古漢語NLP研究現狀綜述(2009—2024)
2024-09-19 00:00:00勞斌彭瑤呂薇植思喆
現代信息科技 2024年13期
摘 要:文章綜述了古漢語自然語言處理(NLP)領域的研究現狀,特別是下游任務方面的進展。通過分析2009年至2024年的23篇相關論文,文章指出古漢語NLP面臨的挑戰,并探討了包括斷句與標點、分詞、詞性標注、命名實體識別等任務的研究方法和成果。研究發現,盡管古漢語與現代漢語在NLP任務上存在差異,但深度學習等技術的發展為古漢語文本處理提供了新途徑。文章還討論了多任務一體化研究的潛力,并對未來發展趨勢進行了展望,強調了構建結構化數據集的重要性和對領域發展的促進作用。
關鍵詞:古漢語;自然語言處理;下游任務;研究現狀綜述
中圖分類號:TP391 文獻標識碼:A 文章編號:2096-4706(2024)13-0146-06
The Overview of Research Status for NLP Research in Ancient Chinese (2009-2024)
LAO Bin1, PENG Yao1, LYU Wei2, ZHI Sizhe1
(1.School of Information Science and Technology, Guangdong University of Foreign Studies, Guangzhou 510006, China; 2.School of Foreign Languages, Sun Yat-Sen University, Guangzhou 510275, China)
Abstract: This paper provides an overview of the current research status in the field of Natural Language Processing (NLP) of ancient Chinese, especially the progress in downstream tasks. By analyzing 23 relevant papers from 2009 to 2024, the paper points out the challenges faced by NLP in ancient Chinese and explores research methods and achievements including sentence breaks and punctuation, word segmentation, part of speech tagging, named entity recognition, and other tasks. The research finds that although there are differences in NLP tasks between ancient and modern Chinese, the development of technologies