基于分層強化學習的多智能體博弈策略生成方法
2024-09-19 00:00:00暢鑫李艷斌劉東輝
無線電工程 2024年6期




摘 要:典型基于深度強化學習的多智能體對抗策略生成方法采用“分總” 框架,各智能體基于部分可觀測信息生成策略并進行決策,缺乏從整體角度生成對抗策略的能力,大大限制了決策能力。為了解決該問題,基于分層強化學習提出改進的多智能體博弈策略生成方法。基于分層強化學習構建觀測信息到整體價值的決策映射,以最大化整體價值作為目標構建優(yōu)化問題,并推導了策略優(yōu)化過程,為后續(xù)框架結構和方法實現的設計提供了理論依據;基于決策映射與優(yōu)化問題構建,采用神經網絡設計了模型框架,詳細闡述了頂層策略控制模型和個體策略執(zhí)行模型;基于策略優(yōu)化方法,給出詳細訓練流程和算法流程;采用星際爭霸多智能體對抗(StarCraft Multi-Agent Challenge,SMAC)環(huán)境,與典型多智能體方法進行性能對比。實驗結果表明,該方法能夠有效生成對抗策略,控制異構多智能體戰(zhàn)勝預設對手策略,相比典型多智能體強化學習方法性能提升明顯。
關鍵詞:分層強化學習;多智能體博弈;深度神經網絡
中圖分類號:TN929. 5 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3106(2024)06-1361-07
0 引言
策略生成技術是指通過計算或學習,生成用于指導決策策略的方法和技術。隨著人工智能技術的不斷發(fā)展,策略生成技術被廣泛應用于解決各種復雜的問題。策略通常是一個映射,將環(huán)境的狀態(tài)映射到可能的行動或決策,以最大化某種目標函數(如累積獎勵、成功率等)。相比于利用并且依靠專家經驗和領域知識的策略生成方法,基于海量數據的智能決策降低了知識門檻,并且過程更加客觀,避免主觀因素影響[1],特別是在零和對抗場景中[2-3]。因此,當前智能博弈策略生成技術已經廣泛應用于無人機協同對抗[4]、通信智能抗干擾[5]和智能協同欺騙[6]等電磁頻譜作戰(zhàn)任務中。
當前,主流策略生成技術采用深度強化學習方法[7],根據方法結構和應對受控體數量,可以分為集中式方法和分布式方法。集中式方法統(tǒng)一匯集觀測信息并完成所有受控實體的動作映射。特別是基于Deep QNetwork (DQN)方法的集中式方法在電磁頻譜規(guī)劃等場景中獲得良好表現[8-10],得益于結構良好的可擴展和改進性,能夠適應多種狀態(tài)形式的觀測數據,如圖形化的頻譜瀑布圖[11]、長短時高維數據[12]等。但是,隨著受控數量的增加,集中式方法神經網絡的神經元數量將成指數上升,使得參數優(yōu)化效率變慢,策略生成性能變差,并且資源需求量大幅增加。
