基于改進YOLOv8 的無人機航拍圖像目標檢測算法
2024-07-17 00:00:00程換新喬慶元駱曉玲于沙家
無線電工程 2024年4期
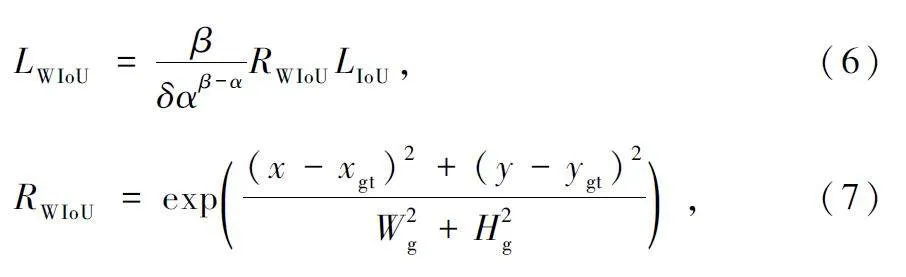

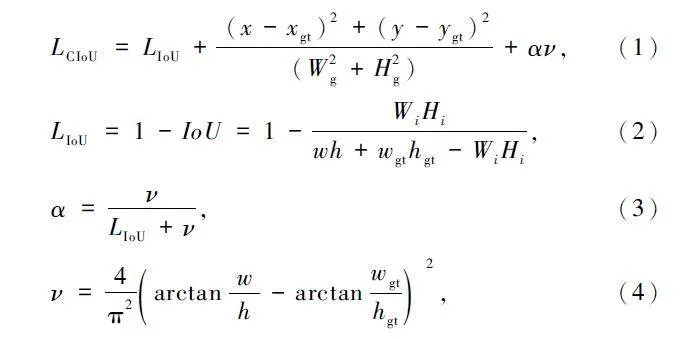
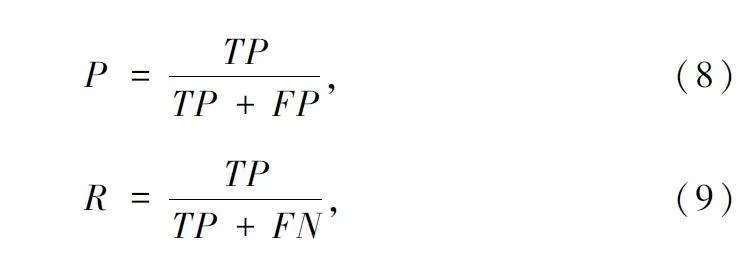


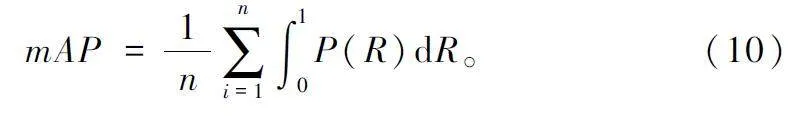


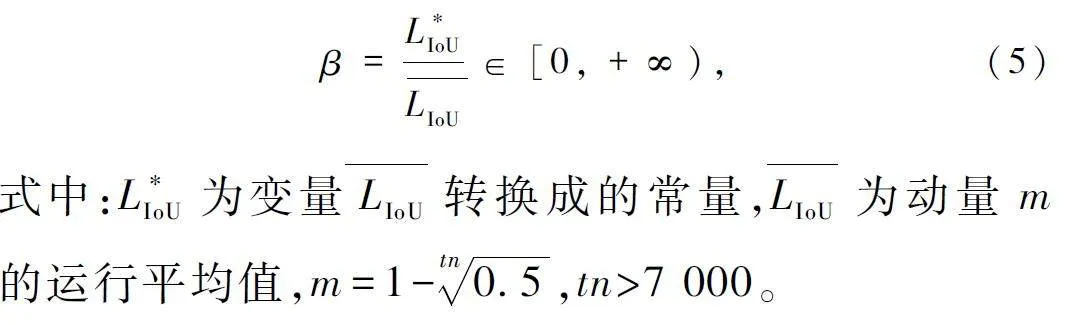
摘 要:針對現存無人機航拍圖像目標檢測算法檢測精度較低、模型較為復雜的問題,提出一種改進YOLOv8 的目標檢測算法。在骨干網絡引入多尺度注意力EMA,捕捉細節信息,以提高模型的特征提取能力;改進C2f 模塊,減小模型的計算量。提出了輕量級的BiYOLOv8 特征金字塔網絡結構改進YOLOv8 的頸部,增強了模型多尺度特征融合能力,改善網絡對小目標的檢測精度。使用WIoU Loss 優化原網絡損失函數,引入一種動態非單調聚焦機制,提高模型的泛化能力。在無人機航拍數據集VisDrone2019 上的實驗表明,提出算法的mAP50 為40. 7% ,較YOLOv8s 提升了1. 5% ,參數量降低了42% ,同時相比于其他先進的目標檢測算法在精度和速度上均有提升,證明了改進算法的有效性和先進性。
關鍵詞:航拍圖像;小目標檢測;YOLOv8;BiYOLOv8;輕量化
中圖分類號:TP391 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3106(2024)04-0871-11
0 引言
隨著無人機技術的蓬勃發展以及制造成本的降低,無人機憑借其機動靈活的特點,能夠飛越人類無法到達的地方,實現大范圍區域的監測,已廣泛應用于各行各業當中[1]。無人機航拍圖像目標檢測是無人機的一個重要應用,在民用和軍事領域發揮著重要作用,應用于測繪航測、應急救援、危險區域監測和識別易受災地區等諸多方面[2]。
目前,基于深度學習的目標檢測性能已經遠超傳統方法,根據有無候選框的生成,可以分為單階段的目標檢測(SSD[3]、YOLO 系列[4]和RetinaNet[5]等)及雙階段的目標檢測(RCNN 系列[6]等)。雖然單階段目標檢測的檢測精度略低于雙階段目標檢測,但其有著更快的檢測速度,便于部署到各項任務當中。
盡管基于深度學習的目標檢測已經具備了很好的效果,但其在無人機目標檢測中表現不佳。一方面是因為無人機航拍圖像不同于自然場景的圖像,具有大場景、多尺度、小目標、背景復雜和相互遮擋的特點,難以準確地識別目標[7];另一方面,無人機目標檢測任務對實時性和準確性有著很高的要求,而復雜的模型難以部署在無人機這樣的小型設備當中,輕量化的模型又難以提高準確度[8-9]。
為解決這些問題,國內外學者展開了一系列的研究。Liu 等[10]提出了一種基于SSD 的特征增強檢測算法,利用ResNet50 網絡的殘差結構來獲取更多的特征信息并融合到骨干網絡,保留更多的淺層特征,提升了對小目標的檢測能力。Wang 等[11]以RetinaNet 為基礎模型,優化其特征金字塔結構并引入注意力機制來關注目標信息。王殿偉等[12]提出一種改進Double-Head RCNN 的檢測算法,在骨干網絡引入Transformer 和可變形卷積,設計了基于內容感知特征重組的特征金字塔網絡結構,以模型變復雜為代價換取更高的精度。