基于水利工程運行管理數據的數據平臺建設研究
2024-09-19 00:00:00梁遠想張軍琿李永勝申超群裴帥
現(xiàn)代信息科技 2024年13期



摘 要:文章對水利工程水庫運行管理數據使用場景進行分析,從水庫運行管理數據分析的現(xiàn)狀和問題出發(fā),發(fā)現(xiàn)傳統(tǒng)手段在數據處理和分析效率上存在瓶頸,無法滿足復雜的管理需求,利用互聯(lián)網相關大數據開源組件(DataX、Dinky、Doris、MinIO)對水利工程水庫運行管理的數據平臺進行了建設研究。通過大壩安全監(jiān)測數據極值取值場景實例應用,驗證數據平臺的有效性和實用性。
關鍵詞:水利工程;數據平臺;大數據;數據分析
中圖分類號:TP311 文獻標識碼:A 文章編號:2096-4706(2024)13-0096-07
Research on the Construction of Data Platform Based on Operational
Management Data in Hydraulic Engineering
LIANG Yuanxiang1, ZHANG Junhui1,2, LI Yongsheng1, SHEN Chaoqun1, PEI Shuai1
(1.Yunhe(Henan)Information Technology Co., Ltd., Zhengzhou 450003, China;
2.Yellow River Engineering Consulting Co., Ltd., Zhengzhou 450003, China)
Abstract: The paper analyzes the usage scenarios of reservoir operational management data in hydraulic engineering. Starting from the current state and issues of reservoir operational management data analysis, it is found that traditional methods face bottlenecks in data processing and analysis efficiency, unable to meet complex management requirements. The research focuses on the construction of a data platform for the reservoir operational management of hydraulic engineering, utilizing internet-related Big Data open-source