基于動態聚類的個性化聯邦學習與模塊化組合策略
2024-09-19 00:00:00周洪煒馬源馬旭
現代信息科技 2024年13期






摘 要:提出一種基于動態聚類的個性化聯邦學習方法來解決聯邦學習下數據異構的問題。此方法將優化目標向量與凝聚聚類算法相結合,在保證節省計算資源的同時,將數據差異較大的客戶端動態劃分到不同的集群中。此外,出于對訓練模型可持續使用的考慮,進一步提出模塊可組合策略,新的客戶端只需將之前訓練模型組合便可以得到一個適合本地任務的初始模型。客戶端只需在該初始模型上進行少量訓練便可以應用于本地任務。在Cafir-10和Minst數據集上,其模型的精確度要優于本地重新訓練模型的精度。
關鍵詞:聯邦學習;個性化;深度神經網絡;可組合;動態聚類
中圖分類號:TP181 文獻標識碼:A 文章編號:2096-4706(2024)13-0061-05
Personalized Federated Learning Based on Dynamic Clustering and Modular Combinatorial Strategy
ZHOU Hongwei, MA Yuan, MA Xu
(Qufu Normal University, Qufu 273165, China)
Abstract: This paper proposes a personalized federated learning method based on dynamic clustering to address the issue of heterogeneous data in Federated Learning. This method combines the optimization target vector with the agglomerative clustering algorithm, dynamically divides clients with significant data differences into different clusters while conserving computing resources. Furthermore, in consideration of the sustainability of training models, the paper further proposes a modular combinatorial strategy, where new clients only need to combine previously trained models to obtain an initial model suitable for local tasks. The client only needs to perform a small amount of training on this initial model to apply it to local tasks. On the Cafir-10 and Minst datasets, the model's accuracy is superior to that of locally retrained models.
Keywords: Federated Learning; personalization; Deep Neural Network; combinatorial; dynamic clustering
0 引 言
傳統的中心化機器學習需要客戶端將本地的數據上傳到服務器,并由服務器利用手機的數據完成模型的訓練,然而數據離開了本地往往會造成第三方對于個人隱私數據的濫用。因此聯邦平均算法[1]于2016年被谷歌學術提出,聯邦平均算法作為經典分布式機器學算法可以使得客戶端訓練數據在不離開本地情況下完成模型的訓練,這有助保護客戶端數據的隱私和安全。因此聯邦學習被廣泛應用于醫療[2]、物聯網[3-4]等領域。然而,一般的聯邦學習算法面臨客戶端數據異構的情況時,通常訓練的模型收斂過慢甚至模型可用性差。因此個性化聯邦學習被提出來應對上述挑戰。常見的個性化聯邦學習方案有基于正則損失的聯邦學習、基于參數解耦的個性化聯邦學習以及基于個性化掩碼的聯邦學習等。基于正則損失的聯邦學習是通過在本地優化目標上添加正則損失來約束本地優化,防止本地過擬合提高模型的泛化能力[5]。參數解耦則是通過將客戶端模型拆分基礎層和個性層,通過共享基礎層參數提高模型泛化能力同時,本地對個性化層的訓練來提高模型個性化能力[6]。個性化掩碼則需要利用本地個性化掩碼對于全局模型進行裁剪來得到適用于本地任務的模型[7]。盡管上述方案在一定程度上能夠緩解數據異構帶來的挑戰,但是面對客戶端數據差異較大的學習場景仍然表現不理想。因此近年來,基于客戶端聚類個性化聯邦學習方案被提出來解決上述的挑戰。