Demesquita 等[13]提出了一種完全卷積的Siamese 自動編碼器方法,用少量無人機航拍圖像作為訓練樣本就能取得不錯的效果。趙耘徹等[14]提出了改進YOLOv4 的檢測算法,用輕量級網絡MobileNetv3 作為特征提取網絡,深度可分離卷積替換3 ×3 常規卷積,簡化了模型,提升了檢測速度。Wang 等[15]提出了一種改進YOLOXX 的檢測算法YOLOX_w,用SAHI 算法進行數據增強以及引入淺層特征圖來提高對小目標的檢測能力,并加入新的檢測頭和超輕量子空間注意力模塊(ULSAM)使模型聚焦于關鍵特征,最后優化了邊界框回歸損失函數,雖然提升了檢測精度,但帶來了參數量變大、運行速度較慢的問題。
上述方法仍存在檢測精度較低、模型較為復雜的問題,不能滿足實時性和準確性的需求,于是本文提出了一種改進YOLOv8 的無人機航拍圖像目標檢測算法來解決這一問題,以下是該算法主要改進和創新:① 采用先提升精度再減輕模型參數的設計理念改進主干,可以在不影響速度的前提下提升精度;② 通過添加跨尺度連接方式和加權特征方法,設計了特征金字塔網絡結構,將深層語義和淺層定位信息進行多尺度特征融合,解決尺度差異大、特征丟失嚴重的問題;③ 用WIoU 替換CIoU,降低低質量樣本對模型的危害,提高了模型的泛化能力。
1 YOLOv8 算法原理
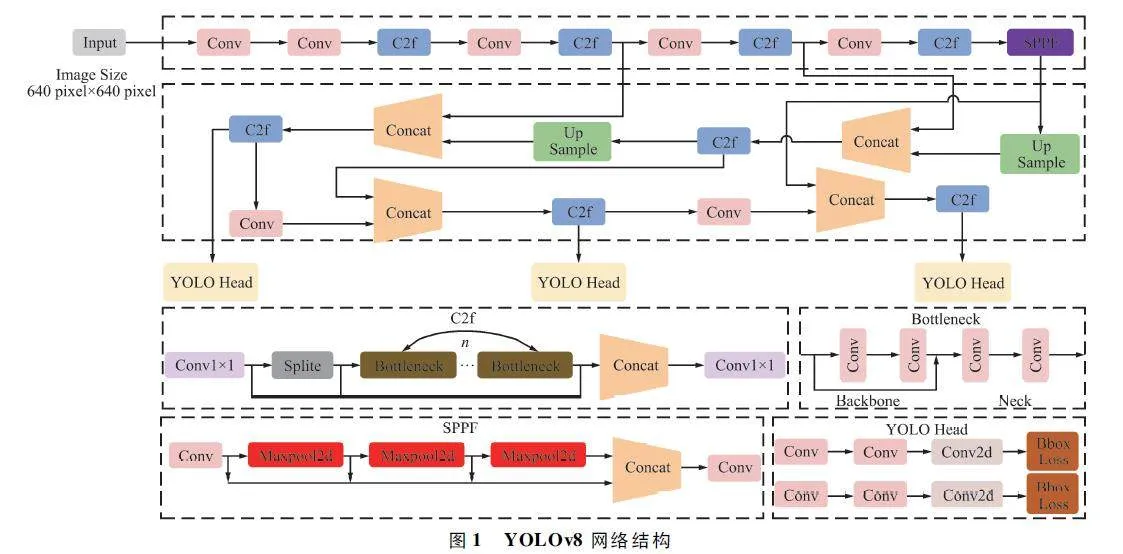
在各種目標檢測算法中,YOLO 系列因具備速度和準確度間的優異平衡脫穎而出,能夠準確、快速地識別目標,便于部署到各種移動設備中,已經廣泛應用于各種領域的目標檢測、跟蹤和分割。目前最新版本YOLOv8 由原v5 的開發團隊Ultralytics 于2023 年1 月提出,按規格大小可劃分為n、s、m、l、x五個版本,是目前最先進的目標檢測算法,有著優異的性能,很適合用于無人機航拍圖像目標檢測。其網絡結構如圖1 所示。
YOLOv8 模型包括Input、Backbone、Neck 和Head 四部分。其中Input 選用了Mosaic 數據增強方法,并且對于不同大小的模型,有部分超參數會進行修改,典型的如大模型會開啟MixUp 和CopyPaste數據增強,能夠豐富數據集,提升模型的泛化能力和魯棒性。Backbone 主要用于提取圖片中的信息,提供給Neck 和Head 使用,由多個Conv、C2f 模塊和尾部的SPPF 組成。Conv 模塊由單個Conv2d、BatchNorm2d 和激活函數構成,用于提取特征并整理特征圖。YOLOv8 參考了C3 模塊的殘差結構以及YOLOv7[16]的ELAN 思想,設計出了C2f 結構,可以在保證輕量化的同時獲得更加豐富的梯度流信息,并根據模型尺度來調整通道數,大幅提升了模型性能。SPPF 是空間金字塔池化,能夠融合不同尺度的特征。Neck 部分主要起特征融合的作用,充分利用了骨干網絡提取的特征,采用FPN[17]+ PAN[18]結構,能夠增強多個尺度上的語義表達和定位能力。Head 輸出端根據前兩部分處理得到的特征來獲取檢測目標的類別和位置信息,做出識別,換成了目前主流的解耦頭結構,將分類和檢測頭分離,解決了分類和定位關注側重點不同的問題,同時也采用了無錨框的目標檢測(AnchorFree),能夠提升檢測速度。Loss 計算方面采用了正負樣本動態分配策略,使用VFL Loss 作為分類損失,使用DFL Loss+CIoULoss 作為回歸損失。
2 改進的YOLOv8 網絡結構
2. 1 骨干網絡的改進