such as Deep Learning has provided new avenues for ancient Chinese text processing. This paper also discusses the potential of multi-task integration research and looks forward to future development trends, emphasizing the importance of constructing structured datasets and their promoting role in domain development.
Keywords: ancient Chinese; natural language processing; downstream task; overview of research status
0 引 言
隨著自然語言處理(NLP)技術的持續進步,其研究視野逐漸擴展至古漢語這一中文語言的重要組成部分。古漢語作為中國傳統文化的精華,蘊含了深厚的歷史、文化與哲學價值,對其的研究不僅具有學術意義,也對傳承和弘揚中華文化具有重要作用。盡管古漢語與現代漢語存在顯著差異,帶來了諸多研究挑戰,但近年來NLP技術的發展為古漢語的研究提供了新的視角和方法。本文旨在全面綜述古漢語NLP領域的最新研究進展,特別是下游任務方面的成果,以期為研究人員提供有價值的信息和啟示。
通過在中國知網中使用“古漢語”及“分詞、詞性標注、命名實體識別”等下游任務作為關鍵詞進行檢索,文章收集了跨度從2009年至2024年的相關文獻。經過精心篩選,共納入23篇論文,并依據不同的下游任務對這些論文進行分類。文章首先對古漢語NLP的研究現狀進行概述,然后基于發表年份和各類任務的論文占比兩個維度對收集的論文進行分析,并探討其背后的原因。最后,文章總結了古漢語NLP領域的現狀和面臨的挑戰,并對其未來的發展方向提出展望,旨在為該領域的持續進步貢獻力量。
1 古漢語NLP領域的研究現狀
與現代漢語的下游任務相比,古漢語領域自然語言處理的下游任務與現代漢語基本相似。但由于古漢語與現代漢語存在著一些區別,如語言形式不同、語料庫難以獲取、字義歧義較多、文化背景不同等原因,因此在古漢語NLP領域的具體實現過程中存在一定的差異。在現代漢語NLP領域中,下游任務包括分詞、詞性標注、命名實體識別、句法分析、情感分析、文本分類、文本摘要、機器翻譯等。而在古漢語NLP領域中,同樣也存在這些下游任務。但是,相比現代漢語,古漢語則多出了一項下游任務,即古文斷句與標點。下文按照古漢語NLP研究的先后順序展開說明。
1.1 古漢語斷句與標點
古漢語與現代漢語在句子結構和標點使用上存在差異。古漢語依賴口頭傳承,文學作品多用于朗誦,故標點使用較少,常采用主題述補結構,有時文字間無間隔。現代漢語則廣泛應用標點符號,注重語法和意義的精確表達。盡管如此,古代漢語也有類似頓號、句號等標點,以及主謂賓、并列和復合等結構。這些差異主要源于不同的語言使用環境和需求,給后續的文本分析和理解帶來了挑戰。為了提升文本處理的效率和準確性,研究人員在處理古漢語的下游任務中添加了斷句和標點這一項任務。
