基于CART決策樹的分布式數據離群點檢測算法
2024-09-21 00:00:00朱華喬勇進董國鋼
現代電子技術 2024年16期
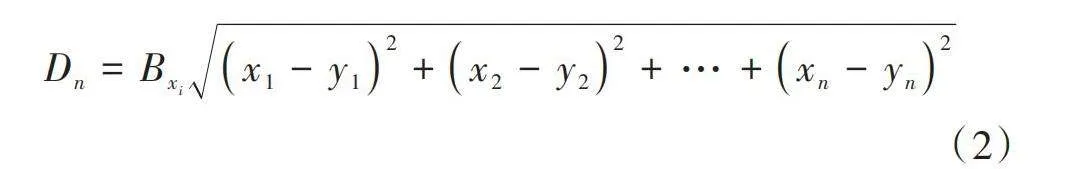
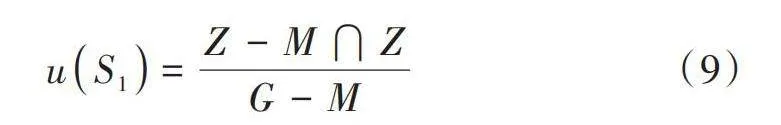

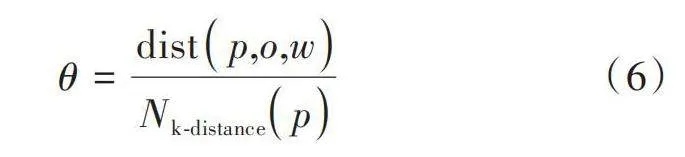



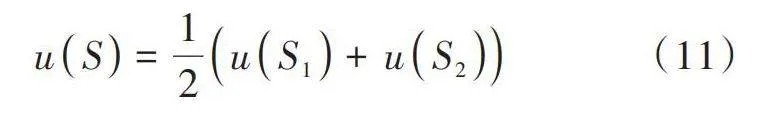

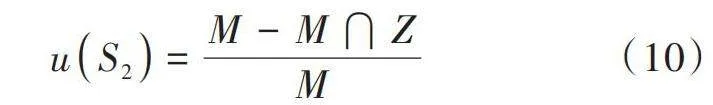


摘" 要: 在分布式計算環境中,離群點通常表示數據中的異常情況,例如故障、欺詐、攻擊等。通過檢測分布式數據的離群點,可以對這些異常數據進行集中處理,保護系統和數據的安全。而進行離群點檢測時,不僅要考慮數據的規模和復雜性,還要在分布式環境下高效地發現離群點。因此,提出一種基于CART決策樹的分布式數據離群點檢測算法。在構建CART決策樹時,使用類間中心距離作為分裂準則,根據分離類別對訓練數據進行分類,從而確定數據的類型。在上述基礎上,考慮到離群點的分布模式與其周圍數據對象不同,使用空間局部偏離因子(SLDF)對空間內各個數據對象之間的離群程度展開度量,同時在高維空間內展開網格劃分,引入SLDF算法檢測剩余離群點集,最終實現分布式數據離群點檢測。實驗結果表明,所提方法的離散點檢測錯誤率在0.010以內,可以更加精準地實現分布式數據離群點檢測,具有良好的檢測性能。
關鍵詞: CART決策樹; 分布式數據; 離群點檢測; 類間距離; 數據分類; 空間局部偏離因子
中圖分類號: TN919?34; TP391" " " " " " " " " "文獻標識碼: A" " " " " " " " " " " 文章編號: 1004?373X(2024)16?0157?06
Distributed data outlier detection algorithm based on CART decision tree
ZHU Hua1, QIAO Yongjin2, 3, DONG Guogang1
(1. School of Computer Science and Technology, Wuhan University of Bioengineering, Wuhan 430415, China;
2. China Agricultural University, Beijing 100091, China; 3. Shanghai Academy of Agricultural Sciences, Shanghai 201403, China)
Abstract: In distributed computing environments, outliers often represent abnormal situations in data, such as failures, fraud, attacks, etc. By detecting outliers in distributed data, these abnormal data can be processed centrally to protect the security of the system and data. When conducting outlier detection, it is not only necessary to consider the size and complexity of the data, but also to efficiently discover outliers in a distributed environment. Therefore, a distributed data outlier detection algorithm based on CART decision tree is proposed. When constructing the CART decision tree, the inter class center distance is used as the splitting criterion to classify the training data according to the separated categories, so as to determine the type of data. On the basis of the above, considering that the distribution pattern of outliers is different from their surrounding data objects, a spatial local deviation factor (SLDF) is used to measure the degree of outliers between various data objects in space. The grid partitioning is carried out in high?dimensional space, and the SLDF algorithm is introduced to detect the remaining outlier set, ultimately realizing the outlier detection of the distributed data. The experimental results show that the error rate of the proposed method for the outlier detection is within 0.010, which can realize more accurate outlier detection of the distributed data, and has good detection performance.
