人特征信息在經(jīng)過第一個1×1卷積后,將輸入劃分為S個子集(ECAPA-TDNN模型中S為8),定義為xi,i ∈ {1,2,...,S },每份子特征的尺度大小都相同,除了最后一個子特征之外,其余的子特征都經(jīng)過一個3×3卷積,并且該卷積有空洞率參數(shù)d,定義為Convi,d ( ),其輸出為yi.子特征xi 都和Convi - 1,d ( ) 進(jìn)行相加,然后輸入Convi,d ( ),因此yi 的公式如下:
除了最后一份子特征外,Res2Block模塊在卷積操作之前可以接收其左邊的特征信息,這使得每個輸出都能夠獲得更大的感受野,從而實(shí)現(xiàn)不同數(shù)量和不同感受野大小的特征組合。
相對于原模型中潛在地獲取左邊子特征的輸出信息,為獲取更多不同大小感受野的大小組合,本文提出一種(All Connect,AC)的模型,如圖2中(b)所示。每個子特征會與左邊所有的子特征卷積結(jié)果進(jìn)行融合后再進(jìn)行卷積操作,最后一份子特征遵循原論文,不做任何操作,保留原信息。改進(jìn)后的公式如下所示:
與原模型相比,在沒有增加模型參數(shù)的前提下,每個子特征相比原來的感受野不斷增大,更全面地捕獲了所有左側(cè)特征的特征表示信息和語義信息,從而能夠更加準(zhǔn)確地提取說話人區(qū)別特征,提高模型的性能和準(zhǔn)確率。
1.4 空洞卷積擴(kuò)張率數(shù)組模塊
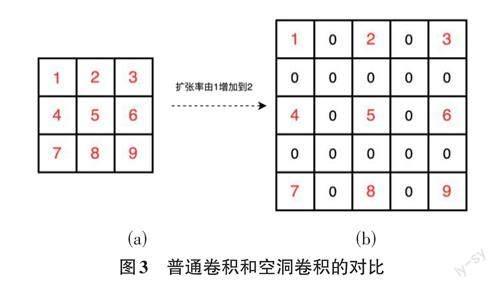
空洞卷積最初是針對圖像語義分割問題中下采樣導(dǎo)致圖像分辨率下降、信息丟失的情況提出的一種卷積方法。相比于標(biāo)準(zhǔn)的卷積,空洞卷積引入了一個超參數(shù)稱為擴(kuò)張率(dilation rate,d),d 表示卷積核內(nèi)部各個點(diǎn)間的數(shù)量,標(biāo)準(zhǔn)卷積核的擴(kuò)張率為1。空洞卷積的優(yōu)點(diǎn)在于不進(jìn)行池化操作的情況下,擴(kuò)大了卷積核的感受野,使得每個卷積可以接收更廣范圍的信息。以3×3的卷積為例來展示普通卷積和空洞卷積,如圖3所示。
由圖3可知,(a) 為普通的標(biāo)準(zhǔn)卷積,其感受野為3;(b) 圖中將標(biāo)準(zhǔn)卷積的d 設(shè)置為2,其感受野由原來的3擴(kuò)大為5。感受野的計算如公式(3) 所示,其中原卷積核的大小為k,空洞擴(kuò)張率為d, k'為等效的卷積核感受野的大小。
在ECAPA-TDNN 的3 層SE-Res2Block 中,Res2Net模塊被均等地分為8份,每一份的卷積核為3×3,由上到下每層SE-Res2Block擴(kuò)張率為固定的2、3、4。本文提出一種多個空洞卷積擴(kuò)張率(Multi-Dilation,MD) 數(shù)組[2,3,4,5,2,3,4,5]來替代固定的擴(kuò)張率。以固定的擴(kuò)張率2來做對比,Re2Net中8份的感受野分別為[5,5,5,5,5,5,5],MD的感受野分別為[5,7,9,11,5,7,9,11]。相比單一固定的空洞擴(kuò)張率,MD方法使用多個不同大小的擴(kuò)張率,每個分支學(xué)習(xí)可以學(xué)習(xí)到不同大小尺度的特征信息,能夠在多個尺度上進(jìn)行表達(dá),從而增加特征的多樣性,提高模型的性能。其次多個不同大小的擴(kuò)張率可以覆蓋到更廣泛的感受野,使得網(wǎng)絡(luò)能夠更好地捕捉說話人的信息,提高模型的表示能力,從而提高模型的性能。
2 實(shí)驗設(shè)置與結(jié)果分析
2.1 實(shí)驗環(huán)境與參數(shù)設(shè)置
本文實(shí)驗的操作系統(tǒng)為Ubantu18.04,開發(fā)環(huán)境為Pytorch1.7.0,Cuda版本為11.0,編程語言為Python。實(shí)驗采用的CPU為Intel Xeon(R) 8255C,GPU為 NVIDIARTX 3090(24GB顯存)。在訓(xùn)練過程中說話人語音特征提取采用幀長為30毫秒,步長為10毫秒,使用漢明窗進(jìn)行加窗操作,使用80維濾波器組特征FBank。采用Adam優(yōu)化器,epoch為100,batchsize為150,初始學(xué)習(xí)率為0.001,采用間隔學(xué)習(xí)率調(diào)整策略(StepLR),step_size為1,gramma為0.97(每輪學(xué)習(xí)率=前一輪學(xué)習(xí)率*0.97)。