2. 1. 1 引入EMA 注意力模塊
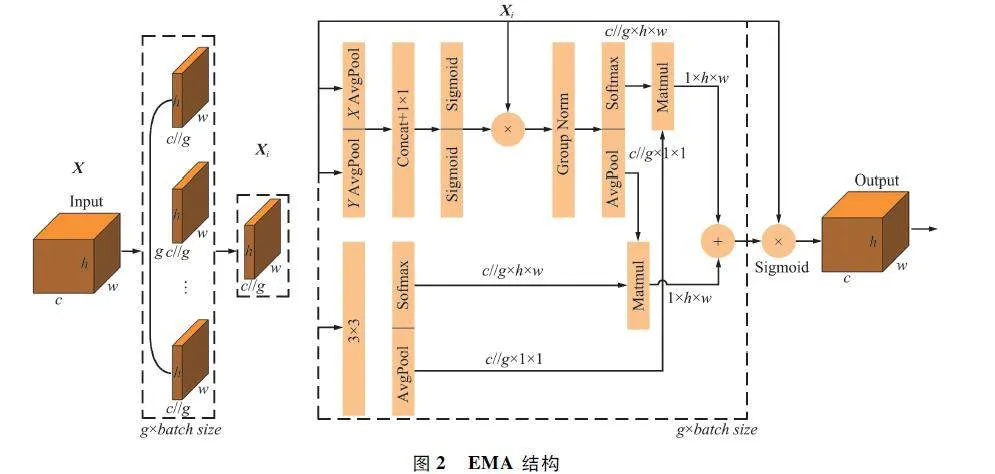
注意力機制能夠捕獲局部重要信息,使模型聚焦于檢測目標的相關特征,在各種計算機視覺任務當中發揮著重要作用。EMA[19]是一種高效多尺度注意力機制,將部分通道重塑為批量維度,避免了通道降維的情況,從而能夠保留每個通道的信息并降低計算成本。EMA 不僅對全局信息編碼來調整并行子網絡通道權重,還通過跨緯度交互融合2 個并行子網絡的輸出特征。EMA 總體結構如圖2所示。
對于輸入特征X∈RC×H×W ,EMA 按通道數將其劃分為G 個子特征,來學習不同的語義,輸入特征X = [X0 ,Xi,…,XG-1 ],Xi∈RC∥G×H×W 。在不損失一般性的前提下,令G-C,并假設學習到的權重描述符將用于增強每個子特征中感興趣區域的特征表示。
EMA 通過2 條在1×1 分支和1 條在3×3 分支上的平行路徑來提取分組特征圖的權重描述符,在1×1 分支中采用了2 個1D 全局平均池化操作沿著2 個空間方向對信道進行編碼,并將2 個編碼特征連接起來,使其不在1 ×1 分支上降維;再將1 ×1 卷積后的輸出重新分解為2 個向量,使用2 個Sigmoid非線性函數來擬合線性卷積上的2D 二進制分布;最后通過乘法聚合通道注意力實現跨通道交互。在3×3 分支中用1 個3 × 3 卷積以捕獲多尺度特征表示。
使用2D 全局平均池化對1×1 分支和3×3 分支輸出中的全局空間信息編碼,輸出將被轉換為相應的維度形狀,即:R1×C∥G1 ×RC∥G×HW2 。最后添加非線性函數Softmax 來擬合線性變換,將2 個分支相同規模的輸出連接起來轉換為R1×H×W 的格式,使用矩陣點積運算將上述并行處理的結果相乘,得到了空間注意力圖,能夠收集不同尺度的空間信息。EMA 的最終輸出與輸入X 的大小相同,便于直接添加到YOLOv8 網絡中,本文選擇在骨干網絡前2 個C2f 后添加EMA 注意力。
2. 1. 2 改進C2f 模塊
YOLOv8 骨干網絡主要使用了常規卷積和C2f模塊,能夠對圖像進行高質量的特征提取。考慮到EMA 注意力的使用一定程度上增加了模型的復雜度,于是選用更簡單的卷積方法替換部分常規卷積來簡化模型,而FasterNet[20]提出了一種新的卷積方式PConv,通過減少計算和內存訪問來有效提取特征,原理如圖3 所示。只對部分輸入通道使用常規卷積進行特征提取,將第1 個或最后1 個cp 通道看作整個特征圖的代表進行計算,并保持通道數不變。
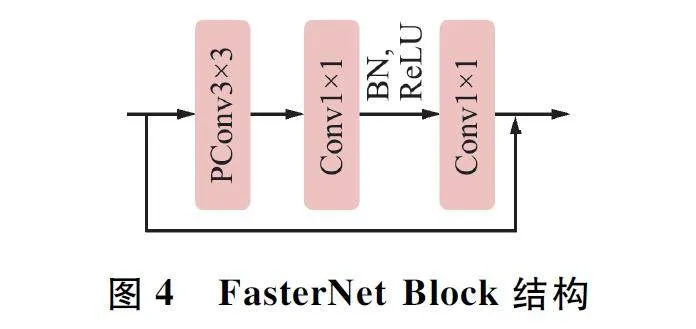
基于PConv 和Bottleneck,得到了新的卷積網絡結構FasterNet Block,其結構如圖4 所示,有1 個PConv 層,后跟2 個1×1 Conv 層。
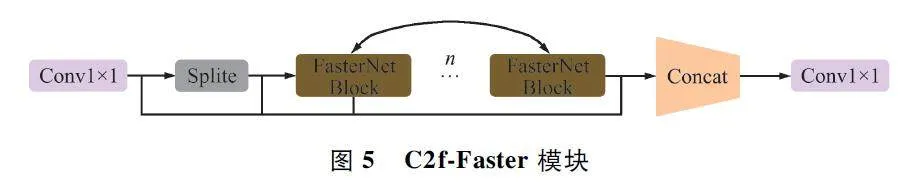
用FasterNet Block 模塊替換C2f 中的Bottleneck,得到了C2f-Faster 模塊來替換骨干網絡中的最后1 個C2f,C2f-Faster 結構如圖5 所示。
2. 2 改進頸部
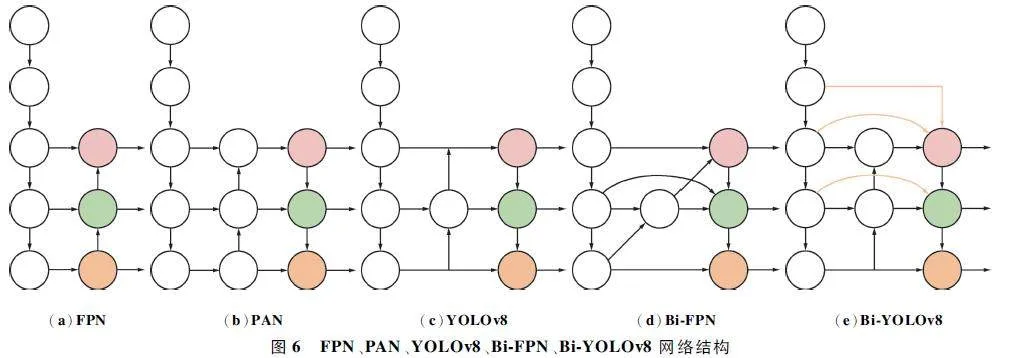