Keywords: CART decision tree; distributed data; outlier detection; inter class distance; data classification; spatial local deviation factor
0" 引" 言
在分布式數據[1?2]中,離群點即那些與數據集中其他數據點顯著不同的數據點,蘊含著重要的信息,如異常行為、故障預警或新的發現等[3?4]。因此,有效地檢測和處理離群點對于提高數據質量、增強決策準確性和保障系統安全具有重要意義。國內外相關專家針對分布式數據離群點檢測方面的內容展開了大量研究。
張忠平等采用近鄰數替換k近似關系,組建全部的鄰域集合,采用質心投影概念刻畫各個數據對象和其鄰居點的分布特征;在數據對象鄰居點逐漸增多的情況下,通過質心投影波動衡量各個數據對象的離散程度,最終實現離群點檢測[5]。該算法在數據集比較大或者維度比較高的情況下,計算復雜度會大幅度增加。鄭忠龍等通過密度估計獲取穩態密度,根據穩態密度展開不同策略的模擬投票;同時考慮了數據點的重要性和其近鄰的相似性展開投票,根據投票結果實現離群點檢測[6]。該算法中的密度估計在實際應用過程中會受到數據分布以及噪聲等因素的影響,從而導致估計結果準確率偏低,進而影響離群點檢測結果。Jing W等采用坐標映射對不同坐標系的數據坐標展開轉換,通過主成分分析可以精準地提取網絡中的流數據特征,最終使用差分點因子對網絡中的非線性異常值展開檢測[7]。該算法適用于特定的數據類型,對于其他類型的數據適用性較差。S. M. Kaddour等提出了一種基于能耗數據的異常檢測方法,以幫助居民減少能源消耗,并為能源提供商提供詳細數據,從而改善能源管理[8]。在研究過程中,某些無監督異常檢測方法對于特定類型的數據特征更為適用,如果所選模型并未考慮到能耗數據的特點,可能無法準確捕捉異常行為,從而導致誤報或漏報。
CART決策樹作為一種強大的機器學習模型,具有良好的解釋性和分類能力。其通過遞歸地將數據劃分為更純的子集來生成樹結構,這一過程自然地適用于數據的分布式處理。通過將決策樹與分布式計算框架相結合,可以實現對大規模數據的并行處理,從而顯著提高離群點檢測的效率。因此,本文提出一種基于CART決策樹的分布式數據離群點檢測算法。