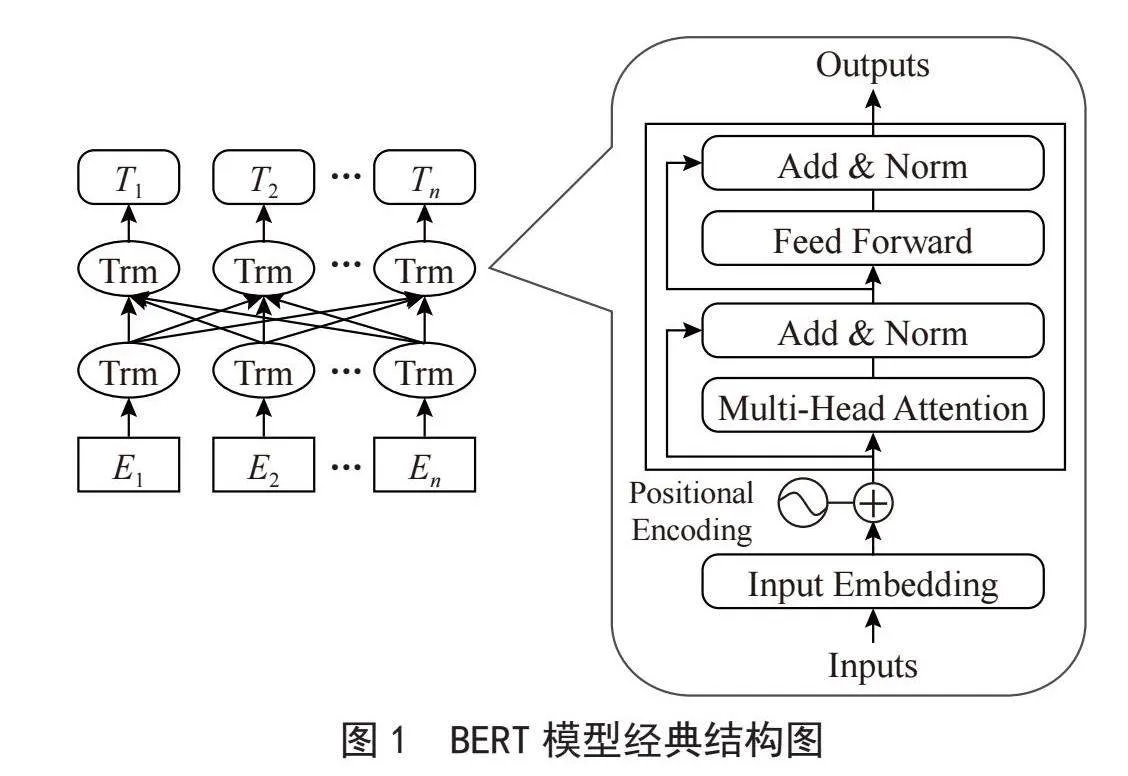
在古漢語短句與標點方面的研究中,胡韌奮等人[1]在其研究中強調斷句過程中需綜合語義、語境及歷史文化等因素,提出了一種基于BERT預訓練模型(BERT模型的經典結構如圖1所示)的古漢語知識表示方法,并結合條件隨機場和卷積神經網絡開發了高精度的自動斷句模型。王倩等人[2]利用《四庫全書》作為語料庫,建立了一套標注體系,并通過構建基于BERT-LSTM-CRF和多特征LSTM-CRF的層疊深度學習模型,實現了古漢語的自動斷句與標點。張開旭等人[3]引入互信息和t檢驗作為特征,提出了一種基于條件隨機場(CRF)的古漢語自動斷句與標點方法。并通過在《論語》和《史記》上的實驗表明,CRF方法能有效處理古文自動標點問題,且層疊CRF策略優于單層策略。
1.2 古漢語分詞
中文分詞是中文自然語言處理中的核心環節,其目的是將連續的文本切分成有意義的詞或短語。與現代漢語分詞任務相似,但古漢語具有其特殊性:古漢語中的詞語多由單字或多字組成,每個字均承載特定含義。因此,在執行古漢語分詞時,必須細致考量每個字的內在含義及其在文本中的關系。舉例說明,現代漢語中的“可以”通常作為一個詞,表示允許或可能;然而,在古漢語中,“可”與“以”是兩個獨立的文字,各自代表“能夠”和“依靠”的意思,合在一起才構成“可以憑借”的含義。這一差異意味著,在現代漢語分詞中,“可以”可能被視為一個單一詞匯,但在古漢語分詞中,則需將其拆分為“可”和“以”兩個獨立的字。因此,古漢語分詞任務要求對文本進行更為細致的語義和結構分析。主要的分詞方法包括基于詞典、基于統計和基于理解的分詞。基于詞典的方法依賴于預設的詞匯庫,通過正向、逆向或雙向匹配,并采用最大匹配、最小匹配或最佳匹配策略,以實現快速分詞,但需注意歧義處理。基于統計的分詞則通過大量標注數據訓練模型,擅長識別未知詞和處理歧義,但該方法計算成本較高,速度較慢。而基于理解的分詞進一步結合了詞典、統計信息和深層語義分析,以獲得更高的準確度,但相應地,它在處理速度和計算資源上有更高的要求。在實際應用中,選擇哪種分詞算法需根據具體任務的需求和可用資源來決定。
在古漢語分詞研究方面,石民等研究者[4]專注于先秦文獻,尤其是《左傳》的分詞與詞性標注研究,他們通過條件隨機場模型對《左傳》進行了一體化的自動分詞、詞性標注及分詞標注實驗,發現一體化分詞在準確率和召回率上優于單獨分詞方法。高毅[5]探討了古漢語自然語言處理技術發展緩慢的問題,并提出了一種基于雙向最大匹配法則和專門訓練的古漢語語料庫的BERT模型,用于自動分詞。唐俊等人[6]設計了一種針對古漢語的BERT預訓練模型即SikuBert-CNN-CRF模型,該模型通過領域適應訓練,使用大量古文語料進行無監督預訓練,并結合多層CNN和條件隨機場(CRF)進行古漢語分詞,在實驗中展現出較強的處理能力和泛化性。