輔助喂食機器人可用于老人進食和兒童保育
2024-06-23 06:56:13
海外星云 2024年6期
關鍵詞:模型
近日,上海交通大學本科校友、美國馬里蘭大學博士生劉睿和所在團隊,提出了一種適用于機器人輔助喂食的視覺模仿學習方法。
該方法可以有效處理多樣化的碗配置和食物類型,即使存在干擾物的情況下也表現出良好的適應性和魯棒性。
通過在真實機器人上開展實驗,驗證了本次方法的有效性,模型的成功度量指標最高提高2.5倍。
通過此,他們展示了機器人輔助喂食領域的創新性進展,也展示了在模仿學習和視覺感知方面的應用,為機器人技術發展提供了新的參考。
作為一款輔助喂食型機器人,該機器人能應對不同的喂食場景,包括不同容器、不同大小,不同屬性的食物,并能滿足用戶的不同偏好。
同時, 它能被用于個人家庭、醫院、養老院等。預計機器人有潛力徹底改變輔助服務,包括幫人做家務、輔助喂食、復健等。

其預計將能實現以下三大場景:
其一,服務于具有特殊需求的群體。
對于身體殘障人士、老年人和行動不便人群,可以通過喂食機器人獲得自主性和獨立性
其二,服務于醫療應用的場景。
在醫院和康復中心,喂食機器人可以幫助醫護人員減輕工作負擔,提高患者的營養攝入。它可以精確控制食物分配,定時提醒患者進食,并記錄攝入量以供醫生評估。
其三,可用于兒童保育場景。
在托兒所和幼兒園,喂食機器人可以幫助保育員更有效地管理多個孩子的飲食,確保他們獲得充足的營養,同時降低過度依賴人工喂養的負擔。

超數百萬成年人需要援助才能實現獨立飲食
預計到2050年,60歲及以上的人口數量將增加一倍,全世界的醫療保健系統和社會服務必須適應人口老齡化。
隨著人口老齡化,老年人和殘疾人輔助喂食的需求變得越來越迫切。目前,有超數百萬成年人需要援助才能實現獨立飲食,這直接影響他們的自尊和生活質量。
不幸的是,由于醫護人員短缺和服務成本高昂,導致難以為所有有需要的人提供護理。
而輔助喂食機器人可以有效減輕醫療保健系統的壓力,特別是在醫護人員短缺的情況下。
目前,市面上已有的輔助喂食機器人,主要依賴于預編程的啟發式方法,無法處理具有不同質地、幾何形狀、變形特性的食物。
基于此,課題組打算開發一款新型輔助喂食機器人,他們希望該機器人能學習并適應各種不同的容器(碗、盤子)和不同的食物類型,最終改善需要輔助喂食的老年人和殘疾人的生活質量。
即使存在干擾物,仍能保持性能
在本次項目之中,該團隊的重點目標是實現輔助喂食功能。其中,裝有叉子或勺子的機械臂,可以叉取或舀取一部分的食物,并將其轉移到使用者的嘴中。
也就是說他們要開發一種機器人喂食系統,利用深度學習技術、并建立新穎的感知策略和學習策略,從而該系統可以處理多種食物,并能提供個性化幫助。
課題組希望實現的是:當機器人遇到看不見的食物時,可以利用人工智能工具(例如ChatGPT)來獲取先驗知識,并通過模仿學習或強化學習的方式,使其能夠實現成功喂食。
這是一種持續的學習過程,并且可以在機器人和食物之間進行轉移。
例如,如果機器人系統已經接受過西蘭花的訓練,但是沒有接受過花椰菜的訓練,那么考慮到這兩種食物在屬性上的相似之處,它就應該傳輸應對這兩種食物的知識。
這就需要整合感知(認識到盤子上的東西是花椰菜)、語義理解(認識到花椰菜和西蘭花具有相似的物理特征,因此學習可以遷移)、運動規劃(用叉子將花椰菜叉起來)。
與此同時,該團隊希望可以讓機器人從一小部分人類演示的數據中掌握控制策略,然后將知識轉移到之前沒有見過的食品上,從而避免收集大量人工數據帶來的成本。
研究中,如何獲取食物、如何檢測用戶位置、如何根據用戶的偏好和指令做出不同響應、如何安全地將食物轉移到使用者口中,都是該團隊要考慮的問題。
