面向車聯網的聯邦學習模型定制框架及算法改進
2024-06-01 23:56:36李翰奇王小妮吳秋新王燦吳浪杜俊龍秦宇
計算機應用研究 2024年5期
李翰奇 王小妮 吳秋新 王燦 吳浪 杜俊龍 秦宇
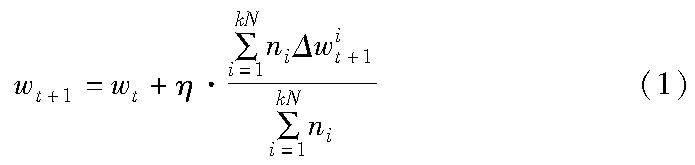
摘 要:針對車聯網聯邦學習服務難以滿足用戶訓練個性化模型的需求,提出一種創新性的車聯網聯邦學習模型定制化服務框架。該框架采用了一種融合設備貢獻度和數據集相似性的聯邦學習聚合算法,實現了個性化聯邦學習。該算法通過不同權重分配方式和相似性計算,使得不同用戶可以根據自己的需求和數據特征,選擇合適的模型訓練方案。該框架還提出了一種雙重抽樣驗證方法,解決了模型性能和可信度問題;此外,利用智能合約支持數據協作,保障了數據的安全性。實驗結果表明,提出算法在大多數實驗場景中表現出較高的準確率,該框架可以顯著提高車聯網服務的個性化水平,同時保證模型的準確性和可靠性。
關鍵詞:車聯網; 聯邦學習; 模型定制; 智能合約; 聚合算法
中圖分類號:TP181;U495 文獻標志碼:A?文章編號:1001-3695(2024)05-007-1328-10
doi:10.19734/j.issn.1001-3695.2023.09.0416
Customized federated learning model framework and
algorithm enhancements for vehicular networks
Abstract:This paper proposed an innovative customized service framework for the federated learning model of the Internet of Vehicles(IoV), which addressed the difficulty of meeting the needs of users to train personalized models in IoV federated learning services. This framework adopted a federated learning aggregation algorithm that integrated device contribution and dataset similarity, achieving personalized federated learning. This algorithm used different weight allocation methods and similarity calculations to enable different users to choose appropriate model training schemes based on their own needs and data characteristics. The framework also proposed a dual sampling validation method to address model performance and credibility issues, and utilized smart contracts to support data collaboration, ensuring data security. The experimental results show that the proposed algorithm exhibits high accuracy in most experimental scenarios, and this framework can significantly improve the personalized level of IoV services while ensuring the accuracy and reliability of the model.
Key words:Internet of Vehicles; federated learning; personalized model; smart contracts; aggregation algorithms
0 引言
車聯網作為智能交通的重要組成部分,正逐步改變人們的出行方式。將車輛、道路基礎設施和互聯網連接起來,為駕駛員和交通管理部門提供了更多的信息和控制手段。為了實現這一連接和信息傳遞,車聯網服務商收集車輛各種形式的數據,包括車輛的位置信息、車速、油耗、行駛路線、發動機狀態、車輛健康狀況、駕駛習慣、車內環境數據等,這些數據通過車載傳感器、GPS定位系統、車輛控制單元等設備收集,隨后經過處理和分析用于提供各種車聯網服務,如實時交通信息、遠程車輛診斷、智能導航、駕駛行為分析、車輛遠程控制和保險定價等功能。這些數據的收集和分析有助于安全駕駛、提高燃油效率、降低維護成本,同時也為用戶提供更便捷、智能化的駕駛體驗。然而,隨之而來的數據隱私和安全問題也需要得到妥善解決,以保護用戶的個人信息和車輛的安全性。對此,谷歌提出一種保護隱私的機器學習方法——聯邦學習(federated lear-ning,FL)[1],其中模型服務商將訓練模型發送給設備進行本地訓練,設備無須向模型服務商發送任何形式的本地數據,而是將更新的模型參數交由模型服務商整合。這樣模型服務商可以把樣本和特征匯聚到一起,獲得更好的預測模型,同時增加了互不信任的各方參與聯邦學習的意愿。
然而,在設備上傳模型參數和模型服務商發送訓練模型時仍然有隱私數據泄露的可能[2]。隨著區塊鏈技術的持續發展,基于區塊鏈技術搭建車聯網數據共享平臺可以實現安全、透明、不可竄改的數據記錄和交換,為車輛之間、車輛與交通基礎設施之間建立信任提供了新的方法,從而實現數據安全性和高參與度的結合,使得該系統適合車輛制造商、保險公司、道路管理機構以及車主和駕駛員,為各方提供了一個安全、可信的數據交換平臺,推動了車聯網技術的廣泛應用和進一步創新。
在傳統聯邦學習中,模型聚合僅針對全局模型參數,最終交付的是適用于所有參與方數據的單一全局模型。然而,不同用戶的應用場景和需求差異巨大。例如:在車輛安全領域,一家汽車制造商可能更關心模型的實時性和穩定性,以支持自動駕駛系統的實時決策;而一家保險公司可能更側重于模型的事故預測準確性和風險評估。面對這種模型服務需求的多樣性,如何有效地針對個性化需求來聚合模型參數以滿足不同用戶的需求,成為一個亟待解決的問題。
