基于知識圖譜的高價值專利技術創新演化研究
2024-06-03 14:42:47曹茹燁曹樹金
現代情報 2024年6期
曹茹燁 曹樹金


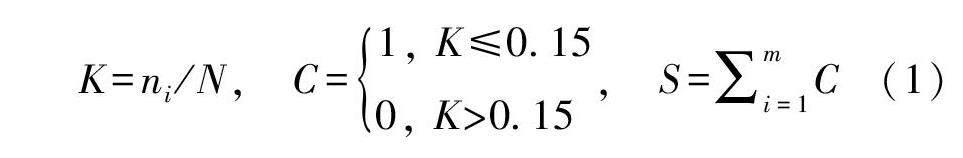
關鍵詞: 高價值專利; 技術創新演化; 知識圖譜; 腦機接口
DOI:10.3969 / j.issn.1008-0821.2024.06.001
〔中圖分類號〕G255 53 〔文獻標識碼〕A 〔文章編號〕1008-0821 (2024) 06-0003-15
隨著新一輪科技革命的加速推進, 科技創新已經成為影響國家競爭力和世界發展格局的關鍵變量。
黨的二十大報告強調, 要加快實施創新驅動發展戰略, 集聚力量進行原創性引領性科技攻關, 堅決打贏關鍵核心技術攻堅戰[1] 。攻克關鍵核心技術領域難題, 首先需要把握技術的演進特征和發展規律[2] 。鑒于高價值性是關鍵核心技術的主要特征[3] , 而專利又是科技創新的重要載體, 精準識別高價值專利,分析技術創新演化態勢, 對國家科技戰略布局、科技機構和企業的創新發展規劃, 以及科研人員理解技術核心要素并發現創新規律和創新機會具有重要意義。
“ 十四五” 規劃中首次將“每萬人口高價值發明專利擁有量” 納入經濟社會發展的主要指標[4] ,培育高價值專利、提升創新質量越來越成為國家科技創新體系的重要一環。目前, 對高價值專利的研究主要集中在高價值專利的識別、價值評估、專利挖掘以及技術擴散分析等方面, 少有針對高價值專利的技術創新演化研究, 較多的是在不區分專利價值高低的基礎上對專利技術的演化分析, 用于技術預測、優勢技術或顛覆性技術識別。從方法上看,多從技術主題視角, 采用文本挖掘和社會網絡分析法實現。然而, 專利尤其是高價值專利的技術創新價值體現在多個維度, 蘊藏在包含復雜語義關系的專利文本內容中。若要對技術研判或未來技術研發提供更具體、明確的落點, 就需要對專利文本進行更加細粒度的揭示, 進而從多維度、多視角挖掘高價值專利的技術演化規律。據此, 本研究擬解決的科學問題是如何挖掘一個領域內高價值專利的多面的、細粒度的、具體的技術創新點并發現其演化規律, 從而為科技創新主體提供多維和具體的參考?具體包括3 個子研究問題: 一是如何設計一套新穎且合理的指標體系來評估和識別高價值專利? 二是如何提取高價值專利文本中的細粒度技術要素并對其進行語義化組織, 以便從多維視角理解專利技術的本質和特征? 三是如何基于多維技術要素及其關聯關系, 從更加細微且多面而非僅僅是粗淺的主題角度來分析高價值專利的技術創新演化現象?