小目標檢測精度不足一直是當下航拍圖像目標檢測存在的主要問題,這主要是因為隨著網絡的加深,一些淺層特征會被網絡刪除,而小尺寸目標的信息主要存在于淺層位置,但通過多尺度特征融合的方法可以有效解決這一問題。谷歌大腦2019 年提出了一種全新的特征融合方法Bi-FPN[21],采用了跨尺度連接方式和加權特征融合思想,能夠在不增加太多成本的情況下融合更多的特性。YOLOv8 很好地結合了FPN 和PAN 的結構,而本文在YOLOv8的基礎上,結合Bi-FPN 的思想,增加了新的跨尺度連接方式和特征融合方法,設計了一種新的特征融合網絡Bi-YOLOv8,上述特征融合網絡結構如圖6所示。
圖6 中紅色圓圈代表小型目標檢測器,綠色圓圈代表中型目標檢測器,橙色圓圈代表大型目標檢測器。如圖6(a)所示,FPN 是自上向下的特征金字塔,把高層的語義特征傳遞下來,但對定位信息傳遞的效果很差。如圖6(b)所示,PAN 針對這一點,在FPN 后面補充了一個自下向上的特征金字塔,將低層的定位特征傳遞上去,形成了一個具備語義信息和定位信息的特征金字塔。如圖6 (c )所示,YOLOv8 在PAN 思想基礎上進一步優化,去除了沒有特征融合的節點,簡化了網絡結構。上述特征融合方法都存在對小目標定位和識別能力弱的問題,這是因為在特征提取過程中,小目標很容易受到正常尺寸目標的干擾以及網絡會刪除不明顯信息的影響,使得小目標信息會不斷減少,導致小目標檢測效果不能滿足預期要求。如圖6(d)所示,引入了更有效的雙向特征金字塔網絡BiFPN,不僅刪除了沒有特征融合的節點,還在處于同一層的原始輸入節點和輸出節點之間添加1 條額外的邊,并用一種簡單而高效的加權特征融合機制替換了原本簡單相加的特征融合,能夠保留更多的漸層特征。如圖6(e)所示,本文提出的結構在Bi-FPN 基礎上添加新的跨尺度連接方法,對第2 層和第3 層的原始特征分別添加額外的3×3 和1 ×1 的常規卷積來調整圖片尺寸為80 pixel×80 pixel,并與相應規模的輸出連接起來;在輸入節點與中間節點之間添加了1 ×1 的卷積,使用加權特征融合方法,能夠在減少模型參數的情況下保留更多的原始特征信息。
2. 3 損失函數的改進
YOlOv8 使用CIoU Loss[22]作為邊界框回歸損失函數,記真實框為Bgt = [xgt,ygt,wgt,hgt ],預測框為B = [x,y,w,h],Bgt 和B 內的值對應邊界框的中心坐標和尺寸大小,原CIoU Loss 定義如式(1 )~式(4)所示:
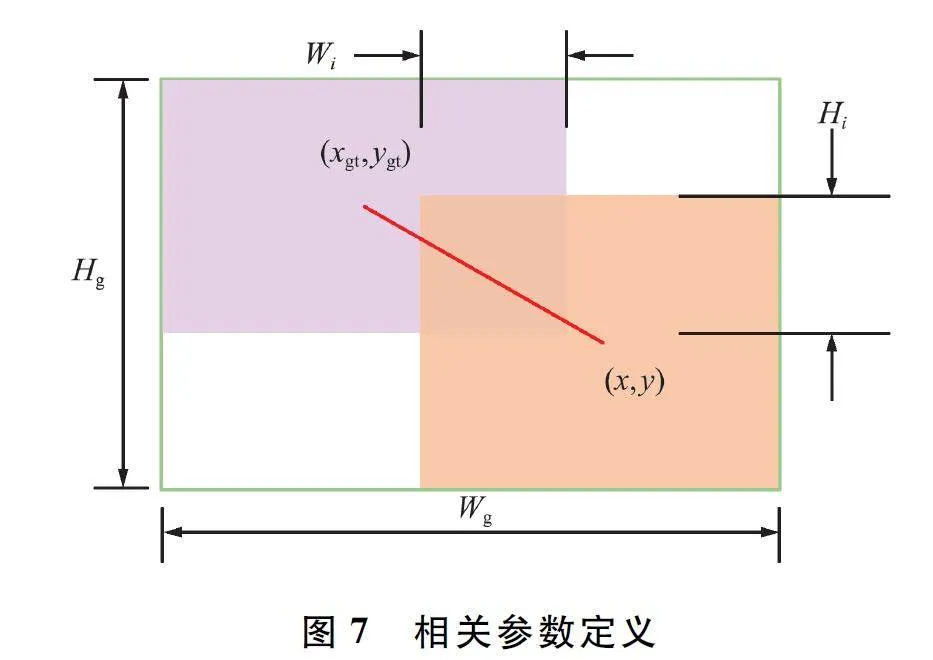
式中:LIoU 為度量預測框和真實框的重疊程度,α 為平衡參數,ν 為長寬比的一致性,其余參數定義如圖7 所示。
CIoU Loss 假設了訓練數據具有較高的質量,側重于增強邊界框損失的擬合能力,沒有考慮到低質量數據對模型性能的危害,為了解決這一問題,選擇使用WIoU Loss[23]來替換CIoU Loss。WIoU Loss 在降低高質量邊界框競爭力的同時,也減小了低質量數據的有害梯度,使得模型可以聚焦普通質量的錨框,從而提高模型的整體性能。
用β 表示預測框的異常程度,定義如下:
使用β 構建動態非單調聚焦機制,并與基于注意力的邊界框損失相結合,得到了能隨時分配符合當時情況梯度增益的WIoU Loss,定義如下:
式中:α、δ 為學習參數,RWIoU ∈[1,e),會顯著放大正常質量錨框的LIoU 。
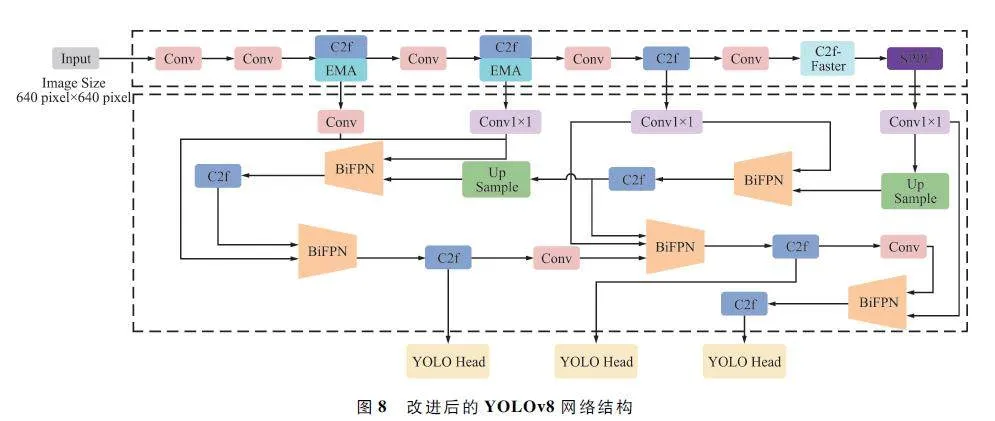
至此,完成了對YOLOv8 骨干網絡、頸部結構和損失函數三方面的改進,改進后的模型網絡結構如圖8 所示。在骨干網絡中引入EMA 注意力機制,增強其特征提取能力,還提出了C2f-Faster 模塊來解決使用注意力導致的模型復雜度上升及運行速度變慢的問題。此外,設計了輕量級的特征融合網絡Bi-YOLOv8 改進頸部,增強了模型多尺度特征融合能力,改善網絡對小目標檢測精度。最后通過使用WIoU 損失函數降低了低質量樣本的不良影響,提升了模型的整體性能。
