不同子詞處理方法對(duì)機(jī)器翻譯的影響研究
2024-06-16 12:58:55唐超超擁措仁青卓瑪
電腦知識(shí)與技術(shù) 2024年12期
唐超超 擁措 仁青卓瑪

關(guān)鍵詞:低資源;機(jī)器翻譯;藏語(yǔ);Transformer;子詞
0 前言
機(jī)器翻譯(MT) 是將一種語(yǔ)言文本轉(zhuǎn)換為另一種語(yǔ)言的技術(shù)。在過(guò)去的幾十年里,機(jī)器翻譯的方法經(jīng)歷了從基于規(guī)則(RBMT) 到基于統(tǒng)計(jì)(SMT) [1],再到基于神經(jīng)網(wǎng)絡(luò)(NMT) [2]的演變。其中,NMT由于其簡(jiǎn)單的端到端架構(gòu)和強(qiáng)大的表示能力,已經(jīng)成為了當(dāng)前機(jī)器翻譯領(lǐng)域的主流方法,并在許多語(yǔ)言對(duì)上取得了顯著的性能提升。然而,如何有效地處理不同語(yǔ)言之間的詞匯差異和數(shù)據(jù)稀疏問(wèn)題仍是一個(gè)巨大的挑戰(zhàn)。據(jù)相關(guān)研究表明,可以使用多種子詞處理方式解決這個(gè)問(wèn)題,如subword-nmt[3]、sentencepiece[4]等方法。但不同的子詞處理方式可能對(duì)不同的語(yǔ)言和數(shù)據(jù)資源有著不同的適應(yīng)性和效果。因此,如何選擇合適的子詞處理方式對(duì)于提高NMT的性能是非常重要的。
由于漢-藏和漢-英屬于兩個(gè)不同的語(yǔ)系,具有不同的語(yǔ)法結(jié)構(gòu)、詞匯特點(diǎn)和文化背景,研究這兩個(gè)語(yǔ)言對(duì)之間的翻譯問(wèn)題能夠幫助我們更好地理解和解決跨語(yǔ)言翻譯的挑戰(zhàn)。因此,針對(duì)上述問(wèn)題,本文旨在漢-藏、漢-英兩個(gè)語(yǔ)言對(duì)上,使用Transformer模型探究在低資源[5]情況下三種子詞處理方式對(duì)翻譯模型性能的影響,并在不同的數(shù)據(jù)規(guī)模下進(jìn)行了實(shí)驗(yàn)。本文主要貢獻(xiàn)如下:
1) 首次探究了在漢-藏方向上不同的子詞處理方式對(duì)神經(jīng)機(jī)器翻譯(NMT) 性能的影響,并與漢-英方向進(jìn)行了對(duì)比,以尋找在這兩個(gè)語(yǔ)言方向上最有效的子詞處理策略。
2) 研究了在不同數(shù)據(jù)量的情況下,使用相同的子詞處理方式對(duì)翻譯模型的效果,從而了解不同數(shù)據(jù)量對(duì)NMT性能的影響,并驗(yàn)證在低資源情況下仍然可行的翻譯方法。
1 相關(guān)工作
集外詞[6]會(huì)降低機(jī)器翻譯的準(zhǔn)確性和流暢性,且在資源稀缺型語(yǔ)言的神經(jīng)機(jī)器翻譯中更加嚴(yán)重。因此,不管是在資源豐富還是資源稀缺的語(yǔ)言中,對(duì)子詞單元進(jìn)行建模已經(jīng)成為解決自然語(yǔ)言處理集外詞的一種比較流行的方法。其中,使用最多的子詞切分方式為字節(jié)對(duì)編碼(BPE) [7]。然而,不同的子詞處理方式在不同的語(yǔ)言上會(huì)產(chǎn)生不同的效果。2015年,Sen?nrich等[3]將BPE與char-bigram處理方式應(yīng)用到NMT 領(lǐng)域,結(jié)果表明英-俄數(shù)據(jù)語(yǔ)料為60k時(shí)char-bigram 效果最佳。2017年,Yang等人[8]對(duì)子詞處理的實(shí)驗(yàn)進(jìn)行了對(duì)比,發(fā)現(xiàn)做子詞處理可以提升模型的效果。2018年,Yang等人[9]使用subword處理方式,在weibo 數(shù)據(jù)集上F1 值最高。2020 年,Provilkov 等人[10]使用BPE以及BPE-dropout在多種語(yǔ)言對(duì)上進(jìn)行實(shí)驗(yàn),結(jié)果表明使用BPE-dropout的性能最好。因此,在特定語(yǔ)料對(duì)上探究合適的子詞處理方式對(duì)機(jī)器翻譯的有效性尤為重要。