本文深入分析了車聯網中的具體問題和需求,提出了一種創新的解決方案,即結合聯邦學習和區塊鏈技術構建一個面向車聯網的模型學習服務框架。在此框架中,提出了融合設備貢獻度和數據集相似性的聯邦學習聚合算法(contribution and simulated-based aggregation algorithm,CSBA)以及雙重抽樣驗證算法(double class-sampled validation-error scheme,D-CSVES)。這些方法的設計充分考慮了數據的異質性,解決了客戶個性化需求的問題。本文主要貢獻如下:a)聯邦學習模式結合了長安鏈(ChainMaker)不可竄改和分布式的特性,針對車聯網數據隱私保護和模型安全更新需求,提出了一種基于區塊鏈和聯邦學習的車聯網數據共享和模型更新方法,使用智能合約操作車輛上傳數據和用戶業務請求數據的過程,以保證數據的隱私性和安全性;b)提出了一種基于數據相似性的聯邦學習聚合算法,允許在模型聚合過程中考慮不同用戶之間的數據相似性,從而更精確地個性化聚合模型參數,滿足不同用戶的需求;c)提出一種改進的雙重抽樣驗證算法,該算法能夠更有效地評估模型在聯邦學習環境中的性能并提供更可靠的性能度量,以支持模型的優化和選擇。使用Python進行模擬驗證系統的可行性,在MNIST數據集、CNN模型的情況下得到了出色的識別準確率,為系統的可行性提供了有力的支持。
1 聯邦學習與區塊鏈
1.1 聯邦學習概述
聯邦學習是機器學習的一個分支,它構建了一種全新的機器學習模式,訓練模型時無須將數據上傳到中央服務器,而是將模型參數在客戶端和服務器之間相互傳遞,以保護客戶端隱私。聯邦學習的工作流程如圖1所示,通常分為三個階段:
a)初始化模型下載。中央服務器初始化初始模型的參數,然后將其作為全局模型廣播給聯邦學習環境中的客戶端。
b)本地模型更新。客戶端使用本地私有數據對接收到的全局模型進行訓練,然后所有的客戶端將它們的本地模型參數發送到中央服務器。全局模型從本地模型參數的平均值中更新。同時,中央服務器可以在訓練過程中隨時添加或者刪除客戶端。
c)全局模型下載。中央服務器將聚合后的全局模型廣播給所有客戶端,完成一次聯邦學習迭代,中央服務器上的模型會隨著迭代次數的增多變得更加符合目標要求。
假設客戶端的總數為N,ni表示第i個客戶端的數據樣本數量。在輪數t,聯邦學習服務器隨機選擇一些客戶端kN(0<k≤1)組成客戶端群,并要求他們用自己的本地數據集更新全局模型。更新方式采用聯邦平均算法,數學表達式為
其中:wt表示模型在時間t時的更新,而wt+1是模型在時間(t+1)時的更新;此外,Δwit+1給出了客戶端i在全局參數中更新的改變量;η為全局聯邦學習模型的學習率。
聯邦學習通過重復b)c)階段,使用聚合算法不斷迭代全局模型,然后同步給全局所有客戶端。在聯邦學習的全局模型更新過程中,聚合算法發揮著至關重要的作用。例如,文獻[1]中谷歌的聯邦學習框架vanilla FL在獲得本地模型更新的參數后,中央服務器通過聯邦平均算法(federated averaging algorithm,FedAvg)計算所有本地模型更新的平均值作為全局模型的更新,但僅限于依據本地數據量占數據總量的比值進行權重分配,然而僅基于本地數據量的比例可能導致某些設備對全局模型的貢獻不足,存在一定的優化空間。Konecˇny'等人[3]提出了Federated- Averaging算法,即一種基于聯邦平均的聯邦學習聚合算法。該算法使用本地更新的梯度進行全局模型的更新,并使用加權平均的方式來平衡設備的不可靠性。FederatedAveraging算法能夠在移動設備上實現聯邦學習,并提高通信效率和設備的可靠性,但是對于數據的不平衡性和異質性表現不佳。Nilsson等人[4]對三種聯邦學習算法進行基準測試,并將它們的性能與傳統機器學習方法進行比較,其中聯邦平均算法在聯邦算法中達到了最高的精度。文獻[5]證明了聯邦匹配平均(federated matched averaging,FedMA)算法與聯邦平均算法和FedProx算法相比,僅在幾輪迭代中表現良好。朱建明等人[6]根據模型質量評估結果以及節點在協作過程中的信譽值評分調整模型聚合權重,增加高質量模型參數在聚合模型中的貢獻度占比,從而提升聚合模型的準確率。從以上聚合方式中可以發現,不同的權重分配方法對于聯邦學習算法的性能有顯著影響。
1.2 長安鏈概述
長安鏈作為區塊鏈開源底層軟件平臺,包涵區塊鏈核心框架、豐富的組件庫和工具集,可以為用戶高效、精準地解決差異化區塊鏈實現需求,構建高性能、高可信、高安全的新型數字基礎設施,同時也是國內首個自主可控區塊鏈軟硬件技術體系。在長安鏈的區塊結構中,每個區塊由Header(區塊頭)、Dag(塊內交易的執行依賴順序)、Txs(塊內交易列表)和AdditionalData(區塊產生以后附加的數據)構成。區塊結構如圖2所示。其中,區塊頭包括了多個字段,如BlockVersion(區塊版本)、BlockType(區塊的類型)、ChainID(鏈標識)、BlockHeight(區塊高度)、BlockHash(本區塊的散列值)等。
鑒于區塊鏈在數據隱私保護方面具有一定優勢,越來越多的研究人員將其應用到聯邦學習上。Zhao等人[7]提出了一種基于區塊鏈的隱私保護聯邦學習框架,在保護數據隱私和確保安全性的同時提高了模型的準確性和收斂速度,但是可能會面臨區塊鏈的性能瓶頸;Wu等人[8]提出了一種基于區塊鏈的去中心化聯邦學習方法,可以提高計算效率,同時保證數據隱私和安全性;Lu等人[9]提出一種使用深度學習模型和差分隱私技術的車聯網數據隱私保護方案;Boualouache等人[10]提出了一種使用差分隱私和聯邦聚合技術方案來保護數據隱私和解決數據不平衡問題,方案中所有車輛的數據都被用于訓練模型,但是當不同車輛之間的數據存在明顯不平衡時會導致模型的學習性能下降;Kang等人[11]提出了一種可靠的聯邦學習激勵機制,結合了聲譽和合同理論以激勵高聲譽的移動設備參與模型學習;Hu等人[12]提出了一種基于區塊鏈的實時分布式能源交易共識機制,解決了傳統共識機制在實時交易中的效率問題;Yuan等人[13]提出了一種名為ShadowEth的新型私秘智能合約方案,該方案基于以太坊公共區塊鏈,使用加密技術保護合約的隱私和安全性,但存在對合約的復雜性和可擴展性等的限制問題;Wang等人[14]提出了一種基于區塊鏈的數據訪問控制和數據共享框架,可以在分散式存儲系統中實現細粒度的數據訪問控制和數據共享,使用智能合約來管理訪問控制策略,同時通過基于區塊鏈的加密技術保護數據的隱私性和安全性;Qu等人[15]通過將區塊鏈和聯邦學習結合實現了分散隱私保護,并防止了霧計算場景中的單點故障,區塊鏈可以向聯邦學習參與者提供激勵;Lu等人[16]通過聯邦學習來構建數據模型并共享,提出了一種新的區塊鏈授權協作架構,通過分布式多方貢獻數據以降低數據泄露的風險,使用基準、開放的真實數據集對提出的模型的有效性進行了評估;Martinez等人[17]建立了一種基于EOS區塊鏈的聯邦學習模式來保護數據安全,提出了一種為設備的數據類定制驗證集以進行類抽樣錯誤驗證(class-sampled