3 實驗結果與分析
3. 1 實驗數據集
為評估本文提出算法的有效性和先進性,在VisDrone2019[24]公開數據集上進行實驗驗證。該數據集包含10 209 張靜態圖像,其中6 471 張用于訓練,548 張用于驗證,3 190 張用于測試,由各種無人機攝像機拍攝,涵蓋廣泛的方面,預測10 種不同的類別。
3. 2 實驗環境及參數配置
本文實驗基于64 位Windows 11 操作系統,實驗環境為Python3. 8、CUDA11. 7 及PyTorch2. 0。實驗所用計算機CPU 為Intel (R ) Core (TM ) i7-12700H,GPU 為NVIDIA GeForce RTX3070,16 GB運行內存。相關參數如下:訓練輪數為150,此時可以達到收斂狀態;批量大小為8,設備GPU 能夠滿功率運行;輸入圖片尺寸為640 pixel×640 pixel,縮放圖片,統一尺寸,提升速度;隨機種子為1,固定隨機數,避免消融實驗受到誤差影響;數據增強為1,開啟數據增強,提高訓練效率,提升模型魯棒性;優化器為SGD,采用梯度下降法調整學習率;初始學習率為0. 01,最小學習率為0. 000 1,隨著訓練的進行不斷減小學習率,初始學習率設置較大以節省訓練時間,設置最小學習率防止網絡被困在局部最小值;α(WIoU)為1. 9,δ(WIoU)為3,WIoU 損失函數的超參數,實驗中得到的最優解。
3. 3 實驗評價指標
為了能夠有效直觀地展示本文對YOLOv8 的改進效果,采用查準率(Precision,P)、召回率(Recall,R)、平均精度均值(mean Average Precision,mAP)、模型參數量(Params)、總浮點運算量(FLOPs)和每秒檢測幀數(Frame Per Second,FPS)作為模型性能的評價指標。其中Params 是指模型中參數的數量,FLOPs 用來衡量模型的復雜度,FPS 指模型每秒鐘處理的圖像數量。查準率用以評估預測的準確度,召回率用以評估找到正確樣本的能力,查準率與召回率定義如下:
式中:TP 表示預測與實際都為真,FP 表示預測為真,實際為假;FN 表示預測為假,實際為真。
平均精度(Average Precision,AP)用以衡量模型在每個類別上的性能,mAP 取所有類別AP 的平均值,以衡量模型在所有類別上的性能,mAP 定義如式(10)所示。mAP50 表示IoU 取值為0. 5 時的總類別平均精度,mAP50:95 表示不同IoU 取值(0. 5 ~ 0. 95,步長0. 05)的平均精度。
3. 4 添加不同數量EMA 對比實驗結果與分析
YOLOv8 骨干網絡中有4 個C2f 模塊,為確定添加在C2f 后的EMA 的數量,以YOLOv8s 為基準算法,分別在骨干網絡第1 個C2f、前2 個C2f、前3 個C2f 和所有C2f 模塊后添加EMA 注意力機制,進行了簡單的對比實驗,實驗結果如表1 所示。
由實驗結果可知,添加多個EMA 注意力機制會導致模型計算速度變慢,且對精度的提升效果并不顯著。相較于只添加1 個EMA,添加2 個EMA 在精度有所提升的同時并沒有使得速度大幅降低。因此,選擇在骨干網絡前2 個C2f 模塊后添加EMA 注意力機制,在速度與精度間達到了一個較好的平衡。
