基于多重特征提取的DNN竊電檢測方法
2024-05-07 09:40:34趙艷龍汪卓俊楊勇勝章建華劉一民
電氣技術與經濟 2024年4期
趙艷龍 汪卓俊 楊勇勝 章建華 蔣 鐘 劉一民
(1.國網浙江省電力有限公司安吉縣供電公司 2.國網浙江省電力有限公司湖州供電公司)
0 引言
電網的損失主要分為技術損失和非技術損失[1]。電阻損耗、變壓器損耗和老化損耗等是造成技術損失的原因,該損失難以解決[2];而竊電則是造成電網非技術損失的主要原因。隨著用戶的竊電方式從早期修改電表結構、私自連接電線到篡改智能電表數據[3]。竊電手段越來越智能化和多樣化,檢測竊電用戶的難度也越來越大[4]。
2017年美國因為竊電造成的損失已達100億美元[5]。中國國家電網也在過去追回了近130億元的竊電資金。隨著AMⅠ的應用與普及,用電信息數據呈爆炸式增長[6]。通過挖掘、分析和有效利用這些海量數據來檢測竊電是當前研究的熱點[7,8],同時對保證電網的供電質量和效率具有重要意義[9]。
闕華坤等人搭建了基于隨機森林的竊電檢測模型,并以南方電網數據作為輸入,驗證了模型的檢測效果,但是沒有用合理的指標加以說明模型的性能[10]。黃剛等人提出了一種基于多層次非負稀疏編碼的竊電檢測方法,用愛爾蘭數據集驗證了其準確率[11]。但該方法的竊電用戶需要以月度單位的連續數據作為證據才能識別,當電表故障時存在用電量記錄缺失,該情況會使得竊電檢測效率降低。
為了實現在線竊電檢測,本文提出了基于多重特征提取的DNN竊電行為檢測方法。首先,采用主成分分析法(PCA)對經過預處理和不平衡處理的數據進行特征初步提取,得到初始的基本特征量。然后,將用戶的用電曲線分離為背景曲線和過濾曲線,分別對兩條曲線進行特征值再提取。最后,利用深度學習網絡(DNN)構建竊電檢測模型,實現對竊電用戶的檢測。
1 模型結構與主要單元
1.1 數據集介紹
本文采用國家電網發布的數據集(SGCC)進行實驗[12]。該數據集包含了2014年1月1日至2016年10月31日的42372個客戶每日的用電量記錄如表1所示。

表1 國家電網數據集
該數據集一共有近420萬條數據,足夠用以搭建與驗證模型。但是,該數據集存在兩種問題。首先,數據集中存在大量的缺失值。其次,正常用戶和竊電用戶的比例為10.72,這種數據分布會導致竊電模型的分析出現數據不平衡問題。
數據不平衡會導致模型更傾向于更多地學習多數類的特征,導致錯誤將少數類樣本預測為多數類,從而產生較高的假陰性率。通常當多數樣本大于少數樣本的10倍時會導致模型在竊電檢測方面的準確率下降,因為它更容易將真正的竊電行為樣本錯誤地分類為非竊電行為。
1.2 數據集介紹
針對不同用戶的數據缺失情況擬定不同的處理辦法。當某位用戶的用電數據缺失數量過多時,無論采用何種插值法去補充缺失部分,都會使得數據的不穩定性和偏差性影響竊電檢測模型的效果。因此在處理缺失值的過程中,設定一個30%的閾值,當缺失值占比超過該用戶的30%時,將此樣本舍棄。在對所有樣本進行篩選后,剩余數據的分布如表2所示。