魏一[7]在其研究中提出一種基于大量古漢語語料的預訓練模型,有效解決了句讀和分詞問題,還引入滑動窗口法處理連續文本,并結合無指導預訓練BERT模型,實現了超越傳統機器學習方法的泛化性能。刑付貴等人[8]通過整合在線古漢語資料,創建了一個含349 740個詞匯的古文詞典CCIDict,在對比測試中,基于此詞典的分詞算法比現有的甲言分詞器在F值上提升了14%,驗證了大型語料庫構建的詞典對提高古文分詞準確性的效用。常博林等人[9]提出了一種融合部首信息的古漢語分詞與詞性標注模型,利用Radical2Vector生成部首向量,并結合SikuRoBERTa模型,通過BiLSTM-CRF結構進行實驗。唐雪梅等人[10]提出了一種基于圖卷積神經網絡的分詞框架,該框架整合預訓練語言模型與圖卷積網絡,引入外部知識以提升分詞效果。楊世超[11]對古漢語的詞性和用法特征進行了細致分析,并據此創建了一套專門的詞性標記系統。通過應用分布式假說理論,他實現了將古漢語文本轉換為計算機可識別和處理的字詞向量表示,此外,他還設計了一個高效的計算模型,顯著提高了古漢語分詞和詞性標注任務的性能。王曉玉等人[12]通過結合CRFs模型與詞典,針對中古漢語分詞效率和一致性進行研究,優化了適用于史書、佛經、小說等語料的分詞策略,并引入了字符分類與字典信息特征以提升分詞性能。
1.3 古漢語詞性標注
古漢語詞性標注是將古漢語中的詞匯按照其語法功能進行分類的過程,對于文本的正確解讀和翻譯具有基礎性的重要性。鑒于古漢語中單個字可能承載多重詞性,準確的詞性標注顯得尤為關鍵。古漢語的詞性體系包括名詞、動詞、形容詞、副詞、介詞等基本類別,其中名詞用于指代人、物或概念,動詞表達行為或狀態的變遷,形容詞描述特性或屬性,副詞對動詞或形容詞進行修飾,而介詞則負責連接句子中的各個成分。此外,古漢語中還包含特殊的助動詞和虛詞,如“之”“乎”“矣”等,它們用于表達肯定或否定的意義,而“了”“著”等助動詞則指示動作的完成或持續狀態。這些詞性的準確識別對于深入理解古漢語文本結構和語義具有不可或缺的作用。
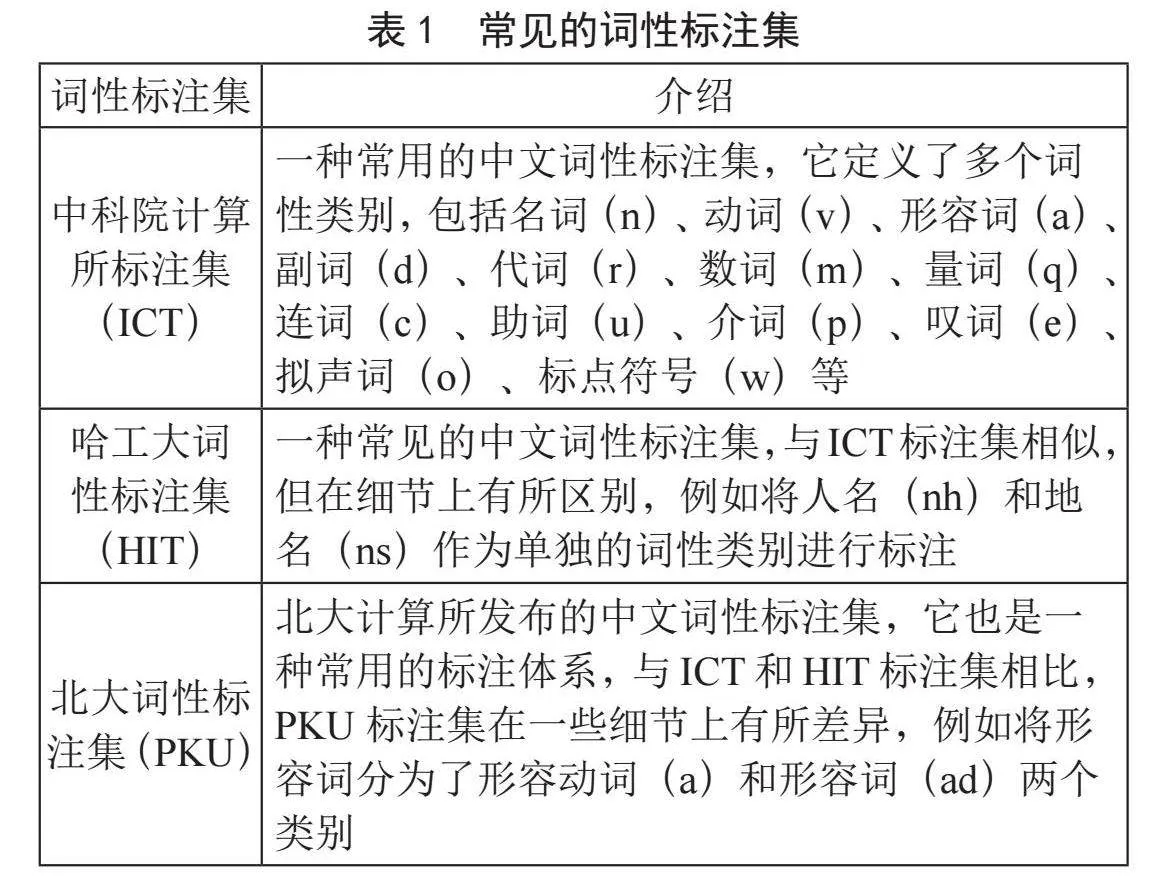
目前在詞性標注集方面,現代漢語的詞性標注集較為常見,如表1所示。
盡管現代漢語的詞性標注集種類繁多,但它們并不適用于古漢語的詞性標注任務。在廣泛文獻回顧的基礎上,石民等人在2010年發表的論文《基于CRF的先秦漢語分詞標注一體化研究》中提出了一套較為適宜的古漢語詞性標注體系。近期,鄭童哲恒等人[13]針對上古時期古籍的計算處理,也制定了一套古漢語分詞與詞性標注規范,以應對研究不足和標注規范缺失的問題,該規范涵蓋7個分詞原則、3個詞性標注原則,并定義了14個一級詞類與15個二級詞類,配備了詳細的標注示例。
在古漢語詞性標注研究中,陳火龍[14]在其研究中針對古漢語虛詞詞性標注問題,構建并擴充了虛詞數據集,并利用Bi-LSTM-CRF模型開發了一個標注系統。楊新生等人[15]提出了一種融合隱馬爾可夫模型和維特比算法的古漢語詞性標注方法,并開發了專用標記集,該方法改進了傳統流程,顯著提高了標注準確率,包括對未登錄詞的有效識別。