compmqnBWWmHb1FzH5did/zsi0WMsOuX68LHq8EyiXmriag=onents such as DataX, Dinky, Doris, and MinIO. Through practical application examples in extreme value scenarios of dam safety monitoring data, the effectiveness and practicality of the data platform are validated.
Keywords: hydraulic engineering; data platform; Big Data; data analysis
0 引 言
隨著水利行業(yè)的快速發(fā)展和數字化轉型的推進,對于數據的需求和依賴程度越來越高。堅持數字賦能。要求業(yè)務部門要善于用數據說話、用數據管理、用數據決策,推動水利業(yè)務智能化,發(fā)揮數字化、網絡化、智能化對水 利現(xiàn)代化的加速器、催化劑作用,推進水利決策科學化、水利治理管理精細化、水利公共服務高效化[1]。
數據底板[2]是流域數字化映射的成果、數字化場景構建的基礎和實現(xiàn)山洪災害監(jiān)測預報預警平臺“四預”功能的重要基礎和支撐載體。而大數據平臺的穩(wěn)定性和技術的先進性是一切業(yè)務應用的基礎條件[3]。且數字孿生水利工程管理系統(tǒng)以提升工程建設管理過程中數字化、網絡化、智能化為主線,以數字化場景、智慧化模擬、精準化決策為路徑,以數字底板、模型平臺、業(yè)務應用系統(tǒng)為支撐,實現(xiàn)工程建設管理過程中數字工程與物理工程同步仿真建設[4]。
水利數據平臺的建設可以整合和共享水利行業(yè)的數據資源,提高數據利用效率和數據質量。然而建設高效、統(tǒng)一、開放的水資源數據管理系統(tǒng),實現(xiàn)水資源多源數據融合面臨諸多挑戰(zhàn)[5]。互聯(lián)網業(yè)界通用做法通過數據平臺數據共享和整合,打破數據壁壘,消除“數據孤島”和“數據煙囪”,實現(xiàn)數據治理的統(tǒng)籌與協(xié)調,進而提高數據資源的利用效率[6]。這不僅可以降低數據采集和處理的成本,還可以提高數據的價值和效益。
企業(yè)數字化轉型有利于提高企業(yè)的內部控制質量與盈利能力,從而有效緩解了市場不確定性與現(xiàn)金流預期不確定性對于企業(yè)固定資產投資的抑制作用,激勵了企業(yè)進行固定資產投資[7]。數字化轉型是水利行業(yè)發(fā)展的必然趨勢,而水利數據平臺的建設是數字化轉型的重要支撐。通過數字化轉型,可以推動水利行業(yè)的信息化水平提升,提高水利行業(yè)的競爭力和可持續(xù)發(fā)展能力。水利數據平臺的建設可以為數字化轉型提供強大的數據支持,推動水利行業(yè)的數字化轉型進程。水利行業(yè)的發(fā)展、云計算技術的發(fā)展、數字化轉型的需求、數據共享和整合的需求以及提高管理效率和決策水平的需求。在這樣的背景下,水利數據平臺的建設變得越來越必要和緊迫,可以為水利行業(yè)的可持續(xù)發(fā)展提供強大的數據支持。