2.2 數(shù)據(jù)集
本文實(shí)驗數(shù)據(jù)采用牛津大學(xué)的VoxCeleb1公開數(shù)據(jù)集。數(shù)據(jù)集全部是文本無關(guān)的,說話人范圍廣泛,并且性別分布均衡。數(shù)據(jù)的音頻為單聲道,頻率為16 Khz,采樣大小為16 bit,WAV格式。在本次實(shí)驗中,將VoxCeleb1數(shù)據(jù)集劃分為訓(xùn)練集和測試集(兩個數(shù)據(jù)集的說話人沒有交集)。其中,訓(xùn)練集(VoxCe?leb1-train) 挑選1 211名說話人的14 864條語音,測試集(Vox Celeb1-Test) 挑選出40名說話人的4 708條語音,構(gòu)成37 611個測試對,其中18 802對來自同一說話人,18 809對來自不同說話人。
2.3 數(shù)據(jù)增強(qiáng)
在深度學(xué)習(xí)訓(xùn)練時,擁有大量的標(biāo)記數(shù)據(jù)會使得訓(xùn)練的效果更好,也能確保訓(xùn)練時,不會發(fā)生過擬合的問題,因此本文實(shí)驗利用數(shù)據(jù)增強(qiáng)的方式來增加訓(xùn)練數(shù)據(jù)的數(shù)目和多樣性。本實(shí)驗采用兩種方法進(jìn)行數(shù)據(jù)的增強(qiáng)。第1種是加入MUSAN語料庫的噪聲,MUSAN語料庫包含了演講、音樂和噪聲3個部分,演講部分的內(nèi)容大部分是政府部門的演講;音樂部分包含了古典樂和現(xiàn)代流行樂;噪聲部分包含了技術(shù)性噪聲(傳真機(jī)噪聲、撥號音等)和環(huán)境噪聲(風(fēng)聲、雨聲、動物噪聲等)。第2種是加入RIR語料庫,即房間脈沖響應(yīng),其主要用于模擬不同房間環(huán)境下的語音信號,可以制作出不同房間的聲學(xué)環(huán)境,通過添加噪聲模擬真實(shí)語音環(huán)境中存在的噪聲問題。
2.4 實(shí)驗評價標(biāo)準(zhǔn)
為了驗證模型的有效性,本文采用在說話人確認(rèn)、人臉識別等領(lǐng)域常用的等錯誤率(Equal ErrorRate,EER) 和最小檢測代價函數(shù)(Minimum DetectionCost Function, minDCF) 作為系統(tǒng)的評價指標(biāo)。minDCF公式為:
為了說明本文方法的有效性,通過消融實(shí)驗來驗證引入擴(kuò)大說話人嵌入向量的維度,空洞卷積率數(shù)組MD和AC模塊的改進(jìn)性,通過與ECAPA-TDNN模型對比驗證本文算法的優(yōu)越性。各個模型的實(shí)驗結(jié)果如表1所示:
從表1可以看出,在ECAPA-TDNN的基礎(chǔ)上將說話人的嵌入向量由192調(diào)整為512,EER和miniDCF分別提升了0.12%、0.01;由于在ECAPA-TDNN 的基礎(chǔ)上添加MD模塊,EER和miniDCF分別提升了0.22%、0.02;由于在ECAPA-TDNN 的基礎(chǔ)上添加AC 模塊,EER 和miniDCF 分別提升了0.17%、0.02。最后本文實(shí)驗添加MD、FC 和512 維度,對比原模型,EER 和miniDCF分別提升了0.31%、0.02。
3 結(jié)論
針對說話人確認(rèn)研究中難于提取充分的語音特征問題,本文提出了一種改進(jìn)ECAPA-TDNN的說話人確認(rèn)方法,該方法主要從3個方面對網(wǎng)絡(luò)層進(jìn)行改進(jìn)。首先,擴(kuò)大說話人的嵌入向量維度,以增強(qiáng)特征表達(dá)能力。其次,采用一種全連接的SE-Res2Block模塊,最后利用空洞卷積擴(kuò)張率數(shù)組,在網(wǎng)絡(luò)輸出中獲取多種感受野大小的組合,從而更有效地表達(dá)語音特征的多個尺度信息。實(shí)驗證明,本文提出的說話人確認(rèn)方法大大降低了等錯誤率,在minDCF上也有顯著提高,后續(xù)會在語音的輸入特征和模型結(jié)構(gòu)上進(jìn)行深入研究。