針對該缺點,“集中式訓練,分布式執(zhí)行”成為解決當前問題的主流理念。分布式方法分別構建對應受控個體的觀測到動作的映射網絡,再構建擬合網絡用于擬合個體動作價值到整體價值的映射。將整體“大網絡”拆分成多個“小網絡”,避免了維度爆炸。但是,該方法的難點在于由個體動作價值擬合整體價值。作為經典方法Value-Decomposition Net-works(VDN)直接將個體動作價值相加得到對整體價值。但是,并非所有個體都具有相同權重的動作價值。特別是在異構博弈對抗環(huán)境中,由于受控個體能力不同,權重必然不同。文獻[13]中,“QMIX”多智能體強化學習方法采用超神經網絡的方法對于整體價值進行了估計,使得個體動作價值到整體價值的映射具有非線性特性,有利于對整體價值的估計。文獻[14]中,“Qtran”方法在此改進思路上進一步延伸,通過構建等價函數、改進值分解等方法,提高了方法的適應性,獲得更優(yōu)的效果。但是,該思路在全局信息的利用上存在缺點。個體只采用部分可觀察信息決策,協同能力是在訓練過程中由整體價值分解得到的,以損失反饋的形式對各個體策略施加影響。在執(zhí)行過程中,難以實時利用全局信息或者由各實體觀測信息整合得到融合信息,影響決策性能。
針對該缺點,以分層強化學習為核心的博弈策略生成方法成為研究重點[15]。該思路通過構建頂層控制單元和個體執(zhí)行單元形成層級支配控制。頂層控制單元匯總個體信息并產生控制信息,控制個體基于部分可觀測信息決策。相比于典型多智能體深度強化學習方法,分層強化學習通過任務分配和組合形成整體策略。智能體在訓練過程中能夠避免智能體策略同時更新,使得單一個體對于體系內其他個體的策略擬合效率更高。文獻[16]在通信抗干擾領域中采用了該思想。首先,頂層控制模塊識別出當前通信干擾樣式,再針對性調用抗干擾樣式。但是個體策略的抗干擾樣式需要提前人為設計。文獻[17]頂層控制單元和個體執(zhí)行單元均采用神經網絡,個體策略也由數據訓練得到。上述2 種方法主要解決單一受控個體面對多任務情況下的策略生成問題,針對異構多智能體問題需要對策略生成框架改造。
基于分層強化學習,本文提出改進的多智能體博弈策略生成方法。首先,基于深度神經網絡,構造融合觀測信息的頂層策略控制模型,完成控制信息的生成。在結構上,具有根據全局信息產生控制信息的能力。在訓練過程中,能夠引導個體決策模型的生成。然后,將個體的部分觀察信息和控制信息映射為個體動作價值。最后,融合個體動作價值形成全局價值,并利用獎賞函數對整個神經網絡參數進行優(yōu)化,達到博弈策略優(yōu)化的目的。
后續(xù)研究思路如下。首先,基于分層強化學習構建觀測信息到整體價值的決策映射,以最大化整體價值作為目標構建優(yōu)化問題,并推導了策略優(yōu)化過程,為后續(xù)框架結構和方法實現的設計提供了理論依據;然后,基于決策映射與優(yōu)化問題構建,采用神經網絡設計了模型框架,詳細闡述了頂層策略控制模型和個體策略執(zhí)行模型;再次,基于策略優(yōu)化方法,給出詳細訓練流程和算法流程;最后,采用典型星際爭霸多智能體對抗(StarCraft Multi-Agent Chal-lenge,SMAC)環(huán)境,與典型多智能體方法進行性能對比,驗證方法性能,并總結全文。
1 策略生成原理
博弈對抗策略的實質是完成觀測信息到動作空間的影射,影射過程即為策略,而利用該過程得到動作即為決策。基于深度神經網絡的策略生成方法中的策略具象化是神經網絡結構和網絡參數。本文網絡結構具體分為策略控制網絡和策略執(zhí)行網絡。在網絡結構確定的情況下,對網絡參數進行優(yōu)化即對策略優(yōu)化。基于此理念,本節(jié)詳細推導策略映射、優(yōu)化問題構建和策略優(yōu)化方法。