1 平臺整體架構
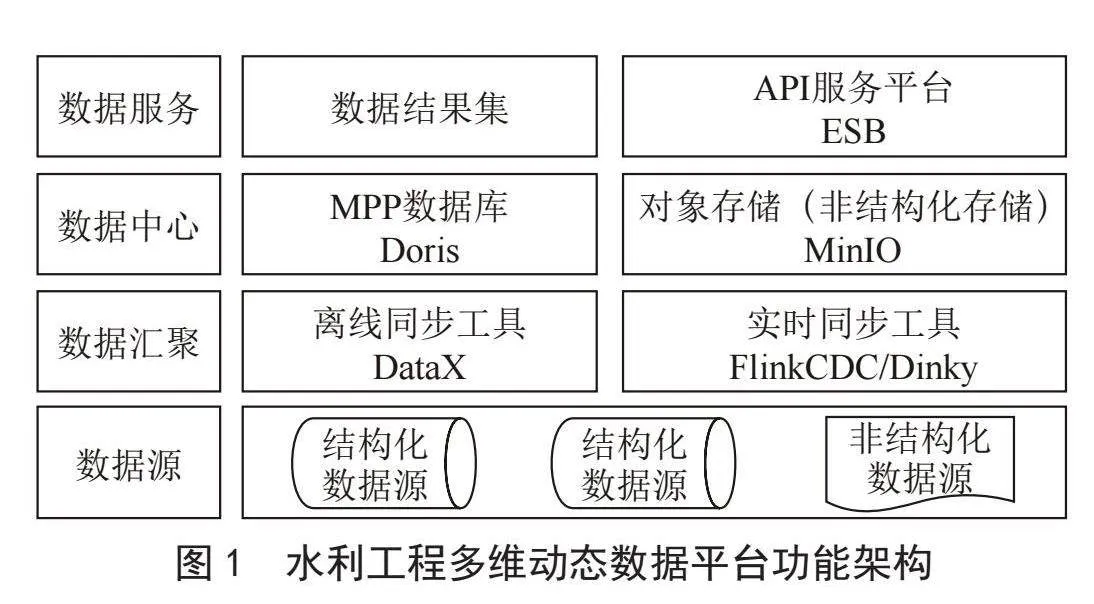
在傳統(tǒng)的煙囪式IT架構中,各系統(tǒng)從后端到前端相互獨立,緊耦合開發(fā),導致系統(tǒng)臃腫、建設效率低、 無法快速響應業(yè)務,且存在大量重復建設工作。為解決上述問題,需要整合出一個中間組織,為所有的項目提供一些公共資源。這個中間組織即為“中臺”,其中,匯聚數據資源,統(tǒng)一提供數據及相關服務的就是“數據平臺”[8]。
數據平臺的功能模塊包括數據采集、數據處理、數據存儲、數據服務等。其中,數據采集模塊支持多種數據源的接入,如傳感器、發(fā)電站、氣象站等;數據處理模塊具備強大的數據處理能力,能夠對大量數據進行快速分析和處理[9];數據存儲模塊采用高性能的分布式存儲系統(tǒng),確保數據的可靠性和完整性;數據服務則提供數據結果集及API接口調用,方便用戶進行數據分析和決策。
數據平臺的技術實現(xiàn),數據平臺采用先進的數據采集和處理技術,能夠實時監(jiān)測水庫的水位、流量、水質等指標,并將監(jiān)測數據傳輸到數據中心進行處理和分析。同時,數據平臺還采用了可視化技術,將數據以直觀易懂的方式展示給用戶。此外,數據平臺還采用了安全技術,確保數據的安全性和可靠性。數據平臺的技術選型及基本功能架構如圖1所示。
2 數據處理流程設計
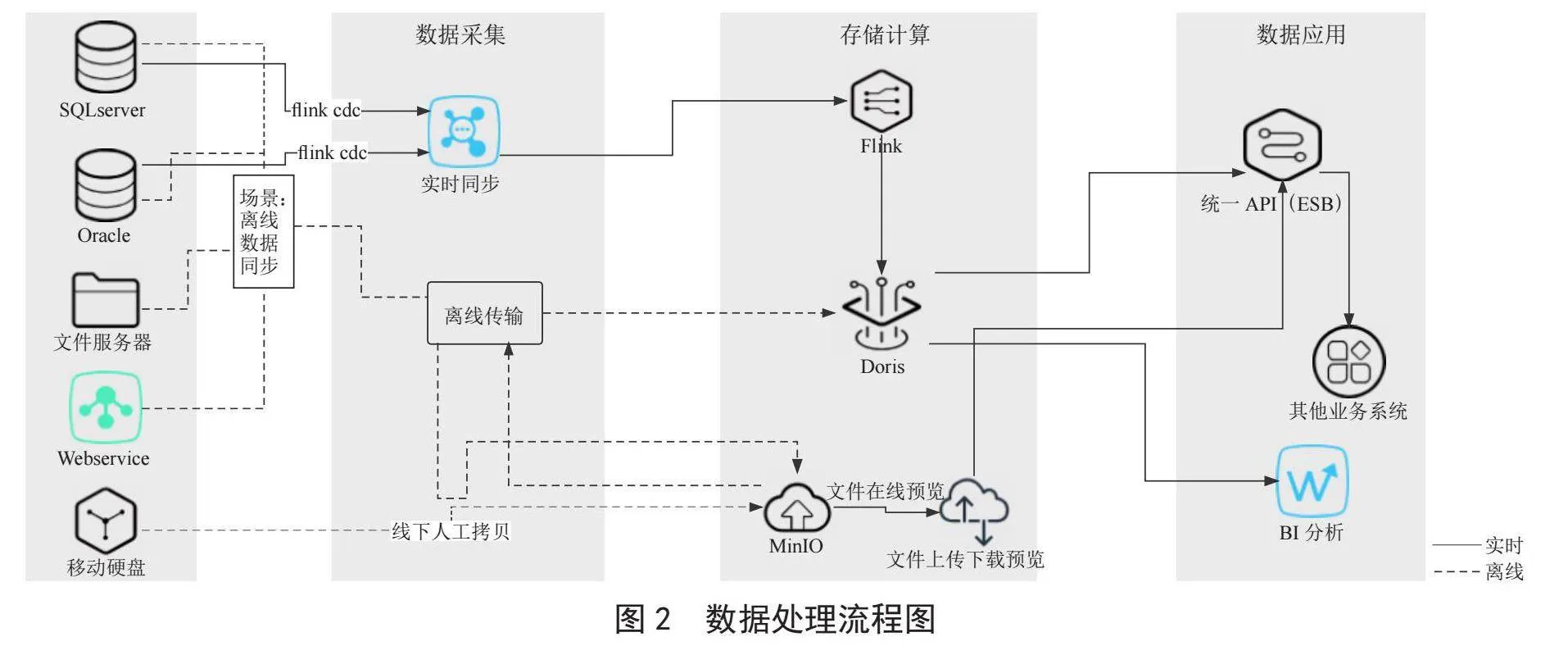
數據平臺包括數據匯聚與融合、數據存儲、數據計算與應用4部分內容。建設統(tǒng)一的數據標準和數據資源管理,將各個業(yè)務系統(tǒng)的數據進行清洗、交換、處理和加載[10]。
2.1 數據采集
在大數據處理的流程中,數據采集是第一步。數據采集自各種來源,包括數據庫、社交媒體、物聯(lián)網設備等。這個過程需要用到各種數據抽取工具和技術,如ETL(Extract-Transform-Load)等,以從各種數據源中抽取、轉換和加載數據。
2.2 數據存儲
采集來的大量數據需要被安全、可靠地存儲起來,以供后續(xù)的計算和分析使用。這通常需要使用到分布式文件系統(tǒng),結構化數據使用Doris進行存儲,非結構化數據用MinIO存儲。這些存儲系統(tǒng)不僅提供了大規(guī)模的數據存儲能力,同時也保證了數據的安全性和可靠性。
2.3 計算處理
大數據的處理通常需要使用分布式計算框架,文章中使用Doris的計算能力。此框架可以處理大規(guī)模的數據,進行實時的計算和分析。在這個過程中,數據清洗、數據去重、數據轉換等操作都會被執(zhí)行,以提高數據的質量,為后續(xù)的數據分析提供準確的基礎。