在2018年,Kudo等[4]提出了一種新的子詞處理方式sentencepiece。與其他子詞處理方式不同,senten?cepiece可以直接從原始句子中進(jìn)行訓(xùn)練,而不依賴于特定語(yǔ)言的預(yù)處理或后處理步驟。這種新的處理方式集成了改進(jìn)后的字節(jié)對(duì)編碼BPE和unigram語(yǔ)言模型[11],從而在多個(gè)文本上取得了最佳效果。實(shí)驗(yàn)證明,該方法在多種語(yǔ)言對(duì)上的翻譯性能要優(yōu)于原始BPE方法。2020年,László János Laki等[12]使用字節(jié)對(duì)編碼的sentencepiece 對(duì)62 種語(yǔ)言進(jìn)行處理,發(fā)現(xiàn)在NMT-TM模型下的效果最好。2021年,Jonne Salev¨a 等人[13]使用四種子詞處理方式在四個(gè)語(yǔ)言對(duì)上進(jìn)行機(jī)器翻譯實(shí)驗(yàn),其中在低資源時(shí)使用sentencepiece僅在1個(gè)語(yǔ)言對(duì)的BLEU值達(dá)到最高,但隨著數(shù)據(jù)量的增加,翻譯性能也隨之提升。同年,Chanjun Park等人[14]使用了五種處理方式,其中sentencepiece性能僅次于該文作者提出的ONE-Piece效果。2022年,Xing?shan Zeng等人[15]發(fā)現(xiàn)使用sentencepiece在三個(gè)語(yǔ)言對(duì)上,BLEU值均為最高。然而,同年Jenalea Rajab[16]發(fā)現(xiàn)在四個(gè)語(yǔ)言上使用sentencepiece進(jìn)行處理,機(jī)器翻譯模型的性能在不同語(yǔ)言對(duì)上并不是隨著數(shù)據(jù)量的增加而增加。因此,探究sentencepiece在不同數(shù)據(jù)量下對(duì)機(jī)器翻譯模型性能的影響較為關(guān)鍵。本文還采用了subword-nmt 與sentencepiece 進(jìn)行對(duì)比實(shí)驗(yàn),以確定在漢藏語(yǔ)言對(duì)上是否適合sentencepiece 處理方式。
2 模型和方法
本文采用了Transformer模型作為基礎(chǔ)框架。該模型由Vaswani等人[17]于2017年提出,是一種基于自注意力機(jī)制的端到端的序列到序列的神經(jīng)網(wǎng)絡(luò)模型。它不需要使用循環(huán)神經(jīng)網(wǎng)絡(luò)或卷積神經(jīng)網(wǎng)絡(luò),而是完全依賴于自注意力機(jī)制來(lái)捕捉序列中的依賴關(guān)系。Transformer模型由編碼器和解碼器兩部分組成。編碼器由N層相同的子層組成,每個(gè)子層包含一個(gè)多頭自注意力機(jī)制和一個(gè)前饋神經(jīng)網(wǎng)絡(luò),以及殘差連接和層歸一化。解碼器也由N層相同的子層組成,每個(gè)子層除了包含編碼器中的組件外,還增加了一個(gè)掩蔽的多頭自注意力機(jī)制和一個(gè)編碼器-解碼器的自注意力機(jī)制,用于分別對(duì)目標(biāo)序列和源序列進(jìn)行注意力計(jì)算。Transformer模型在許多語(yǔ)言對(duì)上都取得了很好的翻譯性能,因此本文選擇它作為基礎(chǔ)框架。