1" 分布式數據離群點檢測
1.1" 分布式數據分類
分布式環境下,數據存儲在不同的節點上,但節點中存在數據傾斜問題,即某些節點上的數據量遠大于其他節點,導致部分節點計算負載過重,影響整體離群點檢測的準確性和效率。而將分布式數據集劃分為多個不同類別的子集,再分布到不同的節點上并行處理,最后整合各節點的結果,可以縮短計算時間,提高效率。CART決策樹是一種二叉樹結構,采用自上而下的遞歸方式展開劃分,在分布式數據分類[9?10]過程中,其可以清晰地展示數據屬性之間的關系和分類依據,有效降低上層節點的分類誤差,獲取更加精準的分類結果。
在構建決策樹時,需要選擇一個最佳的特征和閾值來劃分數據集。通過計算類間距離,可以量化不同類別之間的相似度或差異度,從而更好地選擇適合劃分數據的特征和閾值。
設定類別中共有[N]個樣本,每個樣本具有[i]個特征,則樣本中第[i]個特征的平均值[Bxi]可以表示為:
[Bxi=1Nj=1Nxij] (1)
式中[xij]代表第[j]個樣本中第[i]個特征值。采用公式(1)計算獲取各類分布式數據中每個特征的平均值后,即可確定各類數據的類中心。
接下來,計算各類樣本之間的類間距離[Dn],公式如下:
[Dn=Bxix1-y12+x2-y22+…+xn-yn2] (2)
式中:[xn]和[yn]代表不同類別的分布式數據特征值。
基于數據挖掘[11?12]技術的思想,將分布式數據進行數據清理和集成等相關操作,進而獲取一組高純度的數據集,并直接將其存儲于數據庫中;然后確定數據集的相關屬性,選取分裂函數最大值對應的屬性[Ci]作為分裂屬性。分裂屬性的計算公式如下所示:
[Ci=PkDnRij] (3)
式中:[Rij]代表分布式數據集中的第[i]個屬性;[Pk]代表分布式數據集中第[i]個屬性第[j]個屬性值為第[k]類決策屬性的概率。
通過最佳分裂屬性即可確定最佳分裂點。最佳分裂屬性[Cibest]可以表示為:
[Cibest=CiRLRkRFjtL-RFjtR]" " " " " (4)
式中:[t]的下標L和R代表當前分裂節點的左子樹和右子樹;[RFjtL]和[RFjtR]代表左子樹和右子樹中任意數據記錄被判定為類別[Fj]的概率;[RL]和[Rk]代表分布式數據集中數據記錄所占比例。