validation-error scheme,CSVES)的激勵機制方案,在訓練之前,數據提供者會將使用的一部分分類數據提供給模型服務商,模型服務商在這些分類數據中隨機抽樣一批作為驗證數據集返還給數據提供者,當訓練完成之后,利用這些驗證數據集計算驗證集誤差,如果驗證集誤差是遞減的,則確認所訓練模型是有效的。以上過程均使用智能合約完成操作,以限制模型服務商與本地節點功能的重合。類抽樣驗證錯誤方案解決了獎勵用戶貢獻的不準確或效率低下的問題,但是即便驗證了所有數據提供者提供的模型參數是有效的,通過取平均值的聯邦平均算法對模型聚合,對于模型的參數也是嚴重的浪費。
區塊鏈現在已經向智能合約時代發展,智能合約技術是區塊鏈技術中的一個重要組成部分,它為開發者提供了一種去中心化、不可竄改的計算環境,使得各種應用可以在區塊鏈上進行安全、透明的執行[18]。而智能合約在長安鏈上具有多種功能,如可以實現去中心化的數字貨幣交易、智能投票、鏈上游戲、供應鏈追溯等。同時,長安鏈還提供了多種開發工具和部署工具,方便開發者進行開發、測試和部署。
本文在提出的面向車聯網的聯邦學習模型定制框架中使用了長安鏈的智能合約,將智能合約作為協調各個參與方之間的通信和數據交互的角色。當設備需要上傳本地數據時,使用智能合約進行身份驗證和數據安全保護,確保數據的完整性和隱私性。同時,智能合約還負責管理和控制聯邦學習算法的執行過程,確保各個參與方的本地模型都能按照預定的流程進行訓練和更新。在全局模型更新過程中,智能合約通過調用聯邦學習聚合算法來計算所有本地模型的更新,生成全局模型更新結果并將其發送給各個參與方。通過這種方式能夠更加高效地利用各個設備產生的數據,并保障數據的隱私和安全性。
2 面向車聯網的聯邦學習模型定制框架
2.1 需求分析
車聯網的特點是不同用戶之間的需求和數據具有顯著的差異,這些差異包括駕駛習慣、行車偏好、使用場景等。一輛自動駕駛車輛需要實時性,個人車主需要個性化服務,而車隊管理系統需要協同性和效率,傳統的模型學習方法難以有效滿足多樣性的需求,因此聯邦學習模型服務框架必須具備靈活性以滿足這些多樣性需求,需要解決以下問題:a)個性化需求問題。車聯網用戶需要個性化的預測和分析服務,如何根據用戶的特定需求為他們提供高度個性化的模型是一個重要問題。b)數據碎片化問題。車聯網中的數據通常分散在不同的車輛和用戶側,如何有效地協同利用這些分布式的數據以提高模型的泛化性能。c)數據隱私和安全問題。用戶的車聯網數據包含敏感信息,如行駛軌跡和車輛狀態,如何確保數據的隱私性和安全性,以及如何建立可信任的數據交互環境。d)聯邦學習與區塊鏈整合問題。在解決上述問題時,如何充分利用聯邦學習方法來處理分布式數據和個性化需求,并將其與區塊鏈技術相結合以確保數據的可信任交互和隱私安全。
2.2 面向車聯網的聯邦學習模型定制化服務框架
基于上述需求和問題,設計面向車聯網的聯邦學習模型定制化服務框架。該框架如圖3所示。
主要包括以下組成部分:
a)長安鏈及智能合約。本框架首先在長安鏈上部署一套智能合約,以支撐車輛側、用戶側和模型服務商側建立實現模型定制化服務的聯邦學習,通過智能合約為各方提供可信交互方式并保障數據的安全性和隱私性。
b)用戶側。在框架中,用戶側存在不同類型的用戶,包括車輛、個人和車聯網特定應用系統等。用戶側的每個用戶都可以根據自身需求向模型服務商申請模型定制化服務,用戶通過長安鏈及智能合約與模型服務商交互,完成模型定制需求提交、聚合模型有效性上傳和模型獲取等操作。
c)車輛側。在框架中,車輛側是車聯網運行數據的持有者,每一輛車都可能含有一些特定的數據類型,并通過長安鏈及智能合約參與到模型服務商組織的聯邦學習中。車輛計算出本地數據類的頻率分布,提交給模型服務商用于支持聚合算法;在每一輪的聯邦學習中,參與學習的車輛首先獲取模型服務商的模型參數,然后使用本地數據訓練產生本輪本地模型,并使用從模型服務商獲取的分類抽樣驗證集對本地模型進行驗證,最后將模型參數和驗證結果發送給模型服務商。
d)模型服務商側。模型服務商側在框架中扮演兩個角色,一個是基于長安鏈開發和部署一套支撐聯邦學習的智能合約,另一個是基于用戶側的定制化服務需求組織車輛側的聯邦學習。模型服務商獲取用戶側的模型定制化需求,接收車輛側的各車輛本地數據類的頻率分布,并基于該分布生成分類抽樣驗證集,然后發送給該車輛。組織每一輪的聯邦學習,首先下發模型供車輛側訓練,然后接收各車輛的本地模型和驗證結果,并根據聚合算法進行參數更新和模型聚合;經過多輪聯邦學習后,將所形成的模型交付給用戶側,用戶側驗證有效則完成定制化服務任務,否則繼續進行訓練直到用戶驗證通過。
面向車聯網的聯邦學習模型定制化服務框架融合用戶側、車輛側、模型服務商側,構建了一套新型聯邦學習模式,該模式采用長安鏈智能合約保障聯邦學習交互的可信與安全,并將雙重抽樣驗證融入聯邦學習過程,大大提升了定制化模型的適用性。
2.3 智能合約設計
為了支撐服務體系需要創建一個智能合約,由模型服務商部署在長安鏈上,并授權用戶和車輛可以調用智能合約的函數。函數列表如表1所示。
在這些函數中,由用戶和車輛調用的函數主要用于將用戶模型定制需求、車輛模型參數和數據類頻率分布寫入區塊中,由模型服務商調用的函數主要用于獲取用戶和車輛寫入的內容以及基于車輛本地數據類頻率分布生成分類抽樣驗證集。verifyModelParameters()和verifyDataSet()函數則用于用戶和車輛進行模型參數驗證和結果驗證。
2.4 聯邦學習模型定制化服務運行流程
