基于雙向嵌套級聯殘差的交通標志檢測方法
2024-09-12 00:00:00江金懋鐘國韻
現代電子技術 2024年5期
關鍵詞:模型

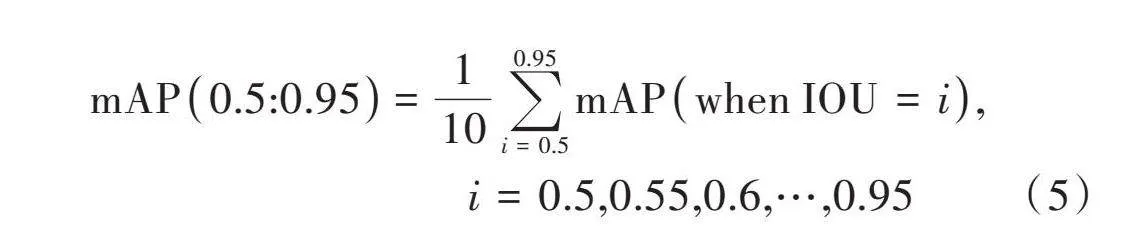


摘" 要: 交通標志檢測是自動駕駛領域的一個重要課題,其對于檢測系統的實時性和精度都有非常高的要求。目標檢測領域中的YOLOv3算法是業界公認在精度和速度上都處于前列的一種算法。文中以YOLOv3檢測算法作為基礎網絡,提出一種雙向嵌套級聯殘差單元(bid?NCR),替換掉原網絡中順序堆疊的標準殘差塊。雙向嵌套級聯殘差單元的兩條殘差邊采用相同的結構,都是一次卷積操作加上一次級聯殘差處理,兩條邊上級聯的標準殘差塊的數量可以調節,從而形成不同的深度差。然后將兩條邊的結果逐像素相加,最后再做一次卷積操作。相較于標準殘差塊,雙向嵌套級聯殘差單元擁有更強的特征提取能力和特征融合能力。文中還提出跨區域壓縮模塊(CRC),它是對2倍率下采樣卷積操作的替代,旨在融合跨區域的通道數據,進一步加強主干網絡輸入特征圖所包含的信息。實驗結果表明:提出的模型在CCTSDB數據集上mAP(0.5)、mAP(0.5∶0.95)分別達到96.86%、68.66%,FPS達到66.09幀。相比于YOLOv3算法,3個指標分別提升1.23%、10.35%、127.90%。
關鍵詞: 交通標志檢測; 雙向嵌套級聯殘差單元; 跨區域壓縮模塊; YOLOv3; 長沙理工大學中國交通標志檢測數據集; 特征提取; 特征融合
中圖分類號: TN911.73?34; TP391" " " " " " " " " "文獻標識碼: A" " " " " " " " " 文章編號: 1004?373X(2024)05?0176?06
Traffic sign detection method based on bi?directional nested cascading residuals
JIANG Jinmao, ZHONG Guoyun
(School of Information Engineering, East China University of Technology, Nanchang 330013, China)
Abstract: Traffic sign detection is an important topic in the field of autonomous driving, which has very high requirements for real?time performance and accuracy of the detection system. The YOLOv3 algorithm in the field of target detection is recognized as one of the leading algorithms in terms of accuracy and speed. In this paper, by taking YOLOv3 detection algorithm as the base network, a bi?directional nested cascaded residual (bid?NCR) unit is proposed to replace the standard residual blocks sequentially stacked in the original network. The two residual edges of the bid?NCR unit is of the same structure, both of which are one convolutional operation plus one cascaded residual processing, and the number of cascaded standard residual blocks on the two edges can be adjusted to form different depth differences. The results of the two edges are then added pixel by pixel, and another convolutional operation is performed, finally. In comparison with the standard residual blocks, the bid?NCR unit has stronger feature extraction capability and feature fusion capability. The cross?region compression (CRC) module, which is an alternative to the 2?fold downsampling convolutional operation, is proposed. It aims to fuse the channel data across regions to further enhance the information contained in the input feature map of the backbone network. The experimental results show that the model proposed in this paper achieves mAP(0.5) and mAP(0.5∶0.95) of 96.86% and 68.66%, respectively, and FPS of 66.09 frames on the dataset CCTSDB. In comparison with YOLOv3 algorithm, the three indicators are improved by 1.23%, 10.35% and 127.90%, respectively.