在機(jī)器翻譯中使用BPE算法可以有效地處理未登錄詞和稀有詞等問(wèn)題。BPE算法首先將訓(xùn)練數(shù)據(jù)中的所有詞初始化為字符序列,并統(tǒng)計(jì)所有相鄰字符對(duì)出現(xiàn)的頻率。然后重復(fù)執(zhí)行以下操作,直到達(dá)到目標(biāo)子詞數(shù)量或者合并操作次數(shù):選擇出現(xiàn)頻率最高的相鄰字符對(duì),將其合并為一個(gè)新的子詞,并更新訓(xùn)練數(shù)據(jù)和字符對(duì)頻率。最后,根據(jù)得到的子詞集合,將詞匯表中的所有詞切分為子詞序列。為了更好地對(duì)比不同子詞處理下的BPE算法,在實(shí)驗(yàn)中分別采用了兩種方式:字節(jié)對(duì)編碼的sentencepiece 和subwordnmt。
2.1 subword-nmt
subword-nmt是由Sennrich等人[3]開(kāi)發(fā)的一個(gè)基于統(tǒng)計(jì)的子詞分割工具,它根據(jù)訓(xùn)練數(shù)據(jù)中的統(tǒng)計(jì)信息來(lái)切分詞匯表中的詞,主要用于神經(jīng)機(jī)器翻譯。subword-nmt需要對(duì)句子進(jìn)行分詞,然后根據(jù)訓(xùn)練數(shù)據(jù)中的統(tǒng)計(jì)信息來(lái)切分詞匯表中的詞。它需要指定一個(gè)合并操作的次數(shù)來(lái)控制子詞數(shù)量,從而有效地處理未登錄詞和稀有詞等問(wèn)題。
為了進(jìn)一步分析subword-nmt子詞處理方式在三種語(yǔ)言上的特點(diǎn)和差異,筆者對(duì)其進(jìn)行了示例分析,其處理后的語(yǔ)句對(duì)如表1所示。在表1中,首先對(duì)原始句子進(jìn)行詞處理,中文語(yǔ)料采用pkuseg分詞[18],英文語(yǔ)料采用nltk分詞[19],藏文語(yǔ)料使用tip-las分詞[20];然后再將處理后的句子進(jìn)行subword-nmt處理。
2.2 sentencepiece
為了探究適合漢藏以及漢英的子詞處理方式,本文采用了另一種基于學(xué)習(xí)的子詞處理方式sentence?piece與subword-nmt進(jìn)行對(duì)比分析。sentencepiece可以從訓(xùn)練數(shù)據(jù)中自行學(xué)習(xí)最為合適的子詞切分方式。它是由Google開(kāi)發(fā)的一個(gè)無(wú)監(jiān)督的文本分詞和反分詞工具,主要用于基于神經(jīng)網(wǎng)絡(luò)的文本生成系統(tǒng),如神經(jīng)機(jī)器翻譯。由于sentencepiece可以直接從原始句子中訓(xùn)練子詞模型,不需要預(yù)先對(duì)句子進(jìn)行分詞,并且實(shí)現(xiàn)了子詞正則化,如子詞采樣和BPE-dropout,從而提高了NMT模型的魯棒性和準(zhǔn)確性,因此在多個(gè)語(yǔ)言對(duì)上都取得了不錯(cuò)的效果。本文采用字節(jié)對(duì)編碼的sentencepiece對(duì)藏漢英三個(gè)語(yǔ)言對(duì)進(jìn)行處理,以分析其在不同語(yǔ)言上的特點(diǎn)。sentencepiece處理后的語(yǔ)句對(duì)如表2所示。
根據(jù)表2的數(shù)據(jù),可以觀察到sentencepiece在中英兩種語(yǔ)言上的子詞粒度明顯高于subword-nmt。這表明sentencepiece能夠更細(xì)致地劃分子詞單元,從而更好地覆蓋更多的語(yǔ)言現(xiàn)象和子詞組合,這也與其在漢英翻譯任務(wù)上表現(xiàn)優(yōu)異的結(jié)果一致。然而,在藏文上,sentencepiece的子詞粒度卻比subword-nmt低。這表明sentencepiece在處理藏文時(shí)可能無(wú)法很好地捕捉語(yǔ)言的復(fù)雜性和多樣性,可能導(dǎo)致一些重要的子詞被忽略或合并,進(jìn)而影響在漢藏翻譯上使用sentence?piece的效果。綜上所述,可以得出以下結(jié)論:senten?cepiece在中英兩種語(yǔ)言上具有較高的子詞粒度,但在藏文上具有較低的子詞粒度。