為解決以上問題, 本研究將以“腦機接口” 領域為例, 從優化部分指標測算方法及指標組合的角度設計能夠反映技術價值、專利權利和市場前景的指標體系以識別高價值專利, 并利用知識圖譜對高價值專利進行細粒度的技術要素提取和關聯關系揭示, 在此基礎上從多角度分析技術創新演化的趨勢,旨在促進關鍵技術領域的創新發展。
1 相關研究
1.1 高價值專利識別相關研究
現有研究多從技術、法律和市場3 個角度評估專利價值以識別高價值專利, 具體包括單一維度的縱深化評估和多維度的綜合評估。比如根據TRIZ的功能分析, 從技術價值視角識別高價值專利[5] ;或者基于技術的轉移轉化對專利價值進行評估[6] ;但更多的是構建高價值專利識別的多維指標體系,如, 付振康等[7] 綜合了能夠反映技術價值的技術生命周期、引證數等指標, 反映法律維度的權利要求數、審查周期等指標, 以及反映市場價值的PCT申請等指標篩選高價值專利。宋凱等[8] 從保護范圍、研發水平、市場前景和主體特征4 個維度構建了一套專利價值評估的指標體系。從高價值專利識別的方法來看, 常見的有基于指標權重的綜合評價法, 如層次分析法和熵權法的結合[9] 、多目標決策分析中的TOPSIS 方法[10] 以及Critic 賦權法的應用[11] 。近年來, 較多研究使用機器學習和深度學習的方法, 將高價值專利識別問題轉化為分類問題。王思培等[12] 基于隨機森林算法, 將反映專利價值的多維指標作為輸入變量, 高價值專利類別作為分類變量, 構建潛在高價值專利的預測模型。Liu WD 等[13] 提出了基于多任務學習的高價值專利識別模型。Woo H 等[14] 采用貝葉斯結構方程模型, 從技術性、權利性和可用性3 個維度對專利價值進行評估建模和分類識別。此外, 還有研究將綜合評價法與機器學習方法結合識別高價值專利, 如基于機器學習改進的AHPSort Ⅱ方法[15] 。
1.2 基于專利分析的技術創新演化相關研究
基于專利的技術創新演化研究主要集中在兩個方面, 一是技術主題的演化分析; 二是技術創新網絡的演化分析。關于技術主題創新演化, 較多學者采用主題識別、機器學習的方法進行分析。如基于Word2Vec 詞向量模型和LDA 主題模型的干細胞治療技術在“科學發現—技術創新—技術應用” 全生命周期的演化脈絡與特征研究[16] ; 基于專利數據,引入技術主題時序共現網絡和主題引用網絡的技術主題演化趨勢分析[17] ; 利用專利摘要, 結合LDA和隱馬爾科夫模型分析3D 打印技術主題的分布和演化模式[18] ; 以及融合SAO 三元組抽取、主題識別與相似度計算分析石墨烯超級電容器領域技術主題的創新演化路徑[19] 等。關于技術創新網絡的演化, 現有研究多利用網絡分析法, 對基于專利的技術創新合作網絡或引文網絡的演化路徑進行探索。如HsuC W 等[20] 基于專利引用關系所產生的社會網絡來討論生物質發酵產氫技術的演化; 束超慧等[21] 以專利申請人作為網絡節點構建顛覆性技術創新網絡, 從而分析了智能語音技術專利合作創新網絡的演化過程。趙靚等[22] 利用基于專利分類代碼構建的專利共現網絡分析了軍事智能技術演化趨勢。
1.3 基于科技文獻的知識圖譜構建與應用研究
知識圖譜是谷歌在2012 年提出的概念, 本質是一種語義網絡, 被廣泛用于智能語義搜索、智能問答和信息推薦等領域。近年來, 諸多學者將其引入科技領域的知識組織和知識發現研究, 探索基于科技文獻(主要為專利、科技論文)的領域知識圖譜構建方法, 以及在此基礎上的技術創新識別與創新知識檢索、新興技術預測、技術推薦等現實應用。在面向科技文獻的知識圖譜構建中, 有研究基于數據增強方法構建了新能源汽車電池技術領域的知識圖譜[23] , 融合聯合抽取模型SpERT 以及關系抽取模型Aggcn 構建了綠色合作領域的專利知識圖譜[24] , 以及基于圖嵌入算法構建非全氟化質子交換膜領域專利知識圖譜等[25] 。