Keywords: traffic sign detection; bid?NCR unit; CRC module; YOLOv3; CSUST Chinese traffic sign detection benchmark (CCTSDB); feature extraction; feature fusion
0" 引" 言
汽車智能化是汽車產業一直在追尋的目標,而自動駕駛是汽車智能化不可或缺的一環。要實現自動駕駛,必須為汽車加上一雙眼睛和配套的處理系統,這套處理系統需要像人一樣識別交通標志。交通標志檢測的實現方案主要有兩大類:一類是基于計算機圖形學的方案,比如依據顏色直方圖、尺度不變特征變換特征、方向梯度直方圖特征[1]等,以上方法最大的問題在于這些人工提取的特征高度依賴于特定的場景,泛化能力很差;另一類是基于深度學習的方案,比如文獻[2]提出的基于多尺度卷積神經網絡的方案,設計了一個多尺度空洞卷積池化金字塔模塊用于采樣。文獻[3]對Tiny YOLOv4算法進行了改進,引入了跨階段局部網絡和SPP結構。基于深度學習的方案有兩類技術路線:一類是文獻[4]提出的RCNN算法,包括文獻[5]提出的FasterRCNN和文獻[6]提出的CascadeRCNN;另一類是文獻[7]提出的YOLO系列算法和文獻[8]提出的SSD算法。模型改進的思路大致也分為兩種:一種是提出新的、更輕更強的模塊對原網絡進行重構,比如文獻[9]提出Ghost Net模塊,文獻[10]提出雙尺度注意力模塊;另一種是先將原網絡變淺、變窄,然后再采取其他措施提高精度,比如說文獻[11]設計了一種叫copy?paste的數據增強方式,文獻[12]設計了基于坐標注意力的CA機制。
1" 算法基礎
1.1" YOLOv3網絡
YOLOv3[13]網絡由3個部分構成,負責提取特征的主干網絡,負責融合多尺度特征的頸部網絡,負責輸出預測結果的頭部網絡。主干網絡采用了相比YOLOv2[14]更深的殘差網絡,將五組殘差塊以1、2、8、8、4數量配比的形式進行堆疊。頸部網絡采用特征金字塔結構對多尺度特征進行融合。頭部網絡則負責輸出3個尺度的預測結果。
1.2" 殘差思想
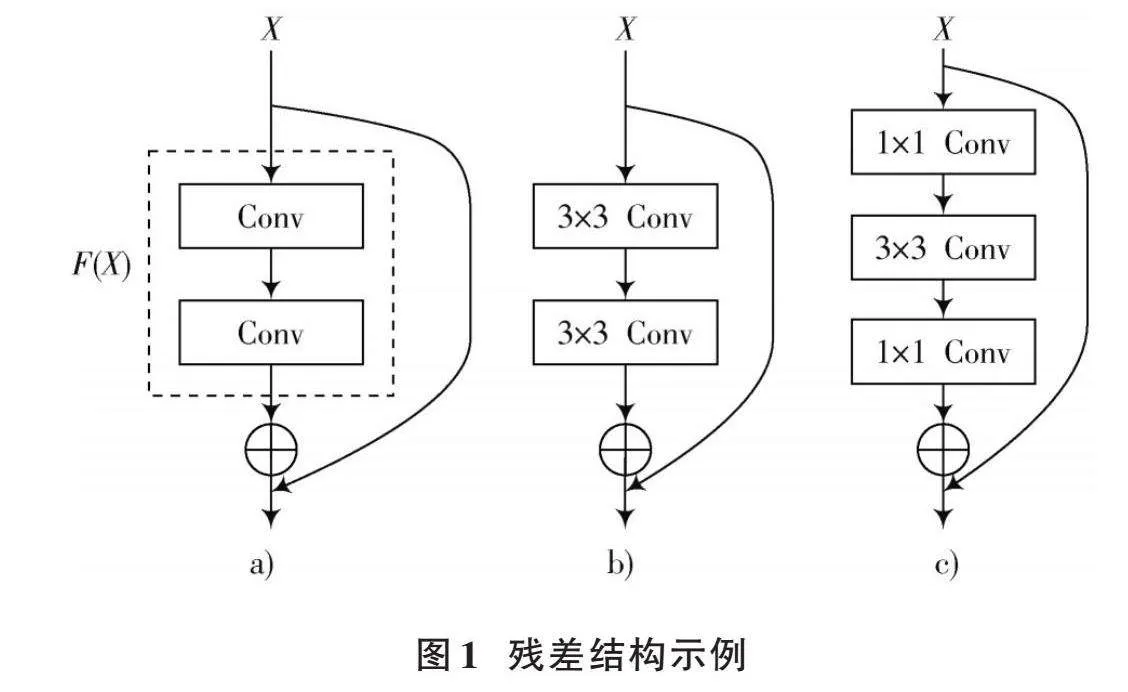
當神經網絡被設計得越來越深,模型性能并沒有隨之越來越強,反倒是出現了性能衰退。文獻[15]提到由于使用了非線性激活函數ReLU,當輸入小于0時,神經元的輸出直接被置為0,相當于神經元死亡,這一結果幾乎不可逆,等價于發生了不可逆的信息損失,同時也意味著網絡越深,信息損失越大。文獻[16]實現了恒等映射這一機制,以此盡可能保證特征的完整。圖1a)是殘差塊的基本結構。圖1c)是圖1b)的等價形式,但是參數量要少很多。
2" 基于雙向嵌套級聯殘差單元的交通標志檢測方法
2.1" 跨區域壓縮模塊
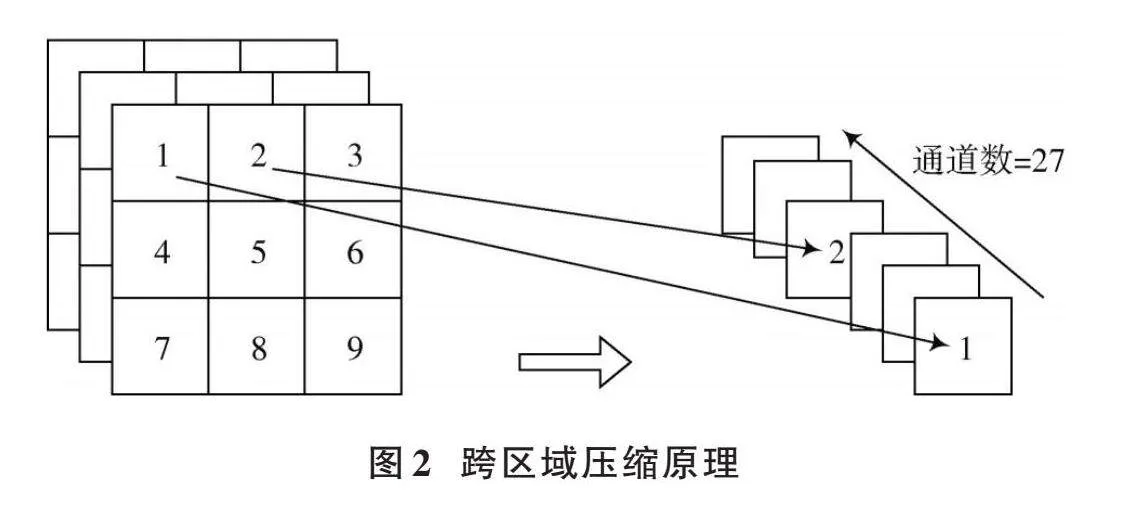
輸入圖像在進入YOLOv3主干網絡之前需要進行一次2倍率下采樣,但是卷積會導致原始圖像在輸入主干網絡之前發生信息衰減。為了解決上述問題,本文提出跨區域壓縮網絡。該模塊以原圖像作為輸入,對輸入圖像進行拼接,同樣能達到2倍率下采樣的效果。
具體來說,如圖2所示,用一個步長為2的3×3網格在圖像上每次選取9個相鄰的像素點,將這9個像素點按照從上到下、從左到右的順序,在通道方向上拼接成分辨率為1×1,通道數為27的特征圖。一方面,該模塊避免了輸入圖像在進入主干網絡之前丟失紋理、顏色、位置等低層次信息;另一方面,該模塊生成的特征圖的每一個像素都融合了附近區域的信息,為主干網絡提供了一個包含豐富信息的輸入。
2.2" 雙向嵌套級聯殘差單元
YOLOv3采用了較深的殘差網絡作為提取特征的主干網絡,殘差網絡在深度增加的同時,精度雖然會隨之增長,檢測速度卻也會相應下降。本文對殘差結構進行了重新設計,提出雙向嵌套級聯殘差單元,此單元將標準殘差塊的兩條殘差邊也設計為殘差結構。文獻[17]也使用了嵌套殘差的思想,他們在模塊之間引入嵌套結構,但本文采用另外一種路線,即在標準殘差塊內部嵌套一個級聯殘差結構。如圖3所示,首先對輸入圖像進行2倍率的下采樣,并將通道數擴大2倍。該模塊的兩條殘差邊都是一次1×1卷積操作加上級聯標準殘差塊。同時,兩條殘差邊上標準殘差塊的數量可以獨立進行調整。緊接著,將兩條殘差邊的結果進行逐像素相加。圖3b)是主干網絡采用的深度差為2的雙向嵌套級聯殘差單元。
兩條殘差邊上的級聯殘差塊的深度差使雙向嵌套級聯殘差單元還可以融合有層次差的特征,將相對更深的語義特征和相對更淺的位置特征相融合,而這將為下一層雙向嵌套級聯殘差單元提供融合更多全局信息和局部信息的特征圖。
