一種基于語音、文本和表情的多模態情感識別算法
2024-05-03 09:43:14吳曉牟璇劉銀華劉曉瑞
西北大學學報(自然科學版) 2024年2期
吳曉 牟璇 劉銀華 劉曉瑞
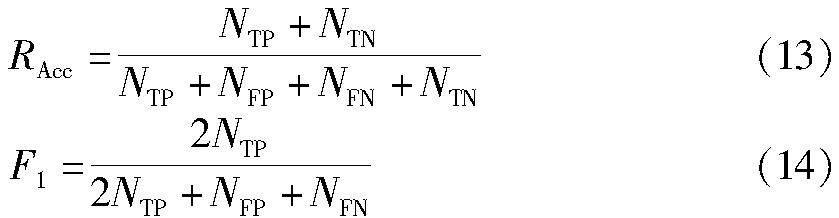
摘要 針對當前多模態情感識別算法在模態特征提取、模態間信息融合等方面存在識別準確率偏低、泛化能力較差的問題,提出了一種基于語音、文本和表情的多模態情感識別算法。首先,設計了一種淺層特征提取網絡(Sfen)和并行卷積模塊(Pconv)提取語音和文本中的情感特征,通過改進的Inception-ResnetV2模型提取視頻序列中的表情情感特征;其次,為強化模態間的關聯性,設計了一種用于優化語音和文本特征融合的交叉注意力模塊;最后,利用基于注意力的雙向長短期記憶(BiLSTM based on attention mechanism,BiLSTM-Attention)模塊關注重點信息,保持模態信息之間的時序相關性。實驗通過對比3種模態不同的組合方式,發現預先對語音和文本進行特征融合可以顯著提高識別精度。在公開情感數據集CH-SIMS和CMU-MOSI上的實驗結果表明,所提出的模型取得了比基線模型更高的識別準確率,三分類和二分類準確率分別達到97.82%和98.18%,證明了該模型的有效性。
關鍵詞 多模態;情感識別;并行卷積;交叉注意力
A multimodal emotion recognition algorithm basedon speech, text and facial expression
Abstract Aiming at the problems of low recognition accuracy and poor generalization ability of current multimodal emotion recognition algorithms in modal feature extraction and information fusion between modalities, a multimodal emotion recognition algorithm based on speech, text and expression is proposed. Firstly, a shallow feature extraction network (Sfen) combined with parallel convolution module (Pconv) is designed to extract the emotional features in speech and text. A modified Inception-ResnetV2 model is adopted to capture the emotional features of expression in video stream. Secondly, in order to strengthen the correlation among modalities, a cross attention module is designed to optimize the fusion between speech and text modalities. Finally, a bidirectional long and short-term memory module based on attention mechanism (BiLSTM-Attention) is used to focus on key information and maintain the temporal correlation between modalities. By comparing the different combinations of the three modalities, it is found that the hierarchical fusion strategy that processes speech and text in advance can obviously improve the accuracy of the model. Experimental results on the public emotion datasets CH-SIMS and CMU-MOSI show that the proposed model achieves higher recognition accuracy than the baseline model, with three-class and two-class accuracy reaching 97.82% and 98.18% respectively, which proves the effectiveness of the model.