依據最佳的分割屬性將當前節點的數據集劃分為兩個子集,一旦所有的葉節點只包含屬于同一類別的訓練樣本,或者沒有可用的分割屬性,則構建二叉樹的流程結束;否則,將繼續在待分裂的節點中展開計算,以找到下一個節點的最佳分裂值。但該過程中生成的二叉樹規模龐大,為了降低計算復雜度,采用剪枝技術在所構建的二叉樹中以最小代價復雜性為目標,組建一顆真誤差率比較小的二叉樹,操作步驟如下。
1) 計算當前二叉樹中節點[Hi]的各個節點[t]的值,公式如下:
[ht=At×h×Tt-AhThTt-1]" "(5)
式中:[ht]代表節點集合[H]中內節點[t]的值;[At]代表擬合節點所在數據集對應的局部平方誤差;[Tt]代表模型的擬合效果評估值;[Ah]代表最小子樹;[Th]代表模型準確性度量結果。
2) 求解最小內節點,同時將其作為下一棵最小樹。
3) 判斷當前是否只有一個根節點。只有一個根節點時,根據分裂屬性確定第一優先級分離類別;反之則跳轉至步驟1)。
4) 設定Gini系數閾值,計算數據集中不同特征的Gini系數;再以Gini系數為判定依據,確定左右節點上的分離類別。如果Gini系數低于設定的閾值則回到決策樹的子節點,重新確定左右節點上的分離類別,完成組建。
5) 將數據集中不同類型的數據分別采用不同的數字代替,同時將數字化的數據進行歸一化處理,確保各值都在[0,1]。
6) 將一個類型的樣例用作正例,剩余部分則用于反例,通過其完成分類器的訓練。
7) 訓練完成后,將預測結果作為第一優先級分離類別的樣本輸出,并剔除該分裂屬性。根據第二優先級分離類別對其他的訓練數據展開分類,確定數據的類型。
8) 重復步驟6)、步驟7),直至分離類別中只有一個類別,輸出最終的分布式數據分類結果。
1.2" 數據離群點檢測
數據離群點檢測的目標是識別異常數據點,而異常數據點通常是在數據分類過程中被錯誤分類的樣本。同時,考慮到離群點的分布模式與其周圍數據對象不同,因此,在分布式數據分類[13?14]的基礎上,采用空間局部偏離因子(SLDF)對設定空間內不同數據對象的離散程度展開度量,更好地捕捉到數據對象之間的相對位置關系,即哪些數據對象在空間中相對分散,哪些數據對象相對聚集。這種信息可以幫助識別出屬于離群點的數據對象,提高離群點檢測的效果。