基于客戶端聚類的主要思想是通過將數據差異較大客戶端分到不同集群中去,來減少同一集群內部的數據異構性。為了能有效地將相似度客戶端分到同一集群中,迭代聯邦聚類算法[8]與軟聚類聯邦學習算法[9]提出依據不同集群模型在客戶端的表現來確定客戶端所屬的集群,但是需要一定的先驗知識預先確定客戶端分組的數量。在實際應用中獲取這些先驗知識通常是困難的。因此,聚類聯邦學習算法[10]提出通過計算客戶端模型梯度之間的相似度對客戶端集群進行遞歸二分類,這使得服務器無須預先確定客戶端模型分組的數量。此外,層次聚合聯邦學習算法[11]利用客戶端模型參數之間的相似性對客戶端進行層次凝聚聚類。然而,上述動態分組都依賴于計算客戶端模型參數或者梯度的相似性,這是十分耗費服務器計算資源的。除此之外,以往的個性化聯邦學習都忽略模型的可重復利用。新的客戶端如果想要得到一個個性化模型需要從頭開始訓練,這通常造成計算資源極大的浪費。為了解決上述問題,本文提出了一種可以為服務器節省計算開銷的動態聚類個性化聯邦學習算法,并且提供了一個模塊組合策略來提高模型利用率。
1 方案設計
1.1 框架設計
本文框架由服務器和客戶端兩大部分構成。根據動態聚類個性化聯邦學習算法和模塊可組合策略,本文將客戶端進一步分為兩類:一類是訓練客戶端,另一類是測試客戶端。在動態聚類個性化聯邦學習算法中,訓練客戶端和服務器被用于訓練出若干個組模型。在可組合策略中,測試客戶端(新客戶端)需要對動態聚類個性化聯邦學習算法中生成的若干個組模型作為模塊進行篩選并組合。動態聚類個性化聯邦學習算法的優化目標可以表示為:
其中,m表示動態聚類個性化聯邦學習算法得到的模塊數量。?i表示i-th訓練客戶端本的損失函數,Di則表示i-th客戶端本地數據集。模塊組合策略的優化目標可以表示為:
其中,?test表示測試客戶端本地的損失函數。Dtest則表示測試客戶端本地數據集。
1.2 動態聚類個性化聯邦學習算法
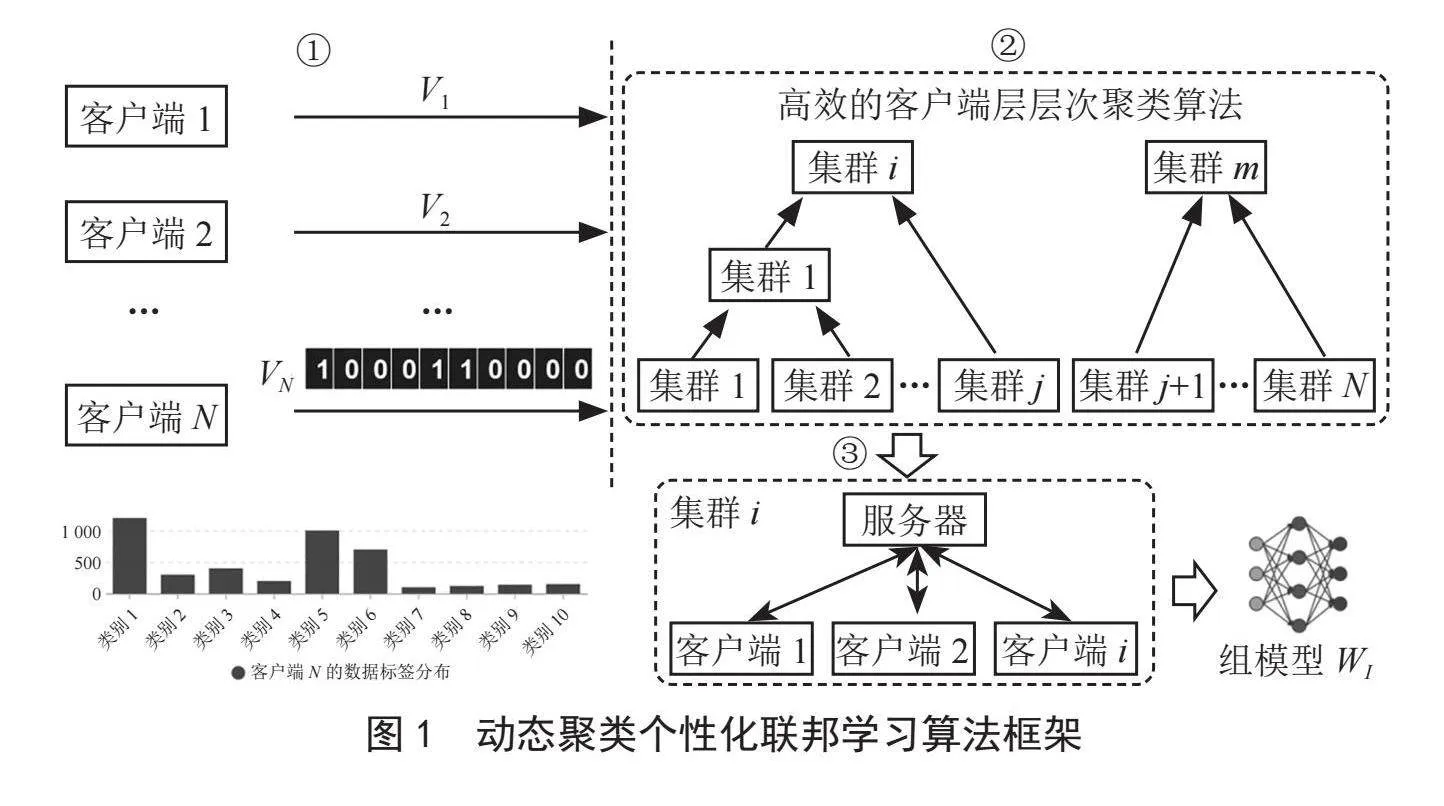
動態聚類個性化聯邦學習算法使用層次凝聚聚類對數據異構的客戶端進行動態分組。為了節省計算開銷,我們通過衡量優化目標向量之間的相似性來代替衡量模型參數之間相似性,算法框架如圖1所示。