在知識圖譜的應用中, 曹樹金等[26] 基于所構建的專利文獻創新知識圖譜分析了其在創新知識檢索及專利文獻創新點對比中的應用; Deng W W 等[27] 提出了一種在專利知識圖譜的基礎上對專利和公司進行加權圖分析的方法, 用于向企業推薦專利; Doerpinghaus J 等[28] 基于PubMed 數據庫中的生物醫學論文數據構建了大型的生物醫學領域知圖譜, 用于上下文挖掘、基于圖的知識查詢以及知識發現; 還有將所構建的知識圖譜用于產業新興技術預測[29] 、專利布局意圖挖掘中[25] 。此外, 也有研究構建了技術演化圖譜, 用于識別優勢專利的技術研發方向[30] 。
綜上所述, 現有研究已有相對成熟的高價值專利評估和篩選的方法, 然而測度技術價值的指標較少深入到專利文本的潛在語義層面, 尤其是不易測度的主題新穎度之類的指標。已有研究表明, 主題新穎性與專利質量[31] 及專利影響力[32-33] 有較大關系。因此, 本研究將重點聚焦于專利技術主題新穎性, 結合反映技術價值的其他指標, 以及專利權利和市場前景來識別高價值專利。鑒于已有的主題新穎度測度方法較多以專利技術出現時間遠近為依據,并未從主題本身考慮, 本研究將提出一種新的測度方法加以優化; 另一方面, 從專利文本內容層面開展的技術創新演化研究多從主題角度切入, 分析的粒度較粗, 維度較單一。而將知識圖譜用于科技文獻挖掘的相關研究為該問題的解決提供了新的思路和理論依據。基于此, 本文將結合知識圖譜的優勢,對高價值專利的技術演化趨勢進行更加具體和多角度的分析, 為科技創新的各類主體提供更明確的參考。
2 研究設計
2.1 研究思路
本研究總體思路如圖1 所示。主要分為4 個階段: 數據收集與預處理、高價值專利識別、高價值專利知識圖譜構建、高價值專利的技術創新演化分析。首先, 在數據集的選取上, 鑒于腦機接口是新一代人機交互和人機混合智能的關鍵核心技術, 被美國商務部列為14 項出口管制技術之一[34] 。因此, 本研究采集了“腦機接口” 領域的專利文獻作為樣本, 經過預處理后形成語料集; 其次, 在高價值專利識別過程中, 重點考慮技術主題的新穎性,借助KeyBERT 模型從專利標題和摘要中抽取關鍵詞, 采用一種新的方法設計主題新穎性測度的指標,該方法主要通過與申請年以前的專利技術進行對比,而非僅依據申請年遠近來判斷新穎性, 如此能夠評估在專利申請的當下所體現的價值, 以便識別出在技術發展的各個不同階段具有高新穎性的專利。與此同時, 結合技術維度的其他指標以及反映專利權利和市場前景的指標, 利用Critic 權重法綜合評估專利價值, 從而篩選出高價值專利。然后, 針對識別出的高價值專利構建知識圖譜, 具體包括實體及關系類型定義、數據標注、采用CasRel 聯合抽取模型進行訓練、利用訓練好的模型對未標注語料進行知識抽取、知識融合與消歧, 并利用Neo4j 圖數據庫實現知識圖譜的存儲與可視化; 最后, 基于所構建的知識圖譜進行技術創新演化分析, 分析的維度依據知識圖譜中所涉及的不同類型的實體及關系。
2.2專利價值評估指標設計與綜合評價
明確高價值專利的內涵是識別高價值專利的前提。對于高價值專利的內涵存在多種說法, 尚未形成統一的定義。國家知識產權局曾對高價值發明專利的范圍進行了說明[35] , 在此基礎上綜合學者們的不同觀點, 發現領域內普遍認為高價值專利應具有較高的技術創新性、較穩定的專利權利、較高的市場應用價值幾大特征[7,36-37] 。因此, 根據相關研究中所涉及的多種指標, 從中歸納出3 個重要維度作為本研究指標設計的基準, 即技術價值、專利權利和市場前景。技術維度的指標主要包括技術主題新穎性、技術覆蓋范圍和技術投入。關于技術新穎性有多種度量方法, 比如采用專利授權的時間度量,即時間越近新穎度越高[11,29] ; 也有以新詞的早期出現率低于15%作為度量依據; 以主題詞組合在專利申請年之前的所有專利中出現的頻次來度量技術新穎性[38] ; 以及通過與歷史主題的相似度計算進行度量[39] 等。