設定對象[p]的k距離鄰域[Nk?distancep],則對象對其鄰域內全部鄰居的平均值[θ]表示為:
[θ=distp,o,wNk?distancep]" " "(6)
式中:[distp,o,w]代表鄰域內全部鄰居的數量;[o]代表數據對象。
結合上述分析,給出SLDF度量空間點對象離群程度的步驟。
1) 對各個對象的非空間屬性值進行歸一化處理。
2) 通過計算可以確定分布式數據集合中隨機兩個數據對象之間的空間距離,進而更好地掌握和理解數據間的關系以及真實分布情況。
3) 從數據集中隨機選擇一個起始點,然后根據數據的特性,逐步確定每個數據點在空間中的位置和鄰近區域。
4) 根據設定的順序對數據集中的各個數據對象展開空間局部偏離率[Sp]計算,即:
[Sp=θNk?distancep]" " " " " " (7)
5) 按照空間局部偏離因子大小對其展開降序排列,同時利用給定的參數,選取一定數量的對象作為結果直接輸出。
接下來展開網格劃分處理,并通過SLDF算法檢測剩余部分的離群點[15]。
第一階段步驟如下所示。
1) 任意地選擇一個分布式數據子空間中沒有訪問過的點,以設定的維度間隔距離值作為判定依據展開網格單元劃分。
2) 組建哈希函數,將網格單元信息映射到對應的哈希表中,計算網格單元中包含的分布式數據點總數。根據事先設定的值判斷網格單元所屬的類型,即稠密網格單元還是非密集網格單元。
3) 對哈希表中的全部標記展開遍歷處理,將其設定為稠密的網格單元,利用其對應的鄰近單元特征判斷網格是否為邊界網格單元,相應地做好標記。
4) 刪除全部稠密網格單元和非邊界網格單元中的聚類點,將剩余網格單元放入到候選離群點集合中。
5) 重復以上操作步驟,直至分布式數據集中全部的點都映射到對應的哈希表中,獲取數據空間中全部聚類區域和全部由非邊界網格單元包含的聚類點,同時將其剔除。
第二階段步驟如下所示。
1) 對分布式數據集展開第1次掃描,獲取每一維數據集中數據對應的取值。將全部數據按照維度大小展開排序,同時利用公式(8)計算各個維度的等分間隔[Dp]。
[Dp=SpNk?distancep]" " " " " " (8)