1.4 古漢語詞法分析
古漢語句法分析旨在解析古漢語文本的語法結構及其成分間的關系。鑒于古漢語的特殊性,如文化背景和表達習慣的差異,句法分析面臨諸多挑戰,包括詞序變化、省略、重復和修飾等復雜現象,這些都需要綜合上下文信息以準確解讀。目前,古漢語句法分析主要采用統計機器學習和深度學習技術,包括隱馬爾可夫模型(HMM)、條件隨機場(CRF)、最大熵馬爾可夫模型(MEMM)、循環神經網絡(RNN)等。除此之外,規則基礎、圖論和統計語言模型等技術也被應用于句法分析。然而,這些方法在處理特定領域或文本類型的語料庫時可能存在局限,因此,需根據具體任務和需求選擇合適的分析方法。
在古漢語詞法分析中,程寧等人[16]在其論文中探討了未經標點斷句的古漢語文本在進行詞法分析時可能遇到的多級錯誤傳播問題,并提出了一種基于BiLSTM-CRF神經網絡的一體化標注方法,通過在四個不同時代的測試集上進行實驗,他們驗證了該方法在古漢語斷句、分詞和詞性標注任務上的有效性。
1.5 古漢語命名實體識別
古漢語命名實體識別技術旨在自動識別古代文本中的人名、地名和機構名等特定實體。鑒于古代漢字的命名特點,該技術通常結合規則和統計學方法進行實體初步識別與結果優化。規則方法用于識別常見部首和字詞組合,而統計學方法用于處理不常見的組合和歧義糾錯,同時,需考慮上下文信息和構建知識庫以輔助實體的準確識別。這些方法的選擇和應用需根據具體場景和需求來定。
由于古漢語命名實體識別具有很強的歷史文化價值和應用前景,在自然語言處理領域得到了較為廣泛的關注和研究。崔丹丹等人[17]提出了一種基于Lattice-LSTM并結合了字符和詞序列信息的古漢語命名實體識別算法,并使用甲言分詞工具與Word2Vec優化字詞向量,相較于BiLSTM-CRF模型,識別效果有所提升。陳雪松等人[18]也發表了一種結合SikuBERT與MHA的方法,旨在解決傳統方法在處理古漢語復雜結構和長序列特征時的信息損失問題。詹子依[19]則探討了古漢語知識點自動化標注,提出了改進傳統命名實體識別的新方法,結合SikuBERT和多頭注意力機制,以及字詞信息融合策略。李靖[20]在其研究中提出m5W9hd6NOXRohGVEc7KU3noYtGMVqVO37Otmcl4o5Zk=了SLFFN和MFFN兩種模型,旨在提高古漢語命名實體識別的性能并減少標注成本。SLFFN模型融合了字-詞和字結構特征,而MFFN模型在此基礎上增加了字讀音特征,兩者均有效提升了實體識別的準確性。吳夢成等人[21]致力于挖掘先秦典籍中的植物知識,通過細致的植物詞標注和分析,開發了基于CRF和深度學習的古漢語植物命名實體識別模型,旨在豐富對古代社會生活的認識。
1.6 古漢語機器翻譯
古漢語機器翻譯旨在將古代漢語轉換為現代漢語或其他語言,面臨形態、用法及含義差異等挑戰。該領域主要采用結合規則和統計學方法,以及新興的深度學習技術。基于規則的方法依賴專家規則庫,具有高可解釋性但覆蓋面有限;統計學方法通過學習平行文本概率模型實現翻譯,能自動學習但存在不確定性;深度學習方法使用神經網絡處理復雜語言任務,盡管需要大量數據和計算資源,模型解釋性有限,但已取得進展并有望促進文化遺產保護和歷史研究。
