一種使用Flash 陣列存儲(chǔ)數(shù)據(jù)的方法研究
2024-04-13 06:53:58翟成瑞林天鵬張彥軍
電子設(shè)計(jì)工程 2024年7期
關(guān)鍵詞:檢測(cè)
翟成瑞,林天鵬,張彥軍
(中北大學(xué)省部共建動(dòng)態(tài)測(cè)試技術(shù)國(guó)家重點(diǎn)實(shí)驗(yàn)室,山西太原 030051)
在航空航天領(lǐng)域裝備的不斷發(fā)展中,F(xiàn)lash 以其體積小,掉電數(shù)據(jù)不丟失,工作可靠等優(yōu)點(diǎn)在航空航天設(shè)備的研制試驗(yàn)過(guò)程中備受歡迎。隨著所需存儲(chǔ)數(shù)據(jù)量的增加和存儲(chǔ)數(shù)據(jù)速度的提高,單片F(xiàn)lash 的存儲(chǔ)容量和速度已經(jīng)不能滿足要求,如果使用其他大容量存儲(chǔ)介質(zhì)會(huì)存在掉電丟失,存儲(chǔ)介質(zhì)體積大,不利于布局,以及部分存儲(chǔ)介質(zhì)存在工作不可靠等缺點(diǎn)[1-2]。因此,針對(duì)高速大容量數(shù)據(jù)存儲(chǔ)的要求,對(duì)Flash陣列式存儲(chǔ)展開(kāi)了研究,針對(duì)Flash工作特性進(jìn)行了流水線管理,無(wú)效塊檢測(cè)等高效使用存儲(chǔ)陣列的方法研究。
1 存儲(chǔ)陣列
由于Flash 芯片的特性,在數(shù)據(jù)寫(xiě)入時(shí)會(huì)有兩個(gè)基本操作,先是將數(shù)據(jù)寫(xiě)到頁(yè)寄存器中,然后再?gòu)捻?yè)寄存器中將數(shù)據(jù)寫(xiě)入對(duì)應(yīng)地址的Flash 存儲(chǔ)頁(yè)中,這個(gè)過(guò)程稱為頁(yè)編程[3]。頁(yè)編程過(guò)程是由芯片自主完成的,在一片F(xiàn)lash 進(jìn)行頁(yè)編程的時(shí)候,此片F(xiàn)lash 不能進(jìn)行其他操作,要等到完成頁(yè)編程之后才可以,頁(yè)編程的時(shí)間相對(duì)于其他操作時(shí)間較長(zhǎng),這對(duì)數(shù)據(jù)存儲(chǔ)速度將會(huì)產(chǎn)生影響。而在Flash進(jìn)行自動(dòng)頁(yè)編程時(shí)是可以進(jìn)行其他芯片的操作。所以在一個(gè)數(shù)據(jù)記錄模塊中同時(shí)控制多片F(xiàn)lash作為存儲(chǔ)載體不僅可以提高存儲(chǔ)系統(tǒng)的存儲(chǔ)容量,還可以提高數(shù)據(jù)的存儲(chǔ)速度[4]。
1.1 并行排列
多片F(xiàn)lash 組合方式的不同也將對(duì)存儲(chǔ)速度產(chǎn)生不同的影響,將Flash 并行排列以后,可以同時(shí)對(duì)多片F(xiàn)lash 進(jìn)行存儲(chǔ)操作,增加了存儲(chǔ)容量[5],在一定程度上數(shù)據(jù)寫(xiě)入速度也得到了提升,但是并行排列的方式依然存在頁(yè)編程時(shí)間等待,資源浪費(fèi)等問(wèn)題,沒(méi)有充分發(fā)揮出組合的優(yōu)點(diǎn)。并行組合示意圖如圖1 所示。