2.4 數據應用
最后,數據分析的結果將被應用到實際業(yè)務中,以支持決策和業(yè)務操作。這包括生成報告、提供數據服務等。同時,這個過程也需要持續(xù)監(jiān)控和優(yōu)化數據處理流程,以提高數據處理效率和質量。數據平臺數據處理流程如圖2所示。
3 數據平臺構建
本部署描述旨在闡述利用互聯(lián)網相關大數據開源組件(DataX、Dinky、Doris、MinIO)搭建水利行業(yè)數據平臺。該平臺將實現(xiàn)對水利行業(yè)數據的采集、存儲、處理、分析以支持水利行業(yè)的決策和業(yè)務發(fā)展,在部署過程中,充分考慮硬件和軟件環(huán)境的要求,確保系統(tǒng)的穩(wěn)定性和性能。
3.1 數據匯聚模塊搭建
基于DataX和Dinky開源組件,搭建數據平臺的數據匯聚功能模塊,實現(xiàn)了多數據源的高效采集和實時同步,確保了數據的準確性和一致性,同時提供了可擴展、高可用的數據匯聚解決方案,為業(yè)務決策提供有力支持。
3.1.1 DataX部署
基于阿里巴巴集團開源DataX離線數據同步工具構建,實現(xiàn)包括MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS等在內的各種異構數據源之間高效的數據同步功能。
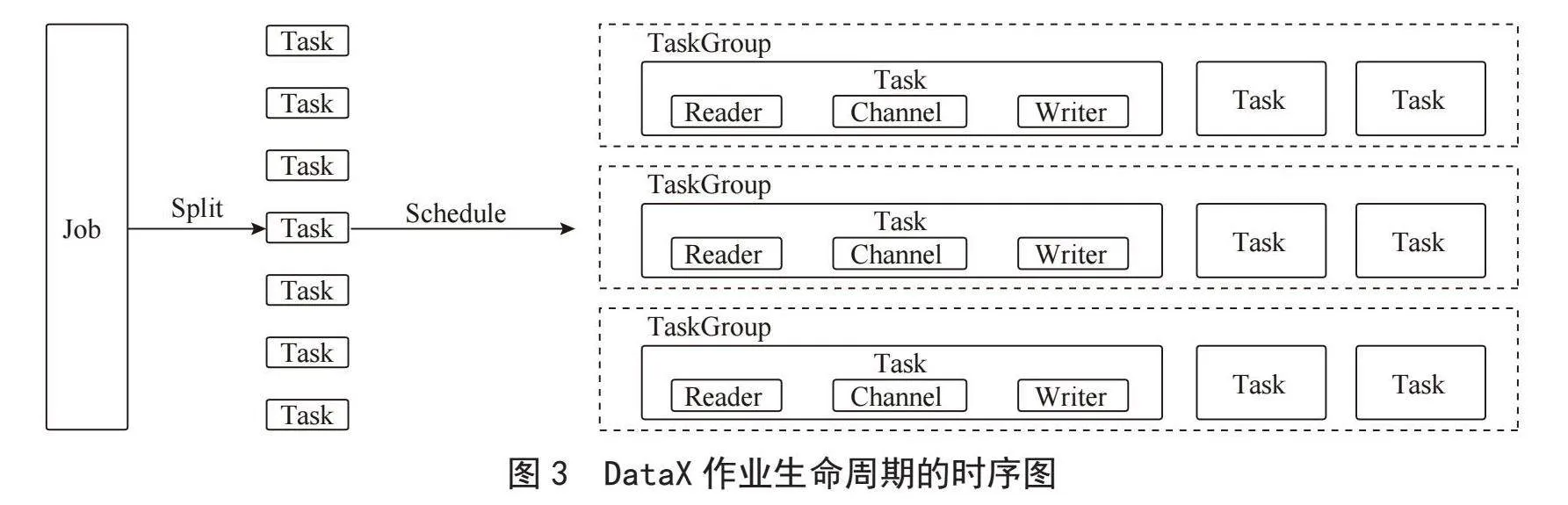
DataX3.0框架設計采用Framework+Plugin架構,將數據源讀取和寫入抽象稱為Reader/Writer插件,納入到整個同步框架中。DataX Job模塊是單個作業(yè)的中樞管理節(jié)點,承擔了數據清理、子任務切分、TaskGroup管理等功能。DataX Job啟動后,會根據不同源端的切分策略,將Job切分成多個小的Task(子任務),以便于并發(fā)執(zhí)行。接著DataX Job會調用Scheduler模塊,根據配置的并發(fā)數量,將拆分成的Task重新組合,組裝成TaskGroup(任務組)。每一個Task都由TaskGroup負責啟動,Task啟動后,會固定啟動Reader→Channel→Writer線程來完成任務同步工作。DataX支持單機多線程模式完成同步作業(yè),用以說明DataX的運行流程、核心概念以及每個概念的關系,DataX作業(yè)生命周期的時序如圖3所示。
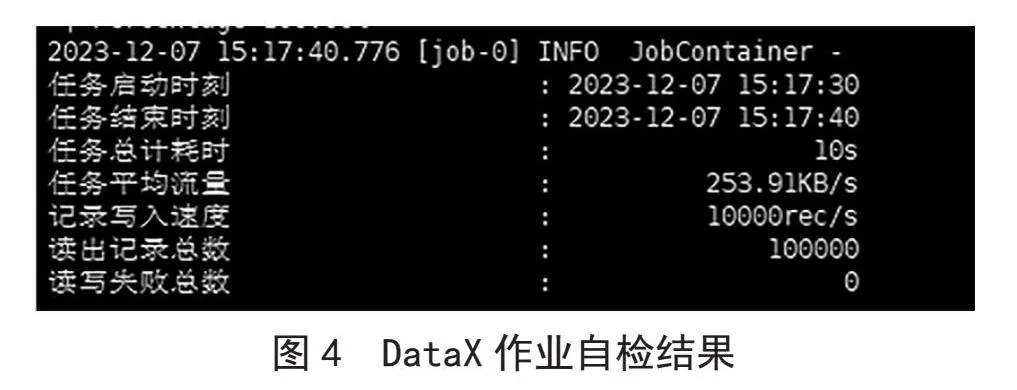
下載DataX安裝包上傳至服務器相應目錄并解壓,運行Python datax.py job.json查看DataX自檢結果,出現(xiàn)如圖4所示結果即為部署成功。
3.1.2 Dinky部署
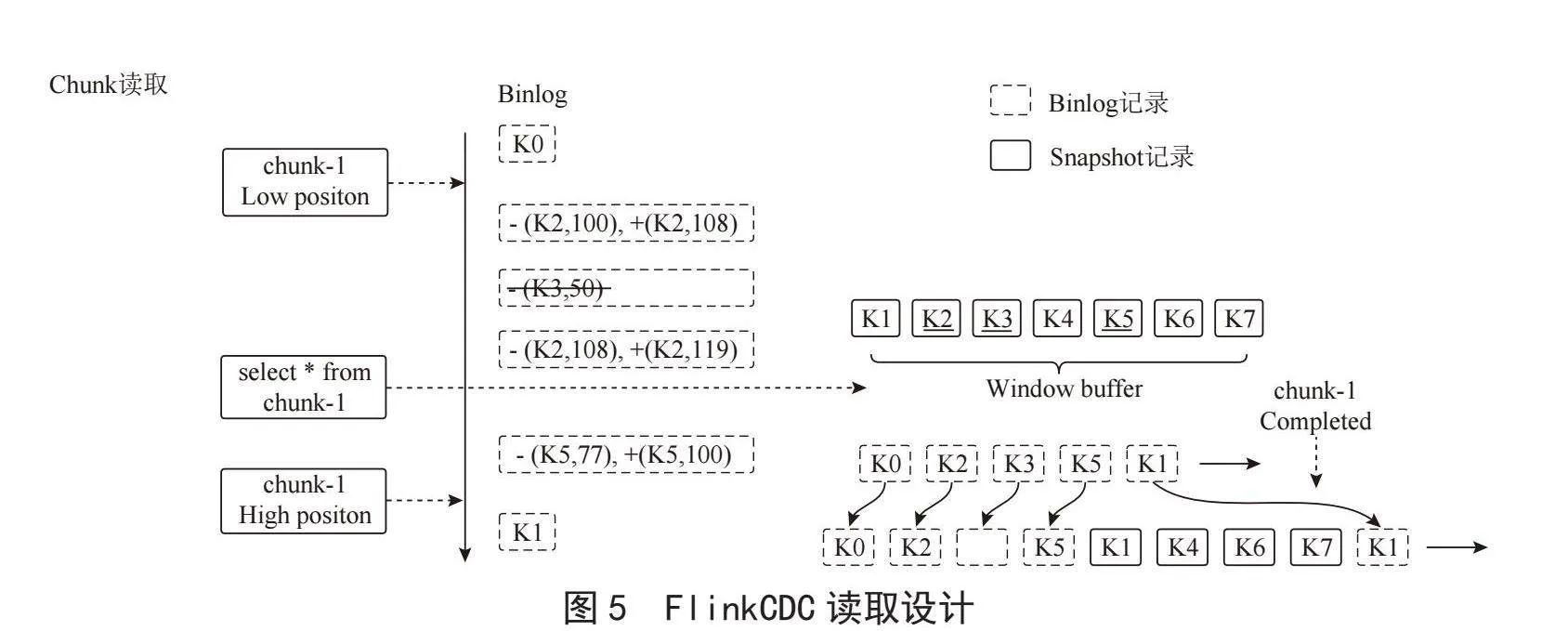