Keywords multimodal; emotion recognition; parallel convolution; cross attention
近年來,隨著人工智能技術的快速發展,人機交互逐漸成為了當前科研人員研究的熱點。情感分析作為人機交互的重要組成部分,也呈現出了模態多元化的趨勢[1],比如使用語音、文本、表情,甚至腦電等生理信號來進行情感分析。因此,如何處理和融合這些異構信息,實現對其準確的分析與判斷,成為了當前需要解決的重點問題。
在情感識別領域中,傳統的機器學習方法如樸素貝葉斯(naive Bayes,NB)、支持向量機(support vector machine,SVM)等[2-3]被廣泛應用。但隨著深度學習技術的發展,以卷積神經網絡(convolutional neural network,CNN)、循環神經網絡(recurrent neural network,RNN)、深度卷積神經網絡(deep convolutional neural network, DCNN)[4-6]為代表的數據驅動方法逐漸成為情感分析的主流。目前,研究人員已經在單模態情感識別領域取得了一定進展。在文本情感識別方面,Xu等人提出一種基于CNN的微博情緒分類模型CNN-Text-Word2vec,使模型的整體準確率比主流方法提高了7.0%[7];在圖像情感識別方面,鄭劍等人提出了一種基于DCNN的FLF-TAWL網絡,該網絡能夠自適應捕捉人臉重要區域,提高人臉識別的有效性[8];在語音情感識別方面,部分研究將聲學特征和RNN進行結合,如Dutta等人提出一種語音識別模型,利用RNN提取線性預測編碼(linear predictive coding,LPC)和Mel頻率倒譜系數(Mel-frequency cepstral coefficients,MFCC)特征,并在識別阿薩姆語上取得了一定效果[9]。
近期的研究表明,多模態情感模型能夠將來自不同感知模態的信息有效融合。由于充分利用了數據的多樣性,多模態模型表現出比單模態模型更大的優勢。針對多模態情感識別,國內外學者已經開展了深入的研究工作。如HOU等人提出一種早期融合模型EF-LSTM,通過拼接語音、文本和表情3種模態的特征并利用LSTM進行編碼,有效提取了模態間的交互信息[10]。Zadeh等人設計一種張量融合網絡(TFN),通過采用多維張量的外積操作,較好地捕獲了不同模態間的交互信息[11]。Liu等人設計一種低秩多模態融合算法(LMF),在TFN的基礎上進行低秩多模態張量融合,使網絡效果得到一定的提升[12]。Zadeh等人提出一種記憶融合網絡(MFN),通過利用注意力機制和多視圖門控網絡,同步捕捉了時序序列和模態間的交互信息[13]。Tsai等人提出一種跨模態網絡Transformer(MulT),通過擴展多式Transformer結構,成功解決了不同模態數據的長期依賴性問題,進一步提高了模型性能[14]。Yu等人提出一種自監督多任務學習網絡Self-MM,通過設計基于自監督學習策略的標簽生成模塊,并引入權重自調整策略,較好地實現了對情感的預測分類[15]。雖然研究者不斷探索新的情感識別模型以提升多模態情感識別的準確率,但仍存在一些不足。在情感特征提取方面,上述多模態情感模型主要通過預訓練模型實現對情感特征提取。但預訓練模型往往需要進行微調或遷移學習來達到適應特定任務的目的,可能會導致在小樣本數據集或特定應用中出現泛化性能力不足的問題。在特征融合方面,上述多模態模型雖然采用了一些改進型的融合方法,但在融合過程中沒有很好地考慮模態特征間的相關性及模態的選擇性問題,導致最終的識別準確率偏低。
針對上述問題,本文在現有研究的基礎上提出了一種基于語音、文本和表情的多模態情感識別算法。該算法利用Sfen網絡和Pconv模塊充分提取語音和文本情感特征;采用改進的Inception-ResnetV2網絡[16]提取表情情感特征;通過交叉注意力融合(cross attention fusion,CAF)模塊強化語音和文本特征的相關性;最后,利用BiLSTM-Attention模塊獲取關鍵信息,保持信息在時間上的連續性。