圖1 并行組合
1.2 串行排列
將Flash 串行排列以后,可以在一片F(xiàn)lash 進(jìn)行頁(yè)編程的時(shí)候?qū)νǖ纼?nèi)其他的Flash 操作來(lái)進(jìn)行數(shù)據(jù)寫(xiě)入,這種排列方式充分利用了在一片F(xiàn)lash 頁(yè)編程期間自身不能進(jìn)行其他操作而需要等待的時(shí)間,提高了數(shù)據(jù)存儲(chǔ)的速度和資源利用率[6]。但是串行排列的方式不能同時(shí)對(duì)多片F(xiàn)lash 同時(shí)進(jìn)行數(shù)據(jù)加載,也沒(méi)有充分發(fā)揮出組合的優(yōu)點(diǎn)。串行組合示意圖如圖2 所示。

圖2 串行組合
1.3 矩陣式排列
基于上述優(yōu)缺點(diǎn),提出了通道間并行排列加通道內(nèi)串行排列的矩陣式組合方式,在通道間可以同時(shí)對(duì)多片F(xiàn)lash 進(jìn)行操作,在通道內(nèi),當(dāng)一片F(xiàn)lash 頁(yè)編程操作時(shí),可以對(duì)其他Flash進(jìn)行操作。這種組合方式不僅充分利用了FPGA 的邏輯資源,也充分利用了Flash的存儲(chǔ)特性進(jìn)行存儲(chǔ),很大程度上提高了數(shù)據(jù)存儲(chǔ)速度及數(shù)據(jù)存儲(chǔ)容量。該組合示意圖如圖3所示。
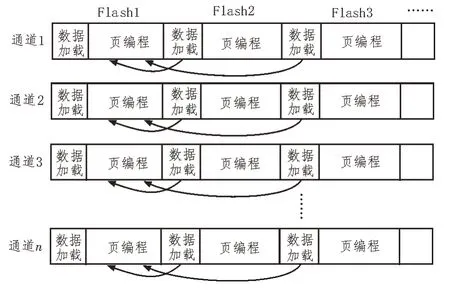
圖3 矩陣式組合
2 流水線管理
Flash 的內(nèi)部寫(xiě)入數(shù)據(jù)和讀取數(shù)據(jù)以頁(yè)為單位,每一頁(yè)中都包含有數(shù)據(jù)空間和緩存空間。許多個(gè)頁(yè)組成一個(gè)塊,數(shù)據(jù)擦除一般以塊為單位[7]。許多個(gè)塊組合組成一個(gè)存儲(chǔ)單元。以單片容量為8 Gb的Flash為例將陣列式存儲(chǔ)單元與單片存儲(chǔ)單元的存儲(chǔ)效率做以對(duì)比[8]。該Flash 的邏輯結(jié)構(gòu)圖如圖4 所示。
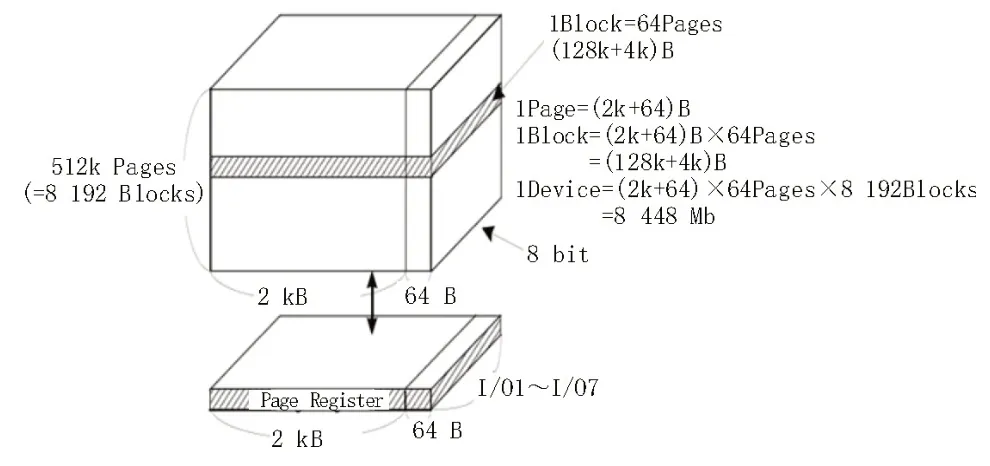
圖4 Flash邏輯結(jié)構(gòu)圖
選用的Flash 每頁(yè)的容量為2 kB,在時(shí)鐘周期50 MHz,即系統(tǒng)在時(shí)鐘周期為20 ns 下工作。Flash寫(xiě)入數(shù)據(jù)的流程為首先寫(xiě)入一個(gè)字節(jié)的命令加五個(gè)字節(jié)將要存放數(shù)據(jù)的地址,然后將數(shù)據(jù)加載到頁(yè)寄存器中,最后將頁(yè)寄存器中的數(shù)據(jù)加載到Flash 對(duì)應(yīng)的存儲(chǔ)單元中,即頁(yè)編程[9]。
