基于Scrapy 的新能源汽車評論數據采集與情感分析
2024-09-03 00:00:00于波馮文雯于曉雨周維燕
電腦知識與技術 2024年19期
摘要:本研究基于Scrapy爬蟲框架從懂車帝網站上爬取新能源汽車評論數據,并進行了數據分析和情感分類。研究發現,用戶對新能源汽車主要關注性能、續航能力、外觀設計、購車體驗和售后服務等方面。情感分析顯示用戶普遍持積極態度,但亦存在對價格和購車過程中的問題的不滿。本研究為新能源汽車行業發展和市場需求提供了數據支持,為互聯網時代大數據分析提供了一個實踐案例。
關鍵詞:新能源汽車;短評論;網絡爬蟲;數據分析;情感分類;可視化
中圖分類號:TP311 文獻標識碼:A
文章編號:1009-3044(2024)19-0033-03
0 引言
在互聯網時代,網絡數據量呈現爆炸性增長的趨勢。截至2023年12月,我國網民規模達10.92億人,較2022年12月新增網民2 480萬人,互聯網普及率達77.5%[1]。在這個背景下,伴隨著國內汽車行業的蓬勃發展,新能源汽車作為其中的主力軍之一,吸引了大量消費者的關注。懂車帝網站作為汽車領域的重要信息交流平臺,匯集了眾多用戶對不同新能源汽車的評論與觀點。
然而,面對互聯網上海量的文本數據,僅依靠人工篩選數據已不再現實。高效地從海量數據中提取有價值信息成了研究人員和企業關注的焦點。自動化網絡爬蟲技術因其在不同領域的廣泛應用而備受矚目。本文基于Python編寫程序,采用Scrapy作為爬蟲框架,從懂車帝網站上爬取當下新能源汽車的評論數據。通過對爬取的數據進行清洗與整理,提取其中的有價值信息,并運用可視化技術進行展示。同時,還對評論進行了情感分析,以探索用戶對新能源汽車的態度與情感傾向。
本文旨在利用網絡爬蟲技術,探索并挖掘新能源汽車領域的用戶評論數據,為汽車行業的發展和市場需求提供數據支持,同時為互聯網時代大數據分析提供一個實踐案例。
1 主要技術
1.1 爬蟲原理