1 多模態情感識別模型
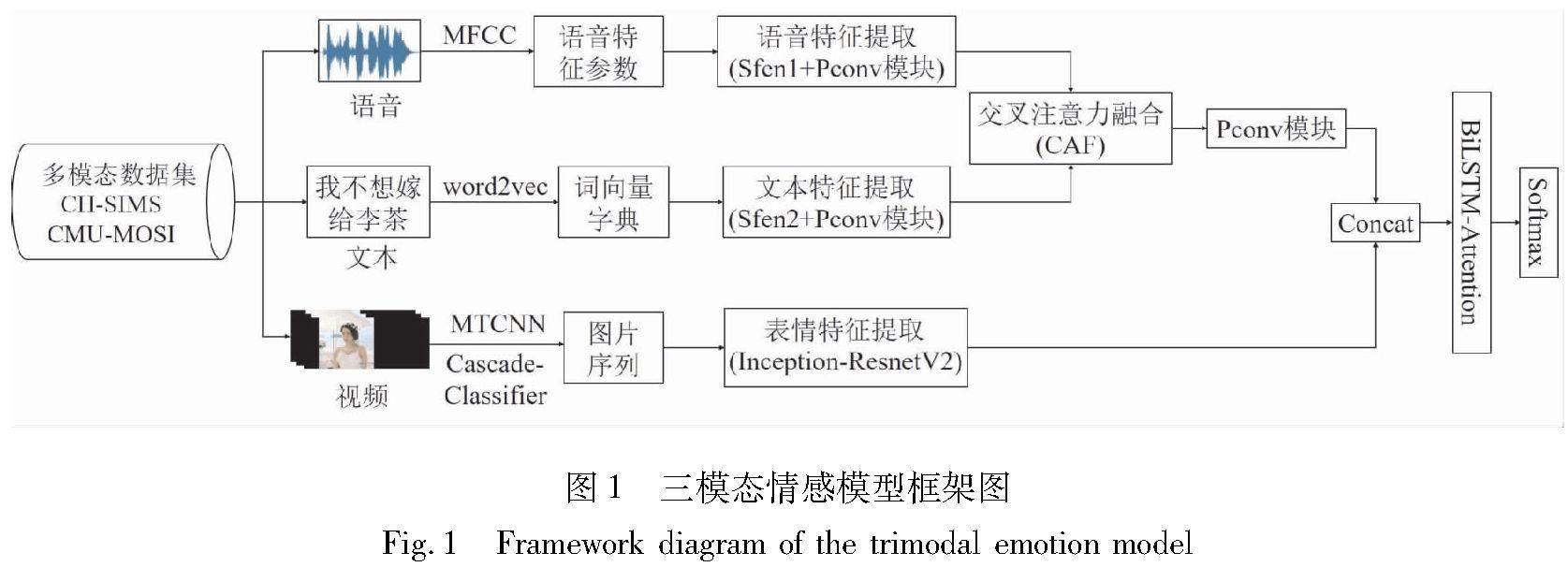
構建多模態情感識別模型通常包括以下幾個方面:多模態信息預處理、情感特征提取、情感識別模型的設計與選擇、特征融合方案[17]。如何確定有效的模態組合方案,并實現有效的特征融合是本文需要研究的重點問題。本文利用語音(A)、文本(T)與表情(V)3種模態構建多模態情感識別模型,該模型主要是由Sfen網絡、Pconv模塊、BiLSTM-Attention模塊和交叉注意力融合(CAF)模塊組成,整體框架如圖1所示。
在圖1所示的模型框架中,首先利用Sfen網絡和Pconv模塊提取語音和文本的情感特征,并通過CAF模塊實現2個模態間的信息互補,優化模態間的信息融合。對于基于視頻的表情信息,該情感識別方法以圖片識別分類常用的Inception-ResnetV2模型為基礎進行改進,以提高在多種環境背景下的魯棒性。在融合策略上,本文將語音-文本特征與表情特征進行特征級[18]融合,并通過BiLSTM-Attention模塊后,利用Softmax實現對情感的識別分類。
1.1 數據預處理
目前語音信號預處理的方法主要有傅里葉變換、 神經網絡、 動態時間規劃和梅爾頻率倒譜系數(MFCC)[19]等, 其中, 梅爾頻率倒譜系數提取到的特征參數更接近人耳感知的特點。 本文利用MFCC對視頻中的原始語音信號進行預處理,通過對提取到的語音數據進行預加重、分幀和加窗等操作,將原始語音信號轉換為語音特征參數。針對原始文本數據,首先,采用文本分類中常用的jieba分詞工具[20]對文本中的分詞進行分類;然后,利用停止詞數據庫去除文本信息中的停止詞,避免無用信息的干擾;最后,通過word2vec[7]模型將文本轉換成詞向量形式,構建詞向量字典。針對研究中使用的文本數據量,使用了word2vec中的CBOW[21]作為本文的神經網絡語言模型。
數據集中原始視頻片段的背景、 光線和環境等因素[22]可能會導致從視頻中提取到的連續幀無法被準確地識別為人臉。 因此, 本文首先將每個視頻片段逐幀處理成連續的圖片, 利用MTCNN[23]模型和OpenCV庫中的CascadeClassifier[24]人臉級聯檢測器實現對人臉的檢測,提高對人臉的檢測精度;然后,將檢測到的人臉圖像裁剪成149×149的統一尺寸大小;最后,經過歸一化、灰度化后,輸出處理后的圖片序列。
1.2 語音文本特征提取
在情感識別的過程中,淺層特征提取主要從輸入的文本、語音或圖像中提取有關情感的表層信息,是數據預處理后的一項關鍵步驟。針對語音和文本模態,本文設計了一種Sfen網絡實現對2種模態淺層特征的提取,Sfen網絡結構如圖2所示。
對于音頻輸入,語音特征參數經過Sfen1網絡中一維卷積層和池化層的處理后得到語音淺層特征(卷積核大小為3×3)。類似地,對于文本輸入,詞向量字典通過Sfen2網絡中的Embedding和BiLSTM層后得到文本淺層特征。其中,Embedding層增強了文本特征之間的相關性,在Embedding層之后引入BiLSTM能夠捕獲更豐富的上下文信息,同時保持文本間的序列關系。語音特征參數和詞向量字典經過各自的Sfen網絡處理后,其輸出特征維度保持相同,確保了后續語音和文本特征融合的可行性。
為獲取深層次的情感特征,本文利用殘差網絡[25](residual network,ResNet)的思想將最大池化層與卷積層進行拼接,針對語音和文本2個模態設計了一種Pconv模塊,其結構如圖3所示。
在圖3中,Pconv模塊由最大池化層、Bconv單元和Sconv單元3部分組成。其中,Bconv單元由3層組成:傳統卷積層、LeakyReLU激活函數、批標準化(Batch Normalization)。Sconv單元與Bconv單元類似,但在輸入環節使用了卷積核大小為3×3的深度可分離卷積層[26](Depth Separable Convolution),進一步減少運算參數的數量,提高運算效率。在次級輸出環節,本文將最大池化層的輸出和Bconv單元的輸出進行拼接,其輸出再與Sconv單元的輸出特征進行疊加。上述設計中的拼接環節可以增加最終輸出特征的多樣性,而疊加環節又可以在輸出前對每個維度的特征進行增強和補充。該Pconv模塊采用的殘差連接的方法,避免了神經網絡中的信息冗余和梯度爆炸[27]問題,使得網絡能夠更有效地學習到數據的特征表示,保證了特征提取的充分性。
1.3 表情特征提取