在古漢語翻譯成現代漢語的相關研究中,韓芳等人[22]開發了針對古漢語的詞典模型,并整合了黎錦熙提出的句本位句法規則以構建知識庫,同時應用詞義消歧算法,致力于古漢語的機器翻譯研究。
1.7 古詩詞與古文生成
在調研的過程中,我們還注意到了一個引人入勝的領域——古詩詞及古文的自動生成。這一領域利用人工智能技術,通過模擬古代詩人的創作手法,開發出能夠自動生成遵循古典文學規范和形式的古詩文的自然語言處理應用。
其中,劉江峰等人[23]在其研究中針對古詩詞自動生成問題,采用繁體《四庫全書》及古詩詞語料對gpt2-chinese-cluecorpussmall模型進行預訓練,構建了SikuGPT2和SikuGPT2-poem模型。實驗顯示,SikuGPT2-poem在生成古詩方面取得了較低困惑度和更高BLEU評分,且人工評分優于基準模型。盡管模型通過圖靈測試表現良好,但受限于預訓練語料的規模,對賦、曲等體裁的適應性仍有待提高。
1.8 研究總結
在自然語言處理(NLP)的領域中,古漢語與現代漢語的比較研究由于其復雜性和邊緣性,目前尚未成為研究的主流。因此,該領域各個下游任務的論文相對較少,難以直接比較優劣。導致這一現象的原因包括古漢語與現代漢語在語法、詞匯和句式上的顯著差異,這為直接比較分析帶來了挑戰。此外,古漢語的語料庫不僅規模較小,而且難以獲取高質量的標注數據,這對機器學習模型的訓練和驗證構成了障礙。盡管現代漢語作為活語言在社會、文化、經濟等多個領域中應用廣泛,吸引了大量的研究興趣和資源,但古漢語的NLP技術發展還處于初級階段。古漢語研究需要語言學家、歷史學家和計算機科學家等多學科專家的合作,這種跨學科合作的難度較大。同時,NLP的下游任務在古漢語上的應用研究還不成熟,缺乏足夠的實證研究來評估其效果。古漢語文本所蘊含的深厚文化內涵和歷史背景,也給現代技術理解和處理這些文本帶來了障礙。盡管面臨諸多困難,古漢語與現代漢語的比較研究具有重要的學術價值和潛在的應用前景,隨著技術的進步和跨學科合作的深入,未來有望產生更多高質量的研究成果。
2 分析與評述
本章根據收集到的文獻從兩個維度進行整理,分別是相關論文歷年發表數量和各個下游任務的論文占比。以下將從這兩個維度進行詳細分析。
2.1 相關論文歷年發表數量
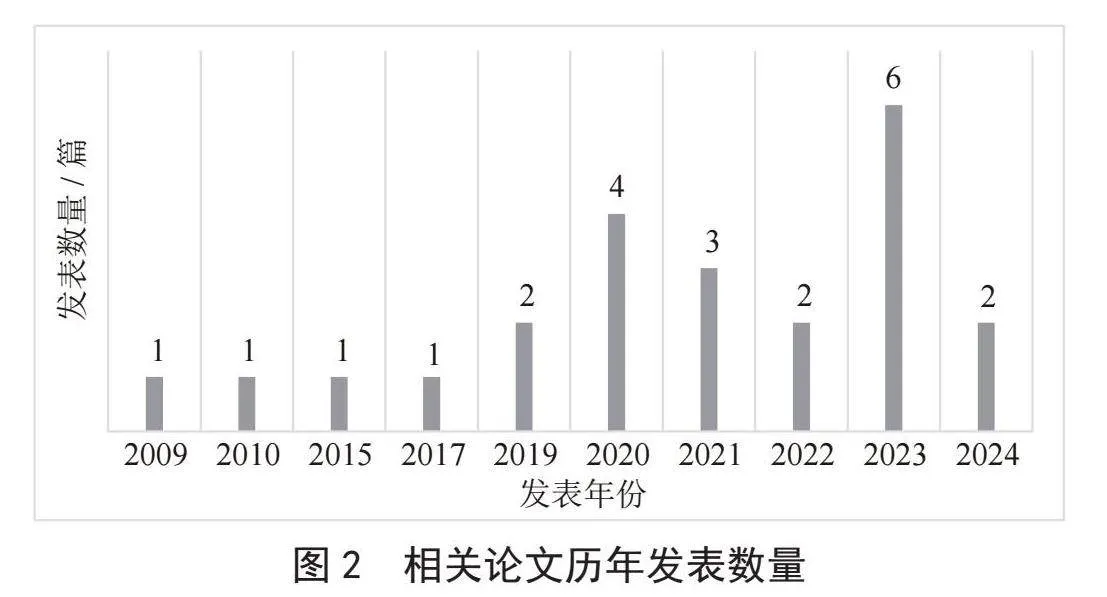
相關論文的發表年份與發表數量的關系如圖2所示。通過分析圖2所示的柱狀圖,可以清晰地看到古漢語與自然語言處理下游任務相關研究論文的發表趨勢隨時間的變化情況。在該柱狀圖中,橫軸代表發表年份,縱軸代表論文發表數量,數據按非連續的年份進行展示。從圖中可以明顯觀察到,在2020年之前,相關領域的論文發表數量較為有限。然而,進入2020年,這一領域的研究論文發表量開始急劇上升,與2009至2019年這十年間相比,研究的熱度和成果產出顯著增加。
圖2 相關論文歷年發表數量