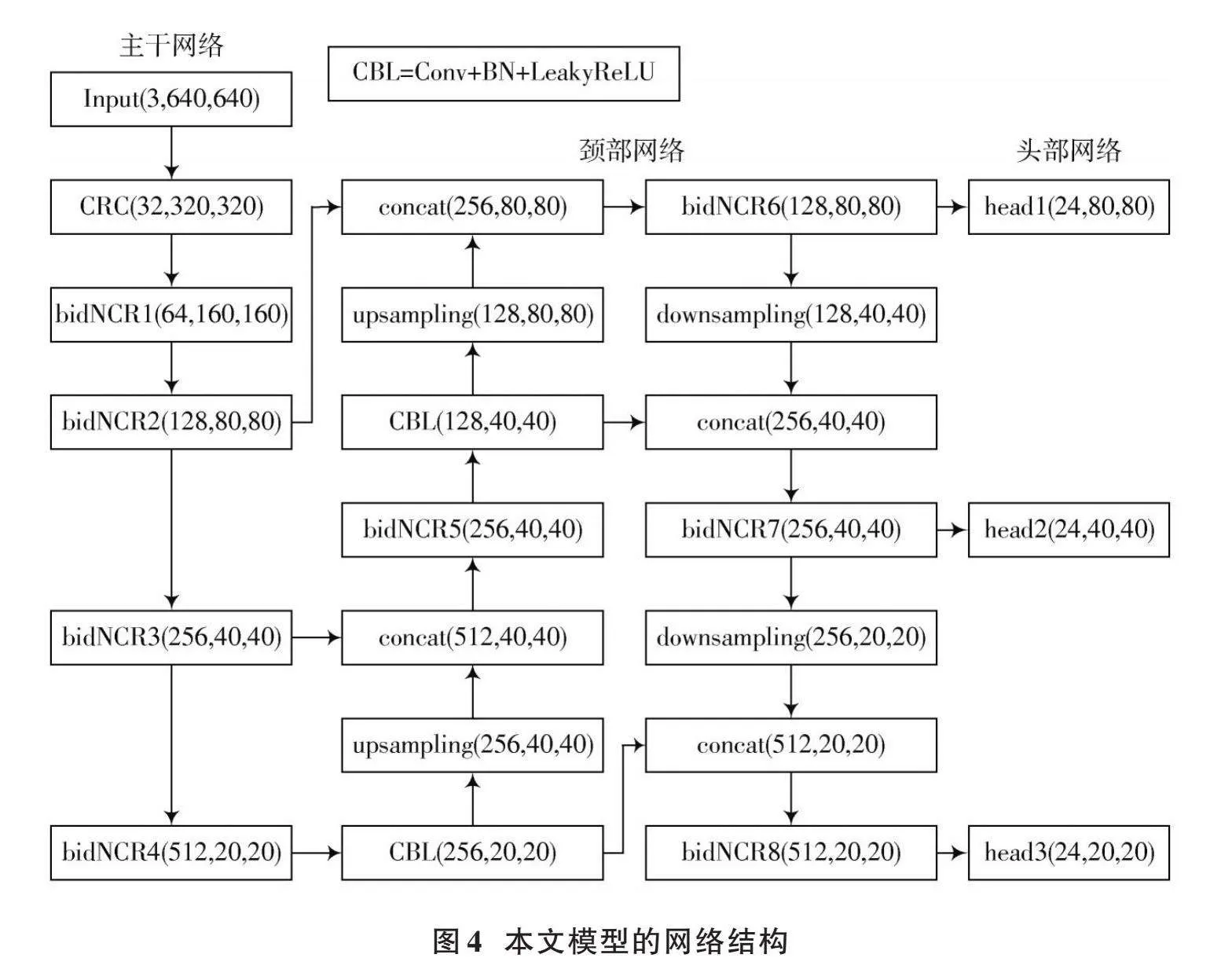
2.3" 基于雙向嵌套級聯殘差單元的網絡結構
本文提出的改進后的YOLOv3網絡結構如圖4所示。主干網絡由CRC模塊、4個bidNCR單元組成。將后面三級殘差單元的輸出作為頸部網絡的輸入。頸部網絡采用FPN結構,并部分采用bidNCR。最后,由頭部網絡負責最終的輸出。
3" 實" 驗
3.1" 實現細節
本文提出的網絡使用NVIDIA 3060 GPU(6 GB顯存)和PyTorch框架實現。主干網絡由ILSVRC上的預訓練模型進行初始化。neck網絡和head網絡都采用隨機初始化。本文將模型訓練150個epoch,采用凍結訓練的策略,即前75個epoch凍結主干網絡的參數,只訓練neck網絡和head網絡,后75個epoch則是整個網絡參與訓練。訓練采用SGD優化器,權重衰減設為0.000 5,初始學習率為0.01,每個epoch降低上一個epoch學習率的3%。
3.2" CCTSDB數據集
本文采用長沙理工大學張建明團隊建立的中國交通標志數據集。此數據集包括3個類別:警告標志、指示標志和禁止標志,如圖5所示。
本文只選取前4 000張圖像作為數據集,經過統計,三種類別圖像的數量分別為警告標志1 999張,禁止標志1 901張,指示標志100張。按照1∶9的比例分割數據集,也就是驗證集400張樣本,訓練集3 600張樣本。最后,直接使用該數據集提供好的測試集,一共400張。
3.3" 評價指標
本文采用目標檢測領域常用的3個標準來評價算法的性能表現。首先做一些定義:正確地將正樣本預測為正樣本,記為TP;正確地將負樣本預測為負樣本,記為TN;錯誤地將正樣本預測為負樣本,記為FN;錯誤地將負樣本預測為正樣本,記為FP。
[P=TPTP+FP] (1)
[R=TPTP+FN] (2)
[AP=01prdr] (3)
[mAP=1mi=1mAPi] (4)
[mAP0.5:0.95=110i=0.50.95mAPwhen IOU=i," " " " " " " " " " " " " " " " " " " i=0.5,0.55,0.6,…,0.95] (5)