可見, 技術新穎度大都反映在時間維度的對比中。鑒于關鍵詞是判斷文獻主題的重要依據[40] , 本研究設計兩個指標來反映技術主題的新穎性, 即關鍵詞早期出現率X1 與關鍵詞相似度X2。關鍵詞通過KeyBERT 從專利標題和摘要中抽取。X1 計算方法如式(1): 對于某一專利, 第i 個關鍵詞在其申請年之前出現的專利總數ni 與申請年之前所有專利總數N 的比值設為K, 參考Por?ter A L 等[41] 的經驗, 當K≤0 15 時認為該詞具有新穎性, 記為1, 該專利的總新穎度得分為所有關鍵詞新穎性計數的總和S。指標X2 的計算方式為:將抽取出的專利關鍵詞組合與申請年之前的每份專利的關鍵詞組合進行相似度計算, 按照相似度遞減排列, 獲得與該專利關鍵詞組合相似度最高的前15%個專利, 以其相似度得分的平均值作為X2 的值。根據付振康等[7] 和張彪等[11] 的研究, 技術覆蓋范圍可由IPC 小類的個數(X3)來反映, 技術投入可由發明人數量(X4)反映。綜合宋凱等[8] 和王思培等[37] 提出的專利價值評估指標, 專利權利維度主要由權利要求數(X5)來測度, 而市場前景維度則由簡單同族數量(X6)測度。
在對各項指標進行測度后, 采用Critic 賦權法確定指標權重。Critic 賦權法利用指標間的沖突性和信息量大小來確定指標權重值, 是一種利用數據自身的客觀屬性進行科學評價的方法。最后將專利價值得分降序排列, 選取高于平均值的專利作為高價值專利。
在構建了此套高價值專利識別的指標體系之后,為了驗證其合理性、科學性和適用性, 首先邀請科學評價領域的兩名專家對指標本身進行定性評估;其次, 由于本研究對評價指標的優化主要體現在專利技術主題新穎性的測度上, 為了驗證該方法相較于根據時間遠近評價的方法更為合理, 隨機選取了腦機接口領域若干篇專利文獻, 利用該方法計算反映主題新穎性的兩項指標值, 即上述的X1 和X2,結果發現有部分近些年(2020 年以后)申請的專利新穎性并不高, 如“基于腦機接口的設備控制方法、裝置XXX” “一種XXX 的半侵入式腦機接口模塊”。經領域專家判斷這些專利技術的新穎性的確相對較低, 若僅用時間遠近判斷并不合理, 由此也驗證了本研究所提方法的優越性; 最后, 將所設計的整套指標體系分別用于腦機接口和教育機器人領域的高價值專利識別, 并由各自領域的專家對篩選出的高價值專利文獻進行了評估, 結果較好。
2.3 高價值專利知識圖譜構建
以高價值專利的摘要作為知識圖譜構建的語料。首先, 需要對摘要文本進行分析, 歸納出實體及關系類型。此過程主要依據已有研究中關于專利特征的總結以及專利摘要構成要素的概括, 并根據特定領域專利文獻自身的特點進行設計; 其次, 知識圖譜構建最重要的就是知識抽取環節, 針對非結構化文本的知識抽取一般涉及實體識別與關系抽取。本研究將采用CasRel 聯合抽取模型同時進行以上兩種抽取任務。CasRel 聯合抽取模型是吉林大學人工智能學院的Wei Z P 等[42] 提出的模型, 主要解決三元組重疊的問題, 即一個句子中的多個三元組共用同一實體。該模型的本質是基于參數共享的聯合實體關系抽取方法, 一般又被稱為層疊指針網絡。模型架構如圖2 所示, 包括編碼端和解碼端, 其中編碼端是基于BERT 的編碼層, 解碼端包括頭實體識別層和關系與尾實體聯合識別層。在進行實體關系聯合抽取時主要涉及兩個步驟: 一是對句子中所有可能的主語進行識別; 二是在每個關系類別下再去抽取與主語(即頭實體)對應的尾實體。鑒于本研究所涉及的專利文本涵蓋復雜的語義關系, 存在較多三元組重疊的問題, 選用CasRel 聯合抽取模型較為合適。確定采用的知識抽取模型之后, 對專利摘要進行分句, 提取部分語料進行人工標注與訓練, 并利用訓練好的模型對未標注的語料進行三元組抽取。在完成知識抽取工作以后, 參照領域專業詞典進行實體對齊、消歧與知識融合。最后, 利用Python 中的Pandas、Py2neo 等工具包將所有的實體關系數據導入至Neo4j 圖數據庫中, 形成高價值專利知識圖譜。