第一階段:客戶端會生成一個優化目標向量Vi,該向量長度和全局數據集類別數量一致。如果客戶端第j個類別數據占比高,客戶端Ci會將Vi的第j維度設置為1,否則設置為0。在這里我們預先設置一個k值,客戶端將本地數據占比最高的前k個類別對應的優化目標向量維度設置為1。隨后客戶端將優化目標向量上傳到服務器。需要注意的是,客戶端僅需要向服務器傳輸一次優化目標向量。
第二階段:服務器在接收客戶端的優化目標向量后首先對客戶端進行分組。為了描述清晰,這里我們將服務器分組過程劃分為三步:1)服務器計算每個簇的優化目標向量。具體來說,服務器對一個簇中的客戶端優化目標向量加和,然后對加和后的結果取前k個最大值并將其對應的維度設置為1,其他維度設置為0。2)計算每個簇之間優化目標向量的相似度s。具體來說,服務器對任意兩個簇的優化目標向量并進行按位與操作,最后服務器記錄按位與結果中每一維的值相加來作為簇之間的相似度s(1≤s≤c,s ∈ Z),c表示全局數據集樣本類別數量。3)服務器合并相似度最大的兩個簇,并按照上一步計算新簇的優化目標向量。重復上述步驟直到簇之間的最小相似度滿足s≤a,a是一個預先設定的值,停止組的合并得到m個分組。
第三階段:隨后對于同一組中的客戶端進行聯邦訓練。具體來講,在t-th輪服務器和客戶端交互中,服務器將組模型 下發給客戶端ci,客戶端ci在本地數據集 上通過隨機梯度下降算法對本地模型進行更新:
其中,?表示本地的交叉熵損失函數,η表示學習率。然后,客戶端將更新后模型 上傳到服務器進行聚合:
其中,|C|表示當前客戶端集群的大小。服務器和客戶端持續上述操作直到模型收斂。
1.3 模塊組合策略
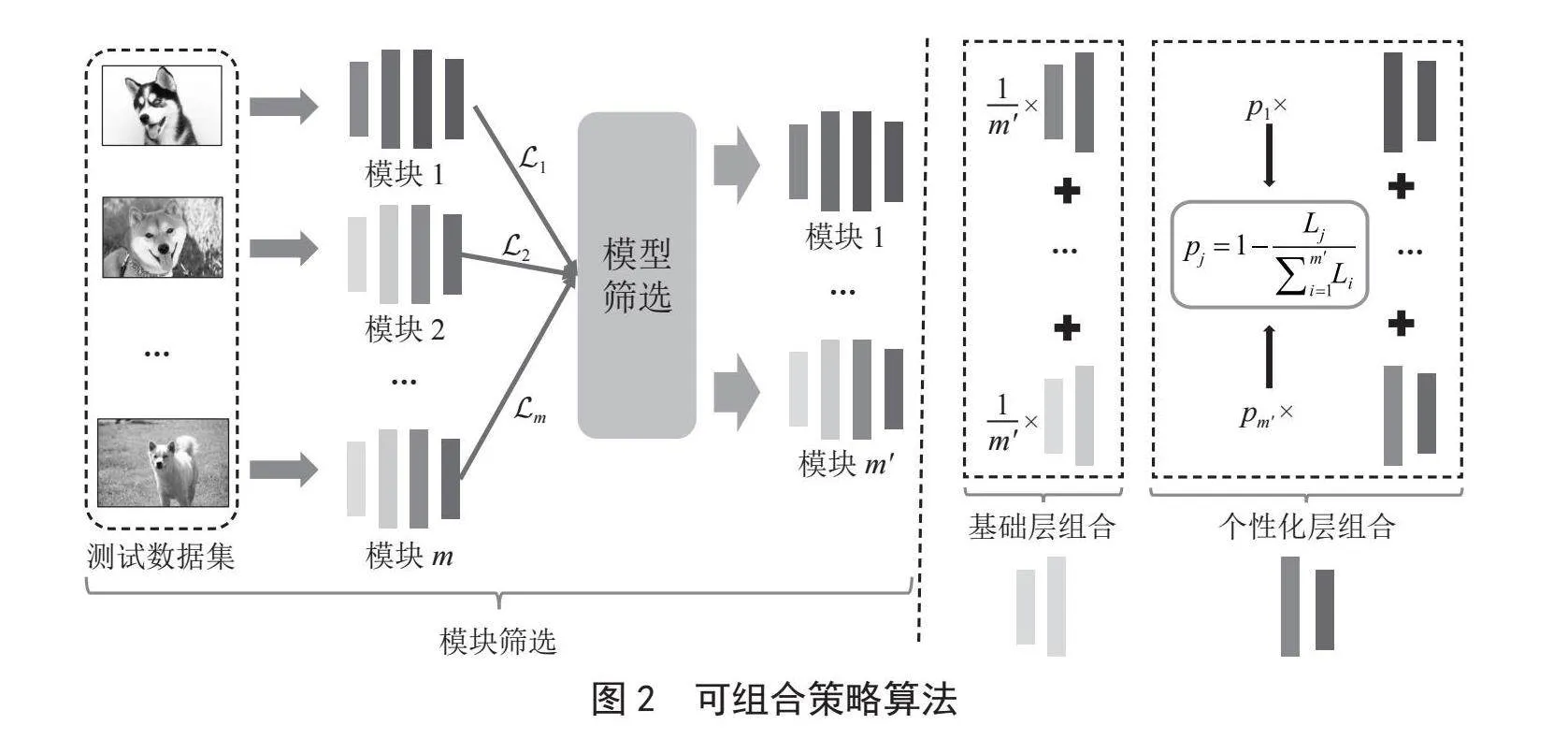
測試客戶端通過模塊組合算法負責將訓練好的m個組模型進行篩選和組合。如圖2所示,測試客戶端首先從服務器獲取m個組模型w1,w2,…,wm,并利用本地的測試集對m個模塊分別計算損失L1,L2,…,Lm。測試客戶端依據計算損失從小到大對組模型進行排序。取m'個損失最小的模塊w1,w2,…,wm',m'≤m。測試客戶端對這m'個模塊進行聚合。在本地更新階段,需要將組合后的模型作為初始模型,并進行微調。這樣不但節省了本地的計算開銷,同時能夠提升本地模型的性能。這是因為,這m'個模型都和本地任務具有一定的相關性,并且這些模塊在此之前都在更為豐富的數據集上進行了訓練。
為了進一步減少測試客戶端計算開銷,我們從模型參數解耦角度出發將m'個模塊分為“基礎層+個性化層”(靠近輸入層部分的模型稱為基礎層wbase,靠近輸出層部分的模型稱為個性化層wperson)。在深度學習過程中,基礎層被認為用于公共特征的提取,而個性化層則被用于本地任務的個性化決策。在模塊聚合時,測試客戶端m'個模塊的前i層作為基礎層并執行平均聚合操作:
對于個性化層的模型參數,測試客戶端需要進行個性組合:
其中,pj表示第j個模塊個性化層組合時的系數,然而如何設置pj是一個比較關鍵的問題,這將直接影響到組合后模型的性能。為了解決這個問題,本文提出將模塊篩選過程得到的損失來作為聚合權重的依據。具體來說,損失越小意味,該模塊越接近于本地的訓練任務,在組合過程中對應的權重值pj應該越大。pj計算過程可以表示為:
測試客戶端通過對m'個模塊聚合得到的模型wnew,可以表示為:
測試客戶端利用本地的數據集通過預先設定好學習率η的隨機梯度下降對wnew進行微調。由于對 聚合時,不同模塊的公共層是近似的,為了減少本地模型訓練的計算開銷,測試客戶端僅對聚合后的個性化層 進行更新:
2 實驗分析
2.1 實驗設置
在本文中,我們選取Minist和Cafir10作為實驗數據集。Minist是一個10分類的手寫字體圖片數據集,總共有70 000張樣本。Cafir10是一個10分類的圖片數據集,總共有60 000張樣本。這兩個數據集在訓練客戶端上是非獨立同分布的。本文在兩個數據集上均設置20個訓練客戶端。遵循常見的數據異構實驗設置[8],預先將這些客戶端劃分為4個組,服務器選取2~3個類別的樣本被分配給每個組的訓練客戶端。所有的數據都被拆分為70%的訓練集和30%的測試集。本文選取Letnet-5深度神經網絡來訓練Minist數據集和CAFIR-10數據集。Letnet-5由兩層卷積層、兩層池化層以及三層全連接層構成。此外,隨機選取2~3個類別測試客戶端的本地數據集。為了公平,測試客戶端本地數據集樣本數量和訓練客戶端本地數據集樣本數量保持一致。服務器與客戶端交互次數我們設置為150輪,本地客戶端更新周期e設置為5。學習率η設置為0.01,動態聚類閾值a設置為1。
2.2 個性化聯邦學習算法性能評估
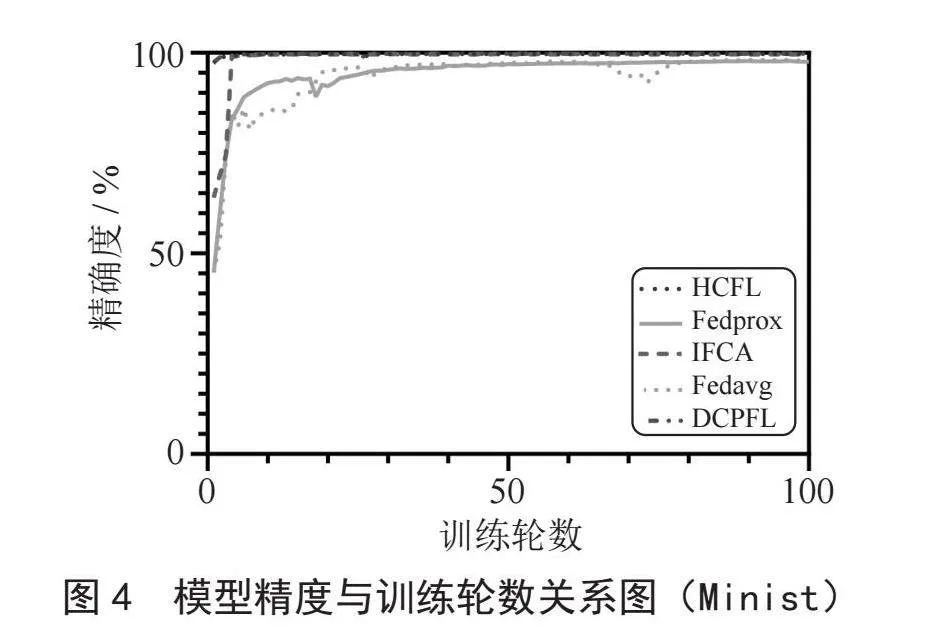