網絡爬蟲是一種基于獲取不同URL的核心支撐,用于搜索和抓取該URL下的各種文章、鏈接和圖片等內容的技術。在給定的URL中,網絡爬蟲會持續從中提取URL,并對當前URL的內容進行篩選和獲取。當一個URL的內容被完全檢索后,網絡爬蟲會自動轉到下一個URL,重復這一過程,直到所有URL都被檢索一次。在技術層面上,網絡爬蟲通過程序模擬瀏覽器請求站點的行為,將站點返回的數據(如HTML代碼、JSON 數據或二進制數據)存儲在本地,以供后續使用。根據不同的需求,網絡爬蟲可以針對性地進行爬取,并增加目標定義和過濾機制。
本文采用Scrapy爬蟲框架進行數據采集。Scrapy 是一個基于Python開發的高層次、快速的網頁抓取框架,用于抓取網站信息并從頁面中提取結構化數據[2]。在數據挖掘、監測和自動化測試等不同場景下,Scrapy 具有廣泛應用。
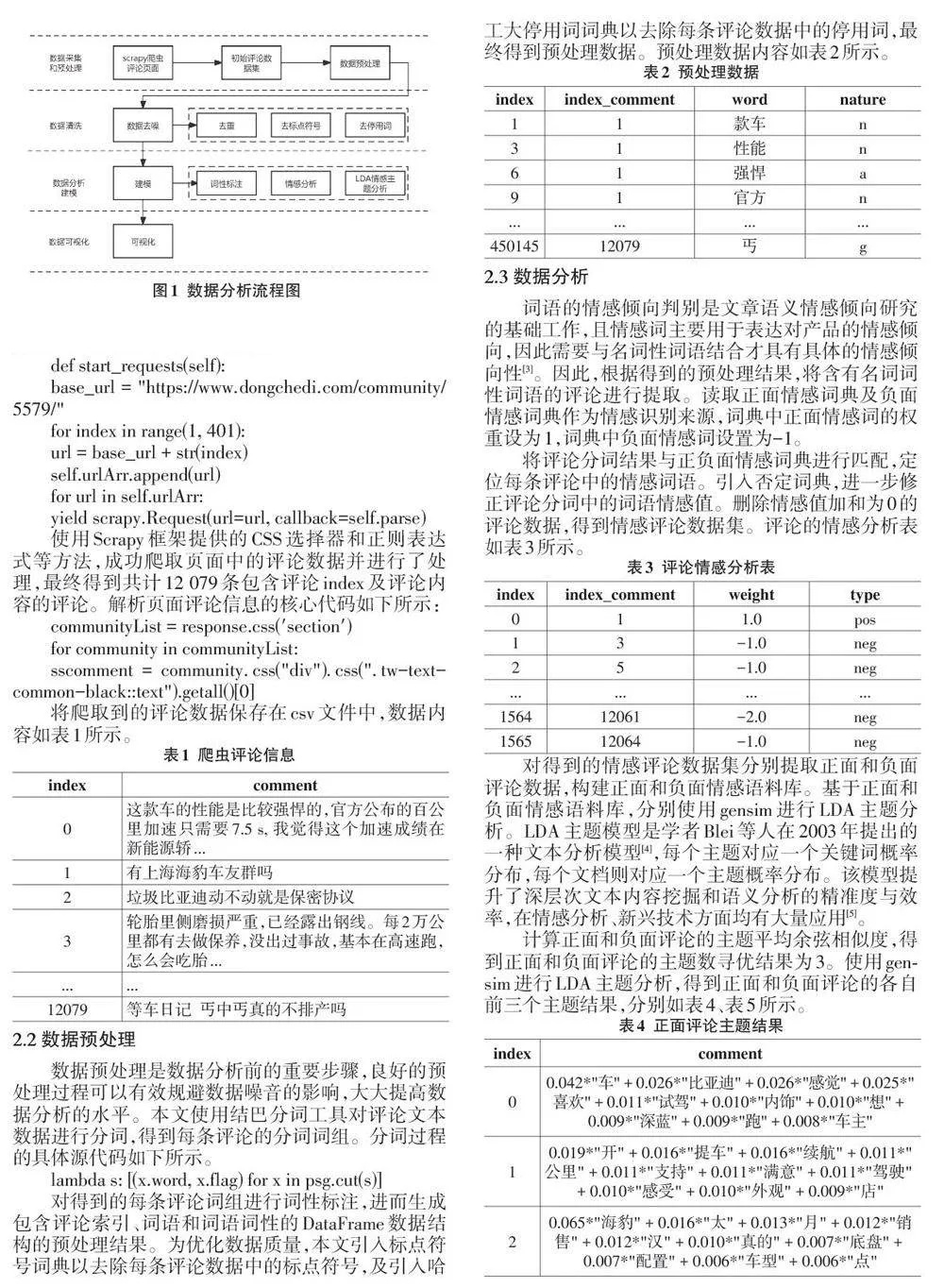
1.2 數據分析流程
數據分析是應用統計、計算機科學、機器學習和領域專業知識等技術和方法,對大量數據進行收集、清洗、處理和分析,以發現有意義的信息、趨勢和模式,并從中獲得見解,從而支持決策制定、問題解決和創新的過程。
本文使用numpy、pandas、jieba分詞、gensim、pyL? DAvis、matplotlib 和wordcloud 等技術工具,對懂車帝比亞迪海豹新能源車的評論信息進行數據分析、情感分類及可視化。具體流程如圖1所示。
2 功能實現
2.1 爬蟲模塊
我們根據懂車帝網站評論頁面的URL結構,定義了URL規則。在URL中發現,每一個車型的汽車在 `/ community` 評論頁URL之后的數字對應了每一個車型的汽車,每個車型汽車數字后面則為評論頁頁碼。評論首頁URL如下所示。
https://www.dongchedi.com/community/5579/1
通過構造相應的URL,循環生成并遍歷每個URL來模擬瀏覽器翻頁過程。本文設定爬取的目標頁數為前400頁,具體代碼如下所示:
