基于YOLO v7的海量煙支外觀缺陷快速自動標注方法
2024-05-30 10:35:02呂獻周蔣銘李慶松吳仕超余茜
科技創新與應用 2024年15期
呂獻周 蔣銘 李慶松 吳仕超 余茜

基金項目:紅云紅河煙草(集團)有限責任公司科技項目(HYHH2022ZK01)
第一作者簡介:呂獻周(1986-),男,工程師。研究方向為卷煙工藝質量管理。
*通信作者:余茜(2000-),女,碩士研究生。研究方向為機器學習,統計學習。
DOI:10.19981/j.CN23-1581/G3.2024.15.009
摘? 要:圖像標注作為監督式機器學習的關鍵環節,在處理海量的煙支缺陷數據時,傳統的人工標注方法由于耗時長和主觀性強等缺點顯得不夠高效。針對煙支缺陷檢測領域中大量圖像數據的自動化標注挑戰,該文以YOLO v7作為基線網絡,并進行一系列經驗性的改進,以解決傳統人工標注過程中存在的高成本和低效率問題。通過對YOLO v7的結構進行創新性調整,如合并neck層和head層,并引入Rep VGG結構,實現煙支圖像的高效自動標注。實驗結果表明,改進后的YOLO v7和YOLO v7-tiny在真實煙支數據集上的標注錯誤率分別為7.3%和6.56%,其中YOLO v7-tiny展現最快的標注速度。這項研究不僅在提高標注效率和準確性方面取得顯著進步,還為煙支缺陷檢測領域提供一種經濟高效的自動化處理方案。
關鍵詞:YOLO v7;煙支外觀缺陷檢測;自動標注;RepConv;VGG
中圖分類號:F768.29? ? ? 文獻標志碼:A? ? ? ? ? 文章編號:2095-2945(2024)15-0040-06
Abstract: Image tagging is a key part of supervised machine learning. When dealing with massive cigarette defect data, the traditional manual labeling method is not efficient because of its long time and strong subjectivity. Aiming at the challenge of automatic labeling of a large number of image data in the field of cigarette defect detection, this paper uses YOLO v7 as the baseline network and makes a series of empirical improvements to solve the problems of high cost and low efficiency in the traditional manual labeling process. Through the innovative adjustment of the structure of YOLO v7, such as merging neck layer and head layer, and introducing Rep VGG structure, the efficient automatic label of cigarette image is realized. The experimental results show that the labeling error rates of the improved