基于ZYNQ的實時視頻邊緣檢測系統(tǒng)設計
2024-05-29 11:42:14蘇恒關燁鋒和河向
電子產(chǎn)品世界 2024年2期
蘇恒 關燁鋒 和河向


關鍵詞:ZYNQ 芯片;實時視頻;邊緣檢測;現(xiàn)場可編程邏輯門陣列
中圖分類號:TP23;TP391.41 文獻標識碼:A
0 引言
人類視覺基礎是圖像信息,隨著嵌入式及集成電路技術的飛速發(fā)展,視覺圖像處理在日常生活與科研領域均得到廣泛應用,圖像處理技術的快速發(fā)展已使其成為圖像信息傳遞的重要手段[1] 且在相關領域取得顯著成果[2-3]。邊緣是一幀圖像中信息最為豐富的區(qū)域,如何對采集到的視頻圖像進行準確、高效的邊緣提取成為圖像處理領域的一個熱點問題。相較于利用軟件實現(xiàn)邊緣檢測算法,硬件電路有著處理速度快、實時性高等優(yōu)點。本研究的實驗平臺以可擴展處理平臺ZYNQ 作為主要的開發(fā)環(huán)境[4],該平臺結合了現(xiàn)場可編程邏輯門陣列(fieldprogrammable gate array,F(xiàn)PGA)和一個雙核ARMCortex-A9 處理器[5-6]。通過軟硬件協(xié)同設計,成功構建了一個嵌入式圖像處理系統(tǒng)[7]。與傳統(tǒng)圖像檢測系統(tǒng)相比,基于ZYNQ 的圖像處理系統(tǒng)在邊緣閾值設置合理時,能顯著提升邊緣檢測質量,具備良好的實時性和可擴展性,為后續(xù)復雜圖像處理算法的擴展和移植提供了有利條件。
1 系統(tǒng)整體架構
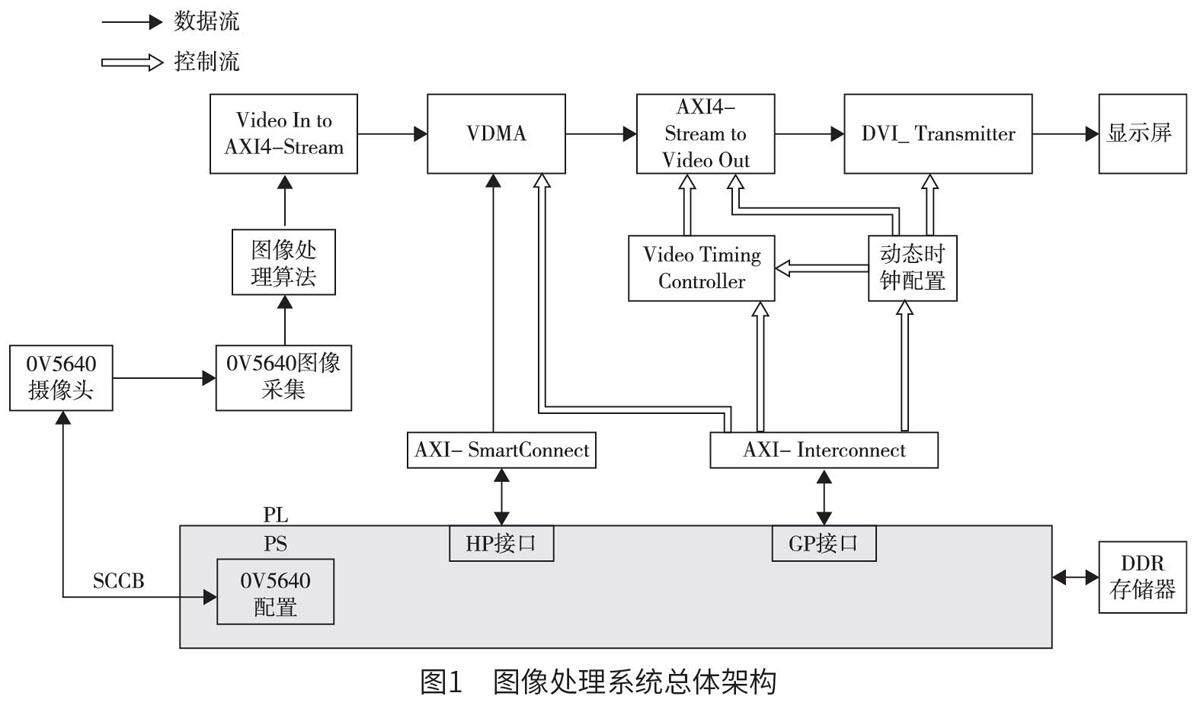
ZYNQ-7000 系列是由Xilinx 公司于2010 年4月推出的采用28 nm 制造工藝的嵌入式處理平臺,也就是一片帶有可編程片上系統(tǒng)的芯片。其包括可編程邏輯(programmable logic,PL)部分和處理系統(tǒng)(processing system,PS)部分。其中,PL 部分是傳統(tǒng)的FPGA,而PS 部分則包含了ARM 處理器,該設計使得ZYNQ 芯片兼具FPGA 的靈活性和ARM 處理器的通用計算能力。如圖1 所示,上方為FPGA 可編程邏輯部分,下方為ARM 處理系統(tǒng)部分,上下部分通過AXI 接口來進行大數(shù)據(jù)量的交互。PL 端包括圖像OV5640 采集、邊緣檢測和AXI 視頻直接內(nèi)存訪問(video direct memoryaccess,VDMA)IP 核等模塊。PS 端包括高性能(high performance,HP)接口、通用目的(generalpurpose,GP)接口、OV5640 配置等模塊。根據(jù)PL 端獲取外界視頻流信息所做的處理,PS 端通過GP 接口對各IP 核進行任務調度,兩者功能的不同可在圖1 中具體劃分為數(shù)據(jù)流和控制流。