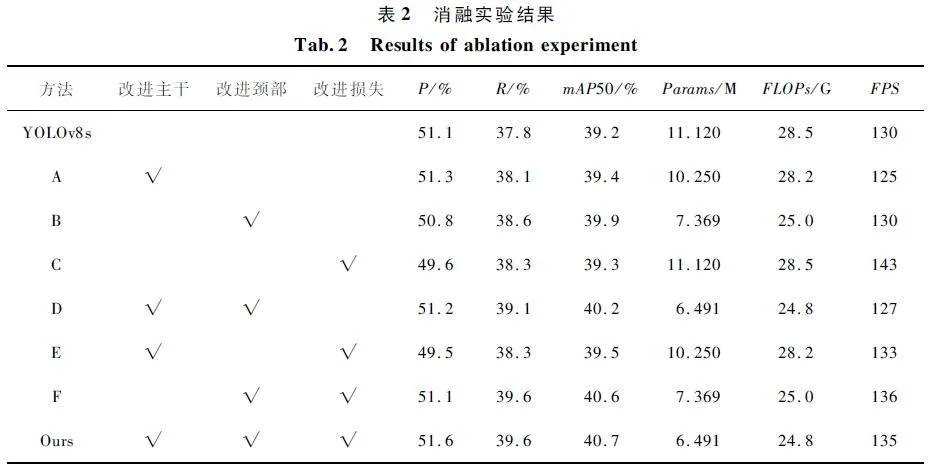
3. 5 消融實驗結果與分析
為證明本文提出的各項改進措施對無人機航拍圖像目標檢測算法性能的提升作用,以YOLOv8s 為基準算法,依此對其添加相應的改進措施,進行了一系列消融實驗,實驗結果如表2 所示。
對表2 中實驗結果進行分析:① A 表示在骨干網絡引入EMA 注意力和C2f-Faster 模塊,大部分指標均有提升,表明對骨干網絡的改進能提升模型的特征提取能力,進而提升網絡的檢測精度。② B 表示將本文提出的Bi-YOLOv8 結構應用于YOLOv8s頸部,與基準算法對比,除查準率外,其余指標均有較大提升,在保證提高精度的前提下實現了模型的輕量化,考慮到查準率并不是評估模型性能的關鍵指標,可以認為對頸部結構的改進是十分有效的。③ C 表示用WIoU 作為邊界框回歸函數,相較于基準算法,在不增加模型復雜度的情況下,提升了網絡的檢測精度。④ 在YOLOv8s 和改進了骨干網絡的2 種網絡結構上應用WIoU 損失函數,mAP50 均只提升了0. 1% ,召回率分別提升了0. 5% 和0. 2% ,而查準率反而有所降低,改進效果一般;但在改進頸部結構的網絡上應用WIoU,mAP50 提升了0. 7% ,召回率提升了1% ,并且查準率也提升了0. 3% ,由對比結果可以看出損失函數優化在改進了頸部結構的網絡上取得了更好的效果,表明WIoU 損失函數更適用于進行了多尺度特征融合的網絡。⑤ Ours表示對YOLOv8s 添加本文所有改進措施,相較于基準算法,本文方法mAP50 提升了1. 5% ,查準率提升了0. 5% ,召回率提升了1. 8% ,參數量降低了4. 629 M,總浮點運算量降低了3. 7 G,每秒檢測幀數提升了5,改進算法各項指標均優于YOLOv8s,表明本文方法不僅提升了檢測精度,還實現了模型的輕量化,能夠滿足實時性和準確性的需求。
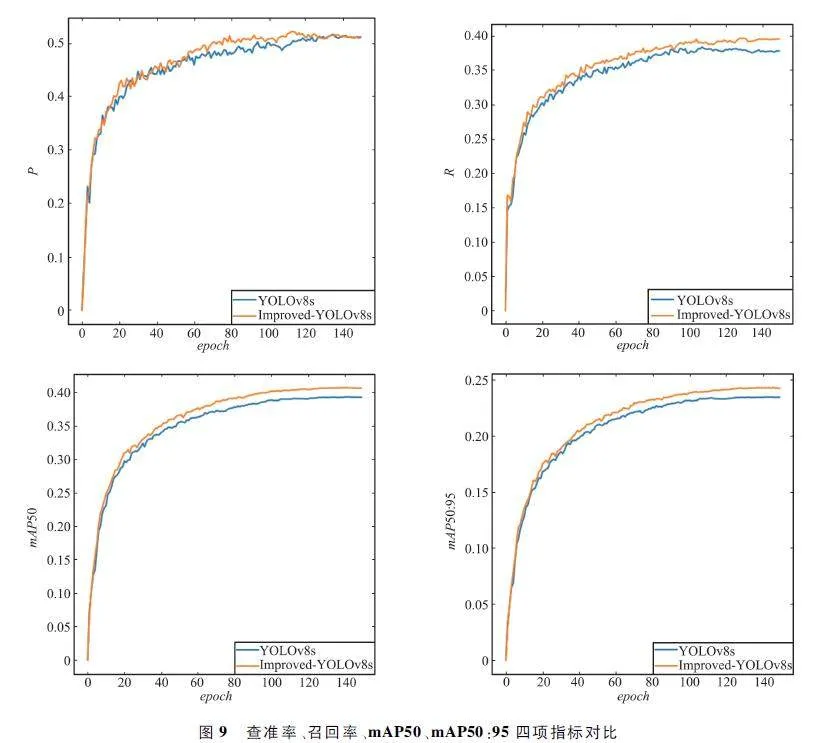
為能更好地表現本文改進算法的有效性,還將YOLOv8s 基準算法與改進后的算法在訓練過程中的查準率、召回率、mAP50 和mAP50:95 四項指標變化情況進行了對比,實驗結果如圖9 所示。從圖中可以看出,2 種算法隨著迭代次數的增加,最終都能達到收斂狀態,但是改進算法的4 項指標均高于基準算法,表明本文改進算法能有效提高檢測精度。
3. 6 本文改進算法目標檢測結果與分析
為了更直觀地展示本文改進算法的檢測效果,用YOLOv8s 與本文方法對幾種不同無人機航拍場景進行檢測,得到的檢測效果對比如圖10 所示。其中左側為原圖,中間為YOLOv8s 算法檢測效果圖,右側為本文改進算法檢測效果圖。
在尺度變化程度較大的情況下,如圖10(a)所示,卡車和汽車在同一場景且因拍攝角度呈現出不同的大小,YOLOv8s 算法對圖中左下角卡車存在漏檢、誤檢的問題,而本文改進算法能準確識別出2 種車輛。在檢測目標密集分布的情況下,如圖10(b)所示,YOLOv8s 方法存在對圖中右上角較遠距離行人漏檢的情況,本文方法能夠檢測出更多的小目標。對于復雜背景情況下的小目標檢測,如圖10(c)所示,本文改進算法也能檢測出更多的目標。對于檢測目標被遮擋的情況,如圖10(d)所示,YOLOv8s 算法生成了很多重疊的邊界框,且存在對汽車誤判面包車的情況,本文算法能夠準確檢測到圖中的所有目標。綜上對比分析可知,改進后的算法檢測效果更好。
3. 7 對比實驗結果與分析