2.4 高價值專利的技術創新演化分析
高價值專利的技術創新演化分析基于所構建的知識圖譜。首先需要確定技術創新演化分析的維度,鑒于知識圖譜對高價值專利進行了更加細粒度的揭示, 涵蓋技術的多個方面(如應用領域、性能優勢、方法基礎等)。因此, 技術創新演化分析的維度可根據知識圖譜中涉及的各個實體及關系類型確定,同時也可涉及粗粒度的主題分析; 其次, 在每個分析維度下, 提取不同時間段的高價值專利文本子圖,總結每個階段的技術創新特征。進而揭示隨著時間推移, 在技術創新的各個維度上, 哪些內容逐漸縮減, 哪些內容被持續關注, 以及某個時間段新出現的內容有哪些, 以便更加具體地反映高價值專利的技術創新演化態勢。基于知識圖譜而非簡單的技術實體識別來開展技術創新演化分析的優勢在于: 專利摘要中的技術實體所屬類型依關系而定, 如一個系統設備或器件可能是專利本身也可能是專利的組件, 一種方法可能是發明專利本身也可能是專利所依賴的技術, 抽取三元組而非單個實體有助于明確區分這些技術實體。此外, 知識圖譜還可用于考察具有關聯關系的技術組合的演化現象。
3 實證研究
3.1 數據采集與預處理
選取“腦機接口” 領域的專利文獻作為分析樣本, 以incoPat 全球專利數據庫作為數據源。首先,參考已有相關研究制定檢索策略: TIABC=(腦機接口OR 腦-機接口OR 腦機交互OR 腦-機交互OR神經控制接口OR 直接神經接口) OR ((“braincomputer” OR “ brain - computer” OR “ brain ma?chine” OR “brain-machine” OR “neural control” OR“mind machine” OR “direct neural”) AND (inter?face? OR communicat?)), 專利類型限定為發明專利和實用新型專利, 檢索日期為2023 年5 月3 日,共獲得相關專利文獻4 060篇。之后將本研究所需的專利題名、摘要、IPC 分類號、申請日、權利要求數、公開號等字段信息導出作為初始語料集。在數據預處理階段, 對數據進行清洗和去噪, 去除重復專利。少數專利的摘要字段缺失, 對此采用簡單同族專利的摘要替代, 并利用翻譯軟件對部分僅有外文摘要的專利進行處理, 統一為中文摘要。經過預處理之后共獲得3 927篇專利文獻, 以此作為最終的語料集。
形成語料集后, 因分詞處理需要加載專業領域詞典, 但目前并沒有“腦機接口” 領域的專門詞典。“腦機接口” 具有交叉學科研究的特性, 涉及生物醫學工程、電子、材料、信息技術等多個學科。因此, 本研究獲取了“腦機接口” 研究論文中的關鍵詞, 結合神經病學、人工智能以及微電子等領域的現有詞典, 人工構建了“腦機接口” 領域詞典,共包括5 586個詞。
3.2 “腦機接口”領域高價值專利識別
3.2.1 技術主題新穎性指標測度
根據本研究設計的高價值專利評估指標體系,專利技術主題新穎性需要計算關鍵詞的早期出現率與關鍵詞相似度。由于專利文本缺少作者標注的關鍵詞集, 本文采用KeyBERT 模型從標題和摘要中進行提取。KeyBERT 是一種易用的關鍵詞提取模型, 原理是利用BERT 嵌入來創建與文檔最為相似的關鍵短語。在關鍵詞提取過程中, 將專利的標題和摘要拼接為TIAB 字段, 利用加載了自定義詞典的Jieba 進行分詞處理, 詞嵌入模型選擇“para?phrase-multilingual-MiniLM-L12-v2”, 超參數設置為use_mmr=True, diversity=0 4, top_n= 6, 即每個專利抽取6 個關鍵詞, 抽取結果示例如表1。提取關鍵詞之后, 按照式(1) 計算指標X1(關鍵詞早期出現頻率)的得分值。指標X2 采用余弦相似度計算, 詞向量模型同上。需要特別說明的是, 本研究對技術主題新穎性的度量是與先前專利對比實現的, 而獲取的專利數據集最早年份為1986 年,最早的專利沒有對比項, 鑒于2003 年以前的專利數不足30 篇, 因此在進行專利價值評估時僅計算2003年以后的專利。