1. 1 決策映射與優(yōu)化問題構建
通過全局信息生成控制信息,并以控制信息對各智能體的策略形成過程施加影響,提高各智能體之間的協同能力。對于策略控制網絡模型f0 用于完成融合信息o0 到控制信息I 的映射:
I = f0,θ0(o0 ), (1)
式中:I = {In},n∈[1,N]表示擬合得到的控制信息,In 表示對應N 個受控智能體;o0 表示各個智能體整合得到的全局信息,是多維矩陣形式[o1 ,…,on,…,oN],on 表示各智能體的觀測空間,即部分可觀測空間,n∈[1,N];θ0 表示深度神經策略控制網絡參數。
在控制信息的影響下,能夠降低智能體對其他智能體策略估計的難度,降低了個體策略生成的難度。對于策略執(zhí)行網絡fn 用于實現控制信息I 和部分可觀測空間on 到離散動作價值Qn 的影射。為了協同能力的提升,各個智能體均均等的拿到所有控制信息。
Qn = fn,θn(I,on ), (2)
式中:Qn 表示第n 個智能體離散動作價值的集合{qa1 ,qa2 ,…,qam },θn 表示深度神經策略執(zhí)行網絡參數。θ0 和θn 構成整個模型的網絡參數θ。
從Qn 中選擇最大值所對應的離散動作am′[18]:
am′ = argmax m Qn , (3)
式中:m∈[1,M],M 為離散動作數量。
1. 2 策略優(yōu)化方法
面對多智能體策略生成問題,整體價值最大化是策略生成與優(yōu)化的目標。多智能體整體價值Qtotal 表示各個智能體價值的累加[19]:
Qtotal = ΣNn = 1Qn,am′ , (4)
式中:Qn,am′ 為第n 個智能體對應的最大離散動作價值。
在各智能體動作在博弈環(huán)境中與對手策略交互之后,獲得的全局獎賞值為r。采用時序差分方法對離散動作價值進行更新:
Qtotal(O,a)← Qtotal(O,a)+ α[r + max a′∈A Qtotal(O′,a′)- Qtotal(O,a)],(5)
式中:α 表示折扣系數,Qtotal(O,a)表示在當前t 時刻觀測空間O 和各智能體所選動作對應的整體價值,max a′∈A Qtotal(O′,a′)表示在后續(xù)t+1 時刻觀測空間O′下各智能體對應的離散動作價值中的最大值求和得到整體價值。
用于網絡參數θ 更新的目標損失函數L 定義為:
進行K 次決策后,將每次差值求取平均值得到目標損失函數。通過最小化目標損失函數更新網絡參數θ。
2 框架結構
本節(jié)給出基于分層強化學習的模型框架,并逐層詳細闡述控制模型。
2. 1 基于分層強化學習的模型框架
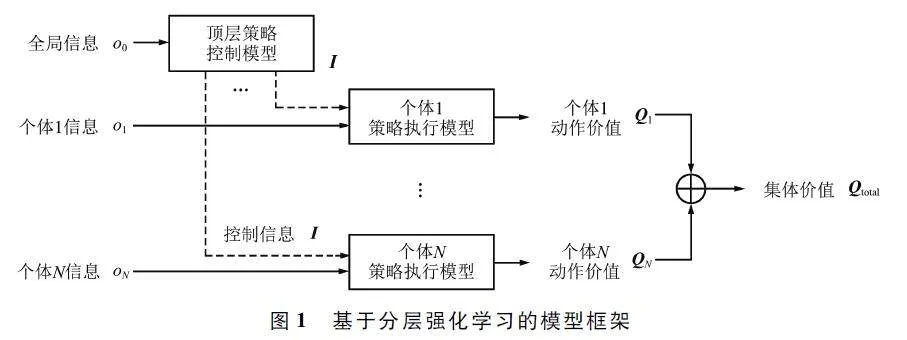
基于策略生成原理,基于分層強化學習的模型框架如圖1 所示。
根據模型框架的結構,其計算過程可以闡述如下:
首先,頂層控制模型產生控制信息。全局信息由個體部分可觀察信息組成,頂層策略控制模型基于全局信息產生控制信息,對應式(1)。
然后,個體策略執(zhí)行模型產生個體動作價值。執(zhí)行模型依據個體信息給出對應離散動作的動作價值,使得框架可以根據動作價值的最大值選擇需要執(zhí)行的動作,對應式(2)和式(3)。