(1)數(shù)據(jù)流:首先使用PS 端的串行攝像機控制總線協(xié)議(serial camera control bus,SCCB)接口對OV5640 攝像頭進行配置,利用PS 端擴展的多路輸入/ 輸出(extended multi-channel input/output,EMIO)來模擬SCCB 協(xié)議[8],從而驅動500 W 的OV5640 攝像頭采集外界視頻圖像信息。攝像頭圖像采集IP 核負責將攝像頭采集到的外界圖像數(shù)據(jù)轉換成視頻流數(shù)據(jù)。然后經(jīng)過灰度處理和邊緣檢測算法IP 核處理,使用AXI4-Stream IP 核將處理后的視頻流數(shù)據(jù)處理轉換成AXI4-Stream 格式的數(shù)據(jù)流。之后VDMA 的寫數(shù)據(jù)通道將這些數(shù)據(jù)轉換成Memory Map 格式,并將其寫入PS 端搭載的DDR3存儲器中緩存數(shù)據(jù)。為了實現(xiàn)與DDR3 存儲器進行大數(shù)據(jù)量的交互,AXI -SmartConnect 連接VDMA和HP 接口。VDMA 在DDR3 中讀出之前緩存過的視頻圖像信息,并將其按行傳輸至AXI4-Stream toVideo Out IP 核。在視頻時序控制器(video timingcontroller,VTC) 的控制下,AXI4-Stream to VideoOut IP 核將所有AXI4-Stream 數(shù)據(jù)轉換為視頻傳輸?shù)臉藴蕯?shù)據(jù)流格式,并將已處理過的視頻數(shù)據(jù)流連接至高清多媒體接口(high definition multimediainterface,HDMI)驅動IP 核的輸入端口。最后,采集并經(jīng)過處理的圖像會實時顯示在HDMI 屏上。
(2)控制流:ZNYQ 的PS 端通過GP 接口的AXI-Interconnect 連接IP 核對VTC 模塊進行系統(tǒng)配置,使得VTC 根據(jù)灰度處理配置信息,將AXI4-Stream 格式的數(shù)據(jù)轉換成符合HDMI 顯示屏輸出的標準數(shù)據(jù)流格式。PS 端根據(jù)HDMI 顯示屏的不同型號,通過識別顯示屏編碼(identity document,ID)控制動態(tài)時鐘IP 核,靈活配置時鐘的IP。這樣的設計允許系統(tǒng)輸出與HDMI 顯示屏兼容的時鐘頻率,從而達到匹配不同分辨率HDMI 顯示屏的目的。
2 軟件算法設計
2.1 RGB 轉YUV
采用500 W 的攝像頭OV5640 采集RGB565 格式的視頻數(shù)據(jù)流,但由于RGB 格式圖片像素數(shù)據(jù)的復雜性和龐大性對后續(xù)高層次操作的圖像處理構成了挑戰(zhàn)[9]。為了解決這個難題,對RGB 彩色圖像進行預處理,即去除多余的色彩信息,僅保留圖像的亮度等級分布特征。在圖像編碼領域,YUV(YCbCr)是一種更為適合處理的圖像格式,可將色度和亮度進行分離[10]。為了降低圖像數(shù)據(jù)所需的存儲容量、減少后續(xù)算法處理時間,首先需要進行RGB 到YUV 圖像格式的轉換。