3.2.2 專利價值綜合評估
除技術主題新穎性指標以外, 技術覆蓋范圍、技術投入、專利權利和市場前景維度的指標均可從incoPat 數據庫中直接獲取。之后, 利用Critic 賦權法對6 類指標進行加權, 在計算綜合得分時采用百分制。表2 呈現了部分專利6 個指標的初始分值和專利價值的綜合得分。按照綜合得分值降序排列,篩選出高于平均值的專利, 即高價值專利共2 500個。
3.3 “腦機接口”領域高價值專利知識圖譜構建
3.3.1 確定實體及關系類型
有研究總結了專利摘要包括的一般內容, 主要有技術的新穎性、技術功效、用途、詳細描述等,涉及對技術結構、應用領域、性能提升情況、關鍵組成部件等技術特征的概括說明[43-44] 。本研究以此作為依據, 結合“腦機接口” 領域專利摘要中涉及的專業術語及語義關系對需要抽取的實體與關系類型進行定義, 考慮到后續技術創新演化分析需要時間要素, 因此將專利申請年作為了實體類型之一。共歸納出12 類實體和12 類關系, 具體如表3 所示。這些實體及關系類型是“腦機接口” 領域的專利摘要中普遍存在的, 而非所有的。
3.3.2 數據標注與知識抽取
訓練CasRel 深度學習模型需要先對原始的部分數據進行標注, 利用訓練好的模型抽取未標注數據中的實體及關系。本研究在識別出2 500篇高價值專利之后, 對其摘要進行分句, 清洗重復句后共獲得28 900多條句子。從中選取2 000條數據進行人工標注, 標注工作由1 名情報學博士生和1 名醫學信息學博士生完成, 之后邀請領域專家核對。需要特殊說明的是, 實體關系類型“專利本身—申請于—申請年” 不需要預先標注和抽取, 因為申請年字段可從專利數據庫中直接導出。最后, 人工標注的數據以Json 格式存儲, 具體如表4 所示。
模型訓練的實驗環境配置為: 在Google Colab平臺上配置Torch2 0 1+cu118、Tensorflow4 18 0、fastNLP0 7、Python3 10 環境。訓練時, 將標注好的數據以6 ∶2 ∶2 的比例劃分為訓練集、驗證集和測試集, 實驗參數設置為: max_epoch = 50、batch_size=4、learning_rate= 1e-5、max_len = 200。模型訓練的最優結果為F1 值達到0 81、準確率為0 81、召回率為0 80。最后, 用訓練好的模型抽取未標注的句子中的三元組, 并進行人工校對。
3.3.3 知識融合與存儲
利用CasRel 深度學習模型抽取完三元組之后,需要對實體進行對齊, 參考專業詞典將同一實體的多種表述(如“EEG 信號” 與“腦電信號”)進行統一。基于表3 定義的實體關系類型, 共獲得10 358個三元組。之后, 將融合后的三元組存儲到Neo4j圖數據庫中。需要特殊說明的是, “專利本身” 這個類型的實體指代的是整個專利, 從句子中抽取三元組時, 該實體一般為“本發明” “本申請” “本實用新型” 等。如果直接導入圖數據庫會導致無法區分每個專利, 如果用標題和摘要作為節點內容過長, 因此這里采用序號指代不同的專利。圖3 是所構建的高價值專利知識圖譜的局部示意圖。
3.4 “腦機接口”領域高價值專利的技術創新演化
本研究識別出的“腦機接口” 領域高價值專利的申請年分布在2003—2023 年。腦機接口技術形成于20 世紀70 年代, 1999 年和2002 年兩次BCI 國際會議為腦機接口技術的發展指明了方向。2000 年以后腦機接口進入技術爆發階段, 21 世紀前十年發展成為一個研究領域, 涌現出多種新型的腦機接口實驗范式。2010 年以后腦機接口研究的規模急劇擴大并滲透至其他領域[45] 。2016 年該領域又取得了幾項重大突破, 出現了第一個有觸覺的可靈活控制機械手臂的人腦控機器人[46] , 癱瘓患者用BCI+VR 實現行走[47] , 腦機接口技術迎來新的發展高潮。根據其發展歷程及關鍵轉折點, 在技術創新演化分析時劃分為3 個階段, 分別是2003—2009年、2010—2016 年、2017—2023 年。技術創新演化分析的維度從粗粒度到細粒度, 包括主題維度、專利本質維度、應用領域維度、方法/ 技術維度、解決問題維度以及其他維度(性能優勢、硬件(組件)維度等)。