式中:[P](Precision)表示分類正確的正樣本數量占系統判定為正樣本數量的比例;[R](Recall)表示分類正確的正樣本數量占數據中真實的正樣本數量的比例,在評判算法優劣時,需要綜合考量[P]、[R]的結果;AP稱為平均精度,通過計算PR曲線與坐標軸圍成的面積求出,AP針對的是單個類別的平均精度;mAP則是求出測試集中所有類別對應AP的均值;mAP(0.5∶0.95)表示IOU閾值從0.5~0.95對應的mAP的均值。
3.4" 模型設置
本文設置了4個模型用于對照實驗。模型1只將雙向嵌套級聯殘差單元應用于主干網絡,并且bidNCR1~ bidNCR4中兩個級聯殘差塊深度的比例分別為1∶1、2∶1、2∶1、1∶1,另外,在輸入位置加上跨區域壓縮模塊;模型2在模型1的基礎上加深了兩個級聯殘差塊的深度差異,將深度比例調整為1∶1、3∶1、3∶1、1∶1;模型3在模型2的基礎上將雙向嵌套級聯殘差單元應用于頸部網絡,bidNCR5~bidNCR8中兩個級聯殘差塊的比例分別為1∶1、1∶1、1∶1、1∶1;模型4在模型3的基礎上,去掉跨區域壓縮模塊。
4" 實驗結果與分析
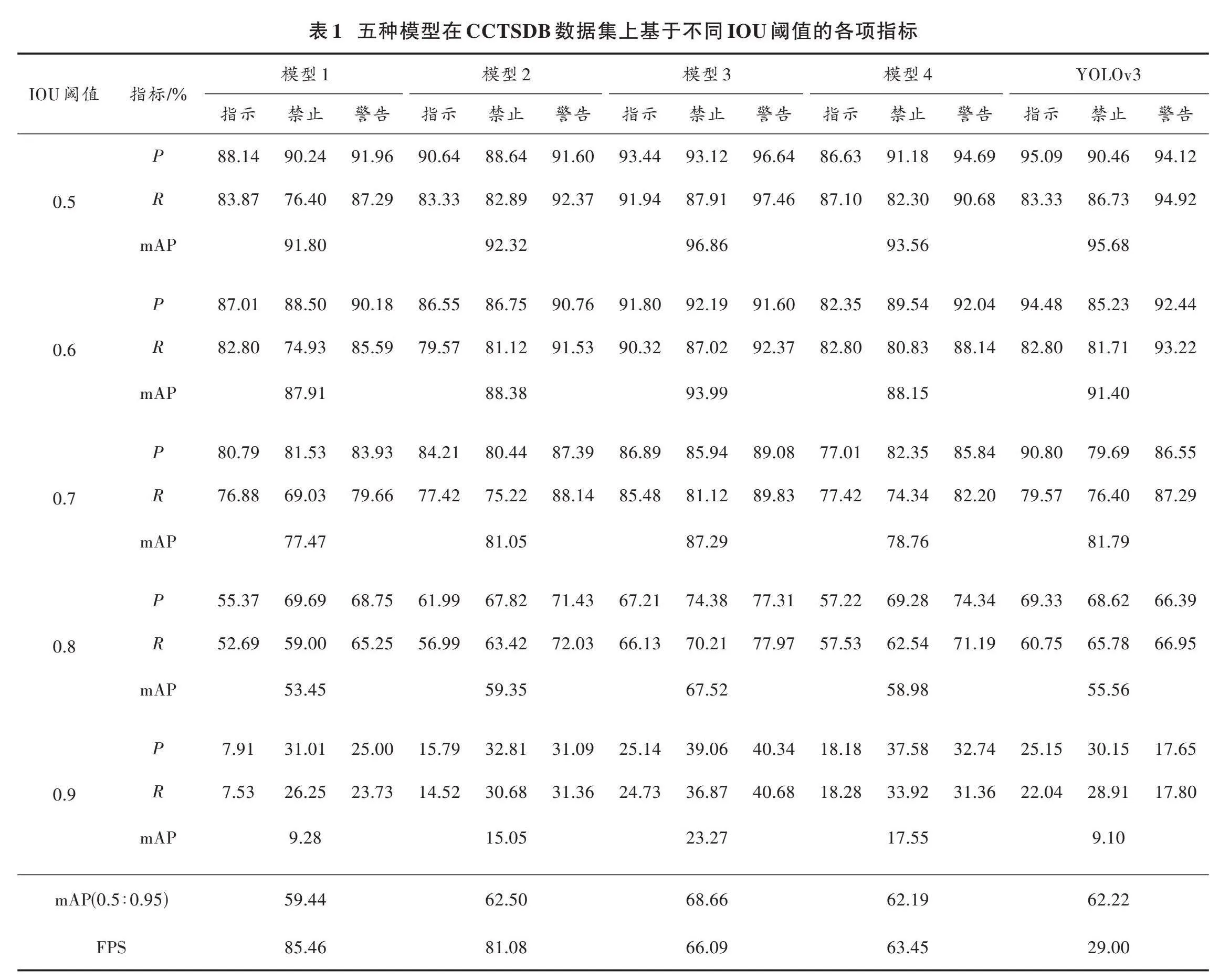
本文將3.4節中設置的4個模型和YOLOv3模型在CCTSDB數據集上一起進行評估。如表1所示,列出了5個模型在不同IOU閾值下的mAP值、三個類別交通標志的[P]、[R]值。設定IOU閾值的范圍為0.5~0.9,變化步長為0.1。
從表1可知,不管IOU是多少,模型1~模型3的[P]值、[R]值、mAP值都在穩步提升。這說明雙向嵌套級聯殘差單元在特征提取和特征融合方面都是有效的。[R]值的提升幅度比[P]值更大,而[R]值的增加,意味著有更多的正樣本被找了出來,這對于提升模型的精度有較強的潛在影響。
比較模型1和模型2可知,加大級聯殘差塊的深度差使模型精度提升3.06%;比較模型2和模型3可知,將雙向嵌套級聯殘差單元應用于特征融合,其帶來的性能提升比單純增加兩個級聯殘差塊的深度差更大,精度提升6.16%;模型4在不同IOU閾值下的所有指標均出現了退化,這說明CRC模塊確實為主干網絡提供了一個信息密度更大的輸入,從而提升了整個模型的性能。比較模型3和YOLOv3模型的結果可知,在低IOU閾值時,YOLOv3模型的[P]值超過了模型3,但是隨著IOU閾值的增大,模型3的[P]值逐步反超了YOLOv3模型。而更重要的是,模型3的[R]值始終遠遠大于YOLOv3模型,[R]值單類別的平均增幅為31.28%。選擇IOU=0.5時的模型3作為本文提出的最優模型。