面向車聯網的聯邦學習模型定制化服務的具體運行流程如下:a)智能合約部署。O需要在長安鏈平臺上部署所設計的智能合約,以支持用戶側Uj、車輛側Di與模型服務商之間的可信安全交互。b)Uj提交模型定制需求。如圖4所示,Uj通過調用submitRequirement()將自己需求的模型所偏好的數據類頻率分布CU寫入區塊中,以便O進行處理。c)Di生成并提交本地數據的數據類頻率分布。如圖5所示,Di通過調用submitParameter()將自己的本地數據分布CD寫入區塊中,以便O獲取。
d)O依據車輛數據類頻率分布生成分類抽樣驗證集vsi。如圖5所示,O依據getParameters()獲取的車輛數據類頻率分布CD,通過調用generateDataSet()向車輛Di提供隨機大小的分類抽樣驗證集vsi,并在智能合約中進行隱私保護措施。
e)O聚合模型。聚合過程如圖6所示,分成兩個階段,第一階段為權重wki的分配,第二階段是模型聚合和本地訓練。
(a)采用三種不同算法(具體見3.2~3.4節)實現權重分配。若采用3.2節的CBA聚合算法,O收到vki后會根據vki進行聚合時每個Di的權重w的分配;若采用3.3節的SBA聚合算法,O收到CU和CD后,會根據CU與CD間的相似性進行聚合時每個Fi的權重w的分配;若采用3.4節的CSBA聚合算法,O收到vki與CU和CD后,會根據vki、CU和CD間的相似性進行聚合時每個Di的權重w的分配。
(b)O利用計算出的車輛權重聚合模型Mj,然后將生成的Mj返回給Uj。每個車輛Di在訓練過程中都有Mj的Tki副本以及當前版本vi=k,k表示第k輪,每個車輛Di∈D在接收到第k個模型Tki時,使用其大小為ni的本地數據di離線訓練模型Tki以獲得更新的模型,然后計算梯度δi=Tk+1i-Tki,將δi的值和Tki同時上傳給O。
f)O下發模型參數。如圖6所示,O通過調用setModelParameters()將模型參數Tik寫入區塊中,供Di獲取。
g)Di獲取模型參數。如圖6所示,每一輪O發放本地模型時,Di可以通過調用getModelParameters()從區塊中獲取模型參數Tik。
h)Di進行本地模型訓練。如圖6所示,車輛Di進行本地模型訓練,然后將δi、vi作為交易從鏈上發送給與Di連接的區塊。從車輛Di上傳交易所需的參數,如表2所示。
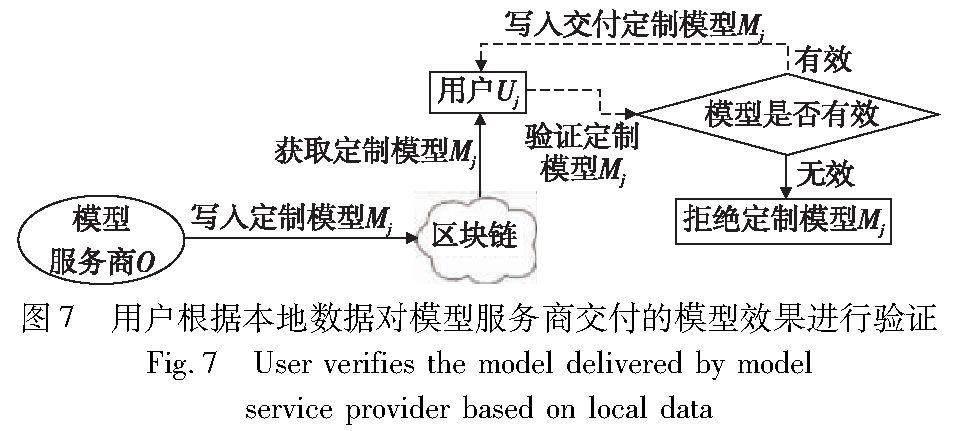
i)Di驗證數據集并提交結果。本框架采用的雙重抽樣驗證分成兩個階段,第一重分類抽樣驗證為車輛本地分類抽樣驗證,如圖5所示,第二重分類抽樣驗證是用戶個性化驗證,如圖7所示。圖5中Di驗證數據集并將驗證結果通過調用verifyDataSet()寫入區塊中,以便O獲取。
在第一重抽樣驗證中,如步驟d)所述,Di與O通過交互生成供Di驗證的數據集vsi,Di根據O設定的輪次(如每l輪開展一次驗證)驗證模型參數,然后將驗證結果vki通過智能合約發送給O。第二重抽樣驗證將在步驟l)開始進行。
j)O獲取驗證結果。如圖5所示,O通過getVerificationResult()獲取Di的驗證結果vki。如果聯邦學習還在設定的輪數內,繼續按步驟e)~j)進行聯邦學習,直到設定的輪數完成。
k)O向Uj交付模型參數。如圖6所示,O通過調用setModelParameters()將全局模型Mj寫入區塊中,供Uj獲取。
l)Uj獲取模型參數。如圖7所示,本步驟開始進行第二重分類抽樣驗證,Uj可以通過調用getModelParameters()從區塊中獲取Mj。
m)Uj提交模型反饋。Uj通過verifyModelParameters()對接收到的Mj進行驗證,如果驗證準確率大于設定的模型驗證閾值θ,則認可Mj,接受該模型,并將驗證結果result置為true;否則,將result置為false。然后通過調用submitModelFeedback()寫入區塊中,以便O獲取。
n)O獲取模型反饋。如圖7所示,O通過調用getModel-Feedback()獲取Uj的模型反饋result,如果為true,則結束聯邦學習,完成Uj的模型定制化服務;否則繼續進行τ輪聯邦學習訓練(τ是事先由O確定),然后再按步驟m)n)對所訓練的模型進行驗證。如此重復,直到Uj接受O所訓練的模型,完成模型定制化服務。
2.5 Petri網建模與分析
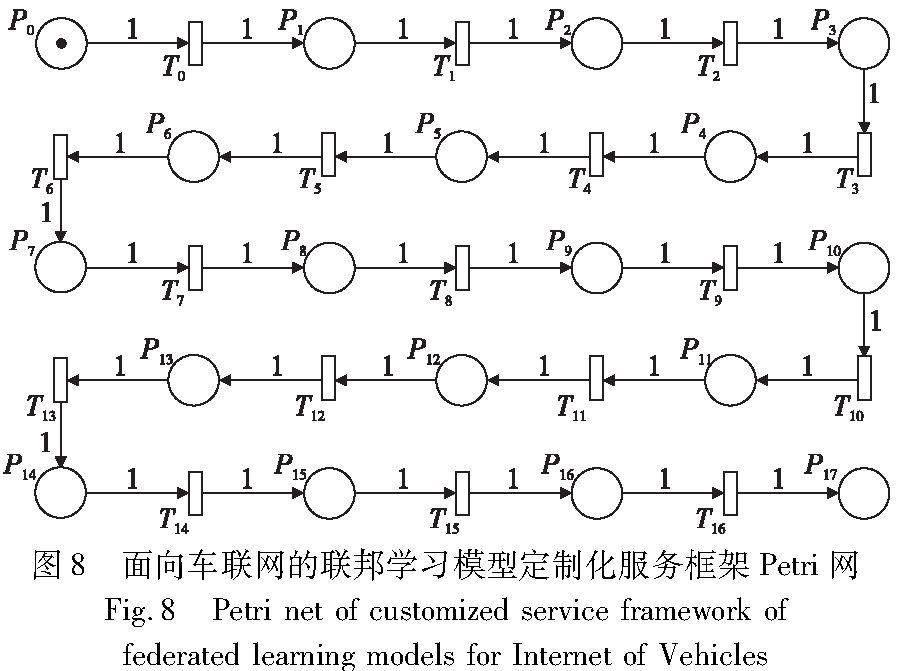
本文采用Petri網建模仿真工具PIPE構建模型和仿真驗證,Petri網的設計如圖8所示,庫所和變遷的定義如表3所示,對面向車聯網的聯邦學習模型定制化服務框架Petri網的模型死鎖、安全性和有界性進行檢驗。
利用PIPE仿真工具對Petri網系統的死鎖、有界性和活性進行仿真分析的結果如表4所示。使用Petri網PIPE仿真工具對面向車聯網的聯邦學習模型定制化服務框架進行仿真分析,驗證了該框架的Petri網模型具有有界性、安全性和活性,表明該框架在實際應用系統開發中是可靠、可行的。
3 算法改進
3.1 模型參數更新計算
在2.1~2.3節所描述的服務框架中,用戶Uj希望訓練一個能夠適應其數據類的模型。如圖4所示,Uj首先將自己的模型需求(需要預測的數據類CU)傳遞給模型服務商O,與此同時,每個車輛Di也加載本地數據,提取本地數據的數據類CD發送給O。為了完成定制化模型需求,O收到CU與CD后,會根據CU與CD間的相似性進行聚合時每個Di的權重w的分配,最后利用計算出的車輛權重聚合模型Mj∈M,然后O會將生成的Mj返回給Uj。O聚合初始模型T0i將所有權重初始化為ω~N(0,1)。用更新的δi對模型進行聚合以計算T1i,定義ωkl為T0i中的第k輪第l個參數,δki,l為第k輪第i個車輛的第l個參數的變化量,bk表示第k輪參與者的數量,η是學習率,wki是根據所選擇的算法第k輪分配的權重。訓練模型應用更新為
若聚合后的最新版本是版本k,則將Tki命名為Mj,稱為全局模型。
3.2 基于設備貢獻度的聯邦學習聚合算法
本節提出一種基于設備貢獻度的聚合 (contribution-based aggregation,CBA) 算法,旨在通過將設備本地驗證準確率作為權重對模型參數的聚合產生影響,使得準確率高的車輛訓練參數對總體模型參數聚合的影響大,準確率低的車輛訓練參數對總體模型參數聚合的影響小。
在CBA算法中,每輛車的本地數據的驗證準確率來自于雙重抽樣驗證(具體見3.4節)的第一重抽樣驗證的分類抽樣結果,即驗證準確率,作為貢獻度發送給模型服務商。模型服務商根據每個設備的貢獻度來分配其權重,然后利用加權平均的方式對模型參數進行聚合。假設模型服務商為第i個車輛提供分類抽樣驗證集vsi,第i個車輛基于自身第k輪訓練模型對vsi進行驗證,得到模型驗證準確率vki為