表2 缺失值過濾后的數據集
在時間序列的用電量數據中,采用線性插值法來填充缺失值占比少于30%的用戶樣本,其公式如下:
式中,x0、y0和x1和y1是距離缺失值最近的數據點。經過線性插值法處理前后的某用戶日功率曲線如圖1(а)和圖1(b)所示。
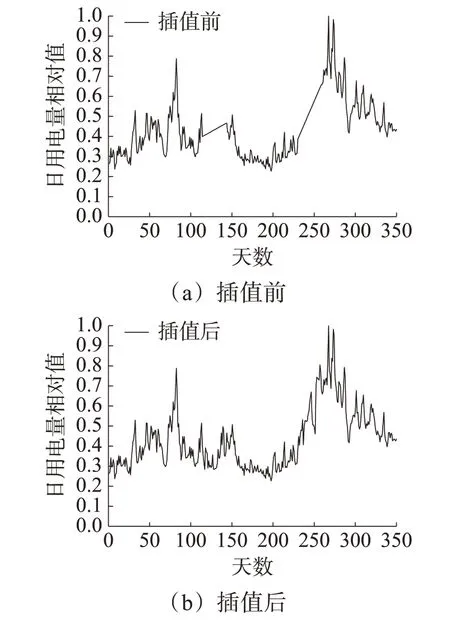
圖1 某用戶功率曲線圖
1.3 數據不平衡問題
文獻[13]介紹了六種用于合成竊電樣本數據的函數,分別是式(2)-式(7)。我們采用這些函數結合SGCC正常用戶數據來生成竊電用戶數據,目的是為了平衡數據集并創建更實用和真實的異常用電消費模式。
具體而言,y1函數將每日實際用電量乘以0.1到0.9之間的隨機數值,這個處理效果類似于電磁干擾竊電導致的情況。y2函數則將一段時間的實際用電量乘以0.1到0.9之間的隨機數,反映用戶采取欠壓竊電和欠流竊電所導致的結果。y3函數代表了用戶不連續的竊電行為。而后三種函數則模擬了針對于數據漏洞的竊電行為。在y4和y5函數中,竊電者在電表數據傳輸過程中結合平均用電量,在不易察覺的情況下修改上報讀數。而y6函數則通過相反的順序發送用電讀數,目的是保證高電量消耗發生在低價時間段。以某用戶一周用電曲線來展示不同函數合成的數據效果,如圖2所示。
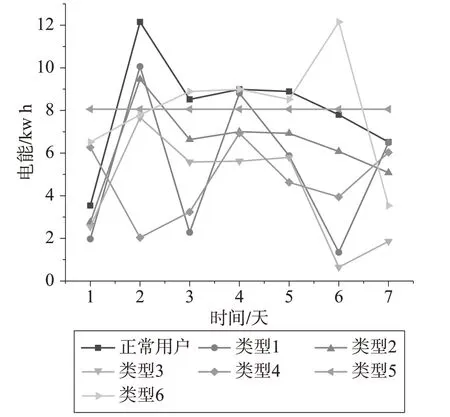
圖2 合成效果對比
我們在SGCC缺失值處理后的25932名正常用戶中,隨機抽取了6000名用戶,并將其分為六組。每組分別采用上述函數來合成竊電樣本。在最終用于后續模型訓練的數據中,正常樣本數為19932,竊電樣本數為8063,比例為2.472比1,這有效解決了數據不平衡的問題。
由于DNN模型的精度極易受到稀疏和未縮放數據的影響,因此采用min-mаx數據縮放方法將所有用戶的用電量歸至0與1之間,如下式所示:
其中mаx(x)和min(x)代表該用電用戶自身1034天的用電量最小值和最大值。
2 竊電檢測模型
2.1 模型介紹
本文提出的基于多重特征提取的DNN竊電檢測模型如圖3所示,該模型通過三階段提取特征值將原本包含1034天用電數據的一位用戶樣本減小至僅有20個特征值,在保留用戶信息的同時極大地減小了后續工作的計算量。然后使用深度神經網絡(DNN)作為竊電檢測模型的核心,并通過不斷優化模型參數,提高模型的準確性和性能。

圖3 竊電檢測模型架構
2.2 特征提取
利用PCA對用戶每日用電量進行初步特征提取。PCA將多個變量指標類型轉化為少數幾個主成分,這些主成分能夠代表原始數據的信息。
在利用PCA提取用戶進行數據處理之后的用電量X′=[x′1,x′2,x′3,…,x′1034]時,將每天的用電量視為其用電特征。以某一用戶A為例,其歸一化日用電曲線如圖4所示。