3.4.1 “腦機接口” 領域高價值專利的“技術主題” 創新演化
在構建的“腦機接口” 領域高價值專利知識圖譜中, 序號指代的是專利本身。針對專利本身可以先從粗粒度的技術主題角度分析演化趨勢。本研究利用Bertopic 主題模型, 基于高價值專利的標題和摘要對3 個時間段的專利主題進行識別, 并利用余弦相似度計算相鄰時間段的主題間的相似度, 繪制技術主題演化的桑基圖, 如圖4 所示。該圖中,相鄰主題間連線越粗, 主題相似度越高。從圖中可以看出, 隨著時間的推移“腦機接口” 領域的技術主題越來越多樣化。而關于“腦機接口改進與優化” “腦電信號處理方法” “腦機接口在輔助運動與康復中的應用” “用戶神經狀態監測” 等的研發始終是領域關注的重點。在2010 年以前腦機接口領域重點關注基礎原理以及技術框架研究, 集中于腦機接口裝置和腦波信號基本處理技術等主題。2010—2016 年間, 技術研究更加深入并逐漸開始涉及臨床應用, 腦機接口系統優化、腦機接口技術在診療與康復干預中的應用, 以及對多類腦電信號的深度處理等主題成為重點。2017 年以來, 人工智能、虛擬現實、增強現實等技術的發展為腦機接口技術的進步注入了新的動能, 基于機器學習、智能算法、無人機、VR 等的腦機接口技術研發、實際應用與產業化等相關主題的研究激增, 主題更加多樣化并呈現跨領域特性, 如腦機接口與無人機設備的結合、腦信號用于認知任務等。
3.4.2 “腦機接口” 領域高價值專利的“專利本質” 創新演化
本研究中的“專利本質” 是指專利的實質,具體體現為系統、方法或裝置。該維度的技術創新演化分析主要是為了了解在不同階段“腦機接口”領域研發的重點對象是什么, 隨著時間推移呈現何種發展態勢。分析過程中, 利用neo4j 的查詢語言進行條件查詢。比如, 構建查詢語句: match(n:‘專利序號) -[r:‘申請于] ->(p:‘申請年),(n)-[s:‘是] ->(m:‘系統/ 方法/ 裝置) wherep.name = ‘2010 or p.name = ‘2011 or p.name =‘2012 or p.name=‘2013 or p.name=‘2014 or p.name=‘2015 or p.name=‘2016 return n,s,m, 可獲取第二個階段專利本質的實體及關系, 圖5 為局部示意圖。
在知識圖譜中檢索3 個階段的“系統/ 方法/裝置” 類型的實體之后, 分別進行人工歸納, 總結出每個時間段主要的“專利本質”, 演化路線如圖6 所示。從圖6 可以看出, 2010 年以前“腦機接口” 領域的研發重點是腦機接口的裝置、控制系統與方法、腦波信號檢測和處理的系統與方法;隨著各項技術的發展, 研發對象趨向多樣化和細分化, 腦機接口系統的類型逐漸增多, 且不僅局限于腦機接口系統本身的開發, 還涉及應用腦機接口技術的各領域系統的研發, 如智能家居的控制系統。近年來, “腦機接口” 領域的研發對象更是拓展至無人機模擬訓練系統、車輛控制方法和系統等。從方法研究來看, 早期注重對腦機接口控制和實現方法的探索, 之后越來越側重于腦機接口的應用與優化方法。
3.4.3 “腦機接口” 領域高價值專利的“應用領域” 創新演化
基于所構建的知識圖譜, 可通過條件查詢分別獲取3 個階段的“專利本身—應用于—應用領域”三元組。比如, 構建查詢: match(n:‘專利序號)-[r:‘申請于] ->(p:‘申請年),(n) -[s:‘應用于]->(m:‘應用領域) where p.name=‘2017 orp.name = ‘2018 or p.name = ‘2019 or p.name =‘2020 or p.name=‘2021 or p.name=‘2022 or p.name=‘2023 return n,s,m, 返回結果(局部)如圖7所示。