其中:TPki表示第i個車輛第k輪把正樣本判斷為正樣本的樣本數量;TNki表示把正樣本判斷為負樣本的樣本數量;FPki表示將負樣本判斷為正樣本的樣本數量;FNki表示將負樣本判斷為負樣本的樣本數量。依據模型驗證準確率vki計算第k輪第i個車輛的模型權重wki為
3.3 基于數據集相似性的聯邦學習聚合算法
本節提出基于數據集相似性的聯邦學習聚合 (simulated-based aggregation,SBA)算法,數據集相似性是通過兩個數據集在數據類分布上的“距離”來定義。這里兩個數據集的數據類分布的“距離”采用信息論中的相對熵或者KL散度來定義。SBA算法旨在通過將數據集相似性作為權重對模型參數的聚合產生影響,使得相似性大的車輛訓練參數對總體模型參數聚合的影響大,相似性小的車輛訓練參數對總體模型參數聚合的影響小。
對提出定制化模型服務需求的用戶,可以用數據類分布CU={CU(k),k=1,2,…,p}來刻畫其模型定制需求,其中CU(k)為用戶第k個數據類的頻率。第i個車輛的數據類分布設為CDi={CDi(k),k=1,2,…,p},其中CDi(k)為第i個車輛第k個數據類的頻率,則第i個車輛與用戶的數據類分布的KL散度為
因為KL散度可以刻畫兩個概率分布之間的“距離”,所以兩個數據集的相似性可以采用散度的倒數來表示,距離小相似性就大,距離大相似性就小。但當兩個分布完全相同時,KL散度的值為0,其倒數為無窮大,導致相似性為無窮大,因此需要進行適當調整。兩個數據集相似性計算調整如下:
為確保各個車輛的權重之和為1,將每個車輛的權重歸一化:
3.4 基于融合設備貢獻度和數據集相似性的聯邦學習聚合算法
本節提出融合設備貢獻度和數據集相似性的聯邦學習聚合算法(CSBA),旨在通過融合本地驗證準確率和數據集相似性作為權重對模型參數的聚合產生影響,使準確率高并且相似性大的車輛訓練參數對總體模型參數聚合的影響加大,準確率低或者相似性小的車輛訓練參數對總體模型參數聚合的影響減小。
假設模型服務商為第i個車輛提供分類抽樣驗證集vsi,并設定提出定制化模型服務需求的用戶,其數據類分布為
3.5 基于CBA或CSBA及雙重分類抽樣驗證的聯邦學習算法
本文提出的基于CBA-CSBA雙重分類抽樣驗證算法(D-CSVES)旨在解決聯邦學習中的數據隱私和模型準確性問題,利用模型服務商和車輛之間的雙重抽樣來驗證車輛本地數據的貢獻度并提高全局模型的準確性。
在第一重抽樣驗證中,車輛的本地數據類CD被提取出來,并從屬于O的鏈下數據集中接收僅從CD的類中選擇的數據點的驗證集,并發送給車輛;車輛利用該數據集周期性地對本地模型進行驗證,然后將驗證結果發送回模型服務商,如果驗證結果較優秀,說明模型參數是一個有價值且有效的更新。選擇CBA算法用于改善聚合模型的效果。
在第二重抽樣驗證中,模型服務商將聚合起來的模型Mk交付給用戶Uj,Uj利用本地數據對模型進行驗證并將結果發送給模型服務商;然后對驗證結果相似的用戶進行聚類分析,以更加深入地了解不同用戶對模型的驗證結果。通過對每個用戶類別進行統計分析,可以得出該類別用戶的平均驗證準確率、標準差、最大值、最小值等指標,這些指標用于評估模型的性能,并為進一步改進模型提供參考。同時將驗證結果與用戶屬性、地理位置等信息進行關聯分析,探索驗證結果與用戶特征之間的關系。例如:可以將用戶按照年齡、性別、教育程度等屬性進行分類,然后比較不同類別用戶的驗證結果,看是否存在顯著差異;也可以考慮將用戶按照地理位置進行分類,然后比較不同地區用戶的驗證結果,探索是否存在地域差異等。通過第二重驗證結果與用戶特征的關聯分析可以為模型的個性化優化提供支持。如果發現某些用戶群體在模型驗證中表現不佳,可以進一步分析他們的特征,從而針對性地優化模型,提高模型的適用性和泛化能力。通過這種雙重抽樣驗證的方式,可以有效驗證車輛本地數據的貢獻度,并提高全局模型的準確性。
算法1 基于CBA或CSBA的雙重分類抽樣驗證算法
輸入:聯邦學習中的用戶U,車輛Di(i=1,2,…,n);聚合的模型Mk;用戶接受的模型驗證閾值θ。
輸出:本地模型分類驗證結果vki,用戶驗證結果result。
1)車輛
輸入:分類抽樣驗證集vsi。
輸出:本地模型分類驗證結果vki。
for e=1,2,…,epoch do
for i=1,2,…,n do
根據驗證集vsi對車輛Di本地模型Tki進行驗證,驗證結果為vki;
end for
將驗證結果vki發送回模型服務商;
end for
2)模型服務商
輸入:聚合的模型Tki,用戶Uj的本地數據,用戶驗證結果result。
輸出:用戶驗證結果result。
while result!=1 do
for i=1,2,…,bk do
for k=1,2,…,p do
if CDi(k)>0 then
從鏈下數據集SO中隨機取一個大小為m的樣本vs[k]i組成vsi;
end if
end for
將vsi發送給第i個車輛;
end for
//等待車輛發送的分類抽樣驗證結果vki
if 采用CBA算法
根據式(4)計算Di的權重wki;
else if 采用CSBA算法
根據式(9)計算Di的權重wki;
//聚合模型
result=將聚合的模型Mk交付給用戶Uj;
end while
3)用戶
輸入:用戶本地數據ui,全局模型Mk,用戶接受的模型驗證閾值θ。
輸出:用戶驗證結果result。
從模型服務商處接收聚合的模型Mk;
利用本地數據ui對模型進行驗證;
result=θ;
if 驗證結果>θ do
result=1;
將驗證結果result發送回模型服務商。
3.6 基于SBA的聯邦學習算法
算法2 基于數據相似性的聯邦學習算法
輸入:聯邦學習中的用戶U;用戶的數據集ui;車輛Di(i=1,2,…,n);車輛的數據集di;聯邦學習模型Tki。
輸出:服務商聚合后的全局模型Mglobal。
1)車輛層面
輸入:車輛Di;車輛數據集di;聯邦學習模型Tik。
輸出:車輛本地數據集的數據類CDi;模型梯度δi。
for e=1,2,…,epoch do
for i=1,2,…,n do
將本地數據集的數據類CDi發送給模型服務商;
Di使用本地數據集di離線訓練聯邦學習第k個模型Tki,得到更新的模型Tki;