2.3 數(shù)據(jù)配置探究
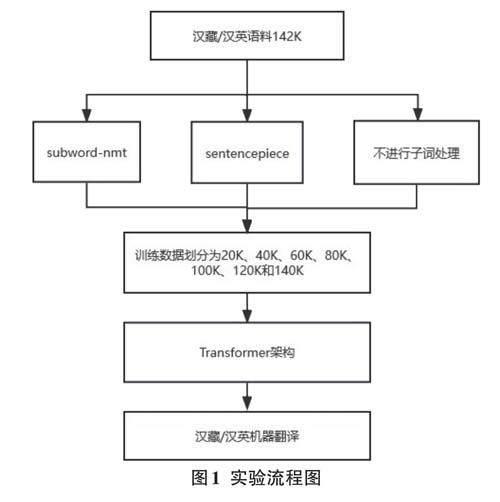
在低資源情況下,找到適合漢-藏和漢-英兩個(gè)語(yǔ)言對(duì)的最佳子詞處理方式對(duì)于機(jī)器翻譯模型的性能至關(guān)重要。因此,本文進(jìn)行了實(shí)驗(yàn),在漢-藏和漢-英兩個(gè)語(yǔ)言對(duì)上分別使用了不同數(shù)量級(jí)的平行語(yǔ)料作為訓(xùn)練數(shù)據(jù)。實(shí)驗(yàn)流程如圖1所示,訓(xùn)練數(shù)據(jù)被分為20K、40K、60K等不同規(guī)模,并以20K為幅度進(jìn)行增長(zhǎng),以更好地觀察在不同語(yǔ)言對(duì)和不同子詞處理方式下模型性能的變化,并從中選擇合適的數(shù)據(jù)規(guī)模和子詞處理方式。
3 實(shí)驗(yàn)與結(jié)果分析
3.1 數(shù)據(jù)集
本次實(shí)驗(yàn)的數(shù)據(jù)來(lái)源包括了第十八屆全國(guó)機(jī)器翻譯大會(huì)(CCMT 2021)提供的15萬(wàn)條藏漢平行語(yǔ)料和EMNLP 2020第五次會(huì)議機(jī)器翻譯(WMT20)新聞評(píng)論v15提供的15萬(wàn)條中英平行語(yǔ)料。經(jīng)過(guò)數(shù)據(jù)清洗和去重處理后,最終獲得了142 000條漢藏和142 000條漢英平行語(yǔ)料。接著,將這些數(shù)據(jù)對(duì)劃分為訓(xùn)練集、驗(yàn)證集和測(cè)試集。驗(yàn)證集和測(cè)試集在各種數(shù)據(jù)規(guī)模下保持固定,均包含1 000條句子,其余則用作訓(xùn)練集。為了研究不同數(shù)據(jù)配置下的效果,將數(shù)據(jù)集分成不同大小的配置,在每個(gè)配置中,模型在漢藏和漢英方向上進(jìn)行訓(xùn)練,直到驗(yàn)證集不再有進(jìn)一步改進(jìn)為止,即認(rèn)為達(dá)到了收斂狀態(tài)。最后,使用BLEU[21]指標(biāo)中的SacreBLEU[22]來(lái)評(píng)估模型性能。
3.2 實(shí)驗(yàn)設(shè)置
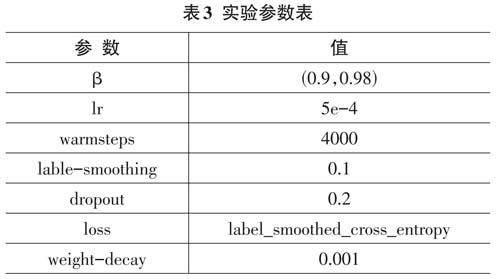
本文中使用Adam優(yōu)化器[23]進(jìn)行所有的NMT模型訓(xùn)練,并且所有的模型訓(xùn)練實(shí)驗(yàn)都在Fairseq框架上進(jìn)行。具體的參數(shù)設(shè)置如表3所示,其中warmsteps參考了Vaswani等人的參數(shù)設(shè)置,并采用了warm-up策略來(lái)動(dòng)態(tài)調(diào)整學(xué)習(xí)率的值。
3.3 結(jié)果分析
本文使用相同大小的數(shù)據(jù)比較了不同的子詞處理結(jié)果。一種是將數(shù)據(jù)以原始形式提供給模型,即沒(méi)有進(jìn)行子詞處理,與在訓(xùn)練之前進(jìn)行子詞處理的情況進(jìn)行比較。另一種情況是在不同語(yǔ)言對(duì)上進(jìn)行訓(xùn)練,即zh-bo與zh-en比較。第一種情況可以衡量子詞處理對(duì)翻譯質(zhì)量的影響,第二種情況可以觀察語(yǔ)言之間屬性的影響,這些屬性可以促進(jìn)或阻礙翻譯性能。為了評(píng)估三種子詞處理方式在不同語(yǔ)言對(duì)上的翻譯性能,本文在zh-bo和zh-en兩個(gè)方向上進(jìn)行了翻譯實(shí)驗(yàn),并在測(cè)試集上計(jì)算了BLEU分?jǐn)?shù),其實(shí)驗(yàn)結(jié)果如表4所示。