在本節中我們通過與本地訓練算法(Local)、聯邦平均算法(Fedavg)[1]以及流行的迭代聯邦聚類算法(IFCA)[8]、正則損失聯邦學習算法(fedprox)[5]、層次聚合聯邦學習算法(HCFL)[11]進行了模型的準確度對比,來說明我們動態分組聚類算法(DCPFL)的有效性。如表1所示,我們將上述算法得到的模型測試精度進行了對比。從圖3和圖4中不難看出,在明顯的客戶端數據差異下,我們的方案要優于其他大部分的個性化學習方案。此外我們發現,DCPFL和HCFL收斂得更快,這是因為兩者預先對客戶端集群完成了劃分,同一集群內數據異構性顯著下降進而導致模型收斂速度要優于其他方案。
盡管IFCA和FLHC在精確度上與DCPFL精度接近,但是DCPFL每次每個客戶端僅需要傳輸一個模型即可,IFCA需要傳輸K個模型(K與預先設定的組的數量相關,在這里我們預先設置K = 4),因此相對于IFCA,DCPFL更節省通信開銷。因為HCFL需要通過計算模型參數之間的相似性進行層次聚類,而DCPFL僅需要依靠本地的優化目標向量的相似便可以完成聚類。不難發現優化目標向量遠小于模型參數向量,因此DCPFL將比HCFL客戶端分組算法更節省計算開銷。
2.3 模塊組合策略性能評估
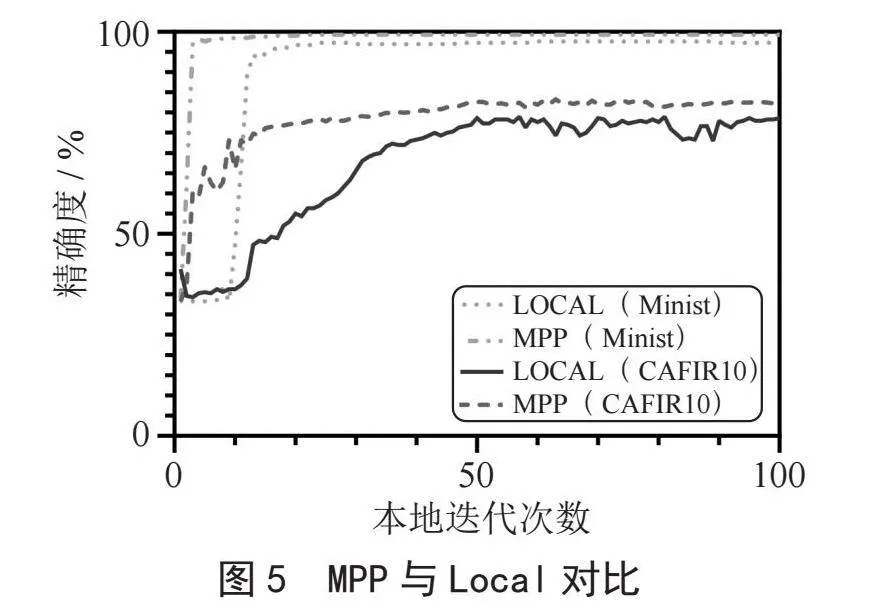
在本節,為了驗證模塊組合策略有效性,我們將測試客戶端采用模塊組合策略訓練過程和本地訓練過程進行了對比。從圖5中可以看出模塊組合策略下客戶端模型收斂得更快,并且最終模型的準確率更高。由于相對本地更新全部的模型參數來講,模塊組合策略僅需要更新個性化層參數,這樣不僅使得本地模型性能有了提升,還極大節省了客戶端計算開銷。
3 結 論
在本文中,我們提出了動態客戶端聚類個性化聯邦學習算法和模塊組合策略,來提高數據異構場景下模型的可用性和可重復利用性。相對于經典的個性化聯邦學習算法,我們不僅提高了模型精確度,同時極大節省了服務器和新客戶端的計算開銷。然而,本文提出的聚類算法目前僅適合客戶端數據差異明顯的簡單場景。并且模塊組合策略要求新的客戶端的任務和訓練模塊的任務接近。因此在未來工作中,我們將進一步改進客戶端聚類算法和模塊組合策略,以適合更為復雜的數據異構場景和實現不同領域任務下的知識遷移。
參考文獻:
[1] MCMAHAN B H,MOORE E,RAMAGE D,et al. Communication-Efficient Learning of Deep Networks from Decentralized Data [J/OL].arXiv:1602.05629 [cs.LG].(2023-01-23)[2023-11-20].https://arxiv.org/abs/1602.05629.