最后,根據個體動作價值形成整體價值。對執(zhí)行模型產生的所有個體的最大動作價值進行累加,形成整體價值,對應式(4)。通過對整體價值的迭代優(yōu)化實現策略優(yōu)化,對應式(5)和式(6)。
2. 2 頂層策略控制模型
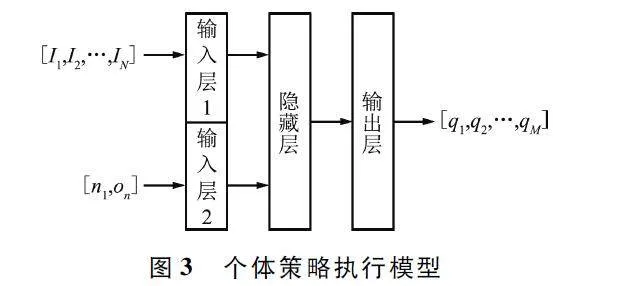
頂層策略控制模型采用深度神經網絡,包含輸入層、隱藏層和輸出層三部分。為了不失一般性并且突出本框架能力,觀測信息和離散動作空間結構采用一維矩陣,頂層策略控制模型中各層均采用全連接神經網絡,并采用ReLU 作為激活函數。特別需要說明,本文核心在于闡述并驗證改進方法的優(yōu)秀性能,弱化了特征工程,如觀測信息為高維數據矩陣等形式,可針對實際工程需求的特異性采用卷積神經網絡(Convolutional Neural Network,CNN)、長短期記憶(Long Short Term Memory,LSTM )網絡和Transform 等神經網絡結構,對本框架進一步改造。頂層策略控制模型如圖2 所示。
全局信息由個體觀測信息拼接組成,形成一維矩陣。全局信息矩陣維度為N×odim,其中odim 為個體觀測信息維度。輸入層的維度與全局信息維度一致。隱藏層用于將全局信息映射為原始控制信息。輸出層用于將原始控制信息按照控制信息維度要求進行特征提取,用于控制個體策略執(zhí)行模型。控制信息為一維矩陣,維度為N×Idim,其中Idim 為對應各個體的控制信息維度。
2. 3 個體策略執(zhí)行模型
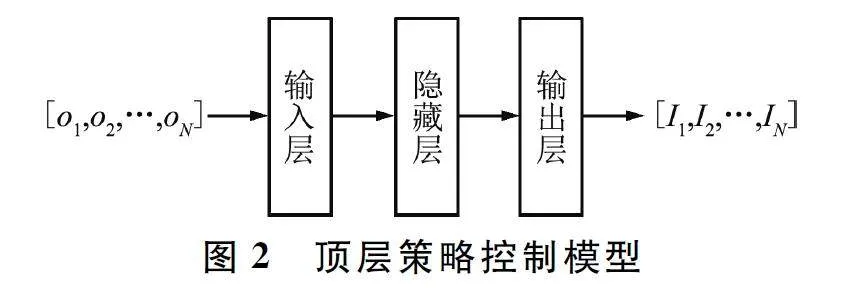
個體策略執(zhí)行模型的構建邏輯與頂層策略控制模型一致,均采用全連接神經網絡,并采用ReLU 作為激活函數,同樣包含輸入層、隱藏層和輸出層三部分。個體策略執(zhí)行模型如圖3 所示。
該模型輸入分為兩部分,分別是控制信息和融合標志位的個體信息。融合標志位的個體信息由個體標志位n 和部分可觀測信息on 構成。加入個體標志位目的是明確區(qū)分當前單體,有助于從控制信息中明確自己對應的信息特征。控制信息和個體信息經過輸入層后,隱藏層提取輸入信息中包含的特征,用于支撐輸出層生成對應離散動作的動作價值,維度為M。
3 方法實現
本節(jié)基于訓練流程和算法流程詳細描述了方法實現。
3. 1 訓練流程
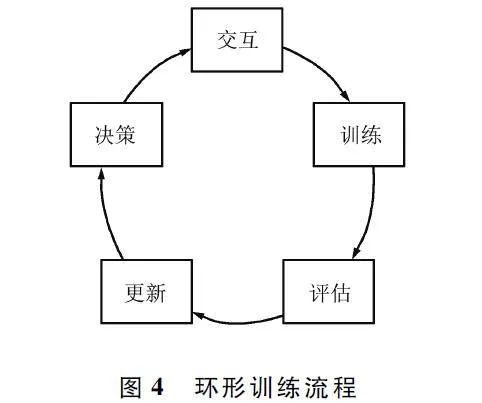
訓練流程采用環(huán)形結構,不斷迭代優(yōu)化博弈策略。除了優(yōu)化過程,還不斷對策略性能進行評估,并保存最優(yōu)參數作為最優(yōu)博弈策略。具體而言,環(huán)形訓練流程包括5 個階段,分別為決策、交互、訓練、評估和更新,如圖4 所示。
在決策階段,基于分層強化學習的模型,輸入觀測信息,得到動作價值,并選擇最大動作價值對應的離散動作。
在交互階段,在博弈環(huán)境中,利用得到的離散動作與對手策略進行交互。通過交互獲得下一步觀測信息和當前獎賞,構建包含當前觀測數據、執(zhí)行動作、當前獎賞和動作執(zhí)行后得到的下一步觀測信息,將上述4 個元素保存為經驗,并存儲在內存空間中,命名為經驗池R。
在訓練階段,隨機從經驗池中抽取多條經驗數據,采用目標損失函數計算損失誤差,并且采用累加求和的方法估計誤差,使得參數尋優(yōu)的過程相對穩(wěn)定。