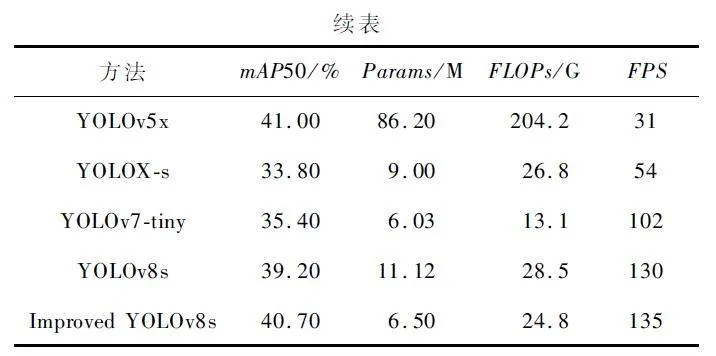
為進一步驗證本文提出方法對無人機航拍圖像目標檢測的性能優勢,將YOLOv8s 基準算法、改進算法與相關領域具有代表性的網絡如Faster-RCNN、SSD、RetinaNet、YOLOv5s、YOLOv5x、YOLOX-s 和YOLOv7-tiny 進行對比,實驗結果如表3 所示。
由對比實驗結果可知,相較于同等規格的模型,本文改進算法的mAP50 值最高,并且也只略低于YOLOv5x,但YOLOv5x 參數量、計算量和檢測速度都遠不及改進算法。與輕量型算法YOLOv7-tiny 相比,改進算法有著更好的性能,而且參數量相差也很小。改進算法還有著最快的檢測速度,并且相較于基準算法YOLOv8s,改進算法所有指標均展現出較大優勢。結合各項指標來看,本文改進算法的綜合性能最好,對無人機航拍圖像有著良好的檢測能力,在速度和精度上都有很好的表現,顯現出本文算法具有明顯的優越性。
3. 8 DOTA 數據集上的實驗結果與分析
為充分驗證本文改進方法的適用性和魯棒性,在DOTA[25]數據集上進行了對比實驗。該數據集包含2 806 張航拍圖像,涵蓋15 種目標類別,尺度差異大、背景復雜,很適合用于驗證本文算法的適用性。DOTA 數據集中大部分圖片像素尺寸較大,接近4 000 pixel×4 000 pixel,若直接用來訓練很難檢測到其中的小目標,因此將原圖統一裁剪為1 024 pixel×1 024 pixel 的圖像,裁剪后圖像數量擴充至21 046 張,隨機選擇15 749 張圖片作為訓練集,5 297 張圖片作為測試集。實驗設置與3. 2 節一致,實驗結果如表4 所示。
由實驗結果可知,改進后的算法在DOTA 數據集上檢測精度提升了1. 2% ,達到了74. 1% ,查準率提升了0. 5% ,召回率提升了1. 5% ,每秒檢測幀數提升了3。充分證明了本文改進方法具有良好的適用性和魯棒性,也再次證實了本文提出算法很適合用于航拍圖像目標檢測。
4 結束語
無人機航拍圖像目標檢測在民用和軍事領域中有著重要的應用價值。為解決由于無人機圖像背景復雜、密集分布的小目標相互遮擋嚴重且呈多尺度分布導致的目標檢測精度較低及模型體積較大的問題,本文基于YOLOv8s 網絡,通過在骨干網絡引入EMA 注意力和C2fFaster 模塊,設計BiYOLOv8 特征融合網絡改進頸部結構,使用新的WIoU 損失函數,提出了一種改進YOLOv8 的無人機航拍圖像目標檢測算法。在無人機航拍數據集VisDrone2019上的實驗表明,本文提出算法全方面優于基準算法YOLOv8s,并且與其他先進方法相比綜合性能最好,能夠滿足實時性和準確性的需求;而在DOTA 數據集上的實驗則是驗證了改進方法的適用性。改進的算法在目標檢測精度上仍有很大提升空間,尤其是針對小目標檢測方面。此外,后期工作中仍需關注模型部署在無人機上的實際表現情況。
參考文獻
[1] 柴興華,胡炎,雷耀麟,等. 無人機智能測控技術研究綜述[J]. 無線電工程,2019,49(10):855-860.
[2] SURMANN H,WORST R,BUSCHMANN T,et al. Integration of UAVs in Urban Search and Rescue Missions[C]∥2019 IEEE International Symposium on Safety,Security,and Rescue Robotics (SSRR). Würzburg:IEEE,2019:203-209.