Dinky基于開源Apache Flink組件構建,它提供了一種基于變更數據FlinkCDC,基于變更數據捕獲(Change Data Capture)的方式,用于監(jiān)測并捕獲數據庫的變動,如插入、更新和刪除等操作。核心思想是將這些變更按發(fā)生的順序完整記錄下來,并將這些信息寫入到消息中間件中,以便于其他服務進行訂閱和消費。同時,提供Flink實時流的計算能力,實時計算數據進行寫入Doris。
FlinkCDC Connectors作為Apache Flink的一組源連接器,使用CDC從不同的數據庫中獲取變更。這種方式相比于傳統(tǒng)的基于查詢的CDC(如Sqoop、DataX等)具有明顯的優(yōu)勢,后者需要離線調度查詢作業(yè)進行批處理,無法保障數據的實時性和一致性。FlinkCDC讀取機制如圖5所示。
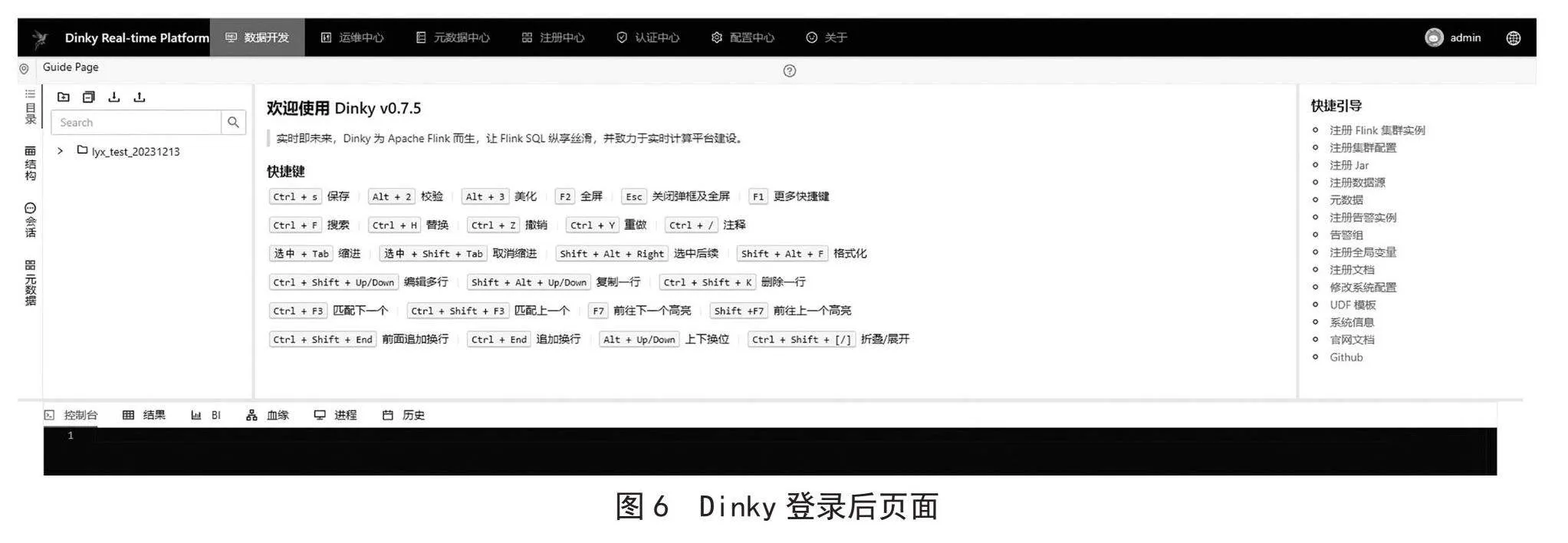
將Dinky安裝包上傳至服務器相應目錄并解壓,在對應數據庫下執(zhí)行SQL目錄下的dlink.sql腳本初始化Dinky數據庫,執(zhí)行成功后,啟動dlink應用進程sh auto.sh start打開登錄Dinky頁面如圖6所示。
3.2 數據中心模塊搭建
3.2.1 Doris部署
基于開源Doris [7]數據庫產品構建水利工程運行管理多維動態(tài)數據中心,Doris是一款基于MPP技術的SQL分析型數據庫系統(tǒng),能夠在海量數據的OLAP場景下提供毫秒級的查詢響應性能。Doris從設計上來說,融合了Google Mesa的數據存儲模型、Apache的ORCFile存儲格式、Apache Impala查詢引擎和MySQL交互協(xié)議,是一個擁有先進技術和先進架構的領先設計產品。
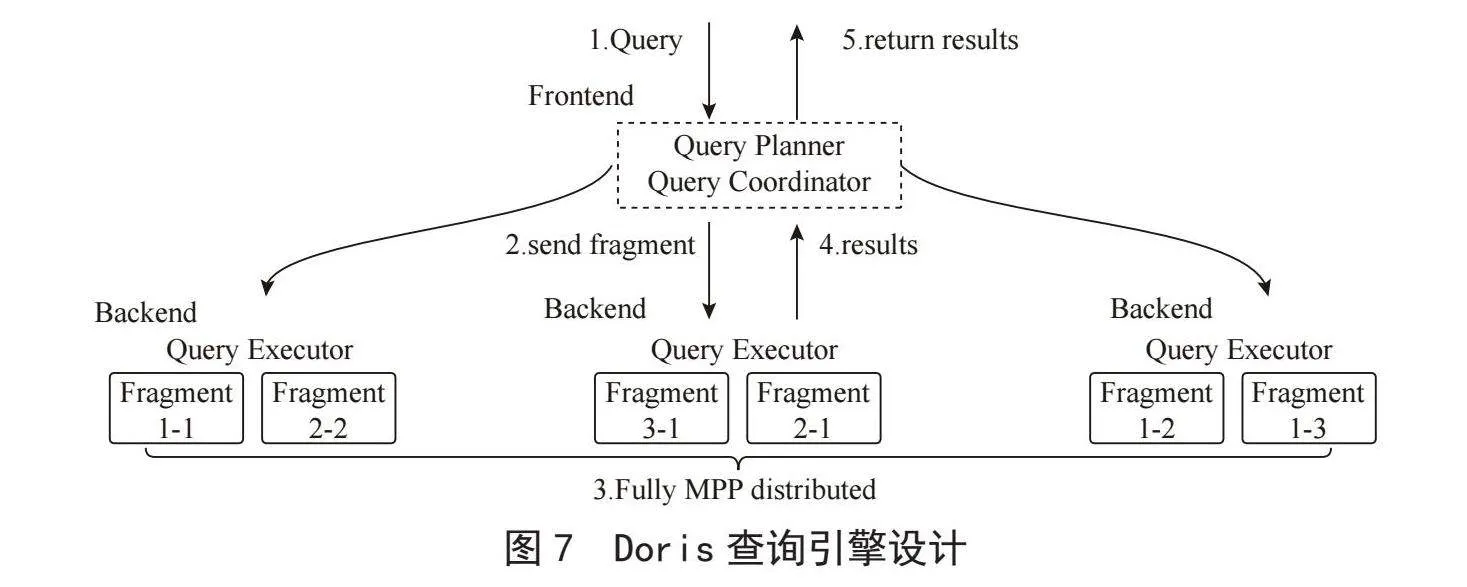
在架構方面,Doris只有兩類進程:一類是FE,可以理解為Doris的管理節(jié)點,主要負責用戶請求的接入、查詢計劃的解析、元數據的存儲和集群管理相關工作;另一類是BE,主要負責數據存儲、查詢計劃的執(zhí)行。這兩類進程都是可以橫向擴展的。除此之外,Doris不依賴任何第三方系統(tǒng)(如HDFS、Zookeeper等)。這種高度集成的架構設計極大地降低了運維成本。Doris查詢引擎原理如圖7所示。
Doris部署選擇三臺服務器進行集群部署,其中FE,BE在一臺服務器上進行混部,其余兩臺服務器單獨部署B(yǎng)E,下載Doris安裝包并解壓得到以下目錄(三臺服務器分別執(zhí)行相同操作),修改fe.conf\be.conf文件指定priority_networks為本地IP,啟動fe_start.sh、be_start.sh后登錄FE頁面,如圖8所示。
3.2.2 MinIO部署