將梯度計算為δi=Tk+1i-Tki并發送給模型服務商;
end for
end for
2)模型服務商層面
輸入:用戶Uj本地數據集的數據類CUj;車輛Di本地數據集的數據類CDi;模型梯度δi。
輸出:聯邦學習模型Tki;服務商聚合后的全局模型Mj。
for e=1,2,…,epoch do
for i=1,2,…,n do
根據式(7)計算Di的數據類CDi和用戶Uj的數據類CUj的數據相似度權重wki;
end for
根據式(2)計算聯邦學習模型Tki中的每個參數ωki;
將聯邦學習模型Tki發送給每個車輛;
end for
將聯邦學習模型Tki更新到模型服務商的全局模型Mj上;
返回服務商聚合后的模型Mj;
3)用戶層面
輸入:服務商聚合后的模型Mj;用戶本地的數據集ui。
輸出:無。
將本地數據集的數據類CU發送給模型服務商。
4 實驗結果及分析
4.1 數據集和實驗場景設置
本文實驗采用MNIST數據集進行實驗,每個實驗場景車輛側設定5輛車,每輛車擁有不同的數據類頻率分布、模型服務商;用戶側設定為1名用戶,進行聯邦學習模型的訓練與評估。實驗設置如下:本文設計了16種實驗場景,每個場景中設定用戶模型定制需求的數據類及分布、每輛車擁有的數據類及其分布。每個實驗場景中,模型服務商還需根據不同實驗場景下各車輛的數據類及分布生成各自的分類抽樣驗證集,而每個用戶將依據其數據類及分布為定制模型生成其分類抽樣驗證集。在每個實驗場景中,四個算法FedAvg、CBA、SBA、CSBA分別運行50次,每次進行10輪聯邦學習通信,而每一輪聯邦學習每輛車要進行10輪本地學習。針對這16種實驗場景,分成兩種實驗模式:a)選出每種算法在10輪聯邦學習通信的準確率均值最高的結果,并呈現其曲線結果;b)選出每種算法在第10輪聯邦學習通信的準確率最高的結果。
4.2 實驗結果分析
在16種實驗場景中,針對實驗模式a),從實驗場景中選擇設置如表5~8所示的4種場景,實驗結果如圖9~12所示,其中包含10輪聯邦學習通信后,使用用戶驗證集進行測試的模型損失曲線和準確率曲線。
實驗1的結果如圖9所示,從總體趨勢來看,在準確率方面CSBA算法表現最好,迅速從54.739%提高到89.867%,并穩定在較高水平;CBA和SBA算法也在10輪通信后取得了較高的準確率,分別達到86.194%和85.992%;FedAvg算法在相同輪次下的準確率為85.439%,略低于其他三個算法。在損失函數方面,CSBA算法同樣取得了最好的結果,從73.253 7下降到16.941 7;其次是CBA和SBA算法,損失函數分別降至26.929 3和25.306 1;FedAvg算法在10輪通信后的損失函數為32.827 4。從整體趨勢來看,CBA、SBA和CSBA算法在準確率和損失函數方面的表現都優于FedAvg算法。
從圖9還可以觀察到在第一輪通信后,CBA和SBA算法都取得了較高的準確率,而CSBA和FedAvg算法的準確率較低;隨著通信輪次的增加,CSBA算法的準確率迅速提高,而FedAvg和CBA算法的準確率增長相對較緩。在損失函數方面,CBA和SBA算法在前幾輪通信后損失函數下降較快,CSBA算法的損失函數下降最為迅速,表現出最佳的收斂速度,FedAvg算法在10輪通信后的損失函數下降幅度相對較小。
觀察各算法在多次實驗中的準確率和損失函數的波動情況可以看出:CSBA算法表現最為穩定,準確率和損失函數曲線較為平滑;CBA和SBA算法在實驗過程中也表現出較好的穩定性,但相比之下略有波動;FedAvg算法的曲線波動較大,表現出較低的穩定性。
在實驗2中,如圖10所示,在10輪聯邦學習通信后,FedAvg算法的準確率從初始的15.655%逐步提高到最終的70.050%;CBA算法從初始的12.267%快速上升至最終的72.431%,表現較為穩定;SBA算法在前幾輪有一定波動,但逐漸趨于穩定,最終的準確率為73.375%;CSBA算法在初始階段準確率較低,隨后快速提升,最終達到73.904%。在損失函數收斂速度上,FedAvg算法的損失函數從167.471 7逐步降低到111.326 2,收斂較快;CBA算法的損失函數在前兩輪下降較快,后續略有波動,最終收斂至105.031 3;SBA算法的損失函數從136.144 2下降至112.856 2,過程中有一定波動,但整體趨勢向下;CSBA算法的損失函數在前四輪下降較快,后續逐漸趨于穩定,最終收斂至111.968 3。可以發現,FedAvg算法在準確率和損失函數方面表現一般,雖然準確率提升較為明顯,但損失函數的收斂速度相對較慢;CBA算法在前幾輪迭代中取得了較高的準確率,但在后期準確率提升相對較緩,收斂速度較快;SBA算法在準確率和損失函數方面表現良好,準確率和損失函數均有較快的下降趨勢,整體穩定性較高;CSBA算法在最初表現不如其他算法,但隨著迭代次數的增加,準確率和損失函數迅速提升,取得了較好的結果。
綜上所述,SBA和CSBA算法在該實驗場景中表現較好,具有較快的準確率和損失函數收斂速度,并且整體穩定性較高;CBA算法在初期,準確率具有較快的上升趨勢,但后期略顯緩慢;FedAvg算法雖然在準確率和損失函數方面均有改進,但整體表現一般。
在實驗3中,如圖11所示,FedAvg算法的準確率從55.354%上升至92.896%,表現出較好的學習能力;CBA算法的準確率從70.729%上升至93.648%;SBA算法從75.914%上升至91.989%;CSBA算法從85.948%上升至93.622%。CBA、SBA和CSBA算法在前幾輪通信后的準確率增長較快,但隨后趨于緩慢增長。與之相比,FedAvg算法在整個學習過程中準確率增長較為平穩。同時可以發現,SBA算法的損失函數在10輪通信后從29.706 4逐漸減小到9.273 5,而其他三個算法在初始輪次中損失函數的降低速度較慢,后續趨于平穩,說明SBA在初始階段具有較好的收斂速度。
綜上所述,CBA、SBA和CSBA算法在一定程度上考慮了車輛個性化需求,對少量車輛數據集效果較好。
在實驗4中,如圖12所示,可以觀察到CBA和CSBA算法在初始幾輪聯邦學習中表現出了較好的性能,特別是在第一輪聯邦學習中,CBA算法的準確率已經達到了76.05%,而CSBA算法的準確率為73.57%,相較于FedAvg算法的準確率45.15%和SBA算法的36.82%,顯著提升了訓練初始階段的模型性能。另外,CBA和CSBA算法在后續的準確率曲線中一直保持較高的水平,并且損失函數下降速度相對較快,表明這兩種算法在訓練過程中能夠更好地適應車聯網數據異構性和模型質量不一致的情況。相比之下,FedAvg算法則在整體準確率和損失函數上有了較大的改進,但與CBA和CSBA算法相比,仍存在一定差距。