2) 繼續對數據集展開掃描描述,經過計算確定數據點在不同維度對應的網格單元;同時利用哈希函數將獲取的網格單元分別映射到對應的哈希表中。
3) 對哈希表掃描,識別出邊界單元網格。
4) 通過廣度優先的遍歷方法對哈希表中的候選離群點展開掃描,同時利用SLDF算法計算各個數據對象的SLDF值[S?]。
第三階段步驟為:將全部數據對象的[SLDFk]值進行降序排列,選取前[m]個數據對象對應的結果作為輸出,實現分布式數據離群點檢測。
2" 實驗分析
2.1" 實驗設置
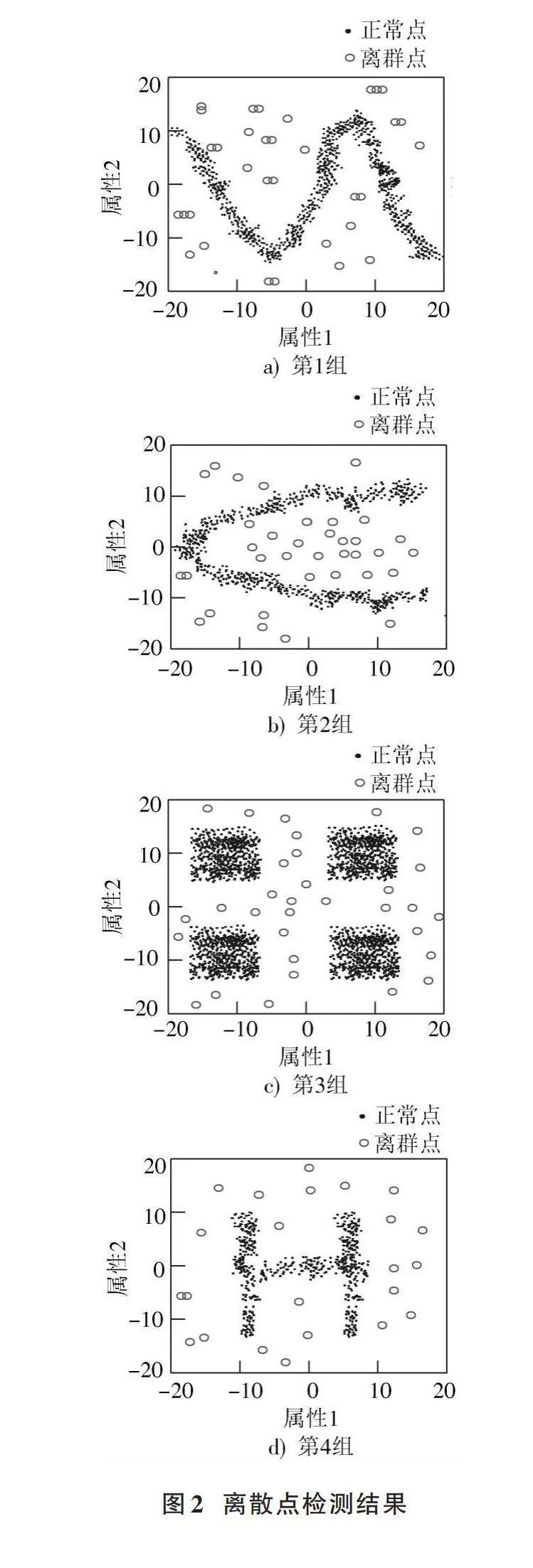
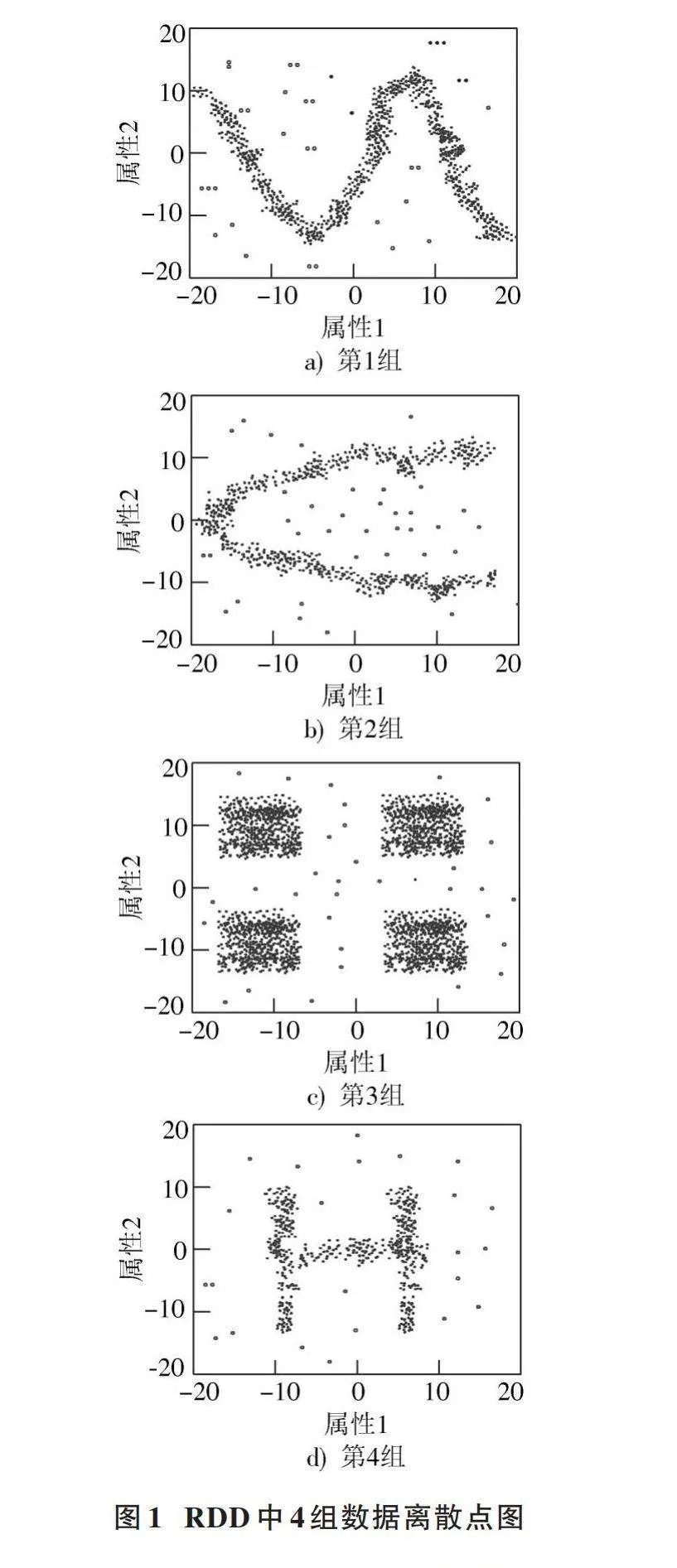
為了驗證基于CART決策樹的分布式數據離群點檢測算法的有效性,選取RDD分布式數據集用于實驗。RDD在抽象上來說是一種元素集合,分為多個分區,每個分區分布在集群中的不同節點上,從而讓RDD中的數據可以被并行操作。在RDD中隨機選取4組數據,離散點圖如圖1所示。
在Ubuntu 20.04 LTS操作系統中設置如表1所示的實驗參數,得到的離群點檢測結果如圖2所示。
分析圖2可知,所提算法可以將離散點與正常點進行有效區分,表明所提方法可以有效檢測出分布式數據中的離散點。
2.2" 結果與分析
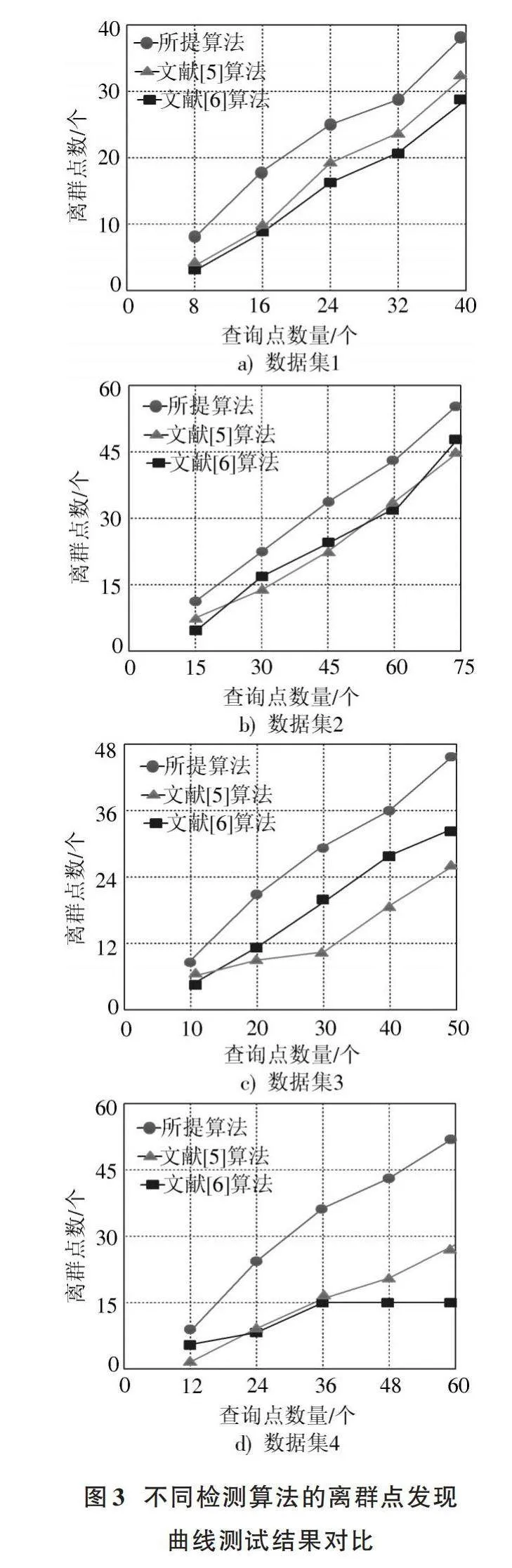
為了進一步驗證所提方法的有效性,在圖1所示的4種不同數據中,以文獻[5]方法和文獻[6]方法作為對比方法展開離群點檢測,獲取的離群點發現曲線如圖3所示。
曲線測試結果對比
通過分析圖3中的實驗數據可以看出,在不同的人工數據集中,所提算法對應的離群點發現曲線表現出最佳性能,說明采用所提算法可以更好地提升分布式數據離群點檢測性能,并且可以適用于不同類型的數據集,具有較好的檢測性能和穩定性。
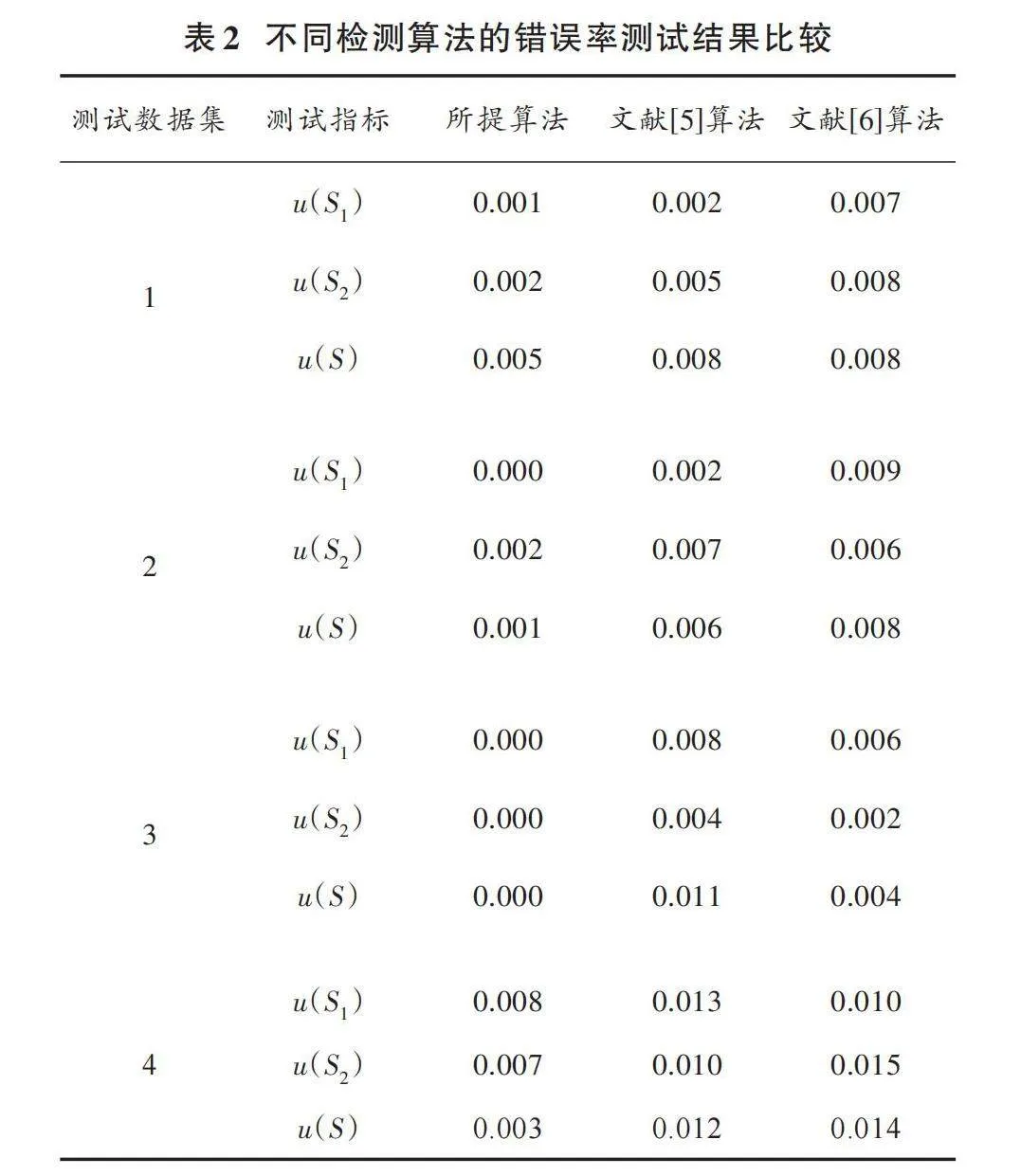
為了進一步驗證各個算法的檢測性能,采用兩種識別錯誤展開分析,第一種類型為[S1],即正常數據被標識為錯誤標記離群點數據;第二種類型為[S2],即錯誤標記離群點數據可以被正確識別。定義3個指標衡量各個算法的性能,具體如下所示。
1) [uS1]代表錯誤丟棄正常數據的概率,公式如下:
[uS1=Z-M?ZG-M] (9)
式中:[Z]代表檢測到的離群點數據;[M]代表訓練樣本中真實離群點數據數量;[G]代表訓練樣本的數量。
2) [uS2]代表誤標記離群點數據沒有被正確識別,主要反映的是漏檢測率,公式如下:
[uS2=M-M?ZM]" (10)
3) [uS]是上述兩種錯誤的一種綜合考慮,公式為:
[uS=12uS1+uS2] (11)
表2給出了各個算法在不同數據集的測試結果。通過分析表2中的實驗數據可以看出,采用所提算法獲取的各項測試指標在0.010以內,均低于另外兩種算法。說明通過所提算法可以有效檢測出分布式數據集中的離群點,充分驗證了該算法的優越性和有效性。
3" 結" 語
離群點通常表示數據中的異常情況,例如故障、欺詐、攻擊等。為保證數據安全,本文提出一種基于CART決策樹的分布式數據離群點檢測算法。在構建CART決策樹時,使用類間中心距離作為分裂準則,根據分離類別對訓練數據進行分類,從而確定數據的類型。在上述基礎上,考慮到離群點的分布模式與其周圍數據對象不同,使用空間局部偏離因子(SLDF)對空間內各個數據對象之間的離群程度展開度量,同時在高維空間內展開網格劃分,引入SLDF算法檢測剩余離群點集,最終實現分布式數據離群點檢測。
通過實驗分析表明,所提算法在不同數據中具有良好的分布式數據離群點檢測性能,可以有效提升檢測結果的準確性。在后續的研究過程中,將針對檢測效率方面的內容進行探索。
參考文獻
[1] 吳愛華,陳出新.分布式數據庫中關系數據正負關聯規則挖掘[J].計算機仿真,2021,38(9):344?347.
[2] 金利娜,于炯,杜旭升,等.基于生成對抗網絡和變分自編碼器的離群點檢測算法[J].計算機應用研究,2022,39(3):774?779.
[3] 葉晟,吳曉朝.基于網格劃分和LLE的高維數據離群點自適應檢測方法[J].湖南科技大學學報(自然科學版),2023,38(1):85?91.
[4] 張忠平,鄧禹,劉偉雄,等.FNOD:基于近鄰差波動因子的離群點檢測算法[J].高技術通訊,2022,32(7):674?686.
[5] 張忠平,張玉停,劉偉雄,等.基于質心投影波動的離群點檢測算法[J].計算機集成制造系統,2022,28(12):3869?3878.