在評估階段,將對當前得到的策略參數進行蒙特卡洛測試驗證。通過與對手策略進行多輪對抗,得到平均總獎賞。除此之外,如果當前訓練得到的策略參數所對應的平均總獎賞優(yōu)于歷史最優(yōu)參數,可以將當前參數保留,作為最優(yōu)策略。
在更新階段,將訓練階段得到的策略參數裝載于基于分層強化學習的模型框架,用于在下一次迭代過程中進行決策并與環(huán)境進行交互。
3. 2 算法流程
基于訓練流程,本文提出了如算法1 所示的基于分層強化學習的多智能體博弈策略生成訓練算法。
4 實驗結果與分析
實驗結果與分析由實驗場景、實驗過程、參數設置和結果分析四部分組成。
4. 1 實驗場景
本文采用OpenAI 和暴雪公司基于“星際爭霸2”構造的SMAC 環(huán)境中名為“3Z2S”的場景開展實驗[20]。SMAC 是一個用于研究多智能體強化學習的環(huán)境。這個環(huán)境基于即時戰(zhàn)略游戲“星際爭霸2”提供了一個多智能體競技場,可以用來評估和比較不同的多智能體強化學習算法。SMAC 環(huán)境提供了豐富的地圖和任務,涵蓋了多種不同的游戲場景和挑戰(zhàn),旨在推動多智能體強化學習技術的發(fā)展,并且為研究人員提供一個標準化的評測平臺。在“3Z2S”場景中,本文方法與基線策略方法分別控制5 個異構Agent 對抗,在對抗中SMAC 環(huán)境將給出對應獎賞值并自動評判是否獲勝。
除此之外,本實驗在Windows 10 操作系統(tǒng)開展,采用的主要設備為處理器、內存和圖像處理器。處理器規(guī)格為Intel(R)Core(TM)i710700K,機帶內存容量為80 GB,圖像處理器為RTX 2070 SUPER。
4. 2 實驗過程
本文實驗過程與經典多智能體強化學習方法驗證實驗的過程保持一致[13-14]。
在實驗中,共設置了106 步的訓練周期,每5 000 步為一個周期,分為訓練階段和評估階段。在訓練階段,共進行了5 000 步訓練,期間進行了神經網絡參數的優(yōu)化更新。每當完成了5 000 步的訓練,即進行一次性能評估。在性能評估階段,與基線策略進行了24 回合的對抗。
在評估指標方面,使用了勝率和平均獎賞。對于勝率,統(tǒng)計了與“3Z2S”場景的基線策略進行對抗獲勝的次數,然后除以總回合數24,得到了勝率。而對于平均獎賞,則是累加了24 回合對抗中SMAC給出的獎賞,再除以總回合數24,得到了平均獎賞。
除此之外,在實驗過程中,將QMIX 和VDN 方法作為對照組,在“3Z2S”場景中分別計算了它們的勝率和平均獎賞。以驗證本方法在性能方面的表現,并與已有的方法進行比較。
4. 3 參數設置
方法參數分為2 類:一類為在策略優(yōu)化過程的學習參數;另一類為構成模型的深度神經網絡參數。學習參數包括獎賞折扣參數、學習率和批量大小,分別設置為0. 99、5×10-4 和32。模型的深度神經網絡參數如表1 所示。
4. 4 結果分析
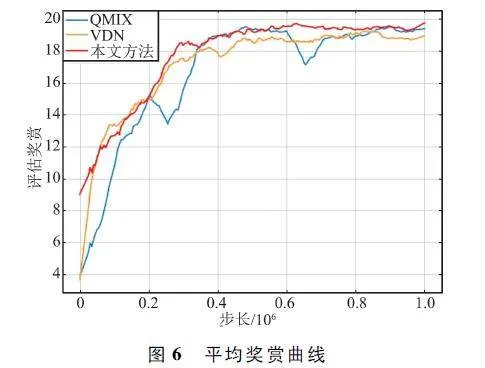
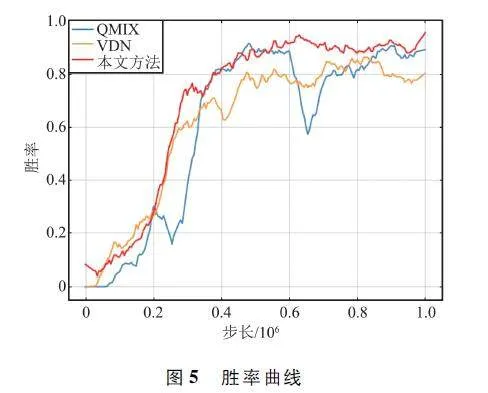