寫(xiě)入指令加地址的時(shí)間為t1,一共需要六個(gè)時(shí)鐘周期;查閱數(shù)據(jù)手冊(cè)得知地址到數(shù)據(jù)加載時(shí)間需要t2=70 ns;將2 kB 的數(shù)據(jù)加載到頁(yè)寄存器中需要的時(shí)間為t3,共2 048 個(gè)時(shí)鐘周期;寫(xiě)使能從高狀態(tài)到忙信號(hào)的拉低時(shí)間需要t4=100 ns;而自動(dòng)頁(yè)編程時(shí)間t5平均需要200 μs,最大需要700 μs,以平均頁(yè)編程時(shí)間計(jì)算寫(xiě)入一頁(yè)數(shù)據(jù)總共需要的時(shí)間。該時(shí)間為T(mén)=t1+t2+t3+t4+t5=241.25 μs。單片F(xiàn)lash 的寫(xiě)入速度為V=2 kB÷241.25 μs=8.1 MB/s。
當(dāng)Flash 組成陣列式存儲(chǔ)單元后,通道間可以同時(shí)對(duì)多片F(xiàn)lash 進(jìn)行數(shù)據(jù)加載及頁(yè)編程,通道內(nèi)可以在一片F(xiàn)lash 進(jìn)行自動(dòng)頁(yè)編程時(shí)對(duì)通道內(nèi)其他的Flash 進(jìn)行數(shù)據(jù)加載操作。以此可以大幅提高數(shù)據(jù)存儲(chǔ)速度和存儲(chǔ)模塊的存儲(chǔ)容量[10]。
通道間Flash為獨(dú)立存在,互不影響,可以同時(shí)進(jìn)行頁(yè)編程操作,即同時(shí)可以將數(shù)據(jù)寫(xiě)入多個(gè)通道的第一片F(xiàn)lash。通道內(nèi)的Flash只能同時(shí)對(duì)一個(gè)芯片進(jìn)行頁(yè)編程。因此在通道內(nèi),當(dāng)數(shù)據(jù)加載到第一片F(xiàn)lash中的頁(yè)寄存器中后,利用第一片進(jìn)行自動(dòng)頁(yè)編程的時(shí)間可以繼續(xù)將需要存儲(chǔ)的數(shù)據(jù)緩存到通道內(nèi)下一片F(xiàn)lash的頁(yè)寄存器,第一片頁(yè)編程時(shí)間足夠?qū)νǖ纼?nèi)后面的好幾片F(xiàn)lash進(jìn)行數(shù)據(jù)加載至頁(yè)寄存器中的操作[11]。
該芯片數(shù)據(jù)加載到頁(yè)寄存器的時(shí)間為41.25 μs,頁(yè)編程時(shí)間200 μs,第一片進(jìn)行頁(yè)編程時(shí),其余幾片頁(yè)加載時(shí)間總和大于頁(yè)編程時(shí)間200 μs 就可以對(duì)頁(yè)編程的時(shí)間進(jìn)行充分利用,因此單個(gè)通道Flash 大于六片即可。所以單個(gè)通道串行排列的數(shù)據(jù)存儲(chǔ)速度最大可以達(dá)到V=2 kB÷41.25 μs=47.35 MB/s。單個(gè)通道內(nèi)為了節(jié)省資源和便于控制,F(xiàn)PGA 與存儲(chǔ)芯片的數(shù)據(jù)傳輸接口、命令、地址、讀寫(xiě)接口均為公用的傳輸線,只有片選信號(hào)和忙閑信號(hào)為單獨(dú)的傳輸線。單個(gè)通道內(nèi)串行排列的方式,其最大數(shù)據(jù)存儲(chǔ)速度就是單頁(yè)的存儲(chǔ)容量除以數(shù)據(jù)加載到頁(yè)寄存器的時(shí)間,這個(gè)速度相對(duì)于單片F(xiàn)lash的存儲(chǔ)速度已經(jīng)有了很大提升,但是在某些高速數(shù)據(jù)的存儲(chǔ)需求下,該速度還是不能滿足要求,所以在通道內(nèi)串行排列的基礎(chǔ)上再進(jìn)行通道間的并行排列,這可以使數(shù)據(jù)存儲(chǔ)速度比串行排列數(shù)據(jù)存儲(chǔ)速度成倍增加,并且依靠FPGA 強(qiáng)大的數(shù)據(jù)處理能力和并行運(yùn)行的特點(diǎn),該存儲(chǔ)陣列也是比較容易實(shí)現(xiàn)的[12]。如上述單個(gè)通道串行排列時(shí)的數(shù)據(jù)傳輸速度最快可以達(dá)到47.35 MB/s,通道間N倍并行排列后,存儲(chǔ)速度將會(huì)為N×47.35 MB/s。通道間并行,通道內(nèi)串行的流水線控制如圖5所示。
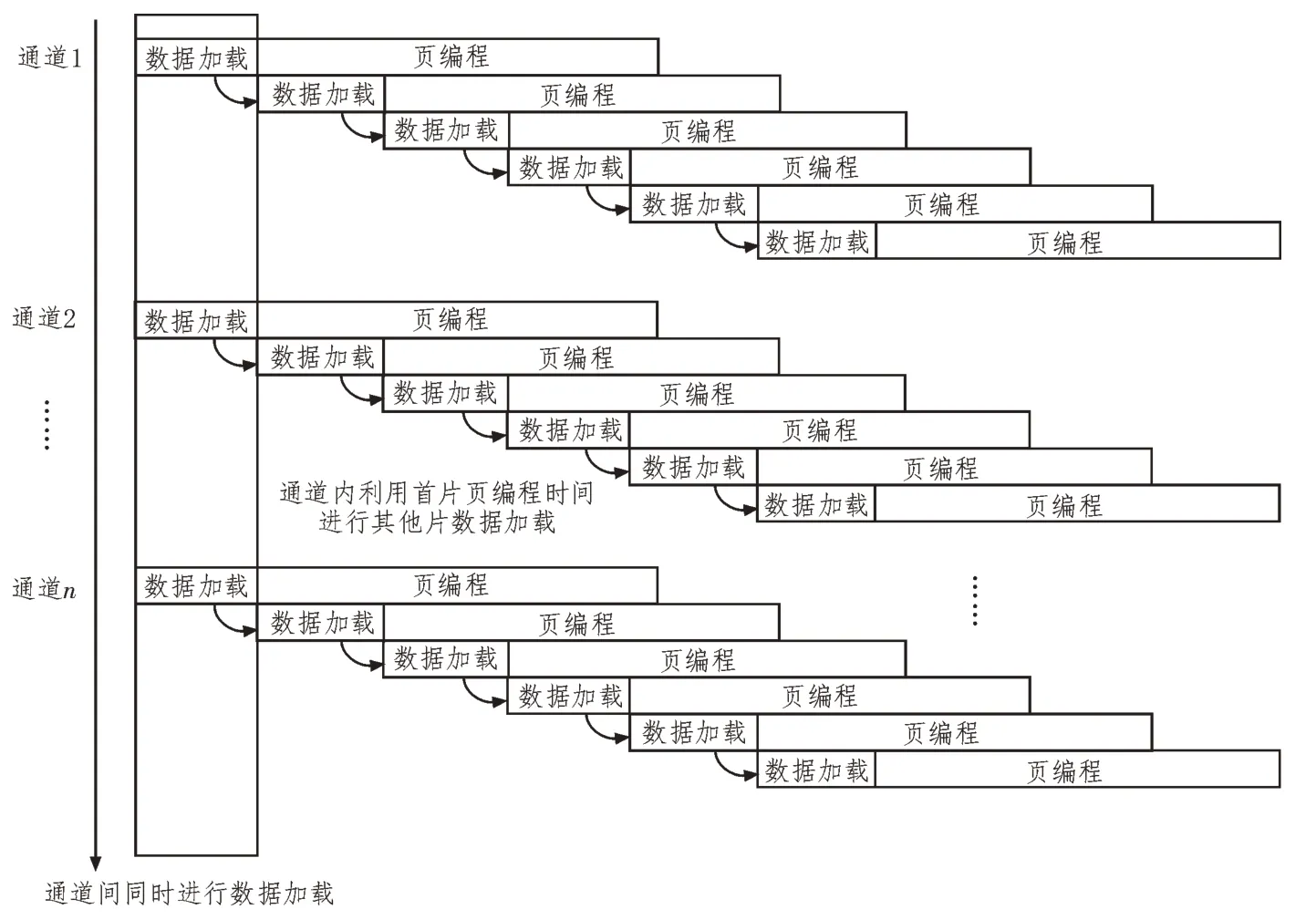
圖5 流水線控制
3 壞塊檢測(cè)及突發(fā)塊處理
3.1 單片檢測(cè)
由于受nand Flash 生產(chǎn)工藝的影響,不能保證在整個(gè)使用周期中都是可靠的,或多或少的都會(huì)產(chǎn)生壞塊,并且Flash 在出廠時(shí)有的就會(huì)存在壞塊[13]。Flash 在全部擦除后,沒(méi)有數(shù)據(jù)寫(xiě)入前,正常狀態(tài)所有的位都為高位,而出現(xiàn)壞塊后,將會(huì)在擦除或者寫(xiě)入數(shù)據(jù)時(shí)不能將某些位拉高,如果不對(duì)這些壞塊加以處理,將會(huì)導(dǎo)致數(shù)據(jù)存儲(chǔ)出現(xiàn)錯(cuò)誤,達(dá)不到預(yù)期的存儲(chǔ)效果[14]。
Flash 每頁(yè)都會(huì)有備用區(qū),而壞塊的信息將在每塊第一頁(yè)的備用區(qū)做以標(biāo)記。單片F(xiàn)lash 的檢測(cè)方式為每次對(duì)Flash 進(jìn)行擦除或者數(shù)據(jù)寫(xiě)入等操作時(shí),都對(duì)存放壞塊信息的頁(yè)空閑區(qū)進(jìn)行遍歷性檢查,如果為壞塊,將會(huì)做壞塊標(biāo)記,后續(xù)操作對(duì)該塊不再進(jìn)行數(shù)據(jù)寫(xiě)入,如果為正常的存儲(chǔ)塊,則地址加一,繼續(xù)檢查下一塊,直到所有的塊狀態(tài)信息都檢查結(jié)束。這種壞塊檢查方法雖然實(shí)現(xiàn)起來(lái)較簡(jiǎn)單,但是所需時(shí)間較長(zhǎng),不適合高速數(shù)據(jù)的存儲(chǔ)。
3.2 陣列檢測(cè)