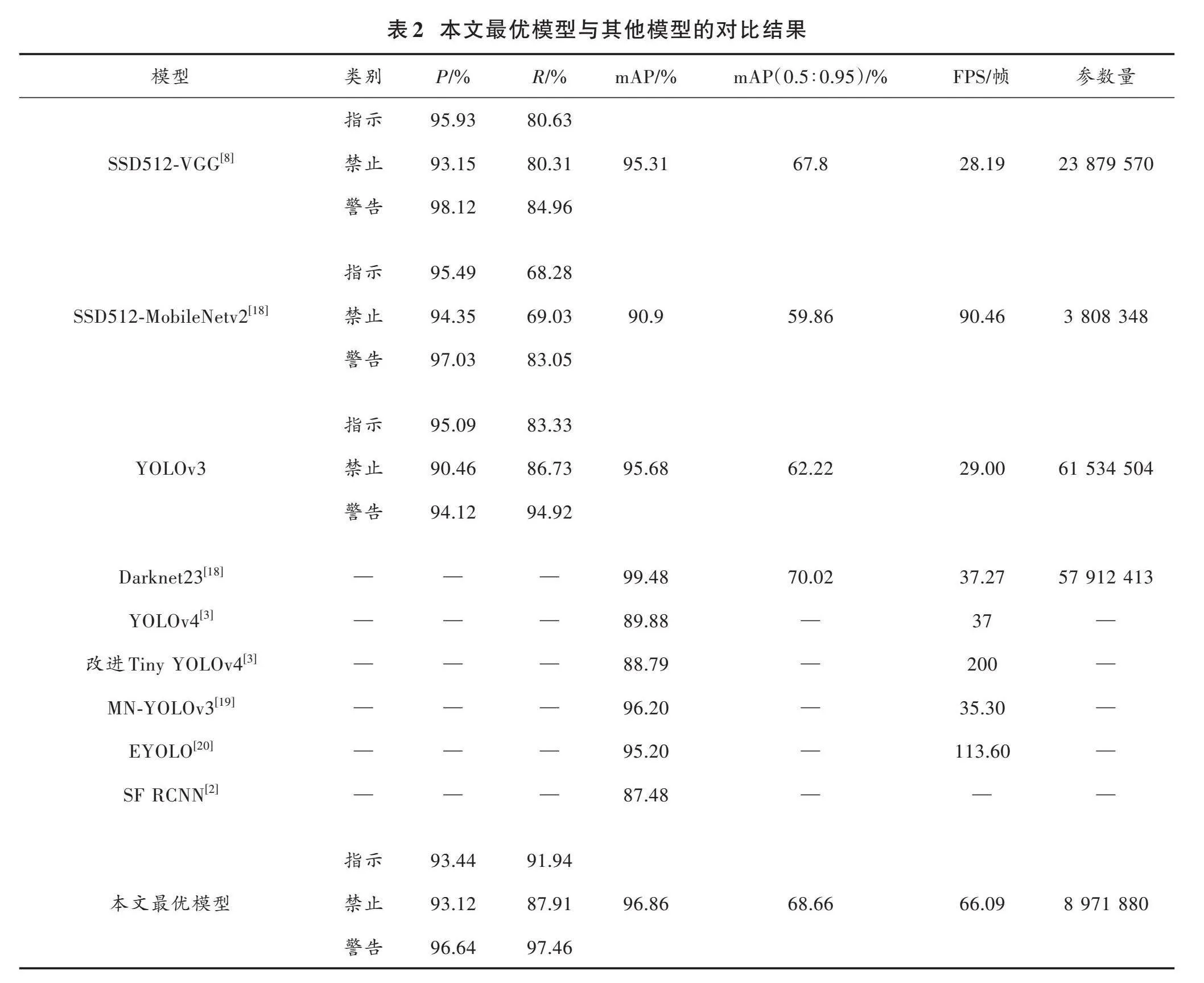
本文還測試了一些單階段和雙階段目標檢測算法,對比結果如表2所示。
由表2可知,無論是SSD還是FasterRCNN,在性能表現上都有明顯的偏向,SSD算法[R]值偏低,FasterRCNN算法雖然在[R]值上取得了3個最大值,但是單類別[P]值基本上都是低于50%。改進的Tiny YOLOv4模型的mAP指標為88.79%,排在第五的位置,但是FPS遠超其他模型,比第二名的90.46幀提升了一倍多。而本文所提出的最優模型[P]值和[R]值都不是最高的,但都取得了不錯的數據,除了禁令標志的[R]值為87.91%之外,其余的[P]、[R]值都在90%以上。在綜合[P]、[R]值結果的mAP指標上,本文所提出的最優模型是最好的。FPS指標也排在第三的位置。
5" 結" 語
本文將YOLOv3算法起始階段的下采樣卷積操作換成了本文提出的跨區域壓縮模塊,一方面為主干網絡提供了一個融合周圍區域通道信息的輸入,另一方面壓縮后的特征圖在通道數量上翻了9倍,信息密度更大。使用4個雙向嵌套級聯殘差單元替代原網絡中的5組級聯殘差塊。雙向嵌套級聯殘差單元相比單純的堆疊標準殘差塊擁有更強的特征提取和特征融合能力,但是運算量和參數量反而變小了。另外,雙向嵌套級聯殘差單元也部署到了頸部網絡,用于特征融合。相比于YOLOv3算法,本文提升了頭部網絡3個側輸出的尺度,將預測框的數量增加了一倍多,從實驗結果看,增加了召回率。
注:本文通訊作者為鐘國韻。
參考文獻
[1] 薛搏,李威,宋海玉,等.交通標志識別特征提取研究綜述[J].圖學學報,2019,40(6):1024?1031.
[2] 劉萬軍,李嘉欣,曲海成,等.基于多尺度卷積神經網絡的交通標示識別研究[J].計算機應用研究,2022,39(5):1557?1562.
[3] 張小雪,黃巍.基于改進的Tiny?YOLOv4快速交通標志檢測算法[J].電子設計工程,2022,30(19):139?143.
[4] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2014: 580?587.