在當前的RGB 轉YUV 算法中,采用加權平均法的圖像灰度化效果最為優(yōu)越[11],能夠有效保留圖像的亮度特征。通過對彩色圖像的每個像素點的3個分量進行加權平均,其中不同的權值考慮了人眼對不同顏色的敏感度[12],得到心理學灰度值的計算公式如下:
Y=0.299×R+0.587×G+0.114×B。 ( 1)
Cb=-0.169×R-0.331×G+0.5×B+128。 ( 2)
Cr=0.5×R-0.419×G-0.081×B+128。 ( 3)
其中,Y、Cb、Cr 分別為YCbCr 圖像格式的3 個不同顏色分量,R、G、B 分別為24 位RGB 數(shù)據(jù)的紅、綠、藍顏色分量。
用Verilog HDL 語言(一種硬件描述語言)對公式進行描述時,由于其無法進行浮點運算,因此將其擴大256 倍再縮小至原值的1/256,最后為避免過程中結果出現(xiàn)負數(shù)可以對其進行變換,變換后的計算公式如下:
Y=(77×R+150×G+29×B)÷256。 ( 4)
Cb=(-43×R-85×G+128×B+32768)÷256。 ( 5)
Cr=(128×R-107×G-21×B+32768)÷256。 ( 6)
2.2 Sobel 邊緣檢測
2.2.1 獲得3×3 原始圖像
將周圍像素灰度值變化較為明顯的像素所組成集合稱為邊緣,其代表了圖像中信息最豐富的區(qū)域,因此該集合是后續(xù)進行復雜圖像處理算法的重要依據(jù)。同時在圖像預處理時,保證圖像邊緣信息的完整性、邊緣輪廓的清晰性是后續(xù)處理的重要保障。目前在圖像處理領域使用較為廣泛的邊緣檢測算法包括Roberts 算子、改進的LoG 算子、Sobel 算子[13]等,其中Sobel 算子可以滿足本研究的需求,該算子是一種離散性差分算子,具有便于在硬件平臺上實現(xiàn)的特點,因此適用于實際工程。通過在每個像素點上與Sobel 模版因子(2 組3×3 的矩陣)進行卷積,可以得到相應的灰度矢量。在進行Sobel 邊緣檢測算法之前,需要先獲得一個3×3 原始圖像模板。
為了獲取一個3×3 原始圖像模板,可以將輸入圖像數(shù)據(jù)的前兩行存入隨機存取存儲器(randomaccess memory,RAM)中,第3 行是當前串口輸入的圖像數(shù)據(jù)。當輸入的圖像數(shù)據(jù)到達時,使用兩個RAM 模塊(一個用于讀取,一個用于寫入)進行實例化,如表1 所示。同時從RAM1 和RAM0中讀取前兩行數(shù)據(jù)與第3 行數(shù)據(jù)進行合并,得到一個“三行一列”的像素數(shù)據(jù)。通過連續(xù)地寄存該“三行一列”的陣列3 次,獲取一個“三行三列”的圖像矩陣,該矩陣就是后續(xù)圖像算法處理所需要的3×3 原始圖像模板。
讀出RAM1 和RAM0 中存儲的兩行數(shù)據(jù)之后,將存儲在RAM0 中的第2 行圖像數(shù)據(jù)寫入RAM1中作為第1 行,之前輸入的一行圖像數(shù)據(jù)寫入RAM0,從而不斷刷新兩個RAM 中的數(shù)據(jù)實現(xiàn)雙RAM 連續(xù)操作。
2.2.2 卷積操作