而在本次項目之中,他們更加關注如何獲取食物。因此,如何使機器人能從不同材質、不同大小、不同位置的碗中舀取,包括顆粒狀、半固態和液態在內的各種食物類型,并且即使在存在干擾物的情況下也能保持魯棒性和適應性,是課題組的主要研究目標。
為此,他們設計了一款名為自適應視覺模仿學習(AVIL)的框架,并開發了空間注意力模塊。
AVIL框架是一個綜合型智能控制系統,能用于實現輔助喂食機器人的自適應和智能化。
而空間注意力模塊,則是AVIL框架中的一個重要組成部分。它通過對環境進行感知和理解,實現對于碗和食物的精準識別和精準處理。
空間注意力模塊能以動態的方式,調整圖像中不同區域的比重,從而讓模型可以集中注意于感興趣的區域(即碗和食物的位置)。
這樣一來,模型就可以準確地舀取位于不同位置、不同大小的碗中食物,并且可以抵抗其他物體的干擾,從而提高模型的魯棒性。
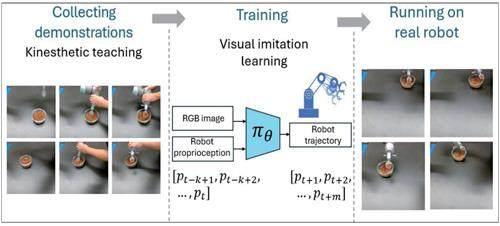
研究中,他們還采用了一種名為行為克隆的模仿學習算法,將輸入的RGB圖像和機器人的關節位置,映射到相應的機器人控制動作。
而在數據收集和模型訓練階段,課題組通過kinesthetic teaching(即人類操作員引導機器人模仿舀取動作)收集數據,并記錄RGB圖像和機器人關節位置,從而用于訓練模型。
上述這些數據包括機器人在不同環境下的操作過程、碗和食物的特征、以及人類專家的行為示范等。
完成數據收集之后,他們針對模型開展訓練,以便讓機器人運動軌跡和人類專家運動軌跡之間的誤差達到最小,從而讓機器人可以模仿人類專家的行為。
訓練過程中,他們不斷地調整網絡參數,以此來提高模型的準確性和魯棒性。
完成模型訓練之后,該團隊又在一款名為“UR5”的真實機器人上進行實驗,以驗證本次方法的有效性。
其間,他們測試了不同材質、不同大小、不同位置的碗,也測試了不同類型的食物包括顆粒狀谷物、半固態果凍和液態水。
為進一步驗證AVIL的有效性,課題組設計了一個Baseline的方法進行比較。
Baseline方法使用RetinaNet算法(一種深度學習檢測算法)來進行碗的檢測,并能計算碗的中心點,然后指導機器人移動到該位置進行舀取。
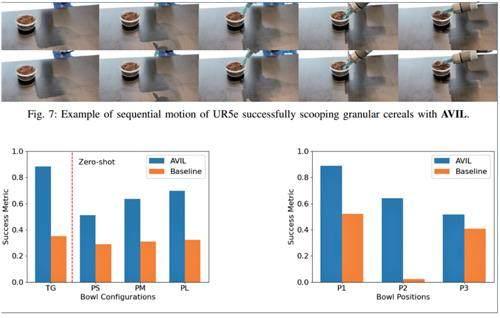
實驗結果表明:AVIL在不同碗配置、不同食物類型、不同碗位置的性能比較之中,都比Baseline表現更佳。
值得一提的是,即使在沒有直接訓練的情況下,即零樣本泛化情況之下,AVIL只在一個盛有顆粒狀谷物的透明玻璃碗的數據上接受了訓練,但它卻展示了針對不同大小的塑料碗、和不同食物類型的有效性能。
此外,他們還模擬了存在干擾物的情況,以此來測試本次模型的魯棒性和適應性。
結果發現:對干擾物AVIL同樣表現出較好的魯棒性,即使存在干擾物的情況下也能保持性能。
最終,相關論文以《機器人輔助喂養的自適應視覺模仿學習在不同的碗配置和食物類型》為題發表。
劉睿、阿米沙·巴斯卡、普拉塔普·托克卡爾是共同作者。
據介紹,本次研究僅僅關注于如何獲取食物。下一步,該團隊將研究如何將食物安全地送入使用者口中。
此外,其還計劃提升該系統的用戶友好度,以滿足不同用戶的偏好,并計劃通過合作方式,將視覺模仿網絡與其他類型的機器人加以集成,從而擴展其應用范圍。
此外, 課題組還將進一步優化本次模型,使其能夠處理更復雜的喂食場景。 (綜合整理報道)(策劃/萊西)
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19