YOLO v7 and YOLO v7-tiny on the real cigarette data set are 7.3% and 6.56% respectively, and YOLO v7-tiny shows the fastest labeling speed. This study has not only made remarkable progress in improving the efficiency and accuracy of labeling, but also provides an economical and efficient automatic processing scheme for cigarette defect detection.
Keywords: YOLO v7; cigarette appearance defect detection; automatic labeling; RepConv; VGG
在煙草行業中,煙支外觀質量的控制對于保證產品一致性和消費者滿意度至關重要。傳統的煙支外觀檢測主要依賴于人工視覺檢測,這一過程不僅耗時耗力,而且在面對高速生產線上海量煙支的檢測任務時,其效率和準確性受到嚴重限制。人工標注作為一種傳統方法,盡管具有一定的靈活性,但在面對海量數據的處理時,常常因為人為疲勞、判斷標準不一致等因素導致標注質量不穩定,從而影響最終的產品質量檢測。
針對上述問題,本研究提出了一種基于YOLO v7的海量煙支外觀缺陷快速自動標注技術。YOLO v7作為最新的目標檢測算法之一,以其高效的檢測速度和優秀的識別準確性而受到關注。我們利用YOLO v7的先進性能,結合煙支外觀特點,開發了一種自動化的缺陷檢測和標注系統。該系統不僅可以顯著提高標注速度,降低人力成本,還能通過連續的學習和調整,不斷提高對缺陷識別的準確度。該方法不僅為煙草行業提供了一種新的質量控制方法,還為類似的高速生產線產品質量檢測提供了參考。通過自動化和智能化的技術手段,我們能夠更有效地保證產品質量,提高生產效率,同時也為深度學習在工業應用中的推廣提供了一個成功案例。
YOLO(You Only Look Once)[1-2]是一種流行的目標檢測算法,其能夠在較短的時間內高效地檢測圖片中的物體。因此,將YOLO算法應用于煙支外觀缺陷檢測可以有效提高煙支外觀缺陷檢測的準確性和效率。除了YOLO,目標檢測的其他算法還有R-CNN[3-4]、Faster R-CNN[5-6]和SSD[7]等都在深度學習領域取得大量的科研成果。Li等[8]通過改進YOLO模型將其全部卷積化,在鋼帶表面缺陷檢測中達到97.5%的精度和95.86%的召回率。Zhu等[9]提出TPH-YOLO v5模型,在YOLO v5基礎上用了變形預測頭TPH并整合了卷積塊注意力模型CBAM,與基準模型(YOLO v5)相比提高了約7%。Wang等[10]提出了一種可訓練的自由包導向解決方案將靈活高效的訓練工具與所提出的架構和復合縮放方法相結合,在所有已知的實時物體檢測器中,YOLO v7在GPU V100上以30 fps或更高的速度檢測物體,準確性最高,達到 56.8% AP。Yong[11]等基于YOLO v5s結合注意力機制提出了一種用于卷煙外觀兩階段圖像缺陷檢測的改進模型,平均精度達到了91.6%。
目前,在目標檢測領域還沒有看到結合自動標注技術用于煙支外觀缺陷檢測方面的研究。煙支缺陷檢測模型需要大量數據。在煙支生產線中需要將存在缺陷的煙支檢測出來并進行剔除,在訓練模型時需要大量的缺陷樣本數據。數據標注過程成本較高,需要耗費大量的人力與時間成本,且存在部分主觀性,對后續訓練模型存在一定程度的影響。基于YOLO v7精度更高,速度更快,能夠處理高分辨率圖像的優點。