通過詳細分析選取的四種實驗場景的實驗結果,可以得出以下結論:CSBA算法相對于FedAvg、CBA和SBA算法表現更優秀。CSBA算法綜合了CBA和SBA的優點,在考慮了用戶分布和車輛分布的個性化特點后提高了模型的泛化性和適應性。隨著通信輪次的增加,CSBA算法逐漸收斂且具有更快的收斂速度,表現出更好的學習能力和性能。
針對實驗模式b),在車聯網應用中,算法需要在有限的通信輪次內給出盡可能好的結果,因此第10輪的比較能夠更直觀地反映算法的短期效果。同時只關注第10輪的結果能夠減少實驗的計算開銷并能提供有價值的信息,從而更高效地進行算法的性能評估和比較。表9是四種算法在五種場景下第10輪聯邦學習通信時的準確率表現。
從表9可以看出,在大多數實驗場景中,SBA和CSBA算法取得了相對較高的準確率,明顯優于FedAvg和CBA算法。特別是在實驗場景9、10、11、13中,SBA和CSBA算法相比其他算法表現出較大的優勢。而在一些實驗場景中,CBA算法取得了與SBA和CSBA算法相近的準確率,表現較為穩定。例如,在實驗場景7中,CBA算法的準確率為98.98%,與SBA和CSBA算法的準確率相差不大。
綜上所述, SBA和CSBA算法在大多數實驗場景中表現出較高的準確率,優于FedAvg和CBA算法。CBA算法在一些場景中也表現穩定,與SBA和CSBA算法的準確率相近;而FedAvg算法在少數實驗場景中也表現出競爭力,但整體性能相對一般。實驗結果表明在不同的實驗場景中,SBA和CSBA算法表現出比FedAvg算法更好的性能,特別是CSBA算法在所有實驗場景中均取得了最高的準確率,CBA算法在某些實驗場景中也表現出較好的性能。這些結果進一步驗證了在聯邦學習環境中,利用準確率聚合、數據相似性的分類聚合和雙重抽樣驗證等方法可以顯著提高模型的性能和收斂速度,說明在聯邦學習環境中,面向車聯網的聯邦學習模型定制化服務框架可以顯著提高模型的性能。
本文設計了四種實驗場景,在面向車聯網的聯邦學習模型定制框架中,將本文方法與FedaAvg、FedFA和文獻[17]中的聯邦學習聚合算法進行對比,每次進行30輪聯邦學習通信,每一輪聯邦學習中每輛車要進行10輪本地學習。四種算法的準確率曲線如圖13所示。
從圖13可以看出,在四種實驗場景中,面向車聯網的聯邦學習模型定制框架中,CSBA算法通過使用數據相似性權重和本地驗證準確率權重聚合,生成的模型更適合用戶目標的數據分布。在30輪的訓練中這種優勢表現得尤為明顯。相比之下,FedAvg采用了傳統的平均聚合方式,FedFA則結合了訓練精度和訓練頻率的信息量來衡量權重,而RFedAvg[17]使用了利用模型差值平均的模型聚合方式,盡管這些算法在某些情況下表現良好,但在定制個性化目標數據分布的訓練任務中效果有限。
5 結束語
面向車聯網的聯邦學習模型定制化服務框架,通過綜合應用長安鏈、數據相似性的聯邦學習聚合算法和雙重抽樣驗證方案,實現了對車聯網數據的高效處理和模型性能的顯著提升。它能夠在保障數據隱私的前提下,根據本地設備的數據相似性賦予模型參數更有針對性的權重,從而更好地利用分布不均的本地數據提高模型的準確性和泛化能力。數據相似性的聯邦學習聚合算法提供了更個性化的模型參數聚合方式,使得模型的構建更貼合需求場景,同時雙重抽樣驗證方案有效預防了模型的過擬合問題,保障了模型的可信度。這一框架有望為車聯網領域提供更安全、高效和個性化的服務。
隨著車聯網技術的不斷發展,用戶對于個性化駕駛體驗的需求將持續增加。這個框架為滿足用戶特定的駕駛習慣、行車偏好和使用場景需求提供了有力支持,為車輛用戶帶來更智能化、個性化的出行體驗。未來可以從以下幾個方面繼續開展研究:
a)改進和優化框架中的算法,進一步提升模型的訓練效率和準確率。同時,計劃擴展框架的適用范圍,將其運用于更多車聯網場景,如自動駕駛、交通管理和車輛安全等領域,以滿足不同用戶群體的需求。
b)關注數據隱私和安全性的問題,進一步加強智能合約的安全性和用戶數據的隱私保護,以確保用戶信息不被濫用或泄露。
c)多模態數據融合,隨著車聯網的不斷發展,車輛將會生成更多的多模態數據,包括圖像、聲音、視頻等。致力開發能夠處理多模態數據的聯邦學習算法,以提供更全面、精確的個性化服務。
參考文獻:
[1]McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Proc of the 20th International Conference on Artificial Intelligence and Statistics. [S.l.]: PMLR, 2017:1273-1282.
[2]Mothukuri V, Parizi R M, Pouriyeh S, et al. A survey on security and privacy of federated learning[J]. Future Generation Computer Systems, 2021,115(2): 619-640.
[3]Konecˇny' J, McMahan H B, Ramage D, et al. Federated optimization: distributed machine learning for on-device intelligence[EB/OL]. (2016-10-08). https://arxiv.org/pdf/1610.02527.pdf.
[4]Nilsson A, Smith S, Ulm G, et al. A performance evaluation of fe-derated learning algorithms[C]//Proc of the 2nd Workshop on Distributed Infrastructures for Deep Learning. New York: ACM Press, 2018: 1-8.
[5]Wang Hongyi, Yurochkin M, Sun Yuekai, et al. Federated learning with matched averaging[EB/OL]. (2020-02-15). https://arxiv.org/pdf/2002.06440.pdf.