Sobel 模版因子是2 組3×3 的矩陣,2 組矩陣因子用于進行水平和豎直方向的邊緣檢測。將原始圖像模板與各方向上不同權重的Sobel 模版因子做卷積操作可以得到兩個不同方向上的亮度差分近似值。水平和豎直方向的圖像灰度值計算公式如下:
通過將結果邊緣閾值與設定好的合理閾值進行比較,大于設定閾值即可判斷該像素點是邊緣信息點,在顯示屏上顯示白色邊緣,反之顯示黑色。
3 實驗結果及分析
對搭建好的圖像處理系統(tǒng)平臺進行功能和性能測試,通過調整邊緣檢測閾值參數(shù)大小,將處理后的圖像數(shù)據(jù)在HDMI 顯示屏上進行實時顯示。結果表明不同閾值下的實時視頻(分辨率為1 280×720)檢測效果各不相同,通過調整閾值大小可以有效地顯示較小字體,如圖2 所示。當閾值為55 時,圖像邊緣部分變得更加纖細同時也較為清晰,圖像完整性得以保留(圖2b)。如圖2c 所示,經(jīng)過閾值為160 的檢測算法處理后,由于閾值設置過大導致一些顏色特征變化不明顯的邊緣點未能準確檢測,導致文字邊緣模糊不清。當閾值為30 時,圖像處理結果如圖2d 所示,閾值設置過小是出現(xiàn)很多虛假邊緣的主要原因。因此,設置合適的閾值對邊緣檢測處理效果有較為明顯的影響。通過對相同物體進行不同閾值的邊緣檢測,實驗結果較好地驗證了該系統(tǒng)功能的完備性以及圖像算法的有效性。
同時對系統(tǒng)片內(nèi)消耗的邏輯資源進行匯總,由表2 可以看出,邊緣檢測算法片內(nèi)資源使用合理,檢測結果完全符合預期且留有豐富資源,為實現(xiàn)后續(xù)更復雜的圖像處理算法提供了一個較好的硬件平臺。
性能測試階段,在OpenCV 平臺和本系統(tǒng)平臺(軟硬件平臺)上對單幀圖像檢測時間進行對比,各平臺邊緣檢測耗時比較如表3 所示。在ARM 處理器上調用OpenCV 函數(shù)對一幀圖像進行邊緣檢測從而獲得一幀檢測時間。在本文設計的平臺上,通過調用中斷來獲取單幀的檢測時間,并將其與OpenCV 平臺的檢測時間進行比較,以評估邊緣檢測速度差異。由表3 可知,采用軟硬件協(xié)同工作的方法對實時視頻中一幀圖像進行邊緣檢測,軟硬件平臺平均檢測耗時相比于OpenCV 平臺處理速度平均提高了7.225 倍,證明該系統(tǒng)在進行圖像處理時具有更快的速度且后期開發(fā)價值大。
4 結論
本文提出一種基于FPGA+ARM 的實時視頻邊緣檢測系統(tǒng),使用全面可編程芯片ZYNQ 作為開發(fā)平臺,系統(tǒng)結合了FPGA 的并行處理數(shù)據(jù)能力和ARM 處理器的靈活任務調度優(yōu)勢對圖像進行算法處理,處理后的圖像數(shù)據(jù)通過HDMI 顯示屏進行實時顯示。該系統(tǒng)充分發(fā)揮了ZYNQ 的PL 端和PS 端通過AXI 接口進行大吞吐量數(shù)據(jù)流交互的優(yōu)勢,合理利用片內(nèi)資源,為后續(xù)算法的實現(xiàn)提供一定空間。同時視頻采集速度能夠達到實時傳輸?shù)囊螅噍^于純軟件平臺算法處理具有明顯優(yōu)勢,為進一步開發(fā)復雜功能的嵌入式視覺系統(tǒng)奠定基礎。