圖4 用戶A每日用電曲線
其中,第一主成分由下式計算而來:
同樣,第二主成分被給出為:
以此類推,本文選擇PCA計算所得的前10個主成分p=[p1,p2,…,p10]作為特征值,從而在保存保存大量數據集信息的條件下,將特征維度減小至10。用戶A的PCA主特征值如圖5所示。

圖5 用戶A主成分值
接下來,利用背景值提取方法,將用戶的日用電曲線分離為背景曲線和過濾曲線。背景值的判斷標準如式8所示。
式中,xα是用戶1034d日用電量的非零眾數,在眾數不存在的情況下用平均數作為替代。
背景曲線代表用戶通常情況下的用電情況,它能夠在一定程度上反映用戶的經濟水平等信息。過濾曲線表明用戶在某些特殊情況下的用電,比如節假日、家庭聚會。用戶A的過濾曲線和背景曲線如圖6所示。

圖6 用戶A過濾曲線與背景曲線
對背景曲線和過濾曲線分別提取共10個特征值,從而補充PCA主成分分析所包含的信息。背景曲線和過濾曲線所提取的特征值如表3所示。

背景曲線4 5 1 2 3 4 5偏斜度標準差平均值非零值最長持續時間連續度月平均值增長率高峰季持續時間

表3 輔助特征值
2.2 基于DNN竊電檢測模型建立
DNN是深層人工神經網絡(ANN)的產物。能夠學習比淺層人工神經網絡更復雜和抽象的特征,其主要架構如圖7所示[14]。

圖7 DNN網絡架構
其中,輸入層x由輸入數據的特征值組成,wi是連接輸入層和隱藏層的權重。隱藏層位于輸出層和輸入層之間,用于分析輸入和輸出信號之間的關系,則為隱藏層之間相互連接的權重。輸出層作為DNN網絡的最后一層給出了網絡的輸出,wo是連接隱藏層和輸出層之間的權重。
為了更快地更新參數并使其收斂,我們采用隨機梯度下降法對DNN中各層的權重進行優化。該方法每次使用一個樣本或者一小批樣本來計算并更新權重,因此其更適用于大規模數據集。
在訓練過程中,使用二分類交叉熵損失函數比較數據真實分布和模型預測分布,其值越小,則表明模型預測的準確率越高。其中,交叉熵的定義如式12所示。
式中,p(x)i是隨機變量xi分類正確的真實概率,q(x)i是模型預測xi的分類正確概率。
3 結果分析
3.1 評價指標
為了更好評估基于特征提取的DNN竊電檢測模型,本文采用準確率(ACC)、誤報率(FDR)、假陽率(FPR)和F1度量(F1-scorе)作為指標。在評估之前將所有用戶根據實際歸屬和檢測模型的結果劃分為四類:真陽性(TP)、真陰性(TN)、假陽性(FP)、假陰性(FN),如表4所示。

表4 異常用電模型評估分類
根據上述劃分,四類指標的意義和計算方法如下所示:
(а)ACC:正確分類的樣本占總樣本的比例,能夠反映整個檢測器的準確性。
(b)FDR:異常用電用戶被判定為正常用戶占所有被判定為正常用戶的比例。
(c)FPR:異常用電用戶被判斷為正常用電用戶占所有異常用戶的比例。
(d)F1-scorе:取值范圍為0-1用于衡量綜合衡量分類器性能,綜合了分類器的精確率和召回率。
其中精確率precison=TP/(TP+FP),召回率Recall=TP/(TP+FN)。
3.2 多重特征值提取的特征選擇算法效果評價
為了驗證基于多重特征值提取的特征選擇算法的性能和效果,選取兩個數據集進行實驗。數據組1是在數據平衡前,竊電用戶數為2063;數據組2是在數據平衡后,竊電用戶數為8063。為了控制其他因素,統一采用3層的CNN進行竊電檢測模型的訓練。圖7展示了PCA、時頻域、隨機森林特征選擇以及多重特征提取等4種特征提取方法的實驗分析結果。
如圖8所示,基于多重特征提取的方法在數據組1上的準確率分別比PCA、時頻域和隨機森林高出4.2%、11.8%和7.9%。在數據組2上,本文所提出的算法相比于PCA、時頻域和隨機森林分別提升了5.1%、13.3%和7.1%。

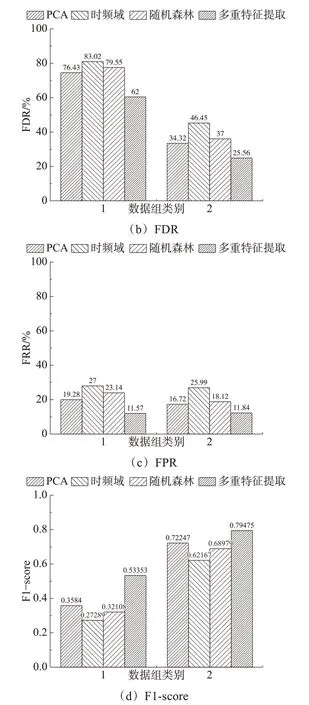
圖8 不同特征提取方法效果比較
通過分析FDR和FPR這兩個指標,發現其在兩組數據上基于多重特征提取的方法較其他三種算法表現顯著優越。這說明本文提出的方法能夠更好地適應不同模式下的竊電檢測。
對于模型在不同數據組下的F1-scorе得分進行橫向比較,我們可以發現采用本文提出的方法來解決數據不平衡問題可以明顯提升竊電檢測模型的性能。值得注意的是,基于多重特征提取的方法訓練的簡單竊電檢測在數據組2的F1-scorе得分可達0.7975,這表明利用本文提出的算法來提取特征可以提高正常用戶被正確預測的比例,有效防止誤判。
3.3 基于多重特征提取的DNN檢測效果評價
將經過數據處理后的數據集分別放入常用的竊電檢測分類模型中,如隨機森林、SVM(支持向量機)和ELM(極限學習機)中。為了驗證本文提出的模型對竊電問題的分類效果,DNN選用8層網絡的架構,測試結果如表5所示。
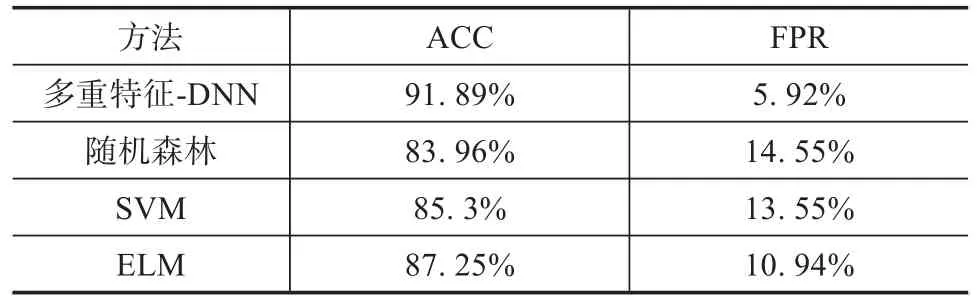
表5 檢測方法效果比較
由表5可以看出,基于多重特征的DNN檢測方法優于隨機森林、SVM和ELM,ACC分別高7.93%、68.6%和4.64%;FPR分別低8.63%、7.63%和5.02%。雖然ELM方法的ACC可以達到87.25%,但是其FPR達到了10.94%。這意味著要消除被錯誤分類為竊電的正常用戶所需的人力資源相當大。綜合考慮以上指標,可以明確本文提出的方法優于其他三種方法。
4 結束語
本文針對竊電檢測問題提出了一種多重特征提取的新的檢測方法,并結合DNN技術訓練了竊電檢測模型。通過在рytorch上對國家電網數據集進行實驗,并與其他竊電檢測器進行對比分析,結果表明本文所提出的方法在精確度和性能方面具有更好的表現。雖然該方法能夠充分利用大數據的優勢,但是研究所用數據的獲取來源相對較為單一。為了進一步完善該方法,未來的工作將考慮對電力系統網絡參數進行分析,以實現對竊電行為的高效且精準檢測,同時在多維度、多方位和多因素上進行研究。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
電子制作(2019年15期)2019-08-27 01:12:00
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