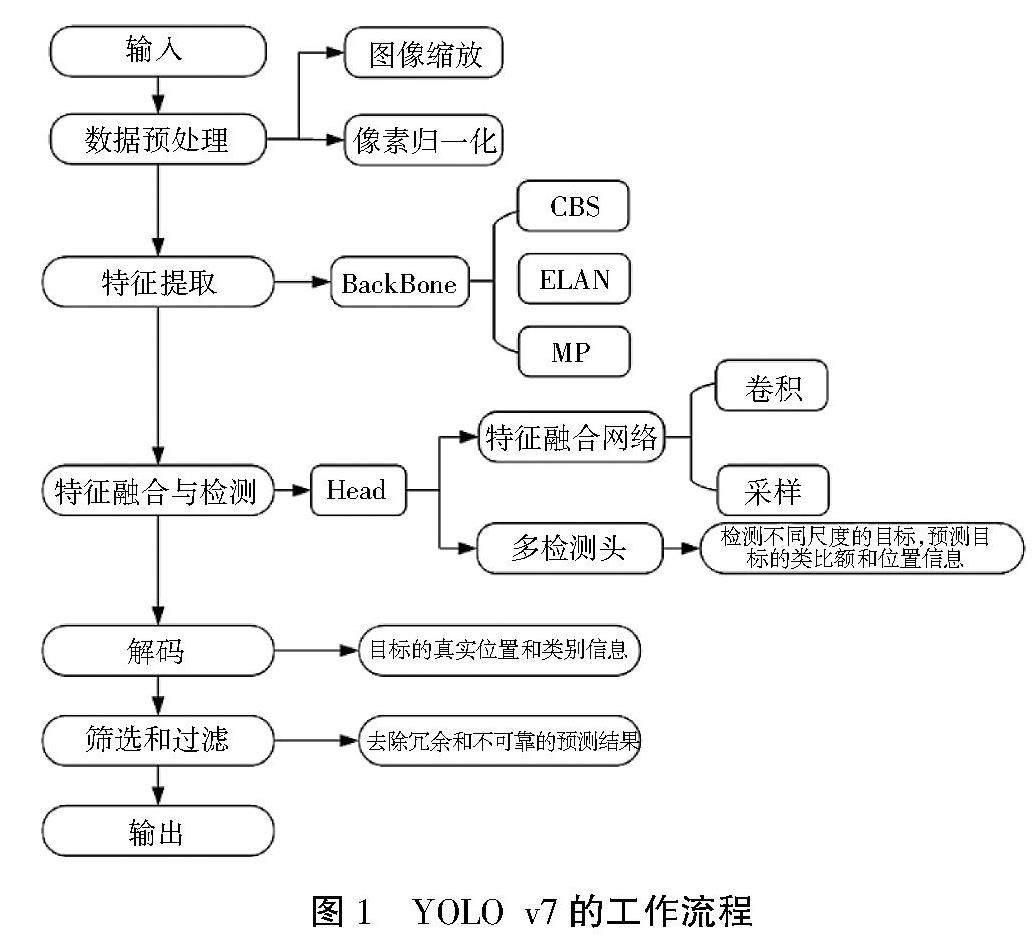
1? YOLO v7的工作流程介紹
圖1為YOLO v7的工作流程,包括如下幾方面的內容。
1.1? 輸入圖像預處理
在YOLO v7的工作流程中,圖像預處理是第一步且至關重要的環節。預處理的主要目標是將原始輸入圖像轉換成適合后續網絡處理的格式。這通常包括圖像的歸一化和縮放。歸一化處理是指將圖像數據的數值范圍調整至一個標準化的區間,通常是0到1或-1到1之間,這樣可以加快網絡的收斂速度并提高訓練過程的穩定性。歸一化處理后,圖像的每個像素值都會被轉換為一個小數,反映原像素值與最大可能像素值之間的比例。圖像縮放則是調整圖像的尺寸以符合模型輸入的要求。
1.2? 特征提取階段
一旦圖像被預處理,它接著被送入卷積神經網絡(CNN)進行特征提取。在這個階段,CNN通過多個卷積層來學習和提取圖像的特征。卷積層通過應用一系列的濾波器(也稱為核),在圖像上滑動并計算局部區域的點積,以此來提取圖像的局部特征。隨著網絡層次的加深,所提取的特征從簡單的邊緣和紋理逐漸轉變為更復雜的形狀和對象部分。在每個卷積層之后,通常會有一個激活函數,如ReLU,用于增加網絡的非線性處理能力。此外,某些層還會使用池化(pooling)操作,以減少特征圖的空間尺寸,從而降低計算量并增加特征的抽象級別。這一過程不僅提高了網絡對圖像中重要特征的敏感度,還降低了對背景噪聲的敏感性,從而使模型能夠更好地學習圖像中的重要信息。
圖1? YOLO v7的工作流程
1.3? 構建特征提取網絡(Backbone Network)
繼特征提取階段之后,YOLO v7的工作流程進入構建特征提取網絡(Backbone Network)的步驟。Backbone Network的核心作用是進一步提高模型對圖像特征的表達能力。這一網絡通常由多個卷積層、池化層和殘差結構組成。殘差結構是一種特殊的網絡設計,它允許信息跨越多個層次直接傳遞,從而解決了在深層網絡中常見的梯度消失和爆炸問題。通過這種方式,Backbone Network能夠在不丟失關鍵信息的情況下,更深入地學習和提取圖像的高級特征。此外,為了應對不同尺度的圖像特征,Backbone Network還會采用多尺度特征提取策略,這意味著網絡能夠同時關注圖像的粗粒度和細粒度特征。這種多層次、多尺度的特征提取策略極大地增強了模型的表現力,使其能夠更準確地識別和定位圖像中的各種目標。
1.4? 特征融合網絡構建(Neck Network)
特征融合網絡(Neck Network)的構建是YOLO v7工作流程的下一個關鍵步驟。Neck Network的主要任務是將Backbone Network提取的不同層次的特征進行有效的融合。為了實現這一目的,Neck Network通常包括多個卷積層、上采樣和降采樣操作。上采樣操作用于增加特征圖的空間分辨率,使得深層的高級特征能夠與淺層的低級特征結合,從而捕捉到更加豐富的空間信息。相反,降采樣操作則用于減少特征圖的空間分辨率,使得淺層的低級特征能夠與深層的高級特征結合,以增強模型對于全局信息的感知能力。通過這種方式,Neck Network能夠整合不同層次的特征,使模型在處理不同尺度的目標時更加靈活和高效。此外,這一階段的操作還包括多種特征融合策略,如特征金字塔網絡(FPN)或其他先進的特征融合技術,以進一步提升模型的性能和魯棒性。