[5] REN S Q, HE K M, GIRSHICK R, et al. Faster R?CNN: Towards real?time object detection with region proposal networks [J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137?1149.
[6] CAI Z W, VASCONCELOS N. Cascase R?CNN: Delving into high quality object detection [EB/OL]. [2018?08?31]. https://www.doc88.com/p?3292522358799.html.
[7] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real?time object detection [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 779?788.
[8] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detextor [EB/OL]. [2018?08?10]. https://download.csdn.net/download/qq_31329259/10594621?utm_source=iteye.
[9] 徐正軍,張強,許亮.一種基于改進YOLOv5s?Ghost網絡的交通標志識別方法[J].光電子·激光,2023,34(1):52?61.
[10] 陳德海,孫仕儒,王昱朝,等.一種改進YOLOv3的交通標志識別算法[J].河南科技大學學報(自然科學版),2022,43(6):31?36.
[11] 喬歡歡,權恒友,邱文利,等.改進YOLOv5s的交通標志識別算法[J].計算機系統應用,2022,31(12):273?279.
[12] 李文舉,張干,崔柳,等.基于坐標注意力的輕量級交通標志識別模型[J].計算機應用,2023,43(2):608?614.
[13] REDMON J, FARHADI A. YOLOv3: An incremental improvement [EB/OL]. [2018?08?13]. http://arxiv.org/abs/1804.02767.
[14] REDMON J, FARHADI A. YOLO9000: Better, faster, stronger [C]// IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2017: 6517?6525.
[15] SANDLER M, HOWARD A, ZHU M L, et al. MobileNetV2: Inverted residuals and linear bottlenecks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2018: 4510?4520.
[16] HE K M, ZHANG X Y, REN S Q. Deep residual learning for image recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2016: 770?778.
[17] 李旭東,張建明,謝志鵬,等.基于三尺度嵌套殘差結構的交通標志快速檢測算法[J].計算機研究與發展,2020,57(5):1022?1036.
[18] 杜婷婷,鐘國韻,江金懋,等.基于Darknet23和特征融合的交通標志檢測方法[J].電子技術應用,2023,49(1):14?19.
[19] 張達為,劉緒崇,周維,等.基于改進YOLOv3的實時交通標志檢測算法[J].計算機應用,2022,42(7):2219?2226.
[20] 王浩,雷印杰,陳浩楠.改進YOLOv3實時交通標志檢測算法[J].計算機工程與應用,2022,58(8):243?248.
[21] ZHANG J M, WANG W, LU C Q, et al. Lightweight deep network for traffic sign classification [J]. Annals of telecommunications, 2020, 75(7/8): 369?379.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