將Flash 陣列組合是為了滿足高速數(shù)據(jù)存儲(chǔ)的要求。如果壞塊檢測(cè)還是使用遍歷性檢查的方法,那將會(huì)對(duì)存儲(chǔ)系統(tǒng)的存儲(chǔ)速度產(chǎn)生很大影響,為此將使用一種提高壞塊檢測(cè)效率的方法進(jìn)行陣列式Flash 的壞塊檢測(cè)。
Flash 中塊的好壞只有兩種狀態(tài),這兩種狀態(tài)可以用0、1 來(lái)表示,該設(shè)計(jì)所選的Flash 有8 192 個(gè)塊,8 kB 的RAM 可以將這些Flash 的所有塊信息寫(xiě)入,這個(gè)操作只需在上電后將塊信息進(jìn)行讀取寫(xiě)入RAM中,后續(xù)操作需要進(jìn)行壞塊檢測(cè)時(shí)只需讀取RAM 中的信息即可。這種壞塊檢測(cè)方式相對(duì)于遍歷性檢測(cè)大大節(jié)省了檢測(cè)時(shí)間,提升了系統(tǒng)的存儲(chǔ)速度。當(dāng)遇到陣列式Flash時(shí),如果每片都映射到一個(gè)RAM中,那所需的時(shí)間也相對(duì)較長(zhǎng),也會(huì)造成資源的浪費(fèi)。通道內(nèi)的Flash 每個(gè)芯片的存儲(chǔ)塊數(shù)是相同的,地址也是相同的,因此設(shè)計(jì)了一種將一個(gè)通道內(nèi)地址相同的塊看成一個(gè)大塊的檢測(cè)方法,這個(gè)大塊中如果有一個(gè)塊是壞塊,就判定這一整個(gè)大塊為壞塊,如圖6所示。

圖6 組合塊檢測(cè)
這種壞塊檢測(cè)方式一定程度上浪費(fèi)了一些好的存儲(chǔ)塊,但是相對(duì)系統(tǒng)總體來(lái)說(shuō),提高了系統(tǒng)的數(shù)據(jù)存儲(chǔ)速度,所浪費(fèi)的存儲(chǔ)容量相對(duì)總?cè)萘縼?lái)說(shuō)也是很少的一部分[15]。查閱芯片手冊(cè)可知,該芯片最少有8 032個(gè)有效塊,即最多每塊中有160個(gè)壞塊,以每個(gè)通道串行6片,且每塊Flash的壞塊地址都不相同,每個(gè)通道最多可達(dá)3 600個(gè)壞塊,這也就導(dǎo)致可能會(huì)有最多3 000個(gè)有效塊被浪費(fèi)。經(jīng)計(jì)算得知,在每個(gè)通道最多浪費(fèi)3 000個(gè)有效塊的情況下,該通道的Flash 存儲(chǔ)利用率為93.9%,而實(shí)際使用下,每片的壞塊不會(huì)那么多,無(wú)效組合塊也就不會(huì)那么多,實(shí)際的存儲(chǔ)容量利用率也會(huì)高于93.9%,對(duì)存儲(chǔ)空間不會(huì)造成太多的浪費(fèi)。
3.3 壞塊替換
在Flash 使用過(guò)程中,也會(huì)不可避免的產(chǎn)生一些突發(fā)的壞塊,在數(shù)據(jù)寫(xiě)入時(shí)如果不做相應(yīng)的處理,就會(huì)使數(shù)據(jù)存儲(chǔ)產(chǎn)生錯(cuò)誤,導(dǎo)致數(shù)據(jù)存儲(chǔ)失敗,降低數(shù)據(jù)存儲(chǔ)裝置的可靠性[16]。