[6] 鄭忠龍,曾心,劉華文.兩階段的近鄰密度投票模擬離群點檢測算法[J].鄭州大學學報(工學版),2023,44(6):33?39.
[7] JING W, WANG P, ZHANG N. A nonlinear outlier detection method in sensor networks based on the coordinate mapping [J]. International journal of sensor networks, 2022, 39(2): 136?144.
[8] KADDOUR S M, LEHSAINI M. Electricity consumption data analysis using various outlier detection methods [J]. International journal of software science and computational intelligence, 2021, 13(3): 12?27.
[9] 梁越,劉曉峰,李權樹,等.面向司法文本的不均衡小樣本數據分類方法[J].計算機應用,2022,42(z2):118?122.
[10] 薛占熬,李永祥,姚守倩,等.基于Bayesian直覺模糊粗糙集的數據分類方法[J].山東大學學報(理學版),2022,57(5):1?10.
[11] 陳波,詹明強,黃梓莘.基于關聯規則的庫岸邊坡監測數據挖掘方法[J].長江科學院院報,2022,39(8):58?64.
[12] 周燕,肖莉.基于改進關聯聚類算法的網絡異常數據挖掘[J].計算機工程與設計,2023,44(1):108?115.
[13] 朱先遠,嚴遠亭,張燕平.鄰域信息修正的不完整數據多填充集成分類方法[J].計算機工程與應用,2023,59(23):125?135.
[14] 李京泰,王曉丹.基于代價敏感激活函數XGBoost的不平衡數據分類方法[J].計算機科學,2022,49(5):135?143.
[15] 高志宇,宋學坤,肖俊生,等.基于神經網絡的大規模數據集離群點檢測算法[J].沈陽工業大學學報,2022,44(4):420?425.