目前處理視頻序列中面部表情信息的方法主要是3D卷積和2D卷積,其中,3D卷積能夠在時間維度上捕捉連續視頻幀之間的動態信息,2D卷積能夠在每個視頻幀中提取空間特征。本文將3D卷積與2D卷積相結合,先利用2D卷積提取圖像幀的空間特征,再使用3D卷積捕捉時間維度的特征,不僅可以形成更深層次的特征表示,還能夠有效地提高面部表情的識別效率。
Inception-ResnetV2神經網絡模型具有良好的特征提取能力和泛化性能,常用于圖像分類、目標檢測等任務。本研究采用的表情情感識別模型是在Inception-ResnetV2模型的基礎上進行的改進,利用3D卷積與2D卷積相結合的多尺度卷積核[28]處理表情數據信息。改進后的模型結構如圖4所示。在傳統的Inception-ResnetV2模型的基礎上,將其前半部分的特征提取層由2D轉換為3D,利用三維卷積核滑動提取相應特征。由于時間維度較小,當時間維度卷積為1時,再次通過壓縮方式(squeeze)將3D卷積轉換為2D卷積,減少訓練參數的產生,降低運算難度。
1.4 交叉注意力融合模塊
模態特征的融合需要考慮不同模態間的耦合關系。目前的研究表明T(文本)和A(語言)2種模態之間存在緊密的時序與特征耦合關系[29]。本文改變了傳統的特征融合方式,設計了一種基于交叉注意力的融合模塊,在保留模態內特征的同時,有效地編碼T和A模態間的信息。該融合模塊結構如圖5所示。
在圖5所示的交叉注意力融合模塊中, Xt和Xa分別代表數據集中的視頻序列X經過Pconv模塊后提取出的T和A的深層特征。 為使模態間的異質性最小化, 設置了一個可學習的權重矩陣W∈Rk×k,相互計算的關系如式(1)所示,
Y=XTa WXt(1)
式中:Y∈Rl×l;W代表文本和語音的相互關系權重;k代表文本和語音的特征維度。相關矩陣Y給出了T和A特征之間的相關性度量,較高的相關系數說明子序列對應的T和A特征之間具有較強的相關性。基于以上思路,分別利用YT和Y的softmax函數進一步計算T和A特征的交叉注意力權重Zt和Za。計算如式(2)和(3)所示。
式中:i和j表示矩陣Y的第i行和第j列元素;Ts表示softmax系數。
式中:Zt和Za分別代表T和A特征的交叉注意力權重。通過將重加權的注意力圖添加到相應的特征上,可獲得2種模態的深層特征表征Xatt,t與Xatt,a,如式(6)和(7)所示。
Xatt,t=tanh(Xt+t)(6)
Xatt,a=tanh(Xa+a)(7)
將Xatt,t和Xatt,a拼接起來,得到T和A的特征表示,即[AKX]=[Xatt,t,Xatt,a]。經過交叉注意力模塊融合后的特征將再次輸入到下一級Pconv模塊中,通過其并行結構充分提取融合后的信息。
1.5 BiLSTM-Attention模塊
長短時記憶網絡[30](long short term memory,LSTM)利用3個不同門結構,有效解決了序列數據的依賴性和語序問題,其結構如圖6所示。
在t時刻,將當前隱層狀態記為ht,各門狀態更新如下:
ft=σ(Wf·[ht-1,xt]+bf)(8)
Ct=ft*Ct-1+it*tanh(Wc·[ht-1,xt]+bc)(9)
it=σ(Wi·[ht-1,xt]+bi)(10)
ot=σ(Wo·[ht-1,xt]+bo)(11)
ht=ot*tanh(Ct)(12)
式中:xt表示當前輸入單元狀態;ft、Ct、it、ot分別表示當前遺忘門、存儲單元、輸入門、輸出門;b*表示偏置項;W*表示權重矩陣;σ是激活函數。
LSTM只能獲取輸出時刻前的信息, 不能利用反向信息, 本文利用了2個單向LSTM構成雙向長短時記憶網絡(BiLSTM), 同時處理前向與后向信息。 此外, 注意力機制[31](attention)能夠在訓練過程中根據特征序列信息的重要程度賦予權重值, 選擇性忽略非重要信息,最大化相關向量的貢獻。 為使模型更好獲取輸入序列中不同位置的重要性, 在BiLSTM層的基礎上添加注意力層提高網絡對關鍵信息的感知和利用能力。BiLSTM-Attention模塊結構如圖7所示。
2 多模態情感識別實驗
2.1 數據集
實驗數據集選用公開的多模態情感數據集CH-SIMS[32]和CMU-MOSI[33]。CH-SIMS數據集取材自60部電影、電視劇與綜藝節目,包括2 281個視頻片段。每個視頻片段中的情感狀態由5個人給予標注,以平均標注結果作為該片段的情緒狀態。CMU-MOSI數據集包含YouTube上收集的90個視頻,并將其人工劃分為2 199個視頻片段。其中,CH-SIMS數據集的情緒狀態分為消極、中性和積極3種(對應標簽0、1、2),CMU-MOSI數據集的情緒狀態分為消極和積極2種(對應標簽0、1)。同時,將數據集劃分訓練集、驗證集和測試集。數據集信息如表1所示。