勝率曲線如圖5 所示。通過圖中對比可以直觀發(fā)現,在初始階段,本方法可獲得高于QMIX 和VDN 的勝率。二者較慢的原因是由于全局信息間接反饋,并且初始階段數據量較少,個體策略無法穩(wěn)定生成,從而其他個體也無法有效通過估計其他個體的策略生成協同策略。除此之外,本文方法相比于2 種典型方法能夠更快達到勝率穩(wěn)態(tài),更高效地形成博弈對抗策略。
平均獎賞曲線如圖6 所示。通過圖中曲線對比可以看出,平均獎賞曲線圖與勝率曲線圖的趨勢近似,本文方法在效率上明顯超過典型方法。
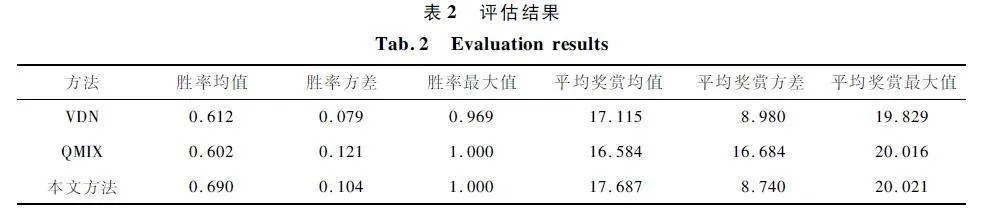
為了客觀評估本方法,給出與2 種典型方法的指標評估,指標包括勝率均值、勝率方差、勝率最大值、平均獎賞均值、平均獎賞方差和平均獎賞最大值。評估結果如表2 所示。
對于勝率,本文方法能夠獲得最大勝率均值。雖然勝率方差低于VDN 方法,但是能夠獲得最大勝率。對于平均獎賞,對比均值和方差,本文方法的均值最高并且方差最低,充分說明了本文方法的穩(wěn)定性。除此之外,在勝率和平均獎賞上,本文方法的最大值均為三者之中最高,有效地說明了本文方法的高效性。
5 結束語
針對典型多智能體深度強化學習方法對于全局信息利用不重復導致個體策略生成慢的問題,本文提出了一種基于分層強化學習的多智能體博弈策略生成方法,通過構建頂層策略控制模型,完成全局信息的提取和控制信息的映射,從而實現層次化分解策略。個體策略執(zhí)行模型在控制信息的引導下,完成部分可觀測信息到動作價值函數映射。將典型方法被動優(yōu)化群體值函數的擬合參數轉化為主動將群體策略分解為個體策略,便于快速生成協同策略的目標。實驗驗證表明,本文所提方法在于基線策略對抗勝率達到100% ,相較典型方法VDN 和QMIX,本文方法勝率最高且方差較低。本文所提方法結構簡潔、可解釋性強,能夠針多受控體有效、高效地生成并優(yōu)化博弈策略。本方法采用個體離散動作價值相累加的方法估計整體價值。雖然結構簡單且計算復雜度低,但是對于各智能體的特性能力缺少較多關注,限制了整體能力。然而,利用超神經網絡估計整體價值的計算復雜度高,并且給策略生成效率帶來了挑戰(zhàn)。在后續(xù)研究中,重點應放在從個體價值相整體價值的估計上,給出能夠平衡計算復雜度和策略效果的估計方法。
參考文獻
[1] FENG S,SUN H W,YAN X T,et al. Dense ReinforcementLearning for Safety Validation of Autonomous Vehicles[J]. Nature,2023,615:620-627.
[2] MNIH V,KAVUKCUOGLU K,SILVER D,et al. Humanlevel Control Through Deep Reinforcement Learning[J].Nature,2015,518:529-533.
[3] VINYALS O,BABUSCHKIN I,CZARNECKI W M,et al.Grandmaster Level in StarCraft II Using Multiagent Reinforcement Learning[J]. Nature,2019,575:350-354.