[6]朱建明, 張沁楠, 高勝, 等. 基于區塊鏈的隱私保護可信聯邦學習模型 [J]. 計算機學報, 2021,44(12): 2464-2484. (Zhu Jianming, Zhang Qinnan, Gao Sheng, et al. Privacy preserving and trustworthy federated learning model based on blockchain[J]. Chinese Journal of Computers, 2021,44(12): 2464-2484.)
[7]Zhao Yang, Zhao Jun, Jiang Linshan, et al. Privacy-preserving blockchain-based federated learning for IoT devices[J]. IEEE Internet of Things Journal, 2021,8(3): 1817-1829.
[8]Wu Xin, Wang Zhi, Zhao Jian, et al. FedBC: blockchain-based decentralized federated learning[C]//Proc of IEEE International Conference on Artificial Intelligence and Computer Applications. Pisca-taway, NJ: IEEE Press, 2020: 217-221.
[9]Lu Yunlong, Huang Xiaohong, Dai Yueyue, et al. Federated lear-ning for data privacy preservation in vehicular cyber-physical systems[J]. IEEE Network, 2020,34(3): 50-56.
[10]Boualouache A, Engel T. Federated learning-based scheme for detecting passive mobile attackers in 5G vehicular edge computing[J]. Annals of Telecommunications, 2022, 77(4):201-220.
[11]Kang Jiawen, Xiong Zehui, Niyato D, et al. Incentive mechanism for reliable federated learning: a joint optimization approach to combining reputation and contract theory[J]. IEEE Internet of Things Journal, 2019, 6(6): 10700-10714.
[12]Hu Meng, Shen Tao, Men Jinbao, et al. CRSM: an effective blockchain consensus resource slicing model for real-time distributed energy trading[J]. IEEE Access, 2020, 8: 206876-206887.
[13]Yuan Rui, Xia Yubin, Chen Haibo, et al. ShadowEth: private smart contract on public blockchain[J]. Journal of Computer Science and Technology, 2018, 33(5): 542-556.
[14]Wang Shangping, Zhang Yinglong, Zhang Yaling. A blockchain-based framework for data sharing with fine-grained access control in decentra-lized storage systems[J]. IEEE Access, 2018, 6: 38437-38450.
[15]Qu Youyang, Gao Longxiang, Luan T H, et al. Decentralized privacy using blockchain-enabled federated learning in fog computing[J]. IEEE Internet of Things Journal, 2020, 7(6): 5171-5183.
[16]Lu Yunlong, Huang Xiaohong, Dai Yueyue, et al. Blockchain and federated learning for privacy-preserved data sharing in industrial IoT[J]. IEEE Trans on Industrial Informatics, 2019,16(6): 4177-4186.
[17]Martinez I, Francis S, Hafid A S. Record and reward federated lear-ning contributions with blockchain[C]//Proc of International Confe-rence on Cyber-Enabled Distributed Computing and Knowledge Discovery. Piscataway, NJ: IEEE Press, 2019: 50-57.
[18]賀海武, 延安, 陳澤華. 基于區塊鏈的智能合約技術與應用綜述[J]. 計算機研究與發展, 2018,55(11): 2452-2466. (He Haiwu, Yan An, Chen Zehua. Survey of smart contract technology and application based on blockchain[J]. Journal of Computer Research and Development, 2018,55(11): 2452-2466.)