1.5? 檢測頭的加入(Detection Head)
在特征融合網絡(Neck Network)之后,YOLO v7的工作流程進入到加入檢測頭(Detection Head)的階段。每個檢測頭負責處理不同尺度的目標檢測任務,并預測目標的類別和位置信息。在實際應用中,這意味著模型能夠同時處理小尺寸目標、中等尺寸目標以及大尺寸目標的檢測。每個檢測頭通常包含多個卷積層,這些卷積層專門針對特定尺度的特征圖進行處理。在此基礎上,每個檢測頭還會對目標的邊界框、置信度以及類別進行預測。這些預測是通過在特征圖上應用一系列的錨框(anchor boxes)來完成的。錨框是預定義的不同形狀和大小的框,它們幫助模型錨定并預測圖像中的對象。每個錨框與一個特定類別的概率以及四個邊界框偏移量相關聯。通過這種方式,檢測頭能夠為每個錨框生成一個預測,包括目標的類別、位置和置信度。這一階段的關鍵在于確保模型能夠有效地識別和定位圖像中的多種目標,同時保持高準確度和低誤檢率。
1.6? 輸出解碼(Decode)
解碼階段的目的是將檢測頭輸出的信息轉化為實際的目標位置和類別信息。這通常涉及對目標邊界框的位置、大小進行調整,以及將類別概率轉換為具體的類別標簽。解碼過程對于將模型的預測轉化為實際可用的結果至關重要。
1.7? 目標信息篩選與過濾
在這一步驟中,系統將解碼后的目標信息進行篩選和過濾。這包括去除低置信度的預測、應用非極大值抑制(NMS)等方法來減少重疊檢測框。這個過程的目的是確保最終輸出的檢測結果既準確又可靠。
1.8? 最終檢測結果輸出
最后階段,系統輸出最終的目標檢測結果。這些結果包括了每個檢測到的對象的類別、位置(通常是邊界框坐標)和置信度。這些信息對于后續的應用,如煙支外觀缺陷檢測和剔除,至關重要。
2? 煙支外觀自動標注流程
為煙支外觀缺陷自動標注流程圖,煙支外觀缺陷數據準備、煙支外觀缺陷檢測模型訓練、煙支外觀缺陷自動標注3個部分組成。
2.1? 煙支外觀缺陷數據準備
在此階段,雙機位相機系統捕獲的煙支圖像數據,經過存儲和預處理后,需進行初步的缺陷標注。這里可以引入YOLO v7的初始模型進行半自動標注,利用其高效的檢測能力快速識別顯著的缺陷特征。這樣不僅加速了標注過程,而且提高了數據集的初始質量。這些數據集將為接下來的模型訓練提供基礎。
2.2? 煙支外觀缺陷檢測模型訓練
在模型訓練階段,加載經過預處理和初步標注的煙支外觀缺陷數據集,并使用YOLO v7進行訓練。YOLO v7的優勢在于其快速且準確的特征提取能力,能夠有效地處理煙支的各種缺陷特征。在訓練過程中,通過不斷調整候選框尺寸和優化網絡參數,YOLO v7模型能夠更精確地學習到煙支缺陷的特征。訓練過程中損失函數的收斂表明模型已經有效學習到了煙支外觀缺陷的識別特征。
2.3? 煙支外觀缺陷自動標注
最后階段,在自動標注階段,加載訓練好的YOLO v7模型來處理新的煙支外觀缺陷數據。YOLO v7的高效檢測能力能夠快速準確地識別并標注出煙支的缺陷區域。通過自動標注,大大減少了人工參與的需求,提高了標注的效率和一致性。標注完成后的結果可以用于后續的分析和質量控制。
3? 實驗結果與分析
3.1? 標注圖片速度對比
圖2展示了不同版本的YOLO v7模型在推理時間(inference)、非極大值抑制時間(nms)和總時間(total)方面的性能比較。時間單位是毫秒(ms),越低表示效率越高。這些模型可能是針對特定任務的不同優化版本或大小變體,例如針對速度、準確性或資源占用的優化。以下是對圖表的詳細分析。