2.2 參數設置與評估指標
實驗基于TensorFlow深度學習框架進行模型搭建,在NF5468型24*GPU服務器上進行模型訓練。訓練中采用SGD作為網絡優化函數,LeakRelu作為激活函數。訓練時的Batch size設置為32,Epoch=1 000,學習率為1e-4,LSTM層的隱藏層單元數量為128。為防止網絡在訓練中出現過擬合現象,在BiLSTM-Attention層后使用P=0.5的Dropout作為補償。
本文采用了準確率(Accuracy,式中簡記RAcc)和F1值(F1-score,式中簡記F1)作為模型整體性能的評估指標。具體計算如式(13)和(14)所示。
式中:NTP表示實際與預測均為正的樣本數;NFP表示實際為負但預測為正的樣本數;NTN表示實際與預測均為負的樣本數;NFN表示實際為正但預測為負的樣本數。
2.3 組合方案討論
為驗證提出的多模態情感框架中采用的模態組合方式的有效性,本文共討論了4種(AT-V、AV-T、TV-A、A-T-V)模態組合方案,如圖8所示。
為保證實驗的可靠度,4組實驗均在CH-SIMS和CMU-MOSI數據集上進行驗證且訓練超參數保持一致,實驗結果如表2所示。其中,Acc-2和Acc-3分別表示二分類和三分類的準確率。通過表2可以看出,方案1中的模態組合AT-V在2類數據集上都取得比另外3種方案更好的識別效果。其中,方案1在CH-SIMS上的Acc-3、F1分別達到了96.94%、96.67%;在CMU-MOSI上分別達到97.73%和97.52%。表明本文采用的語音和文本先進行特征融合是最優的三模態組合方式。
2.4 消融實驗
2.4.1 融合方式消融實驗
在確定2.3節中方案1為最優的三模態組合(AT-V)后,為驗證本文提出的交叉注意力融合模塊(CAF)的優勢,進一步將方案1中的語音和文本特征融合的方式由Concat分別替換為Self-Attention[34]和CAF并進行消融實驗。其中,Concat表示不添加注意力的簡單特征拼接,Self-Attention表示自注意力融合方式,其強調相關特征的組成部分。實驗結果如表3所示。
通過表3可以看出,在引入了交叉注意力后,該模型在2類數據集上的評估指標均得到了顯著的提升。在CH-SIMS數據集上,Acc-3和F1值分別達到97.82%和97.33%;在CMU-MOSI數據集上,Acc-2和F1值分別達到98.18%和97.87%。相對于簡單的特征拼接(Concat)的融合方式,自注意力(Self-Attention)融合方法雖在一定程度提高了系統的性能,凸顯了相關的特征組成部分,但是其計算方式較為復雜,增加了模型的復雜性。相對于自注意力融合,由于交叉注意力融合(CAF)機制通過利用A-T特征之間的相互關聯性,且計算方式更為簡便,有效地捕獲了2種模態的互補性,進一步提高了模型性能。以上結果符合本文的預期設想,證明了提出的交叉注意力能夠更好地利用語音和文本間的特征互補關系,進一步提高特征融合的效果。
2.4.2 BiLSTM-Attention模塊消融實驗
為驗證本文利用的BiLSTM-Attention模塊的作用,做了3組對比實驗。①FC:語音、文本與表情3種模態進行特征融合后輸入到全連接層輸出;②LSTM:在特征融合后通過LSTM網絡輸出;③BiLSTM:特征融合后通過雙向LSTM輸出。實驗結果如表4所示。
從表4可以看出,在以上4種模型對比實驗結果中,本文的BiLSTM-Attention模塊在Acc和F1值上均取得了最優。在CH-SIMS數據集上較其他3種模型至少高出了0.004 5和0.001 5;在CMU-MOSI數據集上至少高出了0.004 5和0.002 2。通過以上不同模型的對比實驗結果可知,本文采用的BiLSTM與Attention相結合的方法有助于更好地實現對多模態情感的分析和預測,進一步表明了該網絡模塊對多模態情感模型的重要性。
2.4.3 模態消融實驗
為驗證本文提出的網絡模型的適用性,在CH-SIMS數據集分別進行了單模態、雙模態及三模態7種組合的消融實驗。具體的消融實驗結果如表5所示。