基于Apache License v2.0開源協(xié)議的分布式文件系統(tǒng)MinIO構建水利工程非結構化數據存儲系統(tǒng),用來保存海量的雷達云圖、衛(wèi)星變化圖斑、監(jiān)控視頻、BIM、GIS等數據。由于采用Golang實現(xiàn),服務端可以工作在Windows、Linux、OS X和FreeBSD上。
MinIO是一種開源的分布式對象存儲系統(tǒng),它可以在多個節(jié)點上存儲和管理大量的數據。MinIO的設計目標是提供一高可用性、高性能、易于擴展的對象存儲系統(tǒng),以滿足現(xiàn)代應用程序的需求。Minio的核心原理是分布式存儲。它將數據分散存儲在多個節(jié)點上,以提高可用性和性能。每人節(jié)點都是一個獨立的存儲單元,可以獨立地處理讀寫請求。當一個節(jié)點出現(xiàn)故障時,其他節(jié)點可以接管它的工作,確保數據的可用性和一致性[11]。
系統(tǒng)部署過程:下載MinIO的二進制文件,然后上傳到我們的服務器上,修改權限chmod +x minio,然后設置用戶名和密碼,注意,用戶名長度至少3位,密碼長度至少8位,然后可以通過nohup ./minio server --address :9000 --console-address :9001 /tools/MinIO/minio_server/data > /tools/MinIO/minio_server/data/minio.log &命令進行后臺啟動,訪問下控制臺服務器ip:9001,如圖9所示。
3.3 數據服務模塊
數據服務模塊借助第三方廠家商業(yè)產品ESB(Enterprise Service Bus)作為數據服務總線模塊進行構建,ESB在混合架構中作為新老架構間的通信橋梁支撐其服務整合與業(yè)務集成;同時,產品支持云環(huán)境下的快速伸縮,支持協(xié)議轉換、消息轉換、消息路由、服務編排、服務注冊、服務查找、服務監(jiān)控、熱更新、訪問控制等系列功能。
數據平臺集成其主要功能:
1)服務編排。ESB可以通過重復利用本地或遠程已有的系統(tǒng)的不同協(xié)議的服務進行組合從而生成新的服務,并可以通過不同的協(xié)議從ESB上暴露給其他業(yè)務系統(tǒng),增強數據平臺應對業(yè)務變化的能力,提高了數據服務效率
2)服務注冊。對服務目錄、服務轉換、路由等內容的管理配置,用以管理、配置服務,包括服務細節(jié),技術接口,告警策略等。為開發(fā)人員能快速發(fā)現(xiàn)滿足他們的服務,服務注冊提供了對企業(yè)服務的發(fā)布,目錄和分類功能。
4 實例應用-監(jiān)測數據極值場景
4.1 極值取值場景分析