[2] TERRAIL J O,AYED S S,CYFFERS E,et al. FLamby: Datasets and Benchmarks for Cross-Silo Federated Learning in Realistic Healthcare Settings [J/OL]arD3K3QSY+lDrXVx8V8KOkxTITapOBWpYHhRZzsd9ISjc=Xiv:2210.04620 [cs.LG].(2023-05-05)[2023-11-20].https://arxiv.org/abs/2210.04620.
[3] KHAN L U,SAAD W,HAN Z,et al. Federated Learning for Internet of Things: Recent Advances, Taxonomy, and Open Challenges [J].IEEE Communications Surveys & Tutorials,2021,23(3):1759-1799.
[4] SUN W,LEI S Y,WANG L,et al. Adaptive0YJ1MMDr40pjfFRhPEOfe2TRhxOaZSEY7PPJ6F8+gWI= Federated Learning and Digital Twin for Industrial Internet of Things [J].IEEE Transactions on Industrial Informatics,2020,17(8):5605-5614.
[5] LI T,SAHU A K,ZAHEER M,et al. Federated Optimization in Heterogeneous Networks [J/OL]. arXiv:1812.06127 [cs.LG].(2020-04-21)[2023-11-20].https://arxiv.org/abs/1812.06127v5.
[6] ARIVAZHAGAN M G,AGGARWAL V,SINGH A K,et al. Federated Learning with Personalization Layers [J/OL].(2019-012-02)[2023-11-26].https://arxiv.org/abs/1912.00818.
[7] HUANG T S,LIU S W, SHEN L,et al. Achieving Personalized Federated Learning with Sparse Local Models [J/OL].arXiv:2201.11380 [cs.LG].(2022-02-27)[2023-11-26].https://arxiv.org/abs/2201.11380.
[8] GHOSH A,CHUNG J C,YIN D,et al. An Efficient Framework for Clustered Federated Learning [J].IEEE Transactions on Information Theory,2022,68(12):8076-8091.
[9] LI C X,LI G,VARSHNEY P K. Federated Learning With Soft Clustering [J].IEEE Internet of Things Journal,2022,9(10):7773-7782.
[10] SATTLER F,MüLLER K R,SAMEK W. Clustered Federated Learning: Model-Agnostic Distributed Multitask Optimization Under Privacy Constraints [J].IEEE Transactions on Neural Networks and Learning Systems,2021,32(8):3710-3722.
[11] BRIGGS C,FAN Z,ANDRAS P. Federated Learning with Hierarchical Clustering of Local Updates to Improve Training on Non-IID Data [C]//2020 International Joint Conference on Neural Networks (IJCNN).Glasgow:IEEE,2020:1-9.
作者簡介:周洪煒(1998.12—),男,漢族,山東濰坊人,碩士在讀,研究方向:聯邦學習、機器學習;馬源(1997.05—),男,漢族,山東青島人,碩士在讀,研究方向:聯邦學習、機器學習;馬旭(1985.05—),男,漢族,山東濟寧人,教授,博士,研究方向:電子信息、機器學習隱私保護、聯邦學習。