這一顯著的增長趨勢可以歸因于多個因素。首先,技術的進步尤其是深度學習和大數據技術的發展,為古漢語文本的處理提供了強大的技術支持,這些技術的發展極大地提高了研究者處理古漢語文本的能力,使得研究工作更為深入和精確;其次,隨著數字化進程的加速,大量古漢語文獻被數字化并公開,為自然語言處理模型的訓練和測試提供了豐富的數據資源,從而推動了研究工作的深入;最后,跨學科合作的興起也為古漢語智能處理研究帶來了新的活力,計算機科學、語言學、歷史學等多學科的融合,為研究者提供了新的視角和解決方案,促進了創新和探索。以上幾個因素相互作用,共同促進了古漢語智能處理研究的發展。
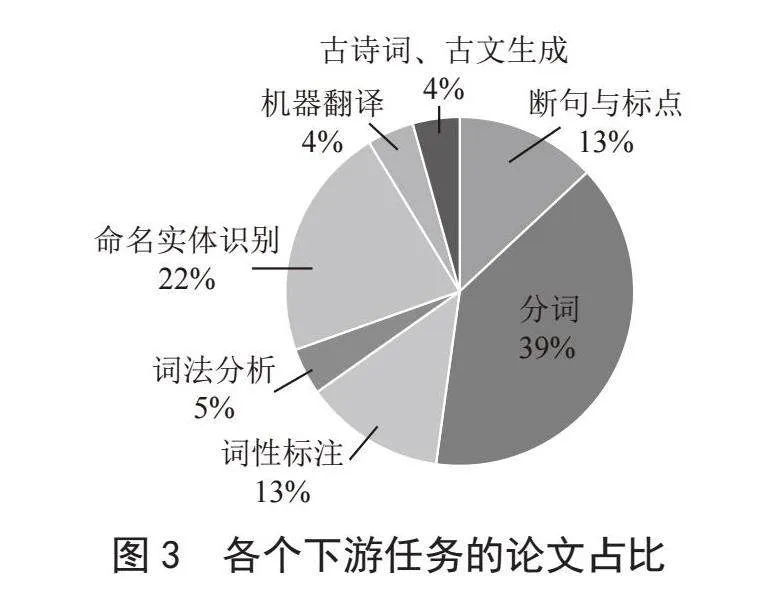
2.2 各個下游任務的論文占比
從圖3數據可以清晰地看到,分詞任務在古漢語研究論文中占據了顯著的比重,緊隨其后的是命名實體識別任務。相對而言,詞法分析、機器翻譯以及古詩詞和古文生成等任務的論文比例較小。在古漢語領域的自然語言處理研究中,分詞任務和命名實體識別(NER)相關的論文數量占據了較大比例,這主要是因為分詞作為基礎性任務對后續處理工作至關重要,尤其是在古漢語這種缺乏明顯詞間分隔的語言中,而命名實體識別則因其在提取關鍵信息和理解文本內容方面的實際應用價值而受到重視。相比之下,詞法分析、機器翻譯和古詩詞古文生成任務的論文數量較少,這是由于它們在古漢語處理上的復雜性和挑戰性較高,以及相對于分詞和NER,它們可能獲得的研究資源和學術關注較少。因此,研究者們在古漢語智能處理的研究中,更傾向于關注那些能夠為理解古文本提供直接幫助的基礎任務和技術。
在自然語言處理的研究中,除了對單一下游任務進行深入探討,一些研究者開始嘗試將多個任務整合,開展一體化的研究。例如,程寧等人[16]將斷句和詞法分析任務結合起來,進行了聯合研究,而常博林等人[9]則針對分詞和詞性標注任務進行了類似的一體化探索。這種多任務聯合的創新研究方法,在實驗中已經展現出了積極的成效。展望未來,多任務一體化的研究路徑無疑值得進一步探索,它有潛力為自然語言處理領域帶來更為全面和高效的解決方案。
3 結 論
目前,在古漢語NLP領域中的下游任務方面,除了分詞、斷句與標點、命名實體識別等幾個熱門任務的研究成果比較多之外,其他幾個下游任務的研究較少,目前還存在較多的空白。出現研究空白的主要原因是這些任務需要依賴前置任務的研究進展,而前置任務的研究還需要更多的努力和時間。在數據集方面,原始語料也并不難獲取,但是根據各個具體的下游任務而做出不同處理的結構化數據集極其缺乏。因為這樣的結構化數據集需要與古漢語相關專業的從事人員或研究人員進行標注,代價極大。這也是古漢語NLP領域中的科研人員需要面臨的重大問題。而該問題若得不到解決,會極大地阻礙古漢語NLP領域的發展。因此,解決這些問題對于古漢語NLP領域發展來說至關重要。只有不斷努力和持續投入,才能夠進一步拓展該領域下游任務研究的廣度和深度,并建立起更加完善和可靠的數據集等基礎設施。
參考文獻:
[1] 胡韌奮,李紳,諸雨辰.基于深層語言模型的古漢語知識表示及自動斷句研究 [J].中文信息學報,2021,35(4):8-15.