①YOLO v7:原始的YOLO v7模型在推理時間上為4 ms,非極大值抑制時間為1.4 ms,總時間合計為5.4 ms。這可以視為我們比較的基線。②YOLO v7x:這個版本的推理時間稍長(6.4 ms),非極大值抑制時間(1.3 ms)與原始YOLO v7相比略微減少,總時間為7.7 ms,表明這個版本可能在推理準確性上有所增強,但犧牲了一定的速度。③YOLO v7-w6:在此版本中,推理時間為4 ms,非極大值抑制時間為1.7 ms,總時間為5.7 ms。這顯示了相對于原始YOLO v7,它在總時間上有所改進。④YOLO v7-d6:推理時間為7.9 ms,非極大值抑制時間為1.6 ms,總時間為9.4 ms。這可能是一個針對更復雜任務設計的版本,具有較長的推理時間。⑤YOLO v7-e6:推理時間為6 ms,非極大值抑制時間為1.5 ms,總時間為7.5 ms。這個版本在推理時間和非極大值抑制時間上都表現出適中的性能。⑥YOLO v7-e6e:這個版本具有最長的推理時間9.2 ms,非極大值抑制時間為1.3 ms,總時間為10.5 ms。它可能是最為復雜的版本,可能在準確性上有所提升,但在速度上損失較大。⑦YOLO v7-tiny:如其名,這可能是一個輕量級版本,具有最短的推理時間(1 ms),非極大值抑制時間(1.1 ms),總時間僅為2.1 ms。這表明它非常快速,但可能在準確性或檢測能力上有所妥協。
圖2? 不同模型性能比較
總體來說,不同的模型版本之間在速度和可能的準確性上存在權衡。選擇哪個模型版本將取決于特定應用的要求,例如在對實時性要求高的場景中,可能會選擇YOLO v7-tiny,而在需要更高準確性的場景中,可能會選擇YOLO v7-e6e或YOLO v7-d6。在實際應用中,還需要考慮模型的復雜性、資源消耗以及目標檢測任務的具體需求。
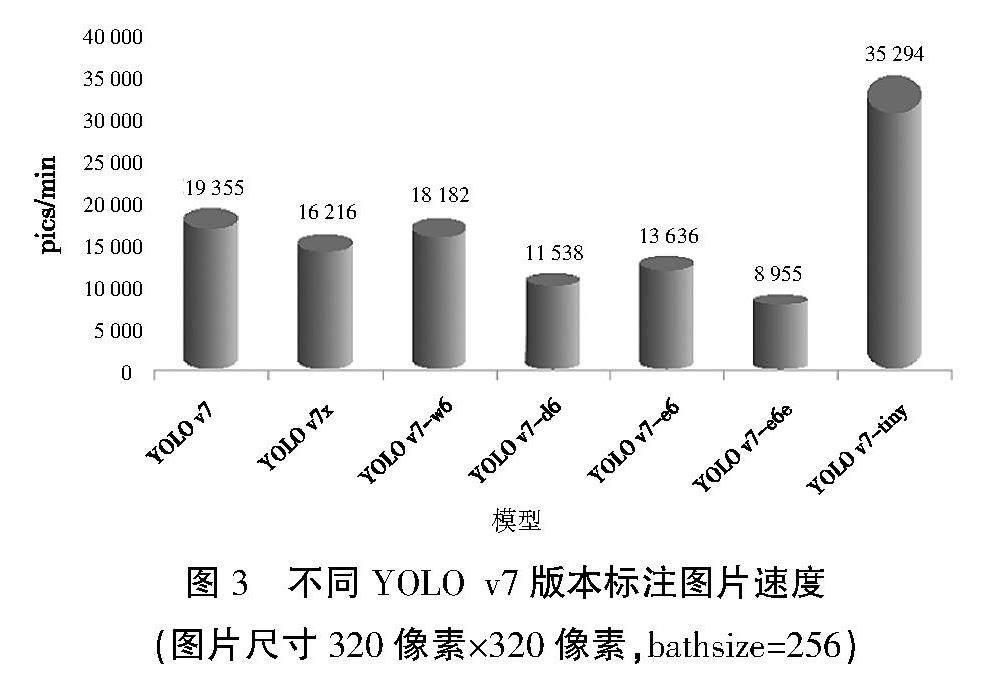
圖3展示了不同版本的YOLOv7模型在處理320像素×320像素分辨率圖片、批量大小為256時的標注速度性能。性能指標是每秒可以處理的圖片數(單位為 pics/min,即張/分鐘),速度越快表示模型效率越高。以下是對圖表的概要性分析。
①YOLO v7:基線模型,處理速度約為19 000 pics/min。②YOLO v7x:略低于基線,處理速度約為16 000 pics/min,可能由于模型更復雜或進行了更深層次的分析,影響了處理速度。③YOLO v7-w6:處理速度為18 000 pics/min,接近基線模型,表明優化可能側重于其他方面,如準確性或特征提取。④YOLO v7-d6:處理速度降到11 000 pics/min,此下降可能表明該版本進行了更為復雜的操作,需要更多的計算資源。⑤YOLO v7-e6:處理速度為13 000 pics/min,比YOLO v7-d6有所提高,處理速度略高于YOLO v7-e6e,但仍低于基線。⑥YOLO v7-e6e:約為9 000 pics/min,表明這兩個模型可能在性能上有細微的區別。⑦YOLO v7-tiny:顯著高于其他所有模型,以約35 000 pics/min的速度處理圖片,這反映了其輕量級設計,旨在提供極高的處理速度,雖然可能犧牲了一些準確度或功能性。
圖3? 不同YOLO v7版本標注圖片速度
(圖片尺寸320像素×320像素,bathsize=256)
總結來看,不同的模型版本在處理速度上有顯著差異,從YOLO v7-tiny的極高速度到YOLO v7-d6的較低速度,這些差異可能反映了模型復雜性、準確性和計算效率之間的平衡。在實際應用中,選擇哪個版本將取決于特定任務的需求,如對速度的敏感度、可接受的準確度損失,以及可用的計算資源。