通過表5可以觀察到三模態的Acc-3和F1指標均優于單模態和雙模態,效果最好。在單模態情感識別實驗中,表情模態信息預測真實情感能力最強,Acc-3達到87.81%,F1達到87.26%。在雙模態情感識別實驗中,A+V組合效果最好,Acc-3、F1分別達到95.20%、94.64%,T+V和T+A次之。心理學家Mehrabian的研究發現,人們在日常生活中的情感信息主要是通過表情與語言傳達的[35],這也與消融實驗中A+V模態組合的實驗結果相符。以上的消融實驗不僅驗證了利用語音、文本和表情進行多模態情感識別的必要性,也證明了本文提出的引入CAF思想的多模態情感融合方法的可行性和有效性。
2.5 對比實驗
本節將提出的多模態模型與目前多種經典的情感模型進行對比,基線模型介紹如下。
EF-LSTM[10]:早期融合的LSTM模型。首先拼接3種模態的特征向量,然后利用LSTM對拼接后的特征進行編碼。
LF-LSTM[10]:晚期融合的LSTM模型。首先LSTM編碼3個模態特征向量,然后結合LSTM最后一層的隱層向量構成多模態的特征表示。
MAG-BERT[36]:多模態自適應門模型。通過提出一種多模態自適應門機制(MAG),使BERT和XLNet能夠在微調過程中接受多模態數據的輸入。
MuIT[14]:多模態Transformer模型。通過考慮不同模態之間的時序依賴關系,實現在非對齊數據集上的跨模態交互。
MMIM[37]:多模態分層互信息最大化框架。在多模態分析任務中引入互信息理論,最大化輸入級和融合級特征表征的互信息。
MISA[38]:模態不變和模態特定表征框架。針對不同模態學習模態不變和模態特定的特征表示,對不同種類的表示向量提出分布相似性損失、重建損失、正交損失及任務預測損失。
Self-MM[15]:自監督多任務學習網絡。通過一種基于自監督策略的標簽生成模塊獲取單模態表征,并在訓練階段設計一種平衡不同任務損失的權重調整策略。
CMFIB[39]:跨模態融合與信息瓶頸模型。利用互信息估計模塊優化多模態表示向量與真實標簽之間的互信息下限,最小化輸入數據與多模態表示向量間的互信息。
經過多次對比實驗,在2類數據集上和其他基線模型的評估指標對比結果如表6所示。
由表6可知,本文提出的模型在Acc和F1值2類評估指標上要優于對比的基線模型,尤其在CMU-MOSI數據集上表現更好,Acc-2和F1指標比最優基線模型分別提升了0.116 2和0.113 7;在CH-SIMS數據集上,Acc-3和F1值比最優基線模型分別提升了0.175 4和0.170 6。該結果表明,本文設計的特征提取網絡以及交叉注意力機制等組件能夠有效地挖掘模態間的特征關系,增強模態間的相互依賴性。這對于多模態數據的融合和各項評估指標的提升產生了顯著效果。
在上述基線模型中,EF-LSTM和LF-LSTM效果表現最差。這是因為2種模型直接拼接3種特征,保留了大量噪聲,無法篩選出重要信息。本文的注意力機制能夠對關鍵信息進行加權處理,增強其顯著性,進而提升模型的性能。與MuIT和MAG-BERT相比,本文的模型的Acc指標在CH-SIMS上至少提升了約21個百分點,在CMU-MOSI上至少提升了約14個百分點。MuIT在計算模態間的依賴關系時,未考慮上下文信息,且網絡結構較為復雜。MAG-BERT雖較MuIT有一定的提升,但在預訓練或微調過程中需要大量的多模態數據,可能會導致模型計算困難。本文模型在情感計算時通過利用多尺度卷積核和BiLSTM網絡,降低了計算量并保持了上下文時序相關性,提高了計算效率。
與MMIM和MISA相比,本文模型采用的交叉注意力融合機制更加適用于多模態識別任務,在有效利用不同模態互補特性的同時增強了模態間的相關性。與Self-MM和CMFIB相比,所提出的方法在2類數據集的評估指標上表現出色,取得了較好的效果。Self-MM在任務間特征共享方面容易過擬合某些任務,可能導致其性能的下降。CMFIB在情感分析時只能捕捉到變量之間的關聯性,難以充分捕捉模態的深層情感特征。本文設計的Pconv模塊利用并行架構和特定網絡層降低了過擬合的風險,并有效提取了深層次的特征。
3 結語
針對當前多模態情感模型存在識別精度低等問題,本文提出了一種基于語音、文本和表情的多模態情感識別算法。該模型由Sfen網絡、Pconv模塊和改進的Inception-ResnetV2網絡提取多模態特征,利用交叉注意力融合機制強化語音-文本雙模態的關聯性,并通過BiLSTM-Attention模塊實現對情感的預測和分類。在CH-SIMS和CMU-MOSI數據集上的實驗表明,該模型可以更好地提取模態特征并進行特征融合,顯著提高情感識別的精度。接下來本研究將進一步細化情感類別,并探討在細粒度識別任務下的多模態融合算法的架構設計。
參考文獻
[1] 李霞, 盧官明, 閆靜杰, 等. 多模態維度情感預測綜述[J]. 自動化學報, 2018, 44(12): 2142-2159.