[3] LIU W,ANGUELOV D,ERHAN D,et al. SSD:SingleShot MultiBox Detector[C]∥2016 European Conferenceon Computer Vision(ECCV). Amsterdam:Springer,2016:21-37.
[4] REDMON J,DIVVALA S,GIRSHICK R,et al. You OnlyLook Once:Unified,Realtime Object Detection [C]∥2016 IEEE Conference on Computer Vision and PatternRecognition(CVPR). Las Vegas:IEEE,2016:779-788.
[5] LIN T Y,GOYAL P,GIRSHICK R,et al. Focal Loss forDense Object Detection [C]∥ Proceedings of the IEEEInternational Conference on Computer Vision (ICCV ).Venice:IEEE,2017:2980-2988.
[6] GIRSHICK R,DONAHUE J,DARRELL T,et al. RichFeature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Columbus:IEEE,2014:580-587.
[7] CAI W W,WEI Z G. Remote Sensing Image ClassificationBased on a Crossattention Mechanism and Graph Convolution[J]. IEEE Geoscience and Remote Sensing Letters,2020,19:1-5.
[8] CHENG Q Q,WANG H J,DING X C,et al. A UAV TargetDetection Algorithm Based on YOLOv4tiny and ImprovedWBF [C ] ∥ Proceedings of the 14th InternationalConference on Wireless Communications and Signal Processing (WCSP). Nanjing:IEEE,2022:122-126.
[9] 羅旭鴻,劉永春,楚國銘,等. 基于改進YOLOv5 無人機圖像目標檢測算法[J]. 無線電工程,2023,53 (7):1528-1535.
[10] LIU W J,QIANG J,LI X X,et al. UAV Image SmallObject Detection Based on Composite Backbone Network[J]. Mobile Information Systems,2022(15):1-11.
[11] WANG B B,YANG G J,YANG H,et al. Multiscale MaizeTassel Identification Based on Improved RetinaNet Modeland UAV Images[J]. Remote Sensing,2023,15(10):2530.
[12] 王殿偉,胡里晨,房杰,等. 基于改進DoubleHeadRCNN 的無人機航拍圖像小目標檢測算法[J]. 北京航空航天大學學報,2023:10.
[13] DEMESQUITA D B,SANTOS R F D,MACHARET D G,et al. Fully Convolutional Siamese Autoencoder for ChangeDetection in UAV Aerial Images [J]. IEEE Geoscienceand Remote Sensing Letters,2020,17(8):1455-1459.
[14] 趙耘徹,張文勝,劉世偉. 基于改進YOLOv4 的無人機航拍目標檢測算法[J]. 電子測量技術,2023,46(8):169-175.
[15] WANG X,HE N,HONG C,et al. Improved YOLOXXBased UAV Aerial Photography Object DetectionAlgorithm [J ]. Image and Vision Computing,2023,135:104697.
[16] WANG C Y,BOCHKOVSKIY A,LIAO H Y M. YOLOv7:Trainable Bagoffreebies Sets New Stateoftheart forRealtime Object Detectors[C]∥2023 IEEE / CVF Conference on Computer Vision and Pattern Recognition(CVPR). Vancouver:IEEE,2023:7464-7475.
[17] LIN T Y,DOLLAR P,GIRSHICK R,et al. FeaturePyramid Networks for Object Detection[C]∥2017 IEEEConference on Computer Vision and Pattern Recognition(CVPR). Honolulu:IEEE,2017:936-944.
[18] LIUS,QI L,QIN H F,et al. Path Aggregation Network forInstance Segmentation[C]∥2018 IEEE / CVF Conferenceon Computer Vision and Pattern Recognition (CVPR).Salt Lake City:IEEE,2018:8759-8768.
[19] OUYANG D L,HE S,ZHANG G Z,et al. Efficient Multiscale Attention Module with Crossspatial Learning[C]∥2023 IEEE International Conference on Acoustics Speechand Signal Processing (ICASSP). Rhodes Island:IEEE,2023:1-5.
[20] CHEN J R,KAO S H,HE H,et al. Run,Don’t Walk:Chasing Higher FLOPS for Faster Neural Networks[C]∥2023 IEEE / CVF Conference on Computer Vision and Pattern Recognition (CVPR ). Vancouver:IEEE,2023:12021-12031.
[21] TAN M X,PANG R M,LE G V. EfficientDet:Scalableand Efficient Object Detection [C]∥ 2020 IEEE / CVFConference on Computer Vision and Pattern Recognition(CVPR). Seattle:IEEE,2020:10778-10787.
[22] ZHENG Z H,WANG P,REN D W,et al. EnhancingGeometric Factors in Model Learning and Inference forObject Detection and Instance Segmentation [J ]. IEEETransactions on Cybernetics,2022,52(8):8574-8586.
[23] TONG Z J,CHEN Y H,XV Z W,et al. WiseIoU:Bounding Box Regression Loss with Dynamic FocusingMechanism[EB / OL]. (2023 -01 -24)[2023 -07 -15].https:∥arxiv. org / abs / 2301. 10051.
[24] DU D W,ZHU P F,WEN L Y,et al. VisDroneDET2019:The Vision Meets Drone Object Detection in Image Challenge Results[C]∥2019 IEEE / CVF International Conference on Computer Vision Workshop (ICCVW). Seoul:IEEE,2019:213-226.
[25] DING J,XUE N,XIA G S J,et al. Object Detection inAerial Images:A Largescale Benchmark and Challenges[J]. IEEE Transactions on Pattern Analysis and MachineIntelligence,2021,44 (11):7778-7796.
作者簡介
程換新 男,(1966—),博士,教授,碩士生導師。主要研究方向:人工智能、先進控制、機器視覺。
喬慶元 男,(2001—),碩士研究生。主要研究方向:計算機視覺、模式識別。
(*通信作者)駱曉玲 女,(1966—),博士,教授,碩士生導師。主要研究方向:過程裝備自動化的優化設計。
于沙家 女,(1986—),碩士,實驗員。主要研究方向:神經網絡控制。
基金項目:國家自然科學基金(62273192)