3.2? YOLO v7自動標注結果展示
在圖4中,使用了YOLO v7模型來自動標注274張圖片,這些圖片涉及煙支生產過程中的8種不同缺陷類別,具體包括刺破、夾沫、爆口、接裝紙異常、遮擋異常、褶皺以及正常的卷煙紙部分和接裝紙部分。這些類別代表了煙支生產和包裝過程中可能出現的典型問題,其中一些是明顯的缺陷,而其他的則是正常的生產過程特征。自動化標注系統的任務是將每張圖片中的特征準確分類和標記。
在自動標注完成后,通過進一步的驗證發現,有20張圖片發生了標注錯誤,包括誤標和漏標的情況。誤標是指錯誤地為圖片中的對象分配了錯誤的類別標簽,而漏標則是指未能識別并標記出應當被標注的對象。標注錯誤率計算為錯誤標注的圖片數量除以總標注圖片數量,再乘以100%,在這種情況下,標注錯誤率為7.3%。這一數值提供了關于YOLO v7在當前配置下針對特定任務的性能的直觀理解。
3.3? YOLO v7-tiny 自動標注結果展示
在圖5中,使用YOLO v7-tiny輕量級版本對數據集進行自動標注,其中這些圖片的類別與YOLO v7模型中的類別一致。在這274張圖片中,有18張存在標注錯誤,包括誤標和漏標,計算得出的標注錯誤率為6.56%。在考慮圖像尺寸對標注效果的影響時,發現使用512像素×512像素的圖像尺寸比320像素×320像素的尺寸更為有效。此外,綜合考慮模型大小、平均精度均值(mAP)、推理時間以及處理圖像的數量,我們認為選擇YOLO v7及YOLO v7-tiny作為自動圖像標注工具是較為合適的選擇。
在對比分析YOLO v7與YOLO v7-tiny 2個模型時,發現主要差異體現在準確性、模型大小和處理速度3個方面,見表1。YOLO v7在平均精度均值(mAP)上略高于YOLO v7-tiny(0.839∶0.824),表明其在識別準確性上有細微的優勢。然而,這種優勢是以較大的模型大小(74.8 MB)和較慢的處理速度(11 111張/min)為代價的。相比之下,YOLO v7-tiny雖然在準確性上略遜一籌,但它的模型大小顯著更小(12.3 MB),且處理速度遠快于YOLO v7(28 571張/min)。這使得YOLO v7-tiny更適用于資源受限或需要快速處理大量數據的場景,而YOLO v7則更適合對準確度要求較高的應用。因此,根據具體應用的需求和限制,選擇兩者之一是關鍵。
表1? YOLO v7與YOLO v7-tiny的各指標
4? 結束語
本文研究基于YOLO v7的煙支外觀缺陷的快速自動標注技術。YOLO v7以其出色的檢測精度、高效的處理速度,以及對高分辨率圖像的強大處理能力,成為本研究的核心技術。通過運用YOLO v7的這些優勢,有效地生成大量高質量的訓練數據,為構建更精確的煙支缺陷檢測模型提供了堅實的基礎。相較于傳統手工標注方法,本技術具有以下幾個顯著優點。
1)提高標注效率:相比人工逐一標注,YOLO技術顯著提升了標注速度,降低了人工成本。
2)提高標注準確率:利用深度學習算法的強大圖像識別能力,YOLO技術能更準確地識別和標注目標,減少了標注誤差。
3)可擴展性強:作為基于深度學習的模型,YOLO技術具有良好的可擴展性。通過增加訓練數據和調整模型參數,可以進一步提高標注的準確率,并適應多樣的標注場景和需求。
4)適用范圍廣:YOLO技術可應用于各類圖像標注場景,如物體檢測、人臉識別、車輛識別等,具備廣泛的適用性。