LI X, LU G M, YAN J J, et al. A review of multimodal dime-nsional sentiment prediction[J]. Journal of Auctomatica Sinica, 2018, 44(12): 2142-2159.
[2] RISH I. An empirical study of the naive Bayes classifier [J].Journal of Universal Computer Science, 2001, 1(2):127.
[3] 趙健, 周莉蕓, 武孟青, 等. 基于人工智能的抑郁癥輔助診斷方法[J].西北大學學報(自然科學版), 2023, 53(3): 325-335.
ZHAO J, ZHOU L Y, WU M Q, et al. Assistant diagnosis method of depression based on artificial intelligence [J]. Journal of Northwest University (Natural Science Edition), 2023, 53(3): 325-335.
[4] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[5] ELMAN J L. Finding structure in time[J]. Cognitive Science, 1990, 14(2): 179-211.
[6] MAJUMDER N, HAZARIKA D, GELBUKH A, et al. Multimodal sentiment analysis using hierarchical fusion with context modeling[J]. Knowledge-Based Systems, 2018, 161: 124-133.
[7] XU D L, TIAN Z H, LAI R F, et al. Deep learning based emotion analysis of microblog texts[J]. Information Fusion, 2020, 64: 1-11.
[8] 鄭劍, 鄭熾, 劉豪, 等. 融合局部特征與兩階段注意力權重學習的面部表情識別[J]. 計算機應用研究, 2022, 39(3): 889-894.
ZHENG J, ZHENG C, LIU H, et al. Deep convolutional neural network fusing local feature and two-stage attention weight learning for facial expression recognition[J]. Application Research of Computers, 2022, 39(3): 889-894.
[9] DUTTA K, SARMA K K. Multiple feature extraction for RNN-based Assamese speech recognition for speech to text conversion application[C]∥2012 International Conference on Communications, Devices and Intelligent Systems. Kolkata: IEEE, 2012: 600-603.
[10]HOU M, TANG J J, ZHANG J H, et al. Deep multimodal multilinear fusion with high-order polynomial pooling[C]∥Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver: Curran Associates Inc.,2019:12156-12166.
[11]ZADEH A, CHEN M, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis[C]∥Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: Association for Computational Linguistics, 2017: 1103-1114.
[12]LIU Z, SHEN Y, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors[C]∥Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne: Association for Computational Linguistics, 2018: 2247-2256.
[13]ZADEH A, LIANG P P, MAZUMDER N, et al. Memory fusion network for multi-view sequential learning[J].Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1): 5634-5641.
[14]TSAI Y H H, BAI S J, LIANG P P, et al. Multimodal transformer for unaligned multimodal language sequences[J].Proceedings of the? Conference? Association for Computational Linguistics Meeting, 2019, 2019: 6558-6569.
[15]YU W M, XU H, YUAN Z Q, et al. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis[J].Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(12): 10790-10797.
[16]ZHAO J, ZHANG M, HE C, et al. A novel facial attractiveness evaluation system based on face shape, facial structure features and skin[J]. Cognitive Neurodynamics, 2020, 14(5): 643-656.
[17]賈寧, 鄭純軍. 融合音頻、文本、表情動作的多模態情感識別[J]. 應用科學學報, 2023, 41(1): 55-70.
JIA N, ZHENG C J. Multimodal emotion recognition by fusing audio, text, and expression-action[J]. Journal of Applied Sciences, 2023, 41(1): 55-70.
[18]WANG Y Y, GU Y, YIN Y F, et al. Multimodal transformer augmented fusion for speech emotion recognition[J]. Frontiers in Neurorobotics, 2023, 17: 1181598.
[19]焦亞萌, 周成智, 李文萍, 等. 融合多頭注意力的VGGNet語音情感識別研究[J]. 國外電子測量技術, 2022, 41(1): 63-69.
JIAO Y M, ZHOU C Z, LI W P, et al. Research on speech emotion recognition with VGGNet incorporating multi-headed attention [J]. Foreign Electronic Measurement Technology, 2022, 41(1): 63-69.
[20]ZHANG Y M, SUN M H, REN Y, et al. Sentiment analysis of sina weibo users under the impact of super typhoon lekima using natural language processing tools: A multi-tags case study[J]. Procedia Computer Science, 2020, 174: 478-490.
[21]劉亞姝, 侯躍然, 嚴寒冰. 基于異質信息網絡的惡意代碼檢測[J]. 北京航空航天大學學報, 2022, 48(2): 258-265.
LIU Y S, HOU Y R, YAN H B. Malicious code detection based on heterogeneous information networks[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(2): 258-265.