[4] 暢鑫,李艷斌,趙研,等. 基于MA2IDDPG 算法的異構多無人機協同突防方法[J]. 河北工業(yè)科技,2022,39(4):328-334.
[5] CHANG X,LI Y B,ZHAO Y,et al. An Improved Antijamming Method Based on Deep Reinforcement Learningand Feature Engineering [J]. IEEE Access,2022,10:69992-70000.
[6] CHANG X,LI Y B,ZHAO Y,et al. A MultiplejammerDeceptive Jamming Method Based on Particle Swarm Optimization Against Threechannel SAR GMTI [J]. IEEEAccess,2021,9:138385-138393.
[7] MNIH V,KAVUKCUOGLU K,SILVER D,et al. PlayingAtari with Deep Reinforcement Learning [EB / OL ].(2013-12-19)[2024-01-06]. https:∥arxiv. org / abs /1312. 5602.
[8] HASSELT H V,GUEZ A,SILVER D. Deep ReinforcementLearning with Double Qlearning[C]∥Proceedings of theThirtieth AAAI Conference on Artificial Intelligence. Phoenix:AAAI,2016:2094-2100.
[9] SCHAUL T,QUAN J,ANTONOGLOU I,et al. PrioritizedExperience Replay[EB / OL]. (2015 - 11 - 18 )[2024 -01-06]. https:∥arxiv. org / abs / 1511. 05952.
[10] WANG Z Y,SCHAUL T,HESSEL M,et al. DuelingNetwork Architectures for Deep Reinforcement Learning[C]∥ Proceedings of the 33rd International Conferenceon International Conference on Machine Learning. NewYork:JMLR,2016:1995-2003.
[11] LIU X,XU Y H,JIA L L,et al. Antijamming Communications Using Spectrum Waterfall:A Deep ReinforcementLearning Approach [J]. IEEE Communications Letters,2018,22(5):998-1001.
[12] NAPARSTEK O,COHEN K. Deep Multiuser Reinforcement Learning for Distributed Dynamic Spectrum Access[J]. IEEE Transactions on Wireless Communications,2019,18(1):310-323.
[13] RASHID T,SAMVELYAN M,WITT C S D,et al. Monotonic Value Function Factorisation for Deep MultiagentReinforcement Learning[J]. Journal of Machine LearningResearch,2020,21(1):7234-7284.
[14] SON K,KIM D,KANG W J,et al. Learning to Factorizewith Transformation for Cooperative Multiagent Reinforcement Learning [EB / OL]. (2019 - 05 - 14)[2024 -01-06]. http:∥arxiv. org / abs / 1905. 05408.
[15] SHI W S,LI J L,WU H Q,et al. Dronecell TrajectoryPlanning and Resource Allocation for Highly Mobile Networks:A Hierarchical DRL Approach[J]. IEEE Internetof Things Journal,2020,8(12):9800-9813.
[16] LIU S Y,XU Y F,CHEN X Q,et al. Patternaware Intelligent Antijamming Communication:A Sequential DeepReinforcement Learning Approach [J ]. IEEE Access,2019,7:169204-169216.
[17] KULKARNI T D,NARASIMHAN K R,SAEEDI A,et al.Hierarchical Deep Reinforcement Learning:IntegratingTemporal Abstraction and Intrinsic Motivation[C]∥Proceedings of the 30th International Conference on NeuralInformation Processing Systems. Barcelona:Curran Associates Inc. ,2016:3682-3690.
[18] NOCEDAL J,WRIGHT S J. Numerical Optimization[M].New York:Springer,2006.
[19] SUTTON R S,BARTO A G. Reinforcement Learning:AnIntroduction[M]. Cambridge:MIT Press,1998.
[20] SAMVELYAN M,RASHID T,WITT C S D,et al. TheStarCraft Multiagent Challenge. [EB / OL]. (2019 - 02 -11)[2024-01-06]. http:∥arxiv. org / abs / 1902. 04043.
作者簡介
暢 鑫 男,(1990—),博士,高級工程師。
劉東輝 女,(1990—),博士,講師。主要研究方向:復雜系統(tǒng)管理、策略優(yōu)化等。
基金項目:中國博士后科學基金(2021M693002);國家自然科學基金(71991485,71991481,71991480)