[2] 王倩,王東波,李斌,等.面向海量典籍文本的深度學習自動斷句與標點平臺構建研究 [J].數據分析與知識發現,2021,5(3):25-34.
[3] 張開旭,夏云慶,宇航.基于條件隨機場的古漢語自動斷句與標點方法 [J].清華大學學報:自然科學版,2009,49(10):1733-1736.
[4] 石民,李斌,陳小荷.基于CRF的先秦漢語分詞標注一體化研究 [J].中文信息學報,2010,24(2):39-45.
[5] 高毅.基于BERT預訓練模型的古漢語自動分詞方法研究 [J].電子設計工程,2021,29(22):28-32.
[6] 唐俊,高大貴,陳銘萱,等.一種基于預訓練的古漢語分詞模型 [C]//2022中國自動化大會.廈門:中國自動化學會,2022:730-735.
[7] 魏一.古漢語自動句讀與分詞研究 [D].北京:北京大學,2020.
[8] 邢付貴,朱廷劭.基于大規模語料庫的古文詞典構建及分詞技術研究 [J].中文信息學報,2021,35(7):41-46.
[9] 常博林,袁義國,李斌,等.融合部首信息的古漢語自動分詞與詞性標注一體化分析 [J/OL]. 數據分析與知識發現,2024:1-17(2024-01-09).http://kns.cnki.net/kcms/detail/10.1478.G2.20240108.1326.002.html.
[10] 唐雪梅,蘇祺,王軍,等.基于圖卷積神經網絡的古漢語分詞研究 [J].情報學報,2023,42(6):740-750.
[11] 楊世超.古漢語分詞與詞性標注方法研究 [D].唐山:華北理工大學,2018.
[12] 王曉玉,李斌.基于CRFs和詞典信息的中古漢語自動分詞 [J].數據分析與知識發現,2017,1(5):62-70.
[13] 鄭童哲恒,李斌.上古漢語分詞與詞性標注加工規范——基于《史記》深加工語料庫的標注實踐 [J].語言文字應用,2023(4):93-104.
[14] 陳火龍.基于Bi-LSTM-CRF的古漢語虛詞詞性標注系統 [D].武漢:華中科技大學,2019.
[15] 楊新生,胡立生.基于隱馬爾科夫模型的古漢語詞性標注 [J].微型電腦應用,2020,36(5):130-133.
[16] 程寧,李斌,葛四嘉,等.基于BiLSTM-CRF的古漢語自動斷句與詞法分析一體化研究 [J].中文信息學報,2020,34(4):1-9.
[17] 崔丹丹,劉秀磊,陳若愚,等.基于Lattice LSTM的古漢語命名實體識別 [J].計算機科學,2020,47(S2):18-22.
[18] 陳雪松,詹子依,王浩暢.融合SikuBERT模型與MHA的古漢語命名實體識別 [J].吉林大學學報:信息科學版,2023,41(5):866-875.
[19] 詹子依.面向古漢語領域的命名實體識別 [D].大慶:東北石油大學,2023.
[20] 李靖.基于特征融合與數據增強的古漢語命名實體識別研究 [D].長春:吉林大學,2023.
[21] 吳夢成,林立濤,齊月,等.數字人文視域下先秦典籍植物知識挖掘與組織研究 [J].圖書情報工作,2023,67(12):103-113.
[22] 韓芳,楊天心,宋繼華.基于句本位句法體系的古漢語機器翻譯研究 [J].中文信息學報,2015,29(2):103-110+117.
[23] 劉江峰,劉雛菲,齊月,等.AIGC助力數字人文研究的實踐探索:SikuGPT驅動的古詩詞生成研究 [J].情報理論與實踐,2023,46(5):23-31.
作者簡介:勞斌(1985—),男,漢族,廣東廣州人,講師,博士,研究方向:數字人文;通訊作者:彭瑤(1999—),男,漢族,廣東揭陽人,碩士研究生在讀,研究方向:數字人文。