在獲取3 個階段“應用領域” 類型的實體之后, 分別進行分類、歸納, 總結出每個時間段腦機接口技術的主要應用領域, 結果如表5 所示。
從表5 可以看出, “腦機接口” 技術的應用范圍不斷擴大, 從前期主要用于醫療領域的患者狀態檢測、康復訓練、輔助交流, 到中期用于外部設備控制、娛樂和輔助睡眠、交通領域等生活場景中,再到近年來延伸至航空航天模擬訓練、教育、科研、AR/ VR 設備應用等更廣泛的領域中。說明“腦機接口” 作為前沿科技交叉融合領域, 應用前景非常廣闊。
3.4.4 “腦機接口” 領域高價值專利其他維度的創新演化
將“腦機接口” 領域高價值專利在“方法/技術” “解決問題” “性能/優勢” “組件” 等維度的技術創新演化總結為圖8。從“方法/技術” 維度來看, 主要呈現“傳統生物信號處理方法—機器學習方法與虛擬現實技術—深度學習方法與增強現實及混合現實技術” 的發展趨勢; 從“方法/ 技術—處理—生物信號” 關系類型來看, 隨著技術方法種類的增多和智能化, 所處理的生物信號更加精細和多樣, 如瞬態EEG 信號、多通道運動想象腦電信號、腦電肌電雙模態信號等; 從“解決問題” 維度來看, 前期較為關注功能性問題, 到后來重視技術問題、效果和效率問題, 而近年來“人機交互體驗” 問題逐漸成為重點; 從“性能/ 優勢” 維度來看, 簡單、可靠、方便使用一直是專利研發追求的目標, 中期開始從使用者角度改進腦機接口的性能(比如減少受試者疲勞), 近年來又逐漸兼顧醫護人員的體驗, 以及除了功能和操作性能以外的趣味性, 逐漸體現人文關懷的特點; 從組件構成來看,設備更加多樣化、便攜化, 除了腦電采集設備以外,越來越多地涉及一些外控外聯設備。
4 研究結論
本研究以“腦機接口” 領域的專利文獻為例,構建了反映專利價值的多維指標體系以識別高價值專利, 進而構建“腦機接口” 領域的高價值專利知識圖譜, 在此基礎上從技術主題、本質、應用領域、方法、解決問題、性能優勢、組件等維度分析了技術創新演化態勢。研究主要得出以下結論:
設計的高價值專利篩選指標具有側重性與合理性, 通過實證檢驗與專家評價驗證了技術新穎性指標計算方法的優越性以及整套評價指標體系的可用性, 使后續的高價值專利技術創新演化分析具有可靠性。
知識圖譜能夠深度、直觀、細粒度地揭示專利文獻中的技術特征, 從而為技術創新演化分析提供了更多維的視角, 使得分析的層次更加深入, 有助于為研發者、政策制定者、科技戰略制定者提供更具體的參考。
基于研究結論, 本文提出以下建議: 在現有的專利數據庫中, 參考本研究設計的高價值專利評估體系及知識圖譜構建方法, 嵌入高價值專利自動識別、知識問答和創新情報推送的功能模塊。一方面,提供基于知識圖譜的智能檢索或問答服務, 根據用戶需求為其返回各個時期特定領域的高價值專利;另一方面, 基于知識圖譜為用戶提供多維度的技術創新演化、專利技術的對比分析、創新情報咨詢等各項服務。
本文的創新之處與研究貢獻主要體現如下: 首先在高價值專利識別的指標設計中, 提出了一種測度專利技術主題新穎性的新方法, 并與反映專利市場價值和法律價值的其他指標進行組合, 形成了多維度的評估指標體系; 其次, 利用知識圖譜提供了更加精細的、多點的、具體的專利技術創新演化分析視角, 而非局限于粗粒度的主題分析, 能夠為研究者提供更加豐富的參考。本研究存在的不足主要體現在: 用于識別高價值專利的指標仍有補充的空間, 并且僅采用了一個領域的專利文獻進行實驗,數據的范圍和規模都有待擴展。未來將進一步豐富高價值專利篩選的指標體系, 選取更多領域、更大規模的數據進行分析, 使該方法具有更廣泛的適用性。
(責任編輯: 郭沫含)