在數(shù)據(jù)存儲(chǔ)過(guò)程中,當(dāng)數(shù)據(jù)寫(xiě)入到塊A 的第n頁(yè)時(shí),如果發(fā)現(xiàn)返回錯(cuò)誤信息,不能正常寫(xiě)入數(shù)據(jù),將該塊和該頁(yè)的地址記錄下來(lái),并將該塊第n頁(yè)到最后一頁(yè)的數(shù)據(jù)寫(xiě)入到下一個(gè)能正常存儲(chǔ)數(shù)據(jù)的塊B對(duì)應(yīng)頁(yè)中,并對(duì)上述塊A 做壞塊標(biāo)記。當(dāng)全部數(shù)據(jù)都寫(xiě)入完成以后,對(duì)照之前記錄的壞塊和頁(yè)地址,將已經(jīng)寫(xiě)入壞塊A 中的前n-1 頁(yè)的數(shù)據(jù)以頁(yè)為單位讀出后重新寫(xiě)入到其下個(gè)正常塊B 的對(duì)應(yīng)頁(yè)中完成數(shù)據(jù)的完整寫(xiě)入。滯后重寫(xiě)如圖7 所示。

圖7 滯后重寫(xiě)
4 測(cè)試與驗(yàn)證
將模擬信號(hào)源產(chǎn)生的數(shù)據(jù)存入矩陣式存儲(chǔ)陣列中,對(duì)存儲(chǔ)系統(tǒng)存儲(chǔ)容量,存儲(chǔ)速度以及存儲(chǔ)陣列的利用率等進(jìn)行測(cè)試。結(jié)果顯示矩陣式存儲(chǔ)陣列存儲(chǔ)容量和數(shù)據(jù)存儲(chǔ)速度相較單片存儲(chǔ)有成倍的提高,單個(gè)通道的有效塊使用效率達(dá)到了99%以上,遠(yuǎn)高于理論最低使用率的93.9%,且數(shù)據(jù)存儲(chǔ)可靠,滿足數(shù)據(jù)存儲(chǔ)系統(tǒng)的各項(xiàng)要求。圖8 為矩陣式存儲(chǔ)陣列存儲(chǔ)的數(shù)據(jù)。

圖8 存儲(chǔ)數(shù)據(jù)
5 結(jié)束語(yǔ)
針對(duì)單片F(xiàn)lash 存儲(chǔ)容量有限,存儲(chǔ)速度較低的現(xiàn)狀,結(jié)合Flash 的存儲(chǔ)特性,提出了一種使用Flash陣列存儲(chǔ)數(shù)據(jù)的方法,通過(guò)布置存儲(chǔ)陣列,RAM 映射進(jìn)行壞塊檢測(cè),滯后重寫(xiě)等設(shè)計(jì)大大提升了數(shù)據(jù)存儲(chǔ)容量和數(shù)據(jù)存儲(chǔ)速度,經(jīng)過(guò)理論分析及試驗(yàn)驗(yàn)證,該方法可行性高,技術(shù)實(shí)現(xiàn)難度適中,為高速數(shù)據(jù)存儲(chǔ)提供了可行性方案和技術(shù)路線。
猜你喜歡
中國(guó)設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:36
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:34
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:50
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:48