表4顯示了在zh-bo和zh-en方向上的翻譯結(jié)果,每種子詞處理方式都使用了相同的數(shù)據(jù)量和模型參數(shù)。從表4 中可以看出,在zh-bo 數(shù)據(jù)上,采用subword-nmt處理相比未使用子詞處理的情況,BLEU 值約增加了1.2點(diǎn)。這表明subword-nmt能夠更有效地處理漢藏之間的詞匯差異和數(shù)據(jù)稀疏問(wèn)題,因?yàn)樗軌蚋鶕?jù)數(shù)據(jù)特點(diǎn)自動(dòng)學(xué)習(xí)合適的子詞劃分方式,從而提高模型的泛化能力。然而,采用字節(jié)對(duì)編碼的sentencepiece的BLEU值比其他兩種方法要低得多,只有12.54點(diǎn)。這可能是因?yàn)椴卣Z(yǔ)數(shù)據(jù)比較稀疏、不均勻,而sentencepiece 是基于字節(jié)對(duì)頻率的劃分方式,可能導(dǎo)致一些重要的子詞被忽略或合并,因此sentencepiece在漢藏?cái)?shù)據(jù)上不能很好地捕捉到語(yǔ)言的復(fù)雜性和多樣性,即采用subword-nmt處理有利于提高漢藏翻譯性能。
針對(duì)表4中的zh-en數(shù)據(jù),采用字節(jié)對(duì)編碼的sen?tencepiece處理相比subword-nmt處理的BLEU值約增加了1.4點(diǎn),比未使用子詞處理的BLEU值高出4點(diǎn)。這表明sentencepiece能夠更好地適應(yīng)漢英翻譯任務(wù),因?yàn)樗軌蚋玫馗采w更多的語(yǔ)言現(xiàn)象和子詞組合,從而訓(xùn)練出更好的子詞模型。而采用subword-nmt處理相比未使用子詞處理的情況,BLEU值約增加了2 點(diǎn),這也說(shuō)明subword-nmt在漢英數(shù)據(jù)上有一定的效果,但不如sentencepiece。未使用子詞處理的BLEU 值最低,只有19.29點(diǎn),這可能是因?yàn)槲词褂米釉~處理會(huì)導(dǎo)致一些罕見(jiàn)或未登錄詞無(wú)法被模型正確處理,從而影響翻譯質(zhì)量。因此,可以得出結(jié)論,采用senten?cepiece處理有利于提高漢英翻譯性能。
4 總結(jié)
本文針對(duì)不同的子詞處理方式對(duì)不同的語(yǔ)言和數(shù)據(jù)資源有著不同的適應(yīng)性和效果這一問(wèn)題,總共探究了三種子詞處理方式:sentencepiece、subword-nmt 和未使用子詞處理。在不同數(shù)據(jù)量下,在漢-藏和漢- 英兩個(gè)語(yǔ)言對(duì)上進(jìn)行了翻譯實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果表明,sentencepiece在漢-英上的性能隨著數(shù)據(jù)量的增加而顯著提升,遠(yuǎn)超過(guò)其他兩種方式。而subword-nmt在漢-藏上的性能隨著數(shù)據(jù)量的增加而逐漸提升,最終超過(guò)sentencepiece和未使用子詞處理。未使用子詞處理在漢-藏上的性能在數(shù)據(jù)量較少時(shí)優(yōu)于其他兩種方式,但在數(shù)據(jù)量較多時(shí)則落后于subword-nmt。然而,本文沒(méi)有對(duì)使用BPE-dropout的模型進(jìn)行實(shí)驗(yàn),因此無(wú)法評(píng)估使用該方法是否可以改善翻譯性能的效果。在后續(xù)的工作中,將在相同的模型設(shè)置下應(yīng)用BPE-dropout,并觀察它是否能提高模型的效果。