在水利工程監(jiān)測中,數據的極值取值對于判斷工程的安全狀況具有重要意義。例如,水位、滲流、滲壓、位移、流量等指標的極值可能預示著潛在的安全風險。因此,通過對監(jiān)測數據進行極值取值,可以及時發(fā)現(xiàn)并處理潛在的安全風險。當數據量非常大時,傳統(tǒng)關系型數據庫可能面臨查詢性能的問題。特別是在處理極值取值這樣的復雜查詢時,性能問題可能會更加明顯。由于極值取值需要處理的數據量通常很大,因此查詢可能需要花費較長的時間,甚至可能超時,并且會對數據庫帶來性能影響導致線上業(yè)務中斷等嚴重后果。
傳統(tǒng)關系型數據庫通常是集中式的,這意味著隨著數據量的增加,單個數據庫服務器可能無法承受負載。這可能導致性能下降和故障。為了解決這個問題,關系型數據庫通常需要進行分片,但這會增加復雜性并可能導致數據一致性問題。傳統(tǒng)關系型數據庫通常無法有效地處理大數據。對于極值取值這樣的查詢,可能需要掃描大量的數據,這可能會超出傳統(tǒng)關系型數據庫的處理能力。
4.2 Doris極值取值場景應用
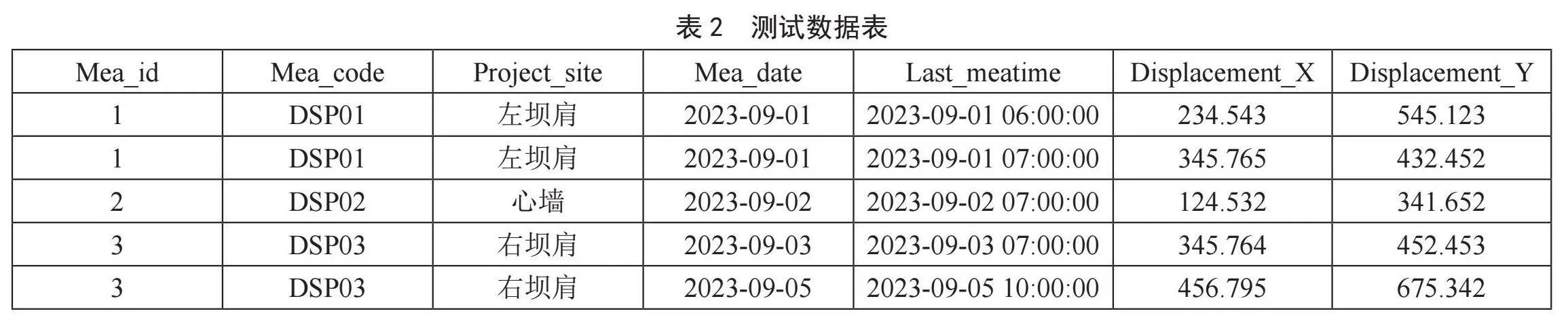
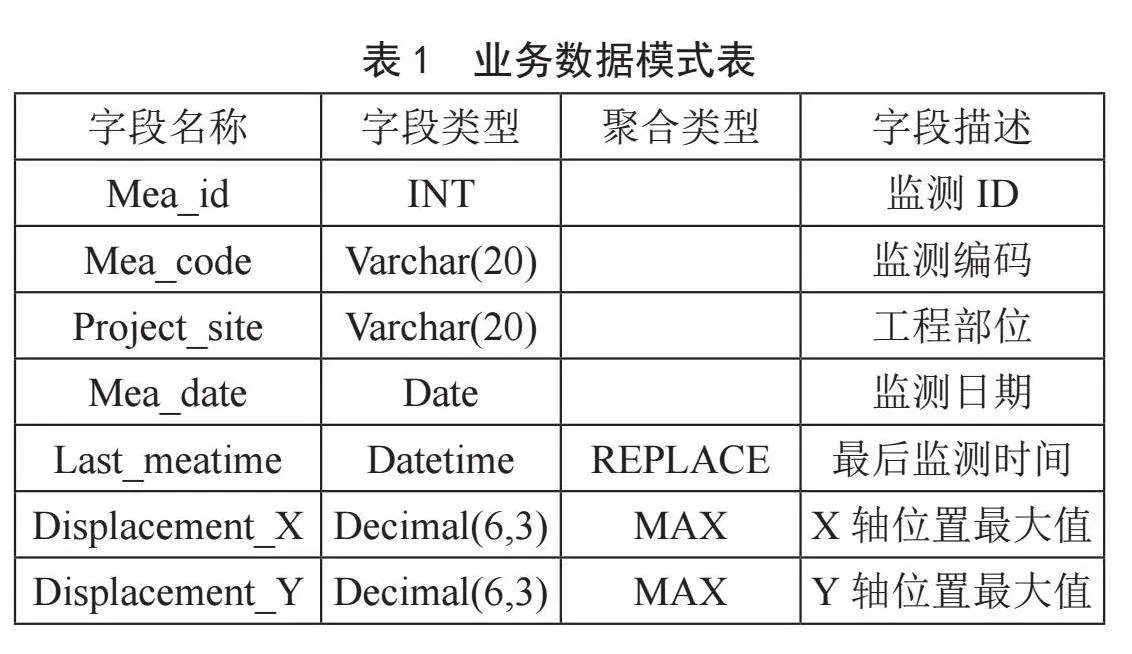
極值提取:創(chuàng)建Doris數據庫的Aggregate數據模型表,以基礎監(jiān)測數據表為例(涉及水利數據機密性,所示數據表信息及數據皆為測試數據)。假設業(yè)務有以下數據表模式,如表1所示。
以下是Doris Aggregate數據模型表建表語句,如圖10所示。
我們有以下導入數據(測試數據),如表2所示。
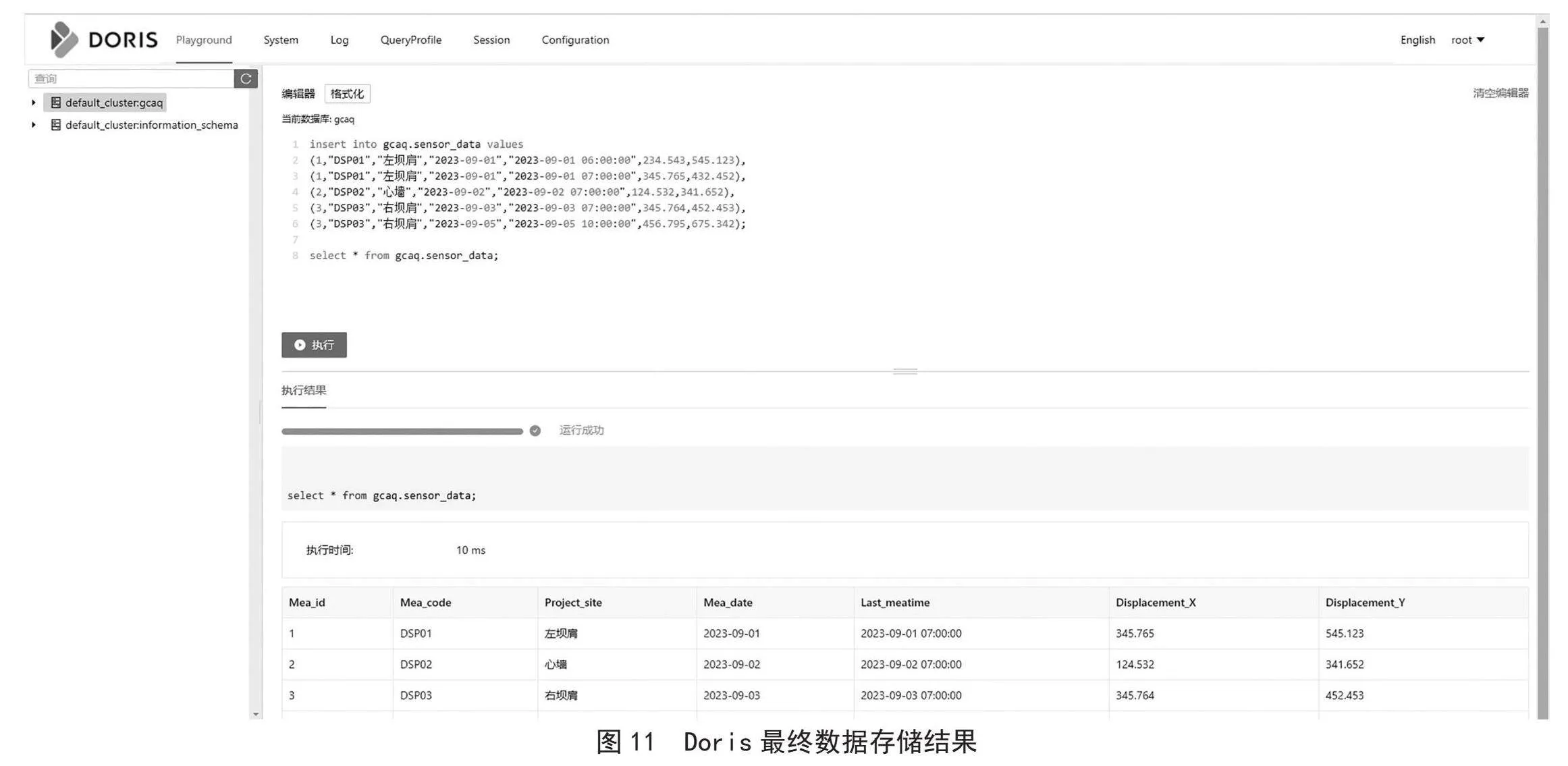
Doris執(zhí)行插入SQL語句后查詢gcaq.sensordata數據表,Doris最終數據存儲結果,如圖11所示。
當我們根據創(chuàng)建的Aggregate模型表導入數據時,對于Key(`Mea_id`, `Mea_code`, `Project_site`, `Mea_date`)列相同的行會聚合,而Value列會按照設置的AggregationType 進行聚合。可以看到監(jiān)測ID:1,只剩下了一行聚合后的數據,最后監(jiān)測時間已經變?yōu)椋?023-09-01 07:00:00、X軸位置最大值為:345.765、Y軸位置最大值為:545.123。
AggregationType目前有以下四種聚合方式:1)SUM(求和),多行的Value進行累加。2)REPLACE(替代),下一批數據中的Value會替換之前導入過的行中的Value。3)MAX,保留最大值。4)MIN,保留最小值。插入即所得,在全量數據極值獲取場景中大大提高了查詢效率,解約了時間成本。通過DorisAggregate模型表,我們可以利用Doris的分布式計算能力,快速提取出數據的極值。
通過以上分析,我們可以看到基于Doris的水利工程監(jiān)測數據極值取值場景實踐應用具有很大的潛力。通過利用Doris的高性能、高可用性、高擴展性等特點,我們可以快速處理和分析海量的水利工程監(jiān)測數據,提取出極值,及時發(fā)現(xiàn)并處理潛在的安全風險。這將有助于保障水利工程的安全運行,提高水資源管理的效率和質量。