[22]邱世振, 白靖文, 張晉行, 等. 基于六軸機械臂驅動的微波球面掃描成像系統[J]. 電子測量與儀器學報, 2023, 37(4): 98-106.
QIU S Z, BAI J W, ZHANG J X, et al. Microwave spherical scanning imaging system driven by six-axis manipulator [J]. Journal of Electronic Measurement and Instrumentation, 2023, 37(4): 98-106.
[23]KU H C, DONG W. Face recognition based on MTCNN and convolutional neural network[J]. Frontiers in Signal Processing, 2020, 4(1): 37-42.
[24]付而康, 周佳玟, 姚智, 等. 基于機器視覺識別的戶外環境情緒感受測度研究[J]. 景觀設計學(中英文), 2021, 9(5): 46-59.
FU E K, ZHOU J C, YAO Z, et al. A study on the measurement of emotional feelings in outdoor environments based on machine vision recognition[J]. Landscape Architecture Frontiers, 2021, 9(5): 46-59.
[25]ZHANG K, SUN M, HAN T X, et al. Residual networks of residual networks: Multilevel residual networks[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 28(6): 1303-1314.
[26]DING W, HUANG Z Y, HUANG Z K, et al. Designing efficient accelerator of depthwise separable convolutional neural network on FPGA[J]. Journal of Systems Architecture, 2019, 97(C): 278-286.
[27]梁宏濤, 劉碩, 杜軍威, 等. 深度學習應用于時序預測研究綜述[J]. 計算機科學與探索, 2023, 17(6): 1285-1300.
LIANG H T, LIU S, DU J W, et al. Research review on application of deep learning to time series prediction [J].Journal of Frontiers of Computer Science and Technology, 2023, 17(6): 1285-1300.
[28]焦義, 徐華興, 毛曉波, 等. 融合多尺度特征的腦電情感識別研究[J]. 計算機工程, 2023, 49(5): 81-89.
JIAO Y, XU H X, MAO X B, et al. Research on EEG emotion recognition by fusing multi-scale features[J]. Computer Engineering, 2023, 49(5): 81-89.
[29]XU Y R, SU H, MA G J, et al. A novel dual-modal emotion recognition algorithm with fusing hybrid features of audio signal and speech context[J]. Complex & Intelligent Systems, 2023, 9(1): 951-963.
[30]王蘭馨, 王衛亞, 程鑫. 結合Bi-LSTM-CNN的語音文本雙模態情感識別模型[J]. 計算機工程與應用, 2022, 58(4): 192-197.
WANG L X, WANG W Y, CHENG X. Combined Bi-LSTM-CNN for speech-text bimodal emotion recognition model[J]. Computer Engineering and Applications, 2022, 58(4): 192-197.
[31]祁宣豪, 智敏. 圖像處理中注意力機制綜述[J].計算機科學與探索,2024,18(2):345-362.
QI X H, ZHI M. A review of attention mechanisms in image processing [J].Journal of Frontiers of Computer Science and Technology, 2024,18(2):345-362.
[32]YU W M, XU H, MENG F P, et al. CH-SIMS: A Chinese multimodal sentiment analysis dataset with fine-grained annotation of modality[C]∥Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: Association for Computational Linguistics, 2020: 3718-3727.
[33]ZADEH A, ZELLERS R, PINCUS E, et al. MOSI: Multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos[EB/OL].(2016-08-12)[2023-09-25].http:∥arxiv.org/abs/1606.06259.
[34]ZHANG X C, QIU X P, PANG J M, et al. Dual-axial self-attention network for text classification[J]. Science China Information Sciences, 2021, 64(12): 80-90.
[35]WANG Y, SONG W, TAO W, et al. A systematic review on affective computing: Emotion models, databases, and recent advances[J]. Information Fusion, 2022, 83/84: 19-52.
[36]RAHMAN W, HASAN M K, LEE S W, et al. Integrating multimodal information in large pretrained transformers[J].Proceedings of the Conference Association for Computational Linguistics? Meeting,? 2020, 2020: 2359-2369.
[37]HAN W, CHEN H, PORIA S. Improving multimodal fusion with hierarchical mutual information maximization for multimodal sentiment analysis[EB/OL].(2021-09-16)[2023-09-25].http:∥arxiv.org/abs/2109.00412.
[38]HAZARIKA D, ZIMMERMANN R, PORIA S. MISA: Modality-invariant and-specific representations for multimodal sentiment analysis[C]∥Proceedings of the 28th ACM International Conference on Multimedia. Seattle: ACM, 2020: 1122-1131.
[39]程子晨, 李彥, 葛江煒, 等. 利用信息瓶頸的多模態情感分析[J]. 計算機工程與應用, 2024, 60(2):137-146.
CHENG Z C, LI Y, GE J W, et al. Multi-modal sentiment analysis using information bottleneck [J].Computer Engineering and Applications, 2024, 60(2):137-146.