綜上所述,本研究提出的基于YOLO v7的煙支外觀缺陷自動標注技術,在該領域中展現出顯著的潛力和廣泛的應用潛力。未來,計劃進一步探索新版本的YOLO模型在煙支圖像標注中的潛在應用和優化方向,以持續提升標注準確性和效率。
參考文獻:
[1] REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]//Computer Vision & Pattern Recognition.IEEE,2016.
[2] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the IEEE conference on computer vision and pattern recognition,2017.
[3] GIRSHICK R, DONAHUE J, DARRELL T,et al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//IEEE Computer Society,2014.
[4] HE K, GKIOXARI G,PIOTR DOLL?魣R, et al. Mask R-CNN[C]//IEEE Transactions on Pattern Analysis & Machine Intelligence,2017.
[5] GIRSHICK R. Fast r-cnn[C]// Proceedings of the IEEE international conference on computer vision,2015.
[6] REN S, HE K, GIRSHICK R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015. 28.
[7] LIU W, ANGUELOV D, ERHAN D, et al. Ssd: Single shot multibox detector[C]//Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part I 14,2016.
[8] LI J, SU Z, GENG J, et al.Real-time detection of steel strip surface defects based on improved yolo detection network[J]. IFAC-PapersOnLine,2018,51(21):76-81.
[9] ZHU X, LYU S, WANG X, et al. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios[C]// Proceedings of the IEEE/CVF international conference on computer vision,2021.
[10] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//arXiv.arXiv,2022.
[11] YONG P, JIANG D, LYV X Z, et al. Efficient and High-performance Cigarette Appearance Detection Based on YOLOv5[C]// In 2023 International Conference on Intelligent Perception and Computer Vision (CIPCV),2023:7-12.