5 結 論
數據平臺的技術實現(xiàn)包括數據采集技術、數據處理技術、數據存儲技術和數據可視化技術等。其中,數據采集技術采用FlinkCDC、DataX技術,實現(xiàn)數據的實時采集和傳輸;數據處理技術采用分布式計算和內存計算等技術,實現(xiàn)對大量數據的快速處理和分析;數據存儲技術采用分布式存儲對象存儲和數據庫技術,確保數據的可靠性和完整性。
通過介紹數據平臺的設計與實現(xiàn),包括整體架構、功能模塊和技術實現(xiàn)等,說明了數據平臺的有效性和實用性。最后,通過實例應用表明了數據平臺在實際水庫運行管理中的應用效果和貢獻。因此,通過以上構建方法去構建一個智慧水利工程水庫運行管理的數據平臺是必要的且可行的。可以通過平臺采集、計算、分析等充分利用水庫運行的各種數據,提高水庫運行管理的效率和水平,為保障人民生命財產安全和經濟社會發(fā)展做出積極貢獻。
參考文獻:
[1] 蔡陽,成建國,曾焱,等.加快構建具有“四預”功能的智慧水利體系 [J].中國水利,2021(20):2-5.
[2] 黃喜峰,劉啟,劉榮華,等.數字孿生山洪小流域數據底板構建關鍵技術及應用 [J].華北水利水電大學學報:自然科學版,2023,44(4):17-26.
[3] 雍熙,魏旭強,賴明東.國家水資源監(jiān)控工程的大數據平臺建設 [J].工程研究-跨學科視野中的工程,2021,13(1):3-9.
[4] 高念高.數字孿生水利工程中的大數據應用初探 [J].信息技術與標準化,2023(8):87-91.
[5] 杜紅艷,薛惠鋒,侯俊杰,等.面向智慧水利的水資源數據融合探析 [J].中國水利,2018(23):61-64.
[6] 陳希琳,翟曉汀.消除制造企業(yè)“數據孤島” 訪國家智能制造專家委員會委員、國家智能制造標準化委員會專家咨詢組專家蔣白樺 [J].經濟,2023(5):43-45.
[7] 賀仁駒,沈濱.數字化轉型促進了企業(yè)固定資產投資嗎?[J].科學決策,2023(11):127-139.
[8] 張潔,許建宏,肖偉.關于數據中臺建設思路的探討 [J].郵電設計技術,2021(8):74-79.
[9] 舒玨淋,曹楊,遲雪,等.面向物聯(lián)網應用的大數據平臺研究與設計 [J].計算機時代,2023(7):127-132.
[10] 熊擁軍,白瀚禎,張廷成.基于數據中臺的圖書館數據資產管理架構 [J].圖書館學研究,2023(8):36-47.
[11] 趙靜靜,金慧峰,李霄.基于MinIO存儲的綜合實踐管理平臺開發(fā) [J].軟件,2022,43(10):55-59.
作者簡介:梁遠想(1989—),男,漢族,河南濮陽人,工程師,本科,研究方向:水利大數據技